基于R軟件和數據庫的生物信息學分析設計
2020-07-31 09:31:55張婕李夢婷
現代信息科技 2020年4期
張婕 李夢婷

摘 ?要:選取NCBI基因表達譜數據庫中訪問號為GSE41439的基因芯片數據集為分析對象,首先利用R軟件篩選差異表達基因并繪制成聚類熱圖,然后將差異基因上傳至DAVID數據庫進行GO功能與KEGG通路富集分析,接著利用STRING數據庫構建蛋白質互作網絡,并利用Cytoscape軟件進行可視化,以直觀地觀察蛋白與蛋白之間的相互關系。由蛋白互作網絡篩選出4個關鍵基因:PIK3R1、GNAS、GNAL、GNG4,可對其進行更深入的討論。此方法適用于多種基因芯片的研究,具有很好的可推廣性,將其運用于疾病相關的基因芯片,可為醫學診斷與精準治療提供一定的幫助。
關鍵詞:生物信息學;R軟件;DAVID數據庫;STRING數據庫;Cytoscape
中圖分類號:R319 ? ? ?文獻標識碼:A 文章編號:2096-4706(2020)04-0076-04
Abstract:The gene chip data set with access number GSE41439 in NCBI gene expression profile database is selected as the analysis object. Firstly,the differential expression genes are screened by R-studio and the clustering heat map is drawn,then the differential genes are uploaded to DAVID database for GO function and KEGG pathway enrichment analysis,and then the protein interaction network is constructed by using STRING database,and can be seen by using Cytoscape software to observe the relationship between protein and protein directly. Four key genes,PIK3R1,GNAS,GNAL and GNG4,were screened out by protein interaction network,which can be further discussed. This method is suitable for the research of many kinds of gene chips,and has good generalization. It can be applied to the disease-related gene chips,which can provide some help for medical diagnosis and precise treatment.
Keywords:bioinformatics;R-studio;DAVID data base;STRING data base;Cytoscape
0 ?引 ?言
隨著精準醫療與計算機技術的迅速發展,計算機技術在數據挖掘方面的優勢逐漸顯現,同時基因組學和蛋白質組學的快速發展積累了大量的生物數據,生物與計算機的結合讓生命科學領域進入大數據時代[1]。生物信息數據庫具有種類多、規模大、覆蓋面廣以及更新速度快等特點,充分利用這一特點,可以識別疾病的潛在治療靶基因,挖掘基因的功能以及基因之間的關聯性,為疾病的預防和治療提供新的途徑[2]。本文以NCBI高通量基因表達譜數據庫(GEO)中訪問號為GSE41439的基因芯片數據集為例,介紹基于R軟件和數據庫的生物信息分析方法,挖掘芯片所包含的潛在信息。該芯片基于GPL570平臺,含有8個樣本信息,比較了正常人胚胎干細胞系VUB01、VUB02、VUB03和VUB07及其含有20q11.21重復序列的亞系的基因表達差異。20q11.21的增加是染色體異常的一種,分析具有正常核型的人胚胎干細胞與獲得20q11.21重復后的細胞內差異表達基因,可以為識別導致染色體異常的關鍵基因及其所參與的功能提供幫助。
1 ?基于R軟件的基因芯片數據處理與初步分析
1.1 ?安裝程序包
R軟件是專業的統計軟件,是統計計算、數據可視化的優秀工具,同時R也是免費開源的軟件,在其官網和鏡像網站中可以下載安裝程序、源代碼和程序包等[3]。R軟件為用戶提供了大量的程序包,使得用戶能夠靈活地運用這些程序包進行數據的分析及可視化,運用R軟件處理基因芯片的第一步即是安裝自己所需的程序包。
1.2 ?數據過濾及標準化
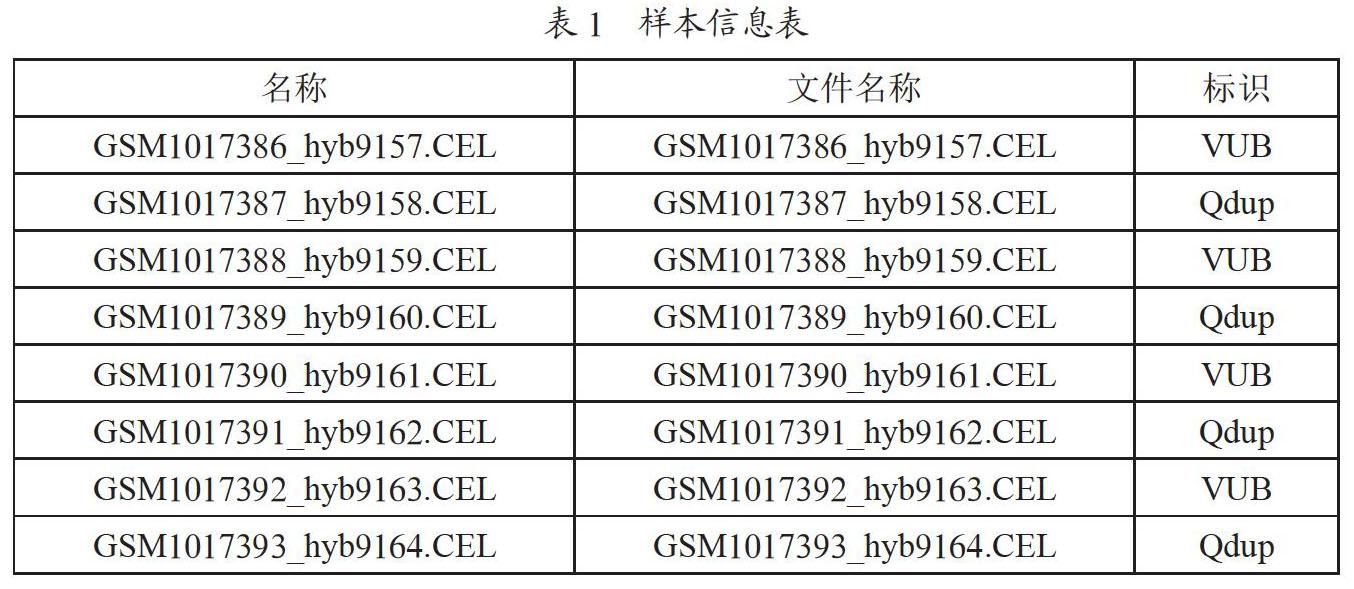
GEO數據庫提供了大量開放共享的基因芯片數據集,分析芯片所包含的信息使得我們能夠從分子層面認識樣本,從而獲取其中的關鍵基因,甚至可以作為疾病分子診斷與治療的依據。從GEO數據庫中下載訪問號為GSE41439的基因芯片原始數據,并將其解壓為CEL文件,整理其所包含的樣本信息為如表1所示。
其中,名稱為樣本的名字,文件名稱為樣本文件的名字,標識為樣本的標簽與類型,各列之間以Tab鍵進行分隔,將整理好的樣本信息文件,與解壓好的CEL文件共同存于同一文件夾下,即可運用R軟件的GC-RMA算法對其進行數據過濾及標準化。
1.3 ?篩選差異表達基因
差異表達基因是分析樣本之間差異信息并進一步尋找核心基因的關鍵,R軟件的limma包提供了相對完善的差異分析工具,本文即運用R軟件的limma包進行差異表達基因的篩選,選定篩選條件為|logFC|>1.00且P.Value<0.05,進一步分析基因芯片蘊含的豐富信息,最終獲得3個有意義的文件,分別為差異表達基因的分析結果、上調基因的具體結果以及下調基因的具體結果,文件自動存入默認工作路徑下。
1.4 ?層次聚類熱圖繪制
層次聚類熱圖可以用于判斷不同條件下的差異基因表達模式,直觀地展示基因芯片的分析結果即某一個位置基因表達水平的高低,從而看出各差異基因在各樣本中的表達情況。首先從GEO數據庫下載GSE41439芯片的基因表達矩陣,并與通過R軟件篩選到的差異表達基因進行整合,得到各差異基因在各個樣本之間的表達矩陣。然后利用R軟件對差異基因表達矩陣進行可視化,采用雙向聚類的方法,根據某一樣本中不同基因的表達水平將基因進行聚類,同時根據某一基因在不同樣本中的表達水平將樣本進行聚類,對基因在行方向進行標準化,設置行列方向的樹高分別為100和20,同時選用由深到淺的顏色進行標記,繪制成層次聚類熱圖,如圖1所示。
2 ?基于數據庫的基因芯片數據挖掘
2.1 ?DAVID數據庫進行富集分析
DAVID[4]是一個為大量基因列表提供一整套功能性注釋的數據庫,其從上傳的基因列表中系統地提取具有生物意義的基因或蛋白,列出涉及到的疾病、蛋白功能域、GO功能、KEGG通路等。GO功能富集分析以及KEGG代謝通路富集分析可以幫助我們從分子層面更深入的了解差異表達基因以及它們之間的富集關系,從而找到富集差異基因的GO分類條目和KEGG通路,得出差異基因可能參與的基因功能以及代謝通路。
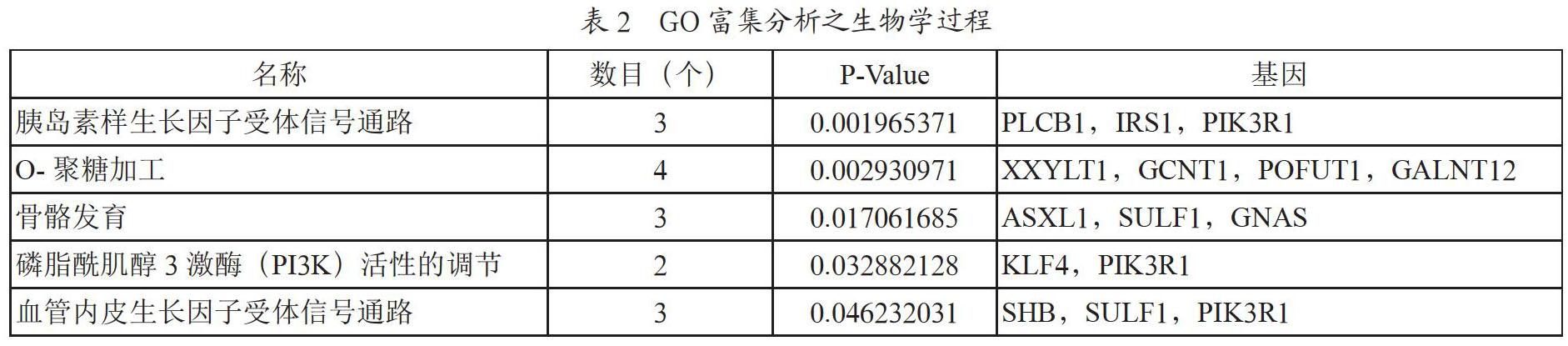
將差異表達基因名上傳至DAVID在線數據庫,并選擇物種背景為homo sapiens,進行富集分析。設定p<0.05,將所得的差異基因歸類到生物學過程(如表2所示)、分子功能、細胞組分以及KEGG通路三種生物學關系中,并將富集分析結果下載以便后續的可視化分析。
2.2 ?STRING數據庫進行互作分析
STRING 11.0[5]數據庫能夠提供對蛋白質相互作用網絡分析和預測的全局視圖。為了得到差異表達基因之間的相互作用,我們將顯著差異基因上傳至STRING 11.0版在線數據庫,并選擇綜合得分≥0.4的基因進行蛋白交互網絡(PPI)構建。將沒有相互作用的節點隱藏,最終得到共有48個節點和55條邊的PPI網絡,如圖2所示,并導出其相互作用表格、蛋白序列以及注釋等信息,以便后續的可視化分析。
3 ?數據庫結果可視化
3.1 ?富集結果可視化之氣泡圖
氣泡圖可以直觀的表征功能富集分析的結果,其中橫軸代表基因比例,即條目所包含基因占所有基因的百分比,單位為%,縱軸代表GO富集分析的具體條目,點的大小反映基因的個數,而顏色的深淺反映P值的高低。本文將DAVID數據庫分析所得的生物學過程富集結果導入R軟件繪制成氣泡圖,如圖3所示。
3.2 ?互作網絡可視化之Cytoscape
Cytoscape是一個基于Java技術的開放源代碼的網絡可視化軟件平臺,主要用于復雜生物網絡的分析研究設計,可以用其繪制基因表達調控網絡、蛋白互作網絡等任何與網絡結構、層級有關系的內容[6]。Cytoscape軟件可構建可視化的分子交互作用網絡圖,節點與節點的連線則表示彼此之間有相互作用,并可將已有的基因表達信息整合到網絡圖中,從而較為容易地觀察蛋白與蛋白之間的關聯性[7]。
本文將所得的相互作用表格、蛋白序列及注釋信息等導入Cytoscape軟件3.7.1版,構建可視化的交互網絡。首先選擇Cytoscape軟件菜單“File-Import-Network from File”輸入網絡表格數據,并設置Source列和Target列及相關屬性列,生成初步的調控網絡。接著我們將其表達信息整合到網絡的節點(Node)與邊(Edge)中,通過選擇Cytoscape軟件控制面板“Control Panel”中的“Style”選項卡對節點、邊和網絡進行樣式設置,其中每一個節點代表一個蛋白(基因),節點大小隨度漸變,深色代表上調,淺色代表下調,每一條邊代表一個交互關系,邊的粗細隨相互作用的強度漸變,最終獲得可視化蛋白交互網絡,如圖4所示。
從圖4中可以初步看出,整個交互網絡以PIK3R1、GNAS、GNAL、GNG4為中心節點,與其他蛋白相互作用,其中PIK3R1、GNAS、GNAL顯著上調,GNG4顯著下調,這4個基因可能是導致20q11.21增加染色體異常的關鍵基因。GO功能富集分析結果表明這些關鍵基因與胰島素樣生長因子受體信號通路、骨骼發育、PI3K活性的調節、血管內皮生長因子受體信號通路等生物過程密切相關,且主要發揮胰島素樣生長因子受體結合、調節PI3K活性、信號傳感器活動、調節跨膜受體蛋白酪氨酸激酶銜接活性等分子功能;KEGG通路富集分析結果表明差異基因顯著富集到血清素能性突觸傳遞通路、多巴胺能突觸傳遞通路以及鈣信號途徑等,與染色體異常密切相關。我們可以初步猜測,20q11.21增加導致的染色體異常可能對這些富集到的生物過程、分子功能以及信號通路產生影響,有了初步的分析結果,則可以應用其他分析方法進一步探索并證明其中的分子機制,研究基因之間的關聯性。
4 ?結 ?論
GEO數據庫提供了大量與疾病相關的基因芯片信息,此研究方法能夠使識別疾病潛在的治療靶基因成為可能。在實際分析中,選取自己感興趣的基因芯片數據集,運用R軟件和生物信息相關的數據庫對基因芯片的信息進行數據挖掘,并利用Cytoscape將其整合到網絡圖中,從而找出關鍵基因,分析其所參與的GO功能以及代謝通路。此外,也可將此數據存入數據庫,以便在后續研究中調用和參考,為臨床分子診斷和精準治療提供一定的幫助。
參考文獻:
[1] 褚皓.數據挖掘在生物信息學中的應用 [J].數字技術與應用,2018,36(10):123-124.
[2] LUSCOMBE NM,GREENBAUM D,GERSTEIN M. What is bioinformatics? A proposed definition and overview of the field [J]. Methods of Information in Medicine,2001,40(4):346-58.
[3] 吳劍,錢進.R軟件在工科概率論與數理統計教學中的應用 [J].考試周刊,2019(29):29.
[4] HUANG D W,SHERMAN B T,QINA T,et al. DAVID Bioinformatics Resources:expanded annotation database and novel algorithms to better extract biology from large gene lists [J].Nucleic Acids Research,2007,35(Web Server issue):169-175.
[5] FRANCESCHINI A,SZKLARCZYK D,FRANKILD S,et al. STRING v9.1:protein-protein interaction networks,with increased coverage and integration [J].Nucleic Acids Research,2013,41(D1):808-815.
[6] 楊淼,杜菁,李冬果,等.基于Cytoscape的miRNA調控網絡的構建與研究 [J].中國醫學裝備,2018,15(10):95-97.
[7] HAMMOND D E,HYDE R,KRATCHMAROVA I,et al. Quantitative Analysis of HGF and EGF-Dependent Phosphotyrosine Signaling Networks [J].Journal of Proteome Research,2010,9(5):2734-2742.
作者簡介:張婕(1998.10-),女,漢族,江蘇淮安人,本科在讀,研究方向:生物信息學。
