安全類文章的多文本分類系統的設計與實現
2020-07-21 06:43:18吳習沫朱廣宇
網絡安全與數據管理 2020年7期
吳習沫,朱廣宇,張 雷
(華北計算機系統工程研究所,北京100083)
0 引言
互聯網已成為信息傳播的普遍途徑,然而,由于互聯網中的冗余信息過多,各網站提供的標簽沒有統一的分類標準,使得整合某一特定類的文章信息所消耗的時間成本和人力成本增加。但目前為止,針對網絡安全類網站的技術類文章,還沒有一套系統能夠很好地解決上述對應問題。
為迅速掌握最新的網絡安全信息,本文設計并實現了基于CNN和LSTM混合模型的安全類文章多文本分類系統,該系統從多種來源收集安全類技術文本,并將它們以特定格式匯總,自動標記匯總后的文章內容。就信息收集而言,系統主要采集近一年的安全類技術文本,收集的目標內容主要包括文章內容和網頁自帶的標簽,對于各網站自定義的文章標簽,可作為多標簽的一部分,供用戶參考。安全類文本與普通文本對比需要由多個標簽對其進行標記分類處理。因此安全類文本的分類要難于普通文本分類處理。
面向網絡安全數據高并發的安全類網站,本文設計和實現了信息采集模塊,該模塊主要實現了基于Scrapy框架的分布式爬蟲程序設計,完成了多個安全類網站技術類文章的文本信息數據采集。
本文設計并實現了信息分類模塊,它負責對所獲得的數據進行預處理、文本表示以及文本分類,其中文本分類模塊具體提出了一種基于CNN和LSTM的混合分類模型,它綜合了CNN與LSTM的優點,提高了模型的特征提取能力。實驗結果表明,基于CNN和LSTM的混合分類模型達到了比較高的準確率,CNN和LSTM的混合模型的準確率為91.99%。CNN-LSTM與CNN、LSTM相比分類準確率提高了1.79%和1.54%。
1 相關工作
文本分詞是中文文本預處理過程中的一個重要環節,分詞技術是把由字構成的句子按語義劃分為由單詞組成的句子。由于網絡語言表現形式自由、語言不規范、內容多樣化等特點,傳統分詞算法難以充分提取特征,此外,網絡新詞的創造相對于傳統詞匯具有一定的變異性[1]。為了克服上述問題,本文應用Bi-LSTM-CRF模型[2]對待分類文本進行中文分詞。神經網絡[3]通過自動學習從樣本數據中提取文本特征,成功地克服了傳統人工提取方法的不足,具有廣泛的應用范圍和廣泛的適用性。在自然語言處理方面谷歌提出的Word2Vec[4]算法在文本表示方面十分突出,該算法使得文本表示更加精準而被廣泛使用,本文通過結合使用Word2Vec字向量和詞向量完成了中文文本的分詞和向量化表示。
HOCHREITER S等人[5]提出短期記憶網絡(Long Short Term Memory,LSTM),它是一種時間遞歸神經網絡,該神經網絡近期被AlexGraves進行了改進。LSTM模型一般用于多文本分類實驗,該模型的優點是可以利用文本中的上下文信息和特征進行非線性擬合,從而實現時間序列的處理和預測。基于該模型設計的系統,已經在聊天機器人、文檔摘要等相關領域被廣泛使用[6]。
KIM Y[7]首次將CNN模型應用在了序列文本問題上,在效果上和LSTM模型互有所長,更多的研究發現,CNN更擅長提取數據不同尺度的局部相關特征,且在處理效率上相較于循環神經網絡有大大提高。兩者單獨使用已經在文本分類問題上取得一定效果。
Lai Siwei等[8]提出在文本分類問題中同時使用CNN和LSTM的混合模型,這兩種模型在文本分類中分別發揮了CNN模型和LSTM模型各自的優勢,故分類試驗的準確率將顯著高于兩種模型中任意一種單獨使用的準確率。
2 系統設計
本系統包括圖1所示的兩個功能模塊:信息采集和信息分類。
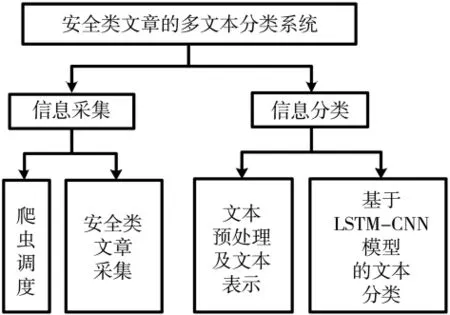
圖1 系統組成圖
信息采集模塊包含爬蟲調度子模塊和安全類文章采集子模塊,實現了基于Scrapy框架對多個安全類網站進行文本信息采集的相關功能。
信息分類模塊包括文本預處理及文本表示子模塊和基于LSTM-CNN模型的文本分類子模塊。
2.1 信息采集
信息采集模塊具體功能包括:獲取當前爬蟲任務狀態,對站點信息進行更新和配置查詢模塊狀態從而進行信息采集。
為實現該爬蟲的上述功能,如圖2所示,設計并實現了兩個交互頁面,分別是配置子頁面和爬蟲管理子頁面,其中頁面交互功能通過信息處理層和業務邏輯層實現。
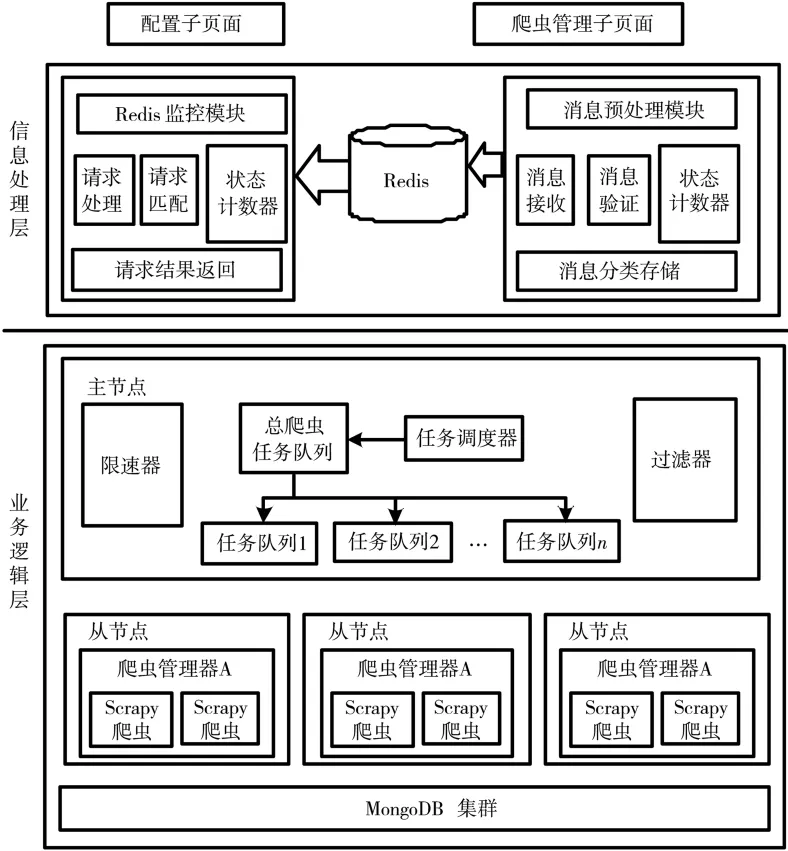
圖2 爬蟲架構圖
配置子頁面用于接收具體采集屬性信息,為便于后續消息預處理功能模塊解析,每類請求都有相應的固定格式。該爬行器通過對子頁集群爬蟲的啟動和停止進行配置,從而實現了對集群爬行的實時動態監控。其中,Handler層的主要任務是驗證和處理頁面發送的請求消息;MessagePression模塊通過自帶的計數器功能對爬蟲請求類型進行計數分析處理;通過對文本信息的請求驗證,將符合隊列信息的內容放入到爬蟲請求隊列中,Redis的循環檢測是由Redisvisition功能模塊執行相關的檢查處理,處理后啟動響應插件,以完成對請求的處理解析,增加Redis監控數量可以顯著提高請求響應速度和可靠性[9]。
2.2 信息分類
本文提出的信息分類模塊主要包括文本預處理及文本表示子模塊和基于LSTM-CNN模型的文本分類子模塊,實現了三個主要功能:文本預處理,文本表示,訓練分類模型。
2.2.1 文本預處理及文本表示
文本預處理包括文本清洗、分詞和文本表示。文本清洗主要有去停用詞,去除非文本符號等。分詞階段,本文使用了基于LSTM模型和字向量的的Bi-LSTM-CRF中文分詞模型[2]進行分詞,通過對典型語料數據集的測試結果表明[10],對于未收錄詞的分詞準確率,該模型明顯好于傳統的分詞方法。第二步結合Bi-LSTM-CRF的輸出結果,對中文文本進行分詞和和索引化,并使用Word2Vec詞嵌入矩陣轉化為詞向量形式。詞向量為文本在高維空間的分布式表示,如圖3所示。文本向量化訓練模型Word2Vec將文本中的每個單詞映射成一個固定維度的向量,這些單詞的向量組合到一起形成詞向量空間。
2.2.2 基于CNN和LSTM的文本分類
對于文本分類,若每一類的關鍵字確定、穩定,使用正則匹配準確率較高。然而,若文本分類界限無明顯區分,關鍵詞混淆、不明確,正則關鍵字匹配分類效果較差。本文的自動化分類是基于深度學習的分類模型,采用基于CNN和LSTM的混合模型,對安全類文本進行分類。利用K-MaxPooling方法提取更多的特征用于分類,在分類器層使用Softmax函數來計算每一類的概率。基于CNN和LSTM,本文設計并實現了一個多文本分類模型,其總體結構如圖4所示,模型分為9個層次:輸入層、Embedding層、雙向 LSTM層、拼接層、CNN層、K-MaxPooling層、全連接層、Softmax層、輸出層。

圖3 詞語向量化
第一層為輸入層,輸入經過文本分詞和索引化后的文本序列。
第二層為Embedding層,作用是將輸入層傳遞來的數據中的每個數字索引轉化為對應的詞向量[11]。
第三層為Bi-LSTM層,如圖5所示,主要負責提取句子向量的上下文信息。相較于單層的LSTM,增加了對語句逆向特征的提取能力。為了防止過擬合,結合使用了L2正則和dropout方法。
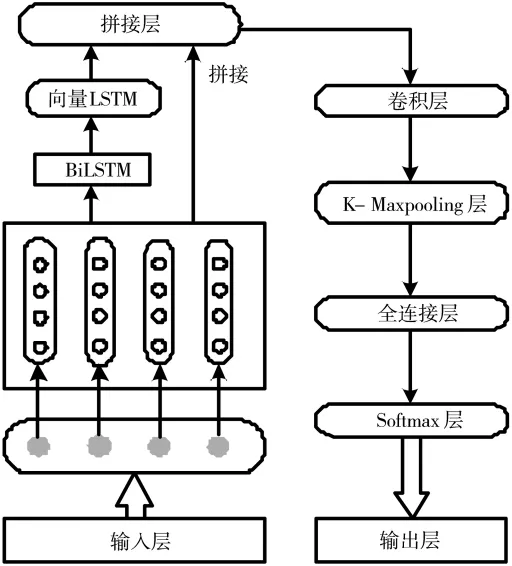
圖4 神經網絡結構架構圖
第四層為拼接層,函數主要用于拼接雙向LSTM層和Embedding層所輸出的特征向量和詞向量。在Embedding層中將LSTM層的特征向量與特征提取和原始向量相結合,可以使處理的文本更豐富,原始信息更完整。在CNN層中加入最終得到的信息,可以有效地提高CNN層次特征表達的能力。
第五層為卷積層,作用是通過卷積操作提取特征之間的局部特征。
第六層為K-MaxPooling層,主要從卷積層提取出多個最大特征值,即提取出最重要的最大特征值數量的信息。
第七層為全連接層,作用是特征降維。
第八層為分類器,通過Softmax函數將文本特征進行類別分類。
第九層為輸出層,主要負責輸出結果數據。
3 實驗分析
3.1 數據集
本實驗數據集來源如表1所示,數據采集層采集多個安全類網站文本信息,采集內容屬性具體包括:文章標題、作者、文章具體內容、原網頁自帶標簽、文章發表日期。數據量為1萬條。標注方式為人工標注。
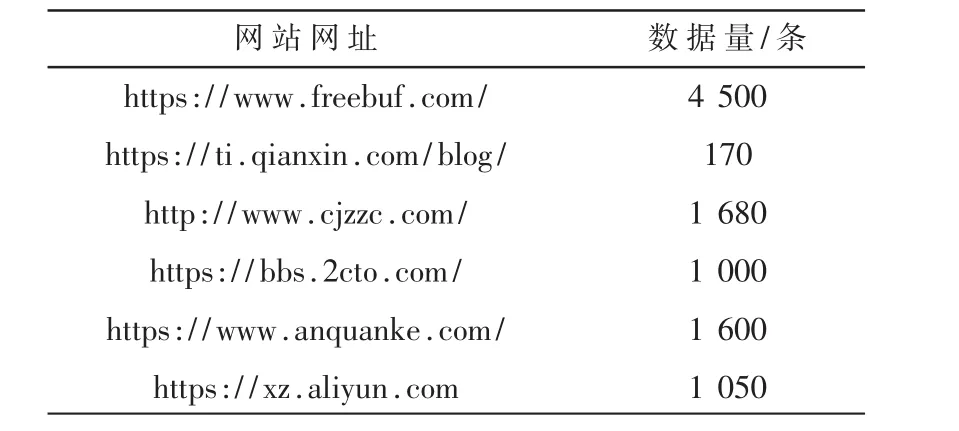
表1 數據集來源
3.2 基準模型分類實驗結果
如表2所示,文章內容為采集模塊輸出的安全類文章的內容,人工標注的分類結果作為目標分類結果,為CNN-LSTM模型分類結果。
表3所示為不同模型的實驗結果,表格顯示CNN-LSTM模型比傳統的CNN、LST模型更準確。
3.3 實驗的參數設置
梯度更新采用動量梯度下降算法,相比原始梯度下降算法,收斂速度更快,效果更好,公式如下:
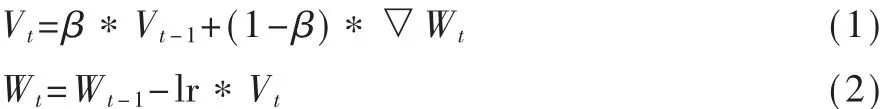
實驗使用Glove.Twitter.42B.300d向量作為英文詞向量表示,Glove.微博.300d向量作為中文字向量表示,相關主要超參數初始化如表4所示。
4 結論
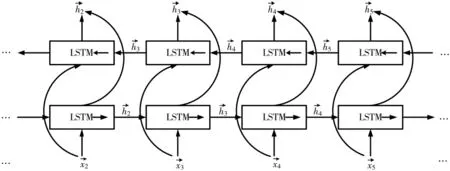
圖5 BiLSTM網絡結構圖

表2 文本內容及分類結果
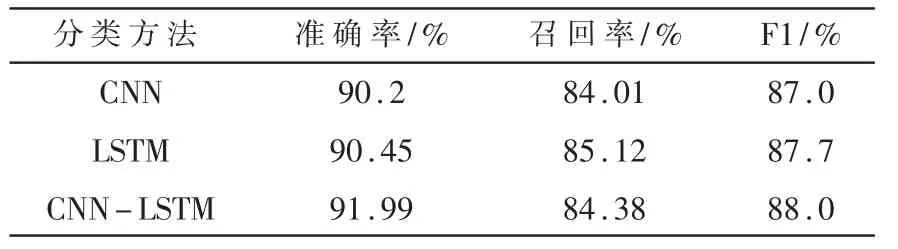
表3 不同模型的實驗結果對比
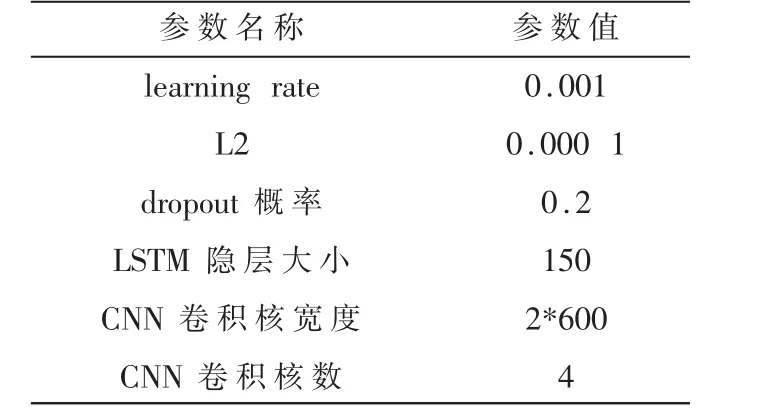
表4 實驗主要超參數設置
本文設計并實現了安全類文章多文本分類系統,主要包含信息采集模塊和信息分類模塊,首先通過信息采集模塊對安全類網站進行大量的信息采集,將采集到的文本數據存入數據庫,然后通過信息分類模塊對存入數據庫中的文本進行了預處理及文本表示,具體包括數據清洗、文本分詞、文本表示等,將文本表示后得到的詞向量分別輸入CNN模型、LSTM模型和CNN-LSTM模型這3個文本分類模型進行多文本分類實驗。實驗結果表明,CNNLSTM混合模型的準確率和F1值分別達到 91.99%和88.02%,均優于CNN和LSTM模型。
猜你喜歡
數學小靈通(1-2年級)(2021年4期)2021-06-09 06:25:56
制造技術與機床(2019年10期)2019-10-26 02:48:08
中學生數理化·七年級數學人教版(2019年4期)2019-05-20 10:06:32
電子制作(2018年18期)2018-11-14 01:48:06
中學生數理化·七年級數學人教版(2018年6期)2018-06-26 08:36:06
初中生世界·七年級(2017年9期)2017-10-13 22:27:46
中華手工(2017年2期)2017-06-06 23:00:31
小學教學參考(2015年20期)2016-01-15 08:44:38
中外會展(2014年4期)2014-11-27 07:46:46
語文知識(2014年1期)2014-02-28 21:59:13
