基于機器學習的車牌識別技術研究
2020-06-16 00:24:24李良榮
計算機技術與發展 2020年6期
陳 政,李良榮,李 震,顧 平
(貴州大學 大數據與信息工程學院,貴州 貴陽 550025)
0 引 言
據《2018年交通運輸行業發展統計公報》顯示,全國公路總里程達到484.65萬公里,其中高速公路里程已經達到14.26萬公里,全國公路隧道為17 738處、1 723.61萬米,其中特長隧道1 058處,470.66萬米,長隧道4 315處、742.18萬米[1]。目前,雖然隧道照明燈的配置僅限于隧道內及其引導路段,但由于國內隧道的基數較大,普遍采用的是常明燈模式,在無車通行時段浪費了大量的能源,同時也給高速公路運營管理部門帶來了沉重的經濟負擔。文中依托國家基金課題“高速公路隧道節能照明關鍵技術研究”,獲取隧道內的行車視頻來對車牌信息展開技術研究,獲取信息是實施隧道“車近燈亮、車過燈滅”節能照明控制、隧道運行信息化管理的重要信息。然而,隧道中無自然光,不僅行車的速度快,而且車型多樣、行駛無規律、車牌位置不同、車燈照明不一致;車道多,可能出現并行、緊隨、超車變道、超速行駛等情況,導致了隧道行車車牌信息獲取算法面臨嚴峻挑戰。因此,針對隧道內高速行駛車輛的車牌識別問題進行研究。
一個完整的車牌識別系統大致由車牌圖像獲取、圖像預處理、車牌定位、字符分割和字符識別這五部分組成[2]。主要流程如圖1所示。
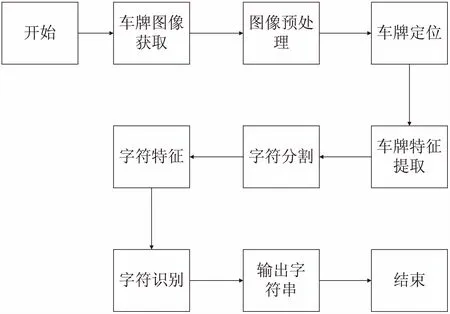
圖1 車牌識別系統主要流程
1 車牌圖像的獲取
針對行車目標檢測中的圖像背景獲取,文中采用彩色視頻背景選擇更新法:即分別對前后兩幀的相應像素的紅色、綠色和藍色分量相減以獲得三個差值。當三個差的平均值小于檢測閾值T,就將其視為背景區域,大于則視為目標區域[3]。其中平均值為:
average|Mj+1(x,y,RGB)-Mj(x,y,RGB)|=
(1)
再用式(2)可得到完整的目標彩色背景圖像:
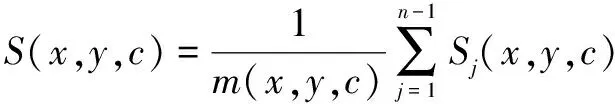
(2)
其中,Mi(i=1,2,…,n)表示圖像序列,Sj(j=1,2,…,n-1)表示背景序列,(x,y)為像素坐標,c為色彩坐標,即c=(R,G,B),m(x,y,c)為(x,y)處Sj(x,y,c)值不為0的次數,m(x,y,c)>1。
2 車牌定位
傳統的車牌定位方法有很多,如基于邊緣特征的定位算法、基于模板匹配的定位算法、基于顏色特征的定位算法等[4]。這些方法的優缺點不同,主要通過運行速度和準確性兩個方面表現。一般來說這兩個方面很難同時滿足,計算量小的算法精度普遍較低,而高精度算法的計算量自然就很大。
文中在車牌定位中選用邊緣檢測與形態學相結合的算法,因為邊緣檢測的定位速度快,符合現代多車輛需要進行實時處理的情況。而車牌污染等因素會對其定位產生影響,且在隧道交通中由車燈照明引起的復雜環境背景會讓邊緣檢測定位到的車牌出現較大的誤差,所以選擇將邊緣檢測與形態學處理結合起來確定候選車牌的輪廓,利用形態腐蝕和膨脹來消除污染和模糊區域來克服這些影響[5]。
2.1 圖像預處理
圖像預處理的步驟中包含了許多算法,其目的是使后續算法具有更快的處理速度或得到更符合所需信息的圖像,因此圖像預處理是影響整個系統性能的重要因素之一。在獲取目標圖像的過程中,除車牌本身之外,還夾帶了一些其他的干擾因素,如復雜的背景信息、環境因素等。首先對獲取的車牌圖像進行灰度化處理以減少數據處理量[6],其灰度化值:
Y=x×R+y×G+z×B
(3)
其中,x、y、z是灰度化處理系數,取值為x=2.97、y=0.581、z=0.124時灰度化效果最好,處理效果如圖2所示。

圖2 灰度化效果
考慮到干擾因素所帶來的噪聲影響,需要對灰度化后的圖像進行濾波以消除噪聲,因為中值濾波可以較好地處理脈沖噪聲、椒鹽噪聲,且邊緣細節保存良好[7]。所以文中采用中值濾波的方法對灰度化后的圖像進行濾波,效果如圖3所示。

圖3 中值濾波效果
2.2 邊緣檢測
圖像邊緣是圖像的基本特征,可以顯示圖像灰度信息的變化情況,反映圖像局部特征的不連續性[8]。常用的邊緣檢測算子有:Sobel算子、Roberts算子、Canny算子、Laplacian算子。因為Roberts算子簡單直觀,且邊緣定位準確,所以首選其進行邊緣檢測,效果如圖4所示。

圖4 Roberts算子效果
2.3 形態學處理
形態學的基本運算有膨脹、腐蝕、開運算和閉運算。其處理方法是利用一個稱為元素結構的“探針”來收集圖像信息,在邊緣檢測之后采用形態學處理將圖像內的字符區域連成一片,消除圖像中存在的干擾邊緣點,以提高定位車牌的準確率。圖5為對車牌圖像進行腐蝕后的效果圖,形態學基本運算:
膨脹:
A⊕B={x,y|(B)xy∩A≠?}
(4)
腐蝕:
AΘB={x,y|(B)xy?A}
(5)
開運算:
A°B=(A?B)⊕B
(6)
閉運算:
A?B=(A⊕B)?B
(7)
其中,A為待處理的圖像,B為結構元素集合,x,y表示平移元素。

圖5 腐蝕后的車牌圖像
2.4 平滑處理
經邊緣檢測和形態學處理之后,車牌圖像已大致可以顯示出車牌區域的輪廓,但還是會受到一些噪聲和其他因素的影響,因此車牌區域還不能完全被計算提取得到[9]。文中采用imclose()函數對圖像進行平滑處理,去除一些孤立而無意義的噪點,以此來消除噪聲帶來的影響。
2.5 移除小對象
在圖像進行平滑處理之后會有許多閉合區域,比如一些噪點和車標,這些不屬于車牌部分的要盡量刪除。文中采用bwareaopen()函數,從圖像中刪除小于設定面積值的部分,最后確定車牌圖像的位置,處理效果如圖6所示。
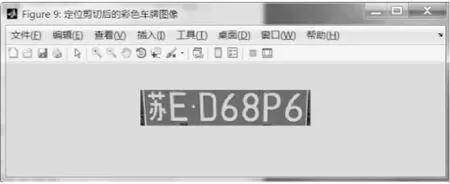
圖6 定位剪切后的彩色車牌圖像
3 車牌字符識別
中國車牌的第一個字符是中文省名的縮寫,第二個字符是英文字母,其他五個字符是數字或英文字母,英文字母不超過兩個。為了準確識別到車牌上的漢字、英文字母和數字,識別的過程中每個字符必須分段。所以車牌字符的分割結果是字符識別的前提和準備,而字符識別通過提取字符特征來識別字符分割,因此字符識別直接決定了車牌識別系統性能的好壞。傳統的字符識別方法有模板匹配法[10]:首先,對樣本進行分類并建立樣本數據庫,然后將識別出的字符進行二值化處理,并通過字符數據庫中的模板大小進行標準化,與所有模板匹配并計算它們的相似度,最后選擇最佳匹配作為結果。但計算量大是一個明顯的缺點,并且對傾斜或環境干擾的圖像很敏感。所以文中采用了基于SVM(支持向量機)的字符識別來完成車牌識別系統最后的過程[11]。
3.1 字符分割
車牌的字符分割將車牌區域劃分為單個字符區域,每個字符區域必須是包含單個字符的最小矩形區域,分割越精確識別效果越好。傳統的垂直投影劃分字符的分割方法相對簡單準確,但分割效果容易受到噪聲和平板傾斜度的影響。文中對定位后的字符圖像首先進行灰度化、二值化、濾波、形態學處理的預處理。因為車牌字符之間的間距較大,所以在分割時不會出現字符粘連等情況,然后去尋找帶有連續文本的模塊,如果長度大于設定閾值I,則認為該塊具有兩個字符需要進行分割,小于則不需要。這種方法可以較好地解決在分割的過程中出現字符斷節等問題,字符分割效果如圖7所示。
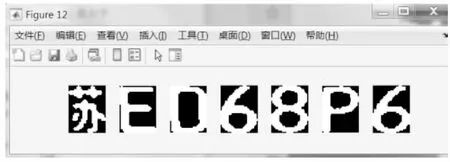
圖7 分割后的字符圖塊
3.2 字符歸一化
字符歸一化可在字符識別中消除字符大小的影響,字符像素由字符在水平和垂直方向上的分布來進行大小歸一,其算法步驟為[12]:
(1)設GI為水平方向的質心,GJ為垂直方向的質心:
(8)
其中,s(i,j)=1表示目標像素,s(i,j)=0表示背景像素,E、F、G、H分別代表字符的上下左右邊界。
(2)設σI為水平方向的散度,σJ為垂直方向的散度:
(11)
計算出質心和散度之后,對進行預處理之后的字符圖塊統一進行40*32的縮放處理,方便后續的字符特征提取。
3.3 字符特征提取
無論是字符樣本還是待識別的字符,都需要經過特征提取后才能夠輸入到相應的識別算法中。文中采用基于HOG的特征提取,將提取到的字符黑白像素的特征參數用作SVM的分類標準,HOG特征關注目標形狀信息分布,在抗目標表觀信息變化方面具有明顯的優勢,可由字符的形狀信息來更好地識別字符。該方法首先將圖像分成較小的連通區域,在此區域上采集各像素點邊緣方向上的直方圖并統計它們的方向特性,最后將這些直方圖組成特征描述器傳送到SVM算法識別模塊。文中將HOG參數Cell的大小設置為[4 4],既可滿足空間信息編碼的大小,又限制了HOG特征向量的維數,從而加快訓練[13]。
3.4 字符分類器的構建
中國車牌的字符種類一共分四類,第一類是車牌最左邊的漢字,第二類是緊跟著首部漢字的字母,第三類是車牌中圓點右側的字母和數字的組合,第四類則是一些專用車牌的字符。字符樣本的種類繁多,其中漢字包含50個、英文字符24個、阿拉伯數字10個,一共是84個種類,如果構建一個多分類SVM分類器,則84個種類就構成15 312個分類器,這個計算量是非常大的。因此,文中采用一對多分類器將樣本的第M類和樣本中其他M-1類分開來構成二分類器,以降低計算量,減少執行訓練樣本和識別的時間。
4 SVM算法和核函數的優化
在SVM識別字符的過程中,核參數的選取對最后識別的性能至關重要,文中選用粒子群算法來對核參數進行優化。
4.1 SVM算法
支持向量機(SVM)是一種在高維特征空間中也可以進行良好分離超平面計算的有效方法,使用線性超平面來創建具有最大余量的分類器,該算法旨在通過在高維特征空間中使用核函數來找到支持向量及相應的系數,以構建最佳分離面[14]。首先可設數據集L(x1,y1),(x2,y2),…,(xd,yd),其中xi是具有關聯類標簽yi的訓練元組集合。每個yi都可以取兩個值中的一個(+1或-1)。在對數據元組進行分類時,最大邊際超平面將比較小邊距更準確,分離超平面可以寫成:
f(x)=w·x+b
(12)
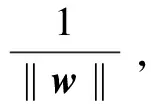
yif(xi)=yi(w·x+b)≥1,i=1,2,…,M
(13)
引入松弛變量ξi來測量邊距與位于邊距另一邊的向量xi之間的距離,然后可以通過公式獲得分離數據的最佳超平面:
(14)
其中,ξi≥0,i=1,2,…,M,C為懲罰因子。通過引入拉格朗日系數i,可將上述優化問題轉化為雙二次優化問題,即
(15)
因此,線性決策函數是通過求解產生的雙優化問題,定義為:
(16)
4.2 核函數的選取
SVM算法核函數提高了模型對非線性樣本的分類能力。選擇不同核函數來代替原始分類方程的內積的過程是將非線性問題轉化為線性問題的過程。它們都影響著系統的分類能力和泛化能力,因此選擇合適的核函數和懲罰因子是SVM算法的核心。對于車牌樣本的非線性不可分割的情況,常用的核函數如下:
(1)多項式核函數。
k(x,xi)=[(x?xi)+1]d
(17)
(2)RBF核函數。
(18)
(3)Sigmod核函數。
k(x,xi)=tanh(k(x?y)+c)
(19)
線性核函數主要是用于線性可分的情況,對于線性可分問題分類效果較好,但是對于車牌樣本而言,其類別和特征向量是非線性的,而且樣本需要映射到高維空間。為此選擇RBF核作為支持向量機的核函數。
4.3 PSO算法原理
PSO算法是一種基于種群的隨機優化的方法,受鳥類群體活動的規律性啟發,進而利用群體智能建立一個簡化的模型[15]。在PSO的描述中,種群是由問題超空間中移動一定數量的粒子構成,通過迭代尋找全局最優解。每個粒子都有一個位置矢量和一個速度矢量來指導它的運動。PSO算法的原理在迭代過程中主要通過以下方式來實現[16]:
(1)在問題空間中對具有隨機位置和速度的粒子群進行初始化;
(2)評估每個粒子的適應度函數;
(3)將每個粒子的適應值與其先前的最佳適應值pbesti進行比較,如果當前值優于pbesti,則將此值設置為pbesti,并將粒子的當前位置xi設置為pi[17-18];
(4)識別具有最佳適應值gbest的鄰域中的粒子,將粒子的位置設置為pg;
(5)每一代粒子根據以下公式更新自己的速度和位置:
vi(k)=ω·vi(k-1)+c1r1[pi-xi(k-1)]+
c2r2[pg-xi(k-1)]
(20)
xi(k)=xi(k-1)+vi(k)
(21)
(6)重復步驟(2)至(5)直到求得粒子的最優函數適應值后停止更新,得到的粒子位置pg即是最佳的解決方案。
上式中i=1,2,…,M,ω是非負常數,稱為慣性權重,隨迭代而線性變小,vi表示每個粒子的飛行速度,c1,c2表示學習因子,r1,r2是介于[0,1]之間的隨機數。在更新過程中,每個粒子通過上述兩個極值連續更新自身,從而產生新一代的群體,將粒子的位置、速度限制在允許的條件之下。
4.4 PSO對SVM參數的優化


表1 PSO參數設置
在多類SVM分類器中,懲罰因子C和內核寬度γ始終為正值。所以在PSO算法中選擇合適的邊緣條件x和速度v非常重要,一般C處于[0.1,100]之間,γ處于[0.1,1 000]之間,為了使粒子在邊界內可以充分搜索到最佳位置,文中對粒子的速度進行了以下約束:
Vc max=k1Cmax
Vγ max=k2γmax
k1=k2=0.5
通過PSO算法對多類SVM分類器的優化設置,經實驗選出最優懲罰因子C和核參數σ,車牌分類器、漢字字符分類器、數字和字母分類器C的取值分別為2、10和20,σ的取值分別為0.8、0.6和0.3。
5 實驗驗證與分析
文中的實驗樣本采取實拍的500幅車牌圖像,對圖像進行預處理之后,選取300張用于SVM樣本訓練,100張用于樣本測試。
實驗環境:英特爾酷睿i74GHz處理器;8GB RAM;Windows 7操作系統;用Matlab實現。分別對參數優化前和優化后的樣本進行訓練與識別,并統計最后得到的訓練時間,字符識別的速度以及識別的準確率,結果如表2所示。
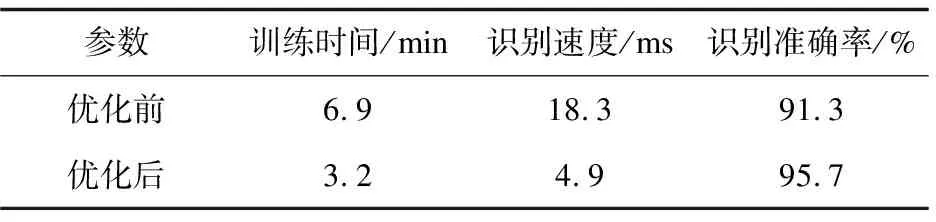
表2 實驗數據對比
從表中的對比可知,參數優化后的SVM字符識別過程中在各個方面上都有顯著的提高,最終字符識別的結果如圖8所示。
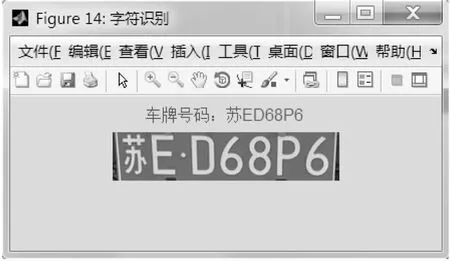
圖8 字符識別的效果
6 結束語
研究了基于機器學習SVM算法的車牌識別系統,項目組通過對視頻中高速行車的車牌檢測實驗,改進了傳統的車牌定位方法與字符分割方法,采用PSO算法對SVM中懲罰因子C與內核寬度γ進行優化,并利用MATLAB對算法進行仿真,通過實驗分析確定C和γ的取值,最后利用車牌識別的效果比較來說明參數優化后的SVM算法,能夠更有效地進行車牌分類、字符識別,可以用于實施“高速公路隧道照明智能化控制方案”,以提高隧道運行的能源利用率,降低運行成本,具有一定的現實意義。
