Elman神經網絡在優化空氣預報模式結果中的應用①
2020-06-20 07:32:30于海飛1杜毅明金繼鑫曹吉龍趙思彤
計算機系統應用 2020年6期
關鍵詞:模型
張 鏑,于海飛1,,劉 閩,杜毅明,金繼鑫,曹吉龍,趙思彤
1(中國科學院大學,北京 100049)
2(中國科學院 沈陽計算技術研究所,沈陽 110168)
3(遼寧省沈陽生態環境監測中心,沈陽 110000)
4(中國醫科大學附屬第四醫院,沈陽 110032)
5(沈陽市第二十二中學,沈陽 110000)
改革開放以來,我國大力發展工業、制造業,經濟發展的同時,帶來的環境問題也不容忽視.近年來,空氣質量狀況越發得到人們的密切關注,2017年我國空氣污染狀況以華北地區為中心呈放射狀分布,空氣質量直接影響到人類的日常生活[1].綠水青山就是金山銀山,地處東北老工業基地的沈陽市也面臨著同樣嚴峻的空氣質量問題.空氣質量的精準預測能夠為空氣質量的治理提供科技支撐,各項污染物濃度數據是計算空氣質量指數進而衡量空氣質量的重要依據.
空氣質量數值模式是一種通過大氣物理化學方式來模擬污染物之間的相互反應、傳輸和轉化過程,進而預測空氣質量的方法.空氣質量模式CMAQ 和CAMx是依據大氣物理化學方法來模擬污染物的擴散和反應過程進而來預測空氣質量的方法.從最初的采用簡單線性機制的第一代空氣質量模式,發展到考慮了物質之間的互相作用和相互轉化的第三代空氣質量模式,預測精度不斷提高.但是由于空氣質量模式受污染源清單數據,氣象數據,光解文件等輸入文件的影響,輸入文件的質量會影響預測結果誤差大小.因此本文提出了一種集成CMAQ 和CAMx 兩種單一空氣質量模式結果的方法,在單一數值模式的基礎上降低誤差,提高預測準確率.司志娟等[2]將灰色GM(1,1)模型與人工神經網絡模型組合,對天津市2009 到2010 的PM10、SO2、NO2進行預測,預測相對誤差在5%以下.張恒德等[3]利用BP 神經網絡集成了CUACE、BREMPS和WRF-Chem 等3 個環境模式預報產品,2015 到2016年在北京和石家莊地區污染物濃度和實測值的均方根誤差比各單一模式降低了15%以上.梅貴琴[4]利用Elman神經網絡根據以往臭氧濃度數據預測未來臭氧濃度值,絕大多數的數據可以達到小于0.2 的相對誤差.神經網絡具有預測未來非線性數據的能力,應用于各個地區空氣質量預測方面取得了良好的效果.考慮到過往短時間段內空氣質量會對未來空氣質量產生影響,而Elman神經網絡能夠增加對過往數據的敏感性.因此本文提出將Elman 神經網絡用于集成CMAQ 和CAMx 兩種數值模式的預測結果,在單一數值模式基礎上提高空氣質量預測結果的準確度.
1 Elman 神經網絡
Elman 神經網絡是一種反饋型神經網絡,由輸入層,隱含層,承接層,輸出層四層組成,承接層是從隱含層獲得反饋信息,然后再輸入到隱含層,以此來記憶隱含層神經元的上一時刻的輸出,這樣的網絡結構可以增強對過往數據的敏感度[5-8].Elman 神經網絡結構如圖1所示.其中,輸入向量是r維的x向量,x=[x1,x2,···,xr];隱含層輸出向量是n維的u向量,u=[u1,u2,···,un];輸出向量是m維的y向量,y=[y1,y2,···,ym];承接層輸出向量是n維的xc向量,xc=[xc1,xc2,···,xcn].w(i,k),w(k,j),w(s,k)分別是輸入層到隱含層,隱含層到輸出層,承接層到隱含層的權重矩陣[9].f(·),g(·)分別是隱含層和輸出層的激活函數,h(·)是承接層激活函數,Xc是承接層輸出,t是時間步長,輸出層輸出為:

隱含層輸出為:
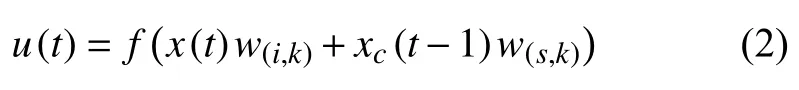
承接層輸出為:

Elman 神經網絡模型的算法學習流程,首先要初始化各層節點的權值,然后輸入訓練數據,計算各層的輸入輸出值.其中將隱含層上一輪的輸出,輸入到承接層,數據經過承接層處理后在本輪和輸入層數據一同輸入到隱含層.最后根據輸出層的結果和誤差函數計算誤差,若誤差的大小滿足要求或訓練次數達到最大,則停止訓練,否則更新權值,進入下一輪訓練.
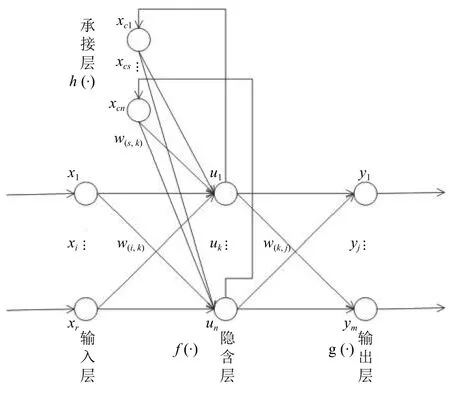
圖1 Elman 神經網絡結構示意圖
誤差函數為:
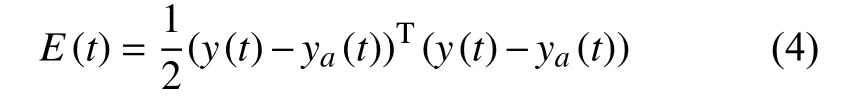
式(4)中,ya(t)是標準實際輸出數據,y(t)模型輸出數據.
根據誤差逆向傳播算法,得到:

其中,
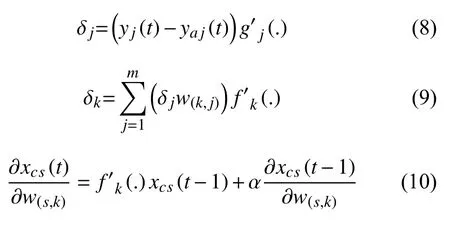
η1,η2,η3分別是w(i,k),w(k,j),w(s,k)的 學習率,δj是輸出層神經元的梯度項,δk是隱含層神經元的梯度項[10].xcs是承接層第s維輸出,uk是隱含層第k維輸出.yj(t)是第j個結點第t輪的輸出值,yaj(t)是第t輪 第j個結點的標準輸出值.g′j(.)是輸出層的導數,f′k(.)是隱含層的導數,0 ≤α <1.
學習算法偽代碼如算法1 所示.

算法1.學習算法.訓練集D={(xt,yt)}1.初始化Elman 神經網絡中所有連接權重和閾值.(xt,yt)∈D2.for all do 3.根據式(1)~式(3)計算每一層的輸出值;4.根據式(8)計算輸出層神經元梯度項;5.根據式(9)計算隱含層神經元梯度項;6.根據式(5)~式(7)更新權值;7.if(達到停止條件)8.break;9.end if 10.end for
2 實驗分析
本文數據集來源為空氣質量數值模式CMAQ 和CAMx 輸出的遼寧省沈陽市6 項常規污染物(包括PM2.5、PM10、SO2、CO、NO2、O3)的濃度結果,以及在中國空氣質量在線監測分析平臺所下載的6 項常規污染物的實測數據.本文中的數據集的大小為2019年1月到2019年6月共181 天,起報時刻為20 時,預報時長為未來4 天的6 項常規污染物24 小時平均濃度數據,其中選取30 條數據用作測試數據來評價模型的效果,剩余數據用于訓練模型.
2.1 數據預處理
空氣質量模式受氣象數據,地理數據,以及污染源清單數據等輸入文件的影響,會出現數據缺測情況,首先要去除缺測值,減少缺測數據對模型訓練的影響.
為了減少不同量綱對后續數據分析和模型訓練造成影響,需要先采用Min-Max 線性歸一化方法對數據進行歸一化處理,將原數據映射到(0,1)之間,公式如式(11)所示:
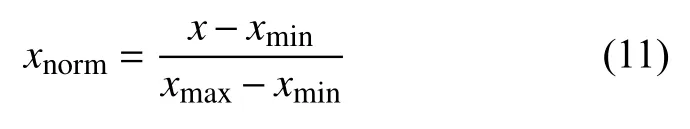
其中,xnorm表示歸一化后的數據,x表示原數據,xmin表示的是數據集中的最小值,xmax表示的是數據集中的最大值.
2.2 實驗過程
實驗過程如圖2所示,首先運行空氣質量模式CMAQ 和CAMx,對得到的空氣質量模式預測結果去除缺測數據處理,然后將空氣質量模式預測結果和實測數據進行歸一化處理,處理后的數據作為Elman 神經網絡的輸入,初始化各層結點的權值,進行訓練.
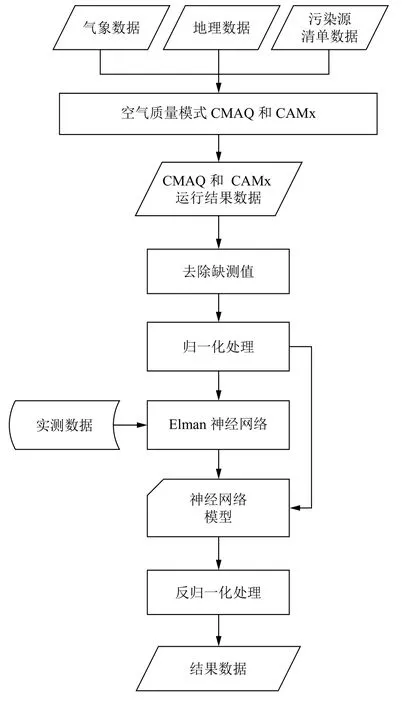
圖2 實驗流程圖
由于本算法需要結合CMAQ 和CAMx 兩個模型優化預測值,所以把輸入層節點數設置為2,輸出層節點數設置為1,經過敏感性實驗得到隱含層節點數設置為10 時效果最佳;輸出層激活函數設置為輸入和輸出相等的Purelin 函數;隱含層激活函數設置為Sigmoid函數,其公式如下所示:
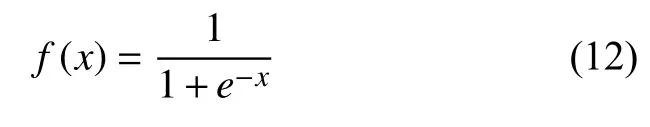
當訓練誤差達到最小(0.01)或達到最大訓練輪數(10 000)停止訓練.將測試數據輸入到訓練好的模型中,得到模型輸出結果,對模型輸出結果進行反歸一化處理,得到Elman 神經網絡模型優化的CMAQ 和CAMx預測結果.
2.3 評價指標
本文使用均方根誤差(RMSE),平均絕對誤差(MAD),和平均絕對百分比誤差(MAPE),來定量分析模型結果的精度[11-14].3 個評價指標公式如下:
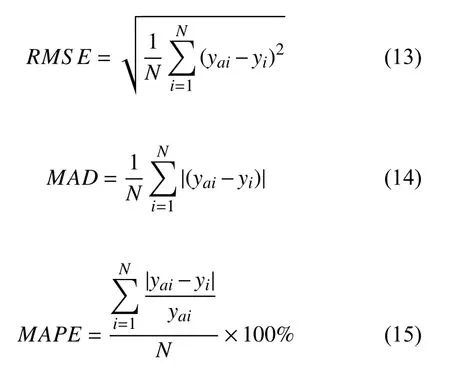
其中,yi是預測值,yai是實測值.均方根誤差(RMSE)是預測值與實測值誤差的平方和與實驗次數N比值的平方根,它能反應出預測值和實測值的偏差大小以及預測結果的穩定程度.平均絕對誤差(MAD)是預測值和實測值的絕對誤差和與實驗次數N的比值.平均絕對百分比誤差(MAPE)能反應模型的優劣程度,是相對誤差的和與試驗次數的比值.
2.4 結果分析
圖3是對比實驗結果圖,橫坐標表示時間序列,縱坐標表示污染物濃度,從圖3中可以看到,CMAQ 和CAMx 兩個單一數值模式的SO2和PM2.5預測結果偏高,NO2預測峰值時結果偏高,PM10和CO 預測趨勢和實測值大致相同,個別地方相差較大;而經過Elman神經網絡優化的預測結果與單一模式相比較更為接近實際值.
空氣質量模式CMAQ,CAMx 和基于Elman 神經網絡集成后結果的評價指標對比情況,如表1所示.綜合表1和圖3我們可以看到,就沈陽市的預報結果而言,兩種單一模式對于6 項污染物的預測結果都有不同程度的誤差.而集成后的6 項污染物預測結果的預測誤差有所下降,綜合對比3 個評價指標可以看到PM2.5和SO2的MAD和RMSE都有下降,MAPE有大幅度下降,其中PM2.5的MAPE下降了50%-88%,SO2的MAPE下降了110%-209%;而PM10,CO,NO2和O3的MAD和RMSE有小幅度下降或持平,MAPE都有所下降.總體來說,基于Elman 神經網絡優化兩種單一空氣質量模式的結果相比于單一空氣質量模式的預測精度和穩定性有所提高.
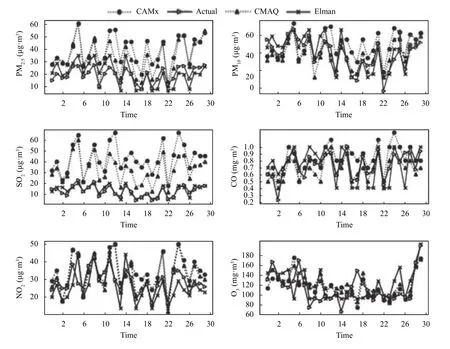
圖3 實驗結果圖
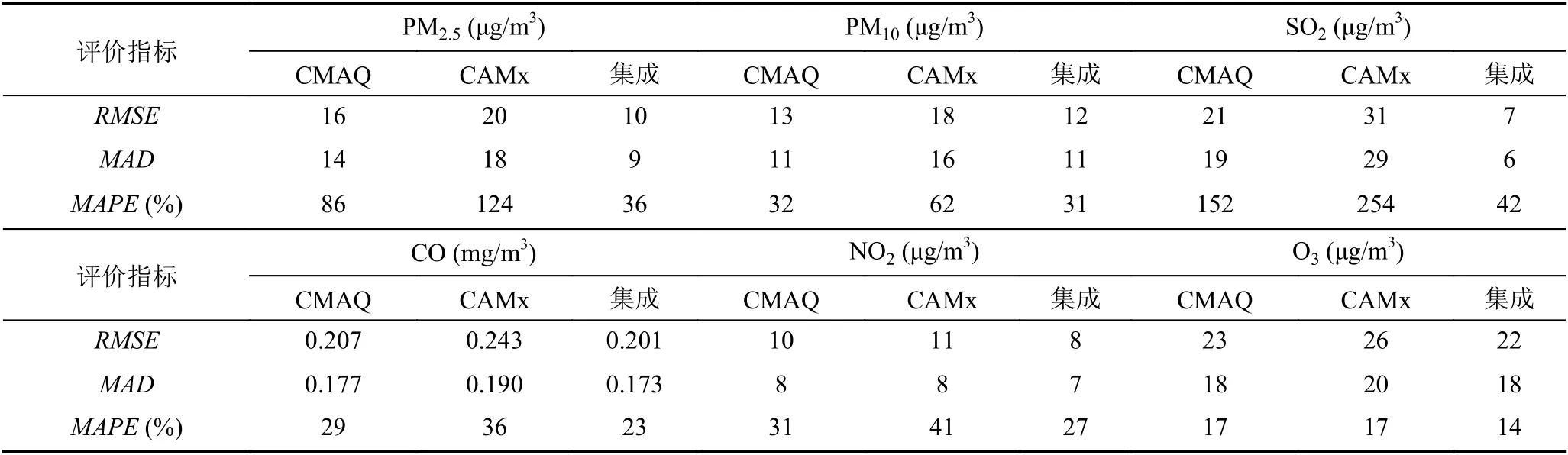
表1 實驗結果對比
3 結論
本文針對空氣質量預測提出了在CMAQ 和CAMx兩個空氣質量數值模型基礎上,通過Elman 神經網絡集成兩個數值模式結果的方法.實驗結果表明,本文提出的方法結合了兩種模型的優勢,提高了預測精度和穩定性,降低了單一空氣質量數值模式的預測誤差,從而能夠為后續空氣質量預報以及空氣質量控制提供數值依據.
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
網絡安全與數據管理(2022年1期)2022-08-29 03:15:20
導航定位學報(2022年4期)2022-08-15 08:27:00
中學生數理化·中考版(2022年8期)2022-06-14 06:55:24
新世紀智能(數學備考)(2021年9期)2021-11-24 01:14:36
成都醫學院學報(2021年2期)2021-07-19 08:35:14
新世紀智能(數學備考)(2020年9期)2021-01-04 00:25:14
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
光學精密工程(2016年6期)2016-11-07 09:07:19
