視覺(jué)類(lèi)深度神經(jīng)網(wǎng)絡(luò)的自動(dòng)標(biāo)注
2020-06-20 12:00:48郭晨皓
計(jì)算機(jī)應(yīng)用 2020年6期
關(guān)鍵詞:模型
李 鳴,郭晨皓,陳 星*
(1.福州大學(xué)數(shù)學(xué)與計(jì)算機(jī)科學(xué)學(xué)院,福州 350108;2.福建省網(wǎng)絡(luò)計(jì)算與智能信息處理重點(diǎn)實(shí)驗(yàn)室(福州大學(xué)),福州 350108)
(?通信作者電子郵箱chenxing@fzu.edu.cn)
0 引言
視覺(jué)是人類(lèi)理解認(rèn)識(shí)外部世界的重要途徑,在人類(lèi)認(rèn)知的過(guò)程中,有超過(guò)80%的信息量來(lái)自視覺(jué)系統(tǒng),而計(jì)算機(jī)視覺(jué)作為計(jì)算機(jī)科學(xué)領(lǐng)域一個(gè)重要的研究方向,目標(biāo)是讓計(jì)算機(jī)能夠幫助或者代替人眼感知圖像、視頻或者多維數(shù)據(jù),并從中獲得目標(biāo)的信息和數(shù)據(jù)[1]。
如今,隨著對(duì)深度神經(jīng)網(wǎng)絡(luò)研究的進(jìn)一步深入,它在計(jì)算機(jī)視覺(jué)領(lǐng)域中也有了廣泛的應(yīng)用,并在目標(biāo)檢測(cè)、目標(biāo)跟蹤、超分辨率、圖片生成、3D 建模和人體姿態(tài)相關(guān)等方向都取得了不錯(cuò)的效果[2]。因此,含有更多隱藏層的復(fù)雜模型被提出,相對(duì)于傳統(tǒng)的機(jī)器學(xué)習(xí)方法具有更強(qiáng)大有效的特征學(xué)習(xí)和特征表達(dá)能力。而面對(duì)著越來(lái)越多的模型,通過(guò)閱讀論文文檔來(lái)學(xué)習(xí)了解相關(guān)模型的開(kāi)發(fā)人員也就產(chǎn)生了如何根據(jù)所遇到的問(wèn)題快速準(zhǔn)確地找到合適模型的需求。本文根據(jù)這一需求進(jìn)行了相關(guān)的調(diào)研,發(fā)現(xiàn)目前已有對(duì)科學(xué)文章進(jìn)行提取關(guān)鍵詞并推薦的研究[3],但是,它不是專(zhuān)門(mén)針對(duì)視覺(jué)類(lèi)計(jì)算機(jī)神經(jīng)網(wǎng)絡(luò)來(lái)實(shí)現(xiàn)自動(dòng)標(biāo)注。因此,本文提出了模型應(yīng)用領(lǐng)域的自動(dòng)標(biāo)注系統(tǒng),通過(guò)對(duì)模型進(jìn)行自動(dòng)標(biāo)注,能夠幫助開(kāi)發(fā)人員更加快速準(zhǔn)確了解該模型的應(yīng)用領(lǐng)域,從而判斷是否是自己需要的模型。
本文的主要工作如下:
1)利用詞頻等信息計(jì)算得到不同領(lǐng)域中的關(guān)鍵詞以及其對(duì)應(yīng)的權(quán)值,并據(jù)此構(gòu)建了視覺(jué)類(lèi)深度神經(jīng)網(wǎng)絡(luò)的架構(gòu)圖,方便之后的模型分類(lèi)。
2)本文發(fā)現(xiàn)關(guān)鍵詞作為最能體現(xiàn)模型所屬領(lǐng)域特點(diǎn)的詞組表達(dá),往往在摘要中出現(xiàn)的地方具有相似性與固定性,根據(jù)這一發(fā)現(xiàn),提出了能夠提取文章摘要關(guān)鍵詞組的八種提取模型。
3)在實(shí)際數(shù)據(jù)上進(jìn)行實(shí)驗(yàn),結(jié)果表明,與傳統(tǒng)機(jī)器學(xué)習(xí)分類(lèi)算法相比,本文的方法可實(shí)現(xiàn)更好的性能。
1 相關(guān)工作
1.1 關(guān)鍵詞提取
目前,關(guān)鍵詞提取技術(shù)主要可以分為三類(lèi):語(yǔ)言學(xué)方法、統(tǒng)計(jì)方法、機(jī)器學(xué)習(xí)方法。
1.1.1 語(yǔ)言學(xué)方法
語(yǔ)言學(xué)方法中使用了單詞、句子和文檔的語(yǔ)言屬性,最常使用的語(yǔ)言屬性是詞法分析、句法分析、語(yǔ)義分析和語(yǔ)篇分析[4-6]。基于語(yǔ)言學(xué)方法具有不可避免的缺點(diǎn),首先語(yǔ)法規(guī)則不可能涵蓋所有語(yǔ)句,其次這種方法對(duì)開(kāi)發(fā)者的要求極為苛刻,開(kāi)發(fā)者不僅要精通計(jì)算機(jī)還要精通語(yǔ)言學(xué),因此,雖然語(yǔ)言學(xué)方法解決了一些簡(jiǎn)單的問(wèn)題,但是無(wú)法從根本上將自然語(yǔ)言理解實(shí)用化。
1.1.2 統(tǒng)計(jì)方法
統(tǒng)計(jì)方法基于術(shù)語(yǔ)內(nèi)部詞之間黏著度較高的假設(shè),該方法不需要訓(xùn)練數(shù)據(jù),而是利用統(tǒng)計(jì)特征實(shí)現(xiàn)關(guān)鍵詞提取[7]。目前統(tǒng)計(jì)方法包括n-gram 統(tǒng)計(jì)信息[8]、單詞詞頻[9]、詞匯同現(xiàn)[10]、PAT 樹(shù)(PATricia tree)[11]等。但是單純依靠?jī)?nèi)部黏著度效果并不理想,并且互信息算法很難排除語(yǔ)料中超低頻詞和超高頻詞的干擾等。
1.1.3 機(jī)器學(xué)習(xí)方法
機(jī)器學(xué)習(xí)方法在關(guān)鍵詞提取上的應(yīng)用主要分為有監(jiān)督和無(wú)監(jiān)督學(xué)習(xí)方法。有監(jiān)督的關(guān)鍵詞提取將問(wèn)題看作是二進(jìn)制分類(lèi)的問(wèn)題,主要存在三個(gè)問(wèn)題:需要昂貴的人工標(biāo)注費(fèi)用,不能滿足某些的特定要求和無(wú)法提取面向事件的關(guān)鍵短語(yǔ)[12]。與之相反,無(wú)監(jiān)督方法不需要標(biāo)記的訓(xùn)練數(shù)據(jù),而是探索一些外部統(tǒng)計(jì)信息來(lái)識(shí)別關(guān)鍵短語(yǔ)[13],目前無(wú)監(jiān)督的方法主要是基于詞頻-逆文本頻率(Term Frequency-Inverse Document Frequency,TF-IDF)、聚類(lèi)和圖的排序[14-16]。
1.2 文本分類(lèi)
目前,文本分類(lèi)主要可以分兩類(lèi):基于傳統(tǒng)機(jī)器學(xué)習(xí)的文本分類(lèi)和基于深度學(xué)習(xí)的文本分類(lèi)。
1.2.1 基于傳統(tǒng)機(jī)器學(xué)習(xí)
傳統(tǒng)的機(jī)器學(xué)習(xí)方法主要利用自然語(yǔ)言處理中的n-gram概念對(duì)文本進(jìn)行特征提取,并且利用TF-IDF[17]對(duì)n-gram 特征權(quán)重進(jìn)行調(diào)整,然后將提取到的文本輸入到Logistics 回歸[18]、支持向量機(jī)(Support Vector Machine,SVM)[19]等分類(lèi)器中進(jìn)行訓(xùn)練,但是,這類(lèi)問(wèn)題存在數(shù)據(jù)稀疏和緯度爆炸等問(wèn)題。
1.2.2 基于深度學(xué)習(xí)
針對(duì)傳統(tǒng)機(jī)器學(xué)習(xí)的高緯度高稀疏、特征表達(dá)能力弱等問(wèn)題,相關(guān)領(lǐng)域?qū)<覍⑸疃葘W(xué)習(xí)應(yīng)用到文本分類(lèi)中來(lái)解決這些不足。
Wang 等[20]通過(guò)應(yīng)用word embedding 來(lái)改善短文文本的分類(lèi),雖然該方法在一些文本分類(lèi)任務(wù)中,分類(lèi)的效果甚至超過(guò)了卷積神經(jīng)網(wǎng)絡(luò)(Convolutional Neural Network,CNN)/循環(huán)神經(jīng)網(wǎng)絡(luò)(Recurrent Neural Network,RNN),但是如果一個(gè)句子如果很長(zhǎng),少量的重要信息會(huì)被多數(shù)的無(wú)用信息淹沒(méi)。Banerjee 等[21]將CNN/RNN 應(yīng)用在文本分類(lèi)中,與word embedding 相比更適用于長(zhǎng)文本的分析,其中CNN 擅長(zhǎng)捕獲更短的序列信息,RNN 擅長(zhǎng)捕獲更長(zhǎng)的序列信息,但它們難以捕獲長(zhǎng)期的上下文信息和非連續(xù)詞之間的相關(guān)性。Cheng等[22]通過(guò)引入Attention 機(jī)制,可以對(duì)輸入的每個(gè)部分賦予不同的權(quán)值,抽取出更加關(guān)鍵及重要的信息,使模型作出更加準(zhǔn)確的判斷,同時(shí)不會(huì)給模型的計(jì)算和存儲(chǔ)帶來(lái)更大的開(kāi)銷(xiāo)。
2 方法設(shè)計(jì)
2.1 總體結(jié)構(gòu)
視覺(jué)類(lèi)深度神經(jīng)網(wǎng)絡(luò)自動(dòng)標(biāo)注的流程如圖1所示。
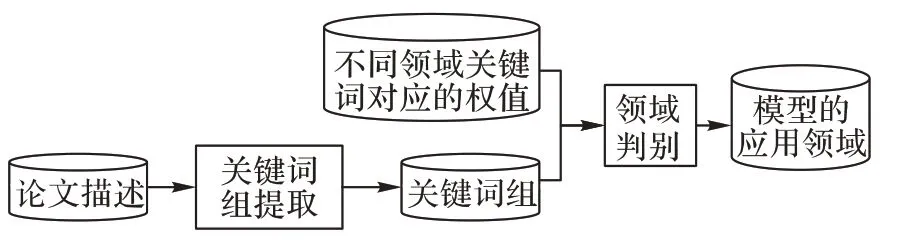
圖1 總體框架Fig.1 Overall framework
首先將模型描述作為輸入,根據(jù)關(guān)鍵詞提取可以得到文章的關(guān)鍵詞,然后依據(jù)得到的關(guān)鍵詞以及不同領(lǐng)域關(guān)鍵詞對(duì)應(yīng)的權(quán)值計(jì)算得到該模型的應(yīng)用領(lǐng)域。
2.2 模型研究領(lǐng)域的判別
2.2.1 視覺(jué)類(lèi)深度神經(jīng)網(wǎng)絡(luò)架構(gòu)圖設(shè)計(jì)
目前,深度神經(jīng)網(wǎng)絡(luò)在計(jì)算機(jī)視覺(jué)中的多個(gè)領(lǐng)域都有著廣泛的應(yīng)用[23],本文主要針對(duì)其中的六個(gè)領(lǐng)域進(jìn)行研究,從網(wǎng)絡(luò)公開(kāi)的計(jì)算機(jī)視覺(jué)類(lèi)論文中,收集了這六個(gè)領(lǐng)域共264 篇論文作為實(shí)驗(yàn)的語(yǔ)料庫(kù)。其中:目標(biāo)檢測(cè)48 篇,目標(biāo)跟蹤44篇,超分辨率54篇,圖像生成43篇,3D建模相關(guān)36篇,人體姿態(tài)相關(guān)39 篇。根據(jù)語(yǔ)料庫(kù)中264 篇論文,并通過(guò)以下的計(jì)算公式,得到不同領(lǐng)域?qū)?yīng)的關(guān)鍵詞及其對(duì)應(yīng)的權(quán)值(關(guān)鍵詞和權(quán)值會(huì)隨著語(yǔ)料庫(kù)的擴(kuò)充進(jìn)行相應(yīng)的增加和修改)。
在對(duì)某個(gè)領(lǐng)域進(jìn)行關(guān)鍵詞選擇和權(quán)值計(jì)算時(shí),本文主要考慮兩方面:第一,詞在該領(lǐng)域論文摘要中出現(xiàn)的頻率;第二,詞出現(xiàn)的論文摘要在該領(lǐng)域摘要中的占比。
1)計(jì)算詞在不同領(lǐng)域論文摘要中出現(xiàn)的頻率,計(jì)算式如下:
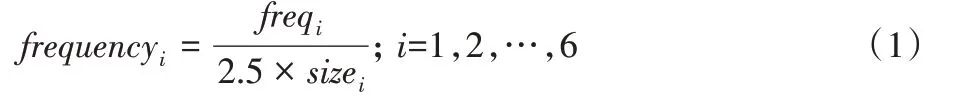
其中:freqi表示該詞在i領(lǐng)域論文摘要出現(xiàn)的次數(shù);sizei表示i領(lǐng)域中總的論文摘要數(shù)。通過(guò)觀察發(fā)現(xiàn),詞在一篇文章中出現(xiàn)的次數(shù)一般為1~3,基本都是低頻詞,所以這里將sizei乘以2.5 是為了保證計(jì)算的frequencyi值不會(huì)超過(guò)1 并且又不會(huì)過(guò)小。
2)計(jì)算詞出現(xiàn)的論文在不同領(lǐng)域的占比,計(jì)算式如下:
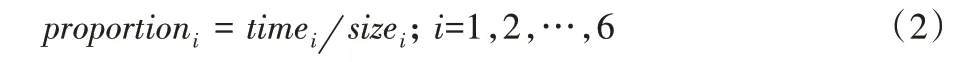
其中:timei表示i領(lǐng)域論文摘要中出現(xiàn)該詞的摘要數(shù);sizei表示i領(lǐng)域中總的論文摘要數(shù)。
3)計(jì)算詞在不同領(lǐng)域的權(quán)值,計(jì)算公式定義如下:
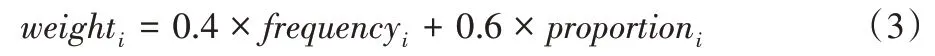
其中詞頻和占比以4∶6 的比例計(jì)算,最終結(jié)果保留一位有效數(shù)字。在計(jì)算過(guò)程中過(guò)濾掉proportioni低于0.2 的詞,因?yàn)檫@些詞不具有領(lǐng)域代表性。最后,通過(guò)人工經(jīng)驗(yàn)篩去一些干擾詞,得到領(lǐng)域的關(guān)鍵詞及其對(duì)應(yīng)的權(quán)值
根據(jù)實(shí)驗(yàn)得到的關(guān)鍵詞和權(quán)值構(gòu)建出了視覺(jué)類(lèi)深度神經(jīng)網(wǎng)絡(luò)架構(gòu),如圖2 所示,其中:第三層中單詞字號(hào)越大代表該單詞在這個(gè)領(lǐng)域的比重越大,而相同大小的單詞代表相同的權(quán)值,第四層是第三層中每個(gè)領(lǐng)域?qū)?yīng)關(guān)鍵詞的具體權(quán)值,這里每個(gè)領(lǐng)域只具體列出前五個(gè)。
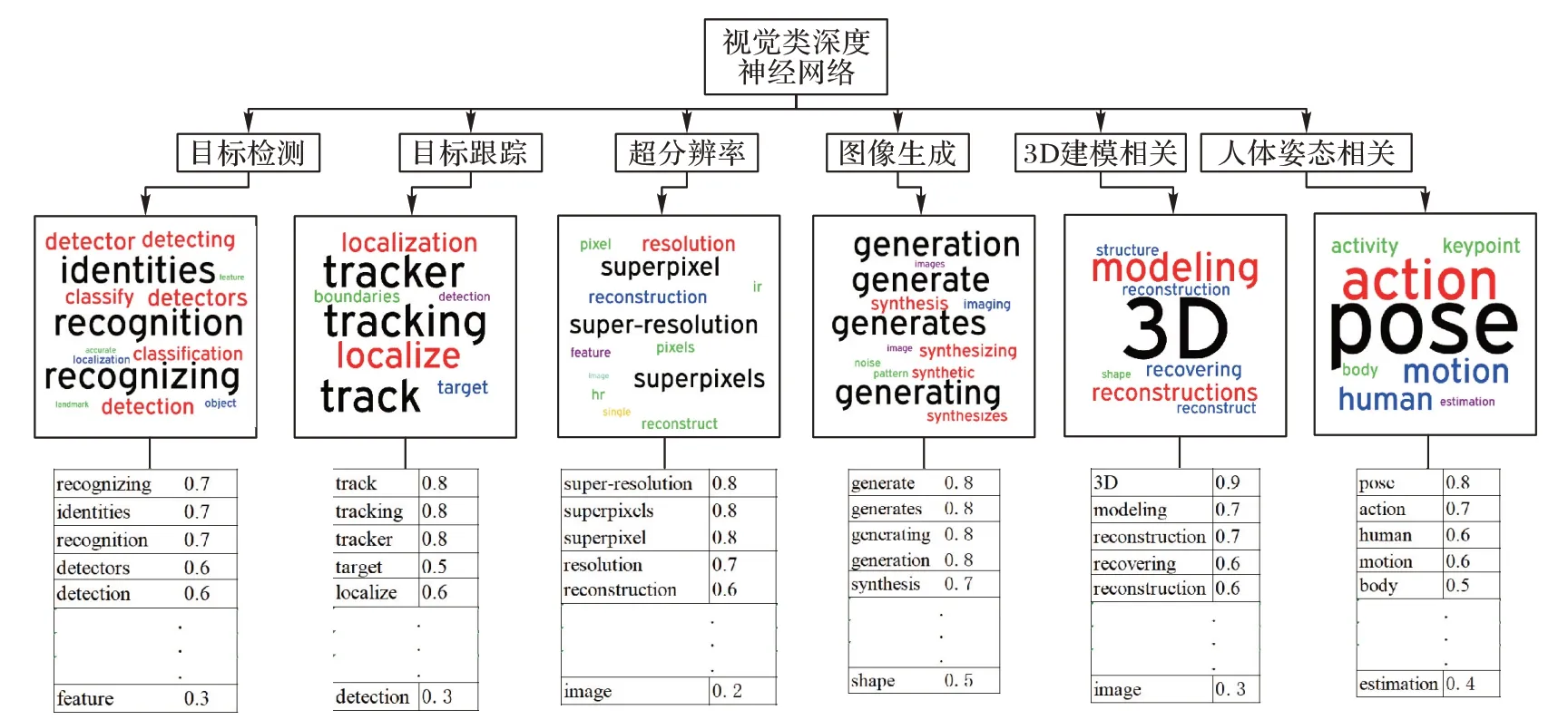
圖2 視覺(jué)類(lèi)深度神經(jīng)網(wǎng)絡(luò)架構(gòu)Fig.2 Visual deep neural network architecture
2.2.2 模型關(guān)鍵詞的提取
通過(guò)觀察視覺(jué)類(lèi)神經(jīng)網(wǎng)絡(luò)論文的摘要特點(diǎn),發(fā)現(xiàn)關(guān)鍵詞作為最能體現(xiàn)模型所屬領(lǐng)域特點(diǎn)的詞組表達(dá),往往在文中出現(xiàn)的地方具有相似性與固定性。根據(jù)這一發(fā)現(xiàn),本文提出了八種關(guān)鍵詞提取模型,以下是模型的定義與示例。
1)提取模型一:首句主語(yǔ)。
在計(jì)算機(jī)視覺(jué)類(lèi)論文的文摘中,論文試圖解決的問(wèn)題一般會(huì)在首句就有體現(xiàn),而首句的主語(yǔ)一般就會(huì)有對(duì)該問(wèn)題的表述,所以首句的主語(yǔ)對(duì)應(yīng)的詞組對(duì)于內(nèi)容的判別來(lái)說(shuō)很有參考和提取的價(jià)值。
提取模型一定義:從句子依存樹(shù)的ROOT(根節(jié)點(diǎn))出發(fā),向前回溯,找到依存于該ROOT 且關(guān)系為nsubj(名詞性主語(yǔ))的實(shí)體詞組,如未找到則取第一個(gè)找到的依存關(guān)系為dobj(直接賓語(yǔ))的實(shí)體詞組。
以句子s1為例:

s1對(duì)應(yīng)依存樹(shù)如圖3所示。
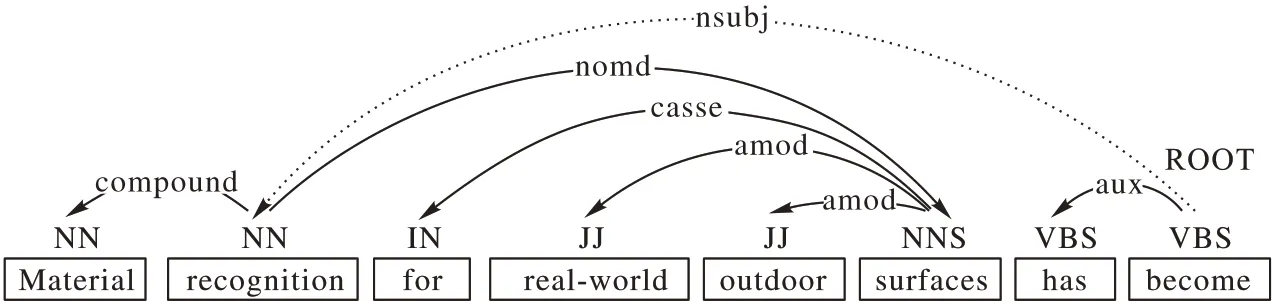
圖3 s1對(duì)應(yīng)的依存分析樹(shù)Fig.3 Dependency analysis tree corresponding to s1
根據(jù)提取模型一的定義,從ROOT 出發(fā),即可得到關(guān)系為nsubj 的詞“recognition”,再以該詞為起點(diǎn)向前和向后尋找與該詞有依存且為修飾關(guān)系的詞,提取到整個(gè)實(shí)體詞組:“Material recognition for real-world outdoor surfaces”。
2)提取模型二:特定名詞及其修飾詞。
在計(jì)算機(jī)視覺(jué)類(lèi)論文的摘要中,表述文章解決的問(wèn)題或涉及的領(lǐng)域的信息常常會(huì)包含某些特定的名詞(具體如表1所示),針對(duì)這些特定的名詞提取出對(duì)應(yīng)的詞組,也能夠幫助判別模型所屬的領(lǐng)域。
提取模型二定義:以特定名詞作為實(shí)體詞組的名詞性主體和觸發(fā)條件,向前回溯與這一名詞性主體存在依存關(guān)系的修飾詞,同時(shí)向后遍歷,提取case(狀語(yǔ))關(guān)系涉及的修飾和conj(連接詞)作為后綴修飾信息。
以句子s2為例:

s2對(duì)應(yīng)依存樹(shù)如圖4所示。
根據(jù)提取模型二的定義,該句中“problems”為特定名詞,向前回溯得到依存于該詞的修飾詞,最終提取出詞組“various visual recognition problems”,由于“problems”無(wú)后綴,所以這里不需要向后遍歷。
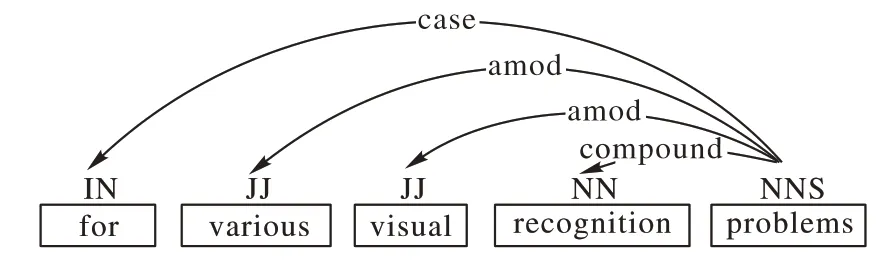
圖4 s2對(duì)應(yīng)的依存分析樹(shù)Fig.4 Dependency analysis tree corresponding to s2
3)提取模型三:特定名詞的case/mark 指向部分。
根據(jù)觀察,提及論文主要工作的詞組常常出現(xiàn)在特定名詞(具體如表1 所示)的case(狀語(yǔ))或者mark(主要為“that”“whether”或者“because”)指向的部分。由此現(xiàn)象,提出了該提取模型三。
提取模型三定義:以特定的名詞出發(fā),向后查看是否存在限定場(chǎng)景、領(lǐng)域和應(yīng)用范圍的case/mark 關(guān)系引導(dǎo),如果有,根據(jù)case和mark引導(dǎo)規(guī)則的不同:對(duì)于case,直接對(duì)case指向的實(shí)體詞組進(jìn)行提取;而對(duì)于mark,向后遍歷找到依存關(guān)系是dobj(直接賓語(yǔ))的詞語(yǔ),然后判別mark 與dobj 對(duì)應(yīng)詞之間的詞是否依存于mark或mark指向的詞,如果有則加入到最后提取出的詞組的前修飾中。
以句子s3為例:

s3對(duì)應(yīng)依存樹(shù)如圖5所示。

圖5 s3對(duì)應(yīng)的依存分析樹(shù)Fig.5 Dependency analysis tree corresponding to s3
根據(jù)提取模型三的定義,該句中the problem of 為特定名詞,而其后是mark 引導(dǎo)的,所以向后尋找依存于mark 的直接賓語(yǔ),得到“keypoints”,然后提取整個(gè)實(shí)體詞組,最終得到“estimating and tracking human body keypoints”。
4)提取模型四:特定及物動(dòng)詞的直接賓語(yǔ)。
在計(jì)算機(jī)視覺(jué)類(lèi)論文的摘要中特定的及物動(dòng)詞(具體如表1 所示)往往直接賓語(yǔ)往往能夠代表文章的主要工作,所以這類(lèi)直接賓語(yǔ)即為需要提取的目標(biāo)詞組。針對(duì)這一規(guī)則,提出了提取模型四。
提取模型四定義:檢測(cè)句子中的關(guān)鍵詞,隨后尋找該關(guān)鍵詞的直接賓語(yǔ),即依存關(guān)系為dobj(直接賓語(yǔ))的詞語(yǔ),依據(jù)索引獲取該詞語(yǔ)對(duì)應(yīng)的實(shí)體詞組。
以句子s4為例:
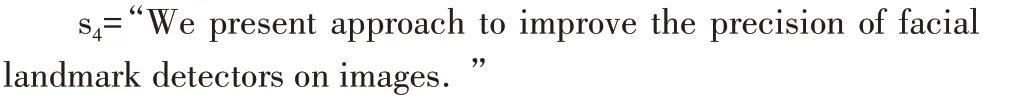
s4對(duì)應(yīng)依存樹(shù)如圖6所示。
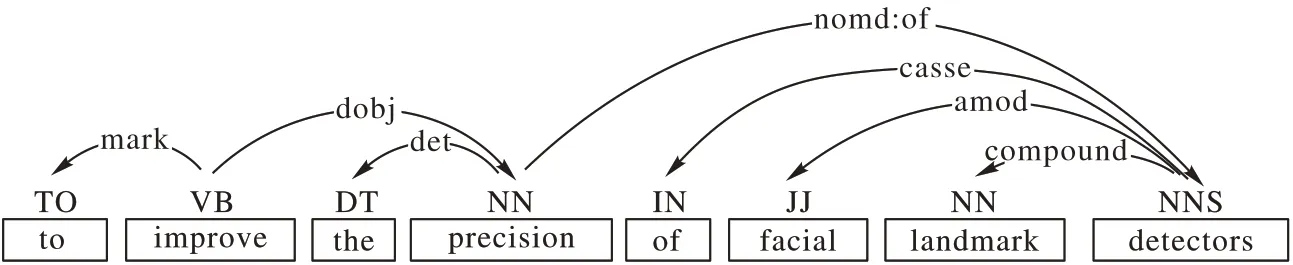
圖6 s4對(duì)應(yīng)的依存分析樹(shù)Fig.6 Dependency analysis tree corresponding to s4
根據(jù)提取模型四的定義,該句中“improve”為特定的及物動(dòng)詞,所以提取其直接賓語(yǔ)“precision”,然后根據(jù)“precision”提取實(shí)體詞組,得到“precision of facial landmark detectors”。
5)提取模型五:特定動(dòng)詞的直接賓語(yǔ)對(duì)應(yīng)的動(dòng)詞短語(yǔ)。
對(duì)于特定的動(dòng)詞(具體如表1 所示),表達(dá)主要文章工作的內(nèi)容常常出現(xiàn)在該修飾的賓語(yǔ)的從句之中,而特定動(dòng)詞修飾的賓語(yǔ)在從句中通常充當(dāng)主語(yǔ)的成分,對(duì)應(yīng)的動(dòng)詞短語(yǔ)即是目標(biāo)詞組。
提取模型五定義:首先檢測(cè)該特定動(dòng)詞對(duì)應(yīng)的依存關(guān)系為dobj(直接賓語(yǔ))的詞語(yǔ),如果之后有從句信息,則繼續(xù)向后遍歷查找依存于該直接賓語(yǔ)的動(dòng)詞,根據(jù)查找到的動(dòng)詞,獲取動(dòng)詞短語(yǔ)作為目標(biāo)詞組。
以句子s5為例:

s5對(duì)應(yīng)依存樹(shù)如圖7所示。
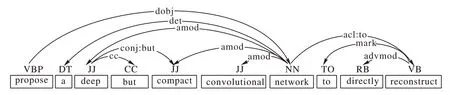
圖7 s5對(duì)應(yīng)的依存分析樹(shù)Fig.7 Dependency analysis tree corresponding to s5
根據(jù)提取模型五的定義,該句中“propose”為特定動(dòng)詞,然后尋找得到對(duì)應(yīng)的直接賓語(yǔ)“network”,由于之后還有從句信息,所以尋找“network”對(duì)應(yīng)的動(dòng)詞即“reconstruct”,最終找到“reconstruct”對(duì)應(yīng)的動(dòng)詞短語(yǔ)“reconstruct the high resolution image”。
6)提取模型六:for引導(dǎo)的短語(yǔ)。
在摘要之中,“For”常常在句首出現(xiàn),作為句子表明解決的問(wèn)題的限定,對(duì)表達(dá)論文屬于哪一計(jì)算機(jī)視覺(jué)類(lèi)的研究方向有著一定指示的作用,同時(shí)由于句式的不同和表達(dá)方式的不同,也存在句中使用“for”引導(dǎo)的情況。基于以上觀察,設(shè)計(jì)和實(shí)現(xiàn)提取模型六。
提取模型六定義:首先判斷是否句首為“For”并且依存關(guān)系為case(狀語(yǔ)),如果滿足,則根據(jù)case 這一依存關(guān)系指示的對(duì)象提取實(shí)體詞組。如果句首不是“For”,則遍歷句子查找“for”單詞,滿足上述同樣的條件的情況下,提取目標(biāo)短語(yǔ)。
以句子s6為例:

s6對(duì)應(yīng)依存樹(shù)如圖8所示。
根據(jù)提取模型六的定義,該句滿足句首為“For”并且依存關(guān)系為case 這一條件,所以找到依存于“for”且關(guān)系為case 的“modeling”,最后根據(jù)“modeling”提取實(shí)體詞組得到“modeling the 3D world behind 2D images”。
7)提取模型七:特定及物動(dòng)詞引導(dǎo)的賓語(yǔ)。
計(jì)算機(jī)視覺(jué)類(lèi)論文的摘要中,一般存在主語(yǔ)為“We”,且句中存在特定及物動(dòng)詞(具體如表1 所示)來(lái)表述關(guān)鍵信息的句子,基于這樣的觀察,設(shè)計(jì)提取模型七。
提取模型七定義:如果句子主語(yǔ)為“We”,則尋找句子中特定及物動(dòng)詞,找到特定及物動(dòng)詞后繼續(xù)向后遍歷找到與該及物動(dòng)詞存在依存關(guān)系的詞,根據(jù)該詞提取前置修飾和后綴修飾,整理組合作為目標(biāo)短語(yǔ)。
以句子s7為例:

s7對(duì)應(yīng)依存樹(shù)如圖9所示。

圖8 s6對(duì)應(yīng)的依存分析樹(shù)Fig.8 Dependency analysis tree corresponding to s6

圖9 s7對(duì)應(yīng)的依存分析樹(shù)Fig.9 Dependency analysis tree corresponding to s7
根據(jù)提取模型七的定義,該句主語(yǔ)為“We”,并且“propose”是特定及物動(dòng)詞,繼續(xù)向后遍歷得到依存于“propose”的詞“algorithm”,然后根據(jù)“algorithm”提取前置修飾和后綴修飾,最終得到“a novel visual tracking algorithm based on the representations”為目標(biāo)詞組。
8)提取模型八:特定非及物動(dòng)詞引導(dǎo)的賓語(yǔ)。
與提取模型七同理,存在主語(yǔ)為“We”,且句中存在特定非及物動(dòng)詞(具體如表1 所示)來(lái)表述關(guān)鍵信息的句子,基于這樣的觀察,設(shè)計(jì)提取模型八。
提取模型八定義:如果句子主語(yǔ)為“We”,則尋找句子中特定非及物動(dòng)詞,找到非及物動(dòng)詞后繼續(xù)向后遍歷,尋找與該詞存在依存關(guān)系的賓語(yǔ),根據(jù)該賓語(yǔ)提取前置修飾和后綴修飾,整理組合作為目標(biāo)詞組。
以句子s8為例:

s8對(duì)應(yīng)依存樹(shù)如圖10所示。
根據(jù)提取模型八的定義,該句主語(yǔ)為“We”,并且“focus”是特定非及物動(dòng)詞,繼續(xù)向后遍歷得到依存于“focus”的賓語(yǔ)“task”,然后根據(jù)“task”提取前置修飾和后綴修飾,最終得到“task of amodal 3D object detection”為目標(biāo)詞組。
由于抽象出的提取模型不同,所以需要結(jié)合不同的特定詞完成提取目標(biāo)詞組,提取模型對(duì)應(yīng)的特定詞如表1所示。

圖10 s8對(duì)應(yīng)的依存分析樹(shù)Fig.10 Dependency analysis tree corresponding to s8

表1 提取模型對(duì)應(yīng)的特定詞Tab.1 Specific words corresponding to extraction models
根據(jù)上述的八種模型,提取得到摘要的關(guān)鍵詞組,為便于后續(xù)公式計(jì)算,進(jìn)行應(yīng)用領(lǐng)域判別,需要將提取到的目標(biāo)詞組轉(zhuǎn)化為單詞的集合,這里采用詞袋模型[24]的思想。

式中:patternResult是所有提取模型結(jié)合關(guān)鍵詞匹配提取的目標(biāo)詞組;wordsi由第i個(gè)模型匹配得到的詞組以詞為單位分解而來(lái)的詞集;wordBag是所有wordsi包含的詞的集合。
2.2.3 領(lǐng)域判別
根據(jù)上述2.2.2 節(jié)中八個(gè)模型提取到的關(guān)鍵詞組以及2.2.1節(jié)中構(gòu)建出的視覺(jué)類(lèi)深度神經(jīng)網(wǎng)絡(luò)架構(gòu),通過(guò)判別公式可以計(jì)算得出模型所屬的領(lǐng)域,這里的判別公示采用余弦相似度[25]來(lái)判斷預(yù)測(cè)模型與哪種領(lǐng)域更加匹配,具體步驟如下:
步驟1 根據(jù)式(7)和2.2.1節(jié)構(gòu)建的視覺(jué)類(lèi)深度神經(jīng)網(wǎng)絡(luò)架構(gòu)第四層的關(guān)鍵詞對(duì)應(yīng)的權(quán)值,計(jì)算六個(gè)領(lǐng)域的領(lǐng)域向量xi。式(7)中wij即為i領(lǐng)域中第j個(gè)關(guān)鍵詞對(duì)應(yīng)的權(quán)值,總共有m個(gè)關(guān)鍵詞(m值根據(jù)所屬領(lǐng)域的關(guān)鍵詞數(shù)量決定),最終得到六個(gè)領(lǐng)域的領(lǐng)域向量如表2所示。
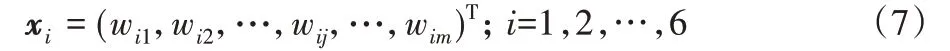
步驟2 根據(jù)式(8)以及模型通過(guò)2.2.2節(jié)中八個(gè)模型提取到的關(guān)鍵詞集合,計(jì)算該模型在六個(gè)領(lǐng)域的模型領(lǐng)域向量yi。式(8)中,zij為i領(lǐng)域中第j個(gè)詞的模型權(quán)值,zij的值有兩種情況,如果模型提取出的關(guān)鍵詞集合中含有i領(lǐng)域的第j個(gè)詞,則zij與wij值一致;否則為0。
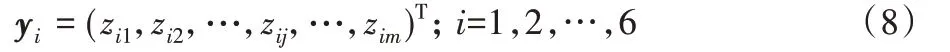
步驟3 計(jì)算模型與六個(gè)領(lǐng)域的匹配程度,由步驟1與步驟2 可以得到xi和yi向量,然后通過(guò)式(9)計(jì)算得到余弦相似度simi表示該模型在第i領(lǐng)域中的相似度,值越大越接近于1表示與這個(gè)領(lǐng)域越匹配。

步驟4 計(jì)算模型第k匹配的領(lǐng)域,根據(jù)式(10)可以得到topk,即6 個(gè)領(lǐng)域中與模型第k接近的領(lǐng)域,當(dāng)k為1 時(shí)即表示模型最大概率所屬的應(yīng)用領(lǐng)域。
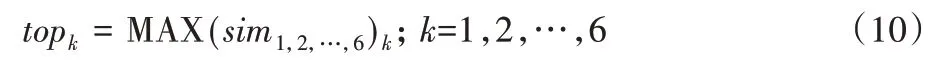

表2 六個(gè)領(lǐng)域?qū)?yīng)的領(lǐng)域向量Tab.2 Field vectors corresponding to six fields
2.2.4 評(píng)估標(biāo)準(zhǔn)
為了正確評(píng)估實(shí)驗(yàn)性能,選擇以下指標(biāo)作為評(píng)估標(biāo)準(zhǔn):查全率R(recall)、查準(zhǔn)率P(precision)、均值F1、宏平均查全率Macro_R、宏平均查準(zhǔn)率Macro_P、宏平均值Macro_F1[26]。
計(jì)算式如下:
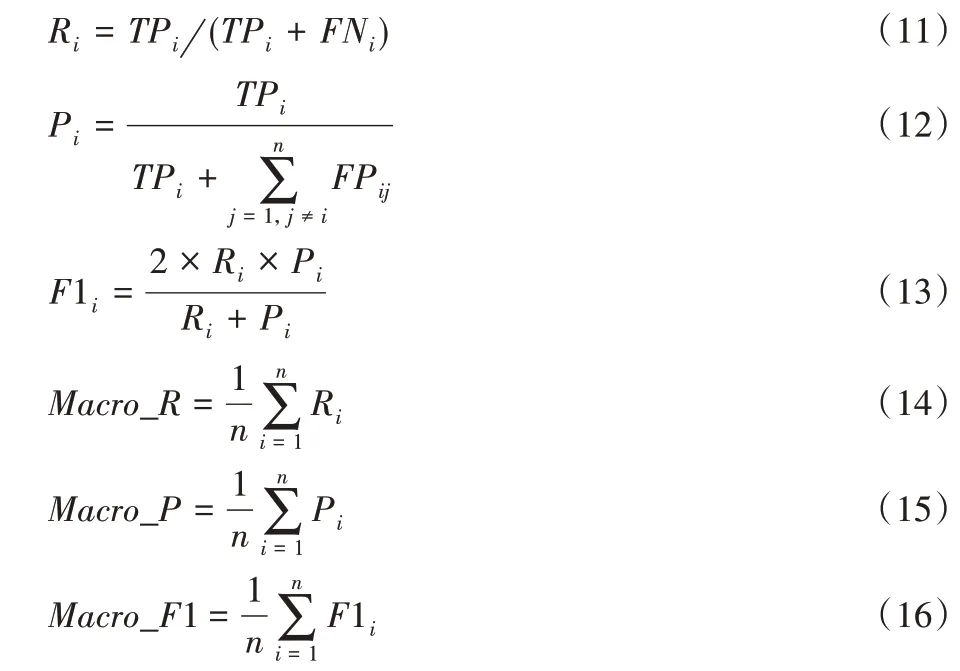
其中:TPi表示標(biāo)注結(jié)果為第i領(lǐng)域且結(jié)果正確的論文摘要數(shù)目;FNi表示將第i類(lèi)領(lǐng)域錯(cuò)誤標(biāo)注成其他領(lǐng)域的論文摘要數(shù)目;FPij表示將第j類(lèi)論文領(lǐng)域錯(cuò)誤標(biāo)注成i類(lèi)的論文摘要數(shù)目。
3 實(shí)驗(yàn)與結(jié)果分析
3.1 實(shí)驗(yàn)數(shù)據(jù)
實(shí)驗(yàn)數(shù)據(jù)來(lái)自近三年計(jì)算機(jī)視覺(jué)方面的三大頂級(jí)國(guó)際會(huì)議:國(guó)際計(jì)算機(jī)視覺(jué)大會(huì)(IEEE International Conference on Computer Vision,ICCV)、IEEE 國(guó)際計(jì)算機(jī)視覺(jué)與模式識(shí)別會(huì)議(IEEE Conference on Computer Vision and Pattern Recognition,CVPR)和歐洲計(jì)算機(jī)視覺(jué)國(guó)際會(huì)議(European Conference on Computer Vision,ECCV),共收集了72 篇論文。其中,目標(biāo)檢測(cè)14 篇,目標(biāo)跟蹤11 篇,超分辨率14 篇,圖片生成11篇,3D建模10篇以及人體姿態(tài)相關(guān)12篇。
3.2 實(shí)驗(yàn)設(shè)計(jì)
首先,對(duì)模型輸入進(jìn)行分句、分詞和依存分析,然后得到實(shí)驗(yàn)所需的單詞集合以及依存分析樹(shù),接著通過(guò)2.2.2 節(jié)中的八個(gè)提取模型對(duì)輸入模型進(jìn)行關(guān)鍵詞的提取,最終根據(jù)2.2.3節(jié)的流程得到輸入模型的應(yīng)用領(lǐng)域判別結(jié)果。
以圖11 為例,在輸入模型之后,得到了模型提取的關(guān)鍵詞、模型領(lǐng)域向量以及模型領(lǐng)域判別結(jié)果,該模型應(yīng)用領(lǐng)域判別結(jié)果顯示:最匹配的領(lǐng)域?yàn)槿梭w姿態(tài)相關(guān),隨后依次是3D建模相關(guān)和目標(biāo)檢測(cè),由于與另外三類(lèi)相似度為0(根據(jù)模型領(lǐng)域向量在這三個(gè)領(lǐng)域值都為0 可以看出),所以這里只輸出三個(gè)匹配結(jié)果。

圖11 實(shí)驗(yàn)示例Fig.11 Experimental example
3.3 實(shí)驗(yàn)結(jié)果及分析
文本實(shí)驗(yàn)設(shè)計(jì)基于以下兩個(gè)方面進(jìn)行比較和驗(yàn)證提出的自動(dòng)標(biāo)注系統(tǒng)的優(yōu)越性和有效性:1)對(duì)于相同的語(yǔ)料庫(kù)和驗(yàn)證集,采用不用的傳統(tǒng)機(jī)器學(xué)習(xí)算法進(jìn)行分類(lèi),比較并驗(yàn)證本文提出的自動(dòng)標(biāo)注系統(tǒng)的優(yōu)越性;2)對(duì)比系統(tǒng)分析出的top1和top2的正確率來(lái)判斷自動(dòng)標(biāo)注系統(tǒng)的有效性。
1)實(shí)驗(yàn)1。
此次實(shí)驗(yàn)直接將自動(dòng)標(biāo)注系統(tǒng)輸出的top1作為最終預(yù)測(cè)的結(jié)果,并和貝葉斯、Logistics回歸、SVM和決策樹(shù)方法進(jìn)行文本分類(lèi)比較。其中貝葉斯采用多項(xiàng)式分布樸素貝葉斯方法,SVM 采用LinearSVC(Linear Support Vector Classification)。評(píng)估標(biāo)準(zhǔn)根據(jù)2.2.4節(jié)中所定義,實(shí)驗(yàn)結(jié)果如圖12和表3所示。
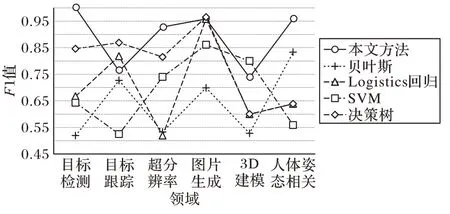
圖12 實(shí)驗(yàn)1中不同方法的F1值對(duì)比Fig.12 F1 value comparison of different methods for experiment 1
通過(guò)圖12 和表3 可以看出,雖然本文方法在目標(biāo)跟蹤和3D 建模上的F1 值不是最高的,但是在其他幾種領(lǐng)域上都是最高且F1 值達(dá)到0.9 以上,尤其在目標(biāo)檢測(cè)上達(dá)到1,并且在Macro_R、Macro_P和Macro_F1 平均達(dá)到0.89,均遠(yuǎn)遠(yuǎn)高于其他4種方法,說(shuō)明獲得了較好的分類(lèi)效果。
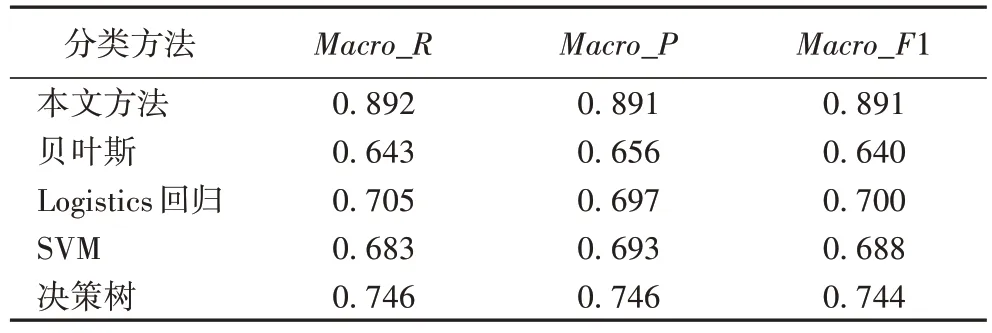
表3 五種方法的宏平均對(duì)比Tab.3 Macro average comparison of five methods
2)實(shí)驗(yàn)2。
為了深入了解模型自動(dòng)標(biāo)注的效果,本實(shí)驗(yàn)對(duì)模型領(lǐng)域預(yù)測(cè)中相似度最高的前兩名計(jì)算了正確率,也就是對(duì)應(yīng)自動(dòng)標(biāo)注系統(tǒng)輸出結(jié)果的top1 和top2 的總正確率,結(jié)果如圖13所示。
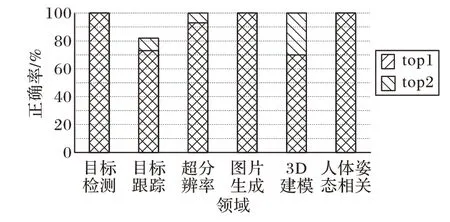
圖13 實(shí)驗(yàn)2中top1和top2的正確率Fig.13 Accuracies of top1 and top2 for experiment 2
單看top1的正確率,目標(biāo)檢測(cè)、圖片生成以及人體姿態(tài)相關(guān)都能達(dá)到100%,而超分辨率和目標(biāo)跟蹤次之,分別為93%和73%,3D 建模最低為70%。當(dāng)引入了top2 的正確率后,可以明顯看出,除了目標(biāo)跟蹤為82%的正確率,其他五個(gè)領(lǐng)域都能達(dá)到100%的正確率,說(shuō)明該自動(dòng)標(biāo)注系統(tǒng)基本能實(shí)現(xiàn)對(duì)輸入模型的準(zhǔn)確判定。開(kāi)發(fā)人員在使用這套系統(tǒng)的時(shí)候,直接通過(guò)輸出的top1 和top2 的結(jié)果,基本就可以快速判斷該模型是否是自己所需要的模型。
綜合以上實(shí)驗(yàn)可以看出,本文的方法在評(píng)估標(biāo)準(zhǔn)上取得了很好的結(jié)果,各方面均優(yōu)于其他的傳統(tǒng)機(jī)器學(xué)習(xí)算法,證明了本文方法的有效性和優(yōu)越性。
4 結(jié)語(yǔ)
本文針對(duì)開(kāi)發(fā)人員難以從眾多復(fù)雜的模型中選擇自己所需要模型的問(wèn)題,提出了對(duì)視覺(jué)類(lèi)深度神經(jīng)網(wǎng)絡(luò)的模型進(jìn)行自動(dòng)標(biāo)注的系統(tǒng),建立了能夠抽取關(guān)鍵詞的八種模型,并基于這些模型對(duì)模型進(jìn)行自動(dòng)標(biāo)注。實(shí)驗(yàn)結(jié)果表明,該方法相較于其他傳統(tǒng)機(jī)器學(xué)習(xí)算法能夠得到較高的宏平均。下一步,將把該自動(dòng)標(biāo)注系統(tǒng)應(yīng)用于對(duì)模型的推薦系統(tǒng)之中,使得開(kāi)發(fā)人員能夠更好地獲取自己需要的相關(guān)模型。
猜你喜歡
童話王國(guó)·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
網(wǎng)絡(luò)安全與數(shù)據(jù)管理(2022年1期)2022-08-29 03:15:20
導(dǎo)航定位學(xué)報(bào)(2022年4期)2022-08-15 08:27:00
中學(xué)生數(shù)理化·中考版(2022年8期)2022-06-14 06:55:24
新世紀(jì)智能(數(shù)學(xué)備考)(2021年9期)2021-11-24 01:14:36
成都醫(yī)學(xué)院學(xué)報(bào)(2021年2期)2021-07-19 08:35:14
新世紀(jì)智能(數(shù)學(xué)備考)(2020年9期)2021-01-04 00:25:14
中學(xué)生數(shù)理化·七年級(jí)數(shù)學(xué)人教版(2020年10期)2020-11-26 08:24:50
數(shù)學(xué)物理學(xué)報(bào)(2020年2期)2020-06-02 11:29:24
光學(xué)精密工程(2016年6期)2016-11-07 09:07:19
