基于協同知識圖譜特征學習的論文推薦方法
2020-09-18 00:36:58劉柏嵩劉曉玲黃偉明
計算機工程 2020年9期
唐 浩,劉柏嵩,劉曉玲,黃偉明
(寧波大學 信息科學與工程學院,浙江 寧波 315211)
0 概述
學術論文作為科研人員重要的學術資源,在整個科學研究過程中起到關鍵作用。在快速發展的互聯網時代,學術論文發文量呈現爆發式增長態勢,用戶面臨日益嚴重的論文信息過載問題,而學術論文推薦被認為是緩解該問題的有效途徑,可幫助用戶快速了解自身研究領域的學術前沿與動態。通過計算用戶與論文的相關性生成Top-N推薦列表,以滿足用戶對新文章或經典文章的個性化需求[1]。
目前,常見的論文推薦方法一般分為基于協同過濾(Collaborative Filtering,CF)的論文推薦方法、基于內容過濾(Content-Based Filtering,CBF)的論文推薦方法和基于網絡結構的論文推薦方法。基于CF的論文推薦方法應用最廣泛,然而其面向海量論文時存在嚴重的數據稀疏性問題,并且還因為僅使用用戶-項目交互數據計算推薦結果,導致論文相關性較低。基于CBF的論文推薦方法實現簡單卻依賴文本相似度判斷推薦相關性,難以保證論文質量,而且對于海量論文的計算代價過大。基于網絡結構的論文推薦方法存在冷啟動問題,例如引文網絡中前沿工作的引文較少,新文章在引文網絡中被邊緣化,并且該方法還忽視了文本內容價值和用戶興趣。總而言之,以上方法均不能有效解決協同過濾的數據稀疏性問題。此外,用戶閱讀行為通常存在很強的目的性,其閱讀視野一般局限于個人掌握背景知識范圍內的系列論文[2],因此在保證推薦列表與用戶有較強相關性外,還需獲取和擴展用戶的潛在興趣。
知識圖譜(Knowledge Graph,KG)自提出以來在電影[3]、圖書[4]、新聞[5-7]等推薦場景中取得了較好的效果,由于知識圖譜內蘊含豐富的結構化知識、背景知識和實體的語義關聯特征,因此知識圖譜增強推薦成為目前的研究熱點[7-9]。研究人員試圖使用多任務學習[4]或聯合學習[3]等方法從電影或圖書知識圖譜中將知識遷移到推薦過程,在一定程度上緩解了數據稀疏性問題。文獻[3]結合推薦計算與鏈接預測,并借鑒基于翻譯的知識圖譜表示學習算法TransH統一推薦任務與知識圖譜補全任務,提升了知識圖譜的應用效果。文獻[5]使用卷積神經網絡(Convolutional Neural Network,CNN)模型的輸出表示新聞特征和建模用戶的歷史興趣,保持新聞中單詞、實體和實體上下文的對齊關系,并將其作為CNN模型的3個輸入通道,增強新聞文本單詞在知識級別的表示。然而,論文知識圖譜的實體數量龐大,多任務學習方法計算代價較大,并且若要達到論文單詞和實體之間較好的對齊效果,則需要高質量的概念知識庫。本文提出基于知識圖譜表示學習的論文推薦方法(KIRec),使用基于翻譯的知識圖譜表示學習算法充分利用知識圖譜中實體間的關系信息,以解決CF的數據稀疏性問題,并保證推薦結果的多樣性。同時,利用文本信息引導用戶節點特征及其鄰域特征的融合生成最終用戶特征表示,實現對用戶與歷史論文之間的交互進行有效表示。
1 相關工作
1.1 基于知識圖譜的協同過濾
由于將知識圖譜作為輔助信息引入到推薦系統中可以有效解決傳統推薦系統存在的稀疏性和冷啟動問題,因此本文主要研究基于語義路徑和特征學習的知識圖譜協同過濾方法。
1)基于語義路徑的知識圖譜協同過濾方法。文獻[10-12]通過元路徑計算相似路徑下用戶與項目的關聯性,實現知識圖譜的協同過濾。PER[10]方法沿著不同元路徑擴散用戶偏好,在矩陣分解(Matrix Factorization,MF)的語義假設下,輸出用戶和項目隱式表示。HINE[13]方法使用基于元路徑的隨機游走策略將節點序列集成到擴展的MF模型中。文獻[6]提出通用的規則推導模塊,即使用游走計算兩個項目間路徑的概率,提升了貝葉斯個性化排序(Bayesian Personalized Ranking,BPR)和神經協同過濾(Neural Collaborative Filtering,NCF)[14]等模型的性能,從而得到項目與項目的特征向量對,該方法通過自動學習知識圖譜上的用戶偏好規則完成現有神經網絡模型的協同過濾。但以上方法的路徑設計過程復雜,需要具備領域知識,并且忽略了用戶-項目中存在的其他語義路徑。
2)基于特征學習的知識圖譜協同過濾方法。該方法將實體和關系映射為低維稠密向量,輔助增強用戶和項目的表示。TransE-CF[15]融合了項目之間與對應實體之間的語義近鄰,在一定程度上解決了冷啟動問題。CKE[16]在協同過濾中同時融入文本信息、結構信息和圖像信息,使用TransR學習結構信息的表示。DKN[5]在學習特定新聞語義時利用基于三通道的卷積神經網絡,融合知識圖譜的實體特征并基于知識感知進行新聞推薦。針對基于項目的協同過濾方法只使用協同相似性關系而忽略了真實場景中各項目之間多種關系的特點,RCF[9]基于項目和關系構建知識圖譜,分層考慮關系類型和關系值。對于數據稀疏性和冷啟動問題,文獻[17-18]提出KGCN和KGCN-LS方法,研究卷積網絡如何自動挖掘知識圖譜用戶以及項目高階結構信息和語義信息,從而獲取用戶潛在興趣。為充分利用項目或實例之間的關系,采用高階關系建模的KGAT[8]基于用戶-項目二部圖和項目知識圖譜構建協同知識圖譜。MKR[4]是一種通用的交替學習框架,其主要思想為將交叉壓縮單元作為知識圖譜表示學習與推薦任務的信息交互通道,用于自動共享隱式特征。本文方法是一種基于特征學習的協同過濾推薦方法,其在用戶表示過程時有選擇性地融入了文本信息與結構信息,即將文本信息形式化為注意力權重,且在建模交互階段采用多層感知機(Multi-Layer Perceptron,MLP)代替點積運算。
1.2 基于知識圖譜的協同過濾應用場景
基于知識圖譜的協同過濾方法在多種推薦場景中得到廣泛應用。表1總結了基于知識圖譜的協同過濾應用場景,可以看出其在電影和圖書推薦中應用最多,主要原因為這兩類推薦容易獲得對應實體,而對于論文類學術文本的推薦,需構建分層的概念知識圖譜,實現難度較大。

表1 基于知識圖譜的協同過濾應用場景
2 協同知識圖譜構建

定義2(協同知識圖譜) 基于用戶-項目交互圖,融入論文知識圖譜,形式上表示為CKG=
為獲取論文相應的實體,需選擇合適的知識庫。本文從實體數量、數據質量和獲取難易程度等方面考慮,最終確定兩個開放論文知識庫OAG[10-11]和Acemap[19]來作為構建知識圖譜的原始數據鏈接源。基于SPARQL語句,以在線的方式從上述知識圖譜中獲取首次鏈接實體及若干關聯后的實體與關系。協同知識圖譜構建具體包括實體鏈接與消歧、關系類型篩選和三元組存儲。
1)實體鏈接與消歧:根據論文標題將論文鏈接到知識庫中的實體。由于論文實體的同名歧義問題,使部分查詢結果不唯一,因此使用論文的多個元數據識別產生歧義的論文。另外,知識庫的內容雖然豐富,但也存在實體鏈接不成功的問題,本文通過將用戶視作特殊實體,在協同知識圖譜中保留未找到關聯的論文,即融合用戶-論文二部圖。
2)關系類型篩選:定義協同知識圖譜模式,構建協同知識圖譜。模式中的關系類型包括用戶與論文的交互關系、論文與論文的引用關系、論文與作者的寫作關系、論文與出版物的出版關系、論文與關鍵詞的提及關系以及論文與領域的從屬關系。
3)三元組存儲:清洗查詢數據和規范化三元組,通過TDB數據庫工具存儲協同知識圖譜,并使用Jena接口進行查詢和推理。
3 基于協同知識圖譜的論文推薦
本文提出的KIRec總體框架如圖1所示。KIRec框架主要分為三部分:1)將協同知識圖譜中的節點(用戶和論文等)映射為低維稠密向量;2)實現用戶和論文表示,其主要工作為文本信息感知的知識圖譜上的鄰域融合;3)通過堆疊的MLP計算論文推薦得分并生成候選列表。

圖1 KIRec總體框架
3.1 實體特征表示
協同知識圖譜利用符號形式對用戶和項目進行建模,在知識圖譜上可以直觀地表示兩者的路徑關聯。通過元路徑設計可以較容易找到用戶感興趣的待推薦論文,然而由于元路徑的設計效率低且需要具備領域知識,因此本文選擇分布式的知識圖譜節點特征表示方式。知識圖譜表示學習算法在保存知識圖譜結構的同時將實體映射為低維稠密向量,其因為結構簡單且高效的特點而受到研究人員的廣泛關注,例如TransE[20]通過優化翻譯準則eh+r≈et(其中,eh表示頭實體,r表示關系,et表示尾實體),高效學習實體和關系的向量。然而,TransE算法難以處理多對多和多對一問題。在本文中,CKG中的同一個關系可能對應多個實體,或者同一個作者發表多篇論文,或者一篇論文對應多個作者。在CKG上應用TransR、TransH[21]、TransD等算法能有效解決上述問題。在協同知識圖譜上使用TransH算法相當于將推薦任務轉換為KG鏈接預測任務。在表示學習過程中,用戶與項目之間潛在的偏好關系將通過其他關系進行體現,表示結果將蘊含用戶對未閱讀論文的偏好。
以用戶實體eu和論文實體ep為例,基于超平面TransH翻譯函數的三元組合理性計算公式如下:
(1)

(2)
(3)
其中,Wr為投影矩陣,根據特定關系將實體映射到超平面。從CKG中學習到的實體向量主要包括待推薦論文表示向量ep,知識圖譜上的用戶表示eu和用戶節點鄰域集{eu1,eu2,…,eun}。
3.2 融合文本特征的用戶表示
在用戶興趣建模階段,融合知識圖譜的用戶節點以及該節點的一階鄰域節點,有利于獲得用戶更全面的特征表示。常用的鄰域融合方法是直接對鄰域表示向量求平均值,計算公式如下:
(4)
該平均方式將所有論文同等對待,但顯然未對用戶興趣進行區分,而且只考慮了KG中包含的結構信息。為更好地衡量用戶已閱讀的文本信息對用戶建模的影響,使用注意力機制計算鄰域節點的權重,計算方法如圖2所示,待推薦論文向量和歷史論文向量即句子向量,權重在圖1中使用wi(i=1,2,…,n)進行表示。該模塊的主要思想在于計算待推薦論文與歷史論文的文本匹配得分,衡量該論文對于用戶興趣的符合程度,可見注意力機制能有效感知用戶面對不同論文時的感興趣程度。

圖2 基于注意力機制的鄰域節點權重計算
ci=Φ(h°wi:i+k-1+b)
(5)

為融合基于TransH表示的用戶節點和基于注意力機制的節點鄰域信息,文本使用雙交互聚合方式[8]將eu和eNu聚合為最終的用戶表示:
LeakyReLU(W2(eu+eNu))
(6)
其中,⊙為向量對應元素的乘積運算,W1和W2為可訓練的參數矩陣,該聚合方式能對用戶與歷史論文之間的交互進行有效表示。
3.3 推薦計算

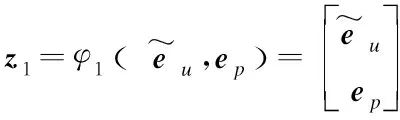
?
(7)
其中,ai(i=1,2,…,L)是多層感知機的激活函數,此處選擇ReLU函數,Wj和bj(j=1,2,…,L)分別表示可訓練的參數矩陣和偏置。最后使用輸出函數計算得分:
sscore=φout(zL)=σ(hTzL)
(8)
其中,σ表示最后一層的輸出函數,選擇sigmoid函數σ=1/(1+e-x)。
4 實驗結果與分析
4.1 實驗環境與數據集
本文實驗運行環境為Linux操作系統、64 GB內存、2 TB硬盤、NVIDIA TITAN Xp顯卡、Python 3.6版本。為驗證KIRec方法的有效性,實驗使用公開獲取的CiteULike-a數據集[24-25],包含用戶和論文的交互記錄210 518條,數據稀疏性為99.78%。該數據集通過虛擬論文資源共享平臺CiteULike收集和整理而成,其允許用戶在線創建和管理文獻。首先,CiteULike平臺的用戶注冊后可創建文獻興趣倉庫,反映了真實場景下用戶對文獻的歷史偏好,因此收集到的數據滿足實驗需求。其次,CiteULike-a數據集包含清洗后的用戶-項目對、論文標題和摘要等數據,其論文標題在預處理后與知識庫進行實體鏈接,具有較高的成功率,其文本內容也滿足本文注意力機制的實驗數據需求。最后,CiteUlike-a數據集的數據稀疏性較高,有效驗證了CKG有助于提升協同過濾算法的性能。
對于數據集的預處理,實驗參照常用處理方式[3,22,24],如果用戶與論文存在交互則編碼為1,否則編碼為0。實驗所需的額外實體和關系來自OAG和Acemap論文知識庫,知識庫基于圖結構保存論文實體、論文元數據及它們之間的關系。針對知識庫的查詢實驗設置關聯次數為1,即查詢結果包括應用實體鏈接技術獲取的實體集合及該集合中所有實體的一階鄰域實體集合。查詢結果以json格式的數據返回,經過數據清洗和數據消歧等操作后所得數據統計如表2所示。考慮到實驗性能且為保證數據集質量,去除交互記錄數量少于5的用戶[3,14]及過濾出現次數低于閾值δ的實體以及對應的邊。實驗中選取δ=5得到形如(頭實體,關系,尾實體)的三元組數量為1 184 131。將用戶-論文隱式反饋對按照7∶3的比例劃分為訓練集和測試集,嵌入向量的維數d=100。
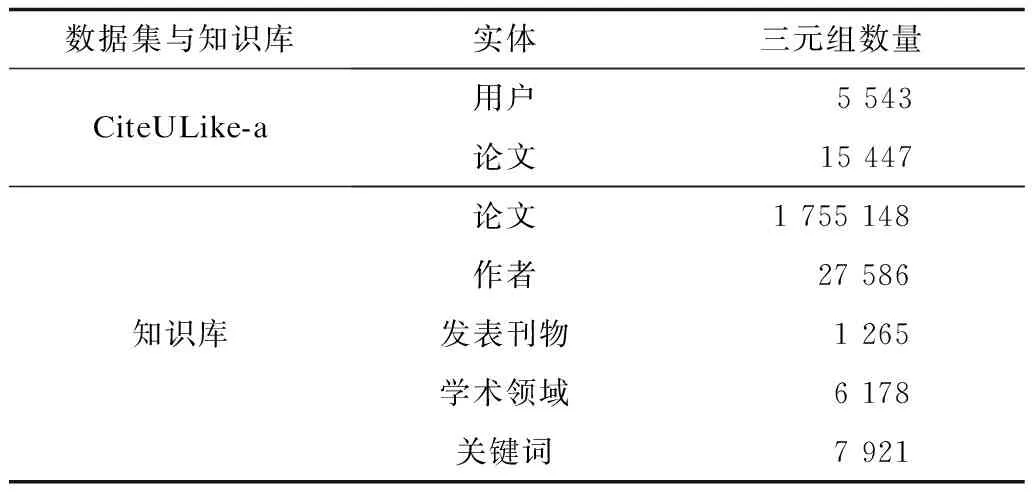
表2 實驗數據統計
4.2 評估方法
在評估階段,隨機選取100篇用戶未交互的論文,與測試集的論文同時進行排序。選擇兩種常用于衡量推薦結果排序質量的評價指標HR@N和NDCG@N,計算基準方法的平均得分。HR@N表示前N篇推薦論文中,正確預測用戶偏好的論文在其中所占的比例,可直觀地看出論文是否出現在推薦列表中。NDCG@N為歸一化折損累積增益,衡量了推薦列表中前N篇論文的排序質量。對于用戶感興趣的論文,根據其位置累積增益,對于不感興趣的論文則增益為0,最終對排序位置進行折損,將用戶感興趣的論文排在前面。
4.3 基準方法
本文選取兩類基準對比方法:
1)基于MF與CBF的論文推薦方法。前者基于協同過濾的矩陣分解方法,廣泛應用于多種推薦場景。后者基于內容過濾,實驗主要評估論文標題和摘要的相似度指標。
2)基于知識圖譜的論文推薦方法:CKE[16]和DKN[5]。前者結合項目結構信息、文本信息和圖像信息的協同推薦算法,實驗過程中應用項目結構信息和文本信息特征。后者通過融入知識圖譜信息和文本信息的知識感知模型,并使用CNN進行實體向量和鄰域向量的特征提取。
4.4 結果分析
表3顯示了KIRec方法與基準方法在N=10時的實驗結果,可以看出CF方法推薦效果較差,其主要原因可能為不同用戶對于論文閱讀感興趣領域不同,只依賴協同關系的推薦列表在數據稀疏的情況下推薦結果會產生較大偏差。CBF方法相對CF方法推薦效果有一定程度的性能提升,其主要原因為用戶閱讀興趣在很大程度上取決于其閱讀過的文本與待推薦文本之間的語義相似性。由此可見,基于知識圖譜的論文推薦方法效果優于基于MF與CBF的論文推薦方法,而KIRec方法能取得最優效果的原因主要與結構信息、文本信息的融合相關,基于注意力機制的DKN和KIRec方法比未使用注意力機制的推薦方法性能更好。

表3 5種推薦方法的實驗結果比較
表4對比了4種基于翻譯的知識圖譜表示學習算法對KIRec方法的影響,可見KIRec+TransH方法的性能表現最好。此外,實驗還對無鄰域信息(withoutNu)的KIRec方法、通過求解領域信息平均值的方式代替注意力機制(Nuby Average)的KIRec方法和本文KIRec方法進行對比,實驗結果如表5所示,可以看出這兩種參數設置方式能有效提升KIRec方法的推薦效果。

表4 基于知識圖譜表示學習算法的KIRec實驗結果比較
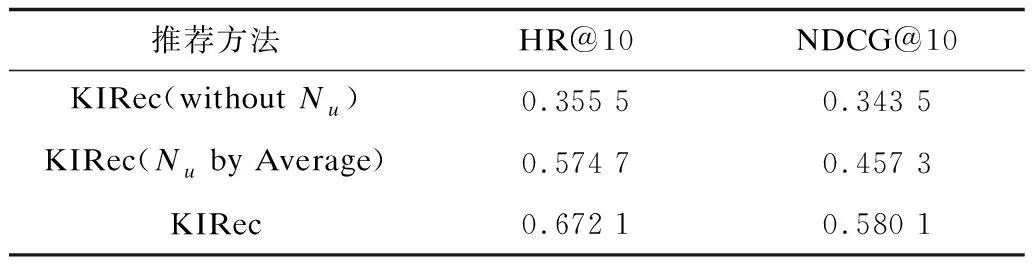
表5 不同參數設置方式的KIRec實驗結果比較
5 結束語
在海量論文中為用戶進行個性化論文推薦時,數據稀疏性問題嚴重影響了論文推薦質量。為此,本文提出基于協同知識圖譜特征學習的論文推薦方法,采用協同知識增強方式加強語義關聯性,利用結合文本信息與結構信息的注意力機制對用戶偏好進行建模。同時,使用聚合函數融合用戶在知識圖譜上的鄰域特征表示,并通過多層感知機的非線性變換提高用戶與論文的推薦得分。實驗結果表明,與傳統推薦方法和基于知識圖譜的推薦方法相比,該方法具有更好的推薦效果和排序質量。但本文構建的知識圖譜中的關系類型較少而論文實體數量較多,且在獲取知識庫實體時僅選取關聯次數為1的相關實體,后續將在研究多樣化關系和用戶偏好類型的基礎上,增加知識庫相關實體的關聯次數,進一步提高論文推薦準確率。
猜你喜歡
制造技術與機床(2019年10期)2019-10-26 02:48:08
電子制作(2018年18期)2018-11-14 01:48:06
中華手工(2017年2期)2017-06-06 23:00:31
商用汽車(2016年11期)2016-12-19 01:20:16
商用汽車(2016年6期)2016-06-29 09:18:54
商用汽車(2016年4期)2016-05-09 01:23:12
小學教學參考(2015年20期)2016-01-15 08:44:38
創業家(2015年5期)2015-02-27 07:53:25
中外會展(2014年4期)2014-11-27 07:46:46
語文知識(2014年1期)2014-02-28 21:59:13
