基于“屬性-情感詞”汽車本體的文本情感分析
2020-08-12 02:33:00王連喜
計算機技術與發(fā)展 2020年8期
王連喜
(1.廣州市非通用語種智能處理重點實驗室,廣東 廣州 510006;2.廣東外語外貿大學 信息科學與技術學院,廣東 廣州 510006)
0 引 言
隨著社會媒體與電子商務技術的快速發(fā)展與普及,普通民眾已經習慣在網絡發(fā)布和獲取信息。據中國互聯(lián)網絡信息中心(CNNIC)發(fā)布的第43次《中國互聯(lián)網絡發(fā)展狀況統(tǒng)計報告》顯示,2018年中國數字經濟以電子商務為先導力量獲得迅速發(fā)展,引領數字產業(yè)崛起和產業(yè)數字化轉型[1]。特別在在線汽車網絡評論領域,互聯(lián)網用戶創(chuàng)造了大量蘊含情感色彩的UGC,準確地對用戶主動生產的口碑評論信息進行挖掘和分析,可以有效幫助消費者了解汽車產品各方面性能的評價分布,從而優(yōu)化其消費決策,同時也可以幫助商家了解用戶需求和理解用戶消費習慣,總結自身產品和服務的優(yōu)勢與不足。
由于網絡上的產品評論大多是以半結構化形式表示的,缺乏對數據本身的描述,也沒有規(guī)范性的結構,甚至有些評論的情感詞在與不同產品屬性進行組合時會表達出不同的情感傾向。例如,“這款車的油耗高”與“這款車的性價比高”兩個評論中都存在情感詞“高”,但是前者的情感傾向性是消極的,而后者是積極的。上述問題會對網民獲取、利用、分析UGC帶來一定的困難,因此亟需高效、有用的方法對特定領域的情感詞、產品屬性對象以及它們組合所蘊含的情感傾向性進行準確識別。
基于此,文中以汽車評論文本為研究對象,通過構造面向汽車領域的“屬性-情感詞”本體,提出基于“屬性-情感詞”本體的觀點句情感分析方法,以期準確識別出情感詞與不同產品屬性對象組合所表達的情感傾向,從而提高汽車產品的細粒度情感分析效果。
1 相關研究
近年來,本體技術[2-3]已經被廣泛應用于評論情感分析研究中。許多學者通過構建通用型情感詞匯本體或情感詞典來輔助情感分析研究,也有部分學者嘗試結合領域本體技術與產品特征來提高特定領域評論情感分析的準確性。2008年,徐琳宏等人通過整理和標注了多種詞典和語義資源,構建了中文情感詞匯本體庫[4]。該情感詞匯本體由三元組來描述,并通過計算情感詞匯與給定的20類標準詞匯在語料中的互信息來確定情感強度和極性。該情感詞匯本體已成為目前被廣大研究人員借鑒或使用最多的工具。Lau等人[5]提出一種用模糊領域本體的實例化版本來表示情感知識,重點關注領域特征、領域情感詞以及它們之間的對應關系抽取,能夠較好地應用于上下文敏感的意見挖掘。郭沖等人[6]定義了一種用于細粒度意見挖掘的情感本體樹結構,并結合細粒度意見要素抽取技術提出基于本體樹的自動構建方法。
在領域本體構建及產品輿情分析方面,目前也產生了許多有價值的成果。杜嘉忠等人[7]提出了一種基于領域專用情感詞的網絡評論情感分析方法,該方法通過構建并利用特征-情感詞本體對網絡上的產品評論進行情感分析。王曉東等人[8]在現(xiàn)有情感詞匯本體的基礎上,結合規(guī)則集和詞類組合模型提出了一種基于語料庫的情感詞匯本體擴展算法。劉麗珍等人[9]構建了產品領域情感本體,并利用領域情感本體的先驗情感知識消除情感詞的領域依賴性,有效識別了暗含的產品特征,能夠提高在線產品評論情感分析的性能。唐曉波等人[10]以情感詞典為基礎,根據手機產品特征及其評論特點,構建了手機產品領域的本體,并實現(xiàn)了手機產品特征的抽取、分類與情感分析。尹裴等人[11]從特征詞與觀點詞的語義關系入手,根據領域本體判斷特征觀點對的極性,并通過加權平均方法計算整個產品的極性。鄭麗娟等人[12]結合基于語義和基于統(tǒng)計的方法,通過抽取特征觀點對和觀點詞情感判斷,構建相應的情感本體,提出了一種基于情感本體的在線評論情感極性及強度分析方法。何有世等人[13]通過構建手機產品領域本體實現(xiàn)了產品屬性的提取與層次劃分,并提出了基于領域本體的產品網絡口碑信息多層次細粒度情感挖掘方法。
以上研究都偏向于用邏輯推理和情感計算的方法實現(xiàn)產品評論領域本體構建。相對其他方法,領域本體對于特定領域的網絡輿情分析、屬性詞提取和觀點抽取等內容更具專業(yè)性和針對性。除基于領域本體的情感分析方法外,還有基于情感知識的情感分析方法和基于機器學習的情感分析方法。
基于情感知識的方法通常使用一些已有的各類情感詞典、領域詞典以及主觀文本的情感極性組合評價單元對主觀文本的極性進行計算[14-17]。常用的知識有WordNet、情感屬性、位置屬性、關鍵詞屬性、詞性搭配關系等。盡管這一類方法可以較為充分地利用文本情感的先驗知識,能夠較好地解決規(guī)范性文本的情感分析問題,但由于忽視了文本分布的信息,所以容易出現(xiàn)經驗偏置,難以解決新興語言表達以及隱式表達的形式。
基于機器學習的方法一般是先采用機器學習方法對文本特征進行識別、提取和選擇,然后構建相應模型完成相關情感分析任務。Pang等[18]將n-gram詞語和詞性作為特征,分別采用樸素貝葉斯、最大熵和支持向量機等機器學習方法來解決文檔級情感分類的問題。基于機器學習的方法由于能充分利用文本特征的分布信息,對規(guī)范化和非規(guī)范化的文本都能有效處理,但容易忽略與情感相關的先驗語義特征,所以其分類性能仍存在較大提升空間。陳炳豐等人[19]通過構建汽車情感詞典,提出了基于條件隨機場模型的情感實體識別和情感傾向分類方法,結果表明該方法能夠應用于汽車領域的網絡輿情分析。
綜上所述,對于領域依賴性和屬性關聯(lián)性的產品網絡輿情分析研究來說,如果能將描述產品屬性和情感傾向的詞匯進行結合和映射,這樣或許能得到更準確的屬性評論傾向。基于此,文中針對汽車領域評論文本的網絡輿情分析,提出采用基于規(guī)則的方法構建“屬性-情感詞”本體,并以此識別汽車屬性及關于屬性的評論傾向,然后將該方法與觀點句識相結合實現(xiàn)汽車領域的網絡口碑信息的情感分析。
2 基于“屬性-情感詞”本體的汽車領域口碑情感分析方法
汽車領域網絡輿情分析是一個非常復雜的文本信息處理和建模的過程,在這個過程中不僅要構建領域詞典或本體,還需要借助機器學習方法構建相關的情感分析模型。在進行情感分析之前,首先需要獲取網絡論壇中的汽車產品評論,同時需要借助外部數據源收集并提取有關于汽車的屬性和專有名詞,然后利用數據預處理方法識別和提取評論中的屬性詞和情感詞,并提出基于四元組的“屬性-情感詞”本體構建方法,最后在上述過程的基礎上結合觀點句識別方法提出基于“屬性-情感詞”本體的情感分析方法。具體實現(xiàn)過程如圖1所示。
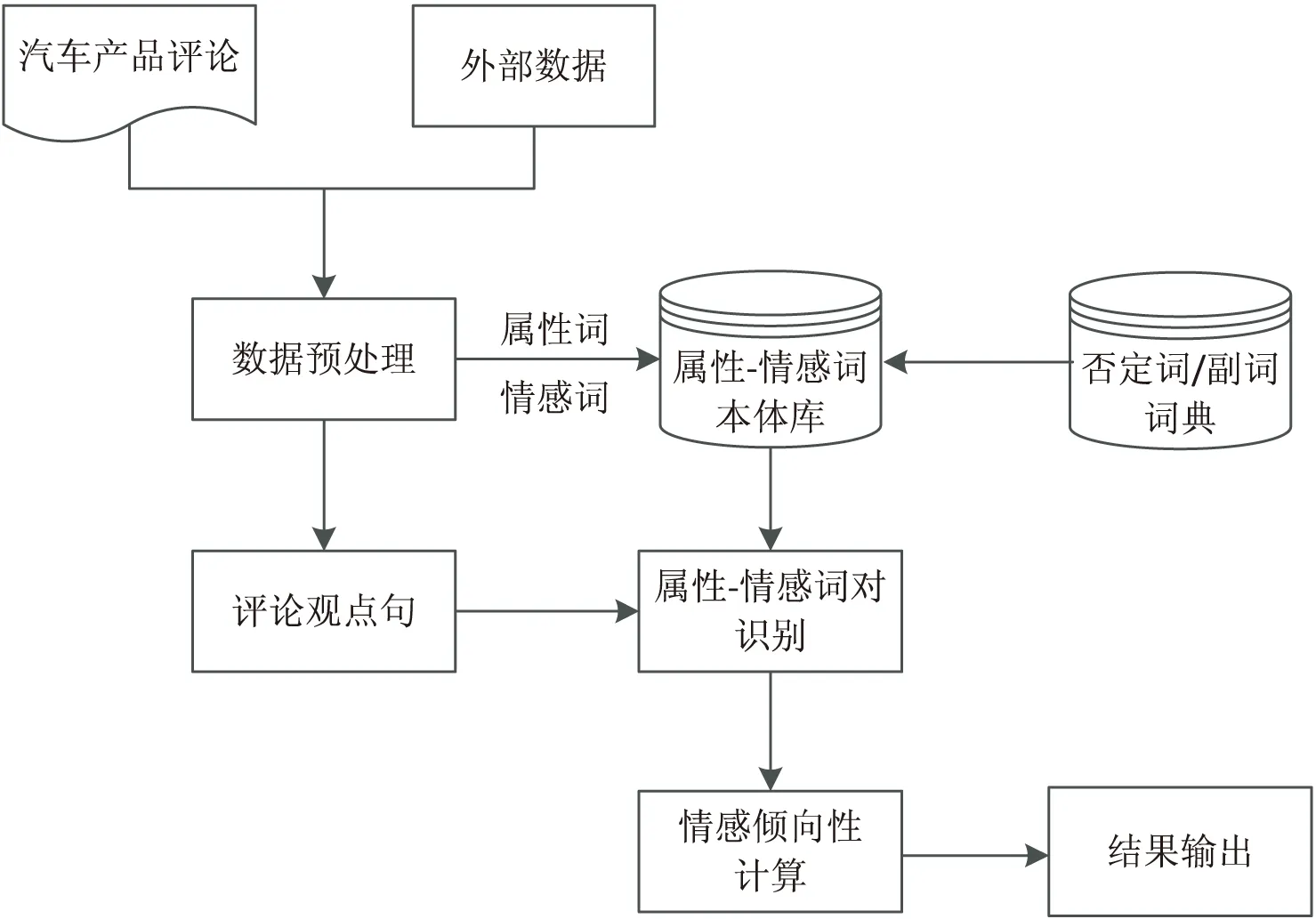
圖1 基于“屬性-情感詞”本體的汽車領域文本情感分析框架
如圖1所示,提出的基于“屬性-情感詞”本體的汽車領域網絡輿情分析方法主要包括三個過程:基于“屬性-情感詞”的本體構建、觀點句識別以及情感分析。
2.1 基于四元組表示的“屬性-情感詞”本體構建
文中構建的汽車領域“屬性-情感詞”本體是一個包含汽車屬性、情感詞以及情感極性的知識模型,可以將其定義為一個四元組,即:O={C,N,S,pol(N,S)},其中,C表示汽車屬性類別,如“性價比”、“油耗”等,N表示汽車屬性關鍵詞,如“質量”、“價格”等,S表示情感詞,如“上乘”、“寬敞”等,pol(N,S)表示屬性關鍵詞-情感詞對的極性,如“1”表示正向,“-1”表示負向。由該定義可知,“屬性-情感詞”本體可用于識別相同情感詞與不同產品屬性對象組合所表達出的情感極性。在具體實現(xiàn)過程中,可采用基于規(guī)則的方法構建“屬性-情感詞”本體方法(如圖2所示)。
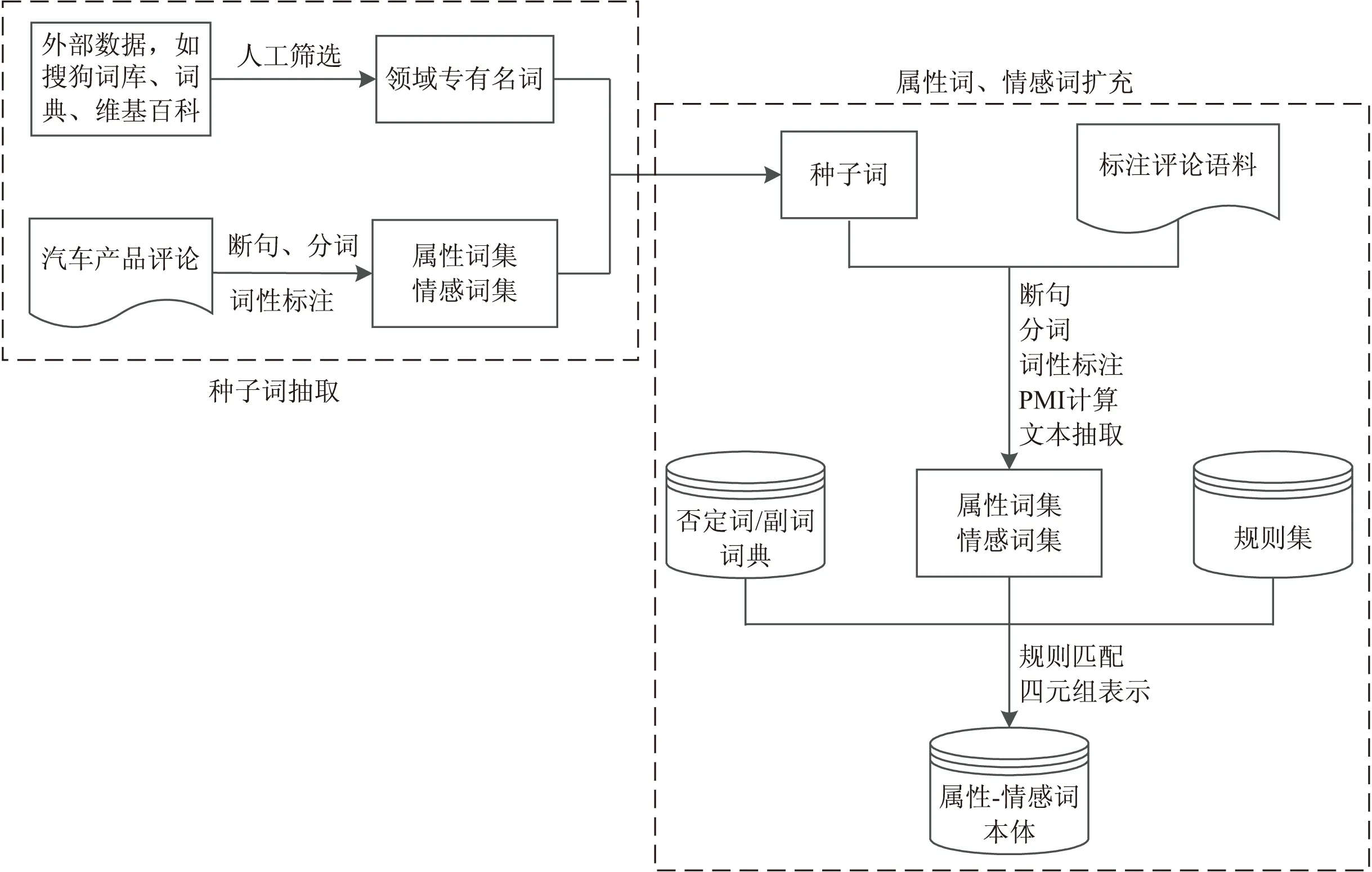
圖2 汽車領域“屬性-情感詞”本體構建流程
由圖2可知,汽車領域的“屬性-情感詞”本體構建過程主要包括兩大模塊:一是種子詞抽取,二是屬性詞、情感詞擴充。在種子詞的識別和抽取方面,一方面通過從企業(yè)官方網站、搜狗詞庫、微博、汽車門戶網站等相關資源中獲取汽車名稱術語及部件術語,構建汽車專有名詞本體庫;另一方面,從汽車之家論壇中采集已對操控、空間、動力、內飾、舒適性、外觀、性價比、油耗等八個方面進行評論的規(guī)范語料,并通過斷句、分詞、詞性標注、詞頻統(tǒng)計、文本抽取等處理過程形成屬性詞和情感詞的種子詞。在屬性詞和情感詞的擴充方面,首先選取一定數量的正負向語料作為訓練集,然后對訓練語料進行預處理(斷句、分詞、詞性標注、PMI計算、文本抽取),并結合否定詞/副詞詞典及相關規(guī)則匹配屬性關鍵詞-形容詞對,最終在進行四元組表示的基礎上形成汽車領域的“屬性-情感詞”本體。

表1 屬性關鍵詞-情感詞對匹配規(guī)則集
由“屬性-情感詞”本體的定義可知,該四元組既包含汽車屬性,也包含了描述該屬性的具體關鍵詞及其情感傾向。但在識別、抽取和判斷評論中的屬性關鍵詞與情感詞對的極性時,需要遵循如表1所示的規(guī)則:如果評論中存在否定詞,則根據否定詞數量對屬性關鍵詞-情感詞對的情感極性進行計算;如果評論中存在多個相同屬性的屬性關鍵詞-情感詞對,則對它們進行線性求和。最后,結合屬性關鍵詞的類別,得到“屬性-情感詞”本體的四元組O={屬性類別,屬性關鍵詞,情感詞,情感極性}。
2.2 汽車評論觀點句識別
由于汽車領域評論語料中包含大量客觀信息,這些信息并不表達用戶對汽車或屬性的評價。太多客觀信息會增加情感分析的工作量,也會影響情感分析的結果,因此在對語料進行情感分析前,需要對語料進行主客觀分類,即對評論語料進行觀點句識別。
針對汽車評論的觀點句識別問題,文中采用融合基于特征模板和基于SVM分類的觀點句識別方法,其主要過程包括:特征提取和SVM分類器構造。在識別觀點句之前,設計了如表2所示的特征模板,該模板包含兩個一元特征和三個二元特征,用于匹配和提取評論中的有用特征。
在基于特征模板的特征提取的基礎上,結合基于SVM分類方法構建觀點句識別模型。該模型的構建步驟如下:首先,對訓練語料進行斷句、分詞、詞性標注,并根據特征模板匹配并提取出訓練語料中的相關特征,同時利用向量空間模型將語料向量化;然后,利用Libsvm軟件中的C-SVC模型構造SVM分類器;最后,利用SVM分類器對測試語料進行觀點句識別。

表2 特征模板
2.3 情感分析
在“屬性-情感詞”本體構建和觀點句識別的基礎上,文中提出基于“屬性-情感詞”本體的情感分析方法。該方法主要是基于特征匹配和映射得出評論中的屬性關鍵詞-情感詞對,并以“屬性-情感詞”本體判定句子情感傾向性,其過程如下:
輸入:汽車評論語料、“屬性-情感詞”本體;
輸出:汽車評論情感分析結果。
Step1:對語料進行斷句(以句號、分號、感嘆號等作為斷句的依據)、分詞、詞性標注等預處理;
Step2:建立并利用規(guī)則對評論中情感詞進行識別,同時計算評論中屬性-情感詞對的情感極性;
Step3:識別并提取評論中的汽車屬性關鍵詞,并利用“屬性關鍵詞-情感詞”對匹配規(guī)則對屬性關鍵詞及其鄰近的詞語進行匹配;
Step4:若匹配成功,則提取相應的情感詞并根據“屬性-情感詞”本體規(guī)則構建四元組;
Step5:對語料中的所有句子按屬性進行情感極性累加,即對具有相同屬性的四元組進行分類求和。
在情感分析過程中,如果匹配過程中出現(xiàn)詞語情感極性無法判定的情況,則可以通過其與對應屬性關鍵詞在訓練集正負向語料中的共現(xiàn)頻率大小來判斷其情感極性。具體判斷規(guī)則如下:

3 實驗與結果分析
3.1 實驗數據
實驗中所用到的語料均來自于太平洋汽車網和汽車之家,且都是經由三名專業(yè)人員進行人工標注而成的。語料規(guī)模為3 200條評論句子,其中用于描述操控、空間、動力、內飾、舒適性、外觀、性價比、油耗等八個屬性的正負向語料各200條評論句子。
3.2 實驗過程
文中使用protégé工具包,通過從企業(yè)官方網站、搜狗詞庫、微博、汽車門戶網站等相關資源獲取汽車名稱術語及部件術語構建汽車評價對象本體庫。將汽車產品評論分為操控、空間、動力、內飾、舒適性、外觀、性價比、油耗這八個屬性,分別構建了這八個屬性的關鍵詞表,然后在此基礎上構建“屬性-情感詞”本體。下面以實驗中某個句子的分析處理為例,詳細說明提出的基于“屬性-情感詞”的情感分析過程(如圖3所示)。
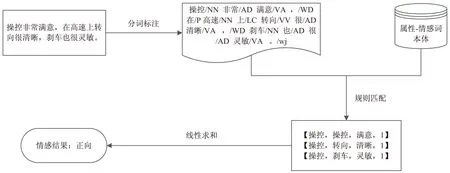
圖3 情感分析示例
3.3 評價指標
采用準確率、召回率和F1值來評價情感分析方法的性能,其計算方法如下:


3.4 結果分析
為了驗證提出方法的有效性,選擇經典的樸素貝葉斯方法作為對比算法。在實驗過程中,選取標注語料的三分之二作為訓練集,訓練出情感分類模型,剩下的三分之一作為測試集。表3列出了基于“屬性-情感詞”本體的情感分析方法和基于樸素貝葉斯的情感分析方法的實驗結果。

表3 對比實驗結果 %
從表3可以看出,提出的基于“屬性-情感詞”本體的情感分析方法比樸素貝葉斯情感分類方法的效果更好。這是因為,樸素貝葉斯分析方法忽略了與情感相關的先驗語義特征,同時也沒有結合語境進行分析,即沒有考慮到情感詞在不同的語境表達中可能會出現(xiàn)不同情感的問題。
而文中方法則可以將情感詞與特定的語境相結合,有效解決了情感詞在描述不同屬性關鍵詞時情感傾向可能不同的問題。例如:文中方法可以正確判別“空間大”為正向情感,“車內噪音大”為負向情感。但由于構建的本體規(guī)模不夠大,使用的規(guī)則不夠完善,該方法在召回率方面還有待改進。
4 結束語
隨著汽車行業(yè)的快速發(fā)展,不同汽車品牌的競爭日趨強烈。通過對用戶使用評論的分析和利用,對汽車企業(yè)的發(fā)展和走向有重要意義。但是,在大數據時代,用戶評論中存在大量噪音,使得企業(yè)對信息的獲取成本大大增加。在此背景下,期望通過基于屬性-情感詞本體的評論情感挖掘對汽車領域產品的八大屬性進行細粒度情感分析,從而給汽車企業(yè)與消費者帶來一定的參考價值。
但是,該研究目前還存在很多的不足。例如,在該方法中由于依賴人工方式構建本體和情感詞典構建的工作量非常大,所以屬性關鍵詞和情感詞的抽取準確率仍然有待提高;該方法在處理成分殘缺句子時的健壯性較差,導致評論分析的召回率比較低。
在未來的研究中,可考慮引入情感強度的計算,從而幫助解決成分殘缺句子屬性關鍵詞的匹配映射以及比較要素的抽取問題。
猜你喜歡
民用飛機設計與研究(2020年4期)2021-01-21 09:15:02
中國生殖健康(2020年5期)2021-01-18 02:59:48
北極光(2019年12期)2020-01-18 06:22:10
小太陽畫報(2019年10期)2019-11-04 02:57:59
電子制作(2018年18期)2018-11-14 01:48:24
中國生殖健康(2018年5期)2018-11-06 07:15:40
兒童時代·快樂苗苗(2017年7期)2018-01-24 18:28:45
山東工業(yè)技術(2016年15期)2016-12-01 05:31:22
作文大王·低年級(2016年4期)2016-04-18 00:24:37
決策探索(2014年21期)2014-11-25 12:29:50
