基于屬性相關分析與聚類的鐵路列車時刻表非均衡數據集預處理方法
2021-11-05 13:28:50孔德越周姍琪朱建生閆力斌
鐵路計算機應用 2021年10期
孔德越,周姍琪,朱建生,閆力斌,吳 穎
(1. 中國鐵道科學研究院集團有限公司 電子計算技術研究所,北京 100081;2. 中國國家鐵路集團有限公司,北京 100844)
隨著鐵路客運市場化改革的 不斷深化,高速鐵路動態(tài)列車開行方案、“一日一圖”等鐵路客運精細化管理策略正在逐步實施[1],列車運行圖調整(簡稱:調圖)日趨頻繁。調圖時,不同車次時刻表的變動頻率和屬性調整范圍不盡相同,部分車次時刻表調整頻率極低,但調整幅度大,甚至會改變開行區(qū)間;部分車次時刻表逐周、逐月調整,但每次僅對某一屬性進行小幅微調[2]。對列車時刻表數據進行挖掘分析時,會面臨非均衡數據集問題,即數據集中不同車次的時刻表數據樣本量差別較大,不同時期運行圖中同一車次的時刻表數據樣本的屬性差異不大。通常,非均衡數據集會對數據分析模型的適用性和準確度產生不利影響,在選擇數據分析模型時存在較大局限。因此,解決數據集不均衡問題是高效、準確地提取列車時刻表數據所蘊含信息的關鍵[3]。
在實際數據分析工作中,為解決非均衡數據集問題,通常需要進行數據預處理。常用的數據預處理方法有重采樣算法和懲罰模型算法,這2類算法各有利弊。重采樣算法是解決非均衡數據集最通用的一類方法,近年來學術界提出合成數據采樣、聚類采樣以及集成采樣等多種具體算法,其中最常用的是SMOTE算法[4-5]。重采樣算法根據需要從原數據集中隨機選擇數據樣本,生成新的均勻數據集,常用于音頻、圖像數據處理,其缺點是:新數據集與原數據集存在一定差異,且隨機性較大,采樣結果不可重現,影響后續(xù)數據分析中模型的應用效果[6-7]。懲罰模型算法是在分類模型的損失函數中引入懲罰項,通過合理分配錯誤分類樣本的懲罰系數,對樣本中數量多、屬性值差異小的類別分配更低的誤分類懲罰系數,以降低其影響[8];這類方法多應用于樣本中分類不均衡的場合[9-10],但對于類別較多的數據集,采用懲罰模型算法會出現數據集權重分配規(guī)則計算量大、算法復雜、且懲罰權重選擇較為困難等問題。因此,這2類算法無法有效處理列車時刻表非均衡數據集問題。
本文研究提出一種基于屬性相關分析與聚類的非均衡列車時刻表數據集預處理方法,可有效合并相似數據,降低數據集中此類相似數據的占比,削弱非均衡數據集對后續(xù)數據分析的不利影響,并能保留數據所蘊含的主要信息,是一種行之有效的數據預處理方法。
1 列車時刻表屬性相關分析
1.1 列車時刻表數據集特征
目前,在我國鐵路運輸生產中,調圖是一項經常性工作。每次調圖時,會對列車時刻表的始發(fā)時間、停站方案、運行編組等屬性進行調整[11-12]。由于不同車次的時刻表調整頻率不同,一段時期內不同車次的時刻表數據記錄的數量存在較大差異,形成不均衡的列車時刻表數據集;不同車次時刻表調整幅度不盡相同,調整較大的會對列車運營造成較大影響,而有的車次僅只微調時刻表的某個特定屬性,調圖前后的列車運營情況基本一致,可將這些車次調圖前后的時刻表數據記錄視作重復數據樣本。
為此,在對列車時刻表數據進行預處理時,判斷是否合并樣本數據,主要考察屬性值變化是否對列車運營產生顯著影響:對于不顯著影響列車運營的時刻表調整,視為列車時刻表記錄的屬性值無顯著變化,故將調圖前后的數據記錄合并后生成一條新的記錄,原記錄中相同的屬性值保留在合并后的新記錄中,而不同的屬性值則經同化處理得到新記錄對應的屬性值;對于調圖后列車運營情況發(fā)生顯著變化的車次,該車次調圖前后的時刻表記錄全部保留,視為不同的數據。
1.2 列車時刻表屬性與列車運營指標的相關分析
列車時刻表調整涉及的主要屬性包括:列車始發(fā)/終到時間、停站個數、開行區(qū)間等。列車運營通常采用旅客發(fā)送量、旅客周轉量、列車客票收入及客座率等指標進行評價,本文選用客座率作為被解釋變量[13-14]。
鑒于普速列車與高速鐵路動車組列車是不同性質的客運產品,需分別分析兩類列車時刻表屬性調整對列車運營的影響。使用歷史上幾次大規(guī)模調圖前后的列車運營數據,對調圖前后兩類列車的客座率變化與列車時刻表屬性變化進行相關分析。
1.2.1 未調整時刻表的列車
未調整時刻表的列車總樣本數共計4 031條,采用單因素方差分析法(one-way ANOVA),分析調圖日前后這些列車的客座率是否發(fā)生顯著變化,檢驗結果如表1所示。表中:SS表示離均差平方和,df表示組間自由度,MS表示均方差,F表示F檢驗的檢驗值,P- value表示F檢驗的結果值,即出現F值的概率,其小于0.05時可以認為兩組數據相同的可能性較小,存在顯著差異,F crit表示結果顯著時F值的臨界值。故結果顯示,調圖后未調整開行計劃的列車客座率降低0.2%,方差分析P=0.986>0.05,由此表明:在觀察期內,未調整時刻表的列車客座率沒有顯著變化。
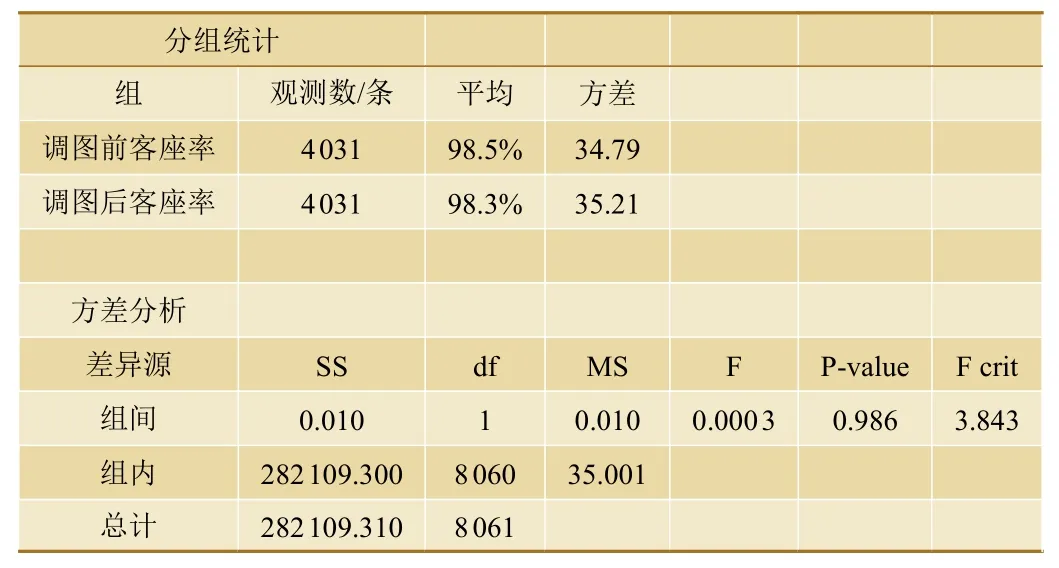
表1 調圖前后單因素方差分析結果
1.2.2 僅調整始發(fā)時間的列車
對于列車時刻表數據集中僅調整始發(fā)時間的列車,按始發(fā)時間調整幅度劃分為7組,分別對列車始發(fā)時間調整時長與列車客座率變化進行相關性分析,如圖1所示。

圖1 調圖前后列車始發(fā)時間調整與列車客座率變化的相關分析結果
由圖1可知:(1)動車組列車始發(fā)時間調整在30 min以內,對列車客座率變化無顯著影響;列車始發(fā)時間調整在30 min以上,對列車客座率變化有顯著影響;(2)普速列車始發(fā)時間調整在60 min以內,對列車客座率變化無顯著影響;列車始發(fā)時間調整在60 min以上,對列車客座率變化有顯著影響。
1.2.3 調整停站個數的列車
對于列車時刻表數據集中開行區(qū)間(即列車始發(fā)站與終到站)不變、始發(fā)時間不變、僅調整停站個數列車,分別對動車組列車與普速列車調圖前后列車客座率進行單因素方差分析,其結果如表2和表3所示。

表2 動車組列車停站個數調整后客座率變化單因素方差分析結果
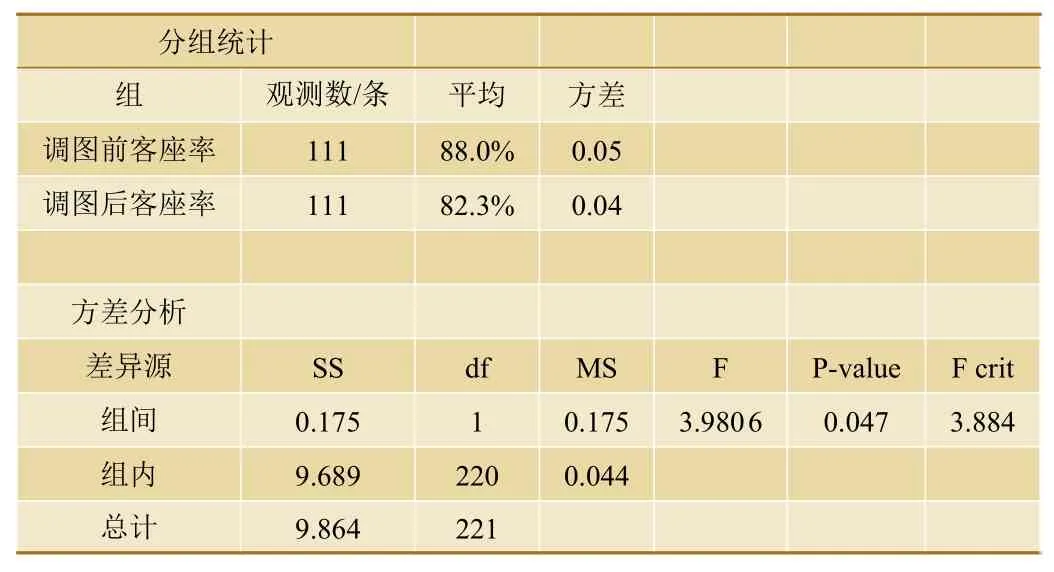
表3 普速列車停站個數增加1站客座率變化單因素方差分析結果
(1)對于動車組列車,當開行區(qū)間不變時,不論停站個數如何調整,其客座率均不會發(fā)生顯著變化(P=0.559>0.05,不顯著),即停站個數調整對客座率無顯著影響;
(2)對于普速列車,當開行區(qū)間不變時,即使僅增加1個停站,其客座率也會發(fā)生顯著變化(P=0.047<0.05,顯著),即停站個數調整對客座率變化有顯著影響。
2 列車時刻表數據聚類(合并處理)
由1.2小節(jié)的列車時刻表屬性相關分析可知:
(1)對于動車組列車,其它屬性不變時,如果始發(fā)時間調整在30 min以內的列車時刻表樣本數據可以進行合并處理;僅停站個數調整的,也可以進行合并處理;
(2)對于普速列車,其它屬性不變時,始發(fā)時間調整在90 min以內的時刻表樣本數據可以進行合并處理;停站個數有調整的,不能進行合并處理;
(3)當動車組列車或普速列車的開行區(qū)間發(fā)生變化時,客運產品的實質已發(fā)生變化,不能進行合并處理。
以某普速列車Z(X)為例,假設某一年度內Z(X)次列車共有4條時刻表數據記錄,編號分別為A、B、C、D,如表4所示。其中,記錄A與記錄B的基礎屬性相同,記錄C與記錄D的基礎屬性中僅始發(fā)時間相距1 min,其它屬性值相同,記錄A、B與記錄C、D的始發(fā)時間及停站個數不同。

表4 普速列車Z(X) 某一年度時刻表原始數據
因此,可將記錄A和B進行合并,以記錄A和B的相同基礎屬性值作為合并后的新記錄A'的基礎屬性值,以記錄A和B的運營結果之和作為新記錄A'的運營結果。同理,對記錄C和D也進行合并,以開行天數更多的記錄D的基礎屬性值作為合并后的新記錄B'的基礎屬性值,以記錄C和D運營結果之和作為記錄B'的運營結果,如表5所示。

表5 普速列車Z(X) 列車時刻表數據的預處理結果
由表4和表5可知:對普速列車Z(X)時刻表數據進行聚類處理后,普速列車Z(X) 原先的4條數據記錄可合并為2條運營結果不同的數據記錄,既消除了屬性值相似數據記錄造成的數據集重復問題,又能夠保留屬性值差異對運營結果的影響特征,可有效提升列車時刻表數據質量。
3 一般數據集的屬性相關分析與聚類算法
對于具有與列車時刻表相同特征的非均衡數據集,即不同類別的數據記錄數量差異較大、相同類別的數據記錄屬性值相似,可使用基于屬性相關分析與聚類算法進行預處理,具體處理流程如下。
(1)初步清洗數據集:糾正明顯的錯誤數據,如檢查出有異常值或缺失值的數據記錄,對其進行修正、填充或將錯誤記錄刪除,統一屬性值格式。
(2)連續(xù)屬性離散化:對數據集中所有連續(xù)屬性進行離散化劃分,通過分組分析找出某一屬性引起被解釋變量顯著變化的屬性值差異的最小值;進行屬性離散化劃分時需要根據數據集特征慎重權衡劃分粒度,如果劃分粒度過大,會導致找出的最小屬性值精度不足,而劃分粒度過小則會導致計算量增大,影響效率。
(3)確定對被解釋變量產生顯著影響的屬性值差異閾值:采取控制變量法,選取待分析屬性值不同、其它屬性值相似的數據記錄,將待分析屬性值離散化分組后,根據屬性值大小對各組數據進行升序排列;對首組數據的屬性值與被解釋變量進行相關性分析,當皮爾森相關性系數達到0.3時,首組數據的屬性值變化對被解釋變量產生顯著影響,此時設定閾值為0,即該屬性值的任意變化均對被解釋變量有顯著影響;若相關性系數小于0.3,則按順序依次選擇首組數據與后續(xù)組別數據,分別進行單因素方差分析;當單因素方差分析結果值P<0.05時,兩組數據間的屬性值差異對被解釋變量產生顯著影響,此時設定閾值為兩組數據屬性值下限的差值。
(4)數據集聚類:將其它屬性值相同、單屬性值差異小于(3)中所確定的閾值的數據記錄聚類后進行合并,保留共有屬性值,以各記錄非共有屬性值的均值,或選擇其中最重要記錄的屬性值作為該屬性的新屬性值,并將各記錄的被解釋變量按業(yè)務規(guī)則進行匯總得到新的樣本數據,新的數據樣本包含合并前各樣本數據的主要信息。
4 結果檢驗與分析
為驗證基于屬性相關分析與聚類的數據預處理算法的有效性,采用不同的數據預處理方式生成訓練集,再利用相同的分析模型對列車客座率進行預測,以檢驗不同的數據預處理方式對預測結果的影響。
使用某年度歷次調圖前后的全部列車時刻表數據和列車運營統計數據(即客座率)作為訓練集,數據記錄屬性包括開行區(qū)間、始發(fā)時間、停站個數、客座率,以次年的數據作為測試集。針對訓練集的數據樣本非均衡性問題,分別采取不處理、重采樣、屬性相關分析與聚類3種數據預處理方式,生成3組樣本數據;使用R語言,分別利用這3組樣本數據訓練K近鄰算法模型(KNN),再用相同的測試集對列車客座率進行預測,以檢驗該模型的預測準確度,對應的預測效果對比如表6所示。

表6 3種數據預處理方式對應的KNN算法模型的預測效果對比
由表6可知:未經預處理的原始樣本預測準確率最低,為77.9%;重采樣處理后的訓練集樣本數量為2 303條,預測準確率為79.3%,能夠有效降低模型計算量,但由于重采樣導致未被采樣記錄所蘊含信息的丟失,限制了預測準確度的提升;經屬性相關與聚類算法處理后的訓練集樣本數量為2 511條,預測準確率達到81.4%,表明該算法對減輕預測模型計算量和提升模型準確度均有良好效果。
5 結束語
針對列車時刻表非均衡數據集的特征,研究提出基于屬性相分析與聚類的數據預處理方法,以客座率為被解釋變量,分別對動車組列車和普速列車在調圖前后的客座率變化與列車時刻表屬性變化進行相關分析,依據分析結果完成列車時刻表數據聚類處理;歸納提出一般數據集的屬性相關分析與聚類算法流程,適用于具有相似特征的非均衡數據集的數據預處理。經分析驗證,此方法可在有效保留原始數據集主要信息的前提下,將屬性值相似的數據進行合并,提高數據集質量,有助于減少數據分析計算量,降低過多相似數據對模型分析效果的影響,為后續(xù)的數據分析和挖掘提供有利條件。
