基于CHAID模型的現代人肥胖狀況及其成因分析
2020-06-23 02:20:54李銀劉麗芬盧利敏
高師理科學刊 2020年5期
關鍵詞:模型
李銀,劉麗芬,盧利敏
(韶關學院 1. 教育學部,2. 數學與統計學院,廣東 韶關 512005)
近年來,肥胖危機在我國迅速蔓延,已逐漸成為全球性的健康問題.肥胖人群是一類特殊的群體,肥胖是人體體內脂肪積聚過多導致的現象,不僅影響形體美,更重要的是肥胖人群比正常體質量人群更容易患病,如高血壓和糖尿病等[1-6].本文針對韶關市湞江區現代人的肥胖現狀,運用決策樹方法對韶關市湞江區人員的肥胖現狀及其成因進行分析,并利用多元Logistic回歸模型和主成分分析法對決策樹CHAID模型得出的結果進行檢驗,為相關決策者制定干預方案提供參考.
1 調查指標選取
世界衛生組織(WHO)一般用身體質量指數(BMI)來對肥胖或超重進行定義,用體質量(kg)數除以身高(m)平方得出的數字,是目前國際上常用的衡量人體胖瘦程度的一個標準.適合中國成年人的肥胖標準為:身體質量指數小于18.5為輕體重,大于等于18.5小于24為健康體重,大于等于24為超重,大于等于28為肥胖.身體質量指數按 B MI ≤ 18.5,18.5 ≤ BMI< 24,24 ≤ BMI< 28, B MI ≥ 28這4個等級水平依次賦值為1,2,3,4.本文在已有研究[7-10]的基礎上,得到調查問卷指標(見表1).

表1 調查問卷指標
2 數據的獲取與處理
通過問卷星進行網上發放問卷和現場發放現場回收的方式,收集韶關市湞江區居民肥胖狀況的相關數據,回收有效問卷196份.問卷采用國際通用的Likert五等級評分法,從“沒有”到“總是”按程度不同分為5個選項,依次賦1~5分.正向條目評分與原始分相同,反向條目評分等于6減原始評分.性別與職業因素、年齡因素、代謝因素、睡眠因素、遺傳因素、心理因素、運動因素和飲食習慣8個一級指標的得分之和為總分,得分越高對應的肥胖狀況應該越嚴重.
將原始得分換算為轉換分數,計算公式為

性別與職業因素理論最高得分為12,理論最低得分為3,因此性別與職業因素的轉化分數為

3 肥胖現狀及其成因分析的決策樹CHAID模型[1]
決策樹CHAID模型是利用卡方自動交互檢測法快速、有效地挖掘出主要的影響因素,它不僅可以處理非線性和高度相關的數據,而且可以將缺失值考慮在內,能克服傳統的參數檢驗方法在這些方面的限制.本文運用決策樹方法,建立CHAID模型.
利用性別與職業因素、年齡因素、代謝因素、睡眠因素、遺傳因素、心理因素、運動因素和飲食習慣共8個變量共同建立一個決策樹CHAID模型來預測肥胖狀態的影響因素.
根據建立的決策樹CHAID模型,運用SPSS軟件對模型進行求解,具體部分操作:選擇菜單分析——分類——決策樹,打開對話框,將相關變量選入到變量欄中,再進行相關操作,得到最終的自變量為性別與職業因素得分、運動得分和代謝得分.
決策樹模型見圖1.決策樹共分為2層,第1層判斷依據是性別與職業因素,第2層判斷依據是運動因素和代謝因素.

圖1 決策樹模型
進行模型風險評估,結果見表2.

表2 風險評估
由表2可以看出,風險評估值為0.388,表示該模型預測判別個案錯誤率為0.388,模型擬合效果較好.
決策樹CHAID模型的分類判別效果見表3(其中:1為輕體重,2為健康體重,3為肥胖/超重).

表3 分類預測效果
由表3可以看出,決策樹CHAID模型對大概61.2%的個體進行了正確的判別.由此看來,該模型是比較合理的.
綜合分析可知,影響肥胖狀況的首要因素是性別與職業,另外運動和代謝也是需要考慮的因素.
4 模型的檢驗
為了避免只采用決策樹CHAID模型方法得出的結論不具備較強的說服力,采用多元Logistic回歸模型和主成分分析法對決策樹CHAID模型進行檢驗.
4.1 多元Logistic回歸模型[1]
設身體質量指數 BMI的等級為y,性別與職業因素為x1,年齡因素為x2,運動因素為x3,遺傳因素為x4,心理因素為x5,睡眠因素為x6,代謝因素為x7,飲食習慣為x8.
建立現代人肥胖狀況影響因素的實證模型

其中:μ為隨機擾動項,反映無法觀察到的其它因素.
由于被解釋變量身體質量指數的選項有多個且有序,故采取多元Logistic回歸模型

其中:j為現代人肥胖程度的4個等級,j=1,2,3,4;μj為分界點;α為截距項;βi為偏回歸系數;為分類j及其以下類別的累積概率,即

采用SPSS進行多元Logistic回歸估計,得到初始模型,再根據似然比檢驗結果將不顯著的變量逐個剔除,直到模型中的變量全部都為較顯著的變量.
對多元Logistic回歸模型進行顯著性檢驗,結果見表4.

表4 模型擬合信息
由表4可以看出,顯著性水平的值明顯小于0.05,所以多元Logistic回歸模型是顯著的.
檢驗模型的偽2R,3種偽決定系數考克斯-斯奈爾系數、內戈爾科系數和麥克法登系數分別為0.481,0.570,0.353.
對多元Logistic回歸模型進行似然比檢驗,結果見表5.

表5 含8個自變量多元Logistic回歸模型的似然比檢驗
就顯著性水平來看,顯著性水平大于0.05的因素對肥胖狀態并沒有顯著的影響,因此可以剔除顯著性水平大于0.05的因素.根據表5,首先剔除最不顯著的飲食因素,再次建立回歸模型,以此類推,直至不存在不顯著變量,依次分別剔除了飲食因素、年齡因素、代謝因素和遺傳因素.
在依次剔除飲食因素、年齡因素、代謝因素和遺傳因素后,對只包含自變量性別與職業因素、運動因素、睡眠因素和心理因素的多元Logistic回歸模型進行似然比檢驗,結果見表6.
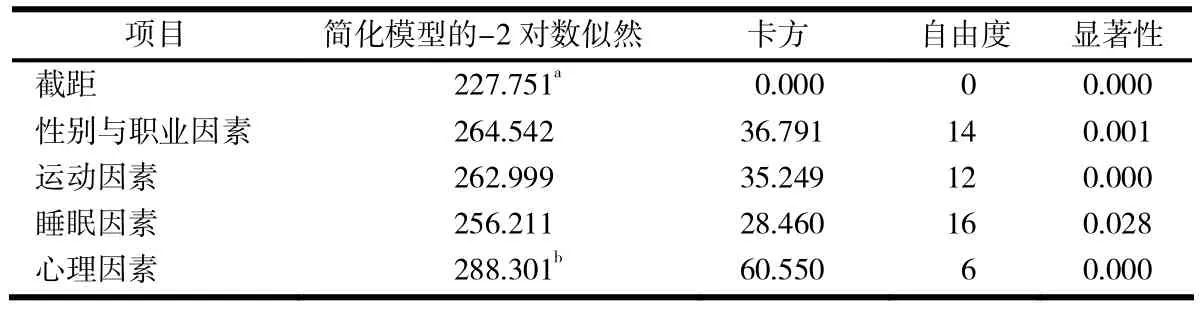
表6 含4個自變量多元Logistic回歸模型的似然比檢驗
由表6可以看出,所有變量的顯著性水平都小于0.05,因此有理由認為此時所有的變量對肥胖狀態都有顯著的影響.
綜合該模型分析可以認為,肥胖狀態的主要影響因素是性別與職業因素、運動因素、睡眠因素和心理因素.
4.2 主成分模型
主成分分析是采用一種數學降維的方法,設法將原來眾多具有一定相關性的變量,重新組合成一組新的相互無關的綜合變量代替原來的變量.利用降維的思想,把多指標轉化為少數幾個綜合指標(即主成分),其中每個主成分都能夠反映原始變量的大部分信息,且所含信息互不重復.主成分分析所需樣本數據較多,比較適合本文的研究.
主成分分析(PCA)方法的基本步驟為:
Step1對原始數據進行標準化處理,得到樣本觀測數據矩陣
Step2計算樣本相關系數矩陣
Step3計算相關系數矩陣R的特征值λ1,λ2,λ3,λ4,λ5,λ6,λ7,λ8和相應的特征向量.
Step4選擇重要的主成分,并寫出主成分的表達式.主成分個數的選取主要根據主成分的累計貢獻率來決定,一般要求累計貢獻率達到85%以上,這樣才能保證綜合變量能包括原始變量的絕大多數信息.
根據建立的主成分分析模型,運用Matlab軟件對模型進行求解.
運用Matlab軟件計算相關系數矩陣及相關系數陣的特征值,計算結果為

前7個特征值之和所占比例(累計貢獻率)達到92.88%,因此去掉第8個主成分.7個保留的特征值對應的7個特征向量分別為

因此取前7個主成分,分別為

對數據直接作線性回歸,得到經驗回歸方程
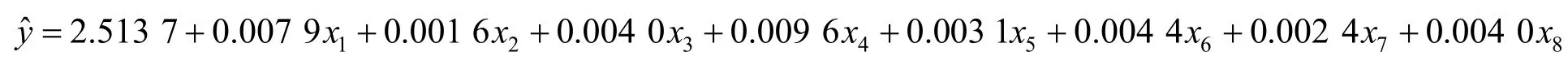
作主成分回歸分析,得到回歸方程

化為標準化變量的回歸方程為

綜合分析可以認為,影響肥胖狀況的首要因素是性別與職業因素,其次是運動因素和飲食因素.
通過主成分模型提示人們,如果平時壓力較大,不經常運動且飲食習慣較為不正常者,則肥胖的可能性較大.通過該模型,讓健康人群(非患病等特殊人群)中任一人填寫該問卷,可以預測該人的肥胖狀況,且準確率較高.
綜合分析結果,建議肥胖人群應該做到:(1)適當地增加運動.人體能量的消耗主要是通過基礎代謝、肌肉運動和食物的生熱效應進行的.正常情況下,人的基礎代謝較為穩定,肌肉運動是人體能量額外消耗的主要方式,通過運動可以達到減肥的效果.(2)多吃蔬菜水果和五谷雜糧,保持飲食均衡,這樣有利于促進新陳代謝.(3)保持愉快的心情,調整好心態,不要焦慮,適當地釋放壓力.
5 結束語
對于某一健康人群,通過該人的某些數據,利用本文模型可以預測該人的肥胖狀況并且準確率較高.且模型對于研究高校大學生亞健康狀況,現代人亞健康狀況及其成因分析,現代人肥胖狀況及其成因分析等都具有一定的借鑒作用和參考價值.
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
網絡安全與數據管理(2022年1期)2022-08-29 03:15:20
導航定位學報(2022年4期)2022-08-15 08:27:00
中學生數理化·中考版(2022年8期)2022-06-14 06:55:24
新世紀智能(數學備考)(2021年9期)2021-11-24 01:14:36
成都醫學院學報(2021年2期)2021-07-19 08:35:14
新世紀智能(數學備考)(2020年9期)2021-01-04 00:25:14
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
光學精密工程(2016年6期)2016-11-07 09:07:19
