基于特征選擇與隨機森林混合模型的社區惡意評論檢測研究
2020-08-19 06:18:24唐洵湯娟周安民
現代計算機 2020年19期
唐洵,湯娟,周安民
(四川大學網絡空間安全學院,成都 610225)
0 引言
當今,網絡社交平臺上的每個用戶都可以閱讀、發布和分享信息,網絡傳播特性使得信息能夠以前所未有的速度向大量受眾傳播,數十億人的生活因此產生革命性的影響。伴隨著移動互聯網的普及,人們在社交網絡上所花費的時間與精力也日益增多,安全問題也日益嚴重。大多數人都在試圖保持網絡的安全性和可用性,這類用戶屬于良性的、正常的用戶,與之相對,有部分用戶試圖發表影響網絡平臺可用性的反社會行為,如仇恨言論,人身攻擊和網絡欺凌[1-3],這些被網絡平臺所禁止的評論通常由釣魚者或噴子(Troll)發表,而且近些年的研究表明,普通人在特定情況下,也會發表惡意評論。
針對惡意評論的早期研究是定性的,學者通常對少數人工識別出的惡意評論的典型案例進行深入研究。在這一階段的工作中,一般認為這是一種具有反社會行為的特殊言論。Buckels[4]在2014 年的研究中提到,惡意評論利用“熱點問題”讓用戶在某種程度上變得過于情緒化、偏激乃至失去理智。故而,惡意言論可以被視為“網絡社區負面行為”。Dlala[5]認為惡意言論故意對討論的主題進行隱晦的誤導,以挑起爭議,擾亂討論,達到讓普通用戶偏離討論主題的目的。Cheng[6]等人在這之后研究了發帖、評論、點贊行為與社區不良行為的關系,他們對被社區禁言的用戶進行異常行為分析,發現其異常行為傾向于集中在少數幾個主題上,能夠吸引更多用戶的關注響應。他們以時間為軸,對用戶行為按照從加入社區到被禁止的演變過程進行分析,惡意言論發布者的語言水平會持續降低,且社區對其容忍程度也呈下降趨勢。同時隨著社區對其管控嚴格化,不良行為反而會因此加劇,所以Cheng 等人提到對惡意用戶的識別應該放在其行為初期,避免后期的不可控行為。他們另一項研究[7]表明,社區中的負面情緒會給社區帶來持續性的負面影響,而積極情緒并不具備類似效應,因為大多數社區并不會對發表積極內容的用戶采取獎勵行為,所以用戶也不會有進一步提高文章質量的積極性。
在檢測言論中惡意行為這一方面,Kumar[8]對Slashdot 社區中的惡意評論進行研究,其惡意行為對社區的信息完整性進行了破壞,由此他們針對Slashdot社區開發了一種通用算法TIA(Troll Identification Algo?rithm),將在線注冊用戶分為惡意或良性,進而對惡意評論進行檢測。在Hardaker[9]的研究中,分析了不同類型惡意評論的特征。Kim[12]通過分析用戶的屬性和代表性行為,如注冊日期、重復轉發和行為跟蹤等來檢測惡意用戶。Risch[10]組合多個常用特征,其實驗表明組合特征的檢測效果明顯優于單一特征。Cambria[11]等人使用帖子中的語義和情感分析進行惡意行為檢測。而Chen[13]等人使用詞匯句法特征分析并檢測惡意行為,包括用戶行文風格、結構和特定網絡欺凌等內容。而在最近的研究中,Cheng,Justin[7]的文章中認為,用戶的前置情緒和帖子的討論情景是用戶是否會產生惡意評論的重要預測因素,用戶近期的發布歷史表明情緒會從先前的討論中延續過來,過去的惡意評論可以預測未來的惡意言論行為。
本文使用爬蟲收集了一組中文社區中用戶的歷史發言數據。在Cheng,Justin[7]的研究基礎上,提取出實驗數據中有關不良情緒和上下文環境的相關特征。本文使用LASSO 回歸,發現部分特征的相關系數較小,因此結合主成分分析法(PCA)對特征進行降維,并采用隨機森林算法建立模型,發現在線討論社區中的惡意評論,得到了87.0%的準確度。實驗結果表明,本文采用的模型對惡意評論具有良好的檢測效果,為凈化社區環境提供了技術支持。
1 惡意評論檢測模型
1.1 檢測模型框架
本文的惡意評論檢測模型如圖1 所示,該模型主要包括三部分:數據特征提取模塊、PCA 特征降維模塊、隨機森林檢測模塊。本文使用Python 爬蟲獲取到原始數據集,經過人工分析后,對數據進行清洗及預處理。根據過去的研究,模型從評論數據中提取出每個評論的特征向量,使用PCA 降維,提取出測試使用的特征集向量。原始數據將被隨機分為70%的訓練數據集和30%的測試數據集,最后使用隨機森林算法進行訓練,將評論數據分類為正常評論以及惡意評論。
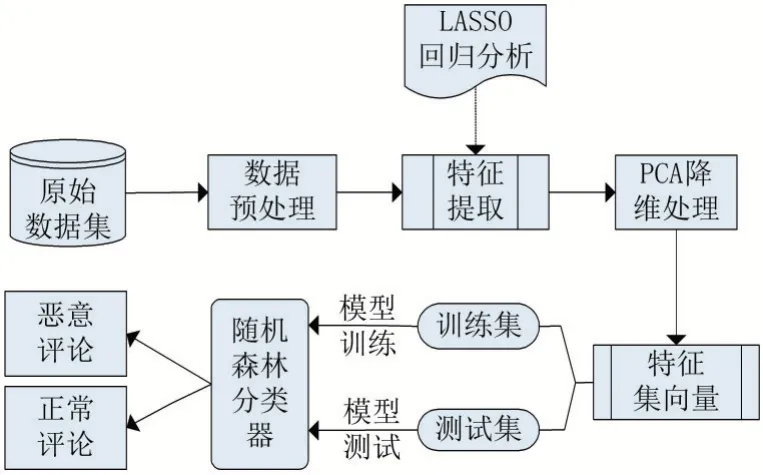
圖1 惡意評論混合檢測模型
1.2 檢測模型特征
經過分析,本文采用的數據集中的46,036 條被刪除的評論多數由未被禁用用戶所發表的。在最新的研究中,Cheng、Justin[7]指出:惡意評論更多可能是由于情景而導致的,并非天生。研究者認為對于普通用戶而言,負面情緒和討論背景都會增加用戶發布惡意評論的可能性。因此,本文根據數據集的特征,選用了以下8 個特征作為基礎特征集,對惡意評論進行檢測。
●情緒特征:
Cheng、Justin 基于情緒做了三個方向的特征研究。認為用戶的惡意評論會隨著早晚,工作日和周末的轉換而變化;憤怒的情緒會帶來更多的惡意評論;而隨著時間的增加,用戶的負面情緒會逐漸降低。
根據上述研究,本文提取出以下四個特征值:
(1)周時間:評論一周內所處的發布時間點;
(2)天時間:評論一天內所處的發布時間點;
(3)前置被標記時間:用戶上一條帖子的標記情況;
(4)治愈時間:用戶上一條被標記帖子與當前帖子的發布時間差。
●討論環境特征
Cheng、Justin 基于討論環境做了三個方向的特征研究。認為如果新聞下的第一條評論被標記,會對后續的討論產生一定影響;如果評論所在的子討論中的首條評論被標記,會對后續的子討論產生影響;在一個子討論中,被標記評論的數量和位置,會對整體子討論產生影響。
根據上述研究,本文提取出以下四個特征值:
(1)首標記:評論所處的新聞中,新聞下首條評論的被標記情況;
(2)根標記:評論所處的新聞中,評論所在的子討論中,根評論的被標記情況;
(3)評論位置:當前評論所處的位置;
(4)被標記數量:在這之前被標記的評論數量。
1.3 PCA降維處理原理概述
PCA(Principal Components Analysis)即主成分分析技術,旨在利用降維的思想,把多指標轉化為少數幾個綜合指標,是一種非監督的機器學習方法。PCA 可以降低算法開銷,通過降維發現更容易理解的特征,增加訓練過程中對有效信息的提取處理,使數據集更容易被使用。
設周時間為W,天時間為D,前置被標記時間為Pt,治愈時間為 Ht,首標記為 Ff,根標記為 Rf,評論位置為P,被標記數量為N。則本文所采用的特征數據集I 為[W,D,Pt,Ht,Ff,Rf]。
LASSO(The Least Absolute Shrinkage and Selection Operator)回歸也稱之為線性回歸的L1 正則化,該回歸可以使常量系數變小直至為0 值,因此特別適用于參數數目縮減和參數的選擇。本文采用LASSO 回歸對特征集的變量進行篩選。通過對特征數據集進行LASSO 回歸處理,得出其對應相關度為[-0.32,-0.69,17.07,0.10,31.81,-2.10,3.01,2.77],并由此觀察到該特征數據集中有三項特征的相關度低于1。于是采用PCA 算法,設置k 值為5,對原有的八個特征進行降維處理,以保證其特征信息的有效性。
算法流程如下:
步驟1 計算對應特征值的平均值并減去。
步驟2 求出特征協方差矩陣。
步驟3 求出協方差矩陣的特征值和特征向量。
步驟4 將特征值按照由大到小的順序排列,保留其中最大的k 個特征值,生成新的特征矩陣。
步驟5 將實驗數據轉換至上述k 個新特征構建的向量空間。
1.4 隨機森林算法概述
隨機森林算法是以集成學習思想為基礎,由多棵決策樹整合而來的分類算法,其每棵決策樹都是一個分類器,隨機森林集合所有分類投票結果,故其表現要優于單一的決策樹。其算法流程如下:
步驟 1 特征數據集 I=[W,D,Pt,Ht,Ff,Rf]由PCA 降維得到的實驗特征集 Ip=[i1,i2,i3,i4,i5]。
步驟2 以隨機選取5 個特征中的2 個特征作為分裂點,其度量標準為基尼系數度量,以備選點的最小值作為最優分裂點的評判標準,公式如下:

步驟3 根據上一步驟的計算方式,逐個計算每一個屬性的最優分裂點,對比不同分裂點的基尼系數,以最小屬性并發生成多棵決策樹。
步驟4 對多棵決策樹的值進行投票并選出最終結果。
2 實驗結果與分析
2.1 實驗數據
本文通過Python 爬蟲,采集并清洗了來自社區chouti.com 的公開數據,包含來自8,869 名用戶的3,450,059 條歷史發言記錄。之后對采集到的原始數據進行了細致的檢查和分析,發現原始數據中存在部分無效內容及數據重復等問題。因此本文對原始數據進行了清洗和預處理,以保證數據的準確性,最終獲得46,036 條被標記為“該評論已被刪除”的數據。實驗將未被刪除的數據標記為0,被刪除的數據標記為1,使用Sklearn 實現PCA 降維和隨機森林算法。
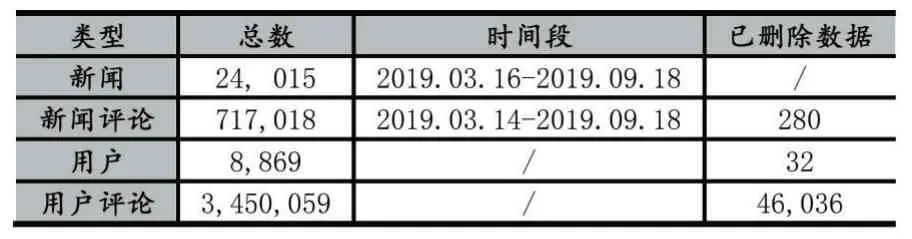
表1 數據集概述
2.2 評估指標
本次實驗的評估指標采用以下四種:
TP:真陽性(True Positive),將正常評論預測為正常評論的數量;
FP:假陽性(False Positive),將惡意評論預測為正常評論的數量;
TN:真陰性(True Negative),將惡意評論預測為惡意評論的數量;
FN:假陰性(False Negative),將正常評論預測為惡意評論的數量。
性能評估使用準確率(A),召回率(R),精確率(P)和召回精確率調和平均數(F1)。
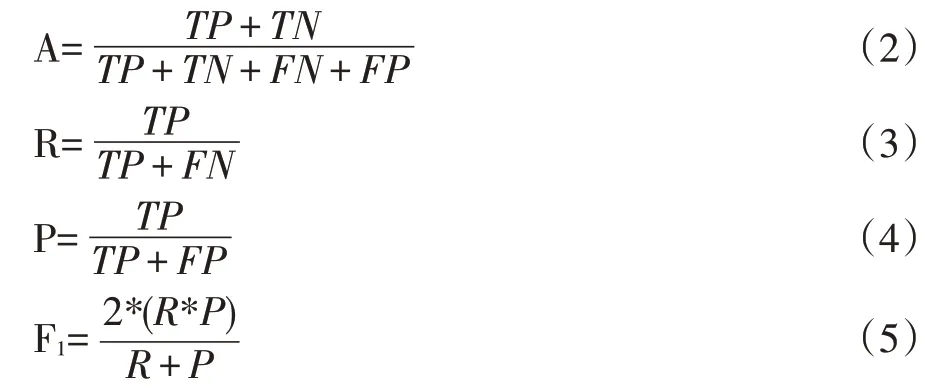
2.3 實驗結果分析
根據上述特征,本文使用了三種不同的機器學習算法(支持向量機、KNN、隨機森林)對惡意評論進行檢測,實驗結果如表2、圖2 所示。
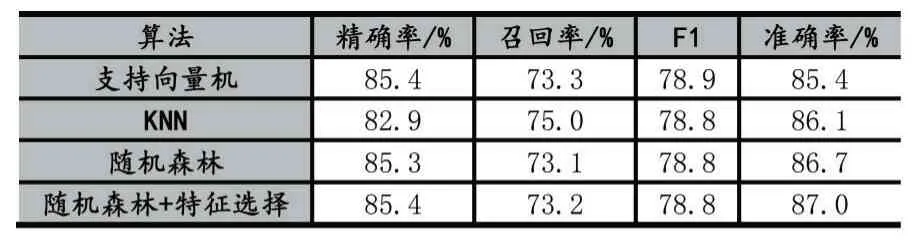
表2 算法性能對比
對比支持向量機、KNN 和隨機森林算法的實驗結果,可以觀察到三種算法的精確率和召回率各有高低,但隨機森林在準確率上要高于其他兩種算法,故隨機森林算法的檢測性能最佳,準確率為86.7%。所以本文選擇隨機森林與特征選擇相結合的混合模型,實現進一步的性能提升。從表中可以看到,隨機森林和特征選擇相結合,可以得到85.4%的精確率、73.2%的召回率以及87.0%的準確率,三項指標較之單一的隨機森林均有提升效果。
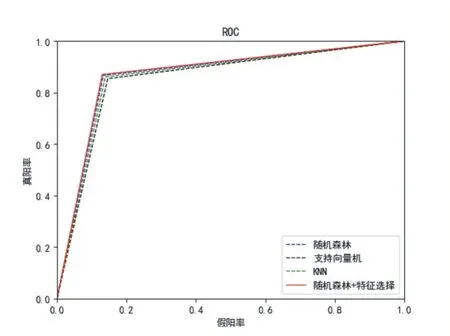
圖2 ROC曲線
3 結語
中文社區評論中的惡意行為相當豐富,且屢禁不止。在大多數網站的評論區中,可以觀測到用戶不友善的溝通與交流。因此,本文希望借由此項研究去發現如何檢測中文社區中的惡意評論。根據最新的研究,本文提取出數據集中被標記數據的8 個特征,在進行LASSO 回歸分析后,發現其中三項特征屬于弱特征。基于以上研究結果,論文采用PCA 對特征進行降維處理,最終結合隨機森林算法對惡意行為進行了檢測。檢測結果表明,結合了PCA 的隨機森林算法模型要比單獨采用隨機森林算法的準確度高,本文提出的模型可提高惡意評論的檢測準確度。
猜你喜歡
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當代陜西(2019年10期)2019-06-03 10:12:04
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
商用汽車(2016年11期)2016-12-19 01:20:16
商用汽車(2016年6期)2016-06-29 09:18:54
海峽科技與產業(2016年3期)2016-05-17 04:32:12
商用汽車(2016年4期)2016-05-09 01:23:12
