基于Apriori算法的高校教務管理系統設計與實現
2020-07-23 08:54:49劉瓔川
現代電子技術 2020年14期
關鍵詞:數據挖掘
劉瓔川
(唐山師范學院, 河北 唐山? 064100)
摘? 要: 為進一步改善高校的管理效率,文中設計一種執行效率較高的教務管理系統。通過分析傳統Apriori算法,指出數據挖掘算法所存在的缺陷。針對以上缺陷,利用散列、事務壓縮、劃分和抽樣等技術,對Apriori算法進行改進,提高該算法的執行效率與可靠性,從而有效提高教務管理系統的管理效率。相關測試結果表明,該系統能夠挖掘學生成績數據之間的關聯與規則,可為教務管理者的決策提供支撐。
關鍵詞: 教務管理系統; 系統設計; Apriori算法; 算法改進; 數據挖掘; 系統測試
中圖分類號: TN911?34; TP311.13? ? ? ? ? ? ? ?文獻標識碼: A? ? ? ? ? ? ? ? ? ? ? 文章編號: 1004?373X(2020)14?0052?03
Design and implementation of university educational administration
system based on Apriori algorithms
LIU Yingchuan
(Tangshan Normal University, Tangshan 064100, China)
Abstract: In order to further improve the management efficiency of colleges and universities, an educational administration system with high efficiency is designed. The shortcomings existing in the data mining algorithm are pointed out by analyzing the traditional Apriori algorithm. The Apriori algorithm is improved by means of hashing, transaction compression, partitioning and sampling technology to overcome the above defects and enhance the execution efficiency and reliability, so as to improve the management efficiency of the educational management system. The related testing results show that this system can mine the relation and rule among the student mark data, and provide support for the decision?making of the educational administration management people.
Keywords: educational administration system; system design; Apriori algorithm; algorithm improvement; data mining; system testing
0? 引? 言
隨著社會與經濟的發展,我國高等教育的招生規模不斷增加,高校的教學資源也逐漸成為稀缺資源。如何快速分析與處理高校學生的教學信息,提高高校教務的管理效率,顯得尤為重要。針對此問題的研究,主要集中在如何利用數據挖掘技術,設計與實現具有普適性的高校教務管理系統。此外,這一方向的研究主要依賴于數據挖掘技術的發展。
目前,較多國外學者致力于數據挖掘技術的研究。其中,Kochetov總結近年來數據挖掘技術的最新進展,具有重要意義[1];Marozzo等利用云平臺技術,提出一種改進的數據挖掘和分析技術[2],促進此研究方向的發展;此外,國內較多學者也逐漸將數據挖掘技術應用于高校的教務管理系統[3?8]。但是,其實用性較高,但理論性較低。例如:邱文教等將DM技術應用于教務管理系統,朱艷鵬等將Apriori算法應用于教務管理的研究中[9?10],但并未得到功能完善的高校教務管理系統。
為了解決此問題,本文利用Hash、劃分和抽樣等技術,改進傳統的Apriori算法,并將其用于具體的教務管理系統,從而提高采集、篩選和分析數據的效率。
1? 算法思想
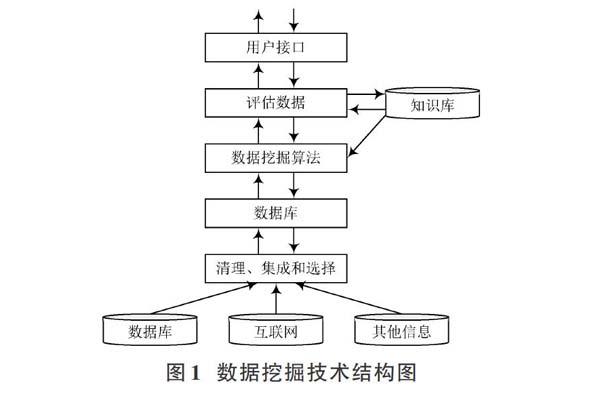
數據挖掘也被稱為數據采礦,即從隨機性數據中提取有效數據的操作,具體的技術結構如圖1所示。
根據技術結構可知,與傳統數據庫技術相比,數據挖掘所處理數據的規模較大,可以發現較多的潛在有效規則,且執行速度更快。該技術具備上述優點,為其應用于關聯規則領域提供了理論基礎。關聯規則是指從某一維度上講,世界上的任何兩件事情均存在某種相關性,這一特征在數據之間表現得尤為明顯。數據關聯是海量數據中存在的某種重要的規律,按照其關系類型,數據關聯可分為簡單關聯、時序關聯和因果關聯。
Apriori算法是關聯規則挖掘的經典算法。該算法包括兩個步驟:
1) 挖掘大量數據中的頻繁項集;
2) 利用已知的頻繁項集,歸納潛在的關聯規則。
通常由于Apriori算法的結構和推導較為簡單,所以其效率、準確度較高。然而,此算法較難挖掘低支持度、多頻繁模式和復雜結構的對象,主要因為:
1) Apriori算法在處理候選集時,若頻繁1?項集的數據量較大,則算法處理候選2?項集的難度會增加,導致算法的效率急劇下降;
2) Apriori算法必須不停地掃描數據庫,耗費大量的計算資源,從而降低算法的模式匹配效率。
2? 算法設計
Apriori算法由項目、關聯規則、事務、頻度和支持度等因素組成。其中,事務是指系統的某一次活動;項目是事務的最小整體,也被簡稱為項;關聯規則是指項目之間的相關性;頻度是指項目在事務中出現的次數;項目的支持度是指其頻度與其在所有事務中出現的總數比值。
為回避Apriori算法的缺陷,本文將散列、事務壓縮、劃分和抽樣等技術融入到算法的流程中。其具體說明如下:
1) 散列技術
當算法在掃描事務的過程中,屬于候選項目集[C1]中的候選1?項集產生頻繁1?項集[L1]。此時,利用散列技術可將這兩個項集均映射到散列表的不同桶中,增加桶的數量。因此,散列表中的桶計數低于候選2?項集,可直接刪除候選項集,達到壓縮候選2?項集的目的。
2) 事務壓縮技術
根據Apriori算法本身的特性,若一個事務不包括任何頻繁[k]?項集,則其也不包含任何頻繁[k+1]?項集。因此,當生成頻繁[j]?項集([j>k])時,則算法不再需要掃描數據庫。從而降低算法掃描數據庫的次數,改善算法的執行速度。
3) 劃分技術
當劃分技術被應用時,算法掃描數據庫的次數可直接降到2。第一次掃描時,算法把事務集劃分為多個邏輯子集,對每個子集尋找其局部頻繁項集;第二次掃描時,計算所有局部候選項集的支持度,通過劃分數據庫來確定全局頻繁項集。
4) 抽樣技術
當抽樣技術被應用時,算法需選擇數據庫[D]中的隨機樣本[S],直接在[S]中搜索頻繁項集。此算法只需掃描一次[S]中的事務,而并非掃描整個數據庫[D]。此外,抽樣技術通過降低算法的準確度,提高執行效率。
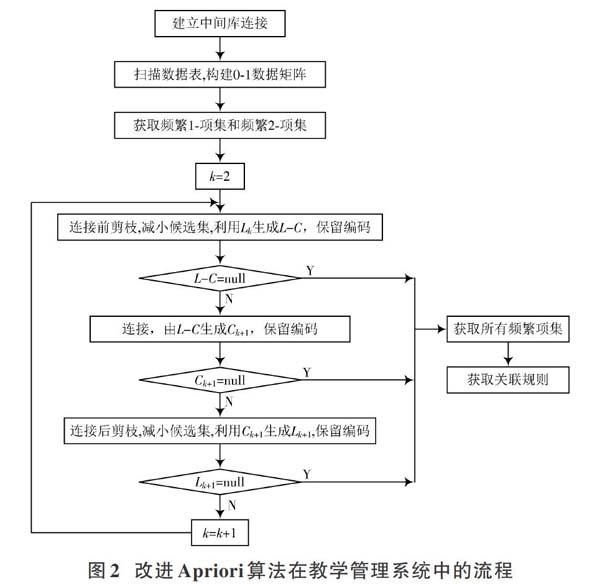
利用以上技術,本文改進Apriori算法,從而提高該算法的執行效率。改進之后的算法流程如圖2所示。
按照圖2所示的流程,本文還給出了改進Apriori算法的偽代碼,其具體描述如下:
Input: 數據庫[D],最小支持度閾值min_sup;
Output: 頻繁項集[L];
步驟1:get items();? ? ? ? ? ? ? ? ? ? ? ? ? ? ?//掃描數據庫項目
second scan();? ? ? ? ? ? ? ? ? ? ? ? //掃描構建0?1矩陣
getL1();? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ?//獲取L1
getC2();? ? ? ? ? ? ? ? ? ? ? ? ? ? ? //獲取候選項目集2
getL2();? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? //獲取L2
步驟2:[for(k=2;Lk-1≠?;k++)]
{
[LC=cutbefore(Lk)];? ? ? ? ? ? ? ? ? ? ? ? ? //連接前剪枝? ? ? ? ? ? ? ?[Ck+1=conitemsLC];? ? ? ? ? ? ? ? ? ? ? //獲取候選項集
[Lk+1=cutafter(Ck+1)];? ? ? ? ? ? ? ? ? ? ? ? ?//連接后剪枝
}
3? 系統實現
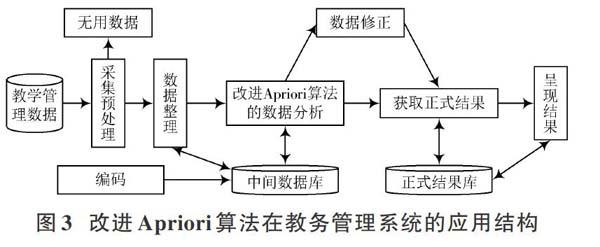
在完成改進Apriori算法的設計后,本文還需將此算法應用于教務管理系統中。通常教務管理系統主要包括采集、整理、處理和修正等模塊,而改進Apriori算法則應用于數據處理模塊。其應用結構設計見圖3。
根據圖3所示的結構,本文可實現系統的各大主要功能模塊,具體介紹如下:
1) 采集預處理。系統的采集預處理模塊主要由數據采集與預處理組成。其中,數據采集的對象為數據庫的各種數據。本系統使用SQL Server數據庫,而實際應用中的數據庫也可能是其他的。例如,Oracle,MySQL或其他類型數據庫。為避免多種數據庫造成的不匹配現象,本系統使用ODBC多種數據庫互通的方式,實現不同數據庫的訪問。
2) 數據整理。在提取數據后,系統需要對數據進行篩選,刪除冗余數據及特征不明顯的數據。同時,將篩選結果存儲到系統的中間數據庫中。在此過程中,系統還需對有效數據進行分類,即清洗數據。
3) 數據分析。數據分析模塊是教務管理系統的核心模塊。其主要利用改進Apriori算法,分析、處理中間數據庫的有效數據,并獲取這些數據之間潛在的關聯規則,從而為系統使用者決策提供依據。
4) 數據修正。由于系統無法預測數據分析的最終結果,所以用戶無法確定其分析結果的實際意義。為避免結果無實際意義或意義模糊的情況,系統需要設立數據修正模塊,對數據分析的結果進行修正、分析,判斷其最終結果是否存在實際意義。
5) 呈現結果。數據挖掘的結果需呈交給系統用戶,所以系統在保持分析結果準確度的前提下,還應盡量提高分析結果的可讀性。這也使得該模塊一般使用圖表的形式,展示系統的分析結果。
4? 系統測試
為了驗證系統的執行效率與可靠性,本文利用處理器為Intel[?] CoreTM i7?4790 CPU @ 3.60 GHz、內存為4 GB、操作系統為Windows 7的電腦。在Matlab軟件環境下,實現該教務管理系統。需說明的是,測試數據來自于某高校的840位同學的多門課程成績。部分測試數據截圖如圖4所示。
在具體的測試過程中,算法執行一步,則更新相應的候選項目集,并計算、比較其最小支持度,從而整理得到最大項目集。當系統的算法全部執行完畢,本文得到的執行結果如圖5所示。
由圖5可知,該教務管理系統在執行數據挖掘的操作后,雖然得到的部分結論沒有實際意義,但同時也獲取了較多有重要價值的結果。例如,其中結論為CN>=60=>HWD>=60[support=49%,confidence=91.5%],這里
的“CN”代表《計算機網絡》,“HWD”代表《計算機硬件課程設計》。支持度與可信度的數據表明,這兩門課程的成績具有相關性,即當某學生的《計算機網絡》課程成績達到60分后,則其《計算機硬件課程設計》的成績大于60分的概率較高。其他測試也可分析得到類似的結果,即本文的教務管理系統基本達到設計要求,具有一定的參考價值。
5? 結? 論
基于改進的Apriori算法,文中主要研究高校教務管理系統的設計與實現。其中,本文主要使用散列、事務壓縮、劃分和抽樣等技術改進Apriori算法,提高算法的執行效率與可靠性,從而提升教務管理系統的效率。然而,該算法依然存在部分優化空間。例如,當支持度、可信度等數據均較高時,系統挖掘的結果并不一定是具有實際意義的關聯規則。也許降低支持度閾值可以解決這一問題,而這也將是下一步的研究方向。
參考文獻
[1] VADIM Kochetov. Overview of different approaches to solving problems of data mining [J]. Computer science, 2018, 123: 234?239.
[2] MAROZZO F, TALIA D, TRUNFIO P. A workflow management system for scalable data mining on clouds [J]. IEEE transactions on services computing, 2018, 11(3): 480?492.
[3] 邱文教,潘曉卉.數據挖掘技術在教務管理中的應用[J].安徽工業大學學報(社會科學版),2005,22(3):133?134.
[4] 曹丹陽.數據挖掘在教務系統中的應用研究[D].北京:北方工業大學,2006.
[5] 陳小莉.基于大數據的計算機數據挖掘技術在檔案管理系統中的研究應用[J].激光雜志,2017,38(2):142?145.
[6] 張艷麗.數據挖掘技術在數字化校園的教務系統中的應用[D].沈陽:東北大學,2005.
[7] 許敏.基于數據挖掘的綜合教務管理系統研究與實現[D].長沙:湖南大學,2014.
[8] 崔貫勛,李梁,王柯柯,等.關聯規則挖掘中Apriori算法的研究與改進[J].計算機應用,2010,30(11):2952?2955.
[9] 朱艷鵬,王曉權.基于Apriori算法的數據關聯規則在教務管理中研究[J].中國管理信息化,2015(17):244?246.
[10] 王華,梁華銀.改進的Apriori算法在高校教學管理系統中的應用[J].科技信息:學術研究,2008(34):226?227.
猜你喜歡
艦船科學技術(2022年14期)2022-09-22 03:10:36
大眾投資指南(2021年35期)2021-02-16 01:06:26
中國交通信息化(2020年1期)2020-07-27 02:50:04
電力與能源(2017年6期)2017-05-14 06:19:37
中國中醫藥信息雜志(2016年7期)2016-12-01 06:07:55
信息通信技術(2015年6期)2015-12-26 01:16:46
西安工程大學學報(2014年2期)2014-02-28 18:03:05
河南科技(2014年23期)2014-02-27 14:18:43
電子設計工程(2014年18期)2014-02-27 12:00:13
電子設計工程(2014年18期)2014-02-27 12:00:12
