基于體檢數據的糖尿病風險預測模型對比研究
2020-07-09 21:26:25馬文彬王克于濱馮超南紀俊
現代信息科技 2020年23期
關鍵詞:機器學習
馬文彬 王克 于濱 馮超南 紀俊

摘 ?要:隨著中國糖尿病患者人數及病死率不斷上升,對空腹血糖的有效檢測及合理預測是目前的研究重點。采用數據挖掘的方法,根據體檢數據建立空腹血糖變化預測模型。基于前三年的醫學檢查數據預測第四年空腹血糖的變化,從醫學檢查數據庫中收集實驗數據。在特征選擇階段,使用主成分分析選擇最佳特征子集,結合5種機器學習算法建立模型并預測患病風險。實驗結果表明隨機森林算法模型對糖尿病風險預測效果最佳。
關鍵詞:空腹血糖;機器學習;PCA;體檢數據;糖尿病預測
中圖分類號:TP311.13;R587.1 ? ? 文獻標識碼:A 文章編號:2096-4706(2020)23-0072-04
Comparative Study of Diabetes Risk Prediction Models Based on Physical Examination Data
MA Wenbin1,WANG Ke2,YU Bin3,FENG Chaonan3,JI Jun1,3
(1.Qingdao University,Qingdao ?266071,China;2.East Hospital of Qingdao Municipal Hospital,Qingdao ?266071,China;
3.Beijing Wanlingpangu Technology Co.,Ltd.,Beijing ?100089,China)
Abstract:With the increasing number of diabetes patients and mortality in China,the effective detection and reasonable prediction of fasting blood glucose is the focus of current research. Using the method of data mining,the prediction model of fasting blood glucose change was established according to the physical examination data. Based on the medical examination data of the previous three years to predict the change of fasting blood glucose in the fourth year,the experimental data is collected from the medical examination database. In the feature selection stage,principal component analysis is used to select the best feature subset,combined with five machine learning algorithms to build a model and predict the risk of disease. The experimental results show that the random forest algorithm model is the best for diabetes risk prediction.
Keywords:fasting blood glucose;machine learning;PCA;physical examination data;diabetes prediction
0 ?引 ?言
糖尿病是一種日漸流行的疾病,嚴重時會引發許多并發癥,但早期糖尿病患者沒有任何癥狀或者癥狀較輕,所以早期糖尿病并不容易被發現[1]。如果在糖尿病早期對患者進行適當的護理,改變其生活方式并輔助藥物治療,能夠使糖尿病并發癥的風險降低30%~60%[2]。空腹血糖(Fasting Blood Glucose,FBG)是糖尿病診斷的重要指標,對于FBG的研究可以幫助患者在糖尿病發病早期發現風險從而得到盡早治療,通過對近些年國內外研究發現,糖尿病預測模型大多采用同年體檢數據,預測效果不可靠且不具有提前預測性。本文以青島大學國家自然科學基金項目“基于健康數據分析的半監督在線學習血糖預測建模算法研究”和青島大學山東省自然科學基金“基于健康數據分析的半監督在線學習血糖預測建模算法研究”為支撐,將數據挖掘、機器學習技術應用于體檢數據中,構建預測模型并預測患病風險。
1 ?研究現狀
近些年來,利用機器學習算法對糖尿病的研究日益增多。Kavakiotis等人[3]使用傳統機器學習算法對糖尿病進行建模預測,Polat和Güne?[4]通過主成分分析和神經模糊推理來區分體檢者是否患有糖尿病。Han等人[5]提出利用支持向量機對糖尿病進行篩查,并添加了集成學習模塊。Tresp等人[6]采用神經網絡對血糖值進行預測,分別從遞歸神經網絡和時間序列卷積神經網絡兩方面研究了神經網絡在糖尿病患者血糖代謝建模中的應用。Georga等人[7]采用支持向量回歸算法對1型糖尿病患者皮下葡萄糖濃度進行預測。余麗玲等人[8]將支持向量機和自回歸積分滑動平均進行組合,較好地反映血糖的波動趨勢。
隨著科技的不斷發展,我們獲取的數據更加全面。Gani等人[9]提出將數據驅動的預測模型與頻繁的葡萄糖測量相結合,為糖尿病患者提供了更好檢測血糖值的方法。Pradhan等人[10]采用遺傳編程對UCI資料庫的糖尿病數據集進行訓練和測試,使用遺傳編程所取得的結果與其他實施技術相比具有最佳的準確性。
有些學者使用了新的預測方法,魏芬芬[11]使用灰色預測模型對血糖進行預測,結果在患者餐后血糖方面的預測效果尤其突出,但過程比較復雜。豐羅菊等人[12]以311名糖尿病患者為例,采用有序回歸和受試者工作特征曲線(Receiver Operating Characteristic Curve,ROC)等方法,對糖尿病腎病患者的空腹血糖值進行了預測值篩選。
目前已有的研究多數存在研究算法單一、樣品量較小等不足,本研究采用海量高維體檢數據,采用多種算法對體檢血糖數據進行建模,對比各算法結果從而選擇最優模型,能夠更加準確地對糖尿病做出風險預測。
2 ?算法簡述
本研究使用決策樹、隨機森林、支持向量機、邏輯回歸、樸素貝葉斯算法對體檢血糖數據進行建模,通過對比各算法結果選擇最優模型。
決策樹(Decision Tree,DT)是一種常見的機器學習算法,它采用“樹狀結構”進行決策[13]。決策樹中主要包括根節點、葉子節點和內部節點。決策樹中的每個節點代表其中一個對象,節點的不同路徑為不同的結果選擇。決策樹學習的目的是產生一棵具有較強泛化能力的決策樹[14]。
隨機森林(Random Forest,RF)是一種用于分類、回歸等任務的集合學習方法,其操作方法是在訓練時構建眾多決策樹,并輸出各個樹類的模式(分類)或平均預測(回歸)的類[15]。通過Bootstrap抽樣方法從原始訓練樣本集N中有放回地隨機抽取k個樣本生成相互之間有差異的新的訓練子集,再根據k個訓練子集建立k棵決策樹,對于響應變量為分類變量的數據,應結合多棵樹的分類結果對每個記錄以投票的方式決定其最終的分類[16]。
支持向量機(Support Vector Machine,SVM)是一種監督學習模型,用于分類和回歸分析[17]。給定一組訓練實例,每個實例被標記為兩類中的一類,SVM算法通過建立模型將新的實例分類,使其成為一個非概率的二元線性分類器。除執行線性分類外,SVM還能使用內核技巧高效地執行非線性分類,將其輸入映射到高維特征空間中[18]。
邏輯回歸(Logistics Regression,LR)是一種廣義的線性回歸模型,常用于數據挖掘、經濟預測等領域,尤其多應用于二分類問題。對邏輯回歸來說,自變量既可以是分類數據,也可以是連續數據;而邏輯回歸的響應變量,則對應著分類變量。邏輯回歸算法中用到的Sigmoid函數以及階躍函數使得它能夠比較容易地擴展到多類問題來使用[19]。
樸素貝葉斯算法(Naive Bayes,NB)使用貝葉斯定理中的概率推理方法,通過計算樣本在不同類別的概率來對樣品進行分類,同時,樸素貝葉斯模型建立在屬性之間相互獨立性的基礎上,各個類別之間不存在任何依賴關系。樸素貝葉斯算法對于樣本數量小的數據表現較優,能夠處理多分類任務,比較適合增量式訓練。
3 ?數據及處理過程
3.1 ?數據來源
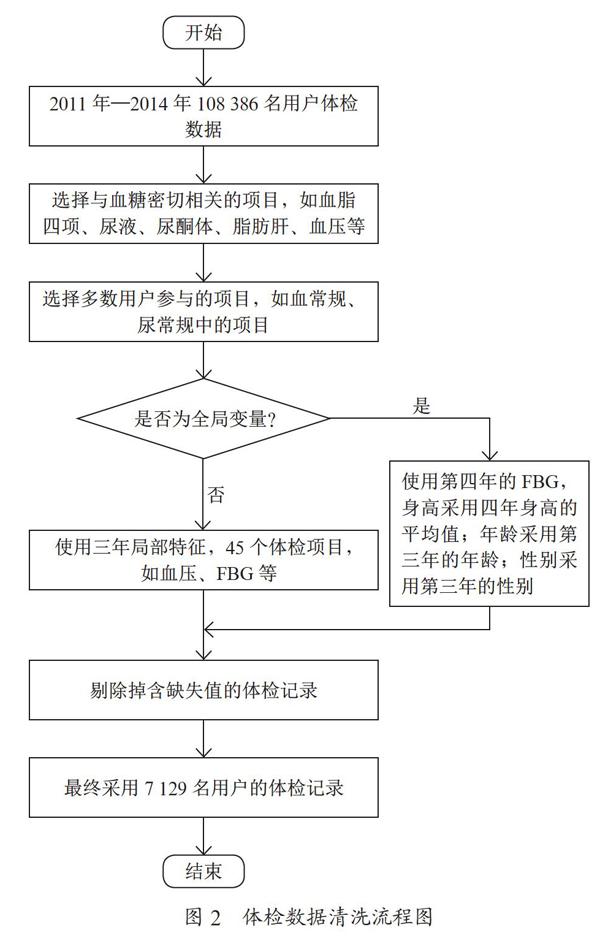
本研究中的數據來自北京華兆益生健康體檢,包含108 386名用戶。為了保持數據的完整性和規范性,選取了2011年1月至2014年12月的體檢記錄。
本研究整個過程包含數據清洗、特征提取、建立模型和預測四部分,流程圖如圖1所示。
3.2 ?數據清洗
數據清洗過程分為有效數據選擇、體檢項目選擇、建立特征、清洗結果四部分。
3.2.1 ?有效數據選擇
某些記錄中的ID與體檢項目無法匹配,為保證數據的準確性,這些記錄被刪除。對于含有缺失值的記錄,為保證數據質量,這類記錄也被刪除。某些特征表達方式不規范,如用“+”、“++”表示,用文字或非標準符號表示。為解決上述情況,將特殊符號用數字代替;將相似術語用相同值代替;將特征中非標準術語和符號刪除。
3.2.2 ?體檢項目選擇
體檢信息包括用戶基本信息(如年齡、性別等)和體檢項目。體檢項目不包含敏感身份信息,選擇標準為:一方面,選擇與血糖密切相關的項目,如血脂四項、尿液、尿酮體、脂肪肝、血壓等;另一方面,選擇用戶參與較多的項目,如血常規、尿常規中的項目。
3.2.3 ?建立特征
特征分為兩類:一類是全局特征,幾乎不隨時間變化或只有一年的項目有意義,如身高、年齡;另一類是局部特征,其體檢結果可能隨年份變化,如體重、FBG、血壓等。全局特征在數據集中唯一存在,局部特征在每一年都存在。
3.2.4 ?清洗結果
數據庫中共有108 386名用戶,體檢記錄9 073 312條,記錄時間為2011年1月至2014年12月。經數據清洗,最終采用7 129名用戶記錄。數據集有139個特征,包括三年的局部特征,45個體檢項目。每年項目主要有血常規、尿常規、血生化、內科、心電圖等。數據集還包括第四年的FBG、身高、年齡、性別四個全局特征。第四年的FBG作為因變量,身高采用四年身高的平均值;年齡采用第三年的年齡;性別采用第三年的性別。
體檢數據的清洗過程如圖2所示。
3.3 ?特征提取
體檢數據中包含多項體檢項,但也有一些體檢項與空腹血糖的預測無關。本研究采用PCA來進行主成分分析,從而達到降維的目的。
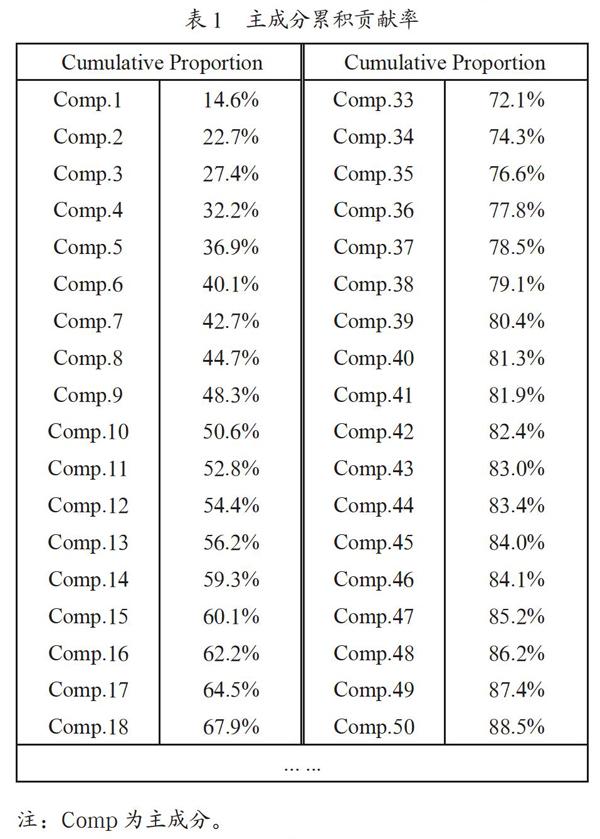
主成分分析是一種常用的統計方法,可以處理大量過程參數間的關系與變化,排除次要因素,提取主要因素。數據采用7 129名用戶的體檢記錄,保留前三年每年45項體檢項以及第四年年齡、身高、性別(其中,男性用0表示,女性用1表示)共138項體檢量作為自變量,記為X1,X2,…,X138,第四年的FBG作為因變量Y。為避免不同醫學指標單位帶來的偏差,對自變量進行標準化,然后對訓練集中自變量進行主成分分析,分析結果如表1所示。
由表1可知,降維后的指標中前47個新指標的累積貢獻率超過85%,也就是說前47個新指標能夠解釋85%的原指標,因此我們使用前47個新指標作為自變量進行后續分析。
3.4 ?建模及預測
本研究提出依據前三年體檢數據,預測第四年用戶是否患有糖尿病的模型,模型建立過程為:
(1)建立包含四年體檢數據的數據集,將第四年空腹血糖體檢值轉換為0~1表示,具體規則為空腹血糖小于7 mmol/L的數據[20]設置為0,大于等于7 mmol/L的數據設置為1。
(2)將特征轉化為特征選擇中選出來的47個新指標。
(3)將數據集分為訓練集和測試集兩部分,比例為2:1,訓練集包含4 754人,測試集包含2 375人。使用訓練集和五種算法(隨機森林、樸素貝葉斯、決策樹、邏輯回歸、支持向量機)生成血糖預測模型。
(4)將測試集輸入步驟(3)所得的模型中,得到第四年的預測值,用ROC曲線下方的面積大小(Area Under Curve,AUC)評價模型預測的性能,使用敏感度、特異度評價模型預測的準確性。
4 ?模型對比結果
為了比較不同算法的性能,分別計算不同模型的敏感度、特異度和AUC值,結果如圖3、圖4所示。
從圖3中可知,邏輯回歸和隨機森林對于血糖數據的分類都有較高的敏感度和特異度,其中,邏輯回歸算法的敏感度和特異度分別為88.51%和92.10%,隨機森林算法的敏感度和特異度分別為86.49%和85.05%,兩者敏感度差異不大。但從圖4的實驗結果來看,隨機森林對于血糖數據的分類AUC值達到了0.931,相較于邏輯回歸的AUC值更高。這說明隨機森林模型對于血糖數據分類效果更好。
5 ?結 ?論
本研究提出了一種基于三年體檢數據來預測用戶第四年是否患有糖尿病的風險預測模型。該模型通過PCA技術降低了自變量(特征變量)的維度,同時削減了變量間的高度重疊和高度相關性,能夠保證新指標之間互不相關或相關性弱。通過5種方法的實驗結果對比,隨機森林算法對于體檢數據糖尿病預測結果最佳,隨機森林算法的敏感度和特異度分別為86.49%和85.05%,AUC值達到了0.931。但由于數據本身存在著變量數據缺失的問題,很多數據不足四年,且在特征選擇中使用了新的綜合指標,可能會丟失掉與空腹血糖相關的體檢信息。在未來的研究中,我們將使用其他技術來改善模型的性能,選取作用更大的醫學檢查項目。
參考文獻:
[1] 劉子琪,劉愛萍,王培玉.中國糖尿病患病率的流行病學調查研究狀況 [J].中華老年多器官疾病雜志,2015,14(7):547-550.
[2] 張占林,孫勇,妥小青,等.隨機森林算法對體檢人群糖尿病患病風險的預測價值研究 [J].中國全科醫學,2019,22(9):1021-1026.
[3] KAVAKIOTIS I,TSAVE O,SALIFOGLOU A,et al. Machine Learning and Data Mining Methods in Diabetes Research [J]. Computational and Structural Biotechnology Journal,2017,15:104-116.
[4] POLAT K,G?NE? S. An expert system approach based on principal component analysis and adaptive neuro-fuzzy inference system to diagnosis of diabetes disease [J]. Digital Signal Processing,2006,17(4):702-710.
[5] HAN L F,LUO S L,YU J M,et al. Rule Extraction From Support Vector Machines Using Ensemble Learning Approach:An Application for Diagnosis of Diabetes [J]. IEEE Journal of Biomedical and Health Informatics,2015,19(2):728-734.
[6] TRESP V,BRIEGEL T,MOODY J. Neural-network models for the blood glucose metabolism of a diabetic [J]. IEEE Transactions on Neural Networks,1999,10(5):1204-1213.
[7] GEORGA E I,PROTOPAPPAS V C,ARDIGO D,et al. Multivariate Prediction of Subcutaneous Glucose Concentration in Type 1 Diabetes Patients Based on Support Vector Regression [J]. IEEE Journal of Biomedical and Health Informatics,2013,17(1):71-81.
[8] 余麗玲,陳婷,金浩宇,等.基于支持向量機和自回歸積分滑動平均模型組合的血糖值預測 [J].中國醫學物理學雜志,2016,33(4):381-384.
[9] GANI A,GRIBOK A V,RAJARAMAN S,et al. Predicting Subcutaneous Glucose Concentration in Humans:Data-Driven Glucose Modeling [J]. IEEE Transactions on Biomedical Engineering,2009,56(2):246-254.
[10] PRADHAN M,BAMNOTE G R. Design of classifier for detection of diabetes mellitus using genetic programming [C]//Proceedings of the 3rd International Conference on Frontiers of Intelligent Computing:Theory and Applications (FICTA),2014:763-770.
[11] 魏芬芬.灰色預測模型在血糖預測中的研究 [D].鄭州:鄭州大學,2016.
[12] 豐羅菊,王亞龍,張建陶,等.糖尿病腎病空腹血糖預測值篩選 [J].中國公共衛生,2008,24(6):727-729.
[13] 林震,王威.基于決策樹的數據挖掘算法優化研究 [J].現代計算機(專業版),2012(28):11-14.
[14] 侯玉梅,朱亞楠,朱立春,等.決策樹模型在2型糖尿病患病風險預測中的應用 [J].中國衛生統計,2016,33(6):976-978+982.
[15] 曹文哲,應俊,陳廣飛,等.基于Logistic回歸和隨機森林算法的2型糖尿病并發視網膜病變風險預測及對比研究 [J].中國醫療設備,2016,31(3):33-38+69.
[16] 肖文翔.基于電子病歷分析的糖尿病患病風險數據挖掘方法研究 [D].青島:青島大學,2016.
[17] 付陽,李昆侖.支持向量機模型參數選擇方法綜述 [J].電腦知識與技術,2010,6(28):8081-8082+8085.
[18] 黃衍,查偉雄.隨機森林與支持向量機分類性能比較 [J].軟件,2012,33(6):107-110.
[19] 龔誼承,都承華,張艷娜,等.基于主成分和GBDT對血糖值的預測 [J].數學的實踐與認識,2019,49(14):116-122.
[20] 中華醫學會糖尿病學分會.中國2型糖尿病防治指南(2017年版) [J].中國實用內科雜志,2018,38(4):292-344.
作者簡介:馬文彬(1994—),男,漢族,山東菏澤人,碩士在讀,研究方向:醫療大數據。
猜你喜歡
電子技術與軟件工程(2016年22期)2016-12-26 21:36:42
時代金融(2016年27期)2016-11-25 17:51:36
科教導刊(2016年26期)2016-11-15 20:19:33
活力(2016年8期)2016-11-12 17:30:08
科學與財富(2016年28期)2016-10-14 21:19:17
電腦知識與技術(2016年20期)2016-08-19 18:49:49
電腦知識與技術(2016年12期)2016-06-14 00:45:31
科教導刊·電子版(2016年10期)2016-06-02 19:17:03
科教導刊·電子版(2016年10期)2016-06-02 18:04:11
電腦知識與技術(2016年3期)2016-04-07 16:12:55
