基于知識圖譜的電影自動問答系統
2020-07-04 04:06:44徐宇晨
科學與財富 2020年15期

摘 要: 為提高用戶獲取電影相關信息的效率和準確性,設計并實現基于知識圖譜的電影自動問答系統。針對電影信息實體的特征,規范解析實體和實體之間的關系,構建電影信息知識圖譜;通過對用戶輸入的問題進行實體識別與詞性標注,進行問句分析,實現問句語義理解;利用貝葉斯分類器匹配問句模板在知識圖譜上進行查找,從大量的非結構化數據中得到所需的具體信息,理解用戶對于電影信息的需求。本系統通過構建電影的知識圖譜結構對知識作了有效區分,實現更好的匹配效果。不僅簡化了操作,還極大的提高了準確度,省時省力更高效。
關鍵詞:自動問答系統;知識圖譜;問句分析;貝葉斯分類器
Abstract: In order to improve the efficiency and accuracy of users' access to film-related information, an automatic question answering system based on knowledge map was designed and implemented. According to the characteristics of film information entities, the relationship between entities and entities is standardized and analyzed, and the map of film information knowledge is constructed. The semantic understanding of the question can be realized by entity recognition and part-of-speech tagging of the question input by the user. The Bayesian classifier matching question template is used to search on the knowledge map to obtain the required specific information from a large number of unstructured data and understand the user's demand for movie information. In this system, the knowledge map structure is constructed to distinguish the knowledge effectively and achieve better matching effect. Not only simplified the operation, but also greatly improved accuracy, saving time and labor more efficient.
Keywords: automatic question answering system; Knowledge map; Question analysis; Bayes classifier
引言
自動問答是一種高級的信息檢索技術,支持用戶針對事物屬性或聯系進行提問,國內外在自動問答系統上已經研究了較長時期,從上世紀60到70年代開始,問答系統就出現在人們的視線,主要依賴搜索技術,對查詢相關的文檔進行檢索,如Yahoo早期的answer and quora[1]。而到了上世紀70年代,自動問答系統開始以結構化知識庫為基礎,通過搜索知識庫得到最終答案,如YAGO[2]、WordNet[3]、張克亮等人基于本體的航空領域問答系統[4]。如今,隨著人工智能的發展,利用知識圖譜構建信息結構設計問答系統成為一種必然的趨勢,如IBM的Watson系統[5]、馬晨浩設計的基于甲狀腺知識圖譜的自動問答系統的設計與實現[6]。基于知識圖譜提供的語義層面上支持的自動問答系統,包含信息分析、自然語言處理和機器學習領域的大量技術創新,能夠幫助用戶從大量非結構化數據中得到所需的具體信息,是新一代信息檢索技術發展的必然趨勢[7]。
知識圖譜,源自于Google的Knowledge Graph,其本質是一種語義網絡,結點代表實體或者概念,邊代表實體/概念之間的各種語義關系。隨著數據的結構化發展,互聯網正從大量互相鏈接的網頁向包含大量描述各種實體和實體之間豐富關系的語義網演進。
目前,中國作為全球第二大電影市場,同時也是增長最快的市場之一,人們對電影產業需求尤為突出。人們在電影的選擇上,會經常利用當代主流搜索引擎對演員、劇情、導演等關鍵詞進行搜索,如文獻文科和百科等形式,但是反饋的結果往往需要通過主觀上多次篩選,才能夠獲得自己真正想要的答案,并不能夠直接提供一個清晰明了的結果,時效性非常低。與國外的自動問答系統相比,由于中文本身的獨特屬性,系統在理解自然語言問句上要比英文難。系統可以自動解析用戶英文提出的問題,不需要考慮問句分詞和理解誤差,如Microsoft Concept Graph[7]。但是從中文角度,系統總是理解的模糊不清。國內外現有的電影信息自動問答系統,大多以SSH框架為基礎或利用tensorflow實現電影信息的問答,如Google中國版電影onebox[8]、時光網等,基于知識圖譜實現的電影自動問答系統并不多。
本文打算做的,即是電影信息領域的自動問答系統,在對大量的電影信息做出有效的整理后,創建生成電影信息知識圖譜,基于該知識圖譜,在Java平臺上實現電影的自動問答系統,用戶輸入問題,系統對輸入的自然語言進行問句分析,匹配不同語義的不同模板,在知識圖譜內進行查詢,獲取答案。該系統結合了多種自然語言處理技術,能夠幫助使用者從大量的非結構化數據中得到所需的具體信息,理解用戶對于電影信息的需求。
1系統架構
整個系統主要分為數據獲取與存儲模塊、自動問答系統實現模塊、用戶交互模塊等三個模塊,具體描述如下:
(1) 數據獲取與存儲模塊,主要是將分布在不同網站的爬蟲文件獲取到的電影數據信息進行整理存儲在MySql數據庫中,根據數據庫中的數據構建出電影信息的知識圖譜,供后期問答業務的處理和實現使用。
(2) 自動問答系統實現模塊,主要是以設計的電影信息知識圖譜為基礎,系統將用戶輸入的問題,進行實體識別與詞性標注,根據識別后的實體,對問題進行分類,匹配不同的問句查詢模板,使用模板在知識圖譜上進行查找,得到用戶問題的最終答案并返回用戶。若問題實體識別后,詞性標注為實體本身,則直接在知識圖譜內進行搜索,返回用戶答案。
(3) 用戶交互模塊,指用戶在使用時所看到的額人機交互界面,提供給用戶查詢問題并獲取答案。具體系統模塊結構圖如圖1所示。
2電影信息知識圖譜的構建
本系統通過分布在不同網站的爬蟲文件,聚合各大電影門戶網站的電影信息,存儲在MySql數據庫中,并提取文本中的命名實體,使數據結構化,從而構建電影信息的知識圖譜,這增強了文本的表示和組合模型[9],使用戶直接獲取電影信息之間的關系。同時利用知識圖譜能將問句中實體和關系識別出,確定問題意圖,映射對應的問題模板,形成對應的語序圖,得到準確的答案。從現有的研究成果來看,知識圖譜的技術還主要應用在科技專業領域的研究,而對于非科技專業的領域,如搜索一些普通的資訊信息,還停留在普通的搜索引擎階段。因此,針對電影信息這類非科技專業領域構建知識圖譜,能夠將數據搜索范圍縮小,從而有利于提高知識搜索的準確性和高效性。
2.1數據獲取與處理
數據獲取主要采取的途徑是利用網絡爬蟲自動獲取。
網絡爬蟲(Web crawler)又被稱為網頁蜘蛛(Web spider),是一種按照一定的規則,自動地抓取萬維網信息的程序或腳本。因為互聯網上的頁面是由多個各大網站的URL相互鏈接起來的,所以首先從一個或若干初始網頁的URL開始,獲得初始網頁上的URL,在爬取網頁的過程中,不斷從當前頁面上抽取新的URL放入隊列,根據頁面標簽的正則匹配算法,過濾與主題無關或無用的信息,保留有用的信息并建立索引,直到滿足系統的一定停止條件。
電影信息的獲取是通過爬取各大電影門戶網站的數據,如百度百科、豆瓣網、時光網、M1905、中國電影票房網等。自動獲取的電影信息主要包括電影的基本信息,如電影類型、劇情介紹、評分等;演員的基本信息,如姓名、角色、性別等。通過對頁面標簽的正則匹配,抽取電影各類實體關系的信息,整理存儲在MySql數據庫中,以備后續操作。
2.2知識圖譜的構建
電影信息的表達形式,是該系統的一個重要組成部分。隨著計算機科學領域和人工智能領域的發展,自然語言處理在機器學習和深度學習相關的算法下取得了突破,比如語義解析、語言建模等[10]。2012年,Google通過將如語義解析、語言建模等系統化后,提出“知識圖譜”,從而越來越多的計算機領域研究學者和開發設計者,將知識圖譜應用在知識的表達形式上。融合知識圖譜,能夠使系統自動給將問題中實體和關系識別出來,基于模板的方法對結構化查詢進行問題的描述[11],形成對應的語序圖,通過查詢知識圖譜中的三元組得到答案。
本系統電影信息知識圖譜根據MySql數據庫中存儲的電影信息構建,包括電影名稱信息實體、電影類別信息實體、演員信息實體等,實體之間存在多種聯系,規范解析實體和實體之間的關系,將數據庫中不同表內的不同數據,以三元組<實體,關系,實體>形式構建電影信息知識圖譜的概念層設計。
定義1 電影信息實體 包括電影名稱實體、電影類別實體、演員信息實體等。實體名稱存放于根目錄,每個實體都包含一組屬性[12],在定義了電影信息實體之后,可以構建電影信息知識圖譜概念層設計如圖2所示。
定義2 電影基本信息關系實體 電影信息關系實體表示電影信息實體間產生的聯系,如<電影名稱,電影信息,演員>。其中,電影名稱、演員都是電影信息的實體,而電影信息為電影基本信息關系實體。電影基本信息關系類型主要包括內容如下:
(1)A is B關系:表示實體A有一個屬性實體B。
(2)A actedin B關系:表示實體A出演實體B的關系。
最后抽取實體和關系,綜合確定三元組,借助Neo4j服務中Cypher模板文件存儲數據,將模糊的查詢條件轉化為精確的查詢區間[13],有效的管理每個節點的特定屬性,以及每條邊與實體之間存在的關系。知識圖譜設計模式圖如圖3所示。
查詢語句[14],利用JDK提供的一些低級API,用基于圖的模式匹配,實現對數據的處理與擴展。同時,Neo4j能夠非常方便的融合到系統中進行后續開發。本系統使用Neo4j構建的電影信息領域的知識圖譜可視化展示如圖4所示。
本系統主要構建以電影信息為核心的知識圖譜,以電影名稱為根節點,以此延伸出電影的名稱、時間、劇情介紹、演員等信息,每一級的節點又可以延伸至下一節點,如將章子怡節點進行展開,可以看得到與章子怡相關的所有電影。電影信息知識圖譜的節點可視化展開如圖5所示。
3問句分析
問句分析主要研究問句的抽象以及問句的分類等自動問答系統所采用的對中文進行自然語言處理的技術,使系統對問題的理解準確度得到提升
3.1問句的抽象
問句的抽象是針對中文進行自然語言處理的基礎步驟,也是實現數據標注處理的基礎模型。與英文問句相比,系統可以通過疑問句中固定的疑問詞自動解析用戶英文提出的問題,但中文具有本身的獨特屬性,中文提出的問題無明顯詞性的界限,因此進行中文問句的自然語言處理時,利用分詞技術實現問句的抽象是第一步。
將知識圖譜中的實體概念和屬性等詞加入領域詞庫,標注單詞的詞性,并添加部分人工標注的命名實體,比如問句中會涉及到的專有的電影名稱、人名、劇情等實體,完成自定義帶有詞性的字典數據[13]。這相當于提供給機器人一個習題集,所謂的標注,就是將整個數據、正確答案作為習題集教給機器人,機器人在學習過程中,就會在做題過程中在習題集內搜索答案。
系統在收到用戶提出的問題后,能夠自動進行問句抽象,對問句進行分詞處理,將中文轉化成系統能夠理解的語義,更加貼合用戶的意圖。
3.2問句的分類
由于中文的獨特屬性,不像英語具有專屬的疑問詞、時態與語法,用戶輸入的問題具有隨意性,即表達相同意思的詞語可以被多種同義詞所替代,表達某一問題的問句可以被隨意組合成多種問句。根據電影信息知識圖譜,自定義帶有詞性的字典數據,將問句定義成不同的類別。問句分類如表1所示。
3.3問句的匹配
對于輸入的自然語言,首先進行問句的分類,根據問句類別的關鍵詞,構造出問句類別向量,進行問句匹配,映射其對應的問句模板,形成對應的有向語序圖。問句匹配是從概率學的角度進行分類,如果將用戶輸入的問句與知識庫中存在的問題庫進行最高程度的匹配,則系統反饋給用戶的答案也將更加準確、快速。
目前常用的分類算法樸素貝葉斯分類器(na?ve Bayes classifier)、支持向量機(support vector machine)與最大熵模型(maximum entropy model)等[15]。其中樸素貝葉斯分類器能夠在復雜的場景中,使對文本訓練集的速度較快且準確。考慮到本系統的研究主要在于準確和問題樣本的特點,需要從電影的名稱這類實體和人工標注的問題分類兩個方面進行匹配計算,所以選擇采用樸素貝葉斯分類器。首先我們要清楚什么是貝葉斯定定理,當事件B已經發生,事件A發生的概率叫做事件B發生下事件A的條件概率,其基本求解公式為:
現有事件B,則在事件A發生的條件下,事件B發生的概率,其基本求解公式為:
樸素貝葉斯分類器是基于貝葉斯定理,根據特征項,選取預測類別,再進行概率計算的分類方法,具體實現的數據模型可以表示如下:
4答案生成
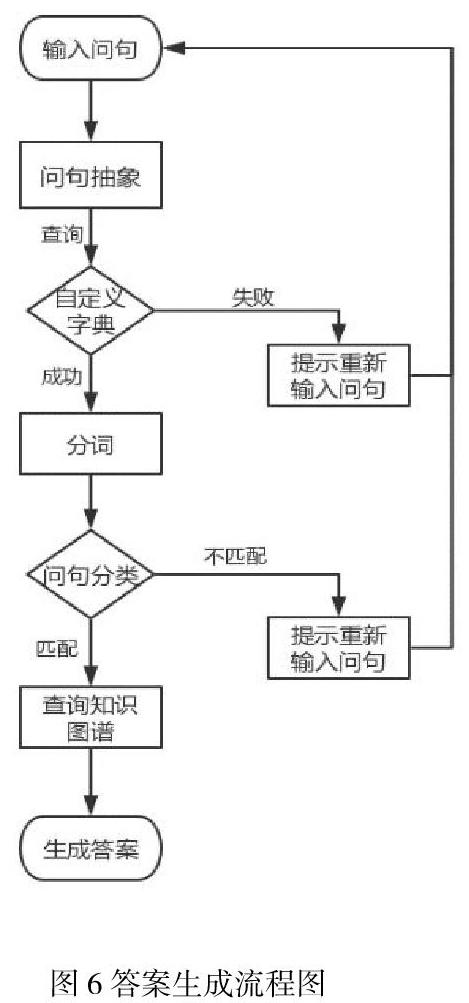
本系統的答案生成主要就是通過樸素貝葉斯分類器實現。答案可能是一個單詞、一個句子片段、一個結構良好且有意義的句子或一組邏輯連貫的句子。答案類型取決于問句的抽象與匹配[16]。基于知識圖譜的自動問答系統通常包括為特定領域開發問答對數據庫,然后根據用戶的問題獲取答案。在用戶輸入問題時,此時問句為原始句子,利用分詞器對原句子進行抽象,將其中電影名稱、人名等用自定義的詞典進行替換,并與事先訓練好的樸素貝葉斯分類器中問題樣本數據集進行匹配問題模板,判斷是否為匹配。若匹配,則直接返回模板中匹配的最終標準問題給用戶,并去圖形數據庫Neo4j中查找問題的答案;反之,則將預測的結果反饋給用戶,提示用戶輸入有效問題。答案生成流程如圖6所示。
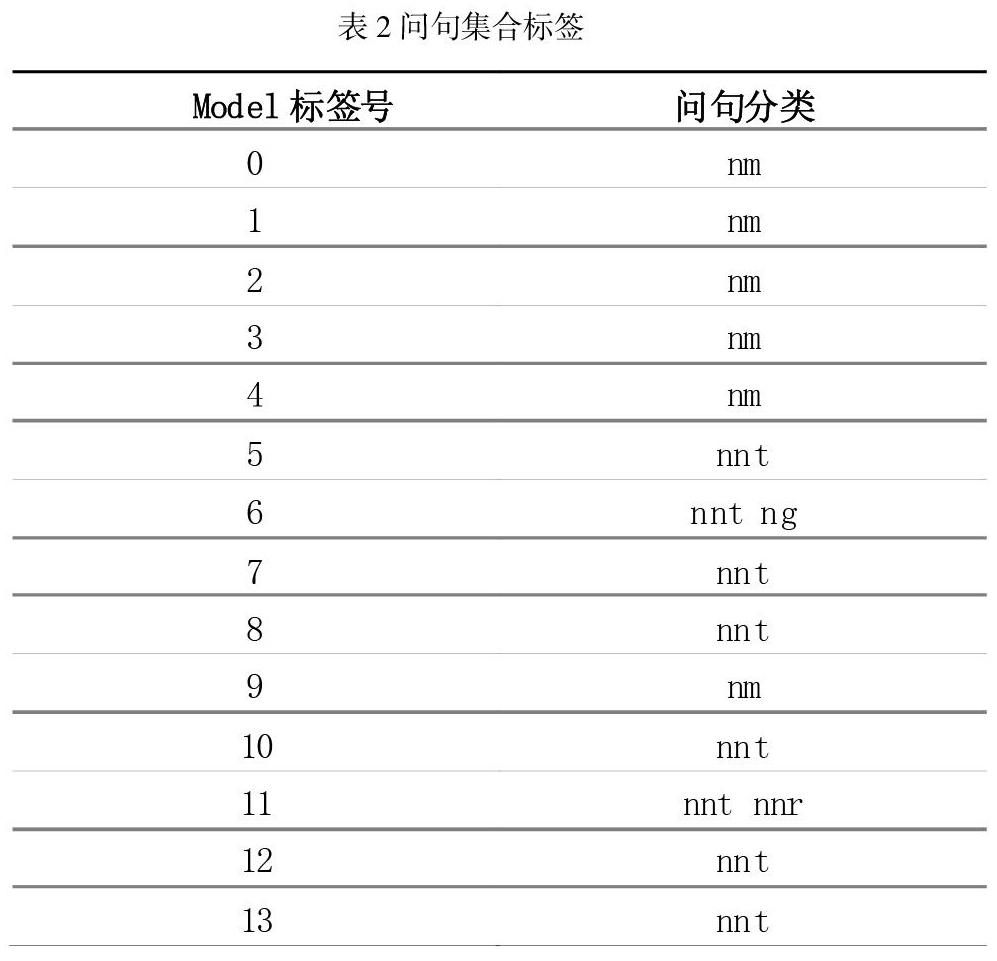
根據之前自定義好的數據詞典,設計用戶可能會提出的問題,將問題詞匯集合成vocabulary數據集,之后按照數據集設置問題集合,分類Model標簽號,具體問題集合如表2所示。
對原始問題進行分詞,提取關鍵特征詞,如“評分”、“多少”等和數據集中關鍵特征進行匹配,在貝葉斯分類器中構造向量,進行詞匯數據集的比對,若有則返回1,反之返回0。
實現答案的查詢過程只要時將問題有序語句轉換成Neo4j的查詢語句,在圖形數據庫中進行查詢。在結構化查詢語言中,鍵值時完全匹配的,但是用戶輸入的是模糊查詢,所以需要將用戶輸入的模糊查詢,轉換為統一鍵值,再翻譯為Neo4j圖數據庫的標準查詢語句Cypher,從而再知識圖譜上進行查詢,如查詢某電影出演的演員有哪些,可以表示為“match(n:Person)-[:actedin]-(m:Movie) where m.title ={title} return n.name”。若遇到不相關的詞語,則用貝葉斯分類器進行特征值和問題模板的匹配,從而完成答案的生成。
5實驗結果與分析
5.1 實驗一 問句詞性識別標注為實體本身類問題
輸入:<實體>
實例輸入:章子怡
預期結果:Beijing-China,人工查詢知識圖譜中章子怡對應為Beijing-China。
實驗運行結果如圖7所示。
5.2 實驗二 問句識別為人工標注的問題-電影評分
輸入:<實體>評分是多少?
實例輸入:英雄的評分是多少?
預期結果:7.3,人工查詢知識圖譜中英雄的評分對應為7.3。
實驗運行結果如圖8所示。
5.2 實驗三 問句識別為人工標注的問題-演員電影作品
輸入:<實體>出演了哪些電影?
實例輸入:章子怡出演的冒險電影有哪些?
預期結果:Godzilla: King of Monsters, Godzilla vs. Kong, 臥虎藏龍, 英雄, TMNT, 十面埋伏。人工查詢知識圖譜中英雄的評分對應為Godzilla: King of Monsters, Godzilla vs. Kong, 臥虎藏龍, 英雄, TMNT, 十面埋伏。
實驗運行結果如圖8所示。
6結束語
隨著互聯網的不斷發展,自動問答系統正在日趨完善。以電影信息為數據,構建基于知識圖譜的電影自動問答系統,在人工標注和自動化結合的方式下,構建了電影知識圖譜和問題詞匯數據集,并設計了多種可能的問題模板,即幫助系統理解用戶意圖,利用知識圖譜獲取用戶想查詢問題的準確答案。可以存儲大量的數據的同時,在后續數據應用方面相比較傳統模式也占據了明顯優勢。
在未來,本系統將會在已有基礎上,不斷擴展電影信息的知識圖譜,使得自動問答系統能夠處理的問題信息更多,并且不斷完善貝葉斯樸素分類器模型,提升被提取特征值的準確率和速率,保障在自動問答模塊上的穩健性。
參考文獻:
[1]劉乙蓉,劉蕓.問答平臺中的答案聚合及其優化[J].圖書館學研究,2017,6.
[2]Suchanek F M, Kasneci G, Weikum G. Yago:a core of semantic knowledge.In:Proceedings of International Conference on World Wide Web,2007:697-706.
[3]Miller G A. WordNet:a lexical database for English. Commun ACM,1995,38:39-41.
[4]張克亮,李偉剛,王慧蘭.基于本體的航空領域問答系統[J].中文信息學報,2015.
[5]孔鹿.IBM的Waton如何改善中國醫療[N].第一財經日報,2016-08-30(A08).
[6]馬晨浩.基于甲狀腺知識圖譜的自動問答系統的設計與實現[J].智能計算機與應用,2018,8(3):102-107.
[7]孟明明,張坤,論兵.一種面向知識圖譜問答的語義查詢擴展方法[J/OL].計算機工程.
[8]Google谷歌中國版電影onebox上線[C].CFan PE:軟件學用通.
[9]安波,韓先培,孫樂.基于知識表示的知識庫問答系統[J].中國科學:信息科學,2018,48(11):1521-1532.
[10]薛蕊,馬小寧.自然語言處理關鍵技術在智能鐵路中的應用研究[J].計算機應用,2018,27(10):40-48.
[11]Dominic Seyler, Mohamed Yahya,Klaus Berberich.Knowledge Questions from Knowledge.Graphs arXiv:1610.09935v2 [cs.CL],1,Nov,2016.
[12]Yuan Yang,Jingcheng Yu,Ye Hu,Xiaoyao Xu,Eric Nyberg.CMU LiveMedQA at TREC 2017 LiveQA: AConsumer Health Question Answering System,2017.
[13]李雪.一種基于Neo4J圖數據庫的模糊查詢研究與實現[J].計算機技術與發展,2018,28(11):16-21.
[14]劉嶠,李楊,段宏,劉瑤,秦志光.知識圖譜構建技術綜述[J].計算機研究與發展,2016,53(3):582-600.
[15]李文寬,劉培玉,朱振方,劉文鋒.基于卷積神經網絡和貝葉斯分類器的句子分類模型[J/OL].計算機應用研究.
[16]Ashwini Jaya Kumar , Christoph Schmidt, Joachim K?hler .A knowledge graph based speech interface for question answering systems :Speech Communicatio 92(2017),1-12.
作者簡介:
徐宇晨(1997-),女,民族: 漢 ,籍貫:江西景德鎮,學歷 :大學本科,職稱:無,畢業院校:無,研究方向:軟件工程 飛行器控制技術.
