基于Python爬蟲的多語言社交媒體情感分析研究
2020-09-28 06:45:22薛濤
信陽農林學院學報 2020年3期
薛 濤
(運城師范高等專科學校 數計系,山西 運城 044000)
互聯網的發展使人們進入了用戶生成內容(User Generated Content,UGC)[1-2]的新時代,許多互聯網技術的應用廣泛地使用UGC提供服務。用戶通過便攜式設備(如手機)、Web等途徑,輕松地發表評論、新聞、活動以及身邊的其他信息。海量UGC(如文本、視頻、音頻)數據的出現,使人們面臨著數據分析、數據抽取等難題。社交網絡信息數據中包含了大量人們對新聞、時間、產品和服務等的評價和感受,研究這些數據信息對于輿情分析、互聯網服務質量的提高等具有理論和實踐意義。與國內的主流社交媒體(如新浪微博)相比,Twitter是一個用戶遍及全球的社交媒體,具有更大的受眾范圍[3]。由于Twitter的信息數據包含了多種語言,擁有多樣的用戶社交圈,因此以Twitter作為研究對象,開展了多語言情感分析的研究。
本文的多語言社交媒體情感分析系統主要包括三個部分:預處理、模式提取和情感分類。該系統將使用三個不同的數據集作為輸入。這三個不同的數據集分別是:評論推文(包含主觀意見)、事實推文(包含客觀描述)、已分類的推文。其中,事實推文用來提取情感模式,已分類推文用來構建分類模型。所有數據集中的數據都必須經過預處理階段,將異常數據清除,使數據格式標準化。為了更好地表示這些集合的數據結構,將推文轉換為圖,即將評論推文轉換為評論圖,將事實推文轉換為事實圖。接下來,對圖進行簡化操作。進行簡化操作后,事實圖用來創建評論圖中的權重,以生成情感圖。然后針對情感圖進行節點中心性和節點聚類分析,以提取用于構建模型的詞匯-句法特征。在提取情感模式后,將情感模式列表和已分類推文相結合,以構造特定的情感模型。最后應用矢量建模技術,便能獲得情感分類器。
1 基于Python爬蟲的數據抓取和預處理
所使用的數據集是通過Python爬蟲收集到的。因此,數據收集的時間越長,數據集就會越大。不同語言的語法、詞匯基礎和其他特征之間具有明顯的差異,因此為了從不同的語言中獲得情感模式,必須獲取相應的語言數據集。評論推文數據集是普通用戶的日常推文,其中包含一些與情感相關的單詞、主題標簽或表情符號。事實推文是官方媒體所發布的推文,主要包含已經發生的事件或報告事物的當前狀態等客觀事實。通過對官方媒體賬戶進行爬蟲就可以獲得事實推文數據集。已分類數據集包含了特定情緒相關的推文。采用Python爬蟲,根據特定情感所對應的主題標簽來獲取含有該情感的推文。首先需要在Twitter開放應用程序的網站(https://dev.twitter.com/apps)上創建一個應用程序,以獲取Twitter API的權限。接下來需要創建一個Token,從開放式授權驗證(OAuth)中獲取Key、Secret、Token和Access Token的信息,并將這些信息填入如表1所示的Python代碼的相應位置中。采用Python提供的tweepy進行爬蟲實現。

表1 獲取應用Key
OAuth是一種開放式身份驗證標準,Twitter已采用該標準來提供對受保護信息的訪問。 OAuth使用三向握手為傳統身份驗證方法提供了一種更安全的替代方法。在實現爬蟲功能之前,需要使用Python的import語句來引入相應的模塊,如表2所示。

表2 Python爬蟲所需要的部分模塊
由于篇幅有限,此處僅展示根據用戶ID搜索推文的部分實現Python代碼,如表3所示。

表3 推文抓取的部分Python代碼
社交網絡應用允許用戶自由地表達自己的情感,推文的內容具有多種形式、長度、符號用法甚至不同的語言。因此,需要對數據集進行預處理,避免噪音對后續處理產生影響。如果推文太短,將很難表達出具體的情感,因此需要將其刪除。這是因為缺乏足夠單詞的文本可能會使句法模式更難識別。在關鍵字之前添加主題標簽“#”有利于社交網絡應用對推文進行分組。但是很多用戶會在推文中濫用主題標簽,最終使得該推文缺乏重要內容。因此,包含太多標簽的推文也將被刪除。另外,也需要刪除轉發的推文。轉發的推文會造成內容重復,而且轉發的推文不一定能反映當前用戶的情感。最后,由于包含URL的推文一般不帶有情感,因此需要將其刪除。在預處理階段之后,首先需要對每個推文進行分詞操作,以獲取多個獨立的單詞。然后,通過使用特殊標記替換推文中的用戶名、URL、主題標簽等來實現單詞的規范化。規范化操作能夠避免可能由于用戶名、標簽等而引起的偏差。
2 模式提取和情感分析
2.1 模式提取
模式提取是情感分析的一個重要過程。不同的語言在語法和句法上有所不同。句子由模式組成,它們提供了表達的結構。模式提取算法包括兩個主要部分:基于圖的單詞提取和情感模式提取。基于圖的單詞提取組件是一種無監督的方法,可以提取兩種類型的單詞,即連接詞和情感詞,它們是模式的組成部分。情感模式提取組件使用提取的單詞列表來識別語料庫中的重復模式。根據評論推文和事實推文分別構建兩個不同的加權圖:Gu(Vu;Au)和Gn(Vn;An)。對于每個圖,V是節點的集合,每個節點代表一個單詞;A是一組弧線,用來表示兩個單詞之間的關系。為了保留推文的韻律和基礎結構,根據推文中單詞的順序定義弧。用freq(ai)表示弧ai出現的頻率,用w(ai)表示弧ai的權重,其定義如下:
(1)
因此,文本中單詞之間的關系都可以由圖中的弧表示,而且這些弧具有權重。為了更準確地對評論推文數據的結構進行建模,基于評論推文圖Gu來構造情感圖Ge,并根據事實推文圖Gn的內容對情感圖Ge進行調整。首先,通過包含Gu中的所有節點和弧來構造一個新圖Ge,并根據以下的規則來調整Ge的權重。
(2)
新圖Ge強調個人情感和個人觀點,因此那些僅在評論推文中出現且不在事實推文中出現的推文的權重將保持不變。如果一條弧同時出現在評論圖和事實圖中,則該弧的權重會減少。在新圖Ge中,弧的權重較高表示單詞序列與評論推文更相關,而具有低權重的弧則與事實推文更相關。在后續的圖分析過程中,權重較低的弧具有更低的重要性。因此,當弧權重低于閾值thw時,該弧將被刪除。最后生成的圖稱為情感圖。
接下來對情感圖進行分析,以發現頻繁且相關的單詞以構建連接單詞集,并查找與情感相關的單詞。根據節點的統計信息可以對節點進行分類。以前的方法一般依賴于詞性標簽或基本的統計信息(如字數統計)。在多語言的情況下,這些方法并不適用。本研究所提出的方法是基于圖中節點的中心性來識別連接詞。在圖分析中,節點的中心性衡量其在圖中的相對重要性。最佳連接詞不僅是頻繁出現的詞,而且還是圖的中心。節點相關性也可以通過考慮其他因素來確定(如節點鄰居的重要性)。為了達到這個目的,采用特征向量中心性對單詞進行排序并選擇連接詞。當節點的鄰居具有較高的特征向量中心性時,該節點也會擁有較高的中心性。節點vi的中心性ci的計算方式如下所示:
(3)
其中,λ是特征值。用矩陣M=(mi,j)表示情感圖中節點之間的關系:當節點vi和節點vj在圖Ge中相連接時,mi,j等于1;否則,mi,j等于0。
然后通過保留特征向量中心度高于閾值φeig的所有單詞來形成連接詞列表。在獲得第一個單詞列表后,下一步就是創建一個包含帶有情感單詞的第二個單詞列表。由于僅基于頻率來選擇情感詞并不可靠,而且一般來說情感詞會通過相同的連接詞相互連接,因此通過單詞的平均簇系數來進行情感詞的選擇。節點vi的平均簇系數cli的計算方式如下所示:
(4)
然后通過保留平均聚類系數高于閾值φcl的所有單詞來形成情感詞列表。在獲得兩個單詞列表之后,接下來通過查看連接詞和情感詞的組合來提取模式。考慮帶有兩個或三個單詞的短模式,較長的模式可以通過組合短模式來表示。例如,四個單詞序列可以由兩個具有兩個單詞的模式組合來表示。每個模式必須包含來自連接詞列表和情感詞列表的單詞。這是因為僅由連接詞組成的表達式會缺少情感模式;而僅包含情感詞的表達將缺乏足夠的語法來描繪適當的含義。具有相同連接詞、長度和順序的樣式會被歸為一組。如此一來,能得到多個組,每個組都是一組模式實例。鑒于某些表達結構更為頻繁,某些組將包含更多的實例。每個組中的實例將根據其語法結構定義候選模式,然后將每個組中的情感詞替換為通配符以使該序列能夠匹配其他具有相同模式的單詞序列。這樣一來,就能夠得到表達不同情感的候選模式列表。
2.2 情感分析
使用情感度來反映模式p對特定情感e的重要性,其計算方式如下所示:
edp,e=pfp,e×iefp×divp
(5)
pfp,e是代表模式頻率,定義為pfp,e=log(f(p,e)+1),其中f(p,e)是模式p在情感e中出現的頻率。iefp是逆情感頻率,其計算方式為iefp=|E|/|{e∈E∶f(p,e)>0}|。divp是指多樣性,其計算方式為divp=log(Φ(p,E)),其中Φ(p,E)表示模式p能捕捉的情感數量。
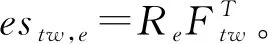
3 實驗評估
所有實驗中使用的數據均來自Twitter。為了提取模式,采用基于Python的爬蟲技術抓取了含有情感的評論推文,其中包括英語、法語和西班牙語的推文各10 000條。而事實推文數據集則是通過抓取官方媒體在Twitter上發表的推文而獲得的,每種語言各獲得了約500條事實推文。考慮的情感分別為憤怒、恐懼、希望、喜悅、悲傷和驚奇。
將本方法與LSTMs(長短期記憶網絡)[4]、Conv-Emb[5]和Conv-Char-S[6]進行了比較。表4展示了三種方法的準確度(accuracy)和F-度量(F-measure),表5展示了三種方法分別應用于不同語言下的分析結果。綜合表4和表5的結果可知,本方法在多語言的情感分析中具有最好的性能。

表4 三種方法的準確度和F-度量對比

表5 三種方法在不同語言下準確度對比
4 結論
本研究探討了多語言的社交媒體情感分析問題,首先設計并實現了基于Python爬蟲的數據獲取和預處理,然后提出了一種無監督的情感分析方法。最后利用真實數據集驗證了本方法的有效性。未來的研究將通過進一步改進本方法,實現在線的社交媒體情感分析。
猜你喜歡
閱讀(快樂英語中年級)(2024年9期)2024-10-23 00:00:00
時代英語·高三(2024年3期)2024-09-03 00:00:00
中國生殖健康(2020年5期)2021-01-18 02:59:48
家庭醫學(下半月)(2020年4期)2020-05-30 12:42:50
北極光(2019年12期)2020-01-18 06:22:10
閱讀(快樂英語高年級)(2020年8期)2020-01-08 02:21:16
小太陽畫報(2019年10期)2019-11-04 02:57:59
中國生殖健康(2018年5期)2018-11-06 07:15:40
智慧少年·故事叮當(2018年11期)2018-05-14 11:48:18
意林(繪英語)(2017年5期)2017-05-15 02:17:23
