基于垂直集成Tri-training的虛假評論檢測模型
2020-09-04 10:00:26尹春勇朱宇航
計算機應用 2020年8期
尹春勇,朱宇航
(南京信息工程大學計算機與軟件學院,南京210044)
0 引言
隨著電子商務和社交網站等網絡平臺的興起和快速發展,越來越多的用戶頻繁地在這些平臺上進行瀏覽、社交、購物等網絡行為,并且為了分享各自的體驗和觀點,用戶發布了大量的評論來展現自己[1]。在其他用戶瀏覽文章或商品等發布的信息時,評論具有相當大程度的導向作用。有些用戶僅僅根據發布信息下面的評論決定自己的觀點,而忽略了關注發布的信息本身,這在電子商務中尤為可見。
在網絡購物時,由于商品實體與購買者分離,店家給出的信息并不完全可信,而他人的評論代表著其購買商品后的實際使用體驗,購買者通過閱讀這些商品評論可間接獲取所買商品的體驗信息,以此來判斷商品是否值得購買。然而,隨著商品評論越來越能決定用戶的購買決策,以及網絡平臺缺乏可信評論的篩選機制,虛假評論也就應運而生。虛假評論是指評論者為獲取某些利益發布不符合客觀真實經歷的評論,而且這些評論對于商品有極端情感的傾向(比如過分吹捧或過分詆毀)。電子商務網站中的虛假評論日趨増多,這不僅會給消費者傳遞錯誤信息,降低用戶體驗;同時也容易給商家造成不必要的經濟損失。而識別出虛假評論并采取相應的措施處理會提升評論的整體可信度,指導消費者做出正確的購買決策[2]。由此可見,有效識別電子商務網站中的虛假評論已成為一項急需解決的任務。
2008 年,Jindal 等[3]首次提出了虛假評論檢測這一問題,指出由于虛假評論的高度混淆性導致其檢測尤其困難。Jindal等[4]在分析了亞馬遜網站的評論之后,總結出了最有可能是虛假評論的三原則,并以此來標注評論。最初的虛假評論檢測是利用詞袋特征和詞性特征來對評論進行語法上的分析[5-6],并且在某些數據集上取得了良好的效果。然而,文獻[7]中的研究表明,使用情感等文本特征來區分虛假評論的效果并不顯著,因為在故意偽造的評論中,這些評論的文本特征并不能明顯識別虛假評論。在測試時增加評論者的特征,檢測效果可能會得到一些提升。隨后,虛假評論檢測添加了評論者、評論者群體的特征[8-11],從用戶方面來識別虛假評論。除了特征提取部分之外,訓練算法對檢測效果也有很大影響。虛假評論檢測可以被視為文本分類中的一個二分類問題,將評論分類為虛假評論和真實評論。用于虛假評論檢測的分類算法包括貝葉斯分類、決策樹分類、支持向量機(Support Vector Machine,SVM)分類和隨機森林[12-17],其原理是在訓練集中學習一個目標函數,該函數將每個樣本矢量映射到預定義的類型標簽。聚類算法是將相似的評論分到一個類中,并且不同的類之間的差異盡可能大[18]。神經網絡也因深度學習的興起而逐漸應用于文本分類中,利用反向傳播來修正輸入層傳遞到輸出層的結果與預期結果不一致的錯誤[19-21],實現實際輸出值與預期輸出值之間的統一。神經網絡的不足之處是在訓練階段時需要提供大量的文本和相關類別信息,以此來保證訓練的準確度。
目前,虛假評論檢測雖然有了快速的發展,但也面臨著諸多技術上和非技術上的難題和挑戰[22-24]。虛假評論檢測技術面臨的挑戰主要體現在以下兩個方面:1)大規模有準確標記的樣本難以獲取;2)人工選取的特征難以完全表示文本語義。
因此,針對面向標記樣本規模受限的虛假評論檢測問題,半監督學習利用帶有標簽的未標記樣本來增強分類效果,因此它是解決標記樣本過少的一個有效方法。其代表性算法有協同訓練、PU 學習(Positive Unlabeled learning,PU learning)等[25-27]。協同訓練要求數據具有兩個足夠冗余且滿足條件獨立性的視圖,同時兩個視圖對于類別標記是獨立的。協同訓練被應用在社交網絡小規模標記樣本中的虛假評論檢測[28]。評論文本特征、評論者特征和評論對象特征構成三個視圖,虛假評論檢測可依據其中的兩個視圖進行協同訓練。在文獻[29]中,模型首先訓練具有少量標記數據的原始分類器,然后在社交圖形傳播中建立信任和不受信任的順序,并選擇由分類器判斷的可信用戶和其排序評分為新的訓練數據,然后重新訓練分類器,檢測效果比常規的協同算法更好。Gilad 等[30]提出了一種基于垂直集成的Co-training(Vertical Ensemble Cotraining,VECT)算法,利用保存協同訓練算法各個迭代過程中的分類器權重共同標記樣例,并在最后全部集成到最終分類器中,以此來解決標記數量過小的識別問題,在多個文本分類數據集上的檢測效果都優于傳統Co-training算法。
為解決虛假評論檢測中由于樣本標記過少而影響檢測效果的問題,本文提出了一個基于垂直集成Tri-training(Vertical Ensemble Tri-training,VETT)的虛假評論檢測模型,該模型主要是結合評論文本特征和評論者的行為特征這兩種特種作為特征提取,而后通過VETT 算法來分類評論。在初始樣本中標記樣本過少時,VETT 算法過程利用Tri-training 以往迭代的分類器模型先訓練各自在這輪迭代的3 個分類器模型,然后通過標記樣本選擇置信度較高的樣本數據來修正3 個分類器權重,以此來提高標簽標記的準確率。
1 相關工作
1.1 虛假評論檢測模型
如圖1 所示,面向標記規模過小的一般虛假評論檢測模型分為特征提取和半監督學習兩個部分。特征提取主要是從原始數據中獲取能夠檢測出虛假評論的特征,這些特征主要是經過分詞處理后的文本特征,而評論者特征、評論對象特征可以有選擇地加入。其中評論文本特征是評論內容中所蘊含的信息,而評論者的特征為評論發布者的一些行為特征和其自身信息。評論對象特征指那些評論的主題,比如商品和事件內容。而在檢測方法中主要是通過利用半監督學習算法來區分真假評論。

圖1 面向標記規模過小的虛假評論檢測模型Fig. 1 Fake review detection model for small labeling scale
電子商務中的虛假評論檢測常用的特征有商品評論特征、用戶行為特征和商品信息特征三類[31-37]。
1.1.1 商品評論特征
如表1 所示,商品評論特征是評論文本信息間接或直接計算而得來的屬性值,主要包括情感極性、評級矛盾、一致性、人稱比例、評論文本長度、商品評論文本相似度、歷史評論文本相似度等。

表1 評論文本特征Tab. 1 Review text characteristics
情感極性表達主觀信息,如人們的意見、立場和情感,反映人們的情感趨勢。情感極性分為積極情感極性和消極情感極性。與正常評論相比,虛假評論往往具有異常的情緒表達,即過分贊美和惡意詆毀。情感極性的計算方法通常通過文本中的情感詞數量的加減來實現。
1)評分偏離性SD(Score Deviation)。此特征表示了某條評論的評分與商品整體評分的偏差程度。在電子商務中,用戶給商品的評分包含商品評分f1、物流評分f2和服務評分f3三種,同時商家店鋪也有這三種整體的平均評分ft。SD越大,表明評論者給出的評分與整體評分的距離越遠,評分與其他評論者的評分趨勢越偏離,評論越有可能是虛假評論;相反地,SD值越小,給出的評分越符合其他評論者的平均打分習慣,評論也趨于真實性。計算公式如式(1)所示:

2)一致性CES(Consistency of Emotional bias and Score)。此特征指評論文本的情感偏向EB(Emotional Bias)與評論所得評分以及平均評分S的偏差程度,兩者偏差越小,評論與評分一致性就越高,評論越可能是真實的。計算公式如式(2)所示:
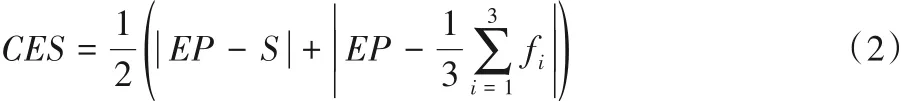
3)人稱比例PR(Person Ratio)。此特征指評論文本中出現“我”第一人稱的次數與出現諸如“你”“它”“他”等人稱的次數的比值。虛假評論發布者通常喜歡使用第一人稱來偽造評論,以此來增強評論的代入感,迷惑消費者的判斷。計算公式如式(3)所示:

其中:f_n表示第一人稱的出現次數,o_n表示其他人稱出現的次數,分母加1是為了避免分母為零。
4)評論文本長度。即評論文本字符數,它計算的是評論文本中的字符數,但不包括標點符號。
5)商品評論文本相似度PRS(Similarity of Product Reviews)和歷史評論文本相似度HRS(Similarity of Historical Reviews)。也就是說,當前評論類似于當前商品的所有評論或評論者的所有歷史評論的文本的相關程度。文本的相似性越大,表明評論越有可能是通過復制或部分修改形成的虛假評論。PRS和HRS的計算公式如式(4)和(5)所示:

其中:p_r是評論商品的所有評論;h_r是當前評論者的所有歷史評論;r是當前評論;l是當前評論的長度;sim()函數是相似度計算函數,可用余弦相似度來計算。
1.1.2 用戶行為特征
此類特征包括評論者的個人信息和在此平臺發布評論的一系列網絡行為等。由于虛假評論者試圖模仿真實評論的描述來干擾檢測結果,用戶的行為特征從側面能反映出虛假評論者的異常行為,能在一定程度上識別評論的真假。這類特征主要包括評論頻率、用戶信譽級別、個人信息完整度、評級標準偏差、不同產品的評分差異等,如表2所示。

表2 評論者行為特征Tab. 2 User behavior characteristics
1)評論頻率。指評論者在一個時間單位中發布的評論數量。評論者發表評論的頻率越大,評論者就越有可能是水軍。
2)用戶信譽級別。其他用戶接受該用戶的評論越多,可信度越高,真實程度越高。
3)評論者個人信息的完整性。評論者個人信息越完整,他就越有可能是真實用戶,而個人信息太少的用戶更有可能是虛假評論發布者。畢竟,個人信息越完善,發布者的真實信息就越能確定。
4)評論者的標準偏差。評論員用于給商品打分的歷史評分以計算標準偏差。虛假評論者給商品的評分很極端,標準偏差過大;普通用戶的歷史評分相對穩定,因此標準差相對較小。
5)不同產品評論的評分差異。普通用戶給出的分數往往波動很小,而虛假評論者的分數通常比較極端,無論是高分還是低分,都形成了兩級分化趨勢。
1.1.3 商品特征
這類特征包括該商品的評論數、平均評分、商品信息等,通常與上述兩類特征有緊密的聯系,故不單獨使用。
1.2 傳統的Tri-training算法
半監督學習主要是有效地利用少量標記數據和大量無標記數據來訓練分類器。Blum 等[38]提出了一個由兩個分類器協同工作的Co-training 協同算法。它使用兩個分類器協同訓練標記數據,由某個分類器訓練的標記數據添加到另一個分類器的標記數據集中,以此訓練這個分類器,并重復這個過程直至兩分類器再無區別。Co-training算法必須滿足這一假設:數據屬性具有兩個充分冗余的視圖。但一般來說,數據難以滿足具有兩個充分冗余視圖的要求。不過研究者提出了一種Tri-training 算法[39],它不需要完全冗余的視圖或不同的分類算法,而是通過在原始數據集中利用隨機采樣bootstrap 方法來獲取3 個數據子集,并且訓練出3 個分類器,就可以確保分類器之間的差異。Tri-training使用3個分類器,以便通過簡單的投票規則確定可被信任的標記數據。詳細情況是:對于未標記數據x,如果Ci和Cj對于x的標記是相同的,那么就把x及其標記y加入到Ck(k≠i,j)的標記訓練數據集中。
由于簡單投票將噪聲引入了第三分類器,因此在Tritraining 算法中增加了一種控制條件,以確保噪聲環境中分類誤差率的收斂。考慮學習數據集錯誤率ω與訓練數據集容量m的數據噪聲速率之間的關系如式(6)所示:

其中:c為一個常量。
如果要確保ωt<ωt-1(t為迭代次數),則在訓練期間必須滿足式(7):
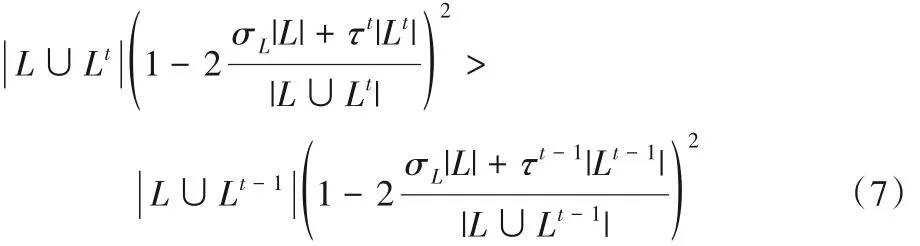
其中:Lt表示在第t次迭代期間前兩個分類器要添加到第三個分類器的標記數據;τt是Lt的標記錯誤率;σL是L上的噪聲數據程度。
很顯然|Lt|>|Lt-1|,那么通過進一步細化獲得的約束如式(8)所示:

因此τt<τt-1而且|Lt|> |Lt-1|。為了確保式(8)為真,有時需要提取Lt的子集作為新添加的標記集。
2 基于VETT的虛假評論檢測模型
針對標記樣本比未標記樣本小得多的情況,本文提出一種基于VETT 的虛假評論檢測模型,具體的模型示意圖如圖2所示。首先,模型需要對原始數據進行預處理,主要過程是整理原始數據集并刪除不符合實驗的數據。然后通過特征提取獲得目標數據集。目標數據集可以視為特征屬性數據集,這對于訓練的分類器和后續檢測非常有用。在此步驟中,數據集中的評論文本和用戶屬性將在數字上進一步量化,以滿足測試的需要。在特征工程過程中,該模型采用用戶行為特征和評論文本功能的混合特征作為目標數據集的屬性集。最后,通過VETT 算法對目標數據集進行訓練,以檢測評論中的虛假評論。
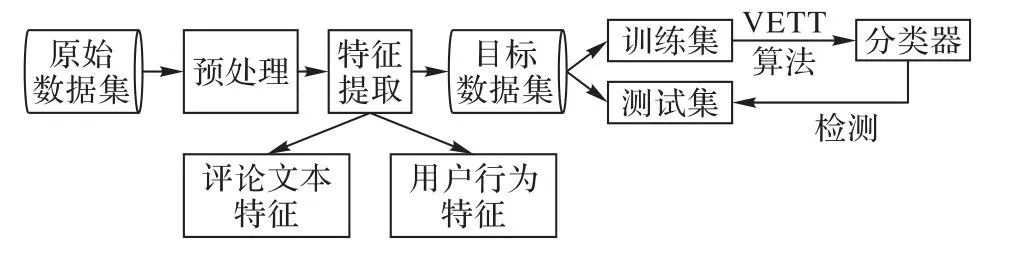
圖2 基于VETT的虛假評論檢測模型Fig. 2 Fake review detection model based on VETT
在特征工程中,比較正常用戶和虛假評論發布者的評論數據,不難發現這種情況:作為正常用戶,在決定要購買產品時,必然會在電商平臺中搜索產品,平臺會給出關于該產品銷售的相關信息(如價格、銷售來源),用戶瀏覽這些相關產品(如品牌或性能),然后比較這些不同來源的相似產品,最后做出購買決策,發布自己的意見;相反,虛假評論者并無此購物前的商品比較過程,只是在下單購買時與正常用戶相同,但多數不會瀏覽其他相似的產品,否則會增加成本。因此,用戶瀏覽某種產品及其同類產品的歷史記錄是一項重要的特征。
針對這種情況,本文提出一種新的用戶行為特征——商品瀏覽度,并給出了其計算方法。商品瀏覽度定義為:在發布商品評論之前的一段時間內,用戶瀏覽類似商品的歷史記錄與之前查看關于該產品所有歷史記錄的比值。在發布真實的商品評論之前,用戶不可避免地會瀏覽其他與該商品類似的產品,因此用戶的商品的歷史瀏覽記錄尤為重要。商品瀏覽度PBR(Product Browsing Relevance)計算公式如下:

其中:T 表示在特定時間段內購買商品前的天數,Ni表示與第i 天瀏覽類似商品的瀏覽記錄數,Mi表示在第i 天瀏覽購買商品的記錄數。由于用戶在電商平臺上只要購買成功,瀏覽該商品的歷史記錄必然存在一次,因此分母不存在零值。PBR值越大,越有可能是真實評論;反之,PBR 值越小就越有可能是虛假評論。
Tri-training 存在兩個缺點:第一個缺點是標記樣本集中添加太多未標記的樣本可能會嚴重影響性能。產生這種情況的原因有錯誤標記的樣本、標記樣本集訓練的分類器之間差異不大、分類模型造成少量樣本過于穩定等。第二個缺點是,Tri-training 訓練過程中生成的最終分類模型不會以任何方式來利用迭代過程中創建的各種分類器所代表的知識。這之所以成為一個問題,不僅是因為分類器迭代時丟失的信息依然具有可用性,還因為這些模型是作為Tri-training 訓練過程的一部分生成的,使用它們沒有額外的成本。
因此,本文提出一種基于垂直集成的改進Tri-training 算法(VETT)。該方法認為,Tri-training 迭代過程生成的模型仍然具有有用的檢測性能,即使迭代更新的模型標記錯誤,以前的迭代模型也可以糾正錯誤標記。在傳統的Tri-training 迭代過程中,3個分類器只要其中2個分類器標記一個數據為相同標簽,就將其交予第三個分類器的訓練集中,即不考慮第三個分類器對于該數據的標記情況,這樣便會導致未標記數據被錯誤標記的情況。Tri-training 的迭代過程更像一種集成器,標注樣例服從少數服從多數的策略。而分類器的差異性越大,標注樣例的準確度就越大。所以參與集成的各種分類模型需要提供關于數據集實例的標簽的不同置信水平。文獻[30]中,研究者發現連續迭代的分類器精度有顯著的波動,即迭代的模型之間具有差異性;而且選擇額外實例的不同策略對Co-training 算法的性能有顯著的影響。尤其對于決策樹這樣的分類器來說,這些變化更為顯著,決策樹利用特征的層次順序,每個屬性具有特定的分割點。以此類推,在Tri-training算法中,3 個分類器模型在數次迭代后,各自的精度都會逐步提高,這就與其在迭代過程中生成的迭代模型有了差異性。如果在3 個分類器迭代前,分類器首先與其以往迭代的分類器模型確定自己分類可信度最高的樣例,可以減少分類器之間的噪聲干擾,減少錯誤標記。因此,本文提出利用以往迭代的模型來減少Tri-training迭代過程中產生的錯誤標記。
如圖3 所示,在Tri-training 訓練的迭代過程中,先訓練初始的3個分類器,而后先用傳統的Tri-training訓練并保存各個分類器迭代中的分類器權重。這一步是先產生一個分類器的以往迭代模型,為之后利用分類器與其歷史迭代模型之間的多樣性來確定自身訓練集高信任度的樣例作準備。3 個分類器的歷史分類模型各自至少需要3 個(奇數個并且少數服從多數),這樣才能判定自身訓練集的樣例標簽。
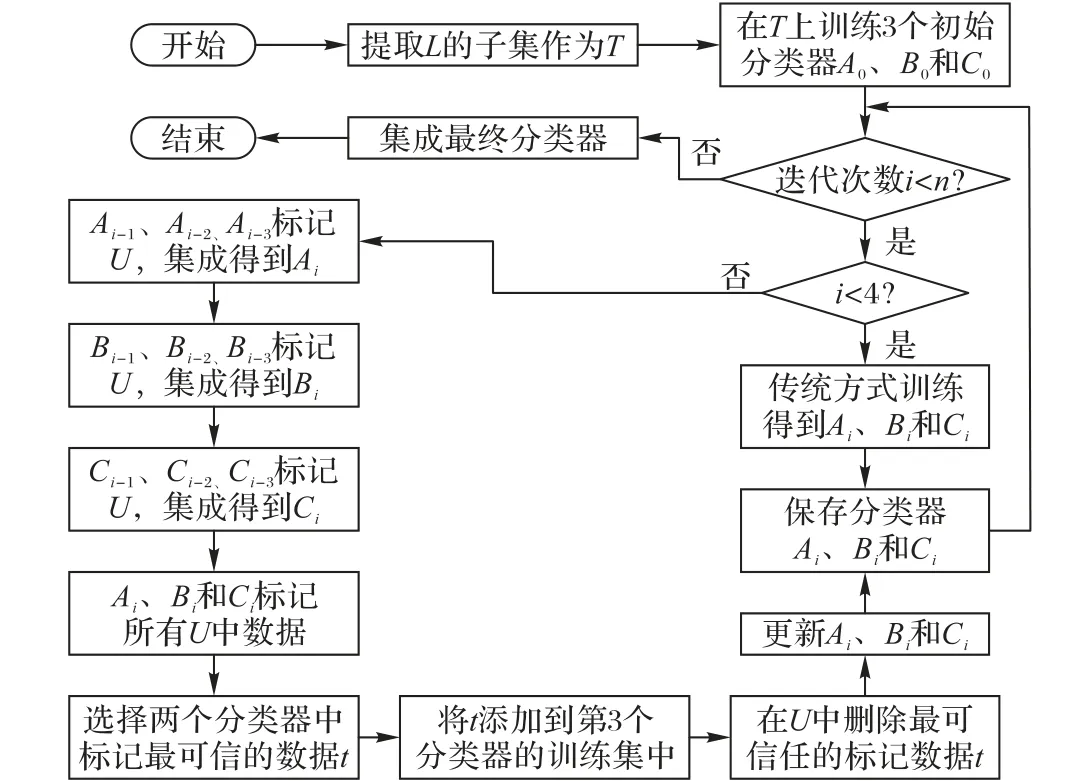
圖3 VETT算法的流程Fig. 3 Flowchart of VETT algorithm
然后是本文的垂直集成策略,主要分為兩步:組內垂直集成和組間水平集成。組內集成是分類器Mi先由其之前的迭代模型訓練集成而成(即將之前的迭代模型一起作為一個組訓練,即等效于一個小型集成分類器),圖3 中Ai是將之前的三次迭代模型在其訓練集TA上訓練集成。在某個迭代過程中,一個分類器的3 個往上迭代的歷史分類模型通過在這個分類器的訓練集上尋找到一致確認的高信任樣例,將其標注后放入到訓練集中,并且交由上一次迭代模型訓練成此次迭代的分類器。
組間集成是對于組內集成后的3 個分類器對未標記的數據進行標注,在兩個分類器標注一致的樣例放置到第3 個分類器的訓練集中,然后3 個分類器在自身的訓練集中依次訓練,得到本次迭代的最終分類器,保存更新這3 個分類器權重。最后在迭代完之后,集成為一個最終分類器。
具體的VETT算法如下:
輸入L(標記集),U(未標記集),n(迭代次數),AI(迭代選擇的索引),V(驗證集)。
輸出ET(擴展訓練集),M(最終分類器)。
初始化ET=L,AI= 0。
第一步 在L上利用bootstrap 抽樣方法選出3 個初始訓練集Tj(j=A,B,C),并通過分類算法I訓練得到3個初始分類器A0、B0、C0。
第二步 如果i<n或者U≠?時,繼續第三步,否則跳至第七步。
第三步 如果i<4時,跳至第五步,否則繼續第四步。
第四步 若i≥ 4,Si(S=A,B,C)由其以往迭代過程的3個分類器Si-3、Si-2、Si-1在訓練集Tj上集成而得,Si-3、Si-2、Si-1標注U中的數據,將3 個分類器都標注相同的樣本數據{x,y}(x為數據,y為標簽)訓練集Tj中,同時將U中標記的最可靠數據{x,y}添加到ET中,在新的訓練集Tj中訓練得到分類器Si。
第五步Ai、Bi、Ci標注U中的數據,將其中兩個分類器標注相同的樣本數據{x,y}放置到第3 個分類器的訓練集Tj中,同時將未標記集U中3 個分類器標記的最可靠數據{x,y}添加到ET中(更新U和ET)。
第六步 在新的訓練集Tj中訓練得到3 個分類器Ai、Bi、Ci,保存其分類器權重,集成分類器M,并在V上驗證性能Vi,如果Vi<Vi-1,則意味著此次的分類性能比上一次迭代中的分類性能差,把它還原到上一次的訓練迭代中(即AI的值減去1),跳出至第七步;否則,AI值加1,轉回第二步。
第七步 結束訓練。
本文算法只是在傳統的Tri-training 算法迭代過程中加入了分類器以往迭代過程中的分類模型,利用連續迭代過程中分類器與其迭代模型所產生的差異性來解決3 個分類器之間的噪聲干擾。從算法的空間復雜度來看,VETT 除了Tritraining 的空間開銷外,由于要保存分類器之前迭代的分類模型,需要占用額外的存儲空間來保存這些分類權重。不過這個開銷是固定的,因為每次迭代,算法只保存此次迭代的最終分類器權重,同時更新之前該分類器往上的四組迭代權重。相當于一個數組包含5 個元素,每次迭代完,所有元素的位置前移一位,將此次迭代的最終結果放置在第5個位置。3個分類器就相當于3 個數組。因此,這個空間開銷是固定的,即為O(1)。算法的空間復雜度來看,額外的時間開銷主要是在一個分類器的以往迭代模型做集成標注時產生的。該分類器的權重首先由上一次的分類模型通過本次迭代最近以往3 次的迭代模型獲取置信度最佳的樣例訓練得到,即迭代過程中分類器的權重計算總共有兩次;而傳統的Tri-training 只有一次,就是在3 個分類器之間標注的時候。因此VETT 的算法開銷為O(T(ET) +T(HT)),其中T(ET)表示迭代模型集成標注的代價,T(HT)是指經典的Tri-training 在其迭代過程中的代價。由于每次迭代時,分類器都會對所有未標注的數據進行一個標記,還有一個置信度的值。如果保存每個分類器的前p個置信度較高的正例和q個置信度比較高的反例,那么無疑T(ET)的開銷就會大幅度減少。可以添加一個固定的緩存池來存儲迭代過程的分類模型所對應的前p+q個置信度較高的未標記數據的標注情況,這樣能減少迭代模型再次計算標注情況的時間。
3 實驗與分析
3.1 數據集
實驗中使用的數據集包括黃金數據集[40]和Amazon 商品數據集[41],以及美國點評網站Yelp 上收集到的兩個數據集YelpChi和YelpNYC[42]。
Li 等[40]使用眾包平臺獲取評論數據集,數據集中的評論來自于芝加哥地區的酒店評論。他們收集了400 條被定義為正面和積極的虛假評論,以及從登錄網站收集和處理的400條真實評論。這些評論共800條。
Amazon 數據集包含580萬條評論、214萬用戶和670萬個產品,涉及3個領域的書籍、音樂DVD和工業產品。數據的標簽采用基于規則標注的方法來標記,其優點是基于規則標注的方法不依賴于人工,標記的成本低,很容易獲得大量的標簽數據,不足之處是會包含一定的噪聲。表3 顯示了Amazon 數據集的特定屬性。

表3 Amazon數據集的數據格式Tab. 3 Data formats of Amazon dataset
在點評網站Yelp 上收集到的兩個數據集都是關于餐館和酒店服務的用戶評論。YelpChi 數據集是在美國芝加哥收集的部分餐館和酒店評論,包含67 395條評論,其中虛假評論有8 916 條;YelpNYC 數據集是紐約地區的餐館評論,總計359 052條評論,包括36 875條虛假評論。
3.2 實驗評價標準
為了全面衡量本文方法的有效性,基于精度和召回率兩個指標,將F1 值作為度量虛假評論檢測性能的最終評價指標。精度P(Precision)、召回率R(Recall)和F1值(F1-Score)的公式如下所示:
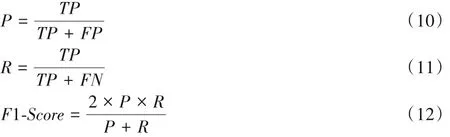
其中:TP指正確識別的虛假評論數量,FP為錯誤標識為真實評論的虛假評論數,TN作為檢測正確的真實評論數量,FN指的是被誤認為是虛假評論的真實評論數量。
3.3 實驗結果分析
對于每個數據集,20%用作測試數據,80%用作訓練數據。實驗中未標記的樣本數據占整體的比率設置為60%,特征的選擇為混合特征(評論文本特征和用戶行為特征)。針對黃金數據集中數據量太小的情況,實驗使用10 折交叉驗證方法。對于Amazon 數據集和Yelp 兩個數據集,隨機抽取40%作為標注數據,并進行了10 次實驗。與本文算法比較的檢測方法包括傳統的 Co-training、Tri-training、基于 AUC(Area Under Curve,AUC)優化的 PU-learning(PU learning based on AUC,PU-AUC)[43]和 VECT[30]。表 4 是不同方法的虛假評論檢測效果對比。
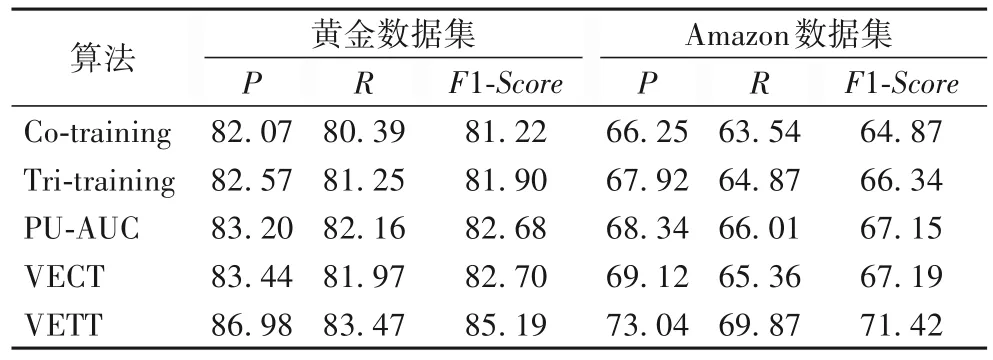
表4 黃金數據集和Amazon數據集上不同算法的性能對比 單位:%Tab. 4 Performance comparison of different algorithms on gold and Amazon datasets unit:%
從表4 中可以看出,在黃金數據集中,每種算法的檢測效果都遠遠高于Amazon數據集中的檢測性能,產生這種情況的原因是真實環境中的評論更為復雜,遠非簡單地能被人為區分。本文的VETT算法在黃金數據集上的檢測性能指標F1值比傳統的 Co-training、Tri-training 的 F1 值分別高了 3.97 個百分點和 3.29 個百分點,同時也比 PU-AUC、VECT 算法的 F1 值分別提高了2.51、2.49 個百分點。而在Amazon 數據集中,本文的VETT 算法的F1值更是分別比Co-training、VECT 的F1值提高了大約6.5、4.2 個百分點。而在表5 中,本文的VETT 算法在YelpChi 和YelpNYC 數據集的性能最優。在YelpChi 中,VETT 分別比 Co-training、Tri-training、PU-AUC、VECT 提高了4.94、3.83、2.17、1.83 個百分點;而在 YelpNYC 中,VETT 也比其他四個算法分別高了4.72、3.48、1.62和1.45個百分點。這說明了本文提出的基于VETT 的虛假評論檢測模型在標注規模受限的情況下依然有較好的分類性能。
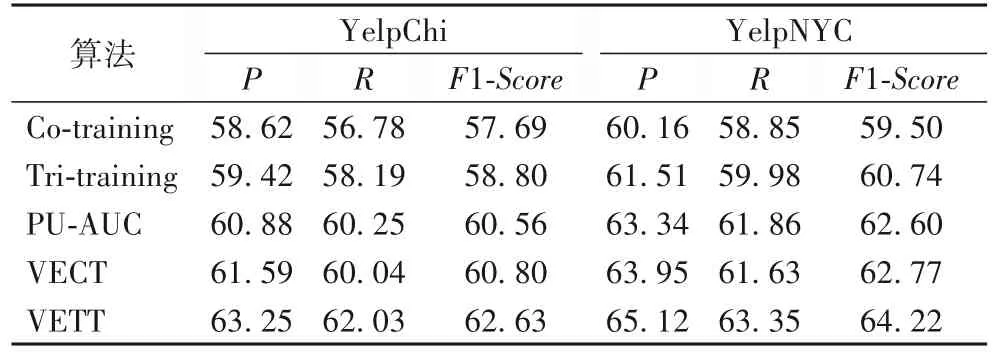
表5 Yelp數據集上不同算法的性能比較 單位:%Tab. 5 Performance comparison of different algorithms on Yelp datasets unit:%
為了驗證第2 章模型中特征提取(評論文本特征和用戶行為特征)的有效性,本文在Amazon 數據集中比較了基于VETT 的虛假評論檢測模型在不同特征情況下的分類效果。在此實驗中,未標記的標注數據的比例設置為60%,并選擇單一的評論文本特征、單一的用戶行為特征以及兩者的混合特征這三種情況,以此來作對比實驗,觀察算法在不同特征下的分類性能,實驗結果如表6 所示。從表6 可以看出,使用混合特征的算法的F1 值最高,表明本文選擇的混合特征是有效的。
為了驗證本文算法在少量的標注數據中可以獲得更好的檢測結果,在Amazon數據集上進行了標注率對于算法效果影響的實驗,將訓練集中的標記樣本數量從10%依次增加到20%、40%、60%和80%。實驗結果如圖4 所示,當標記樣本的比例從10%增加到60%時,盡管前3 個標注率中虛假評論檢測到的F1 值不同,但總體趨勢是增加的,并且標記樣本的比例也在增加。當標注數量較大時,F1 值趨于穩定。因此,從實驗結果可以看出,相較于VECT 和Co-training 算法,本文的VETT 算法可以在少量標記樣本的條件下獲得更好的識別結果,即可在大大減少標注量的同時獲得更好的檢測效果。

表6 Amazon數據集上不同特征下本文算法的F1值 單位:%Tab. 6 F1-Score of the proposed algorithm under different characteristics on Amazon dataset unit:%
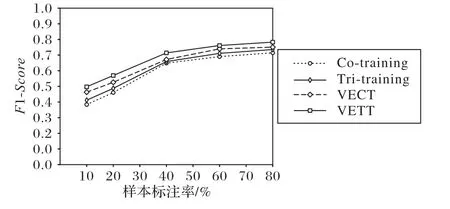
圖4 Amazon數據集上不同標注數據比例下四種算法的F1值Fig. 4 F1-Score of four algorithms under different proportions of labeled data on Amazon dataset
4 結語
高質量的標記數據對于虛假評論的分類至關重要,但是,在許多情況下,標記數據的數量比未標記的數據要少得多,因為標記樣本可能既昂貴又耗時,因此采用半監督學習來利用未標記的數據和少量標記數據進行訓練是非常有效的。
本文提出一種基于垂直集成Tri-training(VETT)的虛假評論檢測模型,結合評論文本特征和用戶行為特征,采用VETT來訓練分類器,以此檢測虛假評論。實驗結果表明Tritraining 迭代過程生成的分類器模型仍然具有一定可用的檢測性能。由于此算法重用訓練迭代中的分類器,計算成本較低。此外該方法結合了大量的分類模型,對分類性能有了實質性的改進,并且使結果更平滑、可靠。
不過本文算法也還存在一些不足:首先對于虛假評論的特征依然是人工設計的,這并不能更為全面地表示一個評論,針對這一方面,未來會對評論文本的特征做進一步的研究,從而能夠從詞向量上深層地表示文本的語義;其次是迭代停止問題,訓練迭代過程依然是人工設置,雖有驗證集驗證最佳效果,但這無疑加大了訓練時間和成本,所以當分類效果最佳時迭代自動停止是一個很好的解決方向,加入強化學習是一個不錯的方法;最后是實驗的數據集在訓練前會有噪聲,以及訓練時依然會有錯誤標注,考慮到噪聲過濾機制的問題,以后會對樣本的抗干擾方面做進一步的研究。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當代陜西(2019年10期)2019-06-03 10:12:04
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
光學精密工程(2016年6期)2016-11-07 09:07:19
