基于復值卷積神經(jīng)網(wǎng)絡樣本精選的極化SAR圖像弱監(jiān)督分類方法
2020-07-13 02:26:58秦先祥余旺盛陳天平鄒煥新
雷達學報 2020年3期
秦先祥 余旺盛 王 鵬 陳天平 鄒煥新
①(空軍工程大學信息與導航學院 西安 710077)
②(國防科技大學電子科學學院 長沙 410073)
1 引言
合成孔徑雷達(Synthetic Aperture Radar,SAR)是一種主動式微波成像傳感器,可以不受云雨等天氣影響,全天時、全天候成像,能夠獲取地物或目標豐富的信息。與常規(guī)的單極化SAR相比,極化SAR能同時工作在多種極化收發(fā)組合下,信息獲取能力更強,這使得極化SAR圖像的應用倍受關注[1]。極化SAR圖像分類是當前SAR圖像解譯領域的一個熱點研究方向,在軍事和民用領域都具有重要的應用價值。例如,在軍事上可用于目標毀傷評估和態(tài)勢理解等;在民用方面可用于城市規(guī)劃、農(nóng)作物生長監(jiān)視、災情評估和海洋開發(fā)評估等[2–5]。
根據(jù)是否采用標記的訓練樣本,極化SAR圖像分類方法可以分為無監(jiān)督[6–10]和監(jiān)督[5,11–13]分類方法兩大類。前者無需標注的訓練樣本,主要從數(shù)據(jù)自身特點出發(fā),利用數(shù)據(jù)間的相似性實現(xiàn)數(shù)據(jù)的聚類劃分,或根據(jù)極化分解方法將各像素劃分為特定的散射機理類別。這類方法通常易于實現(xiàn)、自動化程度較高,但在實際中也面臨諸多問題:例如類別數(shù)目難以有效確定,或者感興趣的類別與散射機理類別不一致而難以滿足實際需求等。相比之下,后者先獲得標注的訓練樣本,這些樣本不僅反映了用戶對類別數(shù)目的要求,還蘊含了各指定類別的數(shù)據(jù)特點,從而能夠更有針對性地訓練分類器,分類精度往往更高,所得結(jié)果與具體應用需求也更為吻合。
近年來,隨著深度學習理論與技術的發(fā)展,基于深度學習尤其是卷積神經(jīng)網(wǎng)絡(Convolutional Neural Network,CNN)的方法在極化SAR圖像分類中受到大量關注,并展現(xiàn)出比很多傳統(tǒng)分類方法明顯更優(yōu)的分類性能[14–19]。例如,為了發(fā)揮CNN優(yōu)良的分類能力,文獻[16]提出了一種基于CNN的以像素鄰域為基本分類單元的極化SAR圖像分類方法;為了能夠直接處理極化SAR圖像復數(shù)據(jù),文獻[17]研究了復值CNN(Complex-Valued CNN,CV-CNN)并應用于極化SAR圖像分類;為了彌補CNN在小樣本下性能的不足,文獻[18]引入極化特征驅(qū)動CNN來實現(xiàn)極化SAR圖像分類。目前,這些方法以監(jiān)督分類方法為主,其性能的發(fā)揮通常需要大量標注訓練樣本作支撐,并且受樣本的標注質(zhì)量影響顯著。實際中,與普通光學圖像相比,極化SAR圖像的視覺直觀性較弱,其標注常需要豐富的經(jīng)驗或?qū)I(yè)知識,因此要完成極化SAR圖像的高質(zhì)量標注非常費時費力,這很大程度上限制了監(jiān)督方法尤其是基于深度學習的監(jiān)督方法在極化SAR圖像分類中的應用。
近年來,為減少監(jiān)督方法對樣本標注質(zhì)量的依賴,弱監(jiān)督分類方法受到了廣泛關注[19–26]。與傳統(tǒng)采用精細標注的監(jiān)督(或稱為全監(jiān)督)分類方法不同,弱監(jiān)督分類方法利用信息較“弱”的粗略標注的樣本,但通過充分挖掘樣本信息來彌補標注精度低帶來的不良影響。弱監(jiān)督分類中粗略標注樣本的典型方法包括物體框標注、點標注、簡筆畫標注和圖像級標注等[20,21]。相比于傳統(tǒng)像素級精細標注方法,這些方法簡單易行,實現(xiàn)效率高。
當前,弱監(jiān)督分類方法在計算機視覺領域得到快速發(fā)展,提出了諸多解決方案:如文獻[19]提出先利用目標識別預訓練網(wǎng)絡來獲取物體掩膜的策略;文獻[23]將弱監(jiān)督標簽作為隱變量來優(yōu)化分類網(wǎng)絡;文獻[26]提出在條件隨機場框架下結(jié)合顯著性先驗的方法等等。盡管如此,限于現(xiàn)實中相對有限的樣本數(shù)據(jù)集,弱監(jiān)督分類方法在SAR圖像處理領域還處于初步探索階段[27,28],發(fā)展相對滯后。鑒于此,本文針對采用物體框樣本標注的極化SAR圖像弱監(jiān)督分類問題,研究了一種基于CV-CNN樣本精選的極化SAR圖像弱監(jiān)督分類方法。基于3幅實測極化SAR圖像的實驗結(jié)果驗證了本文方法的有效性。
2 極化SAR數(shù)據(jù)與復值卷積神經(jīng)網(wǎng)絡
2.1 極化SAR圖像數(shù)據(jù)
對于常規(guī)單視極化SAR圖像,每個像素可由一個Pauli散射矢量進行表示[1]
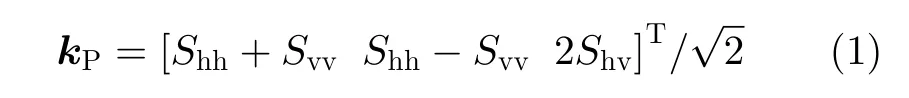
其中,上標 T表 示轉(zhuǎn)置運算,h和v 分別表示水平和垂直極化,Shv表示水平極化發(fā)射垂直極化接收的散射分量,Shh和Svv的意義類似。為抑制相干斑噪聲或壓縮數(shù)據(jù),極化SAR圖像數(shù)據(jù)往往采用多視處理[1]。多視極化SAR圖像的各像素可由一個極化相干矩陣進行表示[1]

其中<·>表示取集平均運算,上標 H表示共軛轉(zhuǎn)置運算。
2.2 復值卷積神經(jīng)網(wǎng)絡
CNN的結(jié)構(gòu)通常由輸入層、卷積層、池化層、全連接層和輸出層組成[29]。常規(guī)CNN定義于實數(shù)域,其網(wǎng)絡權(quán)重和網(wǎng)絡中傳遞的數(shù)據(jù)均為實數(shù)。實際中很多數(shù)據(jù)如SAR圖像為復數(shù)形式,這使得常規(guī)CNN不適合用于直接處理這些數(shù)據(jù)。為充分利用SAR圖像中所蘊含的信息,如幅度和相位信息,文獻[17]研究了CV-CNN并應用于極化SAR圖像的分類。
CV-CNN可視為常規(guī)CNN從實數(shù)域到復數(shù)域的擴展,其網(wǎng)絡參數(shù)均為復數(shù),也允許網(wǎng)絡的輸入為復數(shù)形式,因此可以直接用于處理如極化SAR圖像等復數(shù)據(jù),更好地保留原始復數(shù)據(jù)所蘊含的信息。與常規(guī)CNN一樣,CV-CNN通常也包括輸入層、卷積層、池化層、全連接層和輸出層等網(wǎng)絡層。對于卷積層,其功能是實現(xiàn)輸入復數(shù)據(jù)的卷積運算。設CV-CNN的第l層為卷積層,其有M(l)個輸入特征圖和N(l)個輸出特征圖,記其第m個輸入特征圖和第n個輸出特征圖分別為和,則有[17]
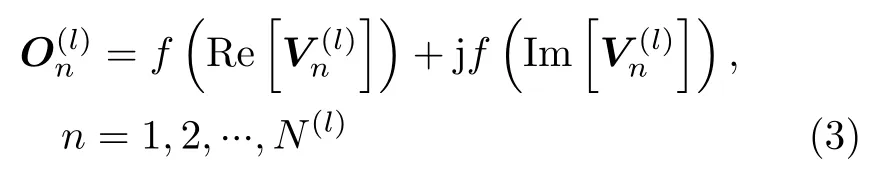
其中,j 為虛數(shù)單位,Re[·]和Im[·]分別表示求復數(shù)的實部和虛部,f(·)為一個非線性激活函數(shù)(本文中采用Sigmoid函數(shù)[29]),為一個中間量
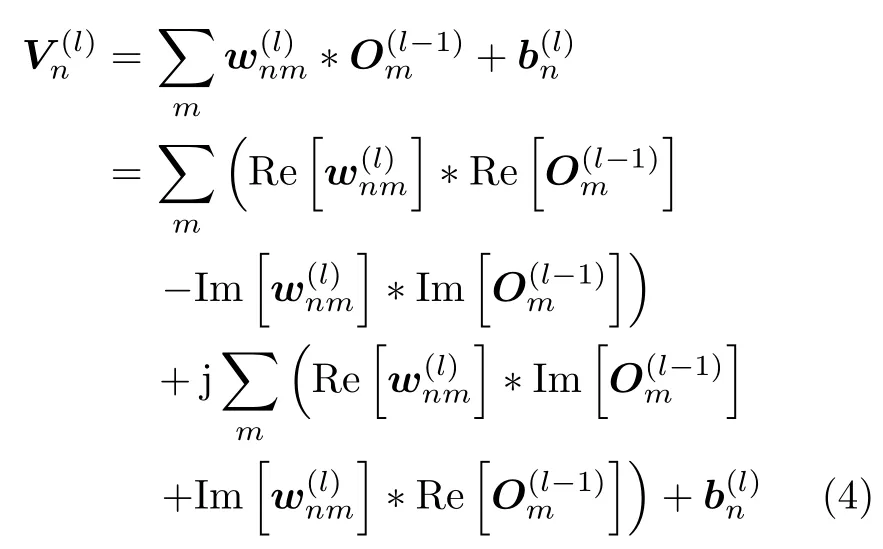
池化層實現(xiàn)輸入數(shù)據(jù)的降采樣處理,其不僅能有效減小數(shù)據(jù)量,還可以增強特征的泛化能力。目前主要有最大值池化和平均值池化兩類典型的池化方法(本文采用平均值池化方法[17,29])。全連接層將輸入特征圖的每個單元與輸出的每個單元進行兩兩連接。若CV-CNN的第k層為全連接層,其有M(k)個輸入單元和N(k)個輸出單元,記其第m個輸入單元和第n個輸出單元的值分別為和,則有
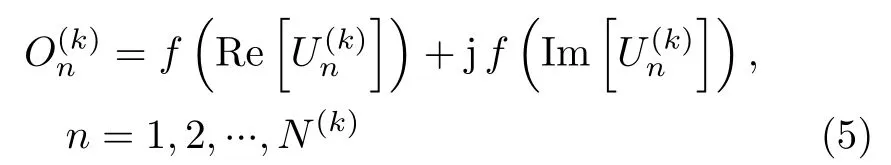
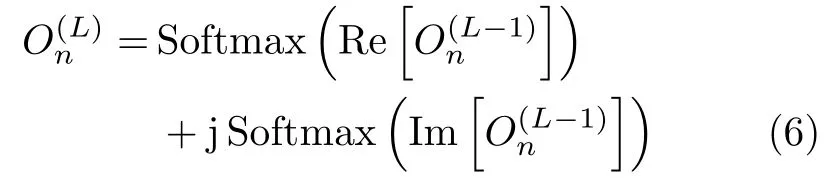
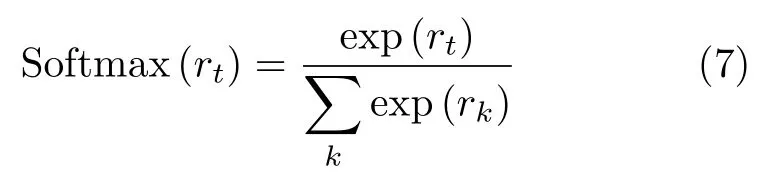
數(shù)據(jù)的真值向量采用獨熱編碼形式[17]:設總的類別數(shù)為C,則第c類的數(shù)據(jù)是真值向量gc為一個C維復向量,其第c個元素為1+j,其余元素均為0,即
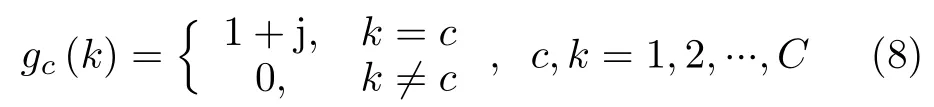
在輸出層,通過計算輸出向量O(L)與各個類別的真值向量之間的距離,將距離最小所對應的類別作為相應的輸出類別
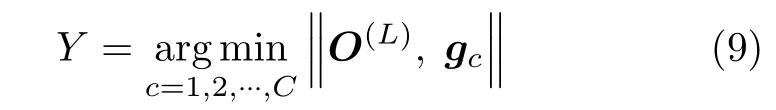
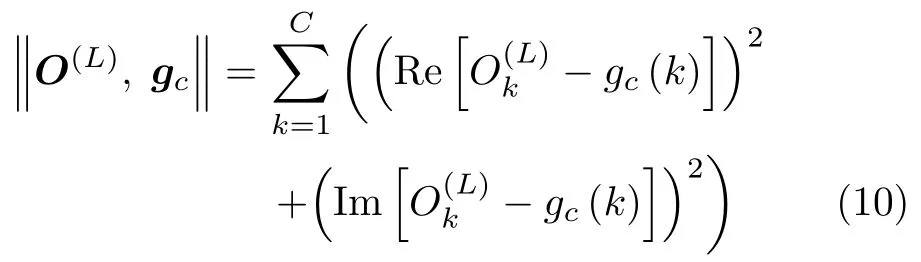
3 物體框樣本標注
在傳統(tǒng)全監(jiān)督分類方法中,訓練樣本采用像素級標注,其精細地勾畫出各個類別的分布區(qū)域。相比之下,弱監(jiān)督分類方法只需要對樣本數(shù)據(jù)進行粗略標注,其中典型的標注方法有物體框標注、點標注、簡筆畫標注和圖像級標注等[20,21]。本文主要關注物體框標注的弱監(jiān)督分類問題。為直觀說明,圖1給出了某極化SAR數(shù)據(jù)樣本的像素級標注和物體框標注的對比示意圖,其中圖1(a)為一幅極化SAR數(shù)據(jù)樣本的Pauli-RGB圖像,圖1(b)和圖1(c)分別為該圖像的像素級標注和物體框標注。對比可見,像素級標注對各類別的數(shù)據(jù)類別的空間分布進行了精細標注,而物體框標注對各類別僅框出了一個大致范圍(通常為矩形區(qū)域),然后將整個區(qū)域的數(shù)據(jù)標記為相應類別。
像素級標注可以充分利用已有數(shù)據(jù)且信息的可靠性強,但顯然,這種精細標注是十分費時費力的。相比之下,物體框標注實現(xiàn)簡單,可以顯著減少圖像標注的時間,有利于快速構(gòu)建規(guī)模較大的標注數(shù)據(jù)庫,具有廣泛的應用前景。然而,物體框標注的精度不高,所得標注數(shù)據(jù)中往往包含大量與標注類別不一致的數(shù)據(jù),本文稱之為異質(zhì)成分。若直接將物體框標注樣本用于分類器的訓練,很可能會嚴重降低分類器性能,難以獲得令人滿意的分類結(jié)果。
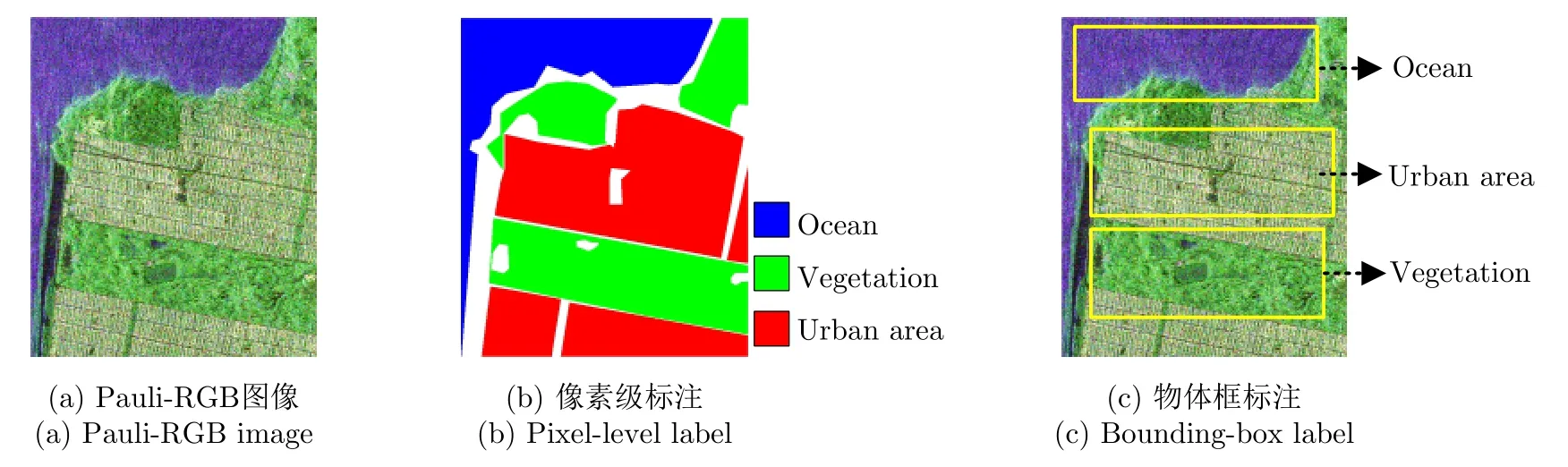
圖1 極化SAR數(shù)據(jù)樣本的像素級標注與物體框標注對比示意圖Fig.1 Comparison illustration of pixel-level label and bounding-box label for a PolSAR data sample
4 基于樣本精選的弱監(jiān)督分類
針對物體框標注樣本標注精度低的問題,本文提出一種基于CV-CNN樣本精選的極化SAR圖像弱監(jiān)督分類方法。方法主要分兩步,首先通過樣本精選方法將物體框標注樣本轉(zhuǎn)換為像素級標注樣本,然后采用傳統(tǒng)全監(jiān)督方法完成極化SAR圖像的分類。
4.1 物體框標注樣本精選
為了將物體框標注樣本轉(zhuǎn)換為像素級標注樣本,本文的基本思路是從給定的物體框標注樣本中剔除異質(zhì)成分。本質(zhì)而言,該過程是對給定標注樣本的再分類,即通過判斷給定樣本的類別標簽的正確性,精選出其中“標注正確”的樣本。分析可知,盡管物體框標注比較粗略,但物體框內(nèi)的樣本主體通常具有正確的類標簽,異質(zhì)成分所占比例相對較少。因此,若先以標注的物體框內(nèi)的像素樣本作為像素級標注樣本來訓練某分類器,再用所得分類器對樣本數(shù)據(jù)進行分類,當分類器性能較優(yōu)時,有理由相信所得分類結(jié)果中包含很多被正確分類的樣本數(shù)據(jù)。若能挑選出這部分數(shù)據(jù),將之用于分類器的再訓練,將會改善分類器的性能,進而獲得更多被正確分類的樣本數(shù)據(jù)。如此迭代反復,將有望剔除大部分異質(zhì)成分,實現(xiàn)物體框標注樣本數(shù)據(jù)的精選,獲得類似于像素級標注的樣本。圖2給出了該物體框標注樣本精選方法的基本流程圖。
給定極化SAR圖像物體框標注樣本數(shù)據(jù)集,方法首先將各物體框的類別標簽賦予到相應框內(nèi)的每個像素,形成相應的偽像素級標注樣本。若樣本數(shù)據(jù)量較大,為提高算法效率,可通過均勻的隨機采樣來減少訓練樣本。接著,利用偽像素級標注樣本訓練給定的分類器,再用訓練好的分類器對原始物體框標注樣本數(shù)據(jù)集進行分類。接著采用一定的策略對物體框標注樣本進行精選,從中選出“被正確分類”的樣本并作為新的訓練樣本,然后返回訓練樣本的隨機選取步驟。重復上述操作直到滿足算法停止條件為止,如分類的迭代次數(shù)達到指定值或者分類結(jié)果變化率小于給定的閾值。該樣本精選方法主要涉及到兩方面問題,即分類器的選擇以及判斷樣本被正確分類的策略。
鑒于CV-CNN的優(yōu)良性能,本文在樣本精選中引入該類網(wǎng)絡作為分類器。本文采用文獻[17]所給的CV-CNN模型,其網(wǎng)絡結(jié)構(gòu)如圖3所示。該網(wǎng)絡包括1個輸入層、2個卷積層、1個池化層、1個全連接層和1個輸出層。輸入層的尺寸為12×12×6,其中12×12表示輸入極化SAR圖像區(qū)域塊的大小,6表示輸入數(shù)據(jù)的通道數(shù),這里對應極化相干矩陣中的6個元素[T11T12T13T22T23T33];網(wǎng)絡中第1和第2個卷積層所包含的卷積核的數(shù)目分別為9和12,各卷積核的大小均為3×3、步長為1;此外,池化層采用2×2的平均值池化,步長為2。
對樣本的分類結(jié)果的正確性判斷,本文通過對比樣本原始標注的類別標簽和分類器所得的類別標簽來完成。對于某樣本數(shù)據(jù),若這兩種標簽一致,則認為其“被正確分類”而保留該樣本,否則舍棄。顯然,利用該方法所保留的樣本中依然可能包含異質(zhì)成分,但通過采用迭代精選的方式有望逐漸減小其所占比例。需要指出的是,通過多次迭代分類和樣本精選后,本方法不僅可以將物體框標注樣本轉(zhuǎn)換為像素級標注樣本,還同時訓練出了一個可直接用于極化SAR圖像分類的CV-CNN。
4.2 極化SAR圖像弱監(jiān)督分類流程
本文針對物體框標注樣本的極化SAR圖像弱監(jiān)督分類方法的基本步驟如下:
步驟 1 CV-CNN分類器設計。本文直接采用文獻[17]給定的CV-CNN作為分類器。
步驟 2 按照4.1節(jié)的方式迭代訓練分類器并完成物體框標注樣本轉(zhuǎn)換為像素級標注樣本,同時獲得訓練好的CV-CNN。
步驟 3 極化SAR圖像分類。利用訓練好的CV-CNN按照全監(jiān)督分類方法方式完成極化SAR圖像分類。對于待分類的極化SAR圖像的各像素,選取以其為中心的鄰域數(shù)據(jù)作為CV-CNN的輸入,其中鄰域大小與CV-CNN輸入數(shù)據(jù)的尺寸保持一致[16,17]。CV-CNN輸出結(jié)果即為相應像素的類別標簽。
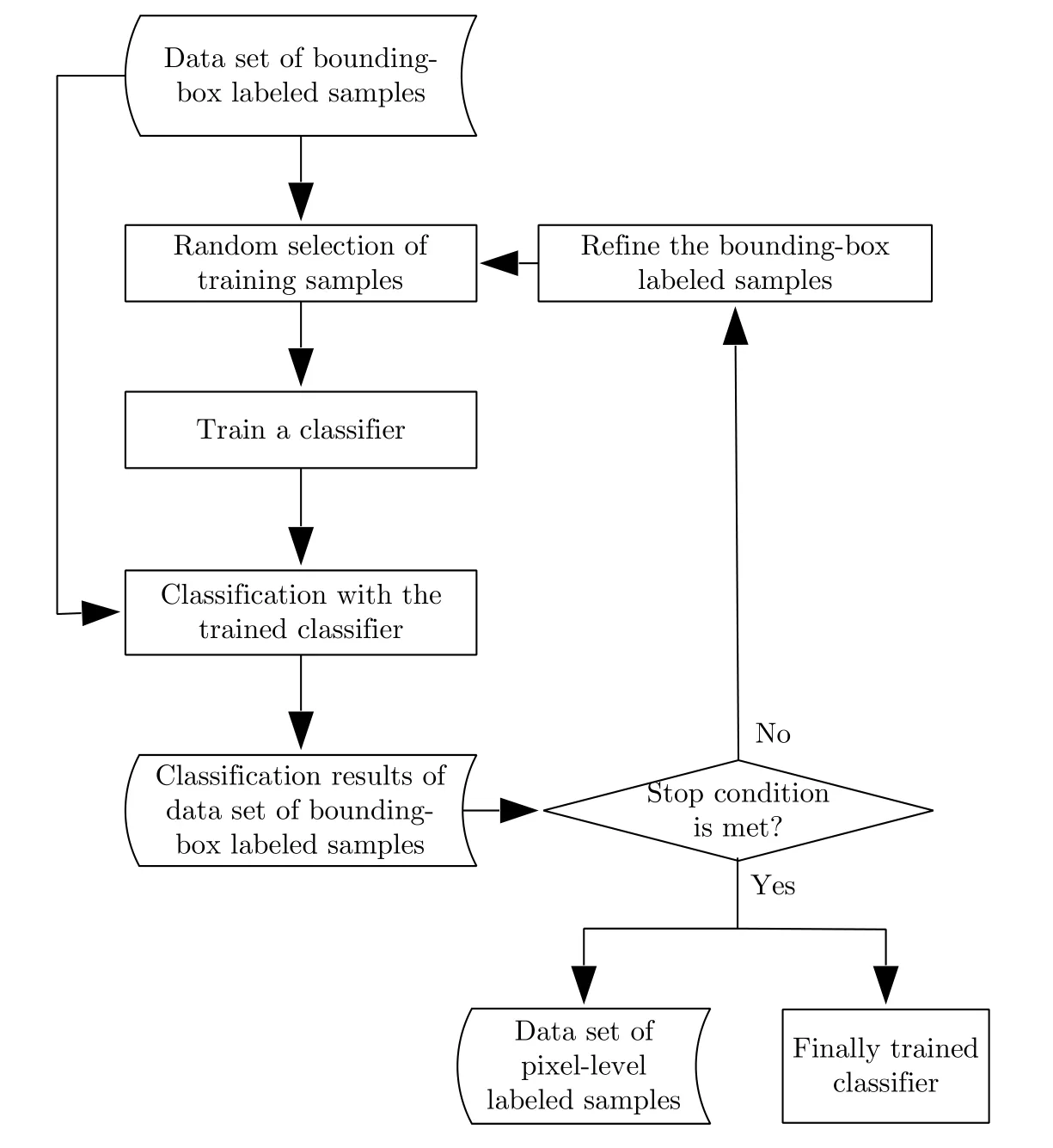
圖2 物體框標注樣本精選方法流程圖Fig.2 Flowchart of refining method for bounding-box labelled samples
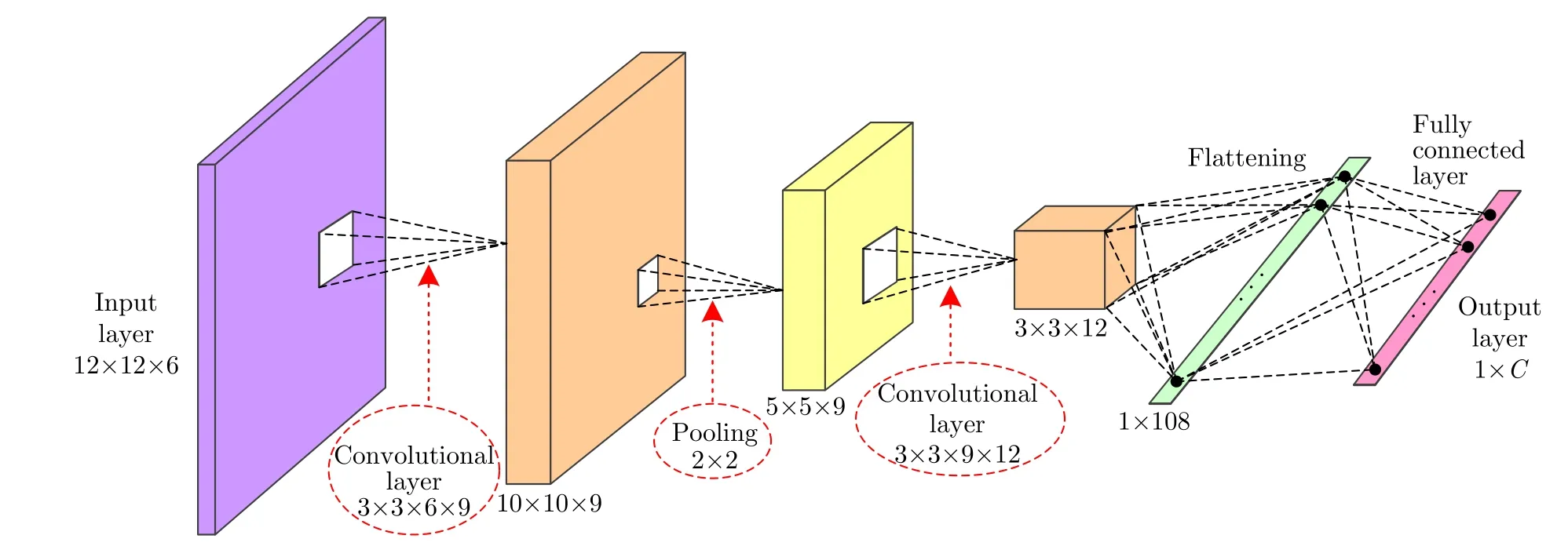
圖3 CV-CNN的結(jié)構(gòu)示意圖Fig.3 Illustration of architecture of CV-CNN
5 實驗結(jié)果與分析
5.1 實驗數(shù)據(jù)說明
為驗證方法的有效性,本文采用3幅實測極化SAR圖像數(shù)據(jù)進行實驗。第1幅實驗圖像為美國NASA/JPL的AIRSAR系統(tǒng)1990年獲取的荷蘭Flevoland地區(qū)的大小為750×1024像素的極化SAR圖像數(shù)據(jù),其包含15類典型地物,分別為蠶豆、豌豆、樹林、苜蓿、小麥1、甜菜、土豆、裸地、草地、油菜籽、大麥、小麥2、小麥3、水域和建筑區(qū)[30]。該圖像數(shù)據(jù)的Pauli-RGB圖像和真值圖分別如圖4(a)和圖4(b)所示。第2幅實驗圖像為美國NASA/JPL的UAVSAR系統(tǒng)2009年獲取的美國墨西哥灣某地區(qū)的大小為1000×1000像素的極化SAR圖像,其包含水域、植被、農(nóng)田和建筑區(qū)四類典型地物。該數(shù)據(jù)的Pauli-RGB圖像、參考光學圖像和真值圖分別如圖5(a)—圖5(c)所示。第3幅實驗圖像為我國高分三號衛(wèi)星2017年獲取的美國舊金山地區(qū)的大小為2000×2000像素的極化SAR圖像,其包含水域、植被和城區(qū)3大類典型地物,其中城區(qū)因結(jié)構(gòu)密度和建筑物朝向的不同還可細分為城區(qū)A,B和C 3種不同類別。圖6(a)—圖6(c) 分別給出了該數(shù)據(jù)的Pauli-RGB圖像、參考光學圖像以及真值圖。需要指出的是,實驗數(shù)據(jù)2和數(shù)據(jù)3的真值圖是綜合相應數(shù)據(jù)的Pauli-RGB圖像和參考光學圖像后通過手工標注獲得,實驗數(shù)據(jù)1因其獲取時間較早,目前缺乏相近時間內(nèi)該數(shù)據(jù)對應地區(qū)的光學圖像,但其真值圖已在很多文獻中給出[30],可以直接用于本文算法性能的評估。
5.2 物體框標注樣本精選實驗結(jié)果與分析
為了驗證本文物體框標注樣本精選方法的有效性,本節(jié)采用上述3幅極化SAR圖像進行實驗。實驗首先設計了一種自動構(gòu)造物體框標注的弱監(jiān)督樣本的方法。對于每幅極化SAR圖像,在圖像中隨機放置某個給定大小的矩形窗口,則窗口中通常包含一類或多類地物。根據(jù)給定的真值圖進行判斷,若窗口中某種類別的像素所占“數(shù)量比”(其像素數(shù)與窗口中的總像素之比)處于某個設定的范圍,則選擇該窗口內(nèi)的數(shù)據(jù)作為一個物體框標注樣本,其類別標注為窗口中像素數(shù)量最多的類別的標簽。因此,該方法可以用于模擬標注人員在快速標注數(shù)據(jù)時獲得的具有一定比例異質(zhì)成分的物體框標注樣本。
在本文實驗中,矩形窗口尺寸的設置與地物在圖中分布范圍大小有關,對于實驗數(shù)據(jù)1~3,窗口大小設置分別為30×30 像素、50×50 像素和80×80像素。在設置“數(shù)量比”范圍時,實驗中作如下假設:數(shù)據(jù)標注人員在獲取物體框標注樣本時,通過目視判別對某類地物框出一定范圍(或指定物體框大小后直接選擇中心點)來獲得相應的訓練樣本,并將其標注為框中數(shù)量最多的像素對應的類別。本實驗將該“數(shù)量比”的范圍設為[0.5,0.8],其中比例下限值0.5意味著所標注的框內(nèi)存在某一類別的像素占主體,而比例上限值0.8意味著要求物體框樣本錯誤率不小于20%,從而較好地反映實際中物體框標注樣本“信息較弱”的特點。需要說明的是,對于實驗數(shù)據(jù)1的第15類地物即建筑物,因其分布在一個較小區(qū)域上而不利于選擇滿足上述條件的樣本,故對該類別將數(shù)量比范圍放寬到[0.3,0.8]。對于各實驗數(shù)據(jù),各類別選取了5個物體框標注樣本,進而構(gòu)建出各實驗數(shù)據(jù)的物體框標注樣本集。圖7(a)、圖8(a)和圖9(a)分別給出這3幅極化SAR圖像的所選樣本集拼接而成的Pauli-RGB圖像,圖7(b)、圖8(b)和圖9(b)分別給出了相應的偽像素級標簽圖。可以看到,所選取的各類訓練樣本不同程度地包含了一些異質(zhì)成分。以實驗數(shù)據(jù)3為例,所選水域樣本中包含了一些陸地區(qū)域,所選植被樣本中包含了部分城區(qū),所選城區(qū)內(nèi)也包含部分植被區(qū)。因此,所選擇的這些樣本符合物體框標注樣本的特點,可以用于評價本文的弱監(jiān)督分類方法的性能。

圖4 實驗圖像數(shù)據(jù)1Fig.4 Experimental image data 1
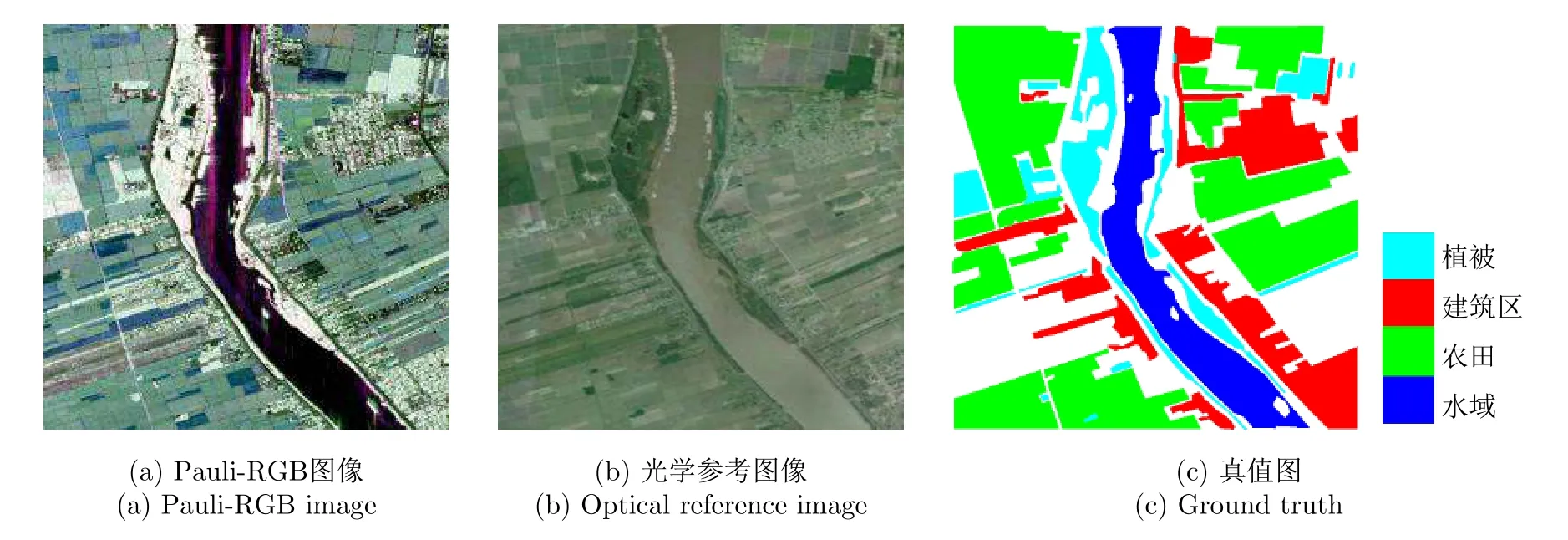
圖5 實驗圖像數(shù)據(jù)2Fig.5 Experimental image data 2
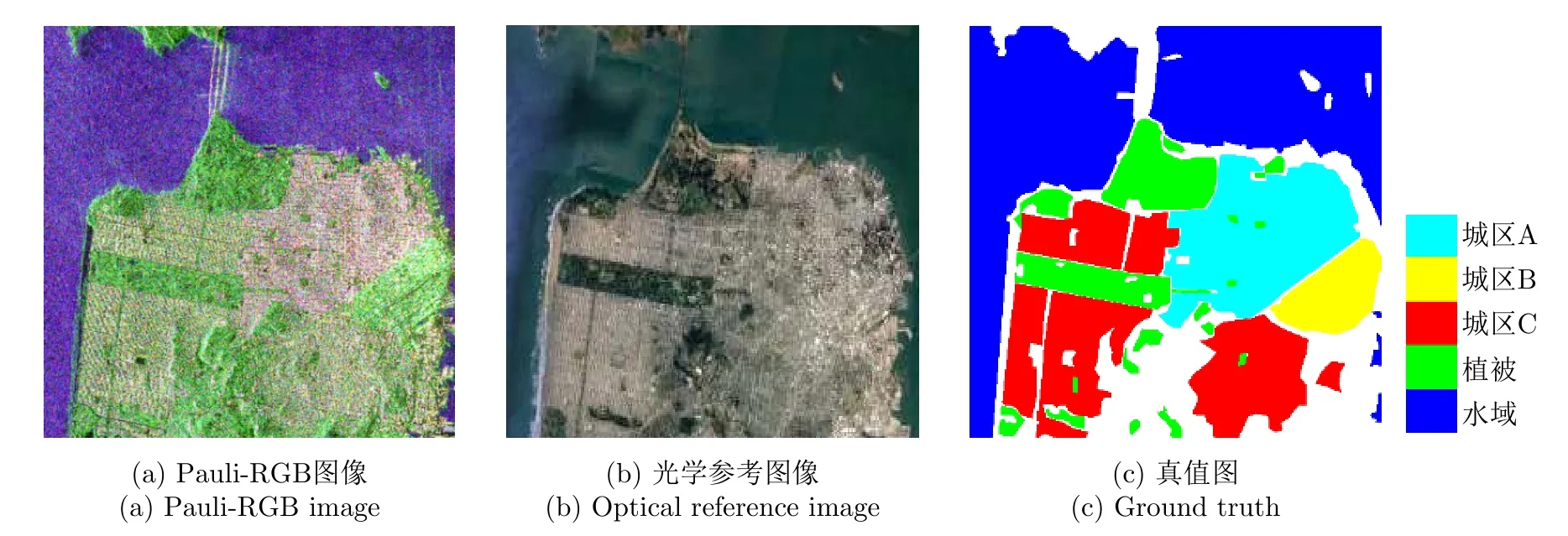
圖6 實驗圖像數(shù)據(jù)3Fig.6 Experimental image data 3

圖7 實驗數(shù)據(jù)1的物體框標注樣本集的Pauli-RGB圖像及3種方法所得分類結(jié)果和精選像素級標簽Fig.7 Pauli-RGB image of the bounding-box labelled sample set of experimental data 1 and its classification results and refined pixel-level labels with three methods
接著對各極化SAR圖像數(shù)據(jù)依次訓練CV-CNN模型。為提高算法效率,首先從給定樣本集中對每類隨機選取300個樣本用于訓練CV-CNN。訓練采用隨機梯度下降法[17,29]進行,其中訓練的超參數(shù)設置如下:學習率為0.5,樣本批量大小batchsize為100,訓練迭代數(shù)epoch為50。此外,算法的停止條件包含2個參數(shù),即最大分類迭代次數(shù)和分類結(jié)果變化率閾值。通常,隨著迭代次數(shù)的增加,樣本精選中分類結(jié)果逐漸趨于穩(wěn)定。本實驗中根據(jù)經(jīng)驗將該最大迭代次數(shù)設為10,在樣本精選結(jié)果基本趨于穩(wěn)定的同時,可避免算法過多的運算以及算法不收斂時帶來的死循環(huán)問題。另外,實驗中分類結(jié)果變化率閾值設為0.01,即當相鄰兩次迭代中的分類結(jié)果的變化率小于1%時,認為樣本精選結(jié)果已經(jīng)足夠穩(wěn)定,則停止算法迭代。最后,采用本文樣本精選方法即可獲得各樣本集的分類結(jié)果和相應的像素級標簽圖像。圖7(c)給出了采用CV-CNN獲得的實驗數(shù)據(jù)1樣本集的最終分類結(jié)果,圖7(d)給出了相應的精選樣本像素級標簽,其中白色區(qū)域表示未標注區(qū)域,對應被剔除的樣本,其他顏色對應不同的類別。類似地,圖8(c)和圖9(c)分別給出了采用CV-CNN獲得的實驗數(shù)據(jù)2和數(shù)據(jù)3的樣本集的最終分類結(jié)果,圖8(d)和圖9(d)分別給出了相應的精選樣本像素級標簽圖像。
此外,為了分析本文樣本精選方法中采用CV-CNN的性能,實驗中還采用了經(jīng)典的Wishart分類器和支持矢量機(Support Vector Machine,SVM)進行比較,即在相同的框架中分別用這兩種分類器替換CV-CNN進行樣本精選。Wishart分類器先利用訓練樣本計算各類別的類心,然后根據(jù)最小Wishart距離[1]準則實現(xiàn)極化SAR圖像各像素的分類;SVM基于LibSVM軟件[31]完成,其中模型參數(shù)采用該軟件分類模塊的默認參數(shù),極化SAR圖像各像素由極化相干矩陣的6個元素構(gòu)成的矢量表示F=[T11T12T13T22T23T33]。采用這兩種分類器的樣本精選方法對3幅實驗圖像的物體框標注樣本進行處理,所得的最終分類結(jié)果和精選后的像素級標簽圖分別如圖7(e)—圖7(h)、圖8(e)—圖8(h)和圖9(e)—圖9(h)所示。

圖8 實驗數(shù)據(jù)2的物體框標注樣本集的Pauli-RGB圖像及3種方法所得分類結(jié)果和精選像素級標簽Fig.8 Pauli-RGB image of the bounding-box labelled sample set of experimental data 2 and its classification results and refined pixel-level labels with three methods

圖9 實驗數(shù)據(jù)3的物體框標注樣本集的Pauli-RGB圖像及3種方法所得分類結(jié)果和精選像素級標簽Fig.9 Pauli-RGB image of the bounding-box labelled sample set of experimental data 3 and its classification results and refined pixel-level labels with three methods
對比圖7—圖9中各樣本集的Pauli-RGB圖像與精選的像素級標簽圖可見,3種采用不同分類器的樣本精選方法能不同程度地剔除異質(zhì)成分,獲得相對可靠的像素級標注樣本。分析可知,Wishart分類器采用最小Wishart距離準則,其性能與各類別的類心估計準確度密切相關,故相應的樣本精選方法對異質(zhì)成分較為敏感。例如數(shù)據(jù)2的樣本集中,水域樣本包含部分數(shù)值較大的異質(zhì)成分(如圖8(a)第3列的白色區(qū)域所示),使得該類別的類心估計值發(fā)生了明顯偏離,進而使得大部分水域樣本被錯分為農(nóng)田(如圖8(c)所示),相應精選的樣本則明顯不可靠(如圖8(d)所示)。與該方法相比,采用SVM的樣本精選方法性能略優(yōu),但對部分樣本精選結(jié)果不佳,例如將數(shù)據(jù)1的草地(類別9)幾乎錯分。此外,這兩種對比方法受相干斑噪聲影響明顯,并對自身起伏較大的類別(如城區(qū))難以得到較好的分類結(jié)果和樣本精選結(jié)果。相比之下,CV-CNN具有較優(yōu)的分類性能,基于該網(wǎng)絡的樣本精選方法能夠更有效地剔除異質(zhì)成分,對自身起伏較大的類別依然可以得到可靠性高的像素級標注樣本。
此外,以實驗數(shù)據(jù)1訓練樣本集的樣本精選為例,圖10給出了基于前述3種不同分類器的樣本精選方法所得分類結(jié)果的變化率關于迭代次數(shù)的變化曲線。可以看到,對于該數(shù)據(jù)而言,3種基于不同分類器的算法在前5次迭代時所得樣本分類結(jié)果的變化率較大,隨后漸趨于穩(wěn)定。由于這些分類結(jié)果變化率均大于所設定的閾值0.01,因此這些算法均在迭代次數(shù)達到設定的最大值時才停止。實際中可以根據(jù)具體應用需求對算法停止條件參數(shù)進行調(diào)整,如更側(cè)重于算法的分類性能而非效率時,可以設置較大的最大迭代次數(shù)和較小的分類結(jié)果變化率閾值;反之則可減小最大迭代次數(shù)和分類變化率閾值。
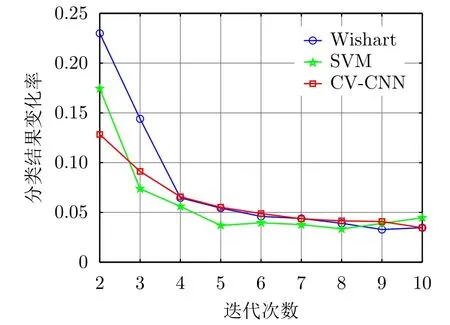
圖10 實驗數(shù)據(jù)1訓練樣本集的分類結(jié)果變化率曲線Fig.10 Curves of change rate of classification results on training set of experimental data 1
5.3 極化SAR圖像分類結(jié)果與分析
為了分析給定物體框標注樣本條件下本文的弱監(jiān)督分類方法的性能,本節(jié)采用全監(jiān)督分類方法進行對比實驗。為公平比較,全監(jiān)督方法與弱監(jiān)督方法采用同一個分類器,它們的唯一區(qū)別在于全監(jiān)督方法在訓練分類器時所用訓練樣本為原始物體框標注對應的偽像素級標注樣本,而弱監(jiān)督方法采用經(jīng)過本文樣本精選方法獲得的像素級標注樣本。為了分析其中分類器的影響,實驗中采用了CV-CNN、Wishart分類器和SVM 3種不同分類器進行對比。
圖11給出了相同物體框標注樣本條件下,基于不同分類器的全監(jiān)督和弱監(jiān)督方法對實驗數(shù)據(jù)1的分類結(jié)果,其中圖11(a)—圖11(c)分別為采用CV-CNN、Wishart分類器和SVM的全監(jiān)督方法對實驗數(shù)據(jù)1的分類結(jié)果,圖11(d)—圖11(f)分別為相應的弱監(jiān)督方法對該數(shù)據(jù)的分類結(jié)果。類似地,圖12和圖13分別給出了各分類方法對實驗數(shù)據(jù)2和數(shù)據(jù)3的分類結(jié)果。為了定量評估分類結(jié)果,表1—表3分別給出了采用不同方法所得的3幅實驗圖像各類別的分類精度,總體精度和Kappa系數(shù)[32]的值,其值越大,通常表明相應的分類結(jié)果越好。

圖11 實驗數(shù)據(jù)1的全監(jiān)督和弱監(jiān)督分類結(jié)果Fig.11 Classification results of experimental data 1 by fully-supervised and proposed weakly-supervised methods

圖12 實驗數(shù)據(jù)2的全監(jiān)督和弱監(jiān)督分類結(jié)果Fig.12 Classification results of experimental data 2 by fully-supervised and proposed weakly-supervised methods

圖13 實驗數(shù)據(jù)3的全監(jiān)督和弱監(jiān)督分類結(jié)果Fig.13 Classification results of experimental data 3 by fully-supervised and proposed weakly-supervised methods
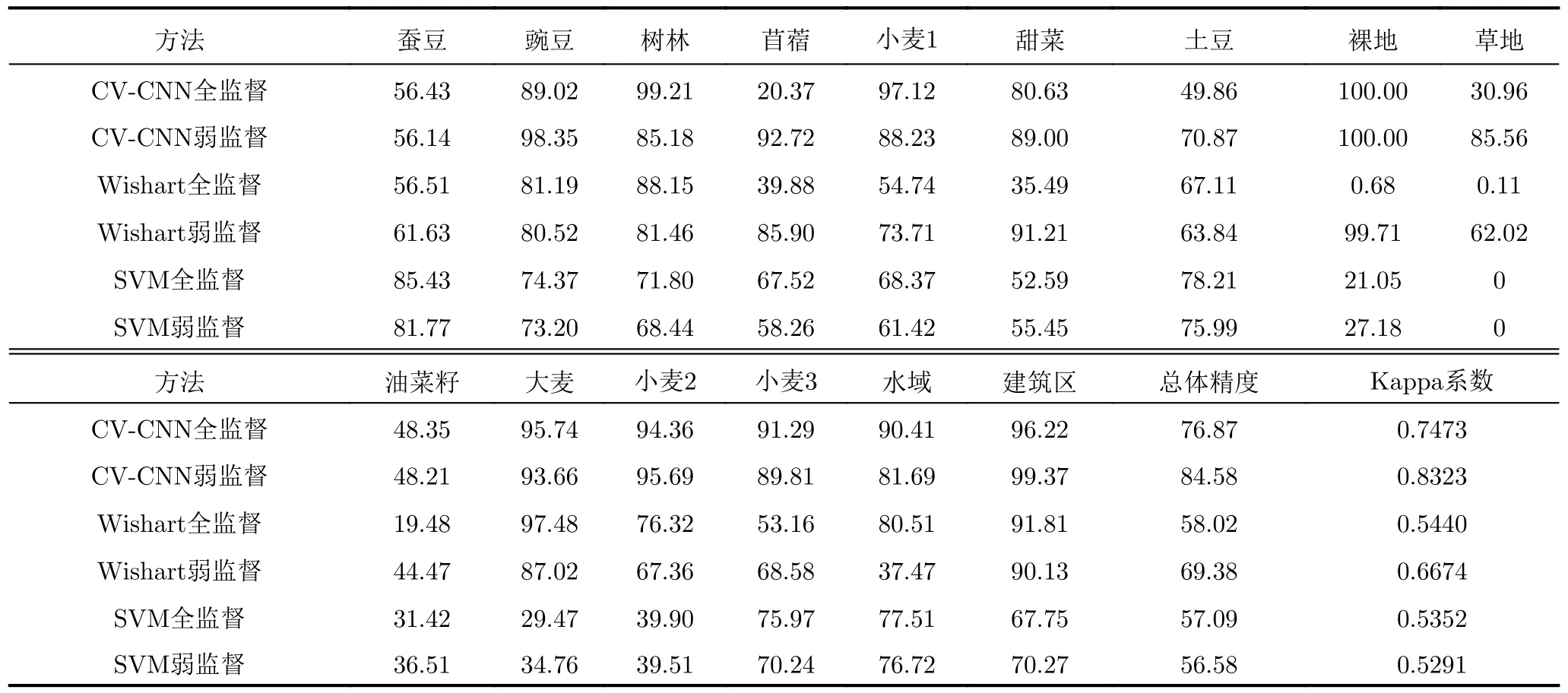
表1 實驗數(shù)據(jù)1的分類精度(%)、總體精度(%)和Kappa系數(shù)Tab.1 Classification accuracy (%),overall accuracy (%) and Kappa coefficient for experimental data 1
由圖11—圖13和表1—表3可見,本文提出的極化SAR圖像弱監(jiān)督分類方法與所用分類器的性能密切相關。在相同的分類方法框架下,采用CV-CNN所得分類結(jié)果明顯優(yōu)于采用Wishart分類器和SVM的方法所得分類結(jié)果,總體分類精度和Kappa系數(shù)的值均明顯增大。這是由于CV-CNN本身具有更優(yōu)的分類性能,可以更好地精選訓練樣本,并更優(yōu)地對極化SAR圖像數(shù)據(jù)分類。值得注意的是,當分類器性能不佳,將使得樣本精選不可靠時,采用本文的弱監(jiān)督方法所得結(jié)果甚至可能不及直接采用物體框標注樣本的全監(jiān)督分類方法所得結(jié)果,例如對于數(shù)據(jù)2,采用Wishart分類器的弱監(jiān)督分類方法的總體分類精度僅為34.54%,小于相應全監(jiān)督方法所得的36.36%。對于該數(shù)據(jù),采用SVM也有類似結(jié)果。
詳細分析采用CV-CNN的方法所得結(jié)果可見,對于實驗數(shù)據(jù)1的一些類別,直接應用物體框標注樣本的全監(jiān)督方法出現(xiàn)了比較明顯錯分,如苜蓿類和草地類的分類精度僅為20.37%和30.96%,分類的總體精度和Kappa系數(shù)分別僅為76.87%和0.7473。相比之下,采用本文精選樣本的弱監(jiān)督分類方法所得結(jié)果得到了較明顯的改善,如苜蓿類和草地類的分類精度分別提高為92.72%和85.56%。整體分類結(jié)果與真值圖更為接近,總體精度和Kappa系數(shù)值分別提升為84.58%和0.8323。此外,從圖12、圖13和表2、表3中可以看到,對實驗數(shù)據(jù)2和數(shù)據(jù)3的分類也有類似的結(jié)果。例如,對于實驗數(shù)據(jù)2,全監(jiān)督方法對植被和水域的分類精度較高,均超過90%,但對農(nóng)田尤其是建筑區(qū)的分類結(jié)果較差,建筑區(qū)的分類精度僅為64.91%。相比之下,本文弱監(jiān)督方法對植被和水域的分類精度與全監(jiān)督分類方法所得結(jié)果相當,但對農(nóng)田的分類精度由82.42%提升到93.34%,對建筑區(qū)的分類精度由64.91%提升到75.88%,均提升10%左右。整體而言,分類的總體精度約提升了8%,Kappa系數(shù)提高超過0.1。對于實驗數(shù)據(jù)3,全監(jiān)督方法對水域、植被和城區(qū)B和城區(qū)C的分類結(jié)果較好,但不能有效區(qū)分城區(qū)A和城區(qū)C,將大部分城區(qū)A像素錯分為城區(qū)C像素。城區(qū)A的分類精度僅為7.55%,而總體分類精度和Kappa系數(shù)分別僅為74.56%和0.6466。相比之下,本文弱監(jiān)督方法能夠有效地區(qū)分不同類別,所得分類結(jié)果與真值圖較為接近,所得各類別的分類精度均超過80%,總體精度達到了91.05%,Kappa系數(shù)為0.8731,明顯高于全監(jiān)督方法所得的結(jié)果。上述實驗結(jié)果表明,物體框標注樣本中的異質(zhì)成分嚴重影響了全監(jiān)督分類方法的性能,而本文弱監(jiān)督分類方法通過樣本精選有效地減小了異質(zhì)成分的不良影響,能夠獲得明顯更優(yōu)的分類結(jié)果。
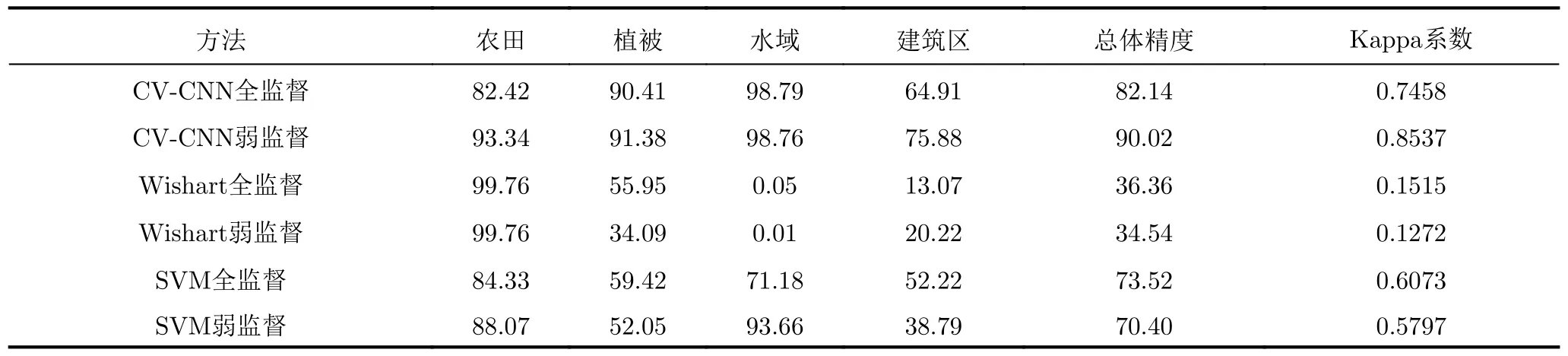
表2 實驗數(shù)據(jù)2的分類精度(%)、總體精度(%)和Kappa系數(shù)Tab.2 Classification accuracy (%),overall accuracy (%) and Kappa coefficient for experimental data 2
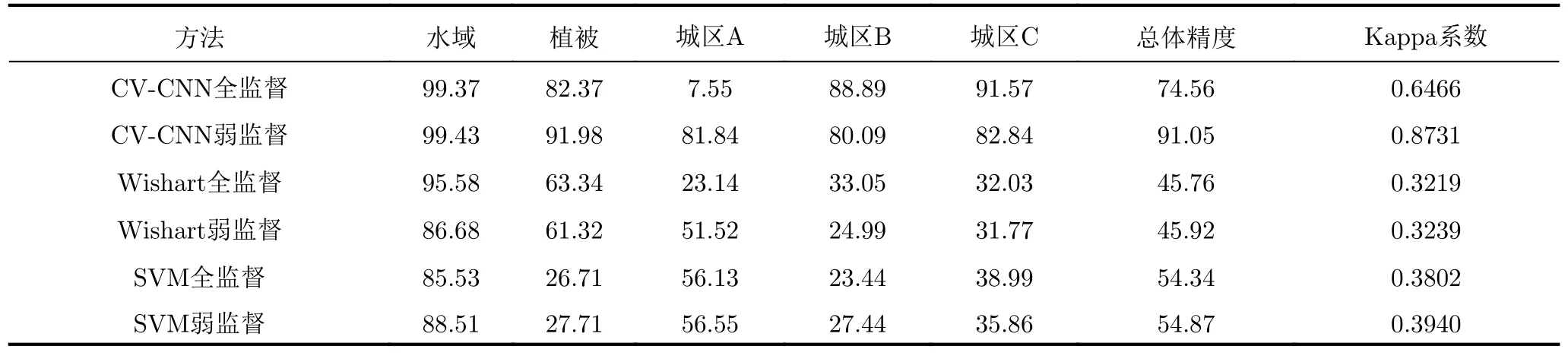
表3 實驗數(shù)據(jù)3的分類精度(%)、總體精度(%)和Kappa系數(shù)Tab.3 Classification accuracy (%),overall accuracy (%) and Kappa coefficient for experimental data 3
6 結(jié)束語
針對物體框標注樣本包含異質(zhì)成分而影響監(jiān)督分類方法性能的問題,本文提出了一種基于CV-CNN樣本精選的極化SAR圖像弱監(jiān)督分類方法。首先基于CV-CNN迭代分類策略剔除原始物體框標注樣本中的異質(zhì)成分,并同時訓練出可用于分類的CV-CNN,然后所得CV-CNN完成極化SAR圖像分類。通過3幅實測極化SAR圖像進行實驗,結(jié)果表明,本文方法能夠有效剔除樣本中的異質(zhì)成分,所得結(jié)果明顯優(yōu)于采用原始樣本訓練的CV-CNN所得結(jié)果。此外,在樣本精選中采用CV-CNN方法性能明顯優(yōu)于采用經(jīng)典的Wishart分類器和SVM。后續(xù)工作可考慮進一步優(yōu)化CV-CNN或采用性能更優(yōu)的其他分類器來代替CV-CNN。
猜你喜歡
數(shù)學小靈通(1-2年級)(2021年4期)2021-06-09 06:25:56
人大建設(2020年4期)2020-09-21 03:39:12
中學生數(shù)理化·七年級數(shù)學人教版(2019年4期)2019-05-20 10:06:32
中學生數(shù)理化·七年級數(shù)學人教版(2018年6期)2018-06-26 08:36:06
初中生世界·七年級(2017年9期)2017-10-13 22:27:46
人大建設(2017年2期)2017-07-21 10:59:25
人大建設(2017年9期)2017-02-03 02:53:31
Coco薇(2016年2期)2016-03-22 02:42:52
Coco薇(2015年1期)2015-08-13 02:47:34
小雪花·成長指南(2015年4期)2015-05-19 14:47:56
