基于Nginx服務器的動態(tài)負載均衡策略
2020-08-17 09:04:40劉佳祎崔建明
桂林理工大學學報 2020年2期
關鍵詞:策略
劉佳祎,崔建明,智 春
(桂林理工大學 a.現(xiàn)代教育技術中心;b.繼續(xù)教育學院;c.信息科學與工程學院, 廣西 桂林 541006)
0 引 言
因特網的快速發(fā)展、人們的需求越來越多樣化,促使網絡技術不斷升級和優(yōu)化,進而導致服務器的并發(fā)訪問量和負載量呈指數級增加。由于服務器物理內存和CPU處理速度的限制,單一服務器的處理能力和負載能力無法滿足日益增長的網絡需求。服務器節(jié)點一旦發(fā)生故障,就無法保證為用戶正常地提供服務,甚至整個系統(tǒng)都有可能癱瘓,使得系統(tǒng)的可靠性和穩(wěn)定性無法得到保障。為避免發(fā)生上述現(xiàn)象,提出了服務器集群技術,多臺相互獨立的服務器組合了一個龐大的服務器集群,可解決大量并發(fā)請求所造成的負載過大、請求錯誤率高、響應速度慢等問題,實現(xiàn)系統(tǒng)的靈活性,進而滿足網絡需求[1]。
負載均衡技術通過運用相關算法將來自網絡中的高并發(fā)請求合理地分配給服務器集群中的節(jié)點,目前經典的算法有輪詢(RR)、 加權輪詢(WRR)、 最小連接(LC)、 加權最小連接(WCL)等[2-5]。隨著負載均衡技術的廣泛應用,國內外眾多學者對其進行改進并提出了一些新的算法。Xu等[6]針對原有的輪詢算法提出一種解決負載均衡問題的新輪詢優(yōu)化算法,該算法在負載范圍和負載方差方面有很大改進。文獻[7]中提出一種對負載信息評價的改進策略,來增強算法的局部搜索能力。為充分利用服務器的資源、縮小平均響應時間,孫喬等[8]提出了一種基于軟件定義網絡的分布式數據庫負載均衡算法。
針對多處理器來說,如何提高其性能、降低負載不均衡率成為學者們研究的重要問題。文獻[9]利用動態(tài)分配的任務中的線程數量來計算配置比率,從而為每個集群生成新的處理元數量。Singh等[10]提出的新方法優(yōu)點在于既保留了多路徑的優(yōu)點,又盡可能地保持其開銷接近單路徑路由。針對如何在原有加權輪詢策略上更好地提高集群性能這一問題, 文獻[11]提出一種基于服務器性能指標的能夠動態(tài)調整權重的負載均衡策略, 該方案使每個節(jié)點都可以分配到適合其負載能力的任務,進而提高集群的性能。
綜上所述,負載均衡技術占有重要地位,應用前景廣闊。本文針對Nginx服務器內置負載均衡策略的不足,進行優(yōu)化設計,提出一種基于Nginx服務器的動態(tài)負載均衡策略,該策略由3個模塊構成,并在算法調度模塊中給出了動態(tài)負反饋調度算法以及不同于傳統(tǒng)算法的度量指標。
1 動態(tài)負載均衡策略的模塊總體設計
負載均衡器是系統(tǒng)的核心,而負載均衡策略是其關鍵點。動態(tài)負載均衡策略的實現(xiàn)主要由負載采集、算法調度以及健康檢查3個模塊共同完成,其中算法調度模塊的核心算法又稱為動態(tài)負反饋調度算法。表1為各模塊的功能說明,用戶瀏覽器發(fā)送HTTP請求時,各個模塊工作流程如圖1所示。

表1 各模塊功能說明Table 1 Functional description of each module
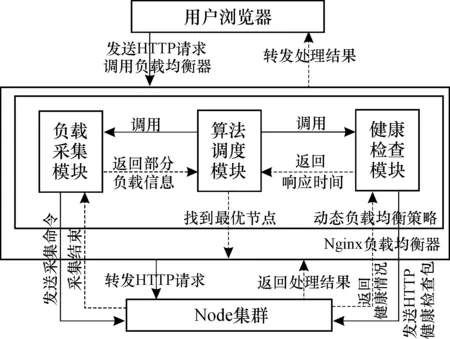
圖1 各模塊工作流程圖Fig.1 Workflow diagram for each module
當Nginx負載均衡器接收到用戶瀏覽器發(fā)送的HTTP請求時,會調用算法調度模塊。算法調度模塊根據采集到的負載信息通過計算找到最優(yōu)節(jié)點,并將其返回給負載均衡器,負載均衡器會將HTTP請求轉發(fā)給該最優(yōu)節(jié)點。負載采集模塊分為負載均衡器上的Server端以及后端節(jié)點上的Client端(本文主要介紹Client端),當Client端接收到Server端的采集命令后,開始采集服務器的負載信息,將其告知Server端。健康檢查模塊周期性地向后端節(jié)點發(fā)送HTTP健康檢查包,根據后端回復包的狀態(tài)碼來判斷健康狀態(tài),并記錄響應時間。服務器接收到HTTP請求后,進行相應的處理,并將處理結果返回給負載均衡器,并由負載均衡器轉發(fā)給用戶瀏覽器。
2 動態(tài)負載均衡策略中各模塊設計
2.1 算法調度模塊
2.1.1 動態(tài)負反饋調度算法設計整體思路 通過分析Nginx內置的輪詢round_robin和最小連接least_conn兩個算法可知, 算法中初始權重是由運維人員根據經驗而人工設置的, 并沒有考慮到服務器性能會隨時間不斷變化, 而least_conn算法雖然引入了連接數來間接地反映節(jié)點的負載情況, 但在處理長連接時會出現(xiàn)連接數不斷增多, 而服務器卻相對空閑的情況。 本文提出動態(tài)負反饋調度算法——dnfs_conn算法,引入負反饋機制對節(jié)點進行休眠和喚醒操作,進而提高服務器利用率,減少能耗。
對于本文算法,節(jié)點的選擇是其核心部分,算法調度模塊接收到連接請求時,會調用dnfs_conn算法獲取后端服務器集群的節(jié)點信息, 若當前負載小于自定義負載下閾值wL, 使用動態(tài)編程(dynamic programming)的方法快速遞歸找到休眠負反饋負載最小節(jié)點, 并將其放入休眠隊列; 若大于負載上閾值wH,則喚醒節(jié)點,繼續(xù)計算當前負載直到負載值在兩者之間為止;如果在上、下閾值之間稱之為理想負載,不進行處理。通過計算每個節(jié)點的負載值將節(jié)點排序,進而選出最優(yōu)節(jié)點,算法流程如圖2所示。
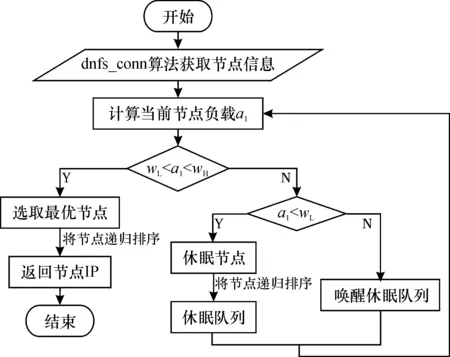
圖2 算法流程Fig.2 Algorithm flowchart
2.1.2 動態(tài)負反饋調度算法相關參數 本文算法的相關參數主要由能夠決定服務器承載能力的靜態(tài)負載因子(static load factor)、 由服務器運行狀態(tài)決定的、能夠反映其當前負載情況的動態(tài)負載因子(dynamic load factor)以及從歷史的性能數據中提取出來的統(tǒng)計類負載因子(statistical load factor)三大類組成。本文選用響應時間和連接數作為統(tǒng)計類負載因子。算法的相關參數說明見表2。

表2 相關負載因子Table 2 Relevant load factor
2.1.3 動態(tài)負反饋調度算法的度量指標 1)負反饋機制。 在控制系統(tǒng)中, 假設某一因素使系統(tǒng)趨于一種狀態(tài),另外一個因素使系統(tǒng)遠離該狀態(tài),如果兩者中有一種或兩種是非線性的影響,就會造成平衡點的出現(xiàn)。為減小節(jié)點的負載波動,引用負反饋機制,假設在tn-1時刻節(jié)點的平均負載為
(1)
其中,LCPU(tn-1)、LMem(tn-1)分別為測量所得到的CPU與內存的負載; 系數p為衡量不同應用中CPU和內存的影響;k為集群節(jié)點數。
在自動控制理論中, 為了使系統(tǒng)能自動適應工作環(huán)境、 任務的變化, 采用由牛頓二項式定理推出的公式——開方的反饋方法(自動調節(jié)開方)[12]自動改變自身結構、 參數等, 使系統(tǒng)始終保持穩(wěn)定的工作狀態(tài):
(2)
A=(x±y)i,
(3)
其中,X(m)為初始值;Q為開方次數;x是估計值;y是誤差值。A值通常接近于X(m), 故最終負載為
LOAD=LOAD(tn)+(LOAD(tn)-LOAD(tn-1))1/Q。
(4)
在現(xiàn)有的負載模型中同時考慮CPU與內存,運用二維向量取模運算。 同時,為衡量不同應用中CPU和內存的不同影響, 引入系數p。 設集群中一個節(jié)點j的負載向量為Lj=〈LCPUj,LMemj〉,LCPUj、LMemj分別為節(jié)點j測量所得CPU和內存負載,當有k個節(jié)點時, 所有節(jié)點在時刻tn的平均負載為
(5)
可知,LOAD(ti)可取值范圍為(0, 1),p的取值根據系統(tǒng)應用而定。
2)抖動系數。 抖動現(xiàn)象指在負載變化較大時, 頻繁地啟動/暫停某一個節(jié)點引起的現(xiàn)象。 若同一節(jié)點多次遷移, 將會嚴重影響性能。 因此,如何減少抖動現(xiàn)象的發(fā)生是當前的首要任務。 本文算法先計算每個節(jié)點的實時負載
(6)
為了增強系統(tǒng)穩(wěn)定性,考慮節(jié)點抖動系數k
(7)
其中: Δt為一個時間周期。k越大,穩(wěn)定性越差, 則加入抖動系數后的負載為
LOADN(tn)=k×LOAD(tn)。
(8)
3)時間跨度。參考文獻[13], 預設在0—T的時間段可分為等長的時間間隔,k段間隔的定義為{(t1-t0),(t2-t1),…,(tk-tk-1)}。由此可知,Tn表示的時間跨度是(tn-tn-1)。
4)k段時間內節(jié)點的平均CPU利用率
(9)
其中,pCPUTn是CPU在Tn時間段的平均利用率。 按照這種方式節(jié)點的內存利用率也可以計算。
5)響應時間TR。 設每個請求均在一臺服務器上進行, 則有
TR=sjtj,
(10)
其中,sj是服務器的請求次數,tj是請求j的處理時長。
6)服務器利用率φ。 設連接數為i時其穩(wěn)態(tài)概率為πi,πc+i為最大連接數時的穩(wěn)態(tài)概率, 則
(11)
其中,c為最大連接數。
7)吞吐量δ。吞吐量作為衡量服務器性能的重要指標, 可直接展現(xiàn)整個服務器處理連接請求的能力, 用λ表示服務率, 可表示為
(12)
2.1.4 dnfs_conn動態(tài)負反饋調度算法 根據算法的設計思路給出具體實現(xiàn)過程的偽代碼如下:
1.輸入:所有節(jié)點的CPU和內存信息
2.初始化:給每個節(jié)點設置特定名字
3.do
4.通過管理節(jié)點,對各工作節(jié)能點根據式(5)統(tǒng)計計算得到運行平均負載a1
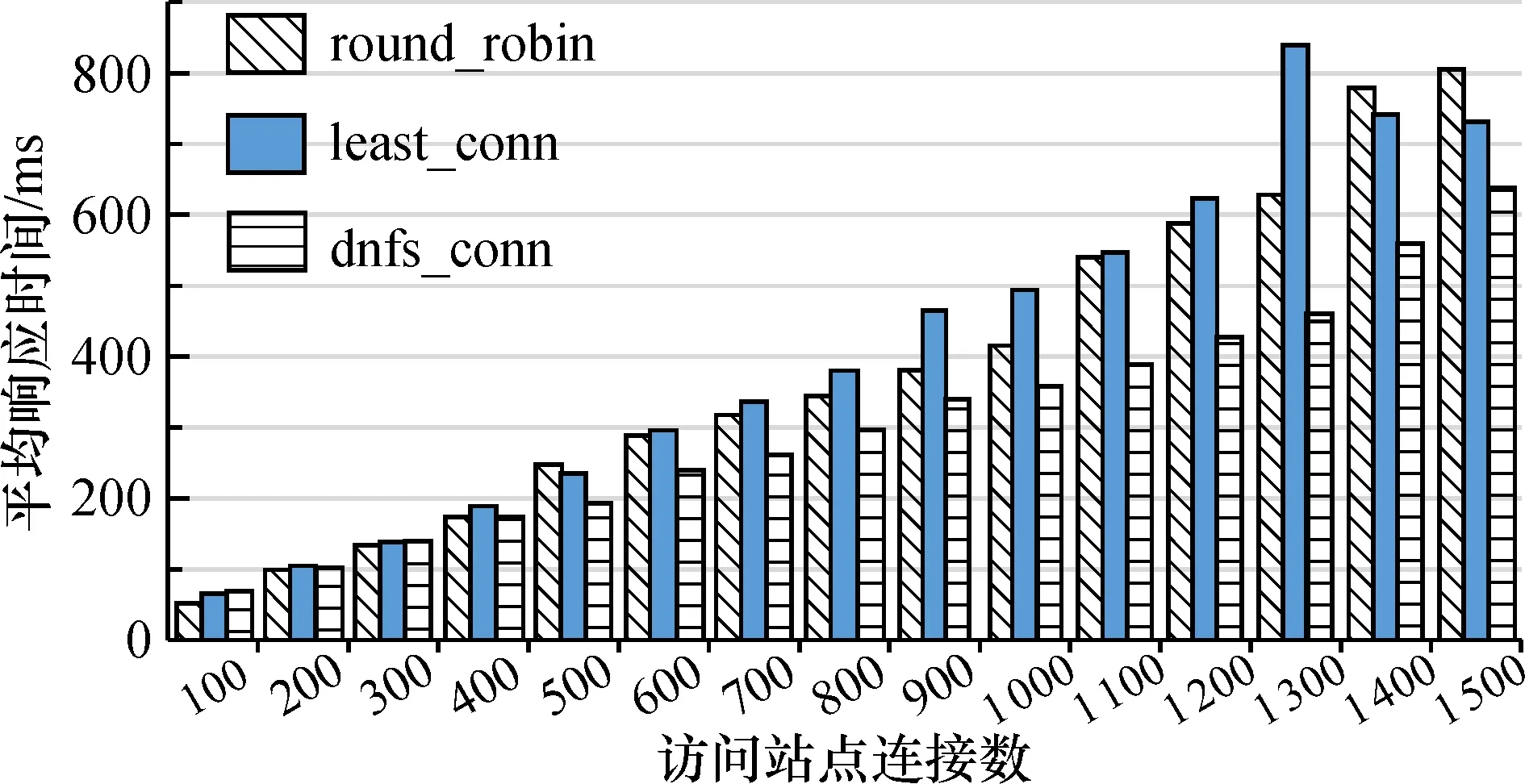
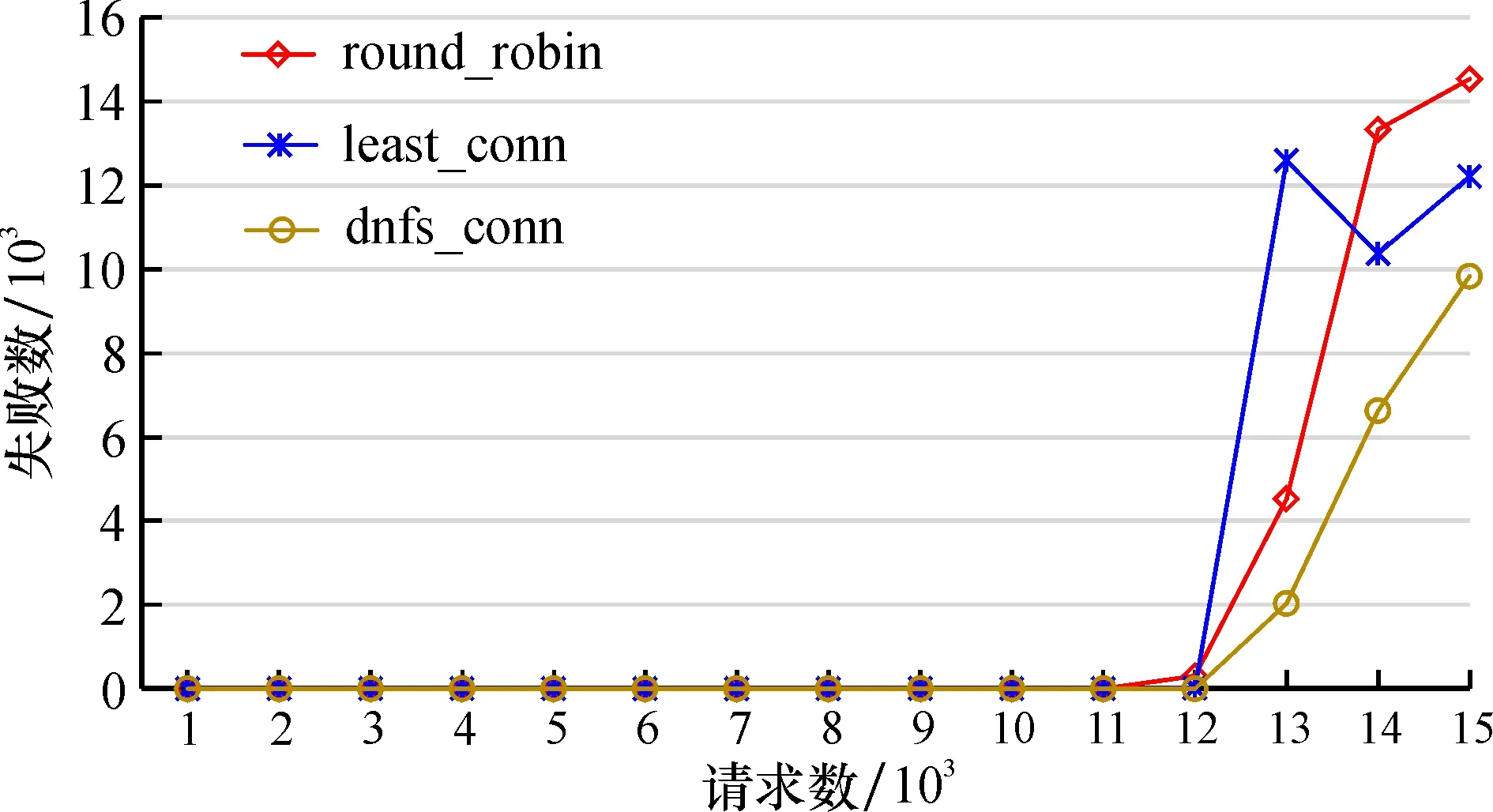
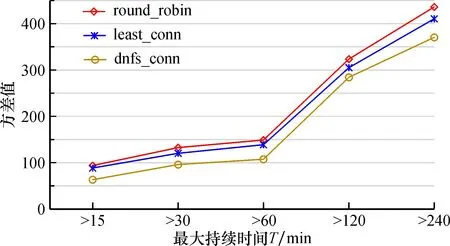
5.IfwL 6.繼續(xù)執(zhí)行操作 7.else ifa1 8.將每個節(jié)點根據式(8)計算其負反饋負載并升序排列 9.將得到的負反饋負載節(jié)點休眠并放入休眠隊列,直到滿足wL 10.end for 11.else 12.將休眠隊列中的節(jié)點喚醒,直到wL 13.end if 14.end do 15.輸出:最佳節(jié)點 本文主要介紹客戶端Client上的負載采集,主要使用node.js開發(fā),通過os模塊獲取系統(tǒng)參數,編寫utils模塊,用于進行數據處理。 2.2.1 靜態(tài)負載因子采集 由2.1.2節(jié)可知,通過計算靜態(tài)負載因子SLF可以得到服務器的承載能力,因此定義getSLF方法用于采集SLF。通過os模塊獲取CPU核心數、主頻以及內存容量,代碼如下: let getSLF=function (){ let slfCPU=os.cups()[0].speed * os.cups().length; let slfMEM=os.totalmem(); return {slfCPU,slfMEM} } 2.2.2 動態(tài)負載因子采集 動態(tài)負載因子的采集相對靜態(tài)的復雜一些,當node.js執(zhí)行shell命令時所花費的時間是無法有效統(tǒng)計的。因此,使用node.js來執(zhí)行shell腳本文件,以解決上述問題。將采集動態(tài)負載因子分為3部分,代碼如下: 1)getDLF將整個采集過程調用并接收結果, 代碼如下: let getDLF=function (){ let [dlfCPU,dlfMEM]=[getDlfCPU(),getDlfMEM()]; return {dlfCPU,dlfMEM} } 2)getDlfCPU通過執(zhí)行cpu.sh腳本來獲取CPU利用率,代碼如下: function getDlfCPU(){ let dlfCPU=child.exeFileSync(’./cpu.sh’).toString(); return dlfCPU; } 3)getDlfMEM內存占用率計算,代碼如下: function getDlfMEM(){ let slfMEM=os.totalmem(); let dlfMEM=(slfMEM-os.freemem())/slfMEM; return dlfMEM;} 2.2.3 周期采集負載信息 客戶端采集負載信息具有周期性,調用setInterval方法可以在每隔time秒更新一次負載信息,核心代碼如下: let collectTimer=setInterval(()=>{ updateLoadInfo(); },time * 1000); function updateLoadInfo(){ let [SLF,DLF]=[collect.getSLF(),collect.getDLF()]; ({slfCPU,slfMEM}=SLF);({dlfCPU,dlfMEM}=DLF); L=a-cpu*dlfCPU+a-mem*dlfMEM; } 將由淘寶Tengine團隊開發(fā)的nginx_upstream_check_module模塊添加到nginx的源碼目錄中用于檢測后端節(jié)點的健康狀況。使用該模塊時,只需要在upstream塊中添加check指令即可,配置如下: upstream backend{ dnfs-conn; server 192.168.201:80; server 192.168.202:80; server 192.168.203:80; check interval=3000 rise=1 fall=5 timeout=1000; } 為了測試本文提出的dnfs_conn算法在高并發(fā)時負載均衡能力, 在內網環(huán)境下選擇lawrence livermore national laboratory(LLNL)的數據在CPU 2.5 GHz、 8 G內存、 Ubuntu16.04操作系統(tǒng)的平臺上用Apache HTTP服務器進行實驗, 測試需要創(chuàng)建5臺云主機組成的集群, 以及一個專有網絡VPC(Virtual Private Cloud),其中, 1臺云主機作為Nginx負載均衡器, 3臺云主機作為Web服務器, 1臺云主機作為測試機對系統(tǒng)進行測試。 通過不斷增加并發(fā)連接數來測試連接失敗數和平均響應時間,驗證本算法的可行性及優(yōu)越性并與Nginx內置的round_robin、 least_conn這兩種算法的結果進行比較。 根據式(5),設系數p為0.6, 上下閾值wH、wL分別為0.7和0.3, 在同一時刻訪問服務器站點連接數1 500、 請求數15 000以下且最大持續(xù)時間超過15個時隙的情況下完成平均響應時間、 請求失敗數以及負載均衡度的對比結果如圖3—5。 圖3描述了3種算法在同一時刻服務器站點連接數即并發(fā)數在1 500以內的變化情況。對于round_robin算法, 連接數達到1 100以后, 平均響應時間瞬間增加后趨于平穩(wěn); least_conn算法的平均響應時間在并發(fā)數1 300時忽然增加到區(qū)間內的最高值; dnfs_conn算法平均響應時間逐漸增加且始終要低于Nginx內置的其他兩種算法,以上表明本文提出的算法在處理高并發(fā)數的連接時明顯優(yōu)于其他算法。 圖3 平均響應時間對比Fig.3 Comparison of average response times 圖4展示了3種算法在請求數為15 000以內時失敗次數的對比情況。可以看出,在算法執(zhí)行過程中,當請求數增加到12 000以后,雖然3種算法均出現(xiàn)失敗現(xiàn)象,但在相同并發(fā)數下發(fā)出相同請求數時,dnfs_conn能夠成功處理的請求數較其他兩種算法有明顯的提高, 能夠快速響應服務請求, 表明本文所提出的算法要優(yōu)于Nginx內置的round_robin和least_conn算法。 圖4 請求失敗數對比Fig.4 Comparison of request failures 針對負載均衡度的對比,采用方差∑(LOADN-LOAD)2的形式, 其中LOADN為LOADN(ti)在周期內計算的平均值,LOAD為LOAD(ti)在周期內計算的平均值。為體現(xiàn)統(tǒng)計性,分別進行5組測試來求算數平均值,比較結果如圖5所示。 圖5 方差值對比Fig.5 Comparison of square difference 可知,在最大持續(xù)時間大于60 min后,3種算法的方差值有明顯的增長現(xiàn)象,但無論最大持續(xù)時間在15 min還是240 min,round_robin和least_conn兩算法的方差值相差不大; dnfs_conn算法由于每次選取節(jié)點的抖動比較小,進而使節(jié)點負載方差值明顯小于前兩者。 在分析Nginx服務器的內置負載均衡策略基礎上,提出一種帶有動態(tài)負反饋調度算法——dnfs_conn算法的動態(tài)負載均衡策略, 其中dnfs_conn算法將動態(tài)、 靜態(tài)以及統(tǒng)計類等負載因子綜合考慮, 并引入負反饋機制對節(jié)點進行休眠和喚醒操作, 進而提高服務器利用率, 減少能耗。 針對3種負載均衡策略的調度算法進行模擬實驗, 將測試結果進行對比分析后發(fā)現(xiàn)本文提出的負載均衡策略比Nginx內置的round_robin和least_conn負載均衡策略有更好的均衡效果。2.2 負載采集模塊
2.3 健康檢查模塊
3 實驗與結果分析
4 結束語
猜你喜歡
教學考試(高考化學)(2021年2期)2021-05-30 06:15:52中學生數理化·七年級數學人教版(2020年12期)2021-01-18 06:57:42中學生數理化·高一版(2020年3期)2020-04-21 08:03:20中學生數理化(高中版.高考理化)(2020年2期)2020-04-21 05:32:50小學生作文(低年級適用)(2019年9期)2019-10-08 08:37:10小學生作文(低年級適用)(2018年9期)2018-10-08 02:29:48中學生數理化·七年級數學人教版(2018年6期)2018-06-26 08:36:10數學大世界(2018年1期)2018-04-12 05:39:14幸福(2017年18期)2018-01-03 06:34:53中國衛(wèi)生(2016年8期)2016-11-12 13:26:50
