點評網站中垃圾用戶識別研究
2020-07-04 02:13:18王亞
電腦知識與技術 2020年13期
王亞

摘要:點評網站作為一種新興的網絡交流平臺,目前存在著大量垃圾用戶,他們發布的虛假垃圾評論信息誤導了消費者的選擇,引起不正當的市場競爭。本文基于機器學習的分類方法,對點評網站的垃圾用戶進行研究,提出了基于用戶評論頻度的垃圾用戶檢測模型和基于用戶評論情感度的垃圾用戶檢測模型,并將模型融合進行模型訓練,以最大限度提高識別垃圾用戶的有效性。實驗表明,本文提出的方法對垃圾用戶識別的準確率最高可達70%。
關鍵詞:垃圾用戶;用戶評論頻度;用戶評論情感度;情感詞庫;邏輯回歸
中文分類號:TP311 文獻標識碼:A
文章編號:1009-3044(2020)13-0214-03
1引言
隨著信息技術、互聯網以及電子商務的發展,第三方點評網站融合購物、社區和點評為一體,如雨后春筍般涌現,成為一種新興的網絡交流平臺。在我國,其中就有一大批具有代表性的點評網站,比如:大眾點評網、淘寶口碑網、百度身邊、騰訊美食、豆瓣網、驢評網、愛幫網等。
點評網站為商家提供了一個發布商品、銷售商品的平臺,也為購買者提供了一個查看、了解、購買、評價商品的平臺。通過點評網站,購買者可以根據自己的消費體驗自由地對某商品或者出售該商品的商家以文字和打分的形式進行點評。而用戶的評論信息對消費者的購買決策具有重要影響。網絡點評已經成為消費者做消費決定的重要因素,用戶的點評對商家的發展至關重要。
在這種利益的推動下,當前在很多點評網站上的商家為了吸引更多的消費者,存在雇傭大量的網絡垃圾用戶購買虛假評論惡意抬高自己所售商品質量和商家名氣的現象。同時還有的購買虛假評論對競爭的商鋪進行惡意差評。這些惡意虛假評論嚴重干擾了市場的正常運行,危害了市場誠信。
目前在進行評論垃圾用戶的檢測中,普遍認為垃圾用戶發表的評論都是垃圾評論,而垃圾評論信息均是由垃圾用戶發布的。因而對垃圾用戶的識別主要聚焦于對垃圾評論的檢測上。對于垃圾評論的檢測研究,許多研究人員把目光聚集在評論的觀點挖掘上面,現有的工作也主要是利用自然語言處理技術和數據挖掘技術挖掘出評論是帶著積極的觀點還是消極的觀點。
Nitin Jindal和Bing Liu最早提出從評論可信度方面進行垃圾評論的研究,他們認為那些文本相似度很高的評論是垃圾評論,同時總結了24個特征用于建立分類模型,最后利用邏輯回歸方法來得到一個分類器,從而找出其他的垃圾評論。Chrysanthos Dellarocas等主要是從用戶評論行為的角度出發檢測垃圾用戶,認為垃圾用戶發表的所有評論都是垃圾評論,從而找出垃圾評。EePengLIM等建立了四種垃圾用戶檢測模型:基于目標產品的垃圾用戶檢測模型、基于目標產品組的垃圾用戶檢測模型、基于一般打分偏差的垃圾用戶檢測模型和基于有權重的打分偏差垃圾用戶檢測模型,從而得到四種垃圾指數。然后選取部分評論進行人工標注。最后,作者采用了線性回歸方法訓練得到一個分類模型,從而對其他的用戶進行分類。孫升蕓,田萱等是以同類別商品、同品牌商品和同賣家商品為基礎建立垃圾用戶檢測模型,方法與EePengLIM類似嘲。
豆瓣網是一個典型的點評網站,是中國最大與最權威的電影分享與評論社區,收錄了百萬條影片與影人的資料,因而本文擬針對點評網站以豆瓣網為例設計垃圾用戶檢測模型,通過對網站評論信息的分析,構建了基于用戶評論頻率的垃圾用戶檢測模型和針對評論文本情感度的垃圾用戶檢測模型,并基于機器學習的分類方法對這兩類模型分別進行垃圾用戶的識別和對融合模型進行垃圾用戶的檢測,以期提高垃圾用戶檢測的效率。
2點評網站一豆瓣網用戶特征提取
由于評論者中存在著很多的職業評論寫手,他們以專門發表垃圾評論作為生存主業或副業,因而在點評中將會頻繁的發布評論信息以混淆視聽。因而本文擬根據評論頻率,構建基于評論頻率的垃圾用戶檢測模型,檢測那些高頻發表評論的垃圾用戶。
垃圾評論通常是為了抬高或貶低某一商品或商家,經常帶有強烈感情色彩,因此本文擬構建基于情感程度的垃圾用戶檢測模型,即根據評論的情感程度判斷某一評論是否是垃圾評論,從而檢測那些發表過帶強烈情感色彩的垃圾用戶。
2.1用戶評論頻率特征
(1)影評時間特征
本文從垃圾用戶的目的性分析認為影響票房而形成輿論的最好時機是電影上映前期,尤其為了對一部電影進行惡意吹捧或惡意打壓,在電影上映后會注冊大量的垃圾用戶賬號,并及時地給予大量的評論來引導輿論傾向。
因而本文將用戶發表影評時間與用戶注冊賬號時間的時間差、以及電影上映時間與電影評論時間的時間差分別作為一個特征,本文建立一個特征值Tc-n。表示用戶發表評論時間與用戶注冊賬號時間的時間差,如果該用戶發表了多條電影評論,則Tc-u。為時間差的平均值。本文建立一個特征值Tc-c,表示用戶發表影評時間與電影上映時間的時間差,如果該用戶發表了多條電影評論,則Tc-r,為對時間差求平均所得的平均值,具體見公式(1)。
對于文本有效詞集合f‘(x)獲得其長度commentlengtll,以此表示文本長度特征。
(2)影評文本情感度
用戶在發表電影評論時總會帶有一定的感情色彩,會有或喜歡或討厭或覺得電影一般等情緒的表露,垃圾用戶一般是對電影進行惡意的貶低或故意抬高,為了對輿論造勢,影響用戶對電影的印象,其評論中往往含較多的情感詞匯,因而本文認為影評中的情感詞個數即影評文本的情感度可以反映用戶對電影的態度。
本文首先構建了自己的影評情感詞庫。即將所有影評中打分為0分和1分的影評文本抽取出來,然后抽取影評打分為4分和5分的影評文本,這兩類文本作為基礎文本,即為高分影評文本和低分影評文本,采用iieba分詞并采用前面所構建的停用詞庫去除兩類文本中的停用詞,得到一些離散的詞匯。采用卡方檢驗輸出計算這些離散的詞匯同兩類文本之間的關系,并按卡方值由大到小進行排序,然后結合人工識別從兩類文本中得到兩類情感詞匯,一類情感詞匯是贊揚電影的詞匯,總共包括93個詞匯,另一類情感詞匯是貶低電影的詞匯,總共包括135個詞匯,其部分情感詞匯如圖1所示。
基于此本文用電影評論中所包含的情感詞的個數作為用戶對電影評論情感激烈程度的一種判斷。本文提取特征commentemotion作為用戶影評中所包含的情感詞個數,如果用戶進行了多部電影的評論,則commentemotion為其多部影評中的情感詞個數的平均值,見公式(4)。
(3)影評文本內容特征
垃圾用戶的影評在一定程度上存在些相似陛,因而本文將用戶發表的評論文本亦作為一個用戶特征。具體實現方法是本文將每個用戶的影評寫入到同一文件中,然后用jieba分詞對句子進行處理,并通過構建中文停用詞庫去除停用詞。采用word2vec對用戶的所有影評進行embedding,最后得到embed-ding后的特征向量comment_w2v,用該特征向量作為用戶的一個特征參與訓練。
3實驗
本文提取了豆瓣網中的七部電影信息和用戶信息,結合用戶的基本信息、影評信息和用戶社交網信息,采用人工標注出垃圾用戶和普通用戶作為樣本。在實驗中,選取了相同數量的垃圾用戶和正常用戶采用五折交叉驗證的方式參與訓練。
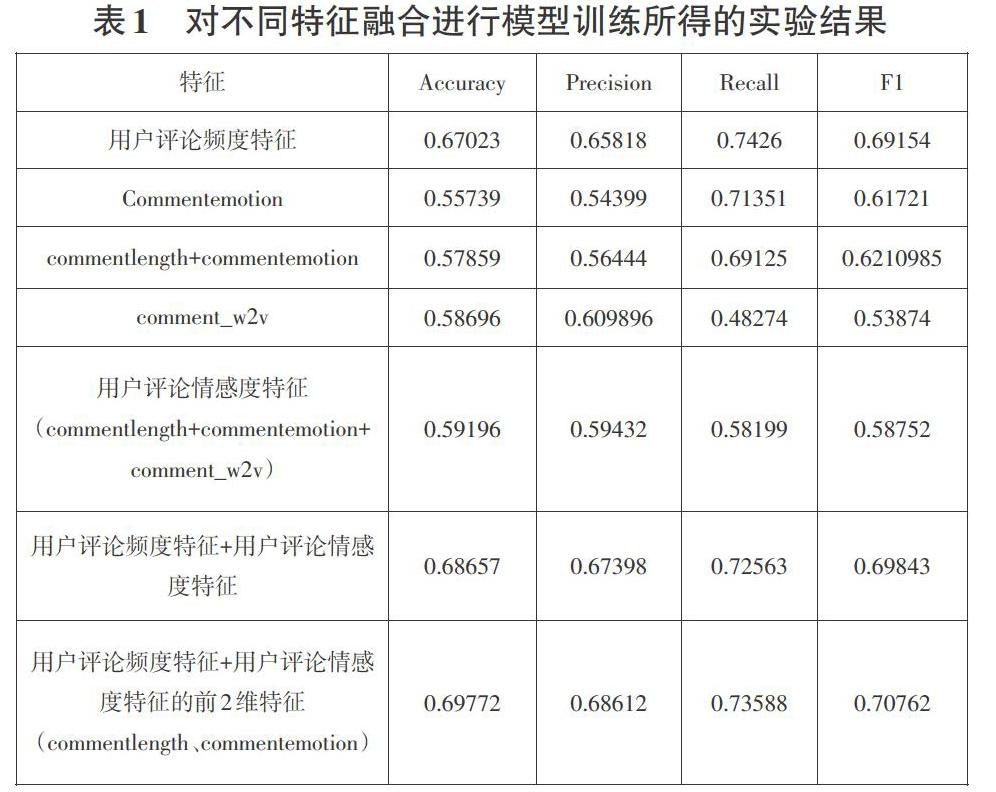
實驗根據提取的用戶特征,采用邏輯回歸的分類方法進行模型的訓練,回歸參數采用默認值,使用準確率、精確率、召回率、F1值這四種指標對模型進行評價。本文對不同的特征進行融合,然后進行模型的訓練,所得的實驗結果如表1所示:
實驗結果表明,單純地采用用戶評論頻度特征進行模型訓練,識別垃圾用戶的準確率為67%。用戶影評文本特征中,有效評論長度和評論情感度每個特征僅有1維,而評論文本內容長度用word2vec進行embedding后其特征為100維,為了保持維度的均衡,本文先將評論長度和評論情感度結合作為用戶的特征進行模型的訓練,其識別水軍的準確率為57.9%,這一結果要比單純只用評論情感度作為特征進行模型訓練效果要好一些。而單純用用戶評論文本詞向量作為用戶的特征進行模型的訓練效果并不太好,其準確率僅為55.7%,若將三者結合,模型的準確率可提高到59.2%。將本文所抽取的用戶評論頻度特征和用戶評論情感度特征融合進行模型的訓練,其準確率可達到68.7%,而除去用戶評論文本的100維特征,將其它所有特征融合進行模型的訓練,其準確率達到最高,將近70%,這說明了用戶文本內容詞向量特征在識別水軍用戶方面并不能算是一個很好的特征,其根本原因大概是水軍用戶的目的在于影響網絡輿情而非發布空內容,因此其影評文本依然圍繞電影展開,在文本中涉及“劇本”“畫面”“特效”“演技”等關鍵詞,就詞頻統計特征與電影密切程度與普通用戶相近,此類垃圾用戶為了改變網絡輿情,一般采用夸大優點與缺點方式。為了使輿論變化接受度更高,此類垃圾用戶會選擇普通用戶提出的觀點進行深人。
4結語
本文選取點評網站以豆瓣網為例對垃圾用戶進行識別研究,基于垃圾用戶的行為特征分析,提取了用戶評論頻度特征和用戶評論情感度特征,采用邏輯回歸分類方法,對以上特征分別進行模型訓練以及融合進行模型訓練,以提高模型預測垃圾用戶的準確率。實驗證明,本文將多種模型特征融合進行模型訓練,其對水軍識別的準確率最高可達到70%。
