數據挖掘在科研設備管理中的應用
2020-07-29 12:35:24李恩寧梁山清葛紅志劉榮斌王曉玲王玨
計算機與網絡 2020年13期
關鍵詞:數據挖掘
李恩寧 梁山清 葛紅志 劉榮斌 王曉玲 王玨
摘要:針對科研院所設備管理過程中普遍存在的設備真實使用率統計難、設備租借分配不合理等問題,將數據挖掘方法與實際問題相結合,根據設備管理系統采集的各設備電流數據,用支持向量機(Support Vector Machine,SVM)算法判定各設備的工作狀態,進而分析出真實使用情況。根據各部門的設備歷史租借清單,用Apriori關聯規則算法分析得出不同設備間的共同關聯關系,為科研設備管理部門采購及出租設備提供合理的分配方案。
關鍵詞:數據挖掘;支持向量機;關聯規則
中圖分類號:TP18文獻標志碼:A文章編號:1008-1739(2020)13-60-4

0引言
科研院所和院校通用設備作為固定資產的組成部分,是現代化建設事業的重要物質保障。科學、有效地管理固定資產,發揮最大使用效益,對提高經濟和社會效益、保證資產保值增值及保持和提高科研生產能力具有重要意義。
目前的設備管理系統[1-3],可實現設備信息的存儲與查詢,可采集設備電流、位置等信息,對使用情況做簡單的統計分析。系統在信息化上有所突破,但智能化尚有不足。
數據挖掘[4]是人工智能和數據庫領域研究的熱點問題,涉及的分類算法[5]和關聯規則[6-7]算法可應用于眾多領域。本文借助設備管理系統,基于多分類SVM[8]思想,探究設備狀態判定算法,分析單個設備的真實使用率;基于Apriori[9]思想,探究設備關聯分析算法,分析設備間的借用和使用關聯關系,對設備的購買、預期使用等提供合理的建議。
1優化算法
1.1優化方向
科研設備管理系統的優化方向有2個:①設備租用后使用率是一個受關注的問題,目前只能以電流值來識別關機和開機2種模式,認為開機就是在工作,并未深度探尋設備的真實工作情況,即無法判別開機工作還是開機空轉的情況,以及工作中處于何種工作模式。將其抽象成分類問題,可考慮用SVM算法來建模判定狀態,獲取設備的真實使用率。②對于設備購置和借用分配問題,目前也未有更合理的解決方案,如果能夠通過各借用部門對每類設備的歷史使用情況分析出規律,則可作為一種輔助決策。將其抽象成關聯規則問題,可考慮用Apriori算法從歷史借用清單和使用數據中找出不同設備的關聯關系,進而為每類設備的借用去向和數量提供參考。
1.2設備狀態判定算法
SVM方法是建立在統計學習理論的VC維理論和結構風險最小原理基礎上的,根據有限的樣本信息在模型的復雜性和學習能力之間尋求最佳折衷,以期獲得最好的推廣能力[10]。
傳統的SVM只能進行二分類,對于多分類問題,可組合多個二分類器來實現多分類器的構造,即訓練出多個SVM分類函數,并構成類似二叉樹的分類結構,對輸入數據進行判定。
在設備管理系統中,簡單的設備狀態很少,通過電流加上允許的誤差就可以判斷出狀態,復雜的設備有很多狀態,且各種狀態下,電流差別不大。為了進行精確分析,需要掌握準確的狀態。為此,可將設備型號、電流值以及設備所處狀態3個指標作為一個樣本進行存儲,生成訓練樣本集合和驗證樣本集合,其中設備所處狀態作為標簽,運用SVM方法訓練和驗證多個SVM分類模型的組合。具體算法如下:

④再以同樣的方式,每次將工作狀態中的第一個設置為-1,其余設置為1,重復上述步驟,得到更多的分類函數,最終分類函數為( ),2( ),...,+1( )。
根據設備的實際數據,生成輸入項,依次經過( ),2( ),...,+1( )的判斷,如果在+1( )之前的任一分類函數得到-1則停止,得到對應的設備狀態;否則+1( )=1,即工作狀態為對應的設備狀態。根據算法實時判定的工作狀態,可統計單臺設備每天的真實使用率。
1.3設備關聯分析算法
Apriori是布爾關聯規則挖掘頻繁項集的原創性算法,使用一種稱作逐層搜索的迭代方法,查找存在于項目集合或對象集合之間的頻繁模式、關聯性或因果結構[11-12]。
在設備管理系統中,根據設備歷史租用和使用數據,分析設備間的關聯關系。此項分析中,考慮靜態和動態2種情況:
①靜態:根據設備出借情況,分析設備間的關聯程度,從共同出借的設備找關聯關系。從各部門大量的歷史借用清單入手,用Apriori算法挖掘哪些設備總是一起被借用,這個不限于指定的部門,也許好幾個部門都需要同時借某幾種設備,這個結果反映了對各種設備的需求關聯。
②動態:以同一部門使用的設備、相同時間段處于工作狀態以及地理位置相互靠近為條件,選取滿足條件的設備,分析設備間的使用關聯關系。從使用數據中找到共同使用的設備,反映具體的科研項目對設備的需求。
上述分析,使用關聯規則算法。具體算法如下:

支持度:所有設備借用清單中,某幾類設備同時出現的次數與總的清單數的比例。
最小支持度閾值:設置支持度的最小值,大于或等于該閾值的可稱為頻繁項集;小于該閾值的項集則被過濾掉。
項:指單臺設備。
項集:幾類設備的組合。
頻繁項集:指頻繁在清單中出現的項集,所謂“頻繁”的標準就是這個項集出現的次數滿足最小支持度閾值。
頻繁項集:種設備同時在清單中頻繁出現。
算法運行結束,可從1到最大數目輸出有關聯關系的設備組,并給出每組關聯的支持度和置信度等指標。在找出相互關聯的設備后,可對管理部門在設備數量購置和借用去向上提供參考建議。
2算法應用示例
2.1設備狀態判定算法
離線訓練階段:采集數據,形成數據矩陣,=[示波器A 10 mA待機;頻譜儀R 200 mA開機;信號發生器B 170 mA工作狀態2;……],是一個100行3列的矩陣,即數據采集了100條,x是這個矩陣的前2列,第1列設備型號可用數字代替,便于數值計算,且要求同類設備數字相同;第2列是電流值,單位為mA;是最后一列,表示設備狀態,假如所有設備狀態共有{待機、開機、工作狀態1、工作狀態2}4種,因為SVM分類函數要求每次只能分成2類,值標簽只有{-1,1},故先將=[{待機}、{開機、工作狀態1、工作狀態2}],將{待機}置為-1,{開機、工作狀態1、工作狀態2}置為1,訓練分類函數( ),得到的結果可判定新數據處于待機還是其他3種狀態;再以同樣的方式,以=[{開機}、{工作狀態1、工作狀態2}]為標簽,其中將{開機}置為-1,{工作狀態1、工作狀態2}置為1,再次劃分得到分類函數2( ),得到的結果可判定新數據處于開機還是其他2種工作狀態;再以同樣的方式可得到3( ),能區分新數據處于工作狀態1還是工作狀態2。
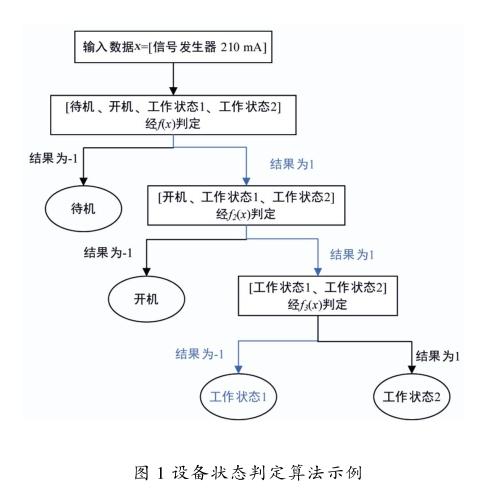
在線判定階段:如前所述生成了分類函數組合,現在輸入一組新數據=[信號發生器B 210 mA],經( )判定,結果為1,則繼續由2( )判斷,結果為1,則繼續由3( )判定,結果為-1,則表示處于工作狀態1,結束。具體過程如圖1所示。
圖中藍色部分為數據經過的判定流程,上述結果為設備狀態的一次判定結果,可設定時段為5 min判定一次,則該設備當天進行了288次判斷,其中122次處于待機,54次處于開機,112次處于工作狀態1,則該設備當天的實際時長為9 h 20 min,真實使用率為38.9%,有4.5 h處于開機不工作的狀態,其余時段處于待機狀態。
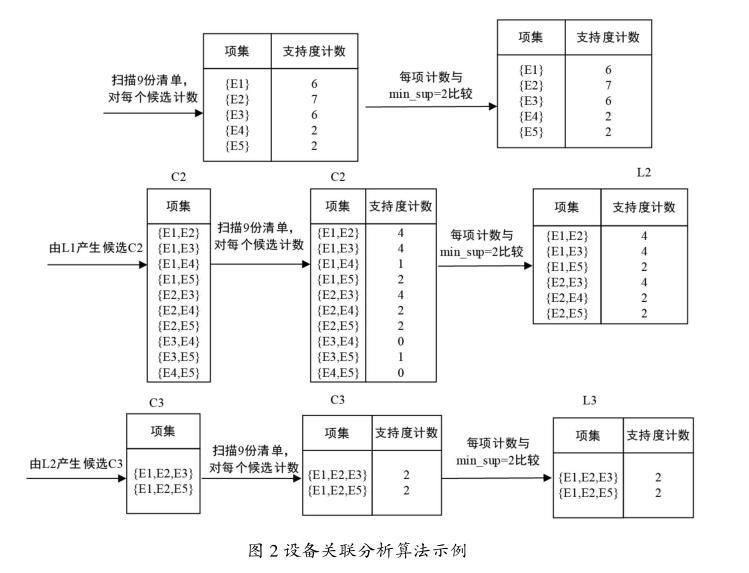
2.2設備關聯分析算法
現在有9份設備借用清單,共涉及5類設備,即:{E1,E2,E5},{E2,E4},{E2,E3},{E1,E2,E4},{E1,E3},{E2,E3},{E1,E3},{E1,E2,E3,E5},{E1,E2,E3},其中,E1代表示波器,E2代表頻譜儀,E3代表信號發生器,E4代表電源,E5代表噪聲發生器,最小支持度閾值min_sup=2。通過L1過程可知5種設備支持度都大于設定閾值,即都屬于頻繁被借用的;通過L2過程可知E1示波器分別與E2頻譜儀、E3信號發生器、E5噪聲發生器相關聯,E2頻譜儀分別與E3信號發生器、E4電源、E5噪聲發生器相關聯;通過L3過程可知,3種設備相互關聯的有E1示波器、E2頻譜儀、E3信號發生器,還有E1示波器、E2頻譜儀、E5噪聲發生器。具體過程如圖2所示。
算法得出互相關聯的若干類設備后,可進一步搜尋這幾種設備的使用關聯關系,具體實施步驟為:在管理平臺上將檢索條件設置為同一部門、同一地理位置,并統計每類設備的使用時間段,兩兩進行比較,如果某2種設備的工作時間段T1,T2的重合度大于50%,則說明這2種設備間具有使用關聯關系,依次類推。例如,在分析出E1示波器和E2頻譜儀具有關聯關系后,根據歷史GPS定位數據,查詢到在某天這2種設備處在同一部門,并根據統計由設備狀態判定算法給出的真實使用時段,得出當天這2種設備有67.3%的時間段在同時使用,則它們具備使用關聯關系。
3結束語
通過介紹數據挖掘方法中的SVM、Apriori兩種經典算法,以及科研設備管理系統的特點和存在問題,提出將SVM、Apriori算法分別應用在設備工作狀態判定以及設備間的關聯關系分析上,發揮2種算法的獨特優勢,可為科研部門在設備管理、租借、購置等方面提供合理的參考依據。
參考文獻
[1]閆偉.以使用單位為主體的資產綜合管理系統的構建[J].實驗室科學,2018,21(6):71-73,77.
[2]王昆.探討實驗室儀器設備的管理[J].中國檢驗檢測,2017, 25(3):59-61.
[3]陸琳睿,李光輝.大數據背景下的儀器設備信息化管理探究[J].實驗技術與管理,2018,35(4):155-158.
[4]張曾蓮.基于非營利性、數據挖掘和科學管理的高校財務分析、評價與管理研究[M].北京:首都經濟貿易大學出版社, 2014.
[5]田文英.機器學習與數據挖掘[J].石家莊職業技術學院學報, 2004(6):30-32.
[6] MITCHELL T M.機器學習[M].曾華軍,張銀奎,等,譯.北京:機械工業出版社,2003.
[7]穆瑞輝,付歡.淺析數據挖掘概念與技術[J].新鄉教育學院學報,2008,21(3):105-106.
[8]羅娜.數據挖掘中的新方法———支持向量機[J].軟件導刊, 2008(10):30-31.
[9]夏火松.數據倉庫與數據挖掘技術[M].北京:科學出版社, 2004.
[10] GRUNWALD P D,RISSANEN J. The Minimum Description Length Principle[M].Cambridge,Ma:MIT Press,2007.
[11]胡可云,田鳳占,黃厚寬.數據挖掘理論與應用[M].北京:清華大學出版社,2008.
[12]吳昱.大數據精準挖掘[M].北京:化學工業出版社,2014.
猜你喜歡
艦船科學技術(2022年14期)2022-09-22 03:10:36
大眾投資指南(2021年35期)2021-02-16 01:06:26
中國交通信息化(2020年1期)2020-07-27 02:50:04
電力與能源(2017年6期)2017-05-14 06:19:37
中國中醫藥信息雜志(2016年7期)2016-12-01 06:07:55
信息通信技術(2015年6期)2015-12-26 01:16:46
西安工程大學學報(2014年2期)2014-02-28 18:03:05
河南科技(2014年23期)2014-02-27 14:18:43
電子設計工程(2014年18期)2014-02-27 12:00:13
電子設計工程(2014年18期)2014-02-27 12:00:12
