基于時間序列的DNA 特征分析
2020-06-22 03:52:20王楚雯方寶琦
科學技術創新 2020年12期
王楚雯 方寶琦 許 瑤
(大連民族大學理學院,遼寧 大連116600)
1 概述
生物學的相關信息量革命性的爆炸,產生了對海量生物信息進行處理的需求,而計算機技術的革命性發展,形成了處理海量生物信息的能力。生物信息學是從大量生物信息中提取生物學知識的學科,其研究了DNA、RNA 和蛋白質分子,這些大分子包含了所有物種遺傳及其進化的信息。如何在DNA 中探索更多的生物信息是有難度的,堿基在基因庫中的增長是迅速的,利用線粒體DNA 進行分析是最有效、最快速的方法,線粒體DNA 是在生物系統研究中應用最為廣泛的遺傳物質之一。線粒體DNA 較核DNA 進化速率快,并在遺傳過程不發生基因重組、倒位、易變等突變,嚴格遵守母系遺傳方式的特點。在此本文對線粒體中攜帶的mtDNA 的一般屬性進行分析,隨機選取30 個哺乳動物的線粒體DNA 序列,利用短記憶ARIMA 模型進行建模,探究不同物種間的系統關系及特征。
2 模型介紹
短記憶ARIMA 模型:
具有如下結構的模型稱為求和自回歸移動平均模型,簡稱為ARIMA(p,d,q)模型:
其中,非負整數d 為求和階數,Φ(B)=1-φ1B-…-φpBp,為平穩可逆ARMA(p,q) 模型的自回歸系數多項式;Θ(B)=1-θ1B-…-θqBq為平穩可逆ARMA 模型的移動平均系數多項式。
d 階差分算子:
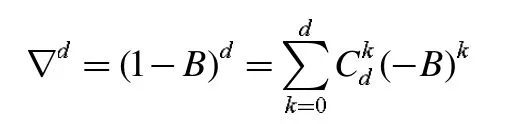
顯然,ARIMA 模型實質就是差分運算與ARMA 模型的組合,說明只要任意序列只要通過適當階數的差分實現差分后平穩,就可以對差分序列進行ARMA 模型擬合了。
ARIMA 模型建模的基本步驟為:①判斷觀察值序列的平穩性。②對原序列進行一階差分運算。對序列進行平穩性檢驗、白噪聲檢驗、殘差序列檢驗、模型預測。如果序列非平穩則重新建立模型。
3 線粒體DNA 的研究分析
隨機抽取30 個哺乳動物的線粒體DNA,對于線粒體DNA攜帶的mtDNA 序列進行研究。首先對選取的數據進行初步處理:抽取mtDNA 序列中第四個位置的堿基為研究對象,將DNA中的四種核苷酸A、T、C、G,分別用編號為1,2,3,4 進行堿基的替換,將DNA 字符串轉換為數值型變量,即DNA 序列時序化。對30 個哺乳動物中的人類、馬、長須鯨、大猩猩、猩猩五種線粒體DNA 攜帶的mtDNA,建立短記憶ARIMA 模型進行DNA 序列的擬合。下面以人為例。
3.1 mtDNA 序列的平穩性及隨機性檢驗
對human 的mtDNA 序列時序化后的時間序列,進行繪制時序圖觀察序列的平穩性,如圖1 所示,70 個數據的時序圖上下波動較大,波動范圍有界,但波動有明顯趨勢性而無周期性,可知為非平穩序列。再對其進行1 階差分,可看到圖二為human 的一階差分時序圖,可看出有平穩性;如圖3,4 所示的是human 的mtDNA 序列的自相關圖和偏自相關圖,可以看出的是差分后的時序圖上下波動,但自相關系數、偏自相關系數始終非零,均具有拖尾性。DNA 序列的純隨機檢驗p 值在延遲6 階和12 階后分別為7.543e-06,3.01e-08,均小于顯著性水平0.05,故拒絕原假設,認為差分后的human 的DNA 序列為平穩非白噪聲序列。

圖1 人的時序圖

圖2 人的一階差分的時序圖

圖3 一階差分自相關圖
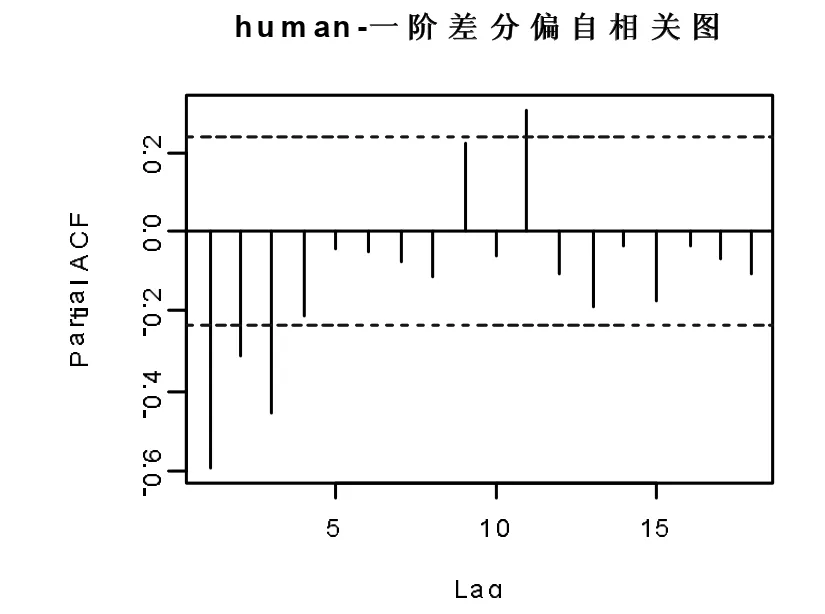
圖4 一階差分偏自相關圖
3.2 模型識別及檢驗
對于平穩非白噪聲序列的人的mtDNA 序列,進行短記憶ARIMA(p,d,q)模型的識別,其中d=1,由1 階差分序列的時序圖、自相關圖和偏自相關圖都表明,差分后的數據具有平穩性,且能看出的是自相關系數在延遲1 階后都具有拖尾性,故我們首先初步確定ARTMA(1,1,1)模型來擬合mtDNA 的時間序列,擬合的模型結果為:
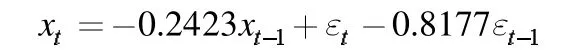
其中aic 值為210.95,再對殘差序列做白噪聲檢驗,白噪聲檢驗結果表明, 延遲 6 階和 12 階的p 值分別為0.4465,0.09382,其值均大于0.05,因此模型成立,即ARIMA(1,1,1)模型擬合成功,但并不是最優模型,重新建立ARIMA(3,1,1)模型,得到擬合模型為:

其中aic 值為209.73<210.95,再做殘差序列的白噪聲檢驗,其結果表明,延遲延遲6 階和12 階的p 值分別為0.9999,0.1856,其值均大于0.05,因此模型成立,通過aic 值可以看出,ARIMA(3,1,1)模型為最優模型。
3.3 其他物種DNA 的數據分析
對于我們隨機選取的其他4 個物種線粒體DNA 攜帶的mtDNA 進行同樣的模型建立,看是ARIMA 模型是否同樣能夠適用并且高度擬合,其他的4 個物種分別是馬、長須鯨、大猩猩、猩猩,對于這四個物種的mtDNA 序列時序化后的時間序列,進行模型識別、參數估計、模型檢驗。首先同樣先用ARIMA(1,1,1)模型來擬合其他四個物種的mtDNA 的時間序列,再建立ARIMA(3,1,1)模型來逼近ARIMA(1,1,1)模型,可以得到是ARIMA(3,1,1)模型依舊是最優模型,其模型擬合結果為表1。其中模型殘差檢驗在延遲6 階和12 階的p 值均大于顯著水平0.05,即模型擬合成功,說明利用短記憶ARIMA 模型進行建模,可以探究不同物種間的系統關系及mtDNA 序列特征。

表1 4 條不同物種mtDNA 序列ARIMA 模型

表2 5 條不同物種mtDNA 序列預測值與真實值對比表
3.4 模型預測
對于上述5 個擬合成功的ARIMA(p,d,q)模型,我們對其mtDNA 序列的后五個堿基(71-75)進行預測,來驗證短記憶ARIMA(p,d,q)模型是否對線粒體DNA 攜帶的mtDNA 具有有效性。對于模型的預測值我們將其與真實值進行比對,來檢驗ARIMA 模型是否高度擬合。下表為五個物種mtDNA 的預測值與真實值對比表。可以見得五個物種的mtDNA 序列的平均誤差分別是(見表2)。
4 結果分析
本文通過運用短記憶ARIMA 模型,能清楚看到對于物種之間線粒體DNA 攜帶mtDNA 的特征,結構以及之間的物種聯系。
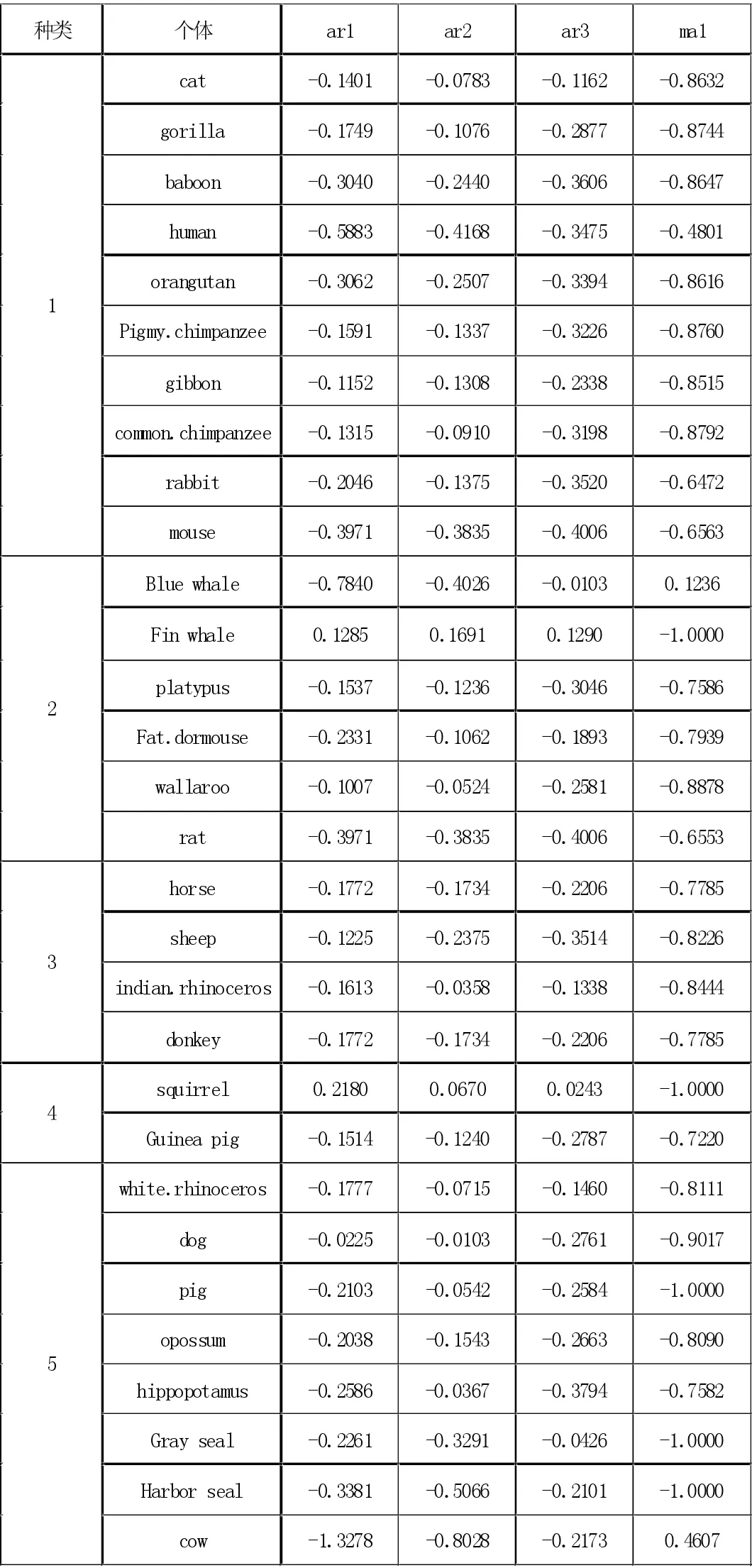
表3 30 個物種mtDNA - ARIMA 模型表
對于30 個物種的mtDNA 再次進行建模分析之間是否有親屬關系以及物種間的相似度,下表為30 條mtdna 根據模型ARIMA 擬合所得參數結果。從表中我們得出30 個線粒體DNA大致分為五大類:
①貓、大猩猩、狒狒、人、猩猩、小黑猩猩、長臂猿、普通黑猩猩、兔子、老鼠、藍鯨、長須鯨、睡鼠、鴨嘴獸、大袋鼠、鼠;其中大猩猩、狒狒、人類、猩猩、小黑猩猩、長臂猿、普通黑猩猩是有共同特性的。根據生物學知識,人和猩猩的基因差異只有0.75%,按照生物的形態結構、功能以及親緣關系,它們都被分屬于動物界脊椎動物門哺乳綱靈長目類。對于其他物種因為我們所選取的是DNA 片段并不全面,會有片面的判斷,因而會造成錯誤分類,出現誤差。
②馬、羊、印度犀牛、驢;其中除了羊、馬、印度犀牛以及驢都屬于動物界脊椎動物門哺乳綱奇蹄目類。
③豚鼠、松鼠;其中豚鼠、松鼠都被分屬于動物界脊椎動物門哺乳綱嚙齒目類。
④白犀牛、狗、豬、負鼠、河馬、灰海豹、斑海豚、牛。第四類沒有顯著特性,這8 個物種也不具備相似的親緣關系。
從上述結果分析來看,30 個物種都可以用ARIMA(p,d,q)模型進行有效合理的擬合,不排除個別個體的差異性,擬合結果都較好,則表明模型建立的合理,如此一來,我們可以利用此模型更準確地估計隨機時序發展變化的規律并且對其進行研究,利于我們生物學進行根深一步的發展和探索。
對于物種之間DNA 的檢驗不僅僅只局限于線粒體DNA 的研究,也不僅僅局限于這30 個物種,生物信息學所含括的還有很多,都可以運用時間序列建立模型進行探索。物種間的遺傳和進化還存在于RNA,蛋白質等大分子中,同樣可以利用短記憶模型。本文基于時間序列對DNA 特性的分析,其結果是DNA分子具有短記憶性,在物種間的聯系可將生物圈分為不同類別。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
英語世界(2023年10期)2023-11-17 09:18:18
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
科學大眾(中學)(2019年3期)2019-05-17 10:04:30
汽車觀察(2018年10期)2018-11-06 07:05:26
作文周刊·小學一年級版(2016年27期)2017-06-03 23:21:17
光學精密工程(2016年6期)2016-11-07 09:07:19
新湘評論·下半月(2016年4期)2016-05-05 22:12:41
新湘評論·下半月(2016年4期)2016-05-05 22:12:41
