基于預警自適應技術的監控系統設計
2020-07-29 12:35:24曹靖城張繼東吳春平
計算機與網絡 2020年13期
關鍵詞:系統
曹靖城 張繼東 吳春平
1引言
傳統監控系統能夠實時采集各項閾值類監控項相關監控數據并進行分析,結合預先設定的閾值進行故障檢測和告警,但在異常判定閾值的設定上存在不足。對不同的應用場景使用統一設定的閾值難以做適配,即使人為根據具體情況進行不同的閾值設定,也無法避免會有主觀因素的影響。本方案提出在保證異常檢測可靠的前提下進一步使檢測閾值合理化,提高監控和告警效率。
2系統總體方案
2.1方案設計
使用一定周期內各項指標的置信區間來設定閾值,在大量數據的基礎上,采用統計學方法計算出合理的閾值區間,采用分時段、動態閾值的方式對指標進行監控并對異常發出告警。同時設置置信區間更新機制應對突發情況,一旦監控數據超出置信區間或系統硬件參數發生變化,可在發出系統警告的同時清除當前置信區間,重新統計,生成新的置信區間。在新的置信區間未生成時,依據人工設定初始閾值,待新的置信區間統計完成,自動切換為新的置信區間。
2.2方案架構
本方案包括5個核心模塊,方案整體架構如圖1所示。
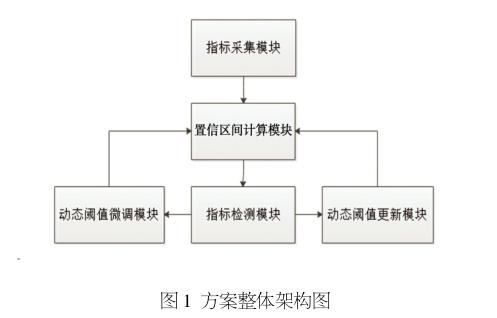
①指標采集模塊,對監控對象分時段周期進行指標數據采集。
②置信區間計算模塊,計算每一時段內指標的平均值、標準差,并結合相關數據對每一周期設置置信水平,計算置信區間。
③指標監測模塊,通過劃分時段的方法計算每個周期內對應指標的相關統計數據,可對每個周期分別動態設置置信區間。
④動態閾值微調模塊,指標監測正常則將采集到的數據用來更新相關統計值并微調動態閾值。
⑤動態閾值更新模塊,指標監測異常則重新采集數據,計算并更新閾值區間,采用設定閾值保持監控,在異常恢復期間重新采集數據進行閾值自適應更新。
2.3系統流程及核心算法
系統設計整體流程如圖2所示,具體步驟如下(以CPU利用率為例)。
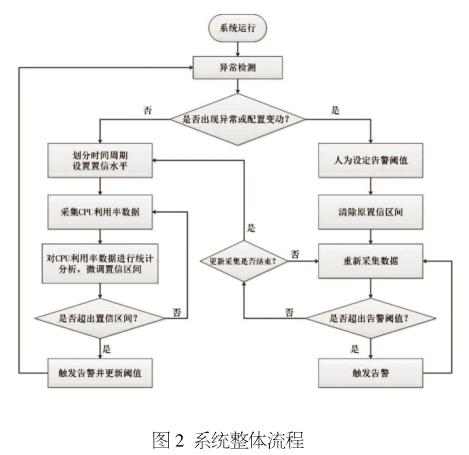
步驟1:根據具體應用場景的實際要求,將一天劃分成不同的時間周期,周期可自定義,采集不同時間周期內的CPU利用率并進行統計分析。
步驟2:計算連續個周期的CPU利用率數據,每一時間周期的數據分別統計,計算每個時間周期內的平均值、標準差,對每一時間周期設置置信水平,按下式計算置信區間:

式(2)用于計算某一周期內CPU利用率的標準差,其中為樣本數量,為式(1)計算得到的樣本均值。
選擇適用于場景的置信度并計算誤差范圍,結合樣本均值生成對應置信度的置信區間,計算公式如下:

步驟3:使用計算得出的置信區間作為當前周期的動態閾值進行CPU利用率監測,若數據處于置信區間內則反饋到置信區間計算模塊進行閾值的微調,若數據超出置信區間則觸發告警。
步驟4:觸發告警后進入置信區間更新狀態,重新采集一定量的數據并進行統計分析,將計算得出的新置信區間更新為動態閾值。更新數據采集期間使用人為設定的固定閾值進行異常檢測,數值超出告警閾值則觸發告警。
2.4測試結果及分析
本測試采用CPU使用率數據為例進行分析,采用95 %的置信水平進行置信區間的計算。實驗數據表示,正常情況下CPU的使用率在20 %上下浮動,而當某一時間點加入新服務后,該服務器的CPU使用率上升,維持在80 %上下浮動。若使用固定閾值,并不能很好地反映當前CPU的負載水平,只能依靠人為修改閾值。若使用動態閾值,根據統計數據計算置信區間,得到較為合理的浮動閾值,并且在服務增加之后能夠自適應地調整閾值以適配業務環境變化,可以更好地反應當前CPU的負載水平,基于置信區間對業務系統設置“分時+分區”的個性化閾值動態設定,規避人為主觀性,極大地提升準確告警能力。
3結束語
文章簡要介紹了監控預警自適應的系統方案、模塊設計、流程說明以及對測試結果的分析,本設計支持嵌入監控系統具有較好的實用性,動態閾值設定精準高效,能夠應對各種突發情況并自動適配多種數值監控告警場景。
猜你喜歡
工業設計(2022年8期)2022-09-09 07:43:20
軍民兩用技術與產品(2021年10期)2021-03-16 06:05:30
北京測繪(2020年12期)2020-12-29 01:33:58
裝備制造技術(2019年12期)2019-12-25 03:06:46
制造技術與機床(2019年10期)2019-10-26 02:47:06
中國洗滌用品工業(2019年4期)2019-05-11 09:27:34
鐵道通信信號(2018年5期)2018-06-28 03:06:24
家庭影院技術(2017年9期)2017-09-26 03:41:45
知識經濟·中國直銷(2017年5期)2017-06-15 20:28:19
通信電源技術(2016年6期)2016-04-20 06:21:32
