基于遺傳模擬退火算法的藥品零售大數據關聯規則挖掘
2020-08-11 07:14:40卞顯福
黑龍江工業學院學報(綜合版) 2020年6期
盛 魁,馬 健,曹 巖,卞顯福
(1.亳州職業技術學院 信息工程系,安徽 亳州 236800;2.安徽中醫藥科學院 亳州中醫藥研究所,安徽 亳州 236800;3.中國科學技術大學 軟件學院,安徽 合肥 230051)
隨著大數據、云計算、物聯網、移動互聯網等信息技術爆發式發展,藥品零售企業積累大量的數據。目前,這些數據只用在銷售統計和藥品庫存管理上,對數據相關性分析和預測分析等深層次運用較少,使得這些有價值的資源卻成為企業信息存儲的負擔。如何從這些海量數據中挖掘出有價值的藥品關聯知識,實現藥品的精準銷售和個性推薦成為當前人們研究的熱點。關聯規則挖掘是一種有效的數據挖掘方法,它可以從大量的數據信息中發現隱藏的、有價值的關聯和規律[1]。大數據的關聯規則挖掘流程包括源數據的獲取、頻繁項集提取、強關聯規則提取和有價值關聯規則提取,已應用于電力、金融、交通、醫療、零售等領域[2-3]。
本文從藥品零售大數據本身出發完成知識發現,在遺傳算法選擇操作、交叉運算和變異運算中融入模擬退火算法,提出一種基于遺傳模擬退火算法的關聯規則挖掘改進算法,用以挖掘藥品零售大數據之間關聯和規律,有效地量化了藥品之間的相關程度,為藥品零售企業的經營決策提供支持,能夠為企業帶來更多潛在商業機會。
1 關聯規則技術研究
1.1 關聯規則挖掘
關聯規則挖掘是從海量數據中發現事物之間可能存在的關聯和相互關系,以揭示事物間內在的本質聯系。設I={i1,i2,…,im}是所有數據項的集合,給定一個事務集合D,T={t1,t2,…tm}為D中的一個事務,即T?I。若項集A?I且A?T,則事務T包含項集A,關聯規則是形如A?B的蘊含式,其中A?I,B?I,且A∩B=φ。一般用支持度(support)和置信度(confidence)來衡量一個關聯規則,支持度表示關聯規則出現的頻度,表達式為:support(A?B)=P(A∪B),置信度則表示關聯規則的強度,表達式為:confidence(A?B)=P(A|B)。如果規則不但滿足support(A?B)>supportmin,而且滿足confidence(A?B)>confidencemin,則稱規則A?B為強關聯規則。關聯規則挖掘是要在事務集合中找出全部強規則。
1.2 關聯規則挖掘方法
常用的關聯規則挖掘算法有Apriori算法、FP-growth算法、Eclat算法、神經網絡法、決策樹法、粗糙集和遺傳算法等,但在具體應用時會根據實際問題需求對現有挖掘算法進行融合或改進,有針對性的進行數據分析和挖掘[4]。
(1)Apriori算法
Apriori算法是一種寬度優先算法,算法簡單、易實現,不需要構建新的數據結構。當數據庫中的數據量較大時,需要對數據庫多次掃描數而產生大量頻繁項集,導致算法效率不高[5]。
(2)FP-growth算法
FP-growth算法采用分而治之的策略,算法對數據庫僅需掃描兩次且不需要產生候選集,在效率上優于Apriori算法。但算法構建項頭表、FP-tree和條件FP-tree等數據結構需要消耗大量存儲空間,影響挖掘效率[6]。
(3)Eclat算法
Eclat算法是一種深度優先搜索的算法,算法對數據庫不需要重復多次遍掃描,通過交集操作求頻繁項集。但算法無法對產生的候選集做剪枝操作,生成大量的候選項集,并且算法在運行的過程中,會消耗大量存儲空間[7]。
(4)遺傳算法
遺傳算法(Genetic Algorithm, GA)是基于達爾文進化論的自適應全局優化概率搜索算法,通過選擇、交叉、變異等遺傳運算達到優化的目的。GA算法具有良好的全局搜索特性,但算法在進化過程中容易出現早熟現象。遺傳算法已在機器學習、人工智能、信號處理、組合優化和自適應控制和等領域得到廣泛的應用。
(5)模擬退火算法
模擬退火算法(Simulated Annealing Algorithm, SA)是基于蒙特卡洛思想設計的隨機尋優迭代求解算法,在問題求解中引入熱力學的退火平衡模型,能夠實現搜索全局最優解。SA算法在較小的范圍內具有尋優速度快、收斂精度高等特點,但是尋優的結果受初始值的影響較大。模擬退火算法已在生產調度、機器學習、控制工程、信號處理、神經網絡等領域得到了廣泛應用。
2 基于GA-SA算法的關聯規則挖掘設計
2.1 挖掘算法設計思想
為了克服GA算法局部搜索能力差、早熟收斂,且易陷入局部最優解的缺點,將SA算法融入GA算法中,形成一種高效的GA-SA算法,實現對藥品零售大數據關聯規則挖掘。GA-SA算法以GA算法為主體,SA算法為其輔助,在SA算法選擇操作、交叉運算和變異運算中融入SA算法,從而提高算法的效率。通過GA算法尋找一批優良的群體,利用SA算法抑制群體陷入局部最優,進一步調整優化種群,減少消耗進而篩選得到有用規則。挖掘流程如圖1所示。

圖1 GA-SA算法的關聯規則挖掘流程圖
2.2 GA-SA算法的設計
(1)編碼方法的設計
關聯規則編碼是設計GA-SA算法時的一個關鍵步驟。為了便于交叉、變異和選擇算子的操作,采用實數編碼方法對個體進行編碼。假設個體的長度為N,定義實數數組A[N]與其對應,字段的屬性值與數組A[i](i∈[1,N])的元素值一一對應,如果此屬性與其他的屬性無關聯則A[i]的值為0。
(2)適應度函數設計
適應度函數是GA-SA算法進化過程的驅動力,也是群體進化過程中用到的唯一信息。采用可信度和支持度表示適應度函數,適應度函數表達式為:
(1)
其中,ws+wc=1,ws≥0,wc≥0,supportmin表示支持度的閾值,confidencemin表示可信度的閾值。
(3)選擇操作
選擇操作是為了提高全局收斂性和計算效率,避免基因缺失。采用最佳個體保存法進行選擇操作,保證交叉和變異操作不能破壞進化過程中某一代的最優解。在當前種群P={x1,x2,…,xn}中,個體xi被選中進入下一代的概率為:
(2)
其中,f(xi)是個體xi的適應度函數。Tk為進化到第k代時的退火溫度。
(4)交叉退火和變異退火操作
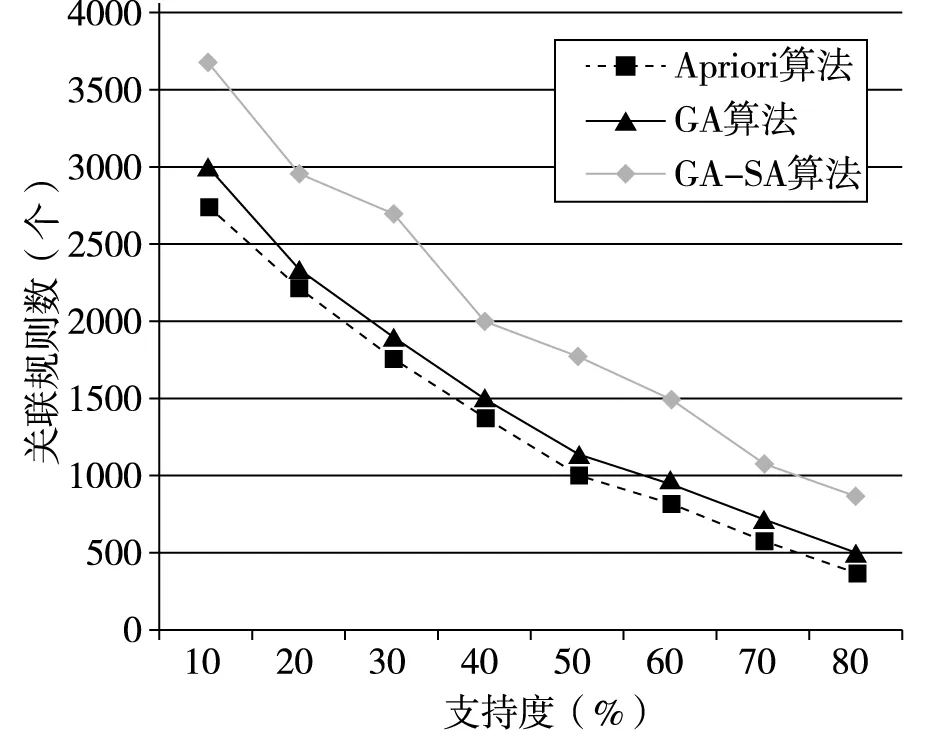
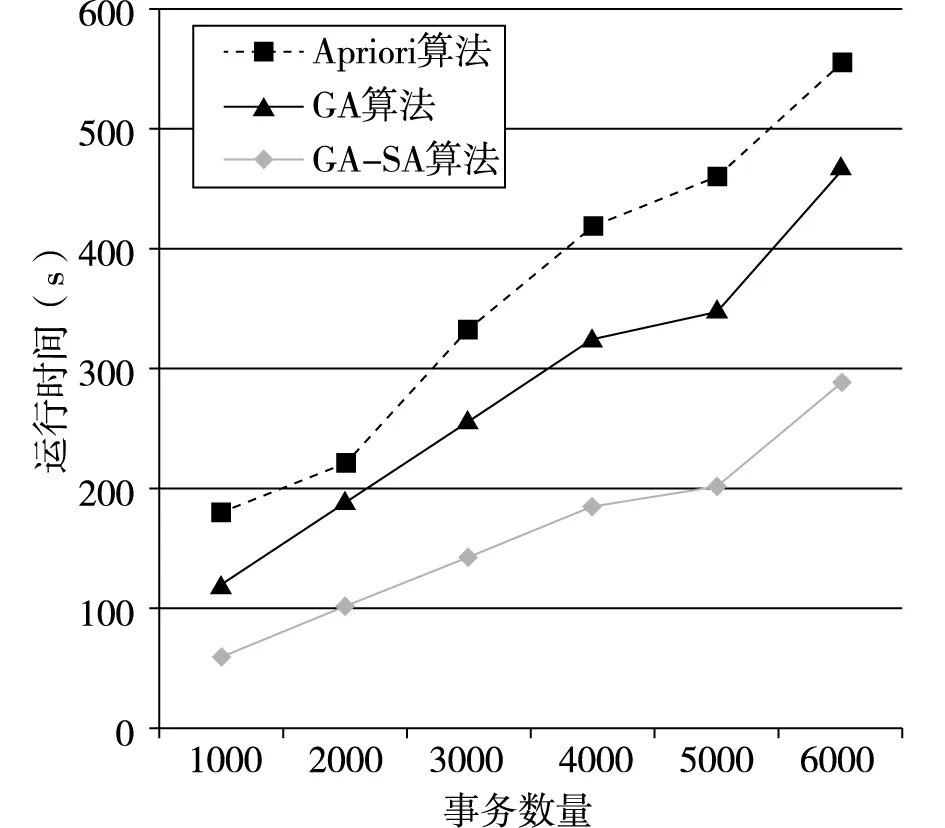
變異退火操作GA-SA算法中生成新個體的主要手段。為了不會影響算法的效率,本文采用單點交的方法。p1、p2按照預定交叉概率,交叉生成新子代c1、c2,計算f(ci)、f(pi)(i=1,2)的值,同時實施模擬退火操作[8],如果f(ci)>f(pi),則用ci代替pi;如果f(ci) (5)降溫操作 采用有限的非齊次馬爾可夫鏈序列[9]實現降溫操作,溫度變化表達: (3) 本文開發環境為Python,版本為Python3.6,IED為Pycharm和Anaconda,運行平臺為windows 10,算法用Python語言實現。 實驗數據來自亳州某連鎖零售藥店21家門店2018年5月1日到2018年10月1日6個月的數據,數據庫包括藥品信息表、藥品類別和門店的銷售表三類原始數據表格682000條記錄。 (1)藥品信息表。包括藥品編碼、藥品名稱、規格、類別、藥品屬性、產地、原價、單價、條形碼等。 (2)藥品類別表。包括商品的藥品編號、藥品名稱、類別碼和類別名稱(如心腦血管類,胃腸類等)、藥品屬性(中成藥、西藥、中藥飲片)等。 (3)門店的銷售表,包括流水號、門店號、購買藥品序號、日期、藥品編碼、購買數量、銷售價格等。 獲取的原始數據含有一些“臟數據”,低質量的“臟數據”將會導致低質量的挖掘結果。數據處理主要包括“臟數據”(不完整的數據、有明顯錯誤的數據以及重復數據)的剔除和處理。數據預處理的過程主要有: (1)數據清洗 根據數據分析的任務選擇任務所需的數據對象和屬性,對缺失數據、重復數據和異常數據等不規整的數據進行清洗。針對臟數據,應用Python編寫程序對原始數據進行處理,清除挖掘中不需要的數據信息,保存藥品數據的原始特征。 (2)數據集成 數據挖掘只需要導入需要的數據,這就需要針對終端零售數據存儲在關系數據庫中的不同表結構中,提取藥品信息表、藥品類別和門店的銷售表所需的數據列數據,如藥品名稱、類別名稱、銷售時間、銷售數量等數據進行處理,提取所需的數據列數據。對原始數據682000條記錄,經過數據清洗和去重等處理后有561357條記錄為有效記錄。 Step1.初始化控制參數。群體規模M,最大遺傳代數MAX,初始種群P,交叉概率Pc,變異概率Pm,初始退火溫度T0,終止溫度Tend,最小支持度supportmin和最小置信度confidencemin。 Step2.適應度函數計算。根據公式(1)計算當前種群P中的每個體適應度值。 Step3.選擇操作。根據公式(2)對全部個體都進行了選擇操作。 Step4.交叉退火操作。按照本文GA-SA算法設計進行交叉退火操作。 Step5.變異退火操作。方法同Step4。 Step6.降溫操作。根據公式(3)進行降溫操作。 Step7.算法終止。判斷遺傳代數是否達到給定到最大遺傳代數或降溫溫度是否達到終止溫度,如果達不到轉Step2;否則結束算法。 Step8.關聯規則挖掘與提取。 初始種群規模為40,最大的迭代次數MAX=30,交叉概率為0.9,變異概率為0.05;最小置信度為0.6,最小支持度設定為0.01,初始溫度為50000,退火終止溫度為15;溫度可以下降的最大次數M=1000。 采用GA-SA算法的關聯規則挖掘算法對預處理后的數據進行分析,最終得到關聯規則7715條,發現部分關聯規則如圖2所示。 圖2 藥品和藥品關聯規則結果 從圖2中可以看出,以“抗感冒藥?抗病毒藥”規則為例,在購買不同種類的消費者中,購買抗感冒藥類藥品同時購買了抗病毒藥,感冒大部分是由病毒引起的,毒性感染導致的鼻塞、流涕、打噴嚏等癥狀,從醫學角度看,需要理抗病毒藥如雙黃連口服液或者抗病毒片等藥品進行聯合治療,規則與實際用藥情況基本相符。 規則“腸胃疾病類?營養保健類”表明,消費者在購買腸胃疾病類藥品的時候購買營養保健類藥品的機率比較大。在購買奧美拉唑腸溶膠囊、硫糖鋁片、正露丸等腸胃道用藥的同時還會買類似復方阿膠、六味地黃丸、維生素類的藥品。從醫學角度看,由于腸胃消化不好的顧客通常體質比較弱,在治療腸胃需要服用營養保健增加腸胃道消化,符合一定用藥的規律。 規則“高血壓類?心腦血管用藥”表明,購買高血壓類藥品的消費者,同時也可能購買心腦血管用藥的藥品。患者長時間服用硝苯地平緩釋片、卡托普利片和替米沙坦降壓藥會導致擴張血管,配合服用阿司匹林腸溶片、復方丹參片和腦洛通膠囊,增加血管彈性,預防腦溢血,調解血脂,改善血液粘稠度,規則與實際用藥情況基本一致。 為了驗證GA-SA算法的性能,從事務數目和支持度兩方面分別與Apriori算法和GA算法進行比較,算法采用Python實現。不同事務數目下算法性能比較結果如圖3和圖4圖所示;不同支持度下算法性能比較結果如圖5和圖6圖所示。 圖6 不同支持度下算法挖掘規則數目比較 圖5 不同支持度下算法運行時間比較 圖3 不同事務數目下算法運行時間比較 圖4 不同事務數目下算法挖掘規則數目比較 通過圖3和圖4可以看出,在事務數據量不斷增加的情況下,運行時間都在增加,但GA-SA算法相比Apriori算法和GA算法挖掘速率略微快些,說明GA-SA算法在處理大規模數據集時,運行較快,性能較好。相同的事務數據量下,GA-SA算法挖掘出的規則數更多。 通過圖5和圖6可以看出,三種算法的性能都受支持度的影響,同一支持度下GA-SA算法挖掘關聯規則運行時間最短,但挖掘的關聯規則數目最多。 通過上面兩種情況下的比較,證明了GA-SA算法不論在運行時間還是在挖掘規則數目上都要優于Apriori算法和GA算法,說明了GA-SA算法在挖掘關聯規則方面具有較高的運行效率和較全面的關聯規則。 本文以遺傳算法為主導,模擬退火算法作為其輔助,提出了一種新穎的GA-SA算法挖掘關聯規則算法,對藥品零售大數據進行分析,能夠挖掘出隱藏在藥品零售大數據之中有價值的知識與信息,并自動計算出藥品之間的支持度與置信度,有效地度量了藥品之間的影響程度,為藥品零售企業決策提供了參考依據,并通過與Apriori算法和GA算法進行對比,證明了GA-SA算法的有效性。藥品零售大數據的挖掘研究仍具有很大的空間,如何設計更準確的算法實現藥品銷售預測和智能采購,將是我們下一步研究的內容。
3 基于GA-SA算法的關聯規則挖掘
3.1 數據采集
3.2 數據預處理
3.3 算法步驟
4 挖掘結果與算法性能分析
4.1 關聯規則挖掘

4.2 算法性能分析


結語
猜你喜歡
中國合理用藥探索(2022年1期)2022-11-26 00:22:32
小獼猴智力畫刊(2022年3期)2022-03-29 01:09:42
當代陜西(2021年17期)2021-11-06 03:21:36
數學小靈通(1-2年級)(2021年4期)2021-06-09 06:26:14
學苑創造·A版(2018年11期)2018-02-01 06:29:20
Coco薇(2017年11期)2018-01-03 20:59:57
讀者(2017年5期)2017-02-15 18:04:18
暨南學報(哲學社會科學版)(2016年9期)2017-01-15 13:52:02
中國衛生(2016年5期)2016-11-12 13:25:28
中國衛生(2015年5期)2015-11-08 12:09:48
