最大似然分類的國內車牌字符識別方法研究
2020-06-10 09:38:16張晨
延安職業技術學院學報 2020年2期
張 晨
(廈門軟件職業技術學院,福建 廈門361024)
一、引言
近年來,隨著汽車工業的發展和汽車消費需求的激增,全球汽車保有量持續上升,已遠超十億。技術的發展使公路變得越來越自動化、智能化,車牌識別系統成為智慧城市的重要組成部分,伴隨車牌識別技術在智能交通系統、高速公路收費、交通分析與執法、自動車輛停車場等領域的深入應用,車牌的識別需求也越來越大。中國的汽車消費市場潛力巨大,保有量增速連續多年居世界第一,國內車牌識別需求越來越大。國外的車牌識別技術起步較早,已有較成熟的系統,但國外車牌在尺寸、顏色、字符等特征上與國內有所不同,直接將國外的技術和系統應用到國內會存在適應性的問題。
車牌識別主要依靠計算機視覺技術,將汽車牌照從場景中提取出來經過一系列處理最后完成字符的識別。車牌識別系統通常由圖像采集、圖像預處理、車牌定位、字符分割和字符識別五部分組成。字符識別是整個流程的核心環節,常常基于OCR 技術完成,是模式識別的一種,目前比較常見的識別方法是模板匹配法、特征匹配法和人工神經網絡。雖然,目前字符識別的研究和現有的系統所采用的技術手段不盡相同,但字符識別一直是車牌識別技術研究的核心內容。本文采用的最大似然分類的方法,利用其具有快速、簡單的特點完成對車牌字符識別進行研究,作為車牌字符識別方法的一個參考。
二、車牌圖像預處理
各個國家和地區的車牌字符寬度、高度、距離等一般是按照標準確定的,不同地域范圍的字符形態特征不盡相同。我國普通汽車車牌由七個字符構成,第一位字符為漢字,代表各省、直轄市、自治區的簡稱;第二位字符為A到Z的大寫英文字母,其中字母O 和I 不使用;第三至第七位字符為大寫英文字母或阿拉伯數字的組合。完成車牌圖像采集之后需要經過二值化、邊緣檢測和形態學處理等一系列圖像預處理過程,以確保字符能夠準確無誤的識別出來。
(一)車牌圖像采集
采集技術決定了車牌圖像的質量,在良好的照明條件和合理的拍攝距離及角度下,采集到的圖像應具有良好的空間分辨率、合理的銳度和較高的對比度。輸入圖像的質量越高,車牌識別的精度期望就越高。當車輛進入識別區域,由成像系統通過攝像頭拍攝完成車牌原始圖像的采集工作,再通過圖像采集卡將圖像進行模擬圖像到數字圖像的轉換并輸入存儲到計算機中。
(二)圖像預處理
各種干擾因素會影響車牌圖像采集造成圖像失真,如感光元件靈敏度不一致造成的光電轉換異常,模數轉換和傳輸過程產生的噪聲,以及其他環境干擾因素等等。利用圖像處理技術可以去除噪聲,提高圖像的細節和輪廓邊緣,還原圖像特征。圖像預處理主要包括三方面的內容:高斯濾波降低圖像噪聲使圖像平滑;圖像灰度化增強圖像的效果;圖像二值化將灰度圖像轉化為二值圖像。
(三)車牌的定位
利用Sobel 算子得到一階水平方向導數,推算出車牌的相對位置,再通過otsu 進行閾值分割,使用閉操作,使車牌區域連接成一個矩形,之后把全圖的輪廓都計算出來并計算輪廓的外接矩形,把傾斜角度大于額定閾值的矩形舍棄,把余下的矩形進行微小的旋轉使其水平,最后完成車牌圖塊的篩選和驗證。
(四)字符分割
按照GA 36-2018《中華人民共和國機動車號牌》行業標準,國內普通汽車車牌布局相對統一,如圖1 所示即寬度為440mm,高度為140mm,字符寬為450mm,高度900mm,寬高比為0.5,第一個字符左邊距為15mm,第二個字符與第三個字符之間的間隙為34mm,其他字符間隙為12mm。把彩色的車牌圖片進行灰度化處理,再使用不同的參數利用大津閾值法進行二值化,根據車牌字符寬度和高度、字符間距、左右邊距等特征得到字符的切割算法公式把圖中的字符矩形區域逐一截取出來。最后歸一化到統一格式。

圖1 國內車牌常見尺寸布局
三、字符特征提取
(一)粗網格特征提取
將分割輸出的字符圖像進行二值化,僅保留黑白像素點,并歸一化為40x20的尺寸,經過處理后的二值點陣圖是一個二維的位數組,每個位點與圖像像素相對應。以像素作為取樣單位,通過對每行和列進行遍歷掃描,灰度值為1的記作黑色,為0的記作白色,統計行和列的1值點數即為該點陣圖的特征值。粗網格特征反映出了字符的整體形狀和像素值分布情況,但容易受到字符傾斜、偏移等情況的影響,因此再結合梯度數據來提取圖像的特征。
(二)梯度特征提取
采用HOG提取圖像邊緣輪廓特征分布數據,進一步減弱噪聲干擾,獲取輪廓信息。通過計算和統計圖像局部區域的梯度方向直方圖得到特征描述子,構成圖像梯度特征:
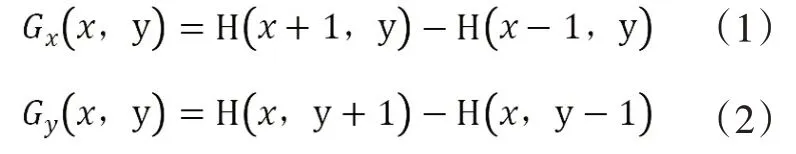

最后由粗網格特征和梯度特征構成整張字符圖像的特征:

四、最大似然分類
(一)最大似然估計
最大似然估計是一種使用概率模型來進行參數估計的方法。利用已知的樣本結果,構建模型并在此基礎上,反推最有可能產生這個結果的模型參數值。利用最大似然估計的基本思想:當車牌字符圖片樣本為(n 為樣本的容量)時,根據概率密度函數構建信號似然函數L(θ),得出θ來使某結果出現的可能性達到最大,并求其最大值對應的θ。
(二)最大似然分類
基于統計分類器的方法是字符識別中常用的方法,如隱馬爾科夫隨機模型(HMMs)、SVM等。最大似然法分類基于經典統計模式識別理論,是一種監督分類方法。分類判別規則基于概率,預先設置好的m類模型數據集,計算出某個像元屬于m中某一類的概率,然后再將該像元劃分到概率最大的那一類。在車牌字符識別中,每個字符樣本數據都是獨立于其他字符數據生成的,所有字符數據的總概率為每個數據點的概率的乘積,即邊緣概率的乘積,從高斯分布中生成的單個目標數據點的邊緣概率是:


μ 是該類別樣本中所有值的估計均值,㎡是該類別樣本中所有觀測值的估計方差。只要得出能夠讓上述表達式最大化的μ 和m 的值就可以得到該樣本最大概率。此時,標準樣本偏差近似為一組特征似然函數的總和:

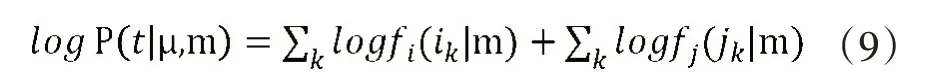
五、實驗結果分析
本文仿真平臺主要基于python 和OpenCV 搭建,用到numpy庫和sympy庫。其中OpenCV用于圖像處理和特征識別,numpy 用于特征數據的處理和存取,sympy 用于處理最大似然分類。整體識別運行過程如圖2 所示。最大似然分類器的運行過程:輸入漢字、字母、數字類別樣本圖片,進行預處理和特征提取;構建最大似然函數,得到字符先驗概率P;分類識別判斷類別結果、檢驗結果。

圖2 車牌字符識別整體運行過程
(一)生成樣本特征數據集
實驗收集的字符樣本來源于網上公開數據庫、網絡搜索引擎搜索結果和虛擬車牌圖片。將所有漢字、數字、字母字符樣本數據集分為訓練集和測試集兩部分。樣本數據集共分為65 類,其中數字0-9 共十個類,字母A-Z 排除O 和I 后共二十四個類,中文漢字共三十一個類(“京”,“津”,“冀”,“晉”,“桂”,“滬”,“陜”,“吉”,“魯”,“貴”,“甘”,“鄂”,“遼”,“贛”,“蒙”,“閩”,“寧”,“黑”,“瓊”,“湘”,“蘇”,“皖”,“青”,“浙”,“豫”,“渝”,“粵”,“云”,“新”,“藏”)。OpenCV將每張輸入字符圖片大小歸一化為40x20,并轉成灰度點陣圖,提取字符特征并將數據處理成.npy的數據。
(二)最大似然分類器
構建最大似然函數,計算各類字符樣本的特征密度函數,從每個備選樣本估計特征向量,用于匹配計算似然性,然后從這些特征中計算出可能性,得到字符各類別的先驗概率P。通過樣本訓練生成參數作為閾值,并進一步細分閾值結果,每個結果定義一個字符。分類識別,將待檢測目標圖像特征輸入進行遍歷計算,最后與閾值比較偏離程度,判斷類別結果。采用一對多分類,65種樣本類別構成分類器,其中漢字分類器31個、數字分類器10個、英文字母分類器24 個。根據具體的識別環境設定一個匹配相似度閾值),定義如果比對偏離值小于匹配不成功,即不是同一字符。可以通過改變閾值來獲得多種候選字符格式,同時閾值變化使系統能夠減少可能因噪聲而導致的錯誤判斷。
(三)分類器的訓練與測試
訓練和測試兩個過程是分開的,按照7:3 的比例將所有正負樣本圖片塊分為訓練集和測試集兩類。分類器存儲各訓練類的均值和方差以及字符各類別的先驗概率。提取車牌標準模板字符特征值,并構建特征向量,待識別車牌字符特征值構造特征向量。先把訓練好的結果以xml 文件的形式存儲,如圖3所示,程序在執行前需要預先加載好xml文件,輸入檢測目標特征計算向量與的偏差,并將其與訓練階段中描述的模型訓練得到的閾值進行比較,在閥值范圍內最終概率最大的被確定為具有最大似然性的結果,判定為某個字符,完成字符識別。針對模型運行所有組件和集合時,可以不斷訓練直到獲得最佳結果。

圖3 最大似然分類的國內車牌字符識別系統
訓練與測試結果如表1 所示,數字和字母的識別率在一定程度上受到了字母與字母、字母與數字之間存在相似字符的情況的影響,不如漢字的識別率高。根據最大似然分類的特點,可加大樣本進行訓練,以提升識別精度。

表1 訓練與測試結果
六.結語
字符識別作為車牌識別過程中最重要的環境,將直接影響到系統的整體效率。利用最大似然分類簡單快速、實施方便的特點,針對國內車牌的一些特點,提出了一種最大似然分類的國內車牌字符識別的方法,以降低字符識別過程的復雜程度,提升識別效率。實驗仿真結果表明,該方法對國內車牌字符可以有效識別,為國內車牌字符識別提供一種參考和借鑒。
猜你喜歡
數學小靈通·3-4年級(2024年2期)2024-05-15 02:02:28
數學小靈通(1-2年級)(2021年4期)2021-06-09 06:25:56
大眾健康(2021年6期)2021-06-08 19:30:06
世界科學技術-中醫藥現代化(2020年2期)2020-07-25 02:05:36
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當代陜西(2019年10期)2019-06-03 10:12:04
中學生數理化·七年級數學人教版(2019年4期)2019-05-20 10:06:32
中學生數理化·七年級數學人教版(2018年6期)2018-06-26 08:36:06
初中生世界·七年級(2017年9期)2017-10-13 22:27:46
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
