基于深度學習的Linux遠控木馬檢測
2020-07-17 07:35:44李明軒楊慧婷
計算機工程 2020年7期
李 峰,舒 斐,李明軒,王 斌,楊慧婷
(國網新疆電力有限公司 電力科學研究院,烏魯木齊 830011)
0 概述
遠控木馬是一種惡意軟件,攻擊者可使用遠控木馬對目標計算機進行遠程控制,訪問目標主機文件系統收集信息,并利用目標主機進一步展開攻擊行為。高級遠控木馬通常具有潛伏性和隱藏性,能夠長期駐留在目標主機中,并繞過反病毒引擎查殺進行隱蔽運行而不被發現。
針對Linux平臺病毒木馬的檢測問題,反病毒軟件的常用方法主要包括靜態分析和行為分析2種。靜態分析的優勢在于分析速度快,但檢測結果容易受到代碼混淆技術的影響,而行為分析會在文件執行期間收集行為信息并進行分析,其能夠有效解決代碼混淆問題,但往往需要消耗較長時間,在惡意行為觸發之后才能判斷出惡意文件。
目前,深度學習技術在圖像分類和文本識別領域得到廣泛應用[1-2],其通過多層神經網絡結構與大量的參數調節,對樣本的特征進行逐層抽取。本文結合靜態分析和動態檢測2種方法,提取Linux樣本數據,利用深度學習算法循環神經網絡(Recurrent Neural Network,RNN)訓練模型,預測輸入文件是否為惡意文件。將檢測模型的預測結果與常見的機器學習算法,如支持向量機(Support Vector Machine,SVM)[3]、K-近鄰(K-Nearest Neighbor,KNN)算法[4]、決策樹(Decision Tree,DT)[5]和隨機森林(Random Forest,RF)算法[6]相比較,并使用混淆矩陣來分析機器學習算法的性能。
1 相關工作
常見的病毒木馬檢測方法主要包括靜態分析和基于行為分析的動態檢測。靜態分析通過提取文件特征并與已知特征庫進行對比分析,從而判斷該文件是否為惡意文件,其分析速度較快,但特征誤報率較高,并且很難分析混淆后的文件。文獻[7]使用代碼特征結合深度前饋神經網絡將惡意軟件與安全軟件進行區分,其真正率達到95.2%。然而,在使用由某個日期之前的樣本數據訓練出的模型來檢測該日期之后的數據時,該方法的真正率下降至67.7%,表明靜態分析的方法對于全新且未知的惡意軟件的檢測效果較差。文獻[8]證明了使用靜態數據訓練的模型的準確率約為95%,但對經過重新打包的惡意樣本檢測的準確率下降至20%。
基于行為分析的動態檢測方法彌補了靜態分析方法的不足,其通過監控文件執行時的行為,分析其系統調用、文件操作和網絡連接等行為,進而判斷文件是否存在惡意行為。文獻[9]使用RNN提取5 min內API調用序列特征,將其反饋給卷積神經網絡(Convolutional Neural Network,CNN)以獲得具有170個樣本的數據集,該方法的模型評估指標AUC分值高達0.96。文獻[10]采用RF算法,使用API調用和相關元數據作為訓練集,其準確率和F1值分別達到97%和98%。動態檢測方法在一定程度上提高了病毒木馬的檢測率,但其分析時間較久,具有滯后性,且在觸發惡意行為后才能判斷出惡意文件。
本文結合上述2種方法,利用深度學習算法RNN訓練分類檢測模型,并通過超參數配置來優化模型性能。
2 模型設計
本節將詳細介紹檢測模型的基本框架與算法結構,給出具體的樣本分析方法和所選特征集,并說明超參數配置的選擇方法。
2.1 整體設計
Linux遠控木馬檢測模型的整體框架如圖1所示。模型首先對樣本進行靜態分析和行為分析,提取相應的靜態數據以及行為數據。在特征學習模塊中,采用RNN算法,結合k-折交叉驗證并使用隨機參數空間配置超參數循環訓練模型,在隨機超參數中最終選擇訓練期間效果較優的超參數配置,最后輸出模型。

圖1 檢測模型整體框架
2.2 樣本分析
樣本分析技術[11]分為3個部分:文件和元數據分析,靜態分析,動態分析。
通過田野作業理解和解讀民眾生活文化與意義世界,是當代民俗學的學術追求之一。研究者與敘述者(被研究者)共同完成該研究過程。同時,通過學術話語的靈活運用,研究者將敘述者的生活及敘事轉譯成為民俗志或民族志文本。因此,民俗學的實踐主體應由敘述者與研究者共同構成,亦即在民俗研究中,研究者與敘述者是互為主體的平等協商關系,是民俗志或民族志作品的共同制作人,可以說,“我們都是故事生產過程中的一個重要環節”[注]黃盈盈:《作為方法的故事社會學——從性故事的講述看“敘述”的陷阱與可能》,《開放時代》2018年第5期。。
1)文件和元數據分析。文件和元數據分析側重于文件本身,提取操作系統運行ELF文件時所需的字段信息。首先,過濾掉與分析無關的文件,例如共享庫、核心轉儲損壞的文件或為其他操作系統設計的可執行文件;其次,利用獲取到的文件信息來識別異常文件結構;最后,從VirusTotal中提取每個樣本的AV標簽并將其提供給AV類工具[12]以獲取惡意軟件的標準化名稱。
2)靜態分析。靜態分析階段包含二進制代碼分析和打包檢測2個部分。二進制代碼分析依賴于眾多自定義的IDA Pro腳本來提取多個代碼指標[13],包括函數數量、環路復雜度、整體覆蓋范圍以及是否存在重疊指令等;打包檢測將從ELF頭部提取的信息與二進制代碼分析相結合,以識別可能的打包程序。
3)動態分析。動態分析包含2種類型的行為分析:在仿真器中執行5 min以及常規的打包分析和解包嘗試。對于仿真,采用2種類型的動態沙箱,即基于KVM的虛擬沙箱以及一組基于QEMU的仿真沙箱。對于監聽,主要采用SystemTap[14]來實現內核探測器(kprobes)和用戶探測器(uprobes)。在執行結束時,每個沙箱都返回一個文本文件,其中包含系統調用和用戶空間函數的完整跟蹤,然后立即解析此跟蹤以識別沙箱的有用反饋信息。
樣本分析具體流程如圖2所示。

圖2 樣本分析具體流程
2.3 數據提取
經過樣本分析后得到json文件形式的分析數據,將json文件中的數據進行清理,使用逐步回歸方法檢查最重要的預測變量,本文最終采用46個變量用于訓練機器學習和深度學習模型,并將數據保存至csv文件中形成數據集。所選變量詳細信息如表1~表4所示,其中,表1為字節部分特征變量,表2為ELF部分特征變量,表3為Funcover部分特征變量,表4為其他部分特征變量。

表1 字節部分變量描述

表2 ELF部分變量描述

表3 Funcover部分變量描述

表4 其他部分變量描述
2.4 交叉驗證
為了提高檢測模型的泛化能力,同時更準確地評估模型的性能,本文對數據集采用k-折交叉驗證[15]方法構造訓練集。k-折交叉驗證指將樣本數據集隨機劃分為k個相同大小的子集,在每次模型訓練迭代過程中,按順序選取其中的一個子集作為測試集,剩下的k-1個子集作為訓練集。本文取k=10,即將數據集分為10份,每次取其中9份進行訓練,根據損失函數(用來評估預測值與實際值的差距)進行優化后執行下一次迭代。
2.5 循環神經網絡
典型的RNN結構如圖3所示,RNN會結合每一個時刻的輸入與當前模型的狀態從而給出一個輸出,從圖3可以看出,RNN主體結構A的輸入除了來自輸入層的xt,還會接收前一時刻的狀態,同時A的狀態也會從當前步傳遞到下一步。
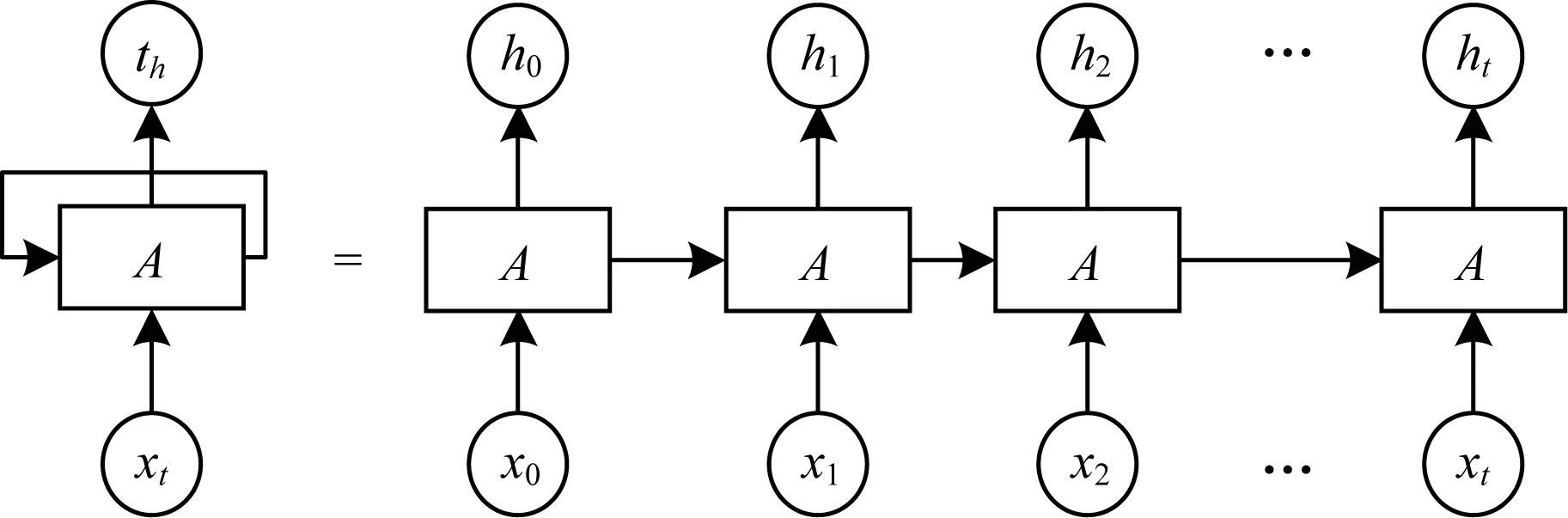
圖3 RNN的典型結構
RNN能有效處理序列數據,為了深層挖掘靜態數據以及行為數據前后依賴關系的特征,本文模型采用RNN中的門控循環單元(Gated Recurrent Unit,GRU)神經網絡[17]。GRU通過“門”結構使信息有選擇性地影響RNN中每個時刻的狀態。“門”結構使用sigmoid(激活函數)的神經網絡和一個按位做乘法的操作,如圖4所示,GRU有更新門與重置門2個門,上述結構使得GRU神經網絡能夠解決序列數據中存在的長期依賴問題,且具有參數少、收斂快的優勢。

圖4 GRU結構
2.6 超參數配置
本文采用隨機搜索參數的方法進行超參數配置,隨機搜索從可能的參數組合中隨機選擇配置,通過使用相對權重值的字典對偏置參數進行選擇。隨機搜索將一直循環運行,默認選擇輪數為100輪,超參數配置隨機搜索空間如表5所示。

表5 超參數配置隨機搜索空間表
3 實驗結果與分析
3.1 數據集
本文所使用的數據集來自文獻[18],該數據集從Padawan[19]多架構ELF分析在線平臺中獲取,并將得到的Linux樣本分析數據清理成多個重要值,最終將數據保存至csv文件中。
利用Padawan平臺可通過Linux樣本哈希值的URL訪問到json格式的分析報告,哈希值列表可在平臺上獲取。平臺提供的數據集[11]除了包含僵尸網絡中的Linux惡意攻擊樣本,還包含數千個屬于其他類別的樣本,例如遠控木馬、后門、勒索軟件、傳統文件感染、權限提升工具、Rootkit、蠕蟲、APT活動中使用的RAT程序以及基于CGI的二進制文件webshells等。
文獻[18]在Padawan平臺上獲得了10 548個json格式的樣本數據,并將json文件中的數據進行清理整合,過濾NA值過大的數據,將json文件轉換成csv格式的文件。在此基礎上,本文將幾款開源Linux遠控工具生成的有效負載上傳至Padawan平臺中進行分析,包括Meterpreter生成編碼混淆的Payload、Stitch Payload、TheFatRat Payload、Pupy Payload和PyIris Backdoor Payload等,獲取其靜態以及行為數據,并將數據添加到數據集中。最終數據集共包含5 518個樣本,其中,3 983個是惡意樣本,1 535個是安全樣本。
3.2 評估指標
為了對檢測模型進行分析,本文選取準確率(ACC)和F1值[20]2個評估指標,如式(1)和式(2)所示:
(1)
(2)
其中,F1值是綜合考慮查準率和查全率的指標,TP是將正類預測為正類的數量,TN是將負類預測為負類的數量,FP是將負類預測為正類的數量,FN是將正類預測為負類的數量。
3.3 參數選擇
本文在隨機搜索空間中循環訓練檢測模型,隨機選擇100種參數配置,經過訓練對比,最終選擇評估指標結果最好的超參數配置,如表6所示。

表6 隨機搜索空間中最優超參數配置
3.4 實驗環境
本文實驗計算機配置為雙核8 GB內存,Intel Core i5處理器,計算機型號為Macbook Pro 2015版,操作系統為macOS 10.14.2版本。在模型搭建階段,采用TensorFlow作為神經網絡框架,python使用2.7.15版本,R語言采用3.5.3版本。在參數設置方面,使用隨機搜索空間中100種超參數配置,并使用k-折交叉驗證,k值取10,每種參數配置訓練輪數為10輪。此外,為了提升訓練速度并防止過擬合現象,模型采用dropout方法,丟棄率使用[0.1,0.2,0.3,0.4,0.5]中的隨機值[21]。在隨機搜索空間中選擇評價指標結果最優的超參數配置重新進行模型訓練,訓練輪數為30輪。
3.5 結果分析
在100輪不同超參數配置的模型訓練過程中,若某一輪次采用的參數配置評估指標未超過在此之前的輪次結果,則放棄此輪參數直接進行下一輪參數配置訓練。最終挑選出其中最優的參數配置(表6),使用此超參數配置再次進行模型訓練,ACC和F1值最高分別達到92.64%和95.20%。圖5所示為本文模型在表6參數配置下的ACC值和F1值。

圖5 最優超參數配置下的評估結果
為了驗證RNN算法訓練出的檢測模型的整體性能,將RNN訓練出的模型與不同的機器學習算法進行比較,其中,機器學習算法包括決策樹中的CART算法、RF算法、SVM算法和KNN算法。所有機器學習算法的訓練和測試數據都相同,以便準確地進行比較,采用ACC和F1值2個評價指標來對比算法,表7所示為RNN與機器學習算法的性能比較結果。
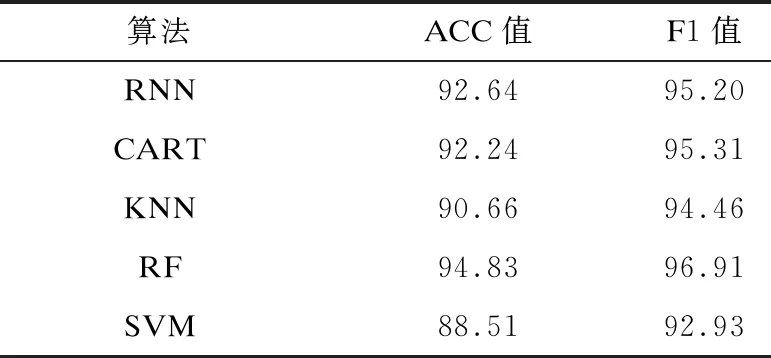
表7 RNN與機器學習算法的性能比較結果
在表7中,RNN為100種隨機超參數配置中的最優選擇,可以看出,其準確率和F1值略優于CART和SVM,但是整體表現不如RF算法。RNN-BP為在Linux數據集上執行更多輪次隨機搜索得到的全局超參數最優配置,該配置下RNN的準確率為95.72%,F1值為97.41,相比100種隨機超參數配置下的結果提高了2個~3個百分點,且檢測性能優于RF算法。
4 結束語
混淆編碼技術可繞過大部分反病毒系統的靜態惡意軟件檢測,動態分析方法雖然能克服靜態分析的不足,但其會耗費較多時間。本文使用Linux樣本靜態與動態分析中所提取的大量數據,通過深度學習算法RNN訓練檢測模型。該模型可以用于預測Linux惡意攻擊(包括Linux遠控木馬、Linux后門、Rootkit等),準確率為92.64%,F1值為95.20%。下一步將針對Linux遠控木馬檢測問題,尋找更優的深度學習神經網絡結構(如LSTM等),豐富訓練數據并提高模型的泛化能力,以加快訓練速度并降低過擬合的可能性。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
民用飛機設計與研究(2020年4期)2021-01-21 09:15:02
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
電子制作(2018年18期)2018-11-14 01:48:24
山東工業技術(2016年15期)2016-12-01 05:31:22
光學精密工程(2016年6期)2016-11-07 09:07:19
