基于文本挖掘法的北京市家庭醫生評價體系構建及實證研究
2020-06-15 23:40:00劉芳羽趙靜李澤黃敏婷趙秉元
中國全科醫學 2020年25期
劉芳羽,趙靜*,李澤,黃敏婷,趙秉元
隨著我國社會經濟水平的不斷發展,人們對于生活質量和生命質量的追求日益迫切,對醫療健康服務和衛生保健資源的需求也在不斷增加。家庭醫生作為衛生事業工作規劃的重點,從2009年至今,每年國家層面的衛生工作重點都會提及。2010年起,北京市開始推行家庭醫生簽約服務,通過家庭醫生簽約服務為簽約居民提供相應的醫療衛生服務,開展預防保健活動[1]。現有的關于北京市家庭醫生服務的評價體系與相關研究多以對簽約居民或提供家庭醫生服務的全科醫生及家庭醫生團隊進行問卷調查、訪談、試點研究等方式,通過患者需求評價或家庭醫生工作滿意度來開展[2]。內容分析法是對明顯的傳播內容做客觀而系統的量化并加以描述的一種專門研究方法,其特征為傳播內容的明顯性、客觀性、系統性及量化性[3]。家庭醫生系列政策作為自上而下的公開政策文件,語言表達統一規范,目的、內容明晰可見,能夠作為量化材料進行數據轉化和分析。曾經有學者運用內容分析及相關文本挖掘方法,對政策評價體系進行量化指標建立和實證分析,構建了廣東省陽光用藥制度評估指標體系[4]。政府是公共政策的制定者,對于政策的效果與實施具有自己的角色期望,本研究通過對家庭醫生相關政策文件的梳理,對家庭醫生的現狀與發展制度進行評價與研究,對政策實施效果進行評價,能夠在一定程度上豐富家庭醫生評價角度,彌補家庭醫生評價體系制定方面尚存在的不足。
1 方法與工具
1.1 成立研究小組 于2019年3—4月,經初步分析研討與工作量計算,成立由8人組成的研究小組,小組成員來自北京中醫藥大學管理學院和研究生院,研究專業涵蓋社會醫學與臨床醫學,包含副高級職稱1人、管理專業碩士研究生6人、臨床專業碩士研究生1人。研究工作內容包括:篩選政策文件、查找并深入閱讀文獻、初步篩選指標體系、聯絡專家與調研場所、調研并統計結果。
1.2 ROST內容挖掘系統 ROST內容挖掘系統是由武漢大學信息管理學院沈陽教授設計編碼的內容挖掘軟件。該軟件能夠支持的分析方法包括:分詞、字頻統計、詞頻統計、聚類、分類、情感分析(含簡單和復雜)、共現分析、同被引分析、依存分析、語義網絡、社會網絡、共現矩陣等。ROST是基于內容挖掘的人文社會科學數字化研究平臺,是能夠依據一定范式進行人文社科智能化學術研究的數字化研究平臺[5]。
2 指標體系初選
本研究以《北京市衛生和計劃生育委員會關于進一步加強家庭醫生簽約服務有關工作的通知》(京衛基層〔2018〕9號)文件為指標體系基礎,由調研人員分組閱讀通知內容,對文件中的政策目標進行背對背整理和篩選,在分組篩選后進行會議討論、修改與調整。為增強標準的普適性和統一性,去掉了以“支持”“鼓勵”等非明確要求為態度的條目(如“鼓勵有條件的地區將基本康復納入對殘疾人的個性化簽約服務范圍”)。將文件中的八大類目按照家庭醫生工作維度與版塊進行分類組合,在保持政策原文內涵和意義不變的條件下,重組形成3個一級指標,分別為服務準備與宣傳、服務內容與流程、服務監督與保障,在符合政策原文要求的同時,對家庭醫生服務的各個環節均有涵蓋,并將配套體制的建設和對政策的宣傳工作也囊括進來。體系的二級指標包含7個維度,均由一級指標細化或拆分而來。在保持政策原意的條件下,提取三級指標,吸收政策原有的文本結構,由二級指標將所有三級指標劃分為不同子組,以期在組間排序和組內排序的過程中能夠更加便利和迅速。依據數據的可獲得性、指標的代表性、指標的客觀性(即無須自報,由第三方從外部獲得)、宏觀整體性、可測量性或可計算性等原則進行核查后[3],篩選出的指標體系見表1。
3 確定指標體系權重
根據初選指標情況,采用文本挖掘的方法與工具對政策文件進行內容分析,通過文本挖掘確定指標體系的權重。
3.1 獲取文本 由調查員以家庭醫生為關鍵詞,收集與其相關的政策文件。獲取途徑主要是國家衛生健康委官網、北京市衛生健康委官網,以及國家、北京市衛生健康委內部參閱材料、工作安排及總結報告。由調查員以“家庭醫生”“全科醫生”為關鍵詞,在國家衛生健康委、北京市衛生健康委等各級政府網站上搜索相關政策文件,政策文件及其來源具有權威性及可靠性。通過逐篇閱讀后排除與家庭醫生主題相關度過低、對構建指標體系參考性過小、數據或材料具有特殊性的材料(如新聞報道與宣傳材料)。本次指標體系建立共納入政策52件,其中國家級政策40件、市級政策12件。將經過篩選的52件政策文件材料整合在同一文件內,并轉化為TXT格式,同時將初選指標體系也一并轉化為 TXT 格式的純文本文件,方便運用ROST軟件進行文本挖掘處理。
3.2 挖掘法處理文本 使用武漢大學信息管理學院的內容分析工具ROST Content Mining 內容挖掘系統5.8.0.603版,將52件政策文件匯總成的文本集合及指標體系進行分詞處理,得到分詞結果。詞頻(TF)表示該詞條在所查文檔中出現的頻率,通過詞頻統計能夠看出每個分詞在文檔中的重要程度。
3.3 計算結果 根據分詞形成的最終結果進行計算處理,得出每個分詞的詞頻及詞云。
3.3.1 輸出詞頻 通過ROST軟件進行分詞處理,導出詞頻排在前1 000位的詞表。由輸出結果可見,有9個詞的詞頻超過1 000次,分別為“衛生”“醫療”“服務”“健康”“機構”“管理”“醫生”“醫院”“加強”。其中,“衛生”“醫療”“服務”的詞頻分別為3 459、2 721、2 677次,位列分詞詞頻的前3位。位于出現分詞詞頻1 000位的有“體質”“實時”“戒煙”“視力”“多樣化”等詞語,詞頻均為16次。
3.3.2 輸出可視化詞云 通過ROST軟件形成可視化詞云(見圖1),詞頻越多的詞語占據畫面越大,通過詞云分布可以比較直觀地看出在總的文本文件中每個分詞的重要性。
3.4 整理指標內容
3.4.1 匯總指標關鍵詞詞頻 根據指標內容將三級指標分解為若干關鍵詞,統計指標下的關鍵詞詞頻,計為指標詞頻數。如將“具有統一的服務協議文本基本內容和格式”條目提取出“統一”“協議”“文本”“內容”“格式”,將各關鍵詞的詞頻加和,得到此條目的詞頻數為148次。對于因表述殊難以提取關鍵詞的條目,經專家討論,采取關鍵詞同義替換或提取核心概念的方式進行關鍵詞檢索,通過詞頻統計,合并頻數較低但經分析不可缺少的條目,如將“及時建立并完善簽約居民健康檔案個人基本信息”和“建立簽約居民的個人資料及隱私保密制度”合并為“及時建立并完善簽約居民健康檔案和信息保密制度”。

表1 北京市家庭醫生評價體系指標初選表Table 1 Primary selection of indicators for Beijing Family Doctor Evaluation System
3.4.2 選擇專家并組織專家咨詢 專家包括北京市社區衛生服務中心從事家庭醫生管理工作3年以上的行政人員;家庭醫生團隊長或家庭醫生工作室負責人;具有中級以上職稱且工作超過5年的一線家庭醫生;最終共選取15名愿意支持并配合本次研究的專家,專家單位涵蓋衛生行政部門、醫療機構與科研院所。通過專家咨詢與小組討論,將可能帶有歧義或能夠合并的條目進行修改整理,調整指標的語序和句式。最終通過詞頻統計,去掉詞頻低于15次的指標,得到三級指標詞頻統計表,詞頻總數為9 905次(見表2)。
3.5 計算指標權重 以詞頻為基礎,對評價體系的三級指標進行歸一化處理,運用歸一化法中的(0,1)法,將各條目詞頻數轉化為1以下的小數,計算出各條目的權重值(見表2)。
4 設置評分辦法
本次指標體系的評分分為定性與定量兩種,對于定量答案采用直接計數制,如居民的家庭醫生簽約服務知曉率。對于定性答案采用三級評分制,即“完全符合”“一般符合”“不符合”,如條目“具有統一的服務協議文本基本內容和格式”,如果既有統一的協議內容又有格式則評為“完全符合”,如果兩個都沒有,則為“不符合”,如果只有統一的內容或統一的格式,則評為“一般符合”。“完全符合”“一般符合”“不符合”3個等級折合分數分別為5、3、1分,定量答案直接按照指標權重計算,如有必要則成倍數轉化,如“居民家庭醫生簽約服務知曉率”范圍為0~100%,則在計算時將原始數據乘5,即若知曉率為80%,則按4分計算,再進行權重處理。將所有條目分數相加得到最終總評分,總評分滿分為5分,分數越高,表明該地的家庭醫生服務建設越完善。
5 實證分析

圖1 家庭醫生政策文件可視化詞云Figure 1 Visualized word clouds in family doctor policy files
為驗證評價體系的實用性及科學性,將指標體系運用到北京市4家社區衛生服務中心進行家庭醫生服務評價,將評價指標體系制作成調研問卷,對選取的4家社區衛生服務中心的負責人或家庭醫生工作負責人進行一對一訪問,得到自評數據(見表3),4個試點地區的家庭醫生服務均在4分以上,可以看出北京市家庭醫生服務的開展已經取得了一些成績,尤其是在公共衛生服務和家庭醫生團隊建設上,4個測試點地區工作都已經比較成熟。同時,通過各條目的得分情況也能夠看出北京市家庭醫生服務尚存的不足,4個測試點得分最低的條目均為“搭建在線管理與考核平臺”,可見在家庭醫生團隊的在線管理與信息化方面,北京市仍應進一步開展相關工作。通過此次實證分析也能夠看出評價體系能夠對北京市家庭醫生服務建設工作進行評價,同時能夠反映出工作現狀及目前存在的一些問題。
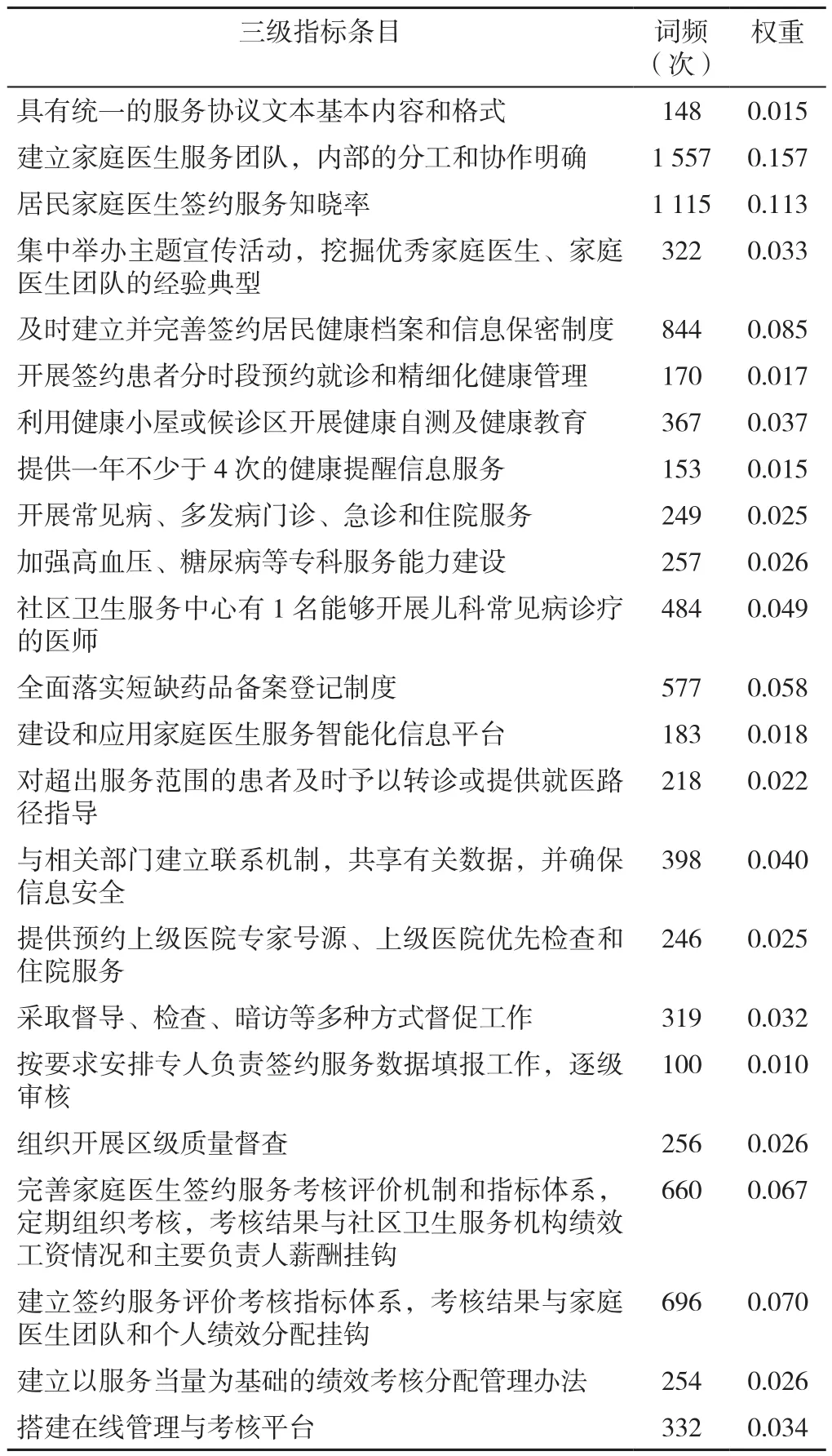
表2 北京市家庭醫生評價體系三級指標詞頻及權重Table 2 Term frequency and weight of three-level indicators in Beijing Family Doctor Evaluation System

表3 北京市4家社區衛生服務中心家庭醫生服務評價得分情況(分)Table 3 Evaluation scores of family doctor services in four community health centres of Beijing
6 結論
通過將政策文件原文內容進行量化,根據政策目標與內容提取指標體系,通過運用文本挖掘法計算詞頻,賦予指標相應權重,能夠減少傳統德爾菲方式下人為因素的主觀性和判斷失誤,能夠在建立過程中更加貼近政策本來的目標與規劃。同時,文本挖掘法借助少量人力和一定的分詞工具,可以提高研究效率,節省研究成本。由于方法較新,可參考文獻較少,研究在指標分詞處理及詞頻統計的精細化上還存在可商榷之處,在實證分析上也只進行了初步探究,還需進一步做深入調研來驗證指標體系的可行性。家庭醫生評價隨著家庭醫生工作的不斷推進還在進一步發展,通過文本挖掘建立評價體系能夠在一定程度上拓展指標體系篩選的方法,未來可以對此途徑進行更加深入的探索和研究。
作者貢獻:劉芳羽、趙靜負責論文選題與研究設計;李澤、黃敏婷負責前期文獻準備與信息收集;趙秉元負責材料整理;全文由劉芳羽執筆,趙靜進行質量控制與審校。
本文無利益沖突。
猜你喜歡
石油瀝青(2021年4期)2021-10-14 08:50:44
制造技術與機床(2019年10期)2019-10-26 02:48:08
今日農業(2019年12期)2019-08-15 00:56:32
今日農業(2019年10期)2019-01-04 04:28:15
今日農業(2019年16期)2019-01-03 11:39:20
電子制作(2018年18期)2018-11-14 01:48:06
商周刊(2017年9期)2017-08-22 02:57:56
小學教學參考(2015年20期)2016-01-15 08:44:38
中國教育技術裝備(2015年19期)2015-03-01 02:43:07
語文知識(2014年1期)2014-02-28 21:59:13
