一種適用于物聯網的在線GP-ELM算法
2020-06-19 08:50:04沈蘇彬
計算機工程 2020年6期
關鍵詞:實驗
張 杰,沈蘇彬
(南京郵電大學 計算機學院,南京 210046)
0 概述
自從極限學習機(Extreme Learning Machine,ELM)被提出以來,由于其具有泛化能力強、訓練時間短的優點,受到了許多學者的關注。文獻[1]證明了ELM的一致逼近性并將ELM直接應用于回歸與多分類問題[2]。為處理非平衡數據的學習問題,文獻[3]通過引入類別權值,提出了加權極限學習機(W-ELM)。文獻[4]提出的在線序列極限學習機(OS-ELM),將ELM延伸至在線學習問題,拓寬其實際應用范圍。目前,ELM在語音識別[5]、電力系統[6]等領域已得到初步應用。
作為一種新興技術,ELM在回歸和分類應用中表現出良好的性能,具有較高的運行速度和較好的通用性,但為探索ELM在現實問題中的普遍適用性,需要確定用于解決特定任務的最合適的網絡架構。ELM與批量學習方案[7]以及在線順序學習方案[8]是以固定網絡規模開發的,搜索這種固定網絡大小的常用方法是通過反復實驗。該方法簡單明了,但計算成本高,不能保證所選擇的網絡規模接近最優。文獻[9]提出增量ELM(I-ELM)算法,其中隱藏節點被逐一隨機添加,并且當添加新的隱藏節點時,現有隱藏節點的輸出權重被凍結,證明了I-ELM的通用逼近能力。凸面I-ELM(CI-ELM)[10]采用另一種源于巴倫凸優化概念的增量方法。當添加新的隱藏節點時,這種方法允許適當地調整現有隱藏節點的輸出權重。在這種情況下,CI-ELM可以實現比I-ELM更快的收斂速度,同時保留I-ELM的簡單性。在I-ELM和CI-ELM的學習過程中,一些新添加的隱藏節點僅在網絡的最終輸出中起很小的作用,因此可能增加網絡復雜性。為避免上述問題并獲得更緊湊的網絡架構,文獻[11]提出增強型I-ELM(EI-ELM)算法。在EI-ELM的每個學習步驟中,隨機生成若干隱藏節點,并且僅將導致最大殘余誤差減少的節點添加到現有網絡。此外,EI-ELM還將I-ELM擴展到通用SLFN。文獻[12]在SAP-ELM 算法的基礎上,結合L2正則化因子和奇異值分解 (SVD),提出一種改進 的SAP-ELM (ImSAP-ELM)算法以提高預測精度和數值穩定性。文獻[13]對靈敏度進行修正,提出更符合實際需求的神經網絡剪枝算法IS-ELM。
文獻[14]提供一種誤差最小化ELM(EM-ELM)方法。該方法允許逐個或逐組添加隨機隱藏節點(具有不同的大小)。此外,EM-ELM在網絡增長期間遞增地更新輸出權重,降低了計算復雜度。然而,在所有上述建設性ELM的實現中,隱藏節點的數量隨著學習進度和最終數量單調增加,隱藏節點的數量相當于學習步驟。如果需要進行許多迭代步驟,最終將獲得大量隱藏節點,而一些隱藏節點可能在網絡輸出中起很小的作用。文獻[15]基于和聲搜索算法優化極限學習機的方法,結合了和聲搜索算法和極限學習機兩者的優勢,利用和聲搜索算法調整極限學習機的輸入權值和隱含層閾值,避免了隨機設定無效節點而導致預測效果不穩定、泛化能力較差等問題。文獻[16]提出了一種新的隱含層節點的選擇算法SHN-ELM。通過對隱含層節點的選擇,提高了ELM 算法的穩定性和分類準確率。文獻[17]提出了以粒子群優化算法搜索ELM隱藏層最佳神經元個數,用極限學習機模型的測試準確率作為粒子群優化算法適應值。文獻[18]提出了一種P-ELM算法,通過統計方法去除不相關或相關性較低的隱藏節點,系統地確定學習過程中隱藏節點的數量,但是這樣的方法卻無法自動地完成。文獻[19]設計了一種基于 EFAST 的隱藏層節點剪枝算法(FOS-ELM),利用傅里葉敏感度測試方法對 OS-ELM 的隱藏節點進行分析,能適用于剪枝后的網絡參數調整算法。文獻[20]針對隱藏節點數量影響ELM泛化性能的問題,提出一種SRM-ELM算法。SRM-ELM在結構風險最小化原則下,建立隱藏節點數與泛化能力的關系函數,利用PSO簡單高效的全局搜索能力,優化ELM的隱藏節點數,避免了傳統方法反復進行調節實驗的繁瑣。但是上述算法耗時比較長,不適用于物聯網的特性。為此,本文提出一種適合物聯網的在線GP-ELM算法。該算法能夠在添加多個節點的同時進行剪枝、刪減節點,以提高ELM的準確性。
1 極限學習機及其相關理論
1.1 極限學習機
在ELM中,只需要預先確定隱藏神經元的數量,而隱藏神經元的參數(如RBF節點的中心和影響因子或附加節點的偏差和輸入權重)是隨機分配的。因此,給出如下ELM預測公式:
(1)
其中,β=[β1,β2,…,βk]是連接隱藏層和輸出層的輸出權重的向量,H(X)=[H1(X),H2(X),…,Hk(X)]是隱藏層相對于樣本X的輸出。 根據Bartlett理論,對于訓練誤差較小的神經網絡,權重范數越小,網絡的泛化性能越可能更好,因此,將訓練誤差與輸出權重的范數最小化:
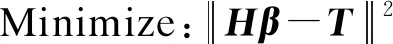
(2)
其中,H是隱藏層的輸出矩陣:
(3)
并且:
(4)
將最小范數最小二乘法用于經典ELM的原始實現中,即:
β=H?T
(5)
其中,H?是H的Moore-Penrose廣義逆,即偽逆。
如果使用標準優化方法,則基于約束優化的ELM可以寫成:
受限于:
ξ=T-Hβ
(6)
根據KKT條件,可以通過以下雙重優化來解決:
(7)
其中,αi∈α=[α1,α2,…,αN]對應于訓練樣本的拉格朗日乘數。KKT最佳條件如下:
(8)
(9)
(10)
根據訓練集的大小可以實現不同的解決方案:
1)訓練樣本數量很大的情況
如果訓練數據N的數量非常大,如比特征空間L的維數大得多,即N> >L,則以下解決方案是優選的。
(11)
在這種情況下,ELM的輸出函數為:
(12)
2)訓練樣本數量少的情況
在這種情況下,通過將式(8)、式(9)代入式(10),可以等效地將式(11)、式(12)寫為:
(13)
由式(4)~式(8),有:
(14)
ELM的輸出方程為:
(15)
1.2 EM-ELM算法
EM-ELM是一種簡單而有效的算法,可以逐個或逐組地隨機添加隱藏節點。在網絡增長期間,基于誤差最小化方法遞增地更新輸出權重。
(16)
可以等效地以矩陣形式表示:
Hβ=T
(17)
其中:
(18)
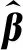
(19)
其中,H?是H的Moore-Penrose廣義逆,即偽逆。
(20)
(21)
(22)
其中:
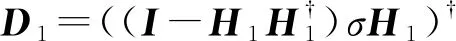
(23)
然后計算β2:
(24)
同樣,輸出權重可以逐步更新為:
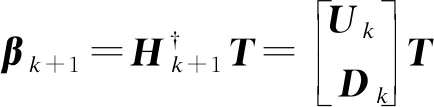
(25)
1.3 在線序列學習機
訓練數據可以在實際應用中逐塊或逐個(塊的特殊情況)到達。在線序列學習機(OS-ELM)算法針對在線學習案例,并在短時間內不斷更新輸出權重。
當新的采樣數據到來時,ELM的數學模型應該被修改為:
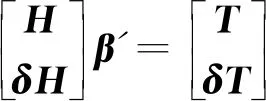
(26)
其中,δH和δT是新生成的隱藏層輸出矩陣,使用當前學習參數和由新獲得的觀測值組成的輸出矩陣,β′是修改后的輸出權重矩陣。OS-ELM算法分為兩個階段,即初始化階段和順序階段。初始化階段與普通ELM算法相同,而輸出權重矩陣β將通過迭代方式在順序階段中更新。
OS-ELM算法步驟如下:

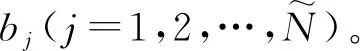
2)計算初始隱藏層輸出矩陣H0:
4)設置k= 0,其中k是表示呈現給網絡的數據塊數量的索引。
步驟2(序列階段) 給出第(k+ 1)個新觀察結果:
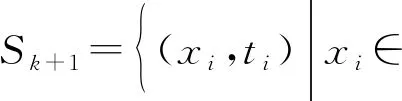
其中,nk表示k塊中新獲得的觀察的數量。顯然,可以得到N0=n0。
1)計算部分隱藏層輸出矩陣hk+1:
hk+1=
2)計算輸出權重矩陣βk+1:
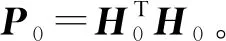
設置k=k+ 1,然后返回序列學習階段。
2 GP-ELM算法
2.1 算法描述
最早的ELM應用是預先設定好隱藏層節點的個數,存在準確率不穩定等不足。該類算法主要有2種:1)逐漸增加一個或者多個節點,這種算法將節點添加之后,隱藏層的參數即固定,這樣一些不必要的節點或者貢獻很小的節點會增加計算量;2)先設定一個較大的值作為隱藏層節點的個數,根據第一次訓練節點的權值刪減一些節點,然后再訓練,這種算法必定要設置一個非常大的值,這對不同的數據的適應性就非常低,因為一些數據只需要較少的節點,而有些則需要較多的節點。
本文算法是在EM-ELM[12]算法模型的基礎上,固定每輪增加節點的個數,增加了每輪對整體節點進行剪枝的過程,能夠保證節點的質量。本文算法結合上文兩類算法的優點,既能動態地根據數據來生成隱藏節點,又能剔除那些沒有起到作用的節點,先生成固定數值節點,在這些節點加入之后進行一次訓練,根據權值矩陣β來計算每個節點的貢獻值:
1)如果β是一維的,則直接將這一列換算成比例。
2)如果β是n維的,則先將每一列換算成比例,然后將每一行取平均值。
根據計算出的貢獻值來選擇刪去哪些節點,然后返回到增加節點的步驟,如此循環,直到達到一定的標準停止循環。
由于物聯網下的數據是不斷產生的,因此在線訓練數據更新參數又是非常有必要的,所以本文算法在確定隱藏層結構后,會根據新來的數據更新參數。
2.2 算法步驟
本文算法步驟如下:
步驟1初始化階段:
2)計算隱藏層的輸出矩陣:
3)計算最優的輸出權重:
β=H?T
其中,H?為H的廣義逆,T為目標矩陣。于是,得到初始函數Ψ1以及相關的誤差E1:
步驟2隱藏節點上升并且刪減(最大隱藏節點數Lmax,需求的錯誤率ε):
1)生成M個隱藏節點參數并將其加入到當前模型,然后根據迭代式計算:
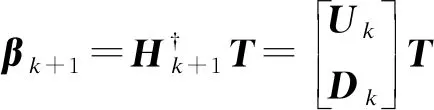
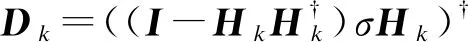
2)計算出輸出權重,生成模型Ψn(x)=βnGn(x),計算其誤差En,如果Ln
3)根據計算出的β計算每個節點的貢獻值:
(1)如果β是一維的,則直接將這一列換算成比例。
(2)如果β是n維的,則先將每一列換算成比例,然后將每一行取平均值。
4)刪除那些幾乎不起作用的節點(兩種方案):
(1)節點貢獻值低于某一個值會被刪除。
(2)對貢獻值進行排序,貢獻值最小的m個節點會被刪除。
5)轉到步驟1。
步驟3在線學習階段:
設置r= 0,其中k是表示呈現給網絡的數據塊的數量的索引,給出第(r+ 1)個新觀察結果:
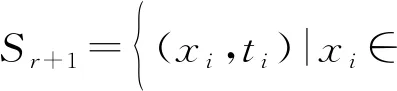
其中,nr表示r塊中新獲得的觀察的數量。顯然,可以得到N0=n0。
1)計算部分隱藏層輸出矩陣hr+1:
2)計算輸出權重矩陣βk+1:
3)如果還有數據進入,則設置r=r+1,然后返回序列學習階段,否則程序結束。
2.3 收斂性證明
定理1給定一個SLFN,令H1作為有L0個隱藏節點的SLFN隱藏層輸出矩陣,如果L1-L0個節點被加入當前模型,新的隱藏層輸出矩陣為H2,于是有:
證明:根據前文的推理,增加σL0=L1-L0可以得到H2=[H1σH1],其中:
σH1=
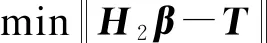
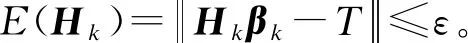
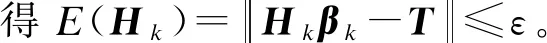
由上面的證明可以看出,本文算法可以使得誤差值達到指定小的值,即算法是收斂的,能夠迭代終止。
3 實驗與結果分析
3.1 實驗環境
本文實驗的實驗平臺為 Intel i7-6700 3.4 GHz,16 GB 內存和 1 TB硬盤的PC,實驗在 Windows 10 系統上用 Matlab 2016(b)實現。本文實驗采用了實際應用的公開的數據集Image Segment(圖片分割)、Satellite Image(衛星圖片分類)和DNA,如表1所示。
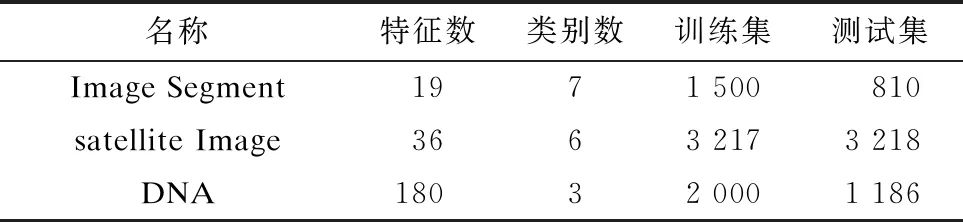
表1 實驗所用數據集
3.2 實驗結果對比
本文實驗將提出的算法GP-ELM與ELM以及各種衍生版本OS-ELM、EI-ELM、D-ELM、EM-ELM進行了對比(本文所有實驗結果都是重復實驗10次后的均值)。
3.2.1 各個數據ELM網絡結構的確定
對每個數據集逐漸增加隱藏節點的個數,如圖1所示。

圖1 準確度隨節點數增長過程
從圖1可以看出,隨著隱藏節點個數的增長,訓練準確度和測試準確度都在逐步上升,測試準確度在500隱藏節點時達到了平穩狀態,并且在550左右開始下降,因此,對于數據集Satellite Image,ELM的最優隱藏節點個數在550左右。對于其他兩組數據集進行同樣的實驗得到了相應的節點個數。
3.2.2 與ELM、OS-ELM算法的對比
將本文算法與ELM、OS-ELM算法進行實驗對比,結果如表2所示。從表2可以看出,本文算法在增加較少訓練時間的代價下,首先完成了隱藏節點個數自動生成的任務,并且在準確度上有了一定的提升,同時需要更少的隱藏節點來完成。這是因為本文提出的算法在每次增加節點之后,對一些不重要的對結果影響特別小的那些隱藏節點都進行刪除,這樣,留下來的節點都是提取了非常重要的特征,對最后的結果有著很大的影響,所以本文提出的算法能用比較少的節點得到比較高的準確度。
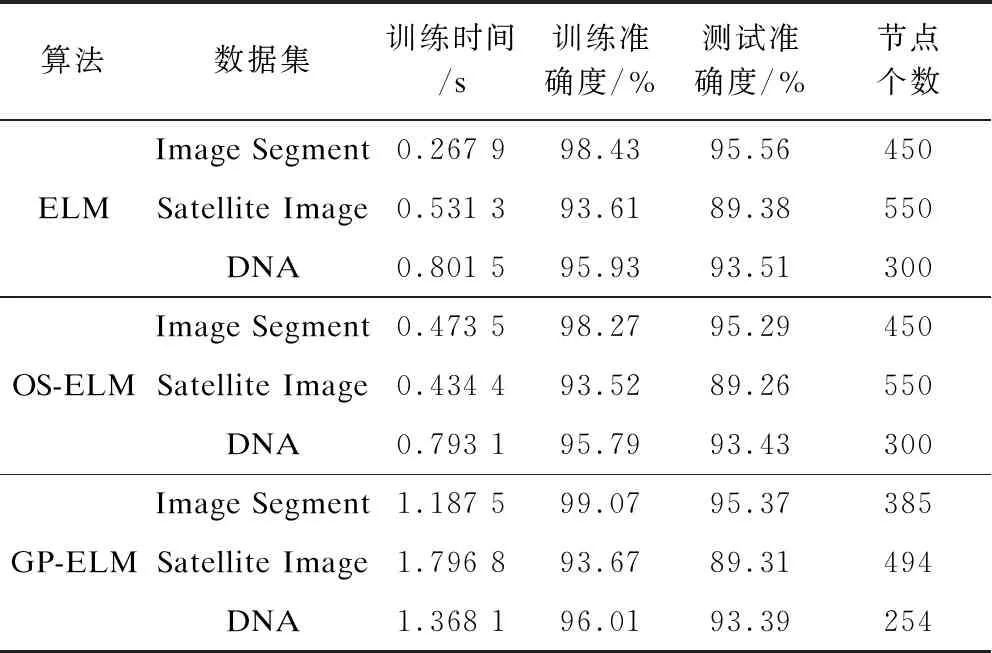
表2 GP-ELM與ELM、OS-ELM算法性能對比
3.2.3 與EI-ELM、D-ELM、EM-ELM算法的對比
本文算法與EI-ELM、D-ELM、EM-ELM算法的性能對比如表3所示。從表3可以看出,本文算法具有更高的準確度,這是因為刪去不重要的節點,使得本文算法生成的節點數量基本是最少的。另外,DP-ELM在訓練時間上相比其他算法要少,這是由于本文的算法并不是一個一個地增加節點,而是一塊一塊地增加,這樣大幅節省了訓練時間,同時,本文算法通過對原有的節點進行刪除修剪,這樣更有效地對ELM的結構進行組裝,提高所選節點的質量,在得到較高準確度的同時節省了隨機搜索而進行的大量迭代時間,保證了更少的節點。
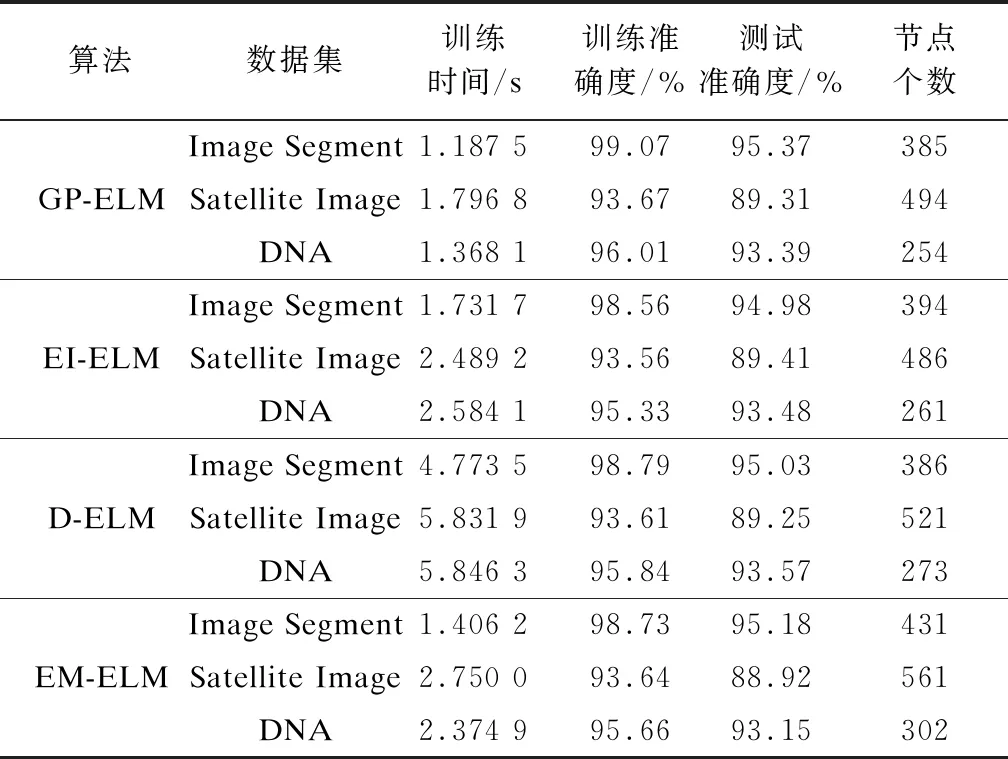
表3 GP-ELM與EI-ELM、D-ELM、EM-ELM 算法性能對比
通過觀察圖2所示的迭代次數與被加入的隱藏節點個數的對比,可以發現GP-ELM是每次增加多個節點然后進行修剪,所以會很快地并以較少的節點完成迭代,可以看出本文算法具有較大的優勢。
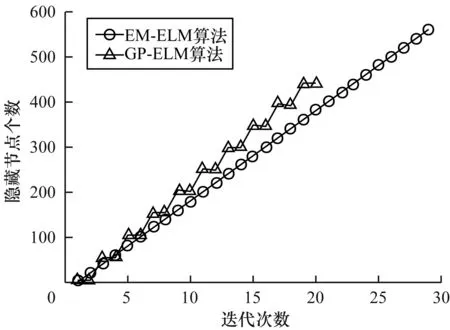
圖2 節點個數隨迭代次數變化過程
4 結束語
為適應機器學習算法準確、快速以及自適應產生參數的需求,本文通過研究ELM網絡結構的確定方法,結合EM-ELM算法節點增加的方式和廣義逆的迭代公式,引入節點的修剪刪除的階段,實現達到根據數據本身自動地確定ELM網絡結構的能力,并且在確定的過程中不斷地刪除貢獻較低的節點,以保持網絡的大小,提高ELM的準確性。實驗結果表明,與EM-ELM、D-ELM和EI-ELM算法相比,DP-ELM算法能夠保證泛化能力,在準確率、訓練時間、模型大小等方面都有著很好的表現,滿足物聯網下邊緣設備對機器學習產生的應用需求。下一步將把該算法拓展到真實的物聯網場景下進行應用,以測試實際的效果與適用范圍。
猜你喜歡
作文·小學低年級(2025年2期)2025-02-13 00:00:00
小雪花·小學生快樂作文(2024年11期)2024-12-31 00:00:00
作文·小學低年級(2024年2期)2024-04-29 00:00:00
作文·小學低年級(2023年3期)2023-04-29 00:00:00
小獼猴智力畫刊(2022年9期)2022-11-04 02:31:42
小主人報(2022年4期)2022-08-09 08:52:06
中學生數理化·中考版(2022年11期)2022-02-16 07:01:20
小哥白尼(趣味科學)(2019年6期)2019-10-10 01:01:50
發明與創新(2016年38期)2016-08-22 03:02:52
太空探索(2016年5期)2016-07-12 15:17:55
