基于全卷積神經網絡的左心室圖像分割方法
2020-06-22 13:15:56謝文鑫苑金輝胡曉飛
軟件導刊 2020年5期
謝文鑫 苑金輝 胡曉飛
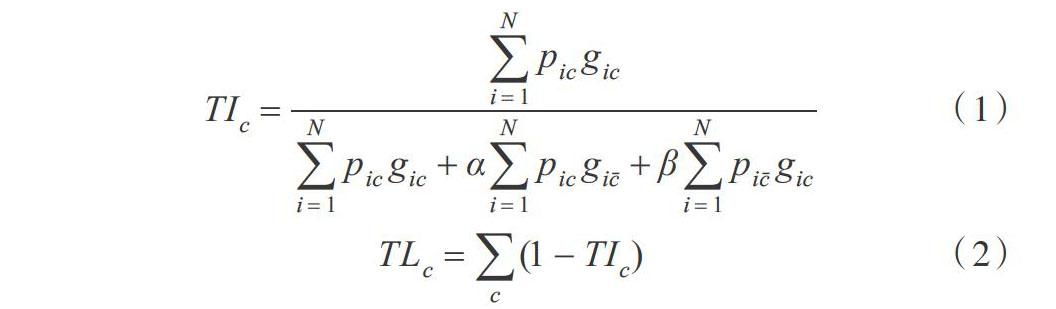
摘 要:針對左心室在心臟圖像中面積較小,且存在樣本數量不平衡等問題,將一種基于Tversky系數的損失函數應用于心臟左心室分割模型訓練。在分割模型中加入注意力模塊,當低層特征向高層特征傳遞圖像語義信息時,抑制低層特征圖中與分割目標不相關區域,減少這些區域對分割結果的干擾。將以上兩種方法結合應用到多輸入多輸出的全卷積神經網絡中,獲得心臟左心室圖像分割結果。實驗結果表明,改進后的算法在原有基礎上Dice系數提高了3.3%,召回率提高了4.8%。
關鍵詞:全卷積神經網絡;圖像分割;損失函數;全卷積神經網絡
DOI:10. 11907/rjdk. 192069 開放科學(資源服務)標識碼(OSID):
中圖分類號:TP301文獻標識碼:A 文章編號:1672-7800(2020)005-0019-04
0 引言
心血管疾病是人類死亡的主要原因,平均每年有1 730萬人因患心血管疾病死亡,預計到2030年這一數字將增加到2 360萬人以上[1]。而在中國,心血管疾病負擔日漸加重,已成為重大的公共衛生問題[2]。其中,冠心病主要涉及心臟左心室區域,通過左心室分割圖像估計左心室功能參數將有助于醫生診斷病情。由于醫生手工分割左心室需要耗費大量人力和精力,利用算法自動分割左心室區域將大大提高醫生工作效率。
值得注意的是,左心室分割算法面臨一系列挑戰[3-5]。例如,在采集過程中引起的偽像和光照變化、不同患者的左心室在形狀和外觀方面存在差異等都會影響圖像分割。更重要的是,左心室在心臟圖像中所占區域比例很小,非左心室區域對左心室分割也造成了很大影響。而傳統基于圖割的方法[6-7]、基于水平集的方法[8-9]、基于概率模型的方法[10]往往分割準確率不高或需要人工干預,難以應用于實踐。
近年來,深度學習已經在計算機視覺、自然語言處理等領域迅速發展,有學者[11-12]將深度學習方法應用于心臟左心室分割方法相關研究中。齊林等[13]將遷移學習應用于全卷積神經網絡模型訓練,利用已在自然圖像中訓練好的模型,對模型中的參數進行微調,取得了較好的左心室內膜分割結果;Avendi等[14]利用卷積神經網絡從心臟圖像中定位出心臟左心室區域,然后利用棧式自編碼算法模型勾勒出左心室初始形狀,在此基礎上,經過可變模型分割出最終結果;Alexandre等[15]對上述分割方法進行了更加深入的研究與探討,試圖通過調節CNN中的參數獲得更好的分割效果。實驗表明,在其它方法不變的情況下,更深的網絡結構可在一定程度上改善分割效果。雖然上述模型對心臟左心室的分割都表現出較好性能,但仍然存在以下兩個問題:①額外使用模型對分目標進行感興趣區域提取,增加了計算復雜度,也造成計算資源浪費;②由于分割目標較小,沒有采用有效的算法解決分割圖像中樣本不平衡問題。本文在心臟左心室分割模型中引入注意力模塊,注意力模塊將抑制與分割目標不相關區域,達到感興趣區域提取效果。同時,引入一種基于Tversky系數的損失函數,解決左心室目標區域太小時樣本不平衡問題。
1 算法理論
1.1 基于Tversky 系數的損失函數
由于在整個心臟圖像中,左心室面積占比很小,而圖像分割的任務就是對圖像中的每個像素點進行分類,目標區域和背景區域面積差別過大,將導致目標分割更加困難。Salehi等[16]提出基于Tversky系數的損失函數,通過調節損失函數中假負類和假正類的權重參數,解決小目標圖像分割任務中樣本不平衡問題。基于Tversky 系數的損失函數如式(1)所示。
其中,TIc(Tversky Index)代表分割結果與標準分割圖像之間的Tversky系數,范圍為0~1。TIc的值越接近1,表示分割結果和標準分割圖像之間相似度越高;相反,越接近0則表示相似度越低。其中,pic代表像素點i預測為c類的概率,gic代表標準分割圖像中像素i對應的值。在本文二分類問題中,gic只有兩種取值,0或者1。0表示該像素點為背景,1代表該像素點為目標。[pic]表示像素點i不屬于c類的概率,[gic]表示在標準分割圖像中像素i對應1-gic的值,N代表一張圖像中像素點的總個數。α和β為權重參數,α+β=1。式(2)為本文采用的基于Tversky系數的損失函數,通過計算式(1)中的Tversky 系數,從而得到網絡分割結果與標準分割圖像的損失值。
在分類問題中,將實例分為正例和負例兩部分,將正例預測成為正例,稱之為真正類(TP,True Positive),將負例預測成為正例,稱為假正類(FP,False Positive)。與此相反,將負例預測為負例,稱之為真負類(TN,Ture Negitave),將正例預測為負例,稱之為假負類(FN,False Negative)。
α和β設置為0.5時,Tversky 系數和Dice系數相等,此時假正類和假負類在相等數量上對損失函數的貢獻相同,而在左心室分割任務中,左心室區域的像素點數量明顯小于非左心室區域的像素點數量。相同的權重參數將無法解決分割圖像中樣本不平衡問題。設置更大的β值將使預測結果中假負類相比于假正類對損失值貢獻更大,使分割結果傾向于假負類較少的結果,從而提升召回率。同樣,如果設置更大的α值,分割結果將會傾向于假正類較少的結果,從而提升精確度。
1.2 注意力模型
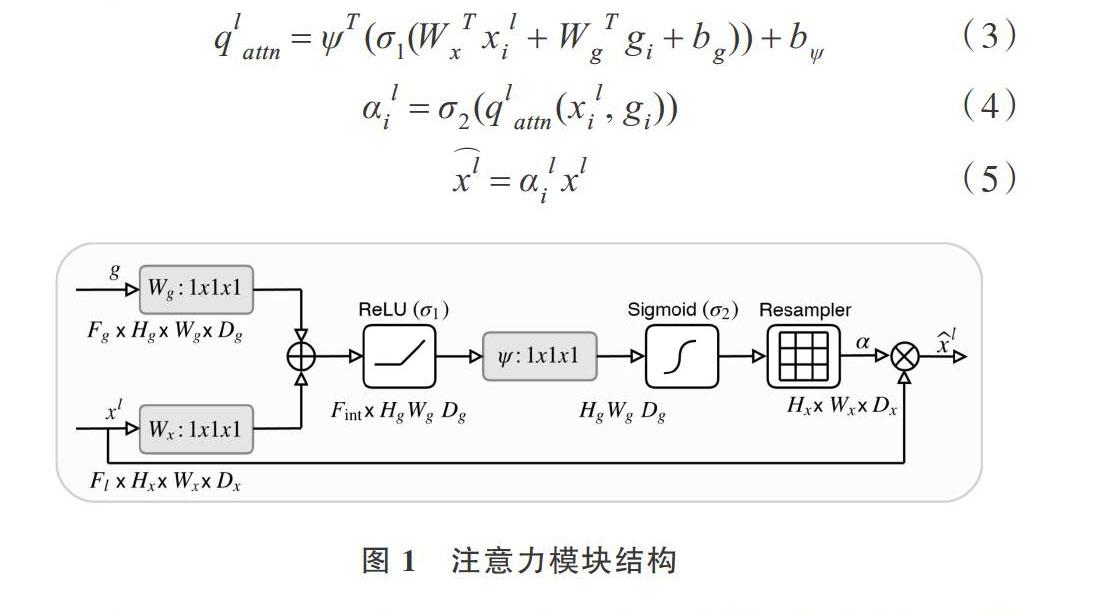
傳統U-net模型在特征圖擴張路徑和特征圖收縮路徑之間引入了跳躍連接,使得在特征圖反卷積過程中擁有了更加豐富的語義信息。但是將低層特征圖信息毫無保留地傳遞給高層特征圖,其中存在著信息冗余,將分割目標不相關區域傳遞給擴張網絡將會影響輸出結果的準確性。Oktay等[17]提出在跳躍連接過程中加入注意力模塊,能夠抑制與分割目標不相關區域,減少冗余信息。注意力模塊定義為:
如圖1所示,兩個輸入xl和gi分別代表本層的特征圖輸入與高層次上下文信息提供的門信號,分別經過1×1的卷積操作后,將特征圖相加,經過Relu激活函數激活得到新值后,再依次進行1×1卷積,通過Sigmoid函數激活、上采樣,得到每個像素點中取值范圍0~1的加權值[αil]。具體計算過程見式(3)和式(4),Wx、Wg、ψ代表線性轉換參數,[bg]和[bψ]代表偏置值,[σ1]、[σ2]分別代表Relu激活函數和Sigmoid激活函數。在圖1中將得到的加權值與本層特征圖xl相應的像素點相乘后,得到最后輸出[xl]。[xl]與[xl]相比,對左心室不相關區域的抑制,使輸出層分割結果更加精確。
1.3 圖像分割全卷積神經網絡模型
1.3.1 全卷積神經網絡
Ronneberger等[18]提出了一種全卷積神經網絡U-net,該網絡分為收縮網絡和擴張網絡兩部分。收縮網絡中每層由2個3×3的卷積層和1個2×2的池化層組成,每次池化操作后,通道數都增加為原來的2倍。擴張網絡與收縮網絡每層相對應,形成一個U型網絡結構,擴張網絡每層包含2個3×3的卷積層以進一步提取特征、一個2×2的反卷積層對圖像進行上采樣。U-net在收縮網絡和擴張網絡之間加入了跳躍連接,可以對擴張網絡中反卷積后缺失的空間信息作一定補充。在U-net的輸出層,通過Softmax函數輸出與原始圖像大小相同的概率圖。
1.3.2 全卷積神經網絡改進
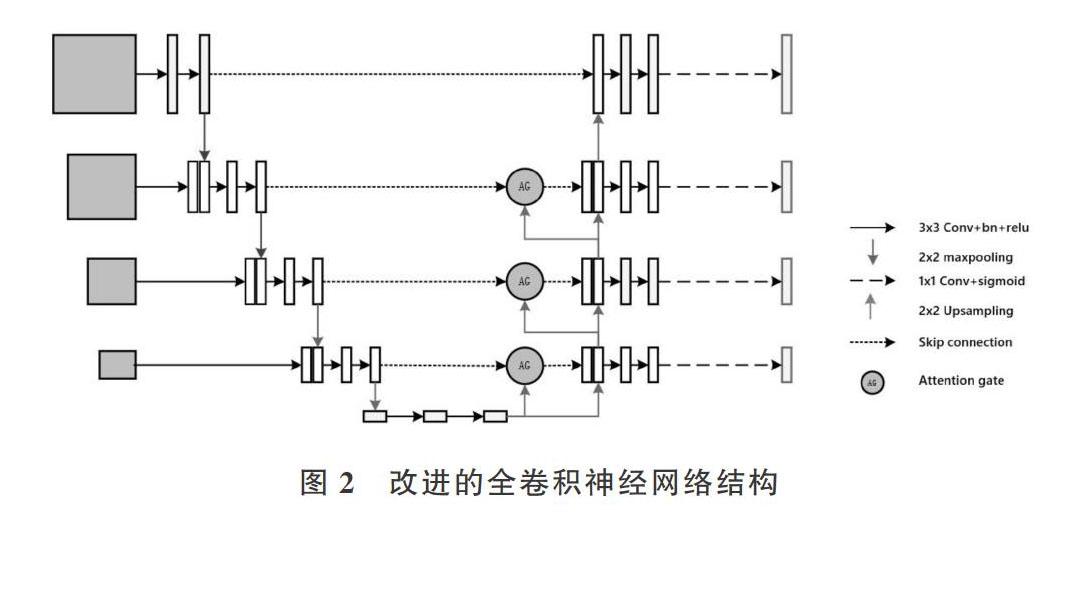
本文模型框架結構如圖2所示。與U-Net網絡類似,左側稱為特征圖收縮網絡,右側稱為特征圖擴張網絡。特征圖收縮網絡每層主要由2個3×3的卷積層和一個2×2的池化層組成。在Relu函數對卷積操作的結果進行激活前,先通過批量歸一化(Batch Normarion,BN)[19]對特征值作歸一化處理,從而加快網絡收斂速度,預防網絡過擬合。經過池化層后,特征圖的尺寸降為原來的1/2。圖2中,特征圖收縮網絡自上而下由第一層輸入原始尺寸圖像,第二到第四層輸入上一層1/2大小的圖像,并與上一層最大池化后的特征圖進行合并,減少由于池化操作造成的空間細節丟失。
特征圖擴張網絡的每層都與收縮網絡相對應。自下而上第一到第三層基本結構主要有來自注意力模塊(Attention Gate,AG)的輸出與上一層網絡輸出合并、兩個相同3×3的卷積、批量歸一化、Relu函數激活,最后經過1×1的卷積后采用Sigmoid激活函數輸出圖像分割概率圖。同時將合并的圖像特征上采樣后傳遞給下一層網絡。特征圖擴張網絡的第四層直接將特征圖收縮網絡的第一層輸出與特征圖擴張網絡的第三層上采樣結果合并后,經過兩個相同的3×3卷積、批量歸一化、Relu函數激活、1×1卷積后通過Sigmoid激活函數輸出圖像分割結果。
相比于原始U-net分割網絡,本文設計的網絡加入了多種尺度的輸入圖像,為特征圖收縮網絡的特征提取提供了更加豐富的空間細節,使得網絡能夠精準地分割出左心室的位置。右側的特征圖擴張網絡提供了不同尺度的標準分割圖像,監督網絡訓練結果。在跳躍連接中加入了注意力模塊,抑制了從收縮網絡傳遞過來的特征圖中與分割目標不相關區域,使得擴張網絡在預測分割結果時能夠較少地受到與分割目標不相關區域的影響,提高分割準確性。
2 實驗結果
2.1 實驗數據
圖像數據來自Sunnybrook[20]公共數據集。該數據集為心臟核磁共振圖像,圖像大小為256×256像素,在病人10~15s的呼吸過程中獲得。該數據集分為4組不同的形態:心力衰竭梗塞、心肌梗死、左心室肥厚和健康。該數據庫最初用于心臟左心室分割,數據分為3個部分:訓練集402張圖片、驗證集202張圖片和測試集201張圖片。實驗中的標準分割圖片由經驗豐富的心臟病專家繪制,對輸入進來的圖片通過計算輸入矩陣的均值和方差,對數據進行歸一化操作,提升訓練速度。
2.2 實驗環境與網絡參數
采用后端為Tensorflow的Keras深度學習框架在英偉達1060 6G的GPU上進行實驗。訓練中將SGD作為優化函數,動量設置為0.9,初始學習率為0.01,每當整個訓練集圖像完成一輪訓練后,學習率降低為原來的10-6。采用高斯分布方式設置神經網絡初始權重參數。損失函數采用基于Tversky 系數的損失函數,Tversky 系數的超參數α設置為0.3,β設置為0.7。
2.3 實驗結果與分析
測試集分割結果示例圖像如圖3所示,第一行為測試集中待分割的心臟MRI圖像,第二行為本文算法分割結果,最后一行為標準左心室分割圖像。將本文算法分割結果圖像與標準分割圖像對比可以看出,對于不同大小的左心室,本文算法能較為準確地從心臟MRI圖像中分割出左心室。
為了進一步定量評價本文算法性能,采用Dice系數(Dice Coefficient)、召回率(Recall)、精確率(Precision)3個指標對模型進行評價。實驗中分別將本文算法與其它3種算法進行比較:使用Dice Loss[21](DL)作為損失函數的U-net網絡,基于超參數α為0.3、β為 0.7 的Tversky Loss(TL)作為損失函數的U-net網絡,加入注意力模塊、損失函數實驗Dice Loss的Attn U-net網絡,結果如表1所示。
本文將U-net模型、損失函數采用基于Dice系數的損失函數作為比較基線。由表1可以看出,采用基于Tversky系數的損失函數代替基于Dice系數的損失函數方法與加入注意力模塊的方法在3個評價指標中均有所提高。而本文方法在結合上述方法優點的基礎上,加入了多尺度輸入圖像,同時采用多尺度的標準分割圖像對網絡預測結果進行監督。實驗表明,本文算法在4種算法中Dice系數和Recall值中均取得最高值。其中,相比基于Dice Loss作為損失函數的U-net網絡,Dice系數提高了3.3%,Recall值提高了4.8%,說明將注意力模塊和基于Tversky系數的損失函數加入心臟左心室圖像分割能夠顯著提升分割準確率。
