基于神經網絡的中超聯賽球隊實力水平聚類方法研究
2020-07-17 16:10:02蘭兆青吳炎兵李京玲
山西大同大學學報(自然科學版) 2020年3期
蘭兆青,吳炎兵,李京玲
(1.山西農業大學文理學院,山西太谷 030801;2.山西農業大學體育學院,山西太谷 030801;3.太原理工大學水利科學與工程學院,山西太原 030001)
四年一屆的世界杯像火球般在2018年夏點燃世界,吸引著無數人為她熬夜,為她瘋狂[1]。代表著中國足球最高水平的中國足球協會超級聯賽更是吸引了若干國人的關注,多位學者從內容、方法等不同側面進行了研究[2-9]。本文運用自組織特征映射網絡和模糊聚類分析相結合的方法,依據2014年至2017年中超足球聯賽16支球隊的最終成績,用聚類法對上海上港和武漢卓爾兩支球隊做出評價。
1 球隊的選取與編碼實現
1.1 球隊選取
球隊的選取分為時間節點的選取和參賽球隊的選取兩部分。首先,時間節點的選取要注重時效性,時間太長,球隊的變動會很大,可能有的球隊會在附加賽中退出,也有可能降級至中甲聯賽,或者有強大資金的注入,邀請強有力的外援。我們從中超歷史上有紀念意義的2014年開始,選取了近4年(2014年、2015年、2016年、2017年)來的中超球隊成績作為本次球隊水平聚類的依據。其次,球隊的選取要照顧到強隊、弱隊,也要照顧到地區的差異,同時還要照顧到老牌球隊與新興勢力。我們選取16支球隊進行聚類,分別為:山東魯能、上海申花、天津泰達、北京國安、長春亞泰、廣州富力、江蘇舜天、河南建業、重慶力帆、浙江綠城、遼寧宏運、石家莊永昌、延邊富德、河北華夏幸福、貴州人和和上海申鑫。
1.2 編碼方法
每一個球隊用一個四維向量x=[x1,x2,x3,x4]來表示,向量的第一至第四個分量分別代表該球隊在2014至2017年中超聯賽上取得的成績(主要指排名)。
具體的編碼方法為:如果進入中超聯賽的,用其自身的最終排名(1~16),如果降級為中甲聯賽的,在球隊中甲聯賽最終排名的基礎上加16。16支球隊最終求得的特征向量,見表1,數字越小表示成績越好。

表1 球隊成績一覽表
2 方法介紹
對于中超足球聯賽的參賽球隊為幾流水平的問題,有許多方法可以得到,但整體上可以分為有監督指導的分類和“無師自通”的分類兩大類。對于有監督指導的分類,我們需要提前給定訓練樣本,即把某幾支球隊定為一流或者二流,并且以其為標準來評價其他球隊。然而這樣的球隊是很難找到的,即使是頂級球隊也有發揮不好的時候,如果將其作為標準,就會產生偏差,并且選取的球隊不同,最終的結果也不同[10]。因此,對于這類問題,我們選擇無監督學習的聚類方式。本文采用自組織特征映射網絡和模糊聚類分析相結合的聚類方法。
2.1 自組織特征映射網絡
自組織特征映射網絡(SOM,Self-Organizing Feature Map),也叫Kohonen網絡,由荷蘭學者Teu?vo Kohonen于1981年提出,是一個由全連接的神經元陣列組成的無教師、自組織、自學習網絡。該網絡中的單個神經元對模式分類不起決定性作用,需要多個神經元協同作用完成,并且是根據輸入空間中輸入向量的分組進行學習和分類,不需要預先知道部分球隊的水平和實力,只要給定分類的類別數量N,算法就會自動將所有樣本按照相似性的原則進行劃分。該法接受一個n維向量作為輸入,對應一個包含n個節點的輸入層,每個輸入的樣本都對應一個競爭層節點。輸入層節點與競爭層通過權值向量連接(網絡結構,見圖1)。網絡訓練的過程就是在空間上對神經元進行有序排列的過程。在更新權值時每個神經元附近一定領域內的神經元也會得到更新,較遠的神經元則不更新,而輸出神經元之間根據距離的遠近決定抑制關系。通過競爭、合作、自適應三個網絡訓練過程,最終使連接權值的統計分布與輸入模式漸趨一致。當訓練結束時,對應同一個競爭層節點的輸入樣本就被列為同一類別。當有新樣本輸入時,系統以拓撲結構的形式輸出分類結果。
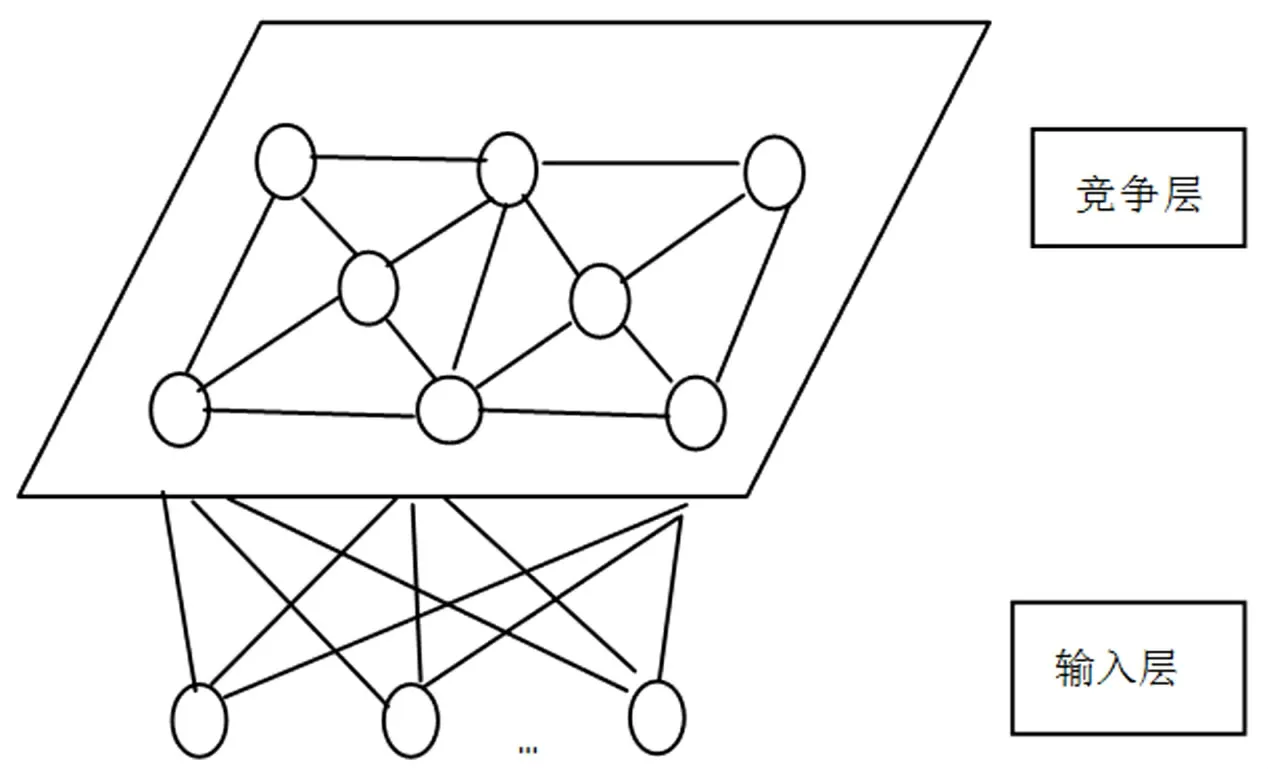
圖1 自組織映射網絡模型
2.2 模糊聚類
聚類就是將數據集分成多個類或簇,使得各個類之間的數據差別應盡可能大,類內之間的數據差別應盡可能小,即為“最小化類間相似性,最大化類內相似性”原則。模糊聚類分析是利用模糊等價關系來實現的一種聚類方法,而模糊等價關系是指在論域R上滿足:①自反性,R?I;②對稱性,即R′=R;③傳遞性,R°R?R。
該法實現聚類是用模糊數學把樣本之間的模糊關系定量的確定,而客觀且準確地進行聚類。主要分為三步:①通過求解樣本集中任意兩個樣本之間的相關系數構造出模糊相似矩陣;②改造相似關系為等價關系;③對求得的模糊等價矩陣求λ截集,實現聚類[11]。
3 足球水平聚類實現
3.1 基于自組織特征映射網絡
(1)定義樣本:足球水平聚類中涉及到16個球隊,而每個球隊的成績用一個四維向量表示,所以足球隊水平抽象為16個4維向量聚類的問題。輸入向量維數為4,同時競爭層也含有4個節點。
(2)創建網絡:考慮到分類過細,有可能把許多球隊單獨分為一類,而選用二分類則分類有點粗,故設定聚類的類別數為4類。設置競爭層為2×2的六邊形結構(見圖2)。使用MatLab工具箱函數selforgmap創建網絡。
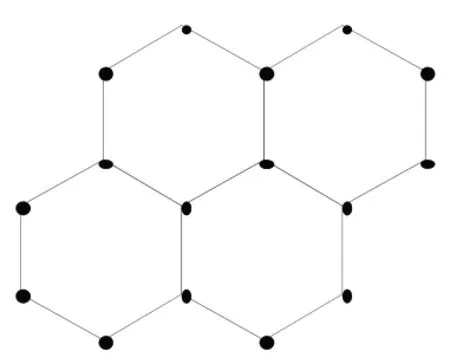
圖2 網絡拓撲結構圖
(3)使用Train函數對輸入樣本進行訓練,并選取和訓練數據一樣的數據作為測試數據對網絡進行測試。測試后的網絡連接,見圖3。
圖3中的六邊形代表神經元,菱形中的細線表示神經元之間有直接的連接,菱形內部的顏色均為白色,說明神經元之間的距離不存在差異,都很近(顏色越深說明神經元之間的距離越遠)。
由于神經網絡具有一定隨機性,所以多次運行可能產生結果不太一樣。總體來說,聚類比較穩定的球隊是:
第一流:山東魯能、上海申花、北京國安、廣州富力;
第二流:遼寧宏運、石家莊永昌;
第三流:延邊富德、河北華夏幸福;
第四流:貴州人和、上海申鑫。
其余球隊都有浮動的趨勢。
3.2 基于模糊聚類分析
主要采用模糊C均值聚類方法的MATLAB函數fcm求解。該方法的調用方式為:[center,U,obj_fcn]=fcm(data,cluster_n)。其中右端data是需要聚類的數據集合,cluster_n為聚類數。左端center指最終的聚類中心矩陣;U為隸屬度函數矩陣;obj_fcn是迭代過程中的目標函數值。使用該方法,將評價區域分為有四個聚類中心的集合:(山東魯能,上海申花,北京國安,廣州富力,江蘇舜天);(天津泰達,長春亞泰,遼寧宏運,河南建業,石家莊永昌,重慶力帆);(浙江綠城,上海申鑫,貴州人和);(延邊富德,河北華夏幸福)。
結合以上兩種方法,中超足球水平聚類如下:
第一流:山東魯能,上海申花,北京國安,江蘇舜天,廣州富力;
第二流:天津泰達,長春亞泰,遼寧宏運,河南建業,石家莊永昌,重慶力帆,浙江綠城;
第三流:延邊富德,河北華夏幸福;
第四流:上海申鑫,貴州人和。
這個聚類結果與中超足球2018年比賽結果基本一致。
4 測試
為了檢驗本次聚類的精確度和客觀性,把已經得到的聚類結果作為分類類別,任意選取的兩支我們熟悉的球隊作為待判樣品(見表2),選用MatLab中的分類函數classify函數進行線性判別分析,判斷這兩支球隊在該標準下屬于哪種水平,并與實際水平作比較。
classify分類函數的調用格式為:
class=classify(s,mydata,g)
其中s是測試樣本的集合;mydata是原始數據集;g是球隊所屬類別構成的集合的轉置。
輸出結果為:Class=1 4
測試結果表明,上海上港劃分為第一流、武漢卓爾劃分為第四流。而上海上港作為測試球隊在2018賽季也是位居積分榜第二,屬于一流水平。測試結果與球隊的實際水平是一致的,可見結合自組織特征映射網絡和模糊聚類分析得出的球隊水平聚類結果是客觀、準確的。
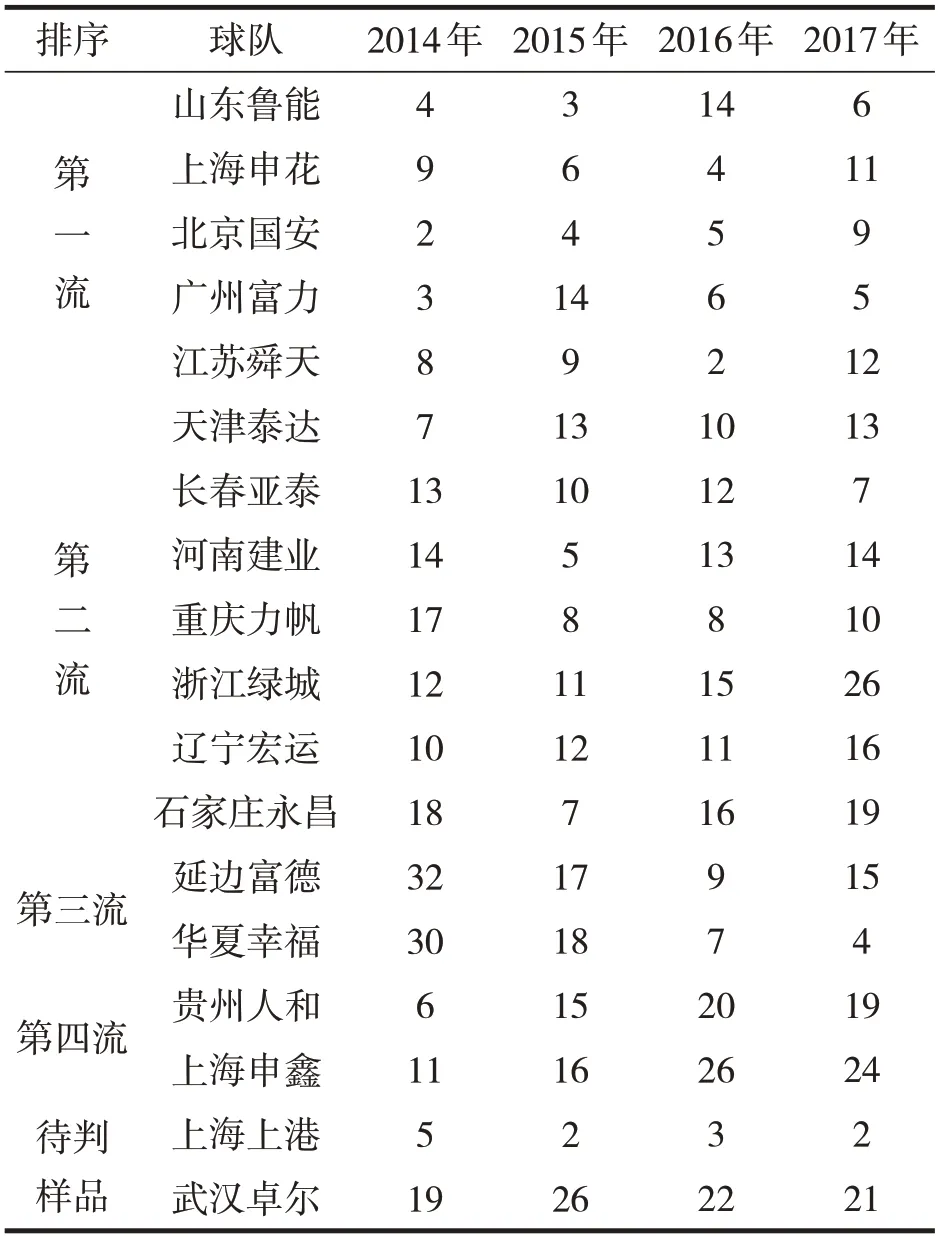
表2 評價標準及待判樣品表
5 結論
(1)結合自組織特征映射網絡和模糊聚類分析對中超聯賽球隊整體水平進行聚類,得出的聚類結果與中超足球2018年比賽結果基本一致。說明本文提出的這種聚類方法是合理可行的,得出的結論是客觀準確的。
(2)從2018中超聯賽貴州人和的參賽成績來看,雖然被劃分為第四流球隊,但在本賽季中卻比出了積分榜第六的好成績。可見,排名只是代表歷史,只要球隊團結努力,一切都可以改變。相信,如果我們在戰略戰術,運行機制等有益于足球水平提高的相關方面多加關注和投入,對中國的足球多一些耐心,少一些苛責,中國足球總會有揚眉吐氣的一天。
猜你喜歡
美與時代·美術學刊(2022年3期)2022-04-27 01:18:15
數學小靈通(1-2年級)(2021年4期)2021-06-09 06:25:56
大眾健康(2021年6期)2021-06-08 19:30:06
火花(2019年12期)2019-12-26 01:00:28
人大建設(2019年12期)2019-05-21 02:55:32
中學生數理化·七年級數學人教版(2019年4期)2019-05-20 10:06:32
中學生數理化·七年級數學人教版(2018年6期)2018-06-26 08:36:06
初中生世界·七年級(2017年9期)2017-10-13 22:27:46
學苑創造·A版(2015年11期)2016-01-14 09:03:27
少兒科學周刊·少年版(2015年3期)2015-07-07 21:00:00
