基于數字標簽的電子檔案序列大數據 并行分類系統設計
2020-07-23 08:54:49詹青
現代電子技術 2020年14期
關鍵詞:大數據
詹青

摘? 要: 為協助用戶在龐大網絡數據中安全、快速尋找所需電子檔案序列大數據,設計基于數字標簽的電子檔案序列大數據并行分類系統。利用云計算理念設計由大數據采集器、處理器和分類模塊構成的并行分類系統總體架構,通過動態易擴展方式分布式配置電子檔案序列大數據,增強系統分類穩定性。設計由芯片和單片機組成的大數據采集器,以及處理器型號為IXP2400的大數據處理器,完成電子檔案序列大數據采集及處理。大數據分類模塊采用基于數字標簽加密分類方法,設計多屬性數字標簽防止電子檔案序列大數據被竊取。基于此,采用加密分類方法將電子檔案序列大數據分成若干大數據塊,實現電子檔案序列大數據加密分類。測試結果表明,所提系統正確分類電子檔案序列大數據的同時分類穩定性好,準確率及召回率分別高達98.63%,99.85%。
關鍵詞: 并行分類; 系統設計; 電子檔案序列; 大數據; 數字標簽; 加密分類
中圖分類號: TN919?34; TP311? ? ? ? ? ? ? ? ? 文獻標識碼: A? ? ? ? ? ? ? ? ? ? ? ?文章編號: 1004?373X(2020)14?0152?04
Design of digital?label based parallel classification system for electronic
archive sequence big data
ZHAN Qing
(College of Big Data, Qingdao Huanghai University, Qingdao 266427, China)
Abstract: A digital?label based parallel classification system for the big data of the electronic archive sequence is designed to help users find the big data of the needed electronic archives sequence safely and quickly in the huge network data. The overall architecture of parallel classification system composed of big data collectors, processors and classification modules is designed by means of the idea of cloud computing. The big data of electronic archive sequence is performed for the distributed configuration in a dynamic and scalable way to enhance the classification stability of the system. The big data collector consisted of the chip and the single chip computer, and the big data processor IXP2400 are designed to complete the acquisition and processing of big data of the electronic file sequence. In the big data classification module, the multi?attribute digital label is designed based on the encryption and classification method based on digital labels to prevent big data of the electronic archive sequence from being stolen. Based on this, the big data of electronic archives sequence is divided into several big data blocks by means of the encryption and classification method, so as to realize the encryption and classification of big data of electronic archives sequence. The testing results show that the proposed system can classify the big data of electronic archive sequence correctly and has good classification stability at the same time. The accuracy and recall rate are 98.63% and 99.85%, respectively.
Keywords: parallel classification; system design; electronic archive sequence; big data; digital label; encryption and classification
0? 引? 言
大數據飛速發展和廣泛應用,使電子數據無處不在。電子數據已經逐步代替紙質數據充斥著人們的生活和工作,導致電子數據爆炸式增長。大數據時代下電子檔案數據也步入數字化建設階段,檔案管理方式由傳統紙質檔案管理轉向電子化管理[1]。但電子檔案序列大數據網絡化給人們帶來方便的同時,也會產生電子檔案序列大數據安全問題,以及大數據大幅度增加帶來用戶使用信息難度大的問題[2]。
丁家滿等人提出Spark環境下采用大數據處理方式將完成的電子檔案序列信息可視化[3];陳海蕊研究電子檔案序列大數據可視化組織分析,提升電子檔案序列大數據利用率和服務質量等功能[4]。
為實現電子檔案序列大數據安全、快速分類,在前人研究理論基礎上,設計基于數字標簽的電子檔案序列大數據并行分類系統,采用多屬性數字標簽確保涉密電子檔案序列大數據的安全性,避免電子檔案序列大數據被復制、修改以及惡意傳播,并在其安全性得以保障的基礎上實現快速、精準分類。
1? 并行系統總體設計方案
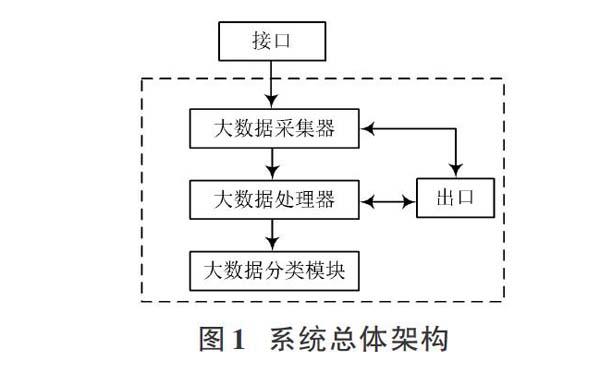
基于云計算理念設計電子檔案序列大數據并行分類系統總體架構[5]。云計算是基于SOA組件模型架構,依照用戶要求,通過動態易擴展方式分布式配置電子檔案序列大數據,提升云計算兼容性,促進電子檔案序列大數據并行分類系統分類穩定性。系統總體架構如圖1所示。
1.1? 大數據采集器設計
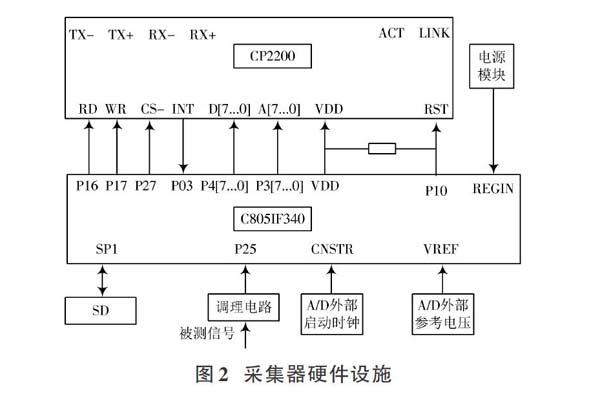
通過設計大數據采集器實現電子檔案序列大數據分類系統大數據采集。大數據采集器硬件裝置安裝于計算機網絡接口處,將采集到的電子檔案序列大數據通過網絡接口傳輸到計算機[6]。數據采集器硬件設施如圖2所示。
大數據采集器主要由芯片及單片機構成,大數據采集器采集到的電子檔案序列大數據經由云計算接口傳輸到大數據處理器[7]。大數據采集器電源模塊將單片機產生的5 V電壓通過REGIN傳輸到電壓調節器,為單片機上方工作供應大小為3 V的電壓;同時通過引腳輸送3 V電壓至其余同樣需要3 V電壓器件中使用,單片機傳輸電壓完成后與其余單片機交換信息[8]。電路整改網絡信號,通過P25引腳將網絡信號輸送至A/D轉化器,并轉化網絡信號為數據[9],完成電子檔案序列大數據采集工作。
1.2? 大數據處理器設計
大數據處理器處理對象為大數據采集器所采集電子檔案序列大數據。大數據處理器選取型號為IXP2400處理器,通過數字線程和微引擎數字信號處理所采集大數據,該方法具備共享效率快的特點[10]。大數據處理器處理大數據過程及模式均可以通過編程實現。
1.3? 分類方法
系統中的大數據分類模塊采用基于多屬性數字標簽的電子檔案序列大數據加密分類方法,完成電子檔案序列大數據分類。
1.3.1? 多屬性數字標簽設計
多屬性數字標簽是一種數據段,可以與電子檔案序列大數據邏輯相關,結構相融。通過瀏覽多屬性數字標簽屬性資料,根據行為屬性中用戶權限資料,判斷用戶權限操作,完成電子檔案數據讀取。多屬性數字標簽應用流程如下:
1) 用戶想訪問涉密電子檔案時,需先向服務器端發送訪問請求,訪問請求接收后,審核用戶身份資料,判別多屬性數字標簽攜帶情況以及多屬性數字標簽是否完整。審核通過,向用戶發送電子檔案位置資料;審核未通過,請求失敗。
2) 用戶身份資料審核通過并成功接收電子檔案位置資料后,需要發送該目標電子檔案查詢請求,等待管理者查詢該用戶目標電子檔案操作權限,并將查詢請求結果返回。
3) 用戶本次操作完成后,多屬性數字標簽中該電子檔案可查詢次數減少一次。
1.3.2? 電子檔案序列大數據加密分類方法
采用基于多屬性數字標簽的電子檔案序列大數據加密分類方法,在保證電子檔案序列大數據安全、可靠、降低涉密電子檔案非法竊取概率基礎上,完成電子檔案序列大數據并行分類。電子檔案序列大數據加密分類原理如圖3所示。
1) 明確待分類電子檔案序列大數據,設定[q]為電子檔案序列大數據分類完成的大數據塊數量,[p]為電子檔案序列大數據操作者數量,則密鑰數量為[Cp-1q],每個數據塊至少具備[Cp-1q]個密鑰。將[Cp-1q]作為變量,采用密鑰生成算法及密鑰分解算法分別逐步算出密鑰數組K和各個分類大數據塊所攜帶密鑰數組,計算各組組合值。
2) 依據等長分類原則分類加密電子檔案序列數據,保證分類后有[q]個大數據塊。設定block?length、[bi(1,2,…,q)]分別為各個大數據塊字節長度、大數據塊列表。保存未達到整個大數據塊的數據位到surplus中,位長用surplus?length描述該大數據塊位長。
3) 電子檔案序列大數據分類時,將大數據塊個數[q]、電子檔案序列大數據操作者數量[p]、密鑰數量[Cp-1q]以及大數據塊位置編號block?num等資料增添在大數據塊塊頭位置。目前大數據塊擁有末尾大數據塊位長surplus?length及密鑰數組資料。
4) 連接末端大數據塊到各個完整的分類大數據塊末端。
采用上述方法將電子檔案序列大數據劃分為若干大數據塊,實現電子檔案序列大數據加密分類。
2? 系統測試
為驗證本文系統的有效性,選擇某網絡知識庫電子檔案序列大數據作為系統測試對象,系統硬件配置如下:處理器為Intel 酷睿i3 350M,內存大小為32 GB。參數設置如下:編號測試用電子檔案序列大數據為K1,K2,K3,K4,K5,K6,K7。電子檔案序列大數據種類為:貿易類大數據、經濟類大數據、交通類大數據、文化類大數據、工業類大數據、體育類大數據、軍事類大數據;數據大小分別為1 652 KB,1 685 KB,1 784 KB,1 756 KB,
1 562 KB,1 579 KB,1 655 KB。
采用本文系統對網絡知識庫中的電子檔案序列大數據展開分類測試,系統大數據采集界面如圖4所示。分類結果表明,本文系統可以正確分類電子檔案序列大數據。
本文系統穩定性實驗結果如表1所示。分析表1數據可知,隨著測試次數增加,本文系統分類準確率和數據分類預估值逐步增加,最高分別可達98.63%,98.91,系統召回率最高達99.85%。測試結果表明,本文分類系統準確率及召回率較高,且系統穩定性好。
系統CPU占用率及內存占用率結果如表2所示。
表2結果顯示,本文系統CPU占用率處于48%~58%之間,內存占用率為18%~31%。測試結果表明本文系統資源占用率較小。
由于本文采用電子檔案序列大數據加密分類方法,系統分類效率由大數據分塊大小決定。大數據塊越多,系統負載越大,分類時間也隨之變長。為驗證大數據塊對本文系統效率的影響,選擇大小為160 MB的電子檔案序列大數據作為測試對象。測試結果如圖5所示。
從圖5測試結果可以看出,當大數據分塊大小為4~5 MB時,本文系統分類耗時最短;當大數據分塊大小超過6 MB時,系統耗時隨大數據塊大小增大急劇上升,嚴重降低系統分類效率。實驗結果表明,大數據塊大小為4~5 MB時,本文系統分類效率最高。
3? 結? 論
本文設計基于數字標簽的電子檔案序列大數據并行分類系統,通過增加多屬性數字標簽,增強電子檔案序列大數據安全性,使電子檔案序列大數據具備防復制、防修改、防擴散等能力。采用加密分類方法將電子檔案序列大數據分成大數據塊,在降低系統存儲空間的基礎上,保障電子檔案序列大數據不被泄露。實驗結果表明,本文系統采用數字標簽進行大數據分類過程中,當數據塊大小為4~5 MB時,系統分類耗時最短,分類效率最高。
參考文獻
[1] 高坤,戴江山,張慕華.基于大數據技術的電子戰情報系統[J].中國電子科學研究院學報,2017,12(2):111?114.
[2] 張譯天,于炯,魯亮,等.大數據流式計算框架Heron環境下的流分類任務調度策略[J].計算機應用,2019,39(4):1106?1116.
[3] 丁家滿,王思晨,賈連印,等.Spark環境下基于綜合權重的不平衡數據集成分類方法[J].小型微型計算機系統,2019,40(2):17?21.
[4] 陳海蕊.面向電子檔案大數據的可視化組織與分析[J].科學技術與工程,2018,18(2):279?284.
[5]申琢.基于云計算和大數據挖掘的礦山事故預警系統研究與設計[J].中國煤炭,2017,43(12):109?114.
[6] 肖建波,鄭偉,代作偉,等.基于大數據采集的播出監管系統設計與實現[J].電視技術,2017,41(6):40?44.
[7] 王磊,鄒恩岑,曾誠,等.基于Spark的大數據聚類研究及系統實現[J].數據采集與處理,2018,33(6):137?145.
[8] 呂慶,劉頌,劉小杰,等.基于大數據技術的燒結全產線質量智能控制系統[J].鋼鐵,2018(7):1?9.
[9] 王欣,張冬梅.大數據環境下基于高校讀者小數據的圖書館個性化智能服務研究[J].情報理論與實踐,2018,41(2):132?137.
[10] 向小佳,趙曉芳,劉洋,等.一種正交分解大數據處理系統設計方法及實現[J].計算機研究與發展,2017,54(5):1097?1108.
猜你喜歡
中國市場(2016年36期)2016-10-19 04:41:16
中國市場(2016年36期)2016-10-19 03:31:48
中國市場(2016年35期)2016-10-19 01:30:59
商(2016年27期)2016-10-17 06:26:00
今傳媒(2016年9期)2016-10-15 23:35:12
今傳媒(2016年9期)2016-10-15 22:09:11
新聞世界(2016年10期)2016-10-11 20:13:53
科技視界(2016年20期)2016-09-29 10:53:22
中國記者(2016年6期)2016-08-26 12:36:20
