基于人眼感知的無參考色調映射圖像質量評價
2020-07-14 02:51:12馬華林張立燕
計算機應用與軟件 2020年7期
馬華林 張立燕
1(浙江工商職業技術學院 浙江 寧波 315012)2(寧波大學信息科學與工程學院 浙江 寧波 315012)
0 引 言
HDR圖像相比低動態范圍(Low Dynamic Range,LDR)圖像能夠表示更大的亮度范圍,其亮度范圍大約是10-4cd/m2~105cd/m2[1-2]。LDR圖像能表示的動態范圍不超過3個數量級,但人類視覺系統在真實場景中可以接受的動態范圍可以達到6個數量級。因此,HDR圖像對用戶來說感受更真實更有吸引力。隨著成像和計算機圖形學技術的發展,HDR圖像的獲得越來越容易。然而,HDR顯示設備比較昂貴[3],超出了普通消費者的承受范圍。為了解決這個問題,產業界和學術界開發了許多色調映射算子[4],TMO能夠把HDR圖像轉換成LDR圖像,轉換后的LDR圖像被稱為色調映射圖像(Tone-mapped Image,TMI)。由于TMI相對HDR圖像縮小了動態范圍,不可避免地產生失真,例如亮度信息丟失、結構信息丟失、不自然的顏色等。針對一個HDR圖像,不同的TMO產生的效果不一樣。因此,TMI質量評價對于選擇合適的TMO和改進TMO本身具有重要的研究意義。
TMI質量評價分為主觀質量評價和客觀質量評價,而早期的TMO性能評價主要采用主觀質量評價。因為人眼是TMI的最終接受者,主觀質量評分具有準確性高的特點。然而,主觀質量評價[5]具有三方面的缺點:主觀質量評價比較耗時費力,需要昂貴的HDR顯示器和多個測試人員多次實驗;主觀質量不能嵌入到圖像處理系統來改進TMO;主觀評價由于人為的一些不確定因素導致評價的誤差,例如對于主觀評分相近的兩個圖像人眼也很難判斷哪個圖像更好一點。傳統的客觀質量評價方法假定參考圖像和測試圖像具有相同的動態范圍,因此傳統的客觀質量評價方法不能直接評價TMI。
近年來,全參考TMI質量評價算法取得了豐碩的成果。Yeganeh等[5]是最先關注TMI質量評價的學者之一。他們首次建立了色調映射圖像數據庫(Tone-mapped Image Database,TMID),可以下載并用于評價TMI質量評價算法的性能。同時,他們提出了一種全參考TMI質量評價方法(Tone Mapped Image Quality Index,TMQI)。這個方法的基本思想是高質量的TMI不但要保護HDR圖像的結構信息,還要保留圖像的自然場景統計特性(Natural Scene Statistics,NSS)。Nafchi等[6]基于圖像的局部相位信息提出了FSITM方法,該方法考慮了圖像的顏色信息,但沒有考慮圖像的自然度。Kundu等[7]針對TMQI均勻池化的缺點,在TMQI基礎上加入了視覺注意力模型,運用感知池化策略提升質量評價算法的性能。Xie等[8]使用字典學習技術在稀疏域提取局部結構相似度和全局自然度,合并這兩個特征提出了一種全參考質量評價算法SMTI。鑒于色調映射圖像失真類型多的特點,Hadizadeh等[9]從結構保真度、自然度、亮度、顏色等方面提取了八類特征來評價TMI質量。
無參考TMI質量評價相對全參考TMI質量評價具有更強的實用性。由于TMI失真通常不會出現模糊、塊效應等類型的失真,傳統的無參考質量評價算法不適合評價TMI。Gu等[10]結合信息量、結構、自然度三方面提出了BTMQI算法,該算法取得了很好的效果,但沒有考慮TMI的顏色失真。Yue等[11]模擬人腦對顏色信息的處理過程來評價TMI質量,從簡單細胞的響應中提取紋理信息特征,從復雜細胞的響應中提取結構和紋理信息。本文提出一種基于人眼感知的無參考色調映射圖像質量評價方法,主要貢獻如下:
(1) 首次采用聚類算法針對TMI高亮區、低暗區曝光異常的特點把色調映射圖像分成暗區、中間區、亮區,根據物理亮度距離與聚類中心亮度值的特性,優化了使用K-means聚類對TMI分區的方法。相對不分區的色調映射圖像質量評價方法顯著提高算法性能。
(2) 在色調映射圖像質量評價研究中首次使用非負矩陣分解方法,根據TMI灰度圖像非負矩陣分解獲得的系數特性,提出了一種新的圖像顯著性區域識別方法。
(3) 結合亮度和顏色兩種信息來提取圖像自然度,發現了亮度自然度和顏色自然度的互補性,相對單獨使用顏色自然度或者亮度自然度顯著提高了算法的SROCC指標。
1 評價方法設計
根據Weber定律,人眼能感受到的最小亮度變化應滿足ΔS=KS,其中K為常量,當亮度值S相近時,對應的能被人眼感知的最小亮度變化范圍ΔS也相近,按照祖母神經元理論人眼感受到亮度變化的原因是由一組感受S+ΔS亮度的神經細胞興奮所致。因此,聚集亮度感知變化范圍相似的細胞為同一個類別,分別分析每一類細胞感知到的圖像質量。本文首先把TMI轉換成灰度圖像,然后使用K-means聚類算法把灰度圖像按照亮度值進行聚類,每一類對應一個區域,在多個區域分別提取特征來評價圖像質量。
根據TVI曲線人眼視覺系統具有5個亮度適應等級[12],因此分別把色調映射圖像分成3個區域、4個區域、5個區域在TMID[5]圖像數據庫上進行實驗。例如對于三個區域的劃分,首先把色調映射圖像用K-means聚類算法分成3個區域,分別提取每個區域的信息熵特征,然后用SVM聚合三個信息熵特征預測圖像質量評分。選取Pearson線性相關系數(Pearson Linear Correlation Coefficient,PLCC)、Spearman秩相關系數(Spearman Rank-order Correlation Coefficient,SROCC)作為評價指標分別評價圖像預測值與主觀評分的準確性和一致性。
如表1所示,把色調映射圖像劃分成三個區域時,信息熵特征的性能指標是最好的,這三個區域分別是亮區、中間區、暗區。色調映射過程會縮小TMI的動態范圍,導致TMI圖像的高亮區和低暗區細節丟失,從而影響TMI的質量。如圖1所示,亮區包含了曝光過度的區域(高亮區域),同理,對于曝光不足的圖像,暗區包含低暗區,因此三個區域的劃分體現了TMI圖像的特性。
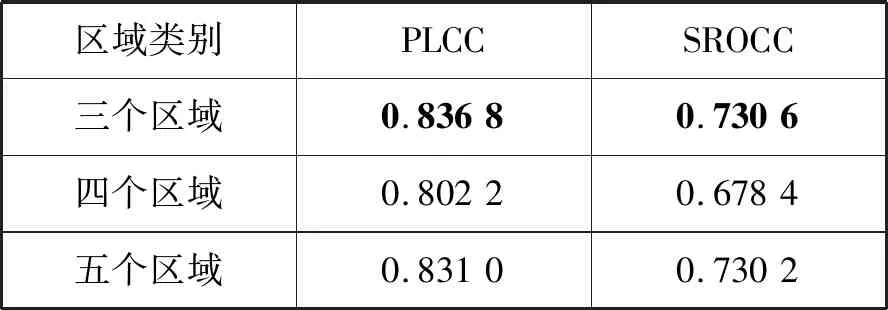
表1 不同區域劃分方法信息熵特征的性能指標

(a) 灰度圖 (b) 分成三個區域后圖1 TMID數據庫中的一幅圖
K-means聚類時只考慮像素點到聚類中心的距離來確定像素點的類別,沒有考慮人眼對亮度感知的非線性特性。設聚類中心亮度值為S1,感知亮度為P1,某個像素點像素亮度值為S2,感知亮度為P2。根據費希納定理:
(1)
則亮度感知差P2-P1和S2與S1的關系為:
(2)
在K-means算法中S1和S2的物理亮度距離為:
D=(S2-S1)2=S12×(10P2-P1-1)2
(3)
對于相近的人眼感知差P2-P1,物理亮度距離與聚類中心的亮度值成正比,即人眼對暗區聚類時與聚類中心的距離要短一些,對中間區域聚類時與聚類中心的距離要長一些。因此,采用如下算法對色調映射圖像的三個區域進行調整。
設L為圖像像素亮度值,C1、C2、C3分別為暗區、中間區、亮區的聚類中心,則三個區域的分類如下:
(4)
如表2所示,采用式(4)對三個區域的分區進行調整后,信息熵特征的PLCC和SROCC都明顯提升,說明分區的調整方法符合人眼的感知特性。
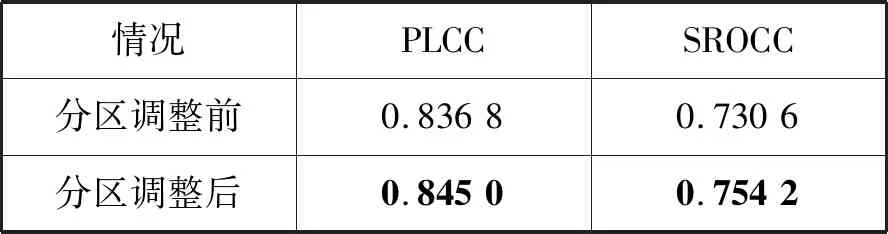
表2 區域調整前后信息熵特征的性能指標
TMI失真主要表現為信息細節的丟失、不自然的顏色、全局亮度和對比度的失真。因此,本文算法綜合考慮了TMI的失真特點。如圖2所示,本文主要提取了聚類感知特征、顯著性區域特征、自然度特征。聚類感知特征在亮度域上提取,先把TMI轉換成灰度圖,根據亮度信息進行聚類,把圖像分成亮區、暗區、中間區三個區域,在每個區域分別提取面積比率和信息熵兩個特征。生理學和心理學的一些證據[13]表明人眼觀察一幅圖像時先看圖像的整體,人腦會抑制圖像中高頻出現的特征,視覺注意力容易關注偏差比較大的區域,即顯著性區域。假設圖像中一個M×M區域具有亮區、暗區、中間區這三個區域中兩個或兩個以上區域的像素,這樣的區域稱為混合區域。混合區域中像素間的亮度值差異比較大,具有顯著性區域的特點。本文通過對TMI的非負矩陣分解得到測試圖像對應的系數,對系數進行分析識別出TMI的混合區域,在混合區域提出塊比例、信息熵特征。由于TMO處理過程縮小了HDR圖像的動態范圍,影響了TMI的自然度,因此提取了亮度通道和顏色通道的自然統計特征。最后使用機器學習方法對所有特征進行回歸,提出了無參考TMI質量評價方法。
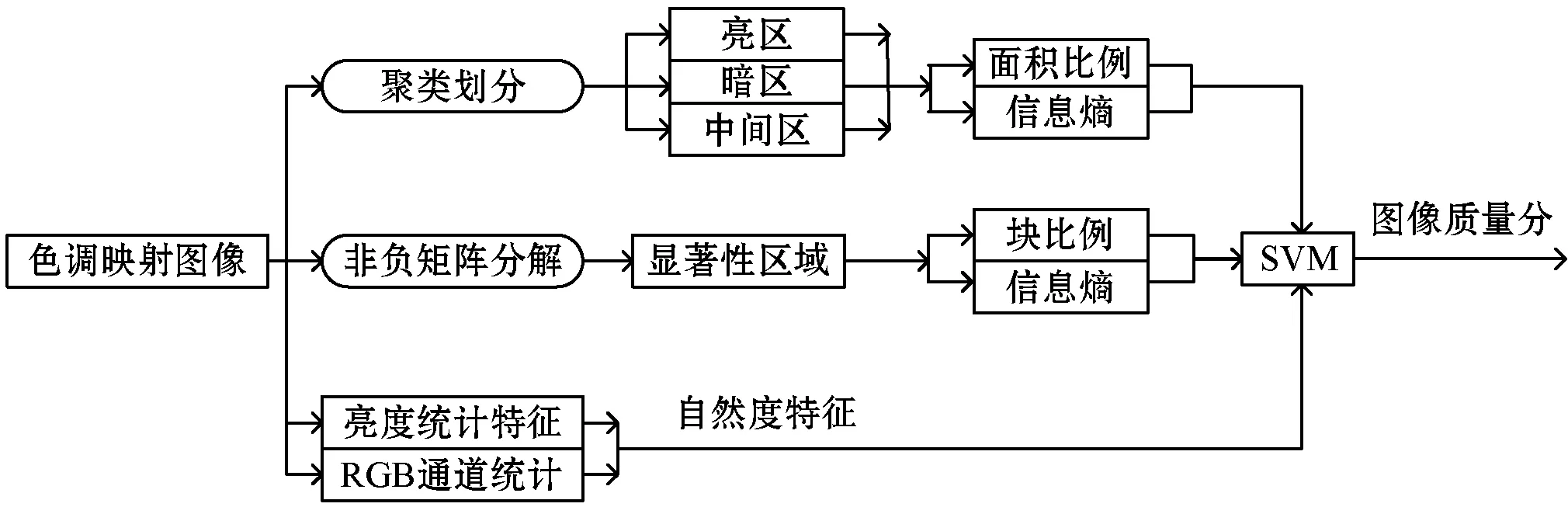
圖2 無參考TMI質量評價框架
1.1 聚類感知特征
在視覺注意處理中,人類視覺系統對視覺細胞產生的刺激進行融合,通過不同的信息特征進行聚類,形成人類視覺系統的注意力分配圖,因此聚類是人類視覺系統的固有功能。設m×n的灰度圖像I,I(x,y)表示圖像I中(x,y)像素點的亮度值,設暗區、中間區、亮區的像素亮度值集合分別為RL、RM、RH,則:
(5)
式中:C3、C1為亮區和暗區的聚類中心。信息熵是衡量信息量的有效方法,設p為概率密度,對RL、RM、RH,I分別求信息熵為:
(6)
EL、EM、EH分別表示暗區、中間區、亮區的信息熵。考慮到人眼觀察圖像時先整體后局部的特點,同時提取全局信息熵EG。
由于TMI圖像容易出現過曝光或欠曝光的區域,這些區域的大小會影響圖像的質量,因此提取了三個區域的面積比例作為特征。設N(·)函數表示計算圖像或者圖像塊的像素個數,則每個區域的面積比例可以表示為:
(7)
RatioL、RatioH、RatioM分別表示暗區、亮區、中間區的面積比率。聚類感知特征向量Fcluster為:
Fcluster={EL,EM,EH,EG,RatioL,RatioM,RatioH}
1.2 顯著性區域特征
當人眼看一幅圖像時注意力會被吸引到圖像中的一部分區域,這部分區域被稱為顯著性區域,是大部分人認為圖像中重要的或者顯著的部分。顯著性區域的圖像質量顯然影響人眼對圖像整體質量的評價。Goferman等[13]認為人眼觀察一幅圖像時先看圖像的整體,人腦會抑制圖像中高頻出現的特征,視覺注意力容易關注偏差比較大的區域,即顯著性區域。本文對TMI灰度圖像的非負矩陣分解獲得對應圖像的系數,通過對系數的直方圖的分析,提出了一種混合區域的識別方法,然后對混合區域提取信息熵,塊比率等特征。
許多研究表明稀疏表示符合人腦對圖像信號的認知,非負矩陣分解(NMF)與稀疏表示的字典學習類似。非負矩陣分解是把一個數據矩陣M分解為兩個非負矩陣W和S的乘積,W為特征矩陣對應字典學習的原子矩陣,S為編碼矩陣。數據矩陣M可以看作特征矩陣W中每一列和S中對應系數的線性組合,由于S的非負性,M是由W中的每一列按照S決定的權重系數累加而成,由于W中的每一列就是一個圖像塊,因此非負矩陣分解與部分組成整體的直觀認知相符。

圖3 從TMID數據庫中選取的原始訓練圖像
對于訓練樣本庫M,NMF的目標是尋找特征矩陣W=[W1,W2,…,Wr]∈Rm×r和S=[S1,S2,…,Sn]∈Rr×n來近似訓練樣本矩陣M:
M=WS
(8)
式中:r是大于零的整數,表示特征矩陣中列向量的個數。W和S的尋找過程可以轉化為如下優化問題:
(9)
本文用Lin[14]的方法計算出了W和S,W就是通過訓練庫訓練得到的特征矩陣。對于一個測試圖像塊轉化而成的列向量Ti∈Rm×1,則得到Ti非負矩陣分解后的編碼矩陣Fi∈Rr×1為:
Ti=WFi?Fi=(WTW)-1WTTi
(10)
式中:(WTW)-1WT是W的偽逆矩陣。對于測試圖像T=[T1,T2,…,Tn]獲得編碼矩陣F=[F1,F2,…,Fn],n為一幅測試圖像包含的圖像塊的個數。
TMI的混合性區域是區域中像素來自兩種或兩種以上聚類感知區域,例如一個圖像塊有三分之一的亮區像素和三分之二的中間區像素。把亮區、暗區、中間區、混合區圖像塊分別進行非負矩陣分解,對每個區域的編碼矩陣進行直方圖分析,如圖4所示。
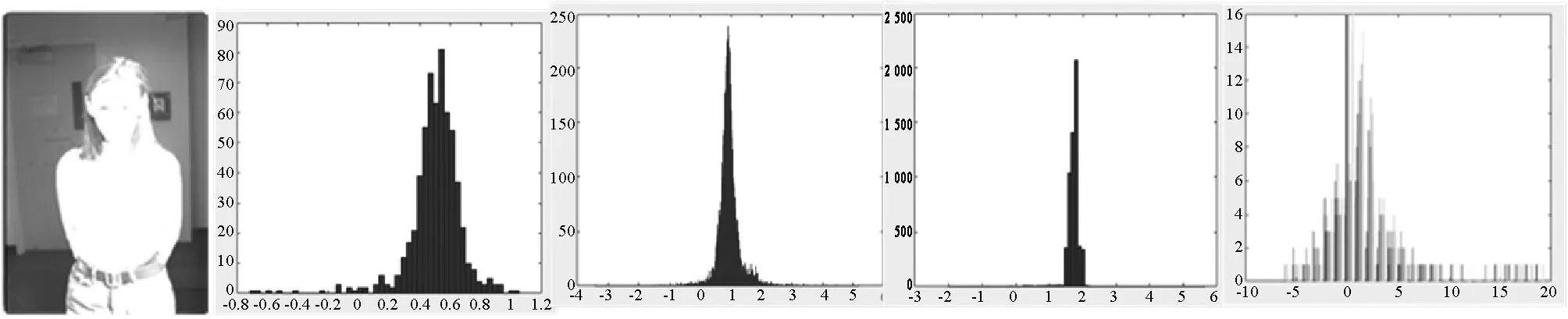
(a) 原圖 (b) 暗區系數 (c) 中間區系數 (d) 亮區系數 (e) 混合區系數圖4 亮區、暗區、中間區、混合區編碼矩陣直方圖
可以看出,圖像暗區、中間區、亮區的編碼矩陣的系數值比較小,混合區系數有較大值。因此可以通過分析編碼矩陣的最大值來判斷顯著性區域,設閾值TH,定義顯著性區域S如下:
S={Ti|max(Fi)>TH,Fi=(WTW)-1WTTi}
i=1,2,…,n
(11)
信息熵能有效衡量圖像的信息量,根據式(6)對S的所有像素求信息熵獲得顯著性區域的信息量ES。顯著性區域面積越大,對圖像質量的影響越大,因此提取顯著性區域的面積比例RatioS:
(12)
式中:N(·)函數表示計算圖像或者圖像塊的像素個數;I表示圖像。顯著性特征FS為:
FS={ES,RatioS}
1.3 自然度特征
HDR圖像經過色調映射后可能會出現曝光過度或者曝光不足的現象,造成TMI看起來不自然。然而,高質量的TMI不應當破壞其自然特性。TMI的自然度失真主要體現在圖像過亮、過暗、不自然的顏色,因此本文考慮基于亮度和顏色提取自然度特征。
(1) 亮度自然度特征。本文采用了TMQI[5]的自然度統計模型,該模型使用3 000幅包括動物、夜景、建筑、草地等14個不同類別場景的自然圖像。首先把每一幅圖像轉化成灰度圖像,然后把灰度圖像分割成11×11的圖像塊,分別求出每個圖像塊的均值與標準差,最后統計一幅圖像中所有圖像塊的均值與標準差的均值,獲得一幅圖像的均值和標準差。圖像的均值、標準差分別與高斯概率密度函數和Beta概率密度函數能夠很好地擬合。兩個概率密度函數計算如下:
(13)
(14)
式中:B(·)是Beta函數,模型的參數設置為μm=115.94,αm=27.99,αd=4.4,βd=10.1。TMQI的亮度和對比度的聯合概率如下:
(15)
式中:K是隨著Pm和Pd改變的標準化因子,K=max{Pm,Pd}使得統計自然度N標準化。
(2) 顏色自然度。本文采用Wang等[15]提出的基于顏色空間的自然度統計方法,該方法表明局部標準化顏色系數(local normalized color coefficients,LNCC)服從高斯分布,LNCC可以表示為:
(16)
式中:IC(i,j)是給定圖像的C顏色通道某個像素的值,(i,j)是圖像的空域坐標。
(17)
(18)
采用廣義高斯函數(generalized Gaussian distribution,GGD)來擬合LNCC參數。GGD概率密度函數如下:
(19)
式中:Γ(·)是伽馬函數。β為:
(20)
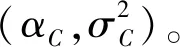
如表3所示,RGB顏色空間自然度特征獲得了最好的性能,因此選擇RGB顏色空間來提取顏色自然度特征FC:
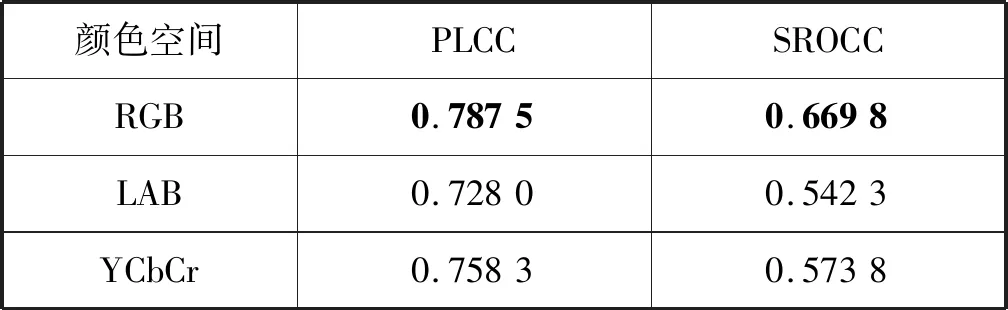
表3 RGB、LAB、YCbCr顏色空間自然度特征性能指標
1.4 聚合策略
本文提取了聚類感知、顯著性區域、自然度三類特征共16個,設V是TMI的特征向量,可以表示為:
V={FC,FS,N,FC}
(21)
特征提取之后需要一個回歸模型來建立一個函數,這個函數能夠映射特征向量到主觀圖像質量評價分。由于支持向量機(Support Vector Machine,SVM)在圖像處理領域得到廣泛的應用,因此把訓練圖像的特征向量和對應的MOS值輸入支持向量機訓練出一個預測模型f(·),把測試圖像的特征向量輸入預測模型獲得圖像的客觀質量預測值Q。
2 實驗結果與分析
2.1 實驗數據庫和性能指標
本文在TMID數據庫上對提出的算法進行了相關性能指標驗證。TMID數據庫由加拿大滑鐵盧大學開發,數據庫中包括15幅不同場景的HDR圖像,在每一幅HDR圖像上使用8種TMO總共生成120幅TMI。主觀實驗邀請了20位測試人員,分別將每幅HDR圖像對應的8幅TMI按主觀質量的好壞進行排序,序號1~8作為分數,然后將每幅TMI的平均分作為主觀質量分數。
根據視頻質量專家組(video quality expert group,VQEG)的建議,PLCC和SROCC兩個參數經常被用來檢測各種圖像質量評價方法的性能。SROCC用來評價客觀質量評價算法和主觀評價的一致性。PLCC用來評價客觀質量評價算法和主觀評價的準確性。在計算PLCC之前,為了消除主觀質量評價引入的非線性因素,需對客觀質量評價結果和主觀質量評價結果進行非線性擬合,本文采用了五參數Logistic擬合方法。PLCC和SROCC值越大表示客觀質量評價算法的性能越好。
2.2 訓練集大小的影響
采用交叉驗證的方法來評價本文提出的無參考色調映射質量評價方法。首先將TMID圖像庫中的TMI分為兩個不重疊的圖像子集。第一子集為訓練圖像,包含了數據庫中120×n%的測試色調映射圖像,并用這部分圖像建立本文所需的預測模型。第二個子集為余下的120×(1-n%)色調映射圖像并作為測試圖像。為了消除性能偏差,本文隨機重復1 000次之前的訓練-測試過程,并將這1 000次測試所得到的性能指標的中值作為最終的性能指標。如表4所示,隨著訓練集尺寸的增大,預測模型的性能逐漸提高,但當訓練集達到80%時,SROCC性能指標提升不再明顯。
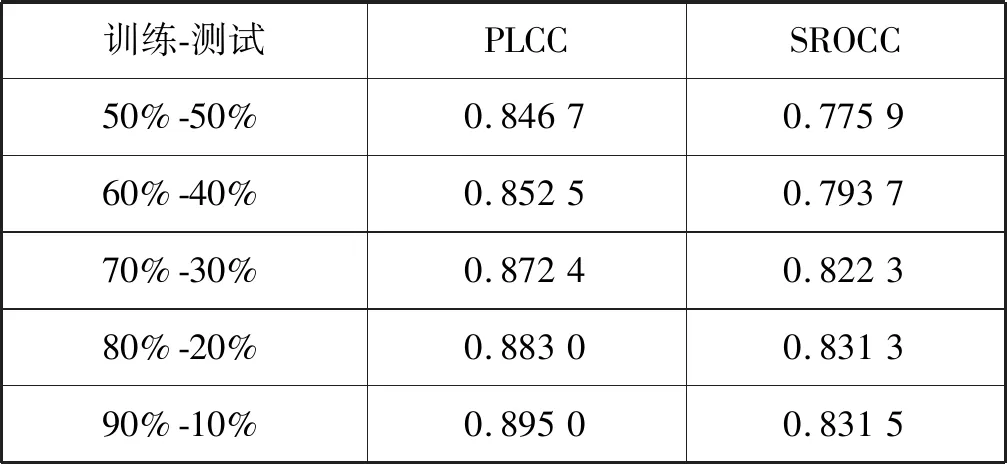
表4 不同大小訓練集的性能指標
2.3 特征分析
本文算法提取了三類特征,具體包括聚類感知特征、自然度特征、顯著性區域特征,如表5所示。聚類感知特征包括全局信息熵、三個區域的信息熵、三個區域的面積比率,全局信息熵可以看作是整個圖像為一類的特殊情況。信息熵越大,說明圖像的信息量越大,對圖像分亮區、中間區、暗區提取的信息熵相對全局信息熵具有更好的性能指標,說明對圖像聚類分區域感知圖像質量的方法是有效的。三個區域信息熵特征和全局信息熵的組合顯著提升了性能指標,說明三個區域信息熵特征可以彌補全局信息熵特征的不足。由于TMI圖像容易出現過曝光或欠曝光的區域,這些區域的大小會影響圖像的質量,三個區域的面積比例RatioΩ和EL、EM、EH、EG的組合提升了性能指標。自然度特征包括亮度通道特征N和RGB顏色通道特征FC,自然度顯然與聚類感知特征具有很好的互補性,自然度和聚類感知特征結合后性能指標大大提高。顯著性區域提取的混合區域特征ES和塊比例RatioS結合使用比單獨使用效果好很多,說明這兩個特征具有互補作用。聚類感知特征、自然度、顯著性特征聯合使用后算法的性能指標進一步提高,說明顯著性特征對TMI質量有一定的影響。
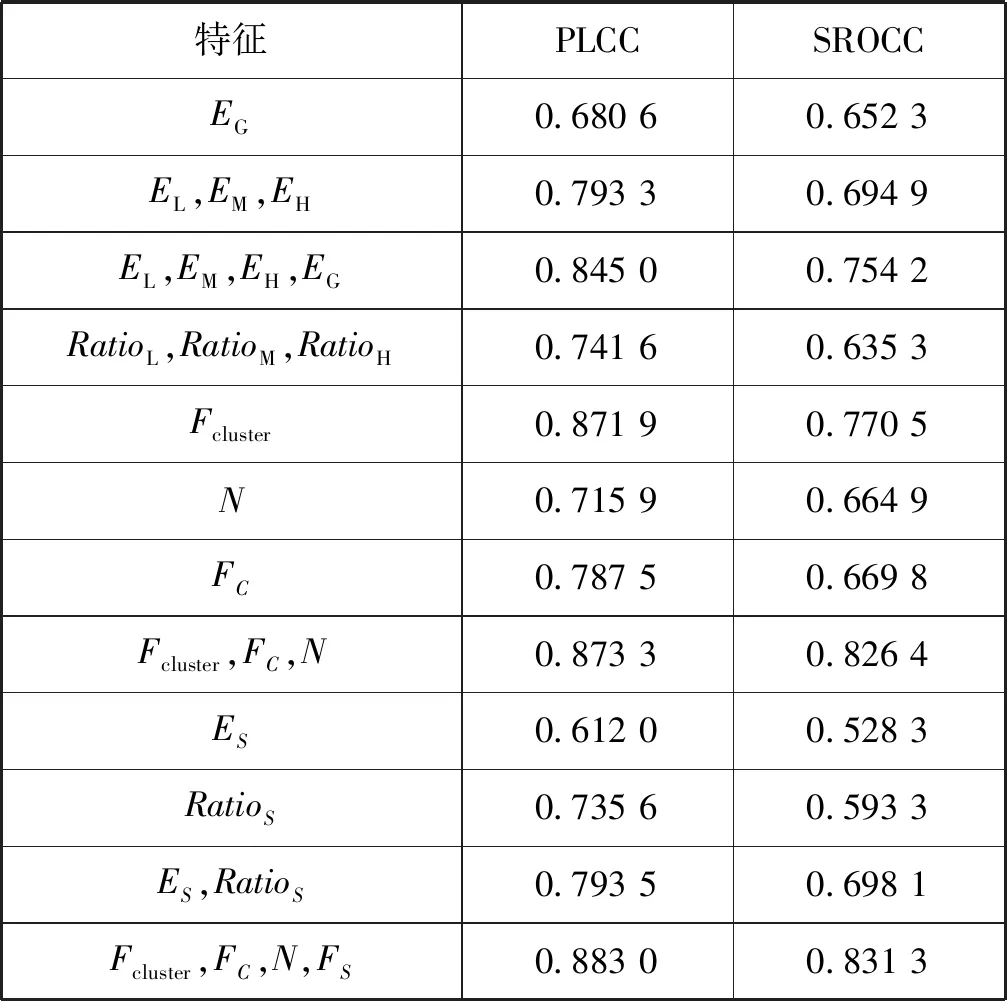
表5 本文算法中各特征的性能指標
2.4 算法比較
為了驗證本文算法的準確性和有效性,在TMID數據庫上與現有的代表性算法進行了比較,如表6所示。選擇了有代表性的全參考和無參考圖像質量評價方法作為對比。全參考圖像質量評價方法包括TMQI[5]、FSITM[6]、NITI[16]。無參考圖像質量評價方法包括BRISQUE[17]、BLIINDS-II[18]、Yue[11]、BTMQI[10]。TMQI、FSITM、NITI等專門為TMI設計的全參考圖像質量評價方法要優于BRISQUE、BLIINDS-II等針對LDR圖像的無參考圖像質量評價方法,說明針對LDR的無參考圖像質量評價方法不適合TMI的質量評價。BTMQI的性能超越了TMQI、FSITM等全參考方法,說明對TMI質量評價,無參考質量評價方法也能取得很好的效果。實驗結果表明在TMID數據庫上,對于PLCC和SROCC兩個性能指標,本文算法優于現有代表性的算法。
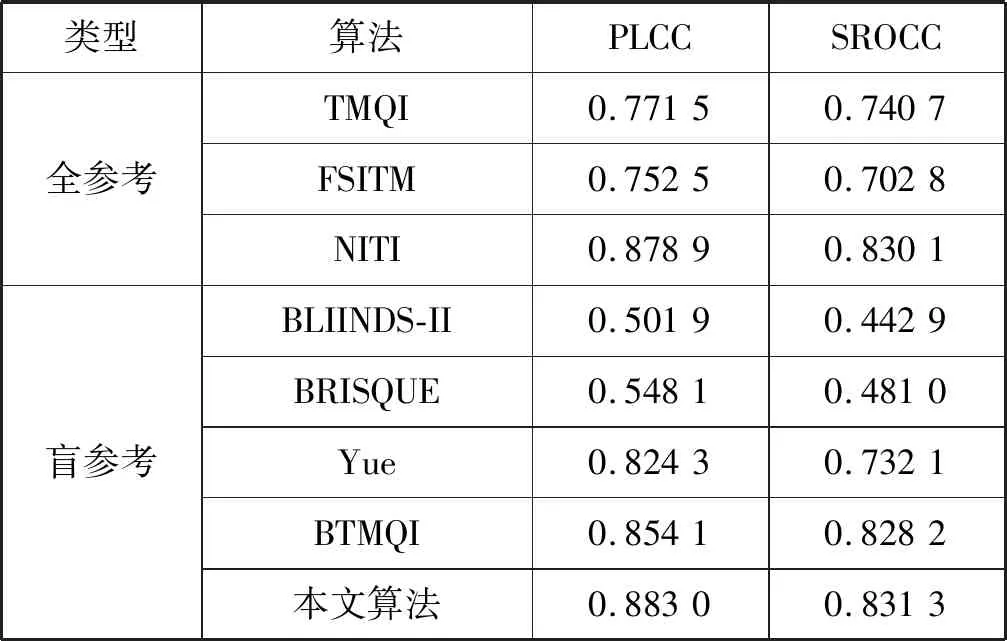
表6 本文算法與代表性算法的比較
3 結 語
本文受Weber定律啟發,采用聚類感知TMI圖像的質量。用K-means聚類算法把TMI分成暗區、中間區、亮區,提取三個區域的信息熵、面積比率和全局信息熵作為特征。通過分析圖像編碼矩陣的系數提取顯著性區域,并在顯著性區域提取信息熵、面積比率特征。在亮度和顏色通道提取了自然度特征。最后用SVM融合全部提取的特征獲得TMI的質量分。實驗表明,本文算法在TMID數據庫上具有很好的性能。
猜你喜歡
石油瀝青(2021年4期)2021-10-14 08:50:44
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當代陜西(2019年10期)2019-06-03 10:12:04
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
中國科技博覽(2016年2期)2016-04-25 20:32:39
小學生導刊(2016年34期)2016-04-11 00:49:44
電測與儀表(2015年5期)2015-04-09 11:30:52
中國教育技術裝備(2015年19期)2015-03-01 02:43:07
河南科技(2014年23期)2014-02-27 14:19:15
民生周刊(2012年10期)2012-10-14 09:06:46
