計算語言學中的重要術語
2020-07-04 02:22:05陸曉蕾王凡柯
中國科技術語 2020年3期
陸曉蕾 王凡柯
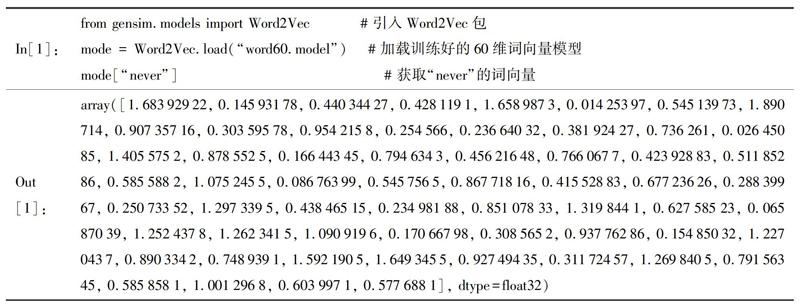
摘 要:過去幾年,自然語言處理(NLP)技術飛速發展,文本表征成了計算語言學的核心。其中,分布式詞向量表征在語義表達方面展現出巨大的潛力與應用效果。文章從語言學理論基礎出發,介紹了計算語言學的重要術語——詞向量。探討了詞向量的兩種表示方式:離散式與分布式;介紹了詞向量在語義變遷等歷時語言學領域的應用。在此基礎上,指出詞向量語義計算法存在的局限性,并總結了兩種詞義消歧方法:無監督與基于知識庫。最后,文章提出大規模知識庫與詞向量的結合可能是未來文本表征研究的重要方向之一。
關鍵詞:自然語言處理;文本表征;詞向量
中圖分類號:H083;TP391.1文獻標識碼:ADOI:10.3969/j.issn.1673-8578.2020.03.004
Abstract: This article focuses on the study of word embedding, a feature-learning technique in natural language processing that maps words or phrases to low-dimensional vectors. Beginning with the linguistic theories concerning contextual similarities — “distributional hypothesis” and “context of situation”, this article introduces two ways of numerical representation of text: one-hot and distributed representation. In addition, this article presents statistical-based language models (such as co-occurrence matrix and singular value decomposition) as well as neural network language models (NNLM, such as continuous bag-of-words and skip-gram). This article also analyzes how word embedding can be applied to the study of word-sense disambiguation and diachronic linguistics.
Keywords: natural language processing;text representation;word embedding
收稿日期:2020-01-02修回日期:2020-05-17
基金項目:教育部人文社科基金青年項目“‘一帶一路戰略下涉外法律機器翻譯云平臺的構建及應用研究”(18YJCZH117);福建省中青年教師教育科研項目“基于語料庫的法律英語教學云平臺的構建”(JZ180061);中央高校基本科研項目“基于語義模型的機器翻譯研究”(20720191053)
作者簡介:陸曉蕾(1988—),女,博士,廈門大學助理教授,主要研究方向為計算語言學。通信方式:luxiaolei@xmu.edu.cn。
引 言
隨著人工智能與大數據研究的興起,自然語言處理(natural language processing,NLP)作為一門集語言學、計算機科學于一體的跨學科研究,獲得了學術界和工業界的廣泛關注。自然語言處理的前提是文本表示(representation),即如何將人類符號化的文本轉換成計算機所能“理解”的表征形式。早期的自然語言表征主要采用離散表示。近年來,隨著深度學習的不斷發展,基于神經網絡的分布式詞向量技術在對海量語料進行算法訓練的基礎上,將符號化的句詞嵌入到低維的稠密向量空間中,在解析句法與分析語義等方面都顯示出強大的潛力與應用效果。
本文述介了詞向量的概念、訓練及應用,厘定了這一重要術語,以期為傳統語言學者了解計算語言學,使用詞向量進行相關研究提供參考。
一 詞向量概念:詞的表征
作為表達語義的基本單位之一,詞是自然語言處理的主要對象。詞向量的基本概念便是將人類符號化的詞進行數值或向量化表征。目前的詞表征方式主要有離散式和分布式兩種。
1.離散表示(one-hot representation)
傳統的基于規則的統計方法通常將詞用離散的方式表示。這種方法把每個詞表示為一個長向量①,這個向量的維度由詞表②大小確定,并且該向量中只有一個維度的值為1,其余維度的值都為0。例如,一個語料庫A中有三個文本,如下:
文本1: never trouble trouble until trouble troubles you.
文本2: trouble never sleeps.
文本3: trouble is a friend.
那么,該語料庫的詞表便由[never, trouble, until, you, sleep, is, a, friend]八個單詞組成。每個單詞可以分別表示成一個維度為八的向量,根據單詞在詞表中所處的位置來計算,具體如下:{“never”: [1 0 0 0 0 0 0 0]}、{“trouble”: [0 1 0 0 0 0 0 0]}、……、{“a”: [0 0 0 0 0 0 0 1 0]}、{“friend”: [0 0 0 0 0 0 0 0 1]}。可以發現,隨著語料庫的變大,詞表也隨之增大,每個詞維度也會不斷變大,每個詞都將成為被大量0所包圍的1。因此,這種稀疏的表示方式又被形象地稱為“獨熱表示”。離散表示相互獨立地表示每個詞,忽略了詞與詞在句子中的相關性,這與傳統統計語言學中的樸素貝葉斯假設③不謀而合。然而,越來越多的實踐表明,離散表示存在兩大缺陷。首先是“語義鴻溝”現象,由于獨熱表示假定詞的意義和語法是互相獨立的,這種獨立性顯然是不適合詞匯語義的比較運算,也不符合基本的語言學常識,因此,整篇文本中容易出現語義斷層現象。例如我們知道“端午節”與“粽子”是有聯系的——端午節通常應該吃粽子。但是這兩個詞對應的離散向量是正交的,其余弦相關度為0,表示兩者在相似度上沒有任何關系。其次是“維度災難”,隨著詞表規模的增加(視語料大小,一般會達到十萬以上),詞向量的維度也會隨之變大,向量中的0也會越來越多,這種維度的激增會使得數據過于稀疏,計算量陡增,并對計算機的硬件和運算能力提出更高的要求。
2.分布式表示(distributed representation)
為解決離散表示的兩大局限性,機器需要通過分布式表示來獲得低維度、具有語義表達能力的詞向量[1-2]。分布式詞向量表征的核心思路是通過大量的上下文語料與算法學習,使得計算機能夠自動構建上下文與目標詞之間的映射關系。其主要思想是詞與上下文信息可以單獨構成一個可行的語義向量,這種假設具有深刻的語言學理論根源。澤利格·哈里斯(Zellig S. Harris)提出分布假說(distributional hypothesis)[3],認為分布相似的詞,其語義也相似,這成為早期詞向量表征的理論淵源之一。倫敦學派奠基人弗斯(John Rupert Firth)繼承并發揚了人類學家布羅尼斯拉夫·馬林諾夫斯基(Bronislaw Malinowski)的“情景語境”(context of situation)理論,提出語境對詞義的重要作用[4],為詞向量的分布式表示與語義計算提供了思想基礎。在分布假說與情景理論的基礎上,詞向量通過神經網絡對上下文,以及上下文和目標詞之間的關系進行語言建模,自動抽取特征,從而表達相對復雜的語義關系并進行語義計算。
分布式表示一般有兩種方法:基于統計學和基于神經網絡(詳見后文)。早期,分布式詞向量的獲取主要通過統計學算法,包括共現矩陣、奇異值分解等。近年來,隨著深度學習技術的不斷成熟,神經網絡開始被用于訓練分布式詞向量,取代了早期的統計方法。目前分布式詞向量通常特指基于神經網絡獲取的低維度詞向量。分布式表示通過統計或神經網絡的方法構建語言模型并獲取詞向量,具體方法為利用詞和上下文的關系,通過算法將原本離散式的詞向量嵌入到一個低維度的連續向量空間中,最終把詞表達成一個固定長度④的短向量。因此,這種表示方法也被稱為“詞嵌入”(word embedding)。此外,根據分布假設,詞嵌入利用上下文與目標詞的聯合訓練,可以獲取詞語的某種語義表達。例如,通過Python程序引入Word2Vec包并加載訓練好的60維詞向量模型,獲得的詞嵌入的形式如下:
二 詞向量訓練:基于統計與神經網絡的語言模型
訓練詞向量時,一般會使用不同類別的語言模型。訓練詞向量的語言模型主要有兩種:基于統計的語言模型和基于神經網絡的語言模型。
1.基于統計的語言模型
(1)共現矩陣(co-occurrence matrix)
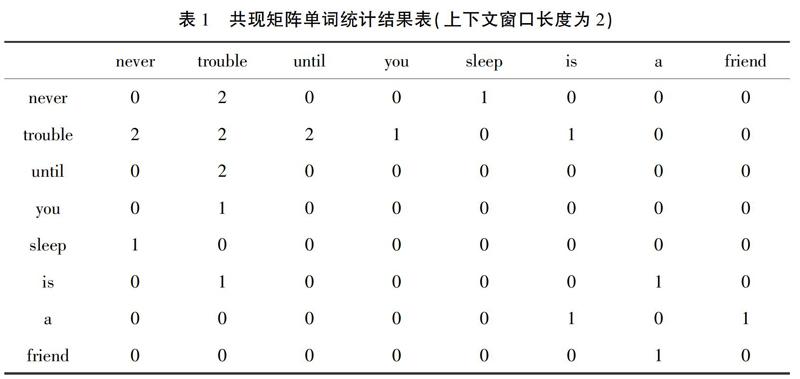
與離散表示不同,共現矩陣通過統計詞表中單詞共同出現的次數,以單詞周圍(可以設置上下文窗口大小)出現的詞頻作為目標詞的向量表示。表1是語料庫A的共現矩陣單詞統計結果,上下文窗口長度取2,共現詞匯為(never,trouble)、(trouble,trouble)、(trouble,until)……,以此類推。
可以發現:never與trouble共同出現的頻次為
2,與until共同出現的頻次為0;這樣,經過統計語料庫A中的所有文本單詞,“never”的詞向量可以表示為[0 2 0 0 0 0 0 0],以此類推,“trouble”可以表示為[2 2 2 1 0 1 0 0]。我們可以發現,基于詞頻統計結果的共現矩陣沒有忽視語義關系,這在一定程度上緩和了“語義鴻溝”的問題,但是由于共現矩陣的維數等于詞表的詞匯總數,因此,矩陣依然十分稀疏,“維度災難”和計算量大的問題仍然存在。
(2) 奇異值分解(singular value decomposition, SVD)
共現矩陣的“維度災難”與數據稀疏等問題,可以通過降低向量維度來解決,即通過算法將共現矩陣降成低維度的稠密(dense)矩陣。奇異值分解是目前使用最為廣泛的一種矩陣分解方法,可以將多維的復雜矩陣M分解成矩陣U、Σ、VT的乘積,如M=UΣVT。根據奇異值的大小截取矩陣U后獲取U′作為降維矩陣,再經過歸一化后得到詞語的詞向量。共現矩陣經過奇異值分解后變為低維度的稠密矩陣,該矩陣可使得語義相近的詞在向量空間上相近,有時甚至能夠反映詞與詞之間的線性關系。然而,奇異值分解算法基于簡單的矩陣變換,可解釋性不強;同時,由于截斷操作,向量表示可能會丟失一些重要信息;另外,奇異值分解算法的計算量隨語料庫與詞典的增長而急劇擴展,新加入的詞會導致統計結果發生變化,矩陣必須重新統計和計算。
2.基于神經網絡的語言模型
傳統的詞向量模型主要基于統計學,由于近年來人工智能的快速發展,基于神經網絡的語言模型愈加成熟。Xu和Alex最早利用神經網絡構建二元(bigram⑤)語言模型的方法訓練詞向量[6]。Bengio等提出了一種三層神經網絡語言模型[2]。該模型不需要人工標注語料,主要根據上文語境預測下一個詞,能夠從單語語料庫中自動獲取豐富的語義信息。該模型的提出為著名的Word2Vec的誕生提供了堅實的算法理論基礎。
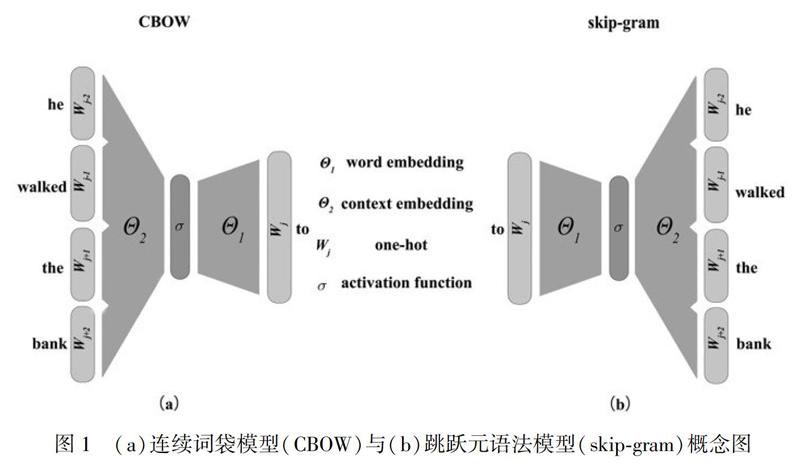
Word2Vec是一款開源詞向量工具包[7],該工具包在算法理論上參考了Bengio設計的神經網絡模型,在處理大規模、超大規模的語料時,可以簡單并且高效地獲取高精度的詞向量,在學術界和業界都獲得了廣泛的關注。Word2vec的實現主要有連續詞袋模型(continuous bag-of-words,CBOW)和跳躍元語法模型(skip-gram)兩種算法(圖1)。
(1) 連續詞袋模型(continuous bag-of-words,CBOW)
連續詞袋模型的核心思想是利用目標詞的上下文來預測目標詞出現的概率。該模型主要通過將文本視為一個詞集合來訓練語言模型,在運算過程中,主要考慮目標詞周圍出現的單詞,忽略其詞序和語法。因其思路類似將文字裝入袋子中,這種模型也被稱為“詞袋模型”[3]。連續詞袋模型運算/運行的具體步驟為:將目標詞的上下文若干個詞對應的離散詞向量輸入模型,輸出詞表中所有詞出現的概率,再通過哈夫曼樹⑥查找目標詞并通過BP算法⑦更新網絡參數使輸出為目標詞的概率最大化,最終將神經網絡中的參數作為目標詞的詞向量。如圖1(a)所示,輸入為he、walked、the、bank四個詞的離散詞向量,輸出為目標詞to的詞向量。為了使得輸出為to的概率最大,連續詞袋模型通過BP算法不斷更新神經網絡參數Θ1和Θ2。經過多次迭代運算后,模型最終收斂并將運算參數(Θ1)作為單詞“to”的理想詞向量。
(2) 跳躍元語法模型(skip-gram)
跳躍元語法模型和詞袋模型的思路相反:利用特定詞語來預測其上下文。該模型接受指定詞的離散詞向量,輸出該詞所對應的上下文詞向量,并且通過BP算法更新網絡參數。如圖1(b)所示,輸入為特定詞to的離散向量,輸出為其上下文he、walked、the、bank四個詞的離散向量。同樣,為了實現模型輸出這四個詞的(即目標詞的上下文)概率最大化,skip-gram通過BP算法更新Θ1和Θ2,并在多次迭代運算后,模型最終收斂并將獲得運算參數(Θ1)作為單詞“to”的理想詞向量。
三 詞向量應用:語義計算、消歧與變遷
1. 語義計算和語義消歧
基于詞的分布式表征以及連續詞袋模型/跳躍元語法模型等神經網絡模型得出的詞向量,可以用于語義計算和語義消歧。傳統語義計算和語義消歧主要采用語法結構分析和人工標注等消歧方法,過程復雜,人工量大。詞向量技術主要通過計算機自主學習來達到消歧目的,大幅度減少了人工的投入。
(1)語義(相關度)計算
語義計算,即詞語間的距離計算,主要用于反映語義相關度。語料經過神經網絡模型運算向量化后,構成了可計算的多維向量空間。每個詞在該空間內都可以表示為多維度的向量。語義計算主要的方法有兩種:①通過語義詞典(如著名的WordNet和HowNet等),把有關詞語的概念或意義組織在一個基于語義的樹形結構中,通過計算其節點(詞)間的距離來反映語義的遠近;②通過提取詞語上下文信息,運用統計的方法進行自動計算。基于詞向量空間模型的語義計算屬于后者。其中,利用神經網絡訓練的詞向量技術將文本表示為低維空間向量,通過計算向量夾角(如余弦相似度)的方式來獲取詞語的語義相關度。相似度取值一般為0~1。
表2是基于跳躍元語法模型獲取的與“語言學”相近的詞,通過引入Word2Vec包,加載預訓練的60維詞向量模型,獲得的結果按照語義相關度大小排序如下:
通過跳躍元語法模型訓練出詞向量后,通過類似聚類的相關度計算,可以快速(毫秒級)獲取與指定詞匯語義相關的詞匯。結果顯示,“語言文學”“語義學”等與“語言學”的相關度較高,在空間位置上較為接近;“竺可楨”“分配律”等與“語言學”的相關度較低。這類語義計算對于語義聚類以及語義挖掘有一定的價值。值得注意的是,分布式詞向量技術對語料的依賴程度較高,因此,需要精選語料進行大規模學習以實現偏差最小化。
通過計算向量相關度,基于詞向量的自然語言處理技術能夠從海量的語料中快速獲取詞語語義的相對位置,并查找出與之相似的詞。多維的詞向量經過降維后,可以在二維平面上清晰地看出語義關系。例如,圖2中,在詞匯關系類比中,king與man之間的距離和queen與woman之間的相對位置非常接近。在句法類比中,slow-slower-slowest三詞之間的相對距離和fast-faster-fastest以及long-longer-longest等的相對位置也十分相似。
以上可以發現詞向量在語義相關度計算與句法分析上可以做到定量分析與可視化,這對語義挖掘具有十分重要的應用價值。
(2)語義消歧
詞向量技術雖然可以表征語義,然而在面對多義詞的時候,單個向量很難表達詞語的多個意義,依然存在詞義模糊以及“多義消失”(meaning conflation)等問題。因此,在使用詞向量時,需要考慮歧義對結果的影響。傳統的語義消歧主要通過語法結構[9],建立特定領域的語義庫以減少語義數[10],通過人工標注的語料學習消歧規則建立詞匯專家系統[11]等,大多依賴人工建立的語義網絡與語義角色。在深度學習領域,消歧主要根據目標詞的上下文信息來進行。目前,語義消歧方法基本上可以分為兩類:無監督式和基于知識庫的方式。無監督的方式直接從文本語料中學習意義,而基于知識庫的方式則在計算機深度學習的基礎上,利用人類專家制作的外部語言知識庫作為意義來源,將機器學習與專家知識相結合。前者可解釋性較差,后者融合專家歸納整理的知識庫,解釋性較好,但也因受限于知識庫,對知識庫以外的詞匯和意義泛化性不足。
1) 無監督消歧
無監督的方式主要有語境聚類式[12]、混合式[13]和語篇主題嵌入式[14]等方法。語境聚類式(clustering-based)消歧的主要思想是通過收集單詞出現的語境,利用聚類算法對其詞義進行自動分類。混合式(joint-training)消歧主要通過在訓練的過程中加入詞義比對更新模式,自動生成詞義組來實現。語篇主題嵌入式主要通過在局部信息(local context)的基礎上引入全局信息(global context)來實現消歧。相對而言,語篇主題嵌入的方法能夠獲得更為精準的語義消歧效果。
在詞向量訓練過程中,一般不考慮整個篇章,僅利用句子上下文幾個窗口的詞提供的信息來訓練模型。然而,有些具有歧義的詞義無法僅憑單句上下文幾個詞的信息來判斷。如圖3的英文句子“he walks to the bank”中,bank可以被理解為“銀行”或者“河岸”。此時,語篇主題嵌入式消歧會在詞向量訓練中加入全局信息和“多種詞義原型”(multiple word prototypes),具體如下:
第一,全局信息模型將整個篇章的詞向量做加權平均(weighted average,權重是tf-idf)計算后作為全局語義向量(global semantic vector),再和正常訓練的局部語義向量相加,這樣訓練出來的加強型詞向量能更好地捕捉語義信息。例如,篇章里出現的諸如river、play、shore、water等詞,可以使得當前bank的語義為“河岸”的概率大大提升。
第二,使用多個詞向量代表多義詞。通過對上下文的詞向量進行加權平均(代表目標詞語義)后進行K均值聚類,根據聚類結果作為目標詞的意義類別,如bank1、bank2和bank3。顯然,這種方式將詞根據語義的不同來分別訓練詞向量,在某種程度上突破了多義消失的問題。然而,調查發現這種方法的效果強烈依賴于聚類算法的可靠性,也不可避免地存在誤差。
2) 基于知識的方法
所謂基于知識的方法,即在詞向量的訓練過程中,加入其他結構化的知識作為監督。隨著以WordNet與HowNet為代表的語言知識庫的不斷完善,基于其網絡結構的圖模型方法也逐漸用于語義消歧中。監督學習借助有標注的訓練語料,在特定領域已經獲得了較好的消歧性能。
Yu等在訓練連續詞袋模型的同時,引入PPDB數據庫⑧和WordNet等外部知識,抽取語義相似詞對作為約束條件,使得對應的詞向量能夠學習到這些詞義相似的信息[15]。Bian等在連續詞袋模型中加入詞的形態、句法和語義信息[16]。Nguyen等在跳躍元語法模型基礎上加入詞匯對比信息共同訓練,使得訓練得到的詞向量能有效識別同義詞和反義詞[17]。Niu等將HowNet知識融入詞向量連續詞袋模型與跳躍元語法模型中,訓練詞義的最基本粒度——義原(sememe)⑨,在訓練過程中加入上下文–單詞–意義–義原的聯合訓練,有效地提升詞向量表達多義詞的效果[18]。
以上,無監督消歧單純依靠語料挖掘意義,極大地減少了人工的投入,而基于知識的方式則引入了外部語料知識,有效地克服了因缺乏足夠信息導致的語義不完整等困難。
2. 語義變遷
詞匯作為語言的基本單位,其語義變遷是研究語言模型和反映社會歷史文化演變的重要手段。傳統的語義變遷研究主要通過從歷史文本中搜索目標詞,統計詞匯的使用頻次,根據語言和歷史知識對其進行人工描述。Michel等利用Google Books五百多萬種出版物,建立語料庫,通過詞頻統計研究人類文化的演變與特點[19]。Bamman等則通過觀測與目標詞匯共現的其他詞匯的頻度變化來間接地探索詞匯語義變化[20]。Mihalcea等通過收集19—21世紀特定術語的使用變化來考察社會現象[21]。以上工作大多通過搜索和統計的方法,從海量的文獻中捕捉到了各個歷史時期的詞匯語義,費時費力,且難以直觀獲取語義內涵。而詞向量表征將文本轉換為空間向量,用向量的夾角代表其語義相似度,能夠定量地從海量歷時文本中獲取語義相近的詞。通過研究詞匯的語義相近詞,能夠比較直觀地看出語義的歷時變化。
劉知遠等基于1950—2003年的《人民日報》文本訓練詞向量模型,對詞匯語義變化進行了定量觀測,探究了詞匯變化反映出來的社會變遷[22]。Hamilton等在多語言大規模語料庫的基礎上,利用Word2Vec的跳躍元語法模型建立歷時詞向量空間來揭示語義變遷規律[23]。如圖4a中,gay在20世紀初與tasteful、cheerful等詞匯在空間位置上較為接近,到了20世紀中葉,gay與witty、bright等詞的語義相關度高。到了20世紀末,gay與lesbian與homosexual等詞在語義計算上結果相近。圖4b顯示,隨著報紙、電視、廣播、網絡等多種媒體的興起,broadcast的相似詞也從19世紀中期的seed、sow等,逐漸演變為newspapers、television、radio、bbc等。圖4c揭示了awful的語義從19世紀中期的solemn逐漸向terrible、appalling等演變的過程。Hamilton等通過動態建模,將靜態的詞向量擴展到動態的時間序列場景中,定量地觀測與剖析了語義更迭與社會文化的變遷[23]。
四 結 語
本文深入探討了計算語言學中的重要術語——詞向量在表達語義方面的表現,介紹了兩種詞向量表達的形式以及獲取方式,證明了詞向量技術為語義消歧與語義變遷等研究提供了定量手段,在語義表達方面顯示出強大的潛力與應用效果。
分布式詞向量模型是基于海量語料的監督學習,充分利用語料庫中詞的上下文相關信息,通過神經網絡優化訓練語言模型,在此過程中獲得詞語的向量化形式。這種向量化的分布式表征以“情景語境”為理論基礎,通過向量間的夾角余弦相似度來度量詞匯的相似度。但是,我們也發現現階段的詞向量僅僅從海量的語料庫中學習到部分語義表達,在其歧義性和不常用詞的弱表達上尚不盡人意,單從海量數據中學到的語義表達還是存在偏差。另外,詞向量對于訓練語料庫中未出現的詞也很難去表達其語義。針對這種情況,本文認為在文本以外,應該引入更加強大的人類專家知識庫的支持,獲取更加強大的語義表達。為此,詞向量的研究,乃至整個自然語言處理系統需要探索數據與知識共同驅動的方法,不斷完善語義表征算法,擴充與優化語言專家知識體系。
注釋
① 這里的長向量是維度較大的向量。在數學中,向量指具有大小和方向的量。它可以形象化地表示為帶箭頭的線段,空間數學可表達為[數值1,數值2,…,數值n]。
② 語料庫中的所有詞構成一個詞表。
③ 樸素貝葉斯假設文本屬性之間是相互獨立的。
④ 一般為60/150/300維。
⑤ gram:粒度、元。N-gram表示多元,是計算機語言學和概率論領域內的概念,是指給定的一段文本中多個連續單位的序列。N可以是任意正整數,如unigram(N=1),bigram(N=2),trigram(N=3),以此類推。
⑥ 哈夫曼樹,又稱“最優樹”,是一種數據壓縮與查找算法。
⑦ BP(back propagation)算法,即反向傳播算法,通過結果誤差的反向傳播來更新神經網絡參數,是深度學習的核心算法。
⑧ PPDB為一種基于農藥特性的專業數據庫。
⑨ 義原在語言學中是指最小的不可再分的語義單位,知網(HowNet)是最著名的義原知識庫。
參考文獻
[1] Hinton G E. Learning Distributed Representations of Concepts[C/OL]. [2020-05-17].http://www.cs.toronto.edu/~hinton/absps/families.pdf.
[2] Bengio Y, Ducharme R, Vincent P, et al. A Neural Probabilistic Language Model[J]. Journal of Machine Learning Research, 2003, 3: 1137-1155.
[3] Harris Z S. Distributional Structure[J]. Word, 1954, 10(2-3): 146-162.
[4] Firth J R. A Synopsis of Linguistic Theory, 1930—1955[J]. Studies in Linguistic Analysis, 1957,168-205.
[5] Li S, Zhao Z, Hu R, et al. Analogical reasoning on Chinese morphological and semantic relations[C/OL]. [2020-05-17].https://arxiv.org/pdf/1805.06504.pdf.
[6] Xu W, Rudnicky A. Can Artificial Neural Networks Learn Language Models?[C/OL]. [2020-05-17].https://kilthub.cmu.edu/articles/Can_Artificial_Neural_Networks_Learn_Language_Models_/6604016/files/12094409.pdf.
[7] Mikolov T, Sutskever I, Chen K, et al. Distributed Representations of Words and Phrases and Their Compositionality[C/OL]. [2020-05-17].https://papers.nips.cc/paper/5021-distributed-representations-of-words-and-phrases-and-their-compositionality.pdf.
[8] Akhtar S S. Robust Representation Learning for Low Resource Languages[M]. INDIA: International Institute of Information Technology, 2018.
[9] Reifler E. The Mechanical Determination of Meaning[J]. Readings in Machine Translation, 1955: 21-36.
[10] Weaver W. Translation[J]. Machine Translation of Languages, 1955, 14: 15-23.
[11] Weiss S F. Learning to disambiguate[J]. Information Storage and Retrieval, 1973, 9(1): 33-41.
[12] Liu P, Qiu X, Huang X. Learning Context-sensitive Word Embeddings with Neural Tensor Skip-gram Model[C/OL]. [2020-05-17].https://www.aaai.org/ocs/index.php/IJCAI/IJCAI15/paper/viewFile/11398/10841.
[13] Li J, Jurafsky D. Do Multi-sense Embeddings Improve Natural Language Understanding?[C/OL]. [2020-05-17]. https://arxiv.org/pdf/1506.01070.
[14] Huang E H, Socher R, Manning C D, et al. Improving Word Representations Via Global Context and Multiple Word Prototypes [C/OL]. [2020-05-17].https://dl.acm.org/doi/pdf/10.5555/2390524.2390645?download=true.
[15] Yu M, Dredze M. Improving Lexical Embeddings with Semantic Knowledge[C/OL]. [2020-05-17].https://www.aclweb.org/anthology/P14-2089.pdf.
[16] Bian J, Gao B, Liu T Y. Knowledge-powered Deep Learning for Word Embedding[C/OL]. [2020-05-17].https://www.microsoft.com/en-us/research/wp-content/uploads/2016/02/5BECML20145D20Knowledge-Powered20Word20Embedding.pdf.
[17] Nguyen K A, Walde S S, Vu N T. Integrating Distributional Lexical Contrast into Word Embeddings for Antonym-synonym Distinction [C/OL]. [2020-05-17].https://arxiv.org/pdf/1605.07766.pdf.
[18] Niu Y, Xie R, Liu Z, et al. Improved Word Representation Learning with Sememes[C/OL]. [2020-05-17].https://www.aclweb.org/anthology/P17-1187.pdf.
[19] Michel J B, Shen Y K, Aiden A P, et al. Quantitative Analysis of Culture Using Millions of Digitized Books[J]. Science, 2011, 331(6014): 176-182.
[20] Bamman D, Crane G. Measuring Historical Word Sense Variation[C/OL]. [2020-05-17].https://dl.acm.org/doi/pdf/10.1145/1998076.1998078.
[21] Mihalcea R, Nastase V. Word Epoch Disambiguation: Finding How Words Change Over Time[C/OL]. [2020-05-17].https://www.aclweb.org/anthology/P12-2051.pdf.
[22] 劉知遠,劉揚,涂存超,等.詞匯語義變化與社會變遷定量觀測與分析[J].語言戰略研究,2016,1(6): 47-54.
[23] Hamilton W L, Leskovec J, Jurafsky D. Diachronic Word Embeddings Reveal Statistical Laws of Semantic Change[C/OL]. [2020-05-17].https://arxiv.org/pdf/1605.09096.pdf.
