一種優(yōu)化初始聚類中心的自適應聚類算法
2020-07-26 14:23:53曹端喜唐加山陳香
軟件導刊 2020年7期
曹端喜 唐加山 陳香


摘 要:K均值算法(K-Means)是聚類算法中最受歡迎且最健壯的一種算法,然而在實際應用中,存在真實數(shù)據(jù)集劃分的類數(shù)無法提前確定及初始聚類中心點隨機選擇易使聚類結果陷入局部最優(yōu)解的問題。因此提出一種基于最大距離中位數(shù)及誤差平方和(SSE)的自適應改進算法。該算法根據(jù)計算獲取初始聚類中心點,并通過SSE變化趨勢決定終止聚類或繼續(xù)簇的分裂,從而自動確定劃分的類簇個數(shù)。采用UCI的4種數(shù)據(jù)集進行實驗。結果表明,改進后的算法相比傳統(tǒng)聚類算法在不增加迭代次數(shù)的情況下,聚類準確率分別提高了17.133%、22.416%、1.545%、0.238%,且聚類結果更加穩(wěn)定。
關鍵詞:聚類算法;K-Means算法;初始聚類中心;自適應
DOI:10. 11907/rjdk. 201478 開放科學(資源服務)標識碼(OSID):
中圖分類號:TP301文獻標識碼:A 文章編號:1672-7800(2020)007-0028-04
An Adaptive Clustering Algorithm by Optimizing Initial Clustering Centers
CAO Duan-xi1,TANG Jia-shan2,CHEN Xiang2
(1. School of Communication and Information Engineering, Nanjing University of Posts and Telecommunications;
2. School of Science, Nanjing University of Posts and Telecommunications, Nanjing 210000,China)
Abstract:K-Means is one of the most popular and robust clustering algorithms. However, in practical applications, the number of classes divided by the real data set cannot be determined in advance and the random selection of the initial clustering center point easily leads to the problem that the clustering result falls into the local optimal solution. To this end, this paper proposes an adaptive and improved algorithm based on the maximum distance median and the sum of squared errors (SSE). The algorithm obtains the initial cluster center point through calculation, and decides to terminate the cluster or continue the division of the cluster based on the change trend of the SSE, so as to automatically determine the number of clusters to be divided. The results of experiments using four UCI data sets show that the improved algorithm improves the clustering accuracy by 17.133%, 22.416%, 1.545%, and 0.238% respectively without increasing the number of iterations compared to the traditional clustering algorithm, and the clustering results are more stable.
Key Words: clustering algorithm; K-Means algorithm; initial clustering center; adaptive
0 引言
“物以類聚”指將同類事物聚在一起。在數(shù)據(jù)科學方面,將相類似的數(shù)據(jù)通過某種準則聚集在一起,從而發(fā)現(xiàn)數(shù)據(jù)間的聯(lián)系,稱為聚類。在實際問題中,聚類分析無法事先知道待操作數(shù)據(jù)劃分的類結果,類結果的形成完全取決于數(shù)據(jù)集中樣本之間的內(nèi)在聯(lián)系[1],這種發(fā)現(xiàn)內(nèi)在結構的方法,是一種無監(jiān)督學習方法。聚類技術是數(shù)據(jù)挖掘領域的重要方法。近年來隨著數(shù)據(jù)量的倍增及大數(shù)據(jù)技術的發(fā)展,該技術備受關注,其在模式識別、圖像分割[2]、文檔聚類[3]、市場細分[4-5]、特征學習[6-7]等方面應用廣泛。
K-Means[8]算法是一種基于劃分的無監(jiān)督學習聚類算法[9],最早由Macqueen提出,該算法由于其簡單、快速的特點得到了廣泛應用,但算法存在難以估計簇數(shù)、隨機選擇的初始聚類中心會使結果陷入局部最優(yōu)化、對離群點和孤立點敏感、無法識別非球形簇的數(shù)據(jù)等缺陷。
目前K-Means算法研究方向主要分為聚類簇數(shù)[k]值確定與初始聚類中心點確定兩個方面。國內(nèi)外眾多學者提出了許多改進算法。文獻[10]基于圖像分割的思想,利用數(shù)據(jù)維數(shù)密度分析,使用分水嶺算法對原始數(shù)據(jù)集進行分割,根據(jù)分割的區(qū)域中心點確定初始聚類中心,分割的區(qū)域個數(shù)作為簇數(shù)[k]。該方法在一定程度上能夠獲得準確的[k]值與初始聚類中心,但分水嶺算法存在噪聲敏感及過分割現(xiàn)象,若數(shù)據(jù)集含有噪聲則聚類結果精度將大幅下降;文獻[11]利用LOF離群點檢測算法篩除離群點,在篩選后的樣本中利用最大最小距離算法選擇初始聚類中心,能有效避免離群點的影響,但篩選過程降低了算法效率;文獻[12]通過比較[k]取所有可能值的聚類結果,選出其中聚類結果最佳[k]值,提出一種確定類簇個數(shù)的方法,但當[k]值變化范圍很大時,該方法將耗費大量時間和精力;文獻[13]提出的X-means算法,采用貝葉斯信息準則(BIC)計算得分,利用K-Means算法二分相應的簇,以此確定最優(yōu)類簇個數(shù);文獻[14]利用期望最大化算法理論,提出似然函數(shù)的碎石圖方法,對于不規(guī)則數(shù)據(jù)集的聚類結果比利用BIC方法更加可靠;文獻[15]利用最小方差與密度之間的關系,提出一種利用最小方差優(yōu)化初始聚類中心的方法,該方法在方差計算與比較上時間復雜度過高,且對于存在孤立點的數(shù)據(jù)不能獲得較好的聚類結果;文獻[16]采用最大最小距離方法,通過兩階段搜索獲取最佳初始聚類中心,對數(shù)據(jù)集采用先分割后合并的思想獲得分類結果,提出一種多中心距離算法。該方法對于不規(guī)則簇有良好的聚類能力。
本文在分析已有算法的基礎上,提出一種基于最大距離中位數(shù)的改進算法,該算法基于K-Means算法,通過計算獲取初始聚類中心點,可自適應確定類簇個數(shù),在不增加迭代次數(shù)的情況下提升聚類結果準確率。仿真結果表明,本文算法聚類結果更加穩(wěn)定。
1 最大距離中位數(shù)與SSE的自適應聚類算法
1.1 算法基本思想
K-Means算法基本思想為:將含有[n]個對象的數(shù)據(jù)集S劃分為[k]個簇,簇中每個對象到簇中心距離最小。K-Means算法是一個不斷迭代的過程[17],影響該算法性能的一個重要方面是初始聚類中心點的選擇,K-Means算法采用隨機獲取的方法,聚類結果易陷入局部最優(yōu)解,另外在使用時必須提前設置好k值,具有一定局限性。
本文算法初始聚類中心點選擇,借鑒K-Means++[18]算法的思想,將數(shù)據(jù)集中最有可能成為聚類中心且相距最遠的兩個點作為最初的選擇點。在數(shù)據(jù)集中存在噪聲或孤立點的情況下,如果直接選擇相距最遠兩點作為初始聚類中心,一旦選擇到的點為噪聲或孤立點,聚類結果會陷入局部最優(yōu)解。故本文提出最大距離中位數(shù)的方法,根據(jù)當前聚類數(shù)據(jù)點與相距最遠兩點和當前聚類中心點之間的距離大小關系,獲取距離值為中位數(shù)的數(shù)據(jù)點,作為下一輪迭代的初始聚類中心點。該方法可有效避免選擇噪聲或者孤立點對聚類結果產(chǎn)生的影響。具體過程如下。
首先獲取相距最遠的點[xa]、[xb],記錄距離為[Dist]。計算所有點與[xa]、[xb]之間的距離[d]以及與初始聚類中心[ic](當前簇的聚類中心點)之間的距離[dc],為使數(shù)據(jù)點限定在各自相應的簇中,采用[dDist/2]且[dcDist/2]作為數(shù)據(jù)點過濾準則,滿足要求的點的總距離[dsum=d+dc]會被記錄下來;最后對記錄集中的[dsum]進行從小到大排序,選擇距離值為中位數(shù)的點作為新的初始聚類中心點。
通過SSE值變化趨勢實現(xiàn)自動確定聚類簇數(shù),曲線變化程度下降幅度最大位置為肘部,對應[k]值為最佳聚類個數(shù),由此可得在此[k]值下聚類的SSE值為最佳值,往后會增加聚類個數(shù),但SSE值變化很小,產(chǎn)生如圖1所示的類似于肘部一般的曲線。但一些數(shù)據(jù)集在聚類過程中呈現(xiàn)出的SSE值變化曲線下降比較平滑,如圖2所示,不易于直觀獲取最佳的聚類個數(shù)[k]。本文對于第一種情況,由于變化曲線遞減程度比較明顯,利用本次與前一次的SSE差值對比[(SSE(t-1)-SSE(t))/SSE(t)]獲取變化量;第二種情況,由于變化趨勢不明顯,可以采用區(qū)間變化值進行比較,每次比較兩段區(qū)間內(nèi)的SSE值變化量,即采用[SSE(t-2)-][SSE(t-1)]與[SSE(t-1)-SSE(t)]對比;將兩種方法得出的變化量與設定的閾值進行比較,如果變化量小于設定的閾值變化量,則終止聚類運算,否則繼續(xù)進行簇分裂操作,從而實現(xiàn)自動確定聚類簇數(shù)。簇分裂操作是根據(jù)已劃分的簇SSE值與簇數(shù)據(jù)個數(shù)的平均值大小選擇分裂平均值最大的簇,平均SSE值越大在一定程度上可以說明數(shù)據(jù)之間差異性較大,需要分裂以降低數(shù)據(jù)之間的差異性。簇的分裂采用K-Means算法。[SSE]值計算公式為:
其中,[k]表示當前類簇個數(shù),[x]表示簇[Ci]中的數(shù)據(jù)點,[Oi]表示當前類簇質(zhì)心。
1.2 算法步驟
給定數(shù)據(jù)集[S={x1,x2,?,xn}],設定算法初始聚類中心集[C],K-Means算法初始聚類中心點集合[C],閾值[δ1]、[δ2],聚類個數(shù)最大值[kmax],迭代處理標志[flag]([flag=3]表示算法步驟(3)進入迭代,[flag=7]表示跳轉(zhuǎn)至步驟(7)),算法具體步驟如下:
(1)計算數(shù)據(jù)集S中所有數(shù)據(jù)點之間的距離[d(xi,xj)],保存并從小到大排序。
(2)由于初始簇由當前整個數(shù)據(jù)集組成,故令初始[SSE(0)=∞],[t=1](簇數(shù)最小為1,也表示當前類簇的個數(shù)) , 計算質(zhì)心作為聚類初始中心[C(1)={X}]。
(3)定義迭代標志[flag=3],處理過程中若發(fā)生變化,下一輪即滿足聚類終止條件結束聚類。判斷[C(t)=kmax]([C(t)]也表示聚類簇數(shù)),若成立表示初始聚類中心點數(shù)已到達最大聚類個數(shù),終止聚類,[flag=7];否則分別計算所有劃分好的簇[Si]([i]=1,…,t,表示第幾個簇)的[SSE]值以及簇的數(shù)據(jù)個數(shù)[Num]。判斷[SSE]值下降趨勢變化量與閾值之間的關系:[SSE(t-1)-SSE(t)SSE(t)<δ1],滿足則終止聚類,[flag=7];否則繼續(xù)判斷[t3](確保SSE含有兩段可比較的曲線)且[SSE(t-2)-SSE(t-1)SSE(t-1)-SSE(t)<δ2],滿足則終止聚類,[flag=7],否則執(zhí)行步驟(4)。
(4)根據(jù)計算的[SSE]獲取[SSE]均值最大的簇,記為[Smax=maxSSENum],當前簇聚類中心標記為[cmax],隨后利用最大距離法找出[Smax]中相距最遠的兩個點[xa]和[xb],兩點之間距離記為[Dist=dxa,xb],計算數(shù)據(jù)中所有滿足要求的點,利用中位數(shù)方法獲取距離中位數(shù)點[xc]和[xd],返回[xc,xd]。
(5)令[t=t+1](進行分裂操作,簇數(shù)加1),此時[xc,xd]兩點分開拷貝至前一個聚類初始中心點[Ccmax]處,另一點則拷貝至當前初始聚類中心點[Ct]處。
(6)將[C]中的點作為初始聚類中心點,采用傳統(tǒng)K-Means算法劃分簇[Smax],將[C]拷貝至[C],在K-Means算法迭代中更新聚類中心集[C],生成[C]個簇。之后將[C]拷貝至初始聚類中心集[C]中,[flag=3]。
(7)結束聚類運算,輸出最終結果[t]、[C],此時[t]值即最佳的類簇個數(shù)[k]值,初始聚類中心點集為[C]。
步驟(3)中根據(jù)SSE值的變化趨勢判斷是否終止聚類或繼續(xù)簇分裂操作,從而自適應獲取聚類簇數(shù)。步驟(4)是對于當前劃分的簇中需進一步分裂的簇,決定要分裂哪一個簇,通過最大距離中位數(shù)方法獲取新一輪迭代的初始聚類中心點。選擇距離中位數(shù)點作為初始聚類中心可避免數(shù)據(jù)偏移(左偏或右偏)帶來的影響,緊密度更高。
本文算法與K-Means算法最大的不同在于初始聚類中心點的選擇,K-Means算法是隨機選擇,而本文算法是通過計算獲取。K-Means算法時間復雜度為[O(knt)],本文算法的時間復雜度為[O(n2)+O(k2nt)],其中[k]為類別數(shù),[n]為數(shù)據(jù)集包含的對象個數(shù),[t]為聚類的迭代次數(shù)。雖然計算數(shù)據(jù)集中數(shù)據(jù)點之間的距離增加了算法時間開銷,但是通過最大距離中位數(shù)方法獲取的初始聚類中心點,相比隨機選擇的初始聚類中心點,最大距離方法降低了初始聚類中心點分布集中度,使得中心點分布更為分散。過于集中的點會增加迭代次數(shù),而較分散的點通常會減少迭代次數(shù)[19]。中位數(shù)選擇緊密程度相對高的點,即點距離聚類實際中心點更近,可進一步減少算法迭代次數(shù),縮短迭代算法時間,迭代次數(shù)越少表明算法收斂越快,收斂性越好;其次本文算法可根據(jù)SSE值變化自動獲取簇數(shù)k值大小,去除聚類之前對簇數(shù)k值的預估過程,在一定程度上提升了聚類算法效率。
2 實驗結果與分析
2.1 實驗數(shù)據(jù)集與實驗環(huán)境
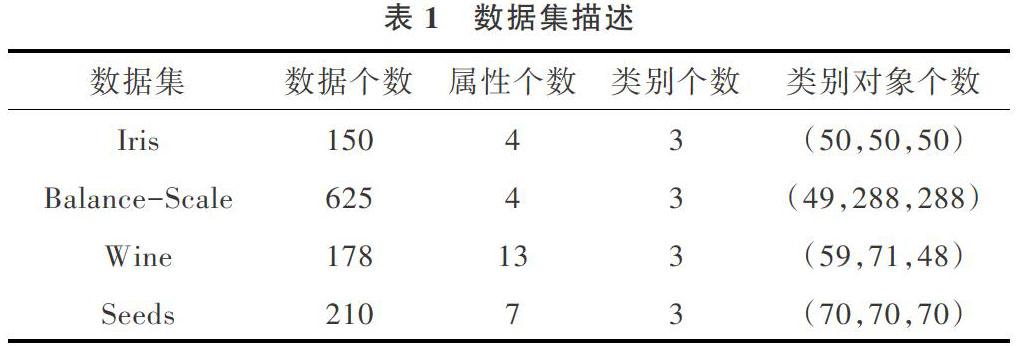
本文實驗采用加州大學歐文分校提供的UCI機器學習庫,選取Iris、Balance-scale、Wine、Seeds數(shù)據(jù)集作為測試數(shù)據(jù)集。實驗編程語言為Java,測試用的主機CPU為Intel? CoreTM i5-4210U CPU,主頻為1.7GHz,內(nèi)存為12GB,改進算法在IDEA上進行測試。實驗主要性能指標為聚類準確率、迭代次數(shù)和運行時間。實驗選擇的Iris、Balance-scale、Wine、Seeds 4個數(shù)據(jù)集的統(tǒng)計信息如表1所示 。實驗參數(shù)[δ1]為0.75,[δ2]為0.18,聚類最大個數(shù)[kmax]為[n],其中[n]為數(shù)據(jù)集數(shù)據(jù)個數(shù)。
2.2 實驗結果分析
由于K-Means算法聚類結果不穩(wěn)定,實驗中對K-Means算法運行結果采取運算10次結果取均值的方法參與比較,有利于提高實驗結果分析合理性。
將不同算法運用至4個數(shù)據(jù)集上進行實驗,將數(shù)據(jù)集分別讀入寫好的運算程序中,實驗結果如表2—表4所示。其中表2為在Iris與Balance-scale數(shù)據(jù)集上的實驗結果,表3為Wine數(shù)據(jù)集與Seeds數(shù)據(jù)集的實驗結果,表4為各數(shù)據(jù)集在各算法下平均運行時間。
為了驗證本文提出算法相比其它優(yōu)化初始中心點算法具有較好的性能,本文選取文獻[20]算法進行實驗結果對比。
從表2—表3可以看出,在聚類準確率方面,本文算法相比傳統(tǒng)算法在不增加迭代次數(shù)的情況下,Iris、Balance-scale、Wine、Seeds數(shù)據(jù)集聚類結果準確率分別提高了17.133%、22.416%、9.545%、0.238%。本文算法通過自適應得到各個數(shù)據(jù)集的類簇個數(shù),其中Iris、Wine、Seeds數(shù)據(jù)集得出的類簇個數(shù)與數(shù)據(jù)集類簇個數(shù)一致,Balance-scale數(shù)據(jù)集本文算法自動獲取2個類簇,相比數(shù)據(jù)集真實類簇個數(shù)少1個,但聚類準確率提升了22.416%,迭代次數(shù)減少了13.7次。
相比文獻[20]算法,本文算法在不降低聚類準確率的同時,Iris、Wine、Seeds數(shù)據(jù)集運算迭代次數(shù)分別減少1次、4次、4次,對于Balance-scale數(shù)據(jù)集,雖然迭代次數(shù)一致,但準確率提升了0.96%。上述聚類結果對比表明,通過最大距離中位數(shù)方法計算獲取的初始聚類中心點距離類簇實際聚類中心點更近,算法收斂次數(shù)更少,收斂速度更快,本文算法在初始聚類中心點的選擇上性能更優(yōu)。
從表4可以看出,由于文獻[20]算法在算法開始階段需計算各個數(shù)據(jù)點之間的距離大小并排序,且在進行簇分裂計算時需根據(jù)相應算法計算選出相對最佳初始聚類中心點,這些計算增加了算法時間復雜度,所以本文算法與文獻[20]算法相比,運行時間更短。從本文算法與文獻[20]算法的運行時間對比可以看出,4個數(shù)據(jù)集在本文算法下進行實驗的整體運行時間均比文獻[20]算法更短,表明迭代次數(shù)的減少可有效降低整體算法時間復雜度,提升算法運行效率。
3 結語
本文針對傳統(tǒng)K-Means算法存在的主要缺陷,提出了一種基于最大距離中位數(shù)與SSE的自適應改進算法,利用最大距離取中位數(shù)的方法,通過計算獲取初始聚類中心點,并根據(jù)SSE值變化趨勢決定終止聚類或繼續(xù)簇的分裂,自動確定數(shù)據(jù)劃分類簇個數(shù)。實驗結果表明,該算法可獲取較高的聚類準確率和較為可觀的收斂速度,聚類結果穩(wěn)定且可自動獲取聚類類簇個數(shù),具有一定的技術優(yōu)勢和應用價值。
參考文獻:
[1] 海沫,張書云,馬燕林. 分布式環(huán)境中聚類問題算法研究綜述[J]. 計算機應用研究,2013,30(9):2561-2564.
[2] 鄒旭華,葉曉東,譚治英.? 一種密度峰值聚類的彩色圖像分割方法[J].? 小型微型計算機系統(tǒng),2017,38(4):868-871.
[3] SARDAR T H,ANRISA A. An analysis of MapReduce efficiency in document clustering using parallel K-means algorithm[J]. Future Computing and Informatics Journal,2018, 3(2): 200-209.
[4] TLEIS M,CALLIERIS R,ROMA R. Segmenting the organic food market in Lebanon: an application of K-means cluster analysis[J]. British Food Journal, 2017, 119(7): 1423-1441.
[5] HUNG P D,NGOC ND,HANH T D. K-means clustering using R A case study of market segmentation[C]. Proceedings of the 2019 5th International Conference on E-Business and Applications,2019:100-104.
[6] TANG J L,WANG D,ZHANG Z G,et al.Weed identification based on K-means feature learning combined with convolutional neural network[J]. Computers and Electronics in Agriculture,2017,135: 63-70.
[7] TANG J L, ZHANG Z G, WANG D, et al. Research on weeds identification based on K-means feature learning[J]. Soft Computing, 2018, 22(22): 7649-7658.
[8] MACQUEEN J. Some methods for classification and analysis of multivariate observations[C]. Proceedings of Berkeley Symposium on Mathematical Statistics & Probability,1965:281-297.
[9] SAROJ K. Review:study on simple K-mean and modified K-mean clustering technique[J]. International Journal of Computer Science Engineering and Technology, 2016, 6(7):279-281.
[10] WANG X,JIAO Y,F(xiàn)EI S. Estimation of clusters number and initial centers of K-means algorithm using watershed method[C]. Guiyang: International Symposium on Distributed Computing & Applications for Business Engineering & Science, 2015.
[11] 唐東凱,王紅梅,胡明,等.? 優(yōu)化初始聚類中心的改進K-means算法[J]. 小型微型計算機系統(tǒng), 2018, 39(8):1819-1823.
[12] 周世兵,徐振源,唐旭清.? K-means算法最佳聚類數(shù)確定方法[J]. 計算機應用,2010,30(8):1995-1998.
[13] GOODE A. X-means: extending K-means with efficient estimation of the number of clusters[M]. Berlin:Springer,2000.
[14] 趙楊璐,段丹丹,胡饒敏,等. 基于EM算法的混合模型中子總體個數(shù)的研究[J]. 數(shù)理統(tǒng)計與管理, 2020, 39(1):35-50.
[15] 謝娟英,王艷娥. 最小方差優(yōu)化初始聚類中心的K-Means算法[J].? 計算機工程,2014, 40(8):205-211,223.
[16] 周涓,熊忠陽,張玉芳,等. 基于最大最小距離法的多中心聚類算法[J]. 計算機應用,2006,26 (6):1425-1427.
[17] ANIL K J. Data clustering: 50 years beyond K-means[J]. Pattern Recognition Letters,2010, 31(8):651-666.
[18] ARTHUR D,VASSILVITSKII S. K-means++: the advantages of careful seeding[C]. New Orleans: Proceedings of the Eighteenth Annual ACM-SIAM Symposium on Discrete Algorithms, 2007.
[19] AGRAWL R, IMIELINSKI T, IYERB, et al. Mining K-Means rules between sets of items in large database[C]. Proceedings of ACM SIGMOD Conference on Management of Data,2013:1-10.
[20] 成衛(wèi)青,盧艷紅. 一種基于最大最小距離和SSE的自適應聚類算法[J]. 南京郵電大學學報(自然科學版),2015,35(2):102-107.
(責任編輯:江 艷)
