基于FPGA的卷積神經網絡動態加載SOC設計
2020-07-15 05:01:22許永全馮玉田
計算機技術與發展 2020年7期
許永全,馮玉田
(上海大學 通信與信息工程學院,上海 200444)
0 引 言
機器視覺正迅速成為工業4.0智能工廠基礎設施的重要組成部分,是制造和質量控制的關鍵技術,在制造業的檢測、測量、掃描和物體檢測中展示了其成本效益,以提高一致性、生產力和整體質量[1]。工業化進程已經走到了一個關鍵的轉折點,正從模仿加改進的開發模式向創新和創造的階段轉變,使用機器學習來增強機器視覺系統,使其能夠快速適應并融入所部署的系統中,是應對復雜應用的一個正確的解決方案[2]。隨著3D機器視覺系統的快速發展,對機器學習算法提出了越來越多的要求,同時也加速了算法迭代的速度,甚至提出隨著外部應用的變換,需要在多種算法間頻繁切換,這些需求的實現加速機器學習解決方案在更廣泛的領域應用。
文中設計了一個基于FPGA的機器學習多重加載和動態部署系統,主要面向工業應用的實用性軟硬件設計方案,充分發揮FPGA的硬件優勢,彌補FPGA開發過程復雜,對工程人員要求高的缺陷[3]。
該系統的機器學習算法采用卷積神經網絡為核心的深度學習算法,并采用SOC技術降低了算法實現和軟件開發的難度,同時將并行處理和串行控制集成到一個平臺上,提高了工業化設備的適用度[4]。另外系統實現了多重加載機器學習算法的功能,使設備具備應對多種應用場景的能力,同時系統能夠通過網絡實現機器學習算法的動態部署和多重預加載,提高了設備的通用性和可維護性。
1 硬件設計
硬件系統主要包括電源時序板、FPGA處理器和CMOS傳感器三部分,電源板和處理器采用排插連接,CMOS傳感器與FPGA處理器之間采用LVDS標準接口[5],并用定制的柔性軟板連接。圖1是系統核心硬件電路板框圖。系統的特點是體積小,處理能力強,適合嵌入到對設備要求苛刻的各種工業設備內,比如工業機器人引導、流水線產品多維度掃描檢測等[6]。
電源時序板為整個系統提供電源,輸入為DC24V標準電源電壓,通過STM32單片機產生時序控制信號,同時芯片會監測所有的電源電壓,保障硬件模塊電源的正常工作。設備的各種異常信號,芯片也會根據設定自動處理,并報告狀態信息,保障系統安全可靠的運行[7],FPGA處理器板的主要功能模塊如圖1所示。系統采用Xilinx公司的Artix-7系列的xc7a200tfbg676芯片,此芯片是Artix-7功能比較強大的一款芯片,擁有134 600個LUT、740個DSP乘法器和365個Block RAM內存單元,非常適合進行大量浮點運算的設計。板載4 GB的DDR3,保障了設備運行流暢性[8],同時搭載MICRON公司的256 Mb的NOR flash為系統提供了足夠的程序存儲空間。

圖1 硬件系統核心電路板
FPGA與外界的通信主要通過兩種方式,TTL232低速串口用于調試設備,千兆網絡接口用于數據的傳輸,保障了從模塊調試到產品部署的通信傳輸。此外電路板還包含了伺服電機運動控制接口、連續激光亮度控制接口,以及為保密而專門設計的DS加密芯片。整個系統主控部分和電源部分的長寬高分別為100 mm、40 mm和15 mm,CMOS傳感器電路板的長寬高分別為40 mm、40 mm和5 mm,版面面積和一般的工業相機的鏡頭截面大小類似[9]。
硬件部分的設計理念是嵌入到各種特殊設備的工業應用,因此體積小、處理能力強、功能靈活等特點是這個系統的基本要求。例如工業機器人3D引導應用領域,首先需要使用電機控制激光掃描,同時高速的CMOS傳感器采集實時圖像,FPGA對采集的圖像實時進行激光線提取,并進行復雜的畸變校正和3D點云生成運算,最后通過機器學習控制機器人動作。由于快速工業流水線操作要求較高的實時性,傳統的CPU無法在有限的時間處理完大量的浮點運算,因此在機器人內部通過并行處理器實時完成復雜的算法實現。
2 FPGA的RTL設計
FPGA芯片內部的RTL設計通常稱為FPGA的硬件設計,硬件架構如圖2所示,Xilinx公司文檔稱為PL(programmable logic)設計,相應的SOC處理器程序設計稱為PS(processing system)端設計,文中將PL簡稱為RTL設計。RTL設計主要分為三部分:外部設備、SOC軟核處理器設計和圖像采集及卷積神經網絡算法部分。
2.1 外部設備
外部設備主要包括DDR3控制器、網絡協議棧收發器、串口收發器以及NOR flash控制器部分[10]。例化的DDR3控制器的主時鐘為800 MHz,32 bit位寬,設計的最大傳輸帶寬為6.4 GB/s,滿足絕大多數的現場應用。網絡協議棧收發器使用的TCP/IP網絡協議,速度為1 000 Mb/s,所有的外部設備都連接到AXI總線上,多設備的訪問使用Vivado提供的內部互聯專用模塊連接。

圖2 FPGA的RTL SOC硬件設計架構
2.2 SOC軟核處理器設計
SOC軟核處理器設計采用Xilinx公司的FPGA開發工具Vivado2017.2提供的軟核處理器MicroBlaze,并例化了兩個獨立的處理器模塊,每個處理器都擁有獨立的片上程序存儲器,并用于存儲各自的BootLoader程序[11]。0號處理器作為主處理器,它的主要功能是控制整個系統的運行,并為各個模塊加載參數配置,1號處理器負責復雜數據傳輸,并掛載網絡協議棧收發器,兩個處理器之間采用MailBox中斷方式進行實時通信,并且,這兩個處理器通過各自的二級緩存訪問全部的DDR的地址,處理器與各個設備模塊之間也是采用高速AXI總線連接的。
2.3 圖像采集及卷積神經網絡算法部分
圖像采集使用的傳感器總線為16位LVDS串行總線,雙邊沿采樣,模塊包括傳感器的控制程序和LVDS總線訓練程序,采集到的圖像首先進行抽樣和截取,滿足設計的算法要求,卷積神經網絡算法模塊同時進行機器學習算法處理,輸出計算結果,其中抽樣或截取后的圖片也可以選擇實時輸出。模塊的輸出最后通過DMA的方式寫入DDR的指定區域。
當設備工作時,0號處理器首先為配置卷積神經網絡計算單元DLA加載算法的網絡模型參數,使其完成指定的網絡算法模型,然后通知CMOS傳感器采集圖像。CMOS傳感器將采集的圖像數據源源不斷地輸入到FPGA內部,經過抽樣后送入到卷積神經網絡計算模塊中,輸出的計算結果通過DMA的方式寫入DDR中,同時通知1號處理器數據已經準備好。1號處理器先將數據分包,再通過DMA的方式從DDR傳輸到網絡協議棧收發器中,最終以TCP/IP協議,將卷積神經網絡算法的計算結果發送給外部設備。
3 BootLoader設計
圖3是系統BootLoader的啟動流程,整個系統需要多個分布式加載的子程序。
系統SOC端的可用存儲器包括4部分,分別是易失性存儲器DDR3、易失性片上存儲器、非易失性程序存儲器NOR Flash和非易失性參數存儲器,其中易失性片上存儲器是使用FPGA的內部Block RAM構建的,每個處理器的易失性片上存儲器是獨立的。

表1 系統需要加載的子程序列表
表1是系統需要加載的子程序列表,其中Bitstream.bit是系統的PL端硬件電路鏡像,通過Vivado SDK提供的Generate Bitstream工具將Bitstream.bit、Boot0.elf、Boot1.elf三個程序合并為一個程序,命名為Download.bit。Boot0.elf、Boot1.elf程序作為非易失性片上存儲器的初始化常量插入到Download.bit中。最終燒寫到NOR Flash中的程序包括Download.bit、Ethenet.elf和多個實現不同網絡模型的Conv1_n.elf鏡像文件,這些鏡像文件開始需要使用Vivado SDK提供的Program Flash Mermory工具單獨寫入NOR Flash指定的偏移地址中,以后可以使用網絡升級和更換這些預置的鏡像[12]。

圖3 系統BootLoader的啟動流程
系統上電后,PL端的程序會自動從NOR Flash加載到FPGA內部,自動加載完成后,系統開始啟動卷積神經網絡的BootLoader流程,如圖3所示。0號處理器作為主處理器,首先將1號處理器應用程序加載到1號處理器的DDR程序運行段中,然后根據配置選擇需要加載的卷積神經網絡模型Conv1_n.elf到自己的DDR程序運行段中,這些配置存儲在非易失性參數存儲器中。加載完成后,通知1號處理啟動應用程序,同時自己也啟動深度學習網絡應用程序,完成BootLoader的整個過程[13]。
系統的多重加載主要體現在同時擁有多個Conv1_n.elf,即多種網絡模型應用,在特定的環境啟動不同網絡算法完成特殊功能。不僅如此,還可以通過外部PC軟件為系統更換這些網絡模型文件。目前設計預置網絡模型的最大數量為10個,燒寫在10個指定NOR Flash偏移地址中。
4 軟件設計
系統的軟件設計主要包括處理器的嵌入式開發和上位機軟件的庫文件,即雙核處理器的應用程序和面向最終用戶的終端軟件中間件程序。
4.1 嵌入式開發
0號處理器是主控處理器,它需要初始所有的外部設備,配置自定義的卷積神經網絡算法模型,分配和管理多種數據塊緩存。1號處理器主要負責網絡傳輸,它根據0號處理器發送的緩存狀態信息,將FPGA產生的數據從DDR發送到TCP/IP網絡協議棧。嵌入式開發使用的是Xilinx公司提供的Vivado SDK,它是一款界面十分友好的嵌入式編譯器,使用C或C++編寫源碼程序,開發難度等同于ARM嵌入式系統開發難度[14]。
固化在硬件中的程序主要在2個MicroBlaze處理器中,包括CAM采圖模塊和DLA卷積神經網絡計算模塊,另外還包括數據傳輸中使用的DMA傳輸。由于0號處理器作為主要的控制單元,1號處理器主要負責網絡傳輸,因此針對不同的網絡模型,需要修改0號處理器對DLA模塊的控制邏輯,并修改CAM采圖后的圖像抽樣以滿足特定網絡需求,其他的配置都不需要變化。
0號處理器的執行流程:
(1)初始化硬件,訓練LVDS接口的采圖時序;
(2)建立DLA的執行網絡模型,指定DLA的內存分配;
(3)設置CAM采圖配置,設置采圖后的數據抽樣;
(4)啟動卷積神經網絡算法,執行采圖;
(5)取出計算結果。
4.2 中間件開發
上位機軟件的庫文件是提供給最終用戶的客戶端使用的,又稱為中間件程序,中間件首先將負責的配置指令重新整合,并提供給用戶控制接口,方便用戶調用。其次將網絡數據重新打包,以整合好的包數據格式提供給終端客戶,最后中間件提供了一個日志信息和錯誤信息接口,記錄了必要的狀態信息和異常情況,方便用戶回溯歷史行為和排查異常。
5 實驗結果
文中使用自制的搭載Xilinx FPGA A7板卡和CMOS傳感器,以及配套的電源、鏡頭等外部設備,實時采集產線上的產品,并將深度學習處理過的數據通過千兆網發送到工控機處理。其中工控機配置I5 5520雙核4線程處理器,8 G內存,500 G固態硬盤,Windows7操作系統。
配置的網絡模型為經典的ImageNet,其中DLA的硬件處理單元為8,傳感器采集實時圖像,抽樣尺寸為227*227*3的ImageNet標準輸入,測試結果為每秒處理155張采集圖像,板卡和傳感器的總功率約12 W。表2是消耗的主要FPGA資源。
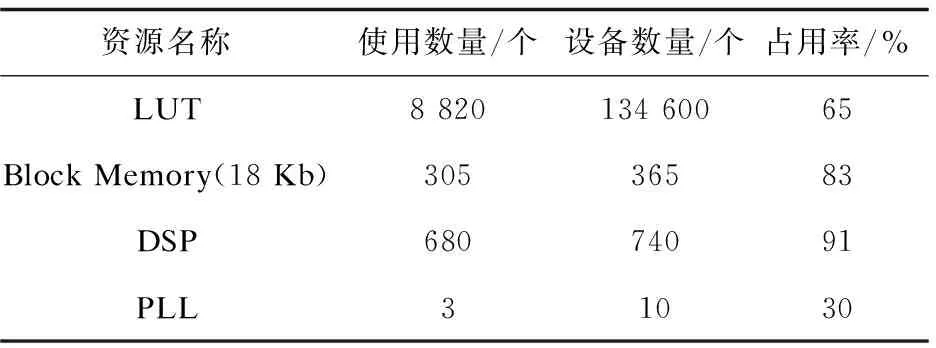
表2 PE=8的卷積神經網絡計算模型占用的資源
6 結束語
文中采用DLA算法核心,在FPGA上實現了卷積神經網絡。系統基于Xilinx的MicroBlaze SOC技術,在單片FPGA上集成一體化環境,將DLA的卷積算法模型集成到設備上,并提供遠程算法升級和多重網絡模型的動態加載,降低了工程人員將自定義機器學習算法落地到工廠的難度,提高了對機器視覺設備的可維護性,有利于推進卷積神經網絡在工業化視覺領域中的應用。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
工業設計(2022年8期)2022-09-09 07:43:20
軍民兩用技術與產品(2021年10期)2021-03-16 06:05:30
北京測繪(2020年12期)2020-12-29 01:33:58
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
藝術啟蒙(2018年7期)2018-08-23 09:14:18
家庭影院技術(2017年9期)2017-09-26 03:41:45
海峽姐妹(2017年7期)2017-07-31 19:08:17
Coco薇(2017年5期)2017-06-05 08:53:16
