多種聚類算法性能的比較分析
2020-08-12 02:32:46紀(jì)漢霖李兆信
計(jì)算機(jī)技術(shù)與發(fā)展 2020年8期
關(guān)鍵詞:效果
紀(jì)漢霖,李兆信
(上海理工大學(xué),上海 200093)
0 引 言
聚類是重要而基礎(chǔ)的數(shù)據(jù)分析和挖掘的算法,在金融、教育、醫(yī)療、互聯(lián)網(wǎng)等方面有著廣泛的應(yīng)用。聚類屬于無監(jiān)督學(xué)習(xí)范疇,在沒有數(shù)據(jù)標(biāo)簽的條件下,可以依據(jù)數(shù)據(jù)之間的相似度(如距離)對數(shù)據(jù)進(jìn)行先驗(yàn)的分組,從而使得分組內(nèi)的數(shù)據(jù)相似度盡可能高,分組之間的數(shù)據(jù)差異度盡可能大。
聚類算法在人工智能熱潮的推動下飛速發(fā)展,算法的種類不斷增多。如何為不同類型的數(shù)據(jù)集匹配恰當(dāng)?shù)木垲愃惴ㄟM(jìn)而挖掘出數(shù)據(jù)集中的有效信息,是當(dāng)下研究的熱點(diǎn)與難點(diǎn),因此對聚類算法在不同數(shù)據(jù)類型中的效能和敏感性的對比分析是一個值得研究的課題。
1 聚類算法的分類
自Lawrence Hubert[1]于1972年提出聚類算法至今已經(jīng)將近半個世紀(jì),在這幾十年中學(xué)者們已經(jīng)提出了上千種聚類算法[2]。聚類算法通過結(jié)合各個學(xué)科的技術(shù)和特點(diǎn),融合發(fā)展為一個跨學(xué)科的方法,進(jìn)而可以通過多種視角和方法對聚類算法進(jìn)行歸類。聚類算法可以分為傳統(tǒng)方法和新方法兩大類,傳統(tǒng)的劃分有層次聚類(HC算法和Birch算法)、劃分式聚類(K-means)、基于密度的劃分(DBSCAN)、基于網(wǎng)格的劃分等(以STING和CLIQUE為代表),近年來也有一些新發(fā)展的方法:基于約束的劃分、基于模糊的劃分、基于粒度的劃分、量子聚類、核聚類、譜聚類[3-5],如圖1所示。
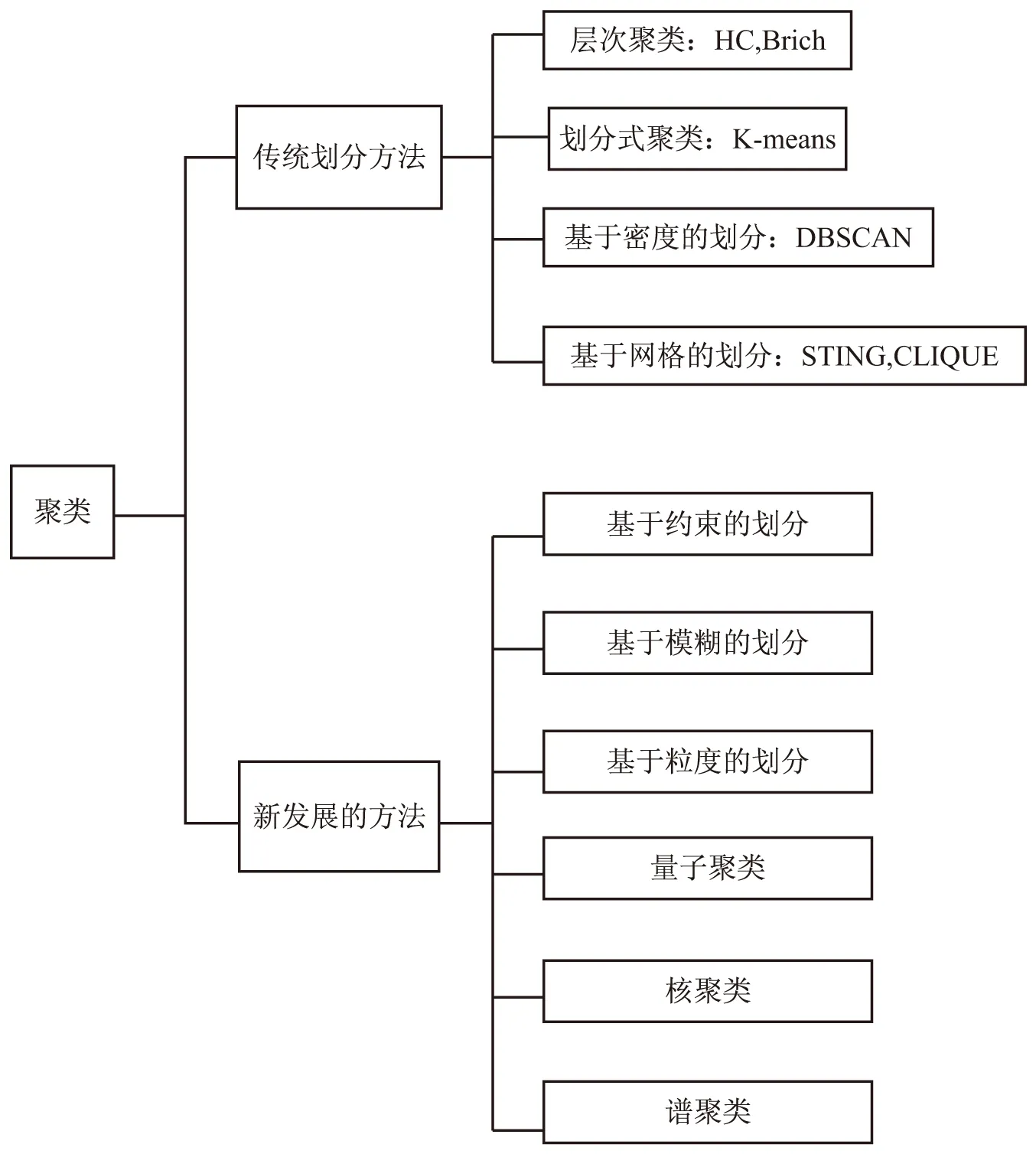
圖1 聚類算法的分類示意圖
以上這些算法大多是基于數(shù)據(jù)的特性而衍生出來的,導(dǎo)致算法對很多數(shù)據(jù)類型的適用效果并不好。因此在聚類研究中,學(xué)者們更側(cè)重于在特定數(shù)據(jù)集的基礎(chǔ)上對算法進(jìn)行研究和改進(jìn)。劉曉勇等(2011)[6]通過在AP算法中加入收縮因子,在服從[0,1]上均勻分布的模擬數(shù)據(jù)點(diǎn)上驗(yàn)證了相關(guān)改進(jìn)能夠加速算法的收斂速度。趙玉艷等(2008)[7]通過在BIRCH算法中加入ID傳播并改進(jìn)近鄰密度的計(jì)算方法,在Manku GS和Motwani R(2002)[8]的DSI數(shù)據(jù)集上驗(yàn)證了相關(guān)改進(jìn)能夠加強(qiáng)算法的伸縮性并提高算法準(zhǔn)確度。胡慶輝等(2013)[9]通過對GMM算法的系數(shù)中加入熵懲罰因子,在基于高斯分布而生成的人工數(shù)據(jù)集上驗(yàn)證了相關(guān)改進(jìn)能夠加快迭代速度并且可以提高魯棒性。陳黎飛等(2008)[10]通過構(gòu)建聚類質(zhì)量曲線確定層次聚類的聚類數(shù)目,在真實(shí)數(shù)據(jù)和人工合成數(shù)據(jù)集的基礎(chǔ)上驗(yàn)證了相關(guān)改進(jìn)能夠?qū)?shù)據(jù)進(jìn)行更好的劃分。周林等(2012)[11]通過在譜聚類算法中使用連接三元組算法,在由加州大學(xué)UCI(University of California Irvine)數(shù)據(jù)庫中選取的數(shù)據(jù)集上驗(yàn)證了相關(guān)改進(jìn)能夠提高簇內(nèi)數(shù)據(jù)相似度和計(jì)算效率。周愛武等(2011)[12]通過提出一種新的方法來確定K-means的聚類中心,在由UCI數(shù)據(jù)庫中提供的數(shù)據(jù)集上驗(yàn)證了相關(guān)改進(jìn)能夠降低孤立點(diǎn)對算法的影響。
在算法性能方面,之前的學(xué)者主要是對AP、Birch、GMM、HC、K-means等主流聚類算法在特定數(shù)據(jù)集上進(jìn)行相關(guān)改進(jìn)和研究,然而卻很少對算法在不同數(shù)據(jù)集上的表現(xiàn)進(jìn)行相應(yīng)的研究。即使在對算法進(jìn)行橫向研究比較時,選用的數(shù)據(jù)測試集也多是來自加州大學(xué)UCI數(shù)據(jù)庫(UCI數(shù)據(jù)庫由真實(shí)數(shù)據(jù)生成的標(biāo)準(zhǔn)測試集組成)。馮曉蒲等(2010)[13]使用UCI數(shù)據(jù)庫中的IRIS對K-means、層次聚類、SOM和FCM四種算法做了對比研究,結(jié)果顯示FCM和K-means的聚類效果比較好,層次聚類算法的聚類效果最差,SOM的效率最低。與之前學(xué)者研究不同的是:文中利用由機(jī)器生成的數(shù)據(jù)集對算法進(jìn)行橫向的研究,數(shù)據(jù)類型分為三類:離散型小數(shù)、離散型整數(shù)和連續(xù)型正數(shù)。
對比分析了Affinity Propagation、Birch、Gaussian Mixture Model、Hierarchical clustering、K-means和Spectral六種聚類算法,采用Silhouette Coefficient和Calinski-Harabaz Index為聚類評價指標(biāo)對算法做了性能測試,采用算法在數(shù)據(jù)集上CPU消耗的時間作為評價指標(biāo)對算法做了效率測試,以及在由不同數(shù)量級組成的數(shù)據(jù)集上對算法進(jìn)行了敏感性分析。
2 聚類算法概述
(1)Affinity Propagation聚類算法。
AP算法是由Frey B J和Dueck D于2007年在科學(xué)雜志上最先提出來的聚類算法[14],之后一直受到后來學(xué)者的關(guān)注與研究。AP算法對數(shù)據(jù)的特性沒有要求,數(shù)據(jù)集結(jié)構(gòu)可以是對稱的也可以是非對稱的。AP算法不需要提前設(shè)定聚類中心的個數(shù),因?yàn)樵撍惴ò褦?shù)據(jù)集中的數(shù)據(jù)點(diǎn)作為潛在的聚類中心,通過算法的不斷迭代確定出聚類中心的數(shù)據(jù)點(diǎn)。
該算法通過計(jì)算出數(shù)據(jù)點(diǎn)之間的相似度,利用相似度組成方形矩陣,方陣對角線的值稱為參考度,參考度越大表示對應(yīng)的數(shù)據(jù)點(diǎn)成為聚類中心點(diǎn)的概率越大。AP算法通過一種數(shù)據(jù)點(diǎn)和潛在聚類中心點(diǎn)互相選擇的機(jī)制來實(shí)現(xiàn)聚類,數(shù)據(jù)點(diǎn)通過計(jì)算發(fā)送到各個潛在聚類中心點(diǎn)的信息來決定自己屬于哪個簇,同樣的聚類中心也通過計(jì)算發(fā)送到各個數(shù)據(jù)點(diǎn)的信息判斷哪些數(shù)據(jù)點(diǎn)屬于本簇,在不斷的迭代下確定聚類的個數(shù)和聚類中心數(shù)據(jù)點(diǎn)。
(2)Birch聚類算法。
Birch算法是由Zhang T等在1996年提出的一種分層聚類算法[15]。算法使用聚類特征CF樹結(jié)構(gòu)對數(shù)據(jù)點(diǎn)進(jìn)行聚類。CF樹是由算法對不同子樹賦予不同的權(quán)重而組成的,每個子樹中包含一個特征元組,特征元組由數(shù)據(jù)點(diǎn)數(shù)、點(diǎn)與點(diǎn)之間的線性和點(diǎn)與點(diǎn)之間的平方和組成,因此CF樹中擁有每個子樹的特征統(tǒng)計(jì)信息。CF樹通過最大子樹的個數(shù)確定聚類個數(shù),每個子樹中數(shù)據(jù)點(diǎn)與聚類中心之間的最大距離確定該數(shù)據(jù)點(diǎn)是否屬于本樹。在CF樹自上而下的掃描過程中,由于其擁有每個子樹的統(tǒng)計(jì)信息,所以不需要把所有數(shù)據(jù)都讀取到內(nèi)存中,正是基于這個特性使得Birch算法能夠處理大規(guī)模的數(shù)據(jù)量。CF樹動態(tài)的特性使其能把讀取的新數(shù)據(jù)點(diǎn)插入到最近的子樹中,如果新的數(shù)據(jù)點(diǎn)的直徑超過了閾值,就會重新新建一棵子樹。通過元組的統(tǒng)計(jì)信息對數(shù)據(jù)集進(jìn)行分類,然后在這個基礎(chǔ)上對新讀取的數(shù)據(jù)進(jìn)行聚類,這使得消耗I/O時間相對其他分層算法要小。
(3)Gaussian Mixture Model聚類算法。
高斯混合模型采用概率為標(biāo)準(zhǔn)衡量數(shù)據(jù)之間的相似度。算法假設(shè)數(shù)據(jù)集是由一定數(shù)量的具有高斯分布特性的數(shù)據(jù)組成的,然后將數(shù)據(jù)點(diǎn)的協(xié)方差與高斯中心結(jié)合起來,進(jìn)而實(shí)現(xiàn)GMM擬合的期望最大化。算法利用貝葉斯準(zhǔn)則對數(shù)據(jù)進(jìn)行隨機(jī)分類,然后計(jì)算每個數(shù)據(jù)點(diǎn)是由高斯分布模型生成的概率,在多次迭代調(diào)整參數(shù)后,最大化給定這些數(shù)據(jù)點(diǎn)的概率,進(jìn)而為每個簇里分配最符合其高斯分布的數(shù)據(jù)[16]。
(4)Hierarchical聚類算法。
HC聚類主要分為自下而上的凝聚層次法和從上到下的分裂層次法,前者簇的數(shù)據(jù)點(diǎn)是從少到多依次合并直到滿足一定的條件而終止,后者是把數(shù)據(jù)點(diǎn)逐漸細(xì)分為小的簇,直到滿足條件不再細(xì)分而終止。文中使用的是scikit-learn的HC算法,其屬于凝聚分層法。算法先把每個數(shù)據(jù)點(diǎn)分為一類,然后利用相似度把兩類并成一類,不斷迭代,最后合并為K類。
(5)K-means聚類算法。
K-means算法在1955年最先由Steinhaus提出,之后其他領(lǐng)域也有學(xué)者在各自科研領(lǐng)域提出,直到1967年MacQueen[17]對前人的研究進(jìn)行總結(jié)完善,并且給出了數(shù)學(xué)證明,使得K-means算法被廣泛應(yīng)用。算法利用距離作為相似度的評價準(zhǔn)則,通過不斷迭代使聚類中心點(diǎn)與簇內(nèi)數(shù)據(jù)點(diǎn)的距離盡可能小。文中使用的是K-means++,該算法在數(shù)據(jù)集中隨機(jī)取一個數(shù)據(jù)點(diǎn)作為簇的中心點(diǎn),然后計(jì)算其他數(shù)據(jù)點(diǎn)到聚類中心點(diǎn)的距離,距離越大所對應(yīng)的數(shù)據(jù)點(diǎn)有可能成為下一個簇的中心點(diǎn),通過不斷迭代確定K個聚類中心點(diǎn),這樣就避免了其對聚類中心初始值選定的敏感問題。
(6)Spectral聚類算法。
譜聚類是一種基于對圖譜劃分的算法(2008)[18],該算法對數(shù)據(jù)的空間形狀沒有要求。算法把數(shù)據(jù)集轉(zhuǎn)換為矩陣,通過計(jì)算矩陣的K個特征值和特征值對應(yīng)的特征向量,使其組成一個特征向量空間,利用特定的劃分規(guī)則,比如基于距離的劃分規(guī)則,在多次迭代之后使簇內(nèi)數(shù)據(jù)點(diǎn)的權(quán)重大(相似度高),簇與簇之間的權(quán)重小(相似度低)。
綜上所述分析,文中選取數(shù)據(jù)屬性、時間復(fù)雜度、算法伸縮性、算法對噪聲的敏感程度、處理高維數(shù)據(jù)的能力、對復(fù)雜形狀的數(shù)據(jù)集是否適用這六個指標(biāo),對上述六種算法的性能進(jìn)行了總結(jié),如表1所示。
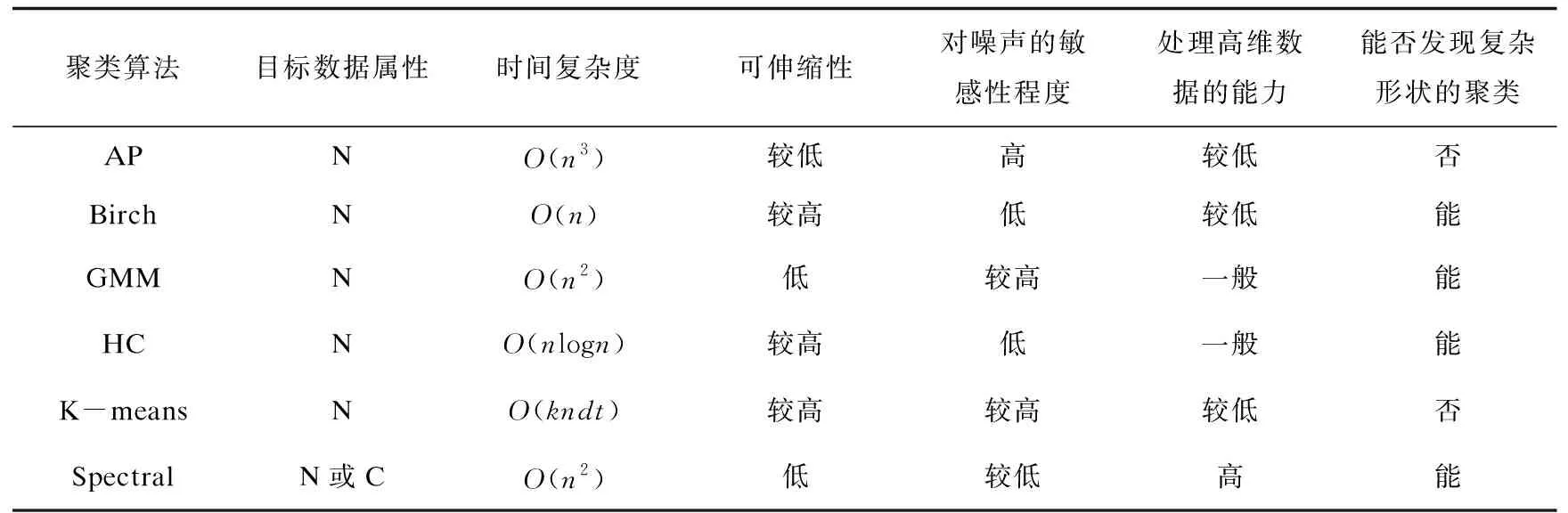
表1 部分聚類算法性能總結(jié)和比較
3 聚類有效性指標(biāo)概述
由于文中的數(shù)據(jù)都是無標(biāo)簽的,所以采用內(nèi)部評價標(biāo)準(zhǔn),利用數(shù)據(jù)集和聚類結(jié)果生成的標(biāo)簽對聚類效果進(jìn)行評估。小組內(nèi)的數(shù)據(jù)相似度越高,小組與小組數(shù)據(jù)差異度越大,說明數(shù)據(jù)被很好地歸類。常用的評價指標(biāo)有Silhouette Coefficient和Calinski-Harabaz Index。
3.1 Silhouette Coefficient
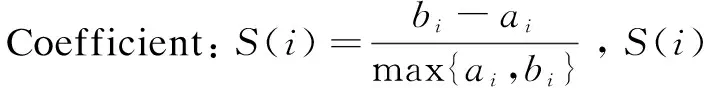
3.2 Calinski-Harabaz Index
Calinski-Harabaz Index是由Calinski和Harabaz[20]于1974年提出的一種評價指標(biāo)。CH系數(shù):
其中,K表示聚類中心的個數(shù),tr(Bk)表示簇與簇之間離差矩陣的跡,tr(Wk)表示簇內(nèi)離差矩陣的跡。Bk表示簇與簇之間的協(xié)方差矩陣,Wk表示簇內(nèi)協(xié)方差矩陣。CH評分是簇間分離值與簇內(nèi)分離值之值,比值越大代表聚類效果越好。
4 實(shí)驗(yàn)測試及分析
本節(jié)利用數(shù)據(jù)的差異對Affinity Propagation、Birch、Gaussian Mixture Model、Hierarchical clustering、K-means和Spectral算法的聚類效果和效率進(jìn)行了綜合實(shí)驗(yàn)評估。所有算法由Python實(shí)現(xiàn),Python的版本是Python 3.7.2,sklearn的版本是scikit-learn v0.21.1,實(shí)驗(yàn)平臺采用Intel(R)Core(TM)i5-4210M CPU @ 2.6 GHz,8 G內(nèi)存,Windows 10企業(yè)版。
4.1 實(shí)驗(yàn)數(shù)據(jù)和測試方法
實(shí)驗(yàn)數(shù)據(jù)均屬于機(jī)器數(shù)據(jù),主要分為兩大類:連續(xù)型數(shù)據(jù)和離散型數(shù)據(jù)。其中連續(xù)型數(shù)據(jù)分為七類,離散型數(shù)據(jù)分為離散小數(shù)和離散整數(shù)兩類。具體信息如表2所示。
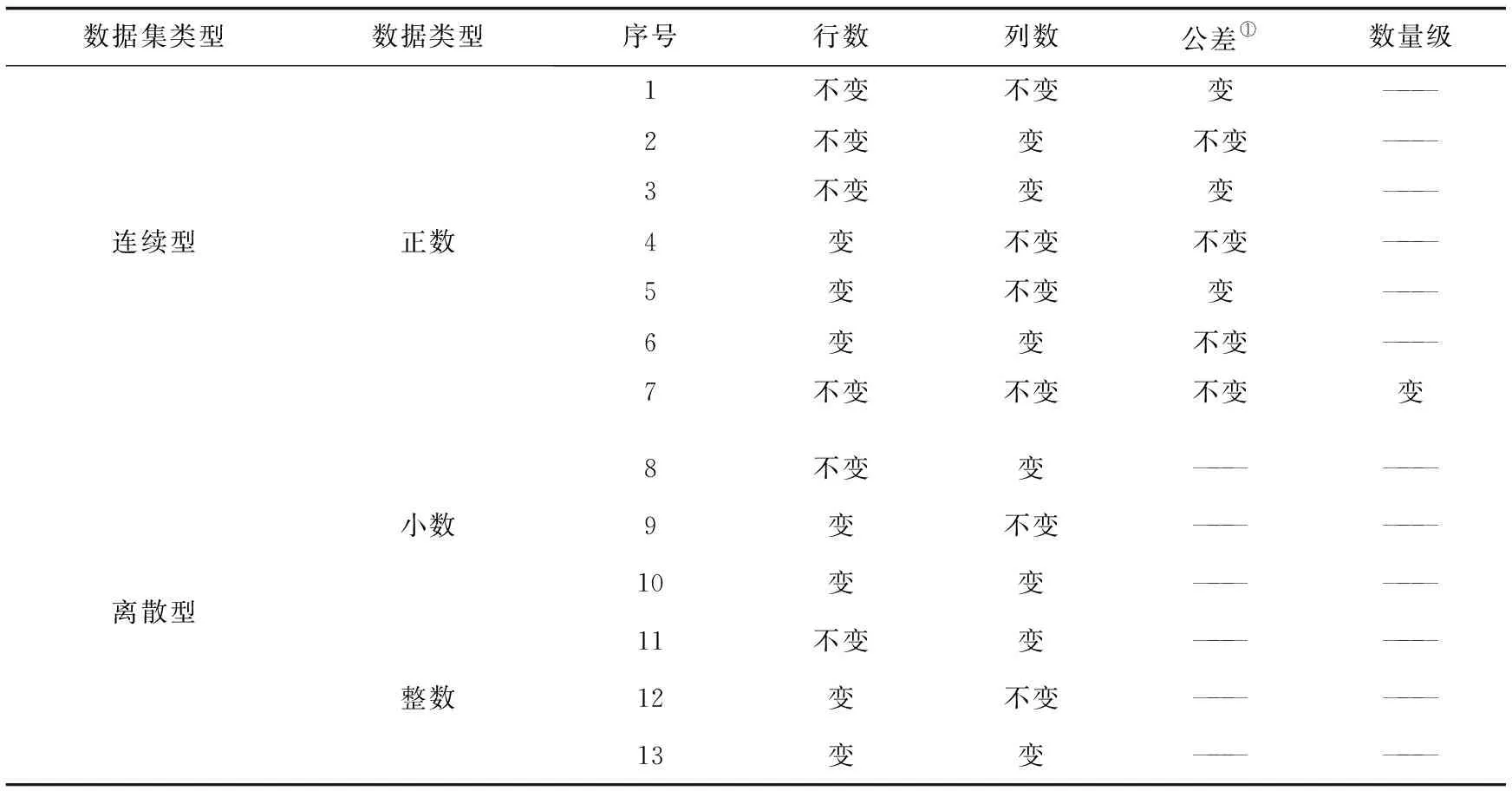
表2 數(shù)據(jù)描述
4.2 測試方法
為了探究聚類算法的有效性,對Affinity Propagation、Birch、Gaussian Mixture Model、Hierarchical clustering、K-means和Spectral算法分別在13類基準(zhǔn)數(shù)據(jù)集上進(jìn)行了測試。因?yàn)橐陨纤惴ň鶎儆跓o監(jiān)督算法,所以聚類效果的評估使用了Silhouette Coefficient(以下簡稱輪廓系數(shù))和Calinski-Harabasz Index(以下簡稱CH評分),使用聚類算法消耗的時間作為算法效率的評價指標(biāo),并且探究了算法對數(shù)量級的敏感性分析。
4.3 效果評估
為了保持一致性,被測試算法被設(shè)定為四個聚類中心。其中Affinity Propagation 算法的preference=-50、Gaussian Mixture Model算法的covariance_type為'full'、K-means算法的內(nèi)核為K-means++,random_state=28。
如圖2所示,為了區(qū)分,采用不同的形狀表示不同的算法。

(a)離散型小數(shù)
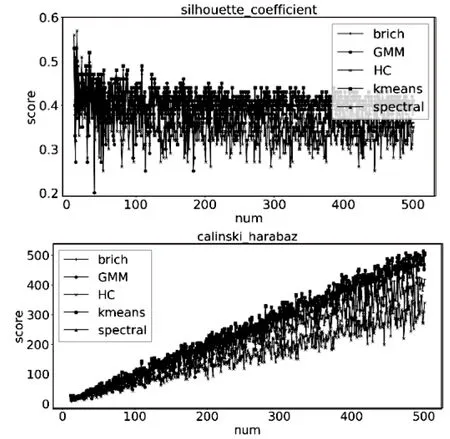
(b)離散型整數(shù)

(沒有AP算法的局部圖)
4.3.1 數(shù)據(jù)只有行數(shù)增加時
當(dāng)數(shù)據(jù)集為離散數(shù)據(jù)時,從圖2(a)和(b)中可以看出,在輪廓系數(shù)中聚類效果隨著行數(shù)的增加而變差,CH評分中聚類效果隨著行數(shù)的增加而變好,在兩種評價指標(biāo)下聚類效果最好的是K-means;當(dāng)數(shù)據(jù)集為連續(xù)型正數(shù)時,從圖2(c)中可以看出,Birch、GMM、HC、K-means和Spectral的聚類效果在CH評分中很接近,AP算法大約在20行以上的聚類效果隨著行數(shù)的增加其CH評分遠(yuǎn)遠(yuǎn)高于其他五種算法,這主要是因?yàn)锳P算法對數(shù)據(jù)的初始值不敏感,并且其聚類中心是數(shù)據(jù)集中的點(diǎn),而不是由算法生成的中心點(diǎn)。然而在輪廓系數(shù)中,AP算法的評分反而是一個比較固定的值,且表現(xiàn)不如其他算法,這是因?yàn)锳P算法的聚類中心點(diǎn)為已有數(shù)據(jù)點(diǎn),數(shù)據(jù)的特性導(dǎo)致簇與簇之間的平均距離和簇內(nèi)平均距離比較固定,進(jìn)而使得輪廓系數(shù)的值隨行數(shù)的變動很小。
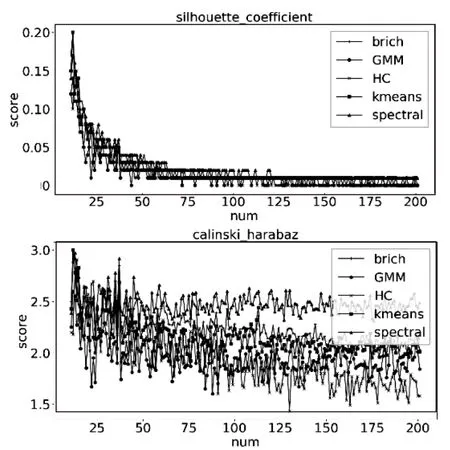
4.3.2 數(shù)據(jù)只有列數(shù)增加時
當(dāng)數(shù)據(jù)集為離散數(shù)時,被測試算法的聚類效果隨著列數(shù)的增加而變差。從圖3(a)中可以看出,當(dāng)數(shù)據(jù)集為離散型小數(shù)時,算法在兩種評價指標(biāo)下的聚類效果很接近,其中Spectral算法隨列數(shù)的增加波動性變大,而其余算法則比較穩(wěn)定。從圖3(b)中可以看出,當(dāng)數(shù)據(jù)隨集為離散型整數(shù)時,算法在兩種評價指標(biāo)下聚類效果很接近,其中HC算法隨列數(shù)的增加波動性變大,而其余算法則比較穩(wěn)定;當(dāng)數(shù)據(jù)集連續(xù)型正數(shù)時,從圖3(c)中可以看出,在兩種評價標(biāo)準(zhǔn)中,被測試算法的聚類效果中除了Spectral算法其余算法基本不受列數(shù)變動的影響,而且被測試算法的聚類效果在兩種評價標(biāo)準(zhǔn)中表現(xiàn)不同。在CH評分下被測試算法聚類效果最好的是AP,其次是K-means,在輪廓系數(shù)評分下被測試算法的聚類效果從好到差排名是:HC、K-means、GMM、Birch、AP。

(a)離散型小數(shù)

(b)離散型整數(shù)

(沒有AP算法的局部圖)
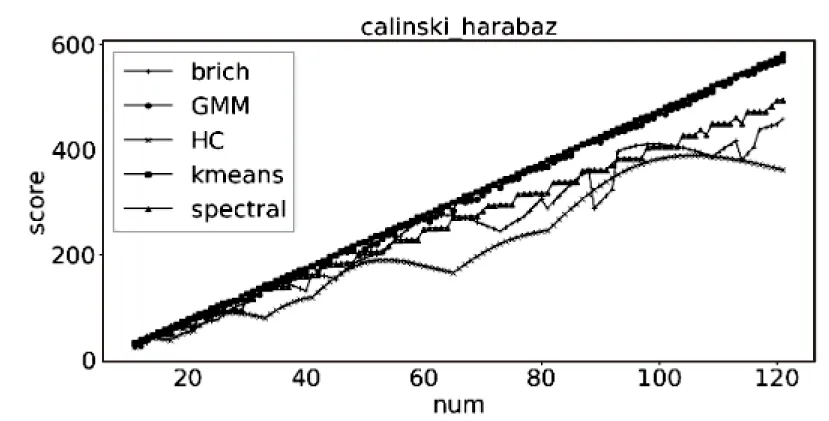
4.3.3 數(shù)據(jù)的行數(shù)和列數(shù)同時增加
當(dāng)數(shù)據(jù)集為離散數(shù)據(jù)時,被測試算法的聚類效果隨著行數(shù)和列數(shù)的增加而變差。從圖4(a)中可以看出,當(dāng)數(shù)據(jù)集為離散型小數(shù)時,算法在兩種評價指標(biāo)下聚類效果很接近,其中Spectral算法的波動性很大。從圖4(b)中可以看出,當(dāng)數(shù)據(jù)集為離散型整數(shù),在行數(shù)超過75時,Spectral算法的CH評分最高;當(dāng)數(shù)據(jù)集為連續(xù)型正數(shù)時,從圖4(c)中可以看出,被測試算法的聚類效果在兩種評價標(biāo)準(zhǔn)中表現(xiàn)不同。在CH評分下被測試算法聚類效果最好的是AP,其余算法的聚類效果則比較接近,在輪廓系數(shù)中當(dāng)數(shù)據(jù)集的列數(shù)超過4列以后,AP算法的聚類效果最差。
(a)離散型小數(shù)
(b)離散型整數(shù)

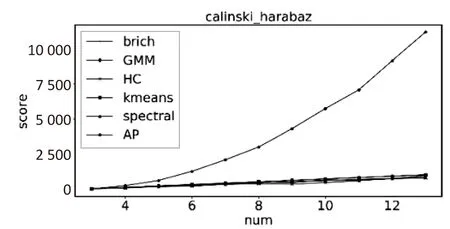
(c)連續(xù)型正數(shù)
4.4 性能測試
本節(jié)在各種數(shù)據(jù)集上測試了不同算法的消耗時間,以消耗時間的多少作為評價算法效率的標(biāo)準(zhǔn)。本節(jié)在離散型小數(shù)、離散型整數(shù)和連續(xù)型正數(shù)中分別選取了500行2列的數(shù)據(jù)集作為研究對象。效果如圖5所示。

(沒有AP算法的局部圖)
從圖5上圖可以看出,AP算法消耗的時間最多,效率最低,這是因?yàn)锳P算法要提前把數(shù)據(jù)點(diǎn)的相似度計(jì)算出來,加之AP算法的時間復(fù)雜度為O(n3),最后使得AP算法消耗時間最多。AP算法在離散整數(shù)型數(shù)據(jù)集中消耗的時間最少。剩余五種被測試的算法消耗的時間接近,所以特意做了一個沒有AP算法的局部圖,如圖5下所示,其中Spectral算法消耗的時間最多,主要是因?yàn)镾pectral算法是基于原有數(shù)據(jù)的相似度來計(jì)算特征值,所以花費(fèi)的時間要多一些。Birch算法在小數(shù)中的計(jì)算速度最快,是因?yàn)槠洳恍枰讶繑?shù)據(jù)遍歷完,只需要對葉子節(jié)點(diǎn)進(jìn)行處理,經(jīng)過多次迭代以后得出聚類中心。因?yàn)闄C(jī)器讀取小數(shù)的速度要快于整數(shù),所以Birch在小數(shù)中的效率要更高。K-means、GMM和HC算法在三類數(shù)據(jù)集中的表現(xiàn)差異不大,說明這三種算法對數(shù)據(jù)類型的敏感度比較低。
4.5 算法對數(shù)據(jù)敏感性分析
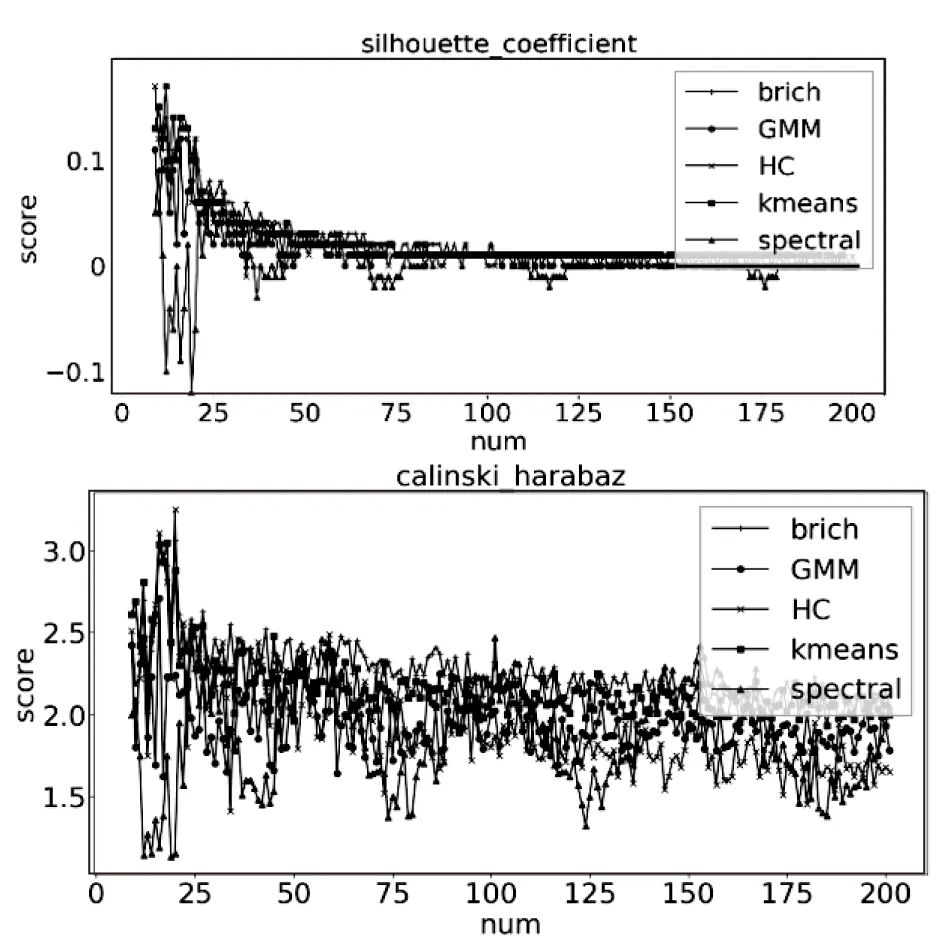
本節(jié)是由不同數(shù)量級的數(shù)據(jù)組成的數(shù)據(jù)集,由于AP、Birch和GMM算法需要變動參數(shù),所以為了保持全文一致性,沒有對這三種算法做敏感性測試。數(shù)據(jù)集結(jié)構(gòu)為300行2列。橫坐標(biāo)的單位值代表十的一次方,測試結(jié)果如圖6所示。由圖6可知,在兩種評價標(biāo)準(zhǔn)下K-means要比其他兩種算法的聚類效果好,其中K-means和HC對數(shù)量級組成的數(shù)據(jù)集不敏感,Spectral算法對數(shù)量級比較敏感。
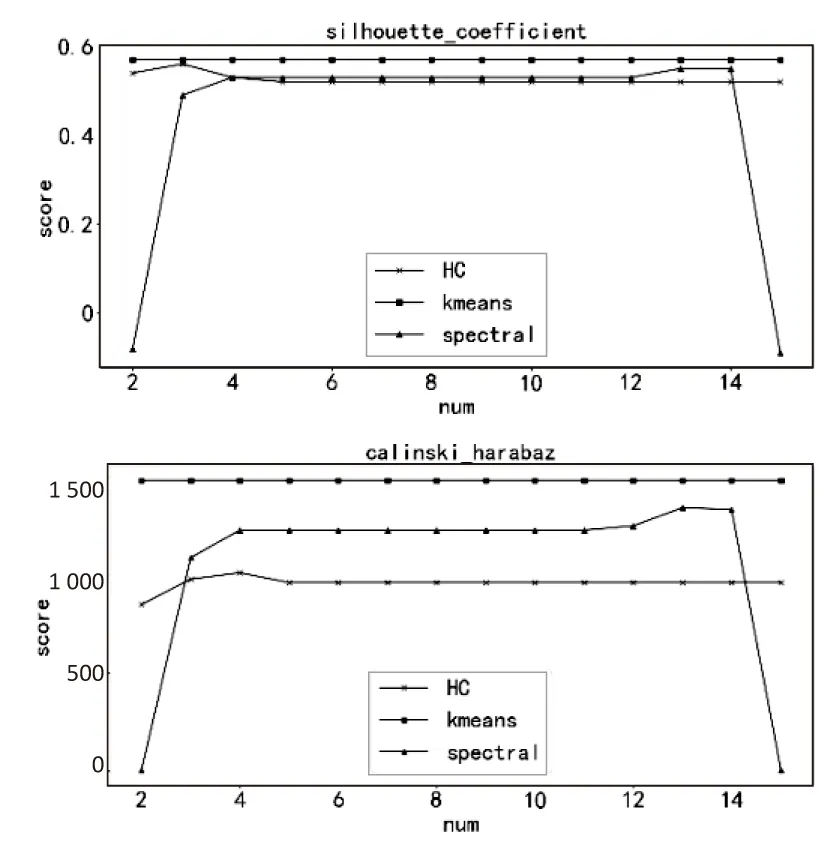
圖6 算法在不同數(shù)量級下的效果對比
5 結(jié)束語
通過上述分析,在聚類效果、性能和敏感性三個方面得到以下結(jié)論:
(1)聚類效果:①數(shù)據(jù)只有行數(shù)增加時,AP算法和K-means的聚類效果好于其他四種算法;②數(shù)據(jù)只有列數(shù)增加時:在數(shù)據(jù)類型為離散型小數(shù)中,算法的聚類效果很接近,其中Spectral算法的波動性最大。在數(shù)據(jù)類型為離散型整數(shù)中,算法的聚類效果很接近,其中HC算法的波動性最大。在數(shù)據(jù)類型為連續(xù)型正數(shù)中,AP算法和K-means的聚類效果好于其他算法;③數(shù)據(jù)的行數(shù)和列數(shù)同時增加時:在數(shù)據(jù)類型為離散小數(shù)中,算法的聚類效果很接近,其中Spectral算法的波動性最大。在數(shù)據(jù)類型為離散整數(shù)中,Spectral算法的聚類效果相對好于其他算法。在數(shù)據(jù)類型為連續(xù)型正數(shù)中,在CH評分下被測試算法的聚類效果最好的是AP,其余算法效果比較接近,在輪廓系數(shù)下當(dāng)列數(shù)超過4以后,AP算法的聚類效果最差。
(2)性能:AP算法消耗的時間最多,效率最低,其次是Spectral算法,剩余幾種算法的計(jì)算效率比較接近。
(3)敏感性:K-means和HC對數(shù)量級不敏感,Spectral算法對數(shù)量級相對比較敏感。
綜上,在聚類效果、性能和對數(shù)量級的敏感性三個方面綜合來看,K-means算法相對優(yōu)于其他五種聚類算法。各個算法各有優(yōu)缺點(diǎn):AP算法在連續(xù)型正數(shù)組成的數(shù)據(jù)集中,隨著行數(shù)的增大其聚類效果明顯好于其他算法。但是AP算法的效率在六種算法中是最差的;Birch算法的效率在數(shù)據(jù)類型為小數(shù)的數(shù)據(jù)集中表現(xiàn)最好,但其適用性相對最差;GMM算法聚類效率在連續(xù)型正數(shù)的數(shù)據(jù)集中表現(xiàn)的最好;HC和K-means算法的聚類效果在連續(xù)型正數(shù)組成的數(shù)據(jù)集中不受列數(shù)變動的影響,但在行數(shù)變化的離散型數(shù)據(jù)集中HC算法的聚類效果相對最差;Spectral算法對數(shù)據(jù)的敏感性相對最高,在小數(shù)構(gòu)成的數(shù)據(jù)集中聚類效果相對最差。
雖然現(xiàn)在很多聚類算法不斷地被提出和改進(jìn),但是還沒有出現(xiàn)一種適用于不同數(shù)據(jù)特征的算法,這主要是因?yàn)榫垲愃惴]有迭代優(yōu)化其正確性,而過分強(qiáng)調(diào)簇內(nèi)緊湊,簇間疏離。隨著大數(shù)據(jù)時代的到來,數(shù)據(jù)不僅越來越多而且數(shù)據(jù)結(jié)構(gòu)越來越復(fù)雜,如何制定一種適合多種情況的聚類算法和評價指標(biāo)將是下一步需要做的重要工作。
猜你喜歡
中老年保健(2021年12期)2021-11-30 02:58:01
好日子(2021年8期)2021-11-04 09:02:46
小學(xué)生學(xué)習(xí)指導(dǎo)(爆笑校園)(2020年6期)2020-07-03 10:01:10
攝影之友(影像視覺)(2019年2期)2019-03-05 08:27:14
攝影之友(影像視覺)(2018年12期)2019-01-28 09:01:02
攝影之友(影像視覺)(2018年12期)2019-01-28 09:01:02
中華詩詞(2018年11期)2018-03-26 06:41:34
小學(xué)生學(xué)習(xí)指導(dǎo)(低年級)(2017年11期)2017-10-23 01:32:36
Coco薇(2016年8期)2016-10-09 02:11:50
中國醫(yī)藥科學(xué)(2015年19期)2015-02-27 12:33:11
