基于Flink實時計算的自動化流控制算法
2020-08-12 02:32:48樊春美朱建生單杏花楊立鵬
計算機技術與發(fā)展 2020年8期
樊春美,朱建生,單杏花,楊立鵬,李 雯
(中國鐵道科學研究院,北京 100081)
0 引 言
隨著鐵路售票系統業(yè)務的多樣化,來自各個業(yè)務系統的日志解析變得越來越復雜。對于日志數據進行實時的采集和解析是當前需要解決的重要問題。鑒于大數據的應用比較廣泛,尤其是分布式的架構和實時計算框架,如Flink[1]、Spark[2]計算平臺變得越來越熱門,因此現在大部分互聯網公司都會采用實時計算來完成日志的采集和存儲。而對于復雜的鐵路售票系統,不僅需要針對不同服務層進行日志的采集,還需要對不同業(yè)務場景的不同類型的日志進行解析,為了業(yè)務數據分析的需要,可能同一份數據還要存儲到不同的渠道中;與此同時系統會隨著生產的需求而不斷完善,因此也會導致日志存儲格式的變動,從而需要不停地調整解析程序來適應新的需求。在每一次變動中,都需要測試整套解析程序,開發(fā)效率較慢,甚至對于一個數據流的解析要啟動多個程序,造成資源的浪費,維護多個程序也變得更加復雜。于是可以采用現在常用的改變配置文件的方式來實時更新解析相關的配置。但是分布式的計算框架刷新配置文件存在著兩個問題,一個是配置文件的存放問題,一般分布式的計算框架,真正的計算程序是在每個節(jié)點上執(zhí)行的,配置文件如果在master節(jié)點上,而每個執(zhí)行節(jié)點是不能讀取master節(jié)點的配置文件的,如果每個執(zhí)行節(jié)點都放一份配置文件,也無法保證每個執(zhí)行節(jié)點的路徑是一致的,只要其中的一個節(jié)點路徑不一致就會導致程序出錯,無法執(zhí)行;另外一個問題是,假設能夠保證每臺機器的路徑都是一致的,配置文件可以放在每臺機器上,這時程序每解析一條數據都要讀取一次配置文件,頻繁的讀取必然會影響解析的效率。由于對于分布式的計算框架刷新配置存在著上述兩個問題,文中提出了一種通過自動化流控制的方法,實現配置文件的實時刷新。
1 相關工作
目前針對大型數據的分析框架主要有Hadoop、Spark、Flink等[3-5]。以Hadoop為代表的大數據技術的出現,可以很好地解決大量靜態(tài)數據集的數據處理與分析,但是很多數據都是實時產生的,用戶希望可以實時地處理這些數據,這就需要使用流計算技術來實時處理這些數據,及時產出應用價值。
而Apache Spark是專為大規(guī)模數據處理而設計的快速通用的計算引擎,是一種與Hadoop相似的開源集群計算環(huán)境,其擁有Hadoop MapReduce所具有的優(yōu)點,但與MapReduce存在的不同是任務中間輸出結果可以保存在內存中,從而不再需要讀寫HDFS,因此Spark除了能夠提供交互式查詢外,還可以優(yōu)化迭代工作,能更好地適用于數據挖掘與機器學習等需要迭代的MapReduce的算法。
隨著Spark計算引擎的出現,促進了上層應用快速發(fā)展,如對各種迭代計算的性能以及對流計算和SQL等的支持,Flink就在這樣的背景下誕生了。Flink的突出優(yōu)勢是對流計算的支持及更一步的實時性。為了對流式引擎處理有更深刻的認識,Sanket Chintapalli等人[6]基于常用的流式計算構建了三種不同的流引擎,進行對比分析。其中Spark streaming是將流劃分解成一系列短小的批處理作業(yè),Flink才是真正的流處理,批處理只是流數據的一個極限特例而已。Flink不僅可以支持本地的快速迭代,以及一些環(huán)形的迭代任務,而且Flink可以定制化內存管理,其并沒有將內存完全交給應用層,因此Flink處理大數據速度快,能夠更好地滿足大數據背景下應用實時計算平臺的需求。
由于Flink框架的優(yōu)勢,現在有很多關于Flink應用的相關研究。蔡鯤鵬[7]研究了Flink的概念、生態(tài)系統和相關技術等理論基礎并對Hadoop和Flink在處理大批量數據上的耗時和準確率進行了對比分析,針對不同的流式處理平臺,分析總結了Flink所面臨的一些挑戰(zhàn),為Flink的進一步研究提供了參考。麥冠華等[8]基于Flink的計算框架,設計了對大規(guī)模軌跡數據進行實時運動模式檢測的算法,彌補了對于當前大規(guī)模軌跡數據只能做范圍查詢、近鄰查詢的簡單處理的不足,很好地應用了Flink實時計算的優(yōu)勢。Marciani G[9]利用Flink框架對社交網絡進行實時分析,系統架構的設計重點在于利用Flink的并行性和內存效率,以便能夠在分布式基礎設施上有效地處理大容量數據流。不僅Flink的應用比較廣泛,對其優(yōu)化的相關研究也比較多。Verbitskiy I等[10]分析了Flink的執(zhí)行效率,通過各種實驗評估表明Apache Flink的性能是高度依賴于問題的;李梓楊等人[11]通過針對大數據流式計算平臺中輸入數據流急劇上升所導致的計算延遲升高問題進行優(yōu)化,有效地提高了現在Flink框架集群的吞吐量;文獻[12-13]對基于多查詢和狀態(tài)管理進行了優(yōu)化,研究了Flink的可擴展性等等。但是對于Flink使用過程中數據解析邏輯的控制研究相對較少。
文中主要從對Flink進行實時解析時邏輯的更改角度進行優(yōu)化,通過使用流控制的方式,減少代碼的開發(fā)量,提高Flink應用實時解析的效率。
2 實時計算架構
隨著業(yè)務越來越復雜,需要采集和存儲的數據越來越多,由于存在著不同的業(yè)務系統,日志的存儲格式多種多樣。為了對不同的日志進行解析,同時能夠根據不同的需求將解析的數據輸出到相應的存儲空間,需要開發(fā)一套滿足靈活地適配各種日志格式的數據解析架構,從而減少同類解析代碼的開發(fā),將不同的數據解析進行集中式的管理。文中基于隊列和分布式流處理架構構建了大數據的實時采集計算和存儲平臺。數據處理架構如圖1所示。
1.數據采集。
日志數據都是實時產生的,在采集的過程中,也是在不斷生成的,因此數據采集模塊需要完成實時采集。目前應用較多的有Tcollector、Filebeat[14]等采集工具。
其中Filebeat具有兩個較大的優(yōu)勢:
(1)性能穩(wěn)健。
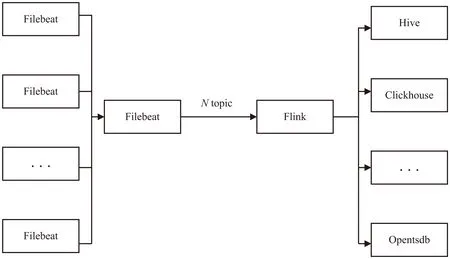
圖1 數據處理架構
無論什么樣的應用都可能存在程序中斷的情況,Filebeat能夠讀取并轉發(fā)日志行,如果出現中斷,還會在一切恢復正常后,從中斷前停止的位置繼續(xù)開始。
(2)部署簡單。
Filebeat內置有多種模塊(Apache、System、MySQL等等),可以針對常見格式的日志大大簡化收集、解析和可視化過程。
基于Filebeat的優(yōu)勢,在構建數據的采集平臺時采用該服務進行日志的實時采集。在部署采集程序時,將不同的業(yè)務發(fā)送到不同的topic數據流中;通過Filebeat的配置文件實現數據采集的機器、日志文件、采集的路徑、數據的輸出端的配置。
2.數據傳輸。
數據傳輸采用Kafka[15]隊列,每個topic隊列作為一個單獨的數據流,并與數據的采集和解析構成完整的數據處理流。除了采集業(yè)務數據的數據流,這里增加一個空流,用來進行流控制。Kafka采集的各個數據流如圖2所示。
圖2 采集的數據流
3.數據解析。
數據解析部分需要獲取多種數據的配置,如系統配置、數據源配置、數據解析邏輯配置、數據存儲配置、監(jiān)控配置等。數據解析模塊主要是通過使用Flink的各種算子組合完成業(yè)務數據解析邏輯的。該模塊是整個實時采集計算和存儲平臺的核心部分,對數據的實時計算能力要求較高。該模塊不僅需要完成對數據流的實時解析,同時還要支持對數據流解析的實時更改。例如一個流能夠解析多個topic的數據,一個topic能夠通過解析程序分流到不同的存儲路徑,對一個流能夠實時地更改解析邏輯,而不需要重啟。
4.數據存儲。
日志數據不僅用來進行業(yè)務的分析,還需要對各種業(yè)務的指標進行監(jiān)控,所以同一份日志的數據需要存儲到不同的存儲介質,因此數據流的輸出結果也會有多種,如hdfs、hive、clickhouse、opentsdb等多個存儲渠道。
3 自動化流控制算法
基于第2節(jié)介紹的實時計算架構,提出了使用更新算子的方式來改變數據流的解析邏輯。
3.1 流迭代算法
現在通用的數據流處理方式是流stream1處理完,將得到的結果作為stream2的輸入,在stream2流的處理中完成對stream1的結果的處理,將stream流的解析通過不同的map邏輯依次處理,直到得到想要的輸出結果。解析邏輯如圖3所示。

圖3 解析邏輯
而第2節(jié)介紹的實時計算架構,不再使用這種方式進行業(yè)務邏輯的處理,而是通過配置文件來實現,為了滿足通過更新配置文件代替代碼開發(fā)完成日志解析的需求,提出流迭代的算法,具體算法邏輯如下:
輸入:需要解析的數據流stream。
輸出:解析結果。
Step1:將每個要處理的數據流的名稱通過hashmap進行存儲,假設
Step2:按照對datastream1的流處理算子得到流處理結果dataset1;
Step3:更新hashmap中stream1的value值為dataset1;
Step4:遍歷下一個需要處理的算子,直接讀取key=stream1的value值,對stream1的value值執(zhí)行相應的解析邏輯得到數據集dataset2;
Step5:更新stream1的value值為dataset2;
Step6:依次迭代對數據流處理的各個算子,直到完成所有的解析邏輯,最后結果依然保存在stream1中。
通過流迭代的方法,每次算子執(zhí)行的時候都是對同一個stream1進行處理,只需要遍歷定義好的算子即可,這樣很多算子在不同的數據流解析中可以共用,不僅可以減少代碼的開發(fā)量,還可以把開發(fā)的重點放在業(yè)務邏輯處理中,解析日志的程序開發(fā)變得更加簡單。在算子中還可以添加復制的算子,將一個數據流復制成多個數據流,再針對不同的數據流配置不同的日志解析算子,實現分流的效果。
3.2 流控制算法
程序的重新啟動會中斷正在運行的解析邏輯,有些數據實時性要求較高,中間重啟程序會造成一些數據的缺失。同時針對3.1介紹的流切換算法中的stream值更新的時候也需要實時地傳入,因此文中設計了免更新、免重啟的流控制算法。
輸入:解析算子γ,算子γ是可以實現數據流選擇和各種解析業(yè)務邏輯的配置,里面通過設置一個參數source,實現對不同數據流的解析邏輯控制。
輸出:按照算子指定的執(zhí)行邏輯輸出結果。
Step1:假設需要解析的數據流為dataA,在現有需要解析的數據流中增加一個空的數據流temp,該數據流開始時不存儲任何數據,同時增加一個內部類的變量用來存儲解析的算子γ;
Step2:在實時的代碼解析邏輯中,增加一個對temp流的解析;
Step3:在需要更新解析邏輯時,通過注入的方式將最新的解析邏輯注入到temp流中;
Step4:通過解析temp流中的數據,獲取針對當前數據流的解析邏輯,并更新為γ的值;
Step5:再次解析數據流dataA的時候,就會使用最新的解析邏輯來處理數據,從而實現解析邏輯的實時控制。
算法的實現邏輯如圖4所示,數據流處理主要分為數據的采集和解析,業(yè)務數據流主要是從各個業(yè)務系統實時采集對應的數據,而邏輯數據流是在需要解析某個業(yè)務數據時,傳入業(yè)務流對應的解析邏輯;在數據解析環(huán)節(jié)首先獲取解析邏輯的解析算子,從而實現對業(yè)務數據流解析的控制。
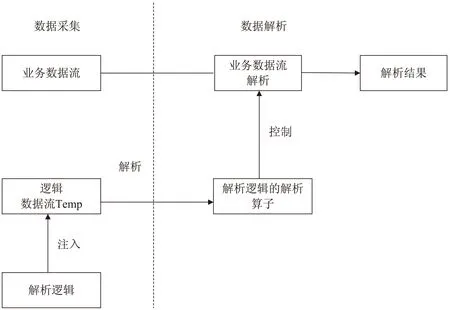
圖4 業(yè)務數據流處理流程
3.3 temp流中的解析算子γ
注入temp數據流的解析算子γ配置如下:
#系統配置
#數據源
#業(yè)務邏輯(任務解析)
#配置輸出
#監(jiān)控配置
通過java生成相應的文件,注入到temp數據流中。在整個架構中有一個控制類,該類通過讀取XML文件,解析一個配置類,配置的成員包括系統配置類、數據源類、業(yè)務邏輯算子類、配置輸出sink類等,其中算子類在實現的時候會繼承一個基類,這樣不同類型的算子都可以組成一個基類算子的list列表。
4 算法應用實例
以從Kafka隊列接收數據,使用Flink解析,輸出到hdfs、Opentsdb存儲數據中為例,介紹該算法在具體的實時流計算框架中的應用。
4.1 配置文件實例
下面給出了注入temp的主要配置信息。
4.2 Flink代碼解析
Flink是一種典型的分布式計算,對于內部類外的變量會在程序啟動后存儲在master節(jié)點上,且后續(xù)都不能改變,而對于內部類中的變量在每次代碼執(zhí)行時都會執(zhí)行,因此采用3.2介紹的流控制方法在內部類中添加一個變量,用來存儲解析算子,在對不同業(yè)務數據進行處理時,更新這個值就可以達到解析的目的。
偽代碼邏輯如下:
創(chuàng)建一個臨時變量str=temp;
#解析數據流DataA
{
#根據str,實現map的解析
DataStream
}
#解析數據流temp
{
Parse(temp_map)
輸入新的解析算子new_temp
If(Source=stream1){ str=new_temp;}
else{Return;}
4.3 實驗對比
目前生產上共配置了5臺CPU16核,內存為64 G的服務器,搭建了實時解析架構平臺,每秒的日志處理流量大概15 W左右,處理業(yè)務日志種類多達50個,隨著業(yè)務的變動,實時平臺的調整也會比較頻繁。
完成一個在線運行的業(yè)務更改邏輯過程對比如下:
不使用文中提出的自動化流控制算法的業(yè)務處理過程:
(1)從Filebeat采集的每條數據中獲取需要的字段;
(2)對指定的日志數據寫代碼進行解析,調試;
(3)查看解析結果,是否滿足業(yè)務的需求;
(4)寫入庫的sink代碼,調試;
(5)查看入庫的結果;
(6)將代碼打包、上傳jar包到各臺服務上;
(7)重啟各個進程,查看程序是否正常啟動。
使用文中提出的自動化流控制算法的業(yè)務處理過程:
(1)在配置文件中實現所有的邏輯;
(2)查看解析和入庫的結果;
(3)將配置文件注入到topic流中;
(4)自動生效,完成邏輯的更改。
消耗和用時結果對比如表1所示。

表1 是否使用流處理的對比結果
從實現的流程可以看到,使用文中提出的自動化流控制算法可以很大程度地減少代碼的開發(fā)與測試,減少生產部署的工作量,最大程度地保證了生產數據的實時性。
5 結束語
通過Filebeat、Kafka隊列和Flink流式處理架構,構建了一套實時數據流解析的平臺,不僅能夠針對大量的數據進行實時解析,還能夠滿足實時更新解析邏輯的策略,極大地提高了生產數據的采集和分析效率。通過該實時解析架構平臺,可以實現多流合并,單流分流,及業(yè)務邏輯實時更新等多個功能,提高了分布式流處理架構Flink的應用性能,為當前各個互聯網公司復雜業(yè)務邏輯的大數據處理提供了解決方案,具有一定的現實意義。后續(xù)將會對Flink使用的資源做進一步的優(yōu)化,提高數據解析平臺的資源利用率。
