數據挖掘方法在網絡學習行為研究中的應用
2020-09-29 07:51:13蔣雯音張穎童亞琴
電腦知識與技術 2020年17期
關鍵詞:數據挖掘
蔣雯音 張穎 童亞琴
摘要:隨著網絡在線教育的普及,網絡教學過程中產生了大量數據資源。在對數據挖掘理論和技術研究的基礎上,利用SPSS Clementine工具并分別采用關聯分析、聚類分析和決策樹分析三種數據挖掘方法,對網絡教學平臺學習者的學習行為數據進行挖掘分析,探究網絡學習行為與學習效果的關聯、不同類型學習群體的學習特征、網絡學習行為規律,最后分析總結了研究網絡學習行為對于促進高效網絡學習、優化網絡教學策略、輔助網絡教學決策方面的現實意義。
關鍵詞:數據挖掘;網絡學習行為;關聯分析;聚類分析;決策樹分析
中圖分類號:G642 ? ? ? ?文獻標識碼:A
文章編號:1009-3044(2020)17-0017-05
1 ?引言
隨著移動互聯網、云計算、大數據等新一代信息技術的發展及在教育領域中的應用,網絡教學方式迅速推廣和普及,各大在線教學平臺推出了慕課(MOOC)、小規模限制性在線課程(SPOC)新型網絡學習課程。學習者在網絡學習過程中,網絡教學平臺獲取并存儲了大量與其網絡學習行為相關的數據(如訪問次數、學習時長、學習進度、作業及測試情況、參與互動情況等),這些數據是分析網上學習效果的寶貴資源,然而卻沒有得到足夠的重視。如何將網絡教學過程中產生的大量學習數據資源,轉化為對教學決策有價值的信息,提升網絡教學的質量和效果,是一個值得探討的問題。因此,對網絡學習行為的分析與研究受到了越來越多的關注和重視。
數據挖掘(Data Mining,簡稱DM)又被稱為數據庫知識發現[1],一般是指從大量的數據中通過算法搜索發現隱藏于其中具有潛在價值的信息的過程,從而幫助決策者發現規律、預測分類、輔助決策。數據挖掘是當前數據分析領域中最活躍最前沿的地帶,是一種深層次的數據分析方法。因此,利用數據挖掘方法對學習者的網絡學習行為進行客觀、科學的分析和研究,挖掘蘊含在數據中的豐富價值,為學習者、教師及學校提供精準的支持服務,為網絡教學提供決策,具有現實意義和價值。
2 ?常用數據挖掘方法
2.1 關聯分析
2.1.1 關聯規則
關聯分析的目的是為了挖掘隱藏在數據間的相互關系,即對于給定的一組項目和一個記錄集,通過對記錄集的分析,得出項目集中的項目之間的相關性[2]。用關聯規則來描述項目之間的相關性,一般表示形式為:X→Y(規則支持度,規則置信度),其中X和Y分別稱為前項和后項[3]。
關聯分析后會產生許多規則集,判斷規則有效性的指標是規則支持度(反映規則普遍性)和規則置信度(反映規則的準確度)。如果一個關聯規則的支持度和置信度均大于設定的最小支持度和最小置信度閾值,那么就是強規則,即表示該關聯關系是有意義的,關聯分析就是對強規則的挖掘。
關聯規則挖掘過程分兩步:首先,尋找頻繁項集,即找出那些出現頻率大于等于最小支持度閾值的項集;然后,從頻繁項集中找出滿足最小置信度的關聯規則。
2.1.2 GRI(Generalized Rule Induction)算法
GRI算法是關聯規則的算法之一,它采用深度優先搜索策略[3]:先確定一個后項Y進行分析,在分析后項Y時,依次分析該后項中包含的各個項目(Y1,Y2…Yn),在分析每個項目Yi時,又逐一分析其前項X所包含的各個項目(X1,X2…Xn),當前項中的每個項目Xi分析完,然后再分析下一個后項中的項目Yi,當后項中所有項目(Y1,Y2…Yn)全部分析完,就完成了對于一個后項Y的分析,分析完一個后項后再分析下一個后項,直至分析完所有后項。
2.2 聚類分析
2.2.1 聚類分析概述
聚類分析是按照個體特征的相似系數或者距離將他們分類,讓同一個類別內的個體之間具有較高的相似度,不同類別之間具有較大的差異性[4],它屬于無監督學習。通過聚類分析,可以了解數據的分布、比較分析各類的特征和規律,它在探索數據內在結構方面具有全面性和客觀性等特點。
聚類分析中有不同的聚類算法,主要有劃分聚類、層次聚類、基于密度聚類、基于網格聚類等,在實際應用中應根據不同的目標選擇相應的聚類算法。
2.2.2 ?K-means算法
K-means是一種常用經典的劃分聚類算法,它通過反復迭代調整類中心來劃分樣本所屬的類,具體聚類過程[4]:
1)取K個初始質心:隨機抽取K個點作為初始聚類的中心,來代表各個類;
2)把每個點劃分進相應類:根據歐式距離最小原則,把每個點劃進距離最近的類中;
3)重新計算質心:根據均值等方法,重新計算每個類的質心;
4)迭代計算質心:重復第2)步和第3)步,迭代計算;
5)聚類完成:類中心不再發生改變。
2.3 決策樹分析
2.3.1 決策樹概述
決策樹算法的目的是通過向數據學習,實現對數據內在規律的探究和新數據對象的分類預測。決策樹學習是已知數據類別的一種有監督學習,采用自頂向下的遞歸方法生成一種樹型結構,樹的最高層節點為根節點,中間各層的每個節點表示對于一個屬性的判斷或測試,每個分支表示一個判斷或測試的輸出,每個葉節點代表一種分類結果[5]。
生成決策樹的過程就是不斷分裂產生分支,每次選擇可以得到最優分類結果的屬性進行分裂,即經過這個屬性的判斷能使分裂后的子集中的記錄盡可能的屬于同一個類別,不斷重復這一過程,直到達到停止分裂的條件。決策樹算法的關鍵是分裂屬性的選擇以及分裂停止的判定。另外,由于異常數據等影響剛建立的決策樹會過于復雜而出現過擬合的情況,導致預測不準確,因此需要通過剪枝對決策樹進行優化[6]。
2.3.2 ?C5.0決策樹
C5.0是一種經典的決策樹算法,可生成多分枝的決策樹或規則集,其目標變量為分類變量。C5.0決策樹以信息增益率作為確定最佳分裂屬性的標準,每次選擇信息增益率最大的屬性進行分裂拆分樣本,每次拆分后的節點對應的子集繼續根據另一個屬性進行拆分,重復這一過程直到所有樣本不能再被拆分為止。最后,從葉節點向上逐層進行剪枝優化,修剪掉那些沒有意義的分支和節點[7]。
3 ?網絡學習行為研究
3.1 研究內容
本研究利用職教云課堂平臺上的一門SPOC課程的學習者網上學習數據作為數據樣本,借助SPSS Clementine工具利用數據挖掘方法對學習者的網絡學習行為進行研究,主要包括以下幾個方面。
1)關聯分析網絡學習行為與學習效果關系
利用關聯分析GRI算法對主要網絡學習行為與學習效果之間的關系進行分析,探究不同學習行為對學習效果產生的影響。
2) 聚類分析學習者群體特征
利用K-means聚類算法將學習者劃分為幾大類型群體,挖掘同一類型群體中學習者的行為共性、不同類型群體之間的學習行為特性及差異。
3)決策樹分析網絡學習行為規律
利用決策樹C5.0算法挖掘網絡學習行為規律,構建決策樹模型預測不同網絡學習行為可能產生的學習效果,同時可以將學生分成不同層次,進而分析不同層次學生的網絡學習行為特點。
3.2 數據挖掘方法應用
3.2.1 學習行為重要性分析
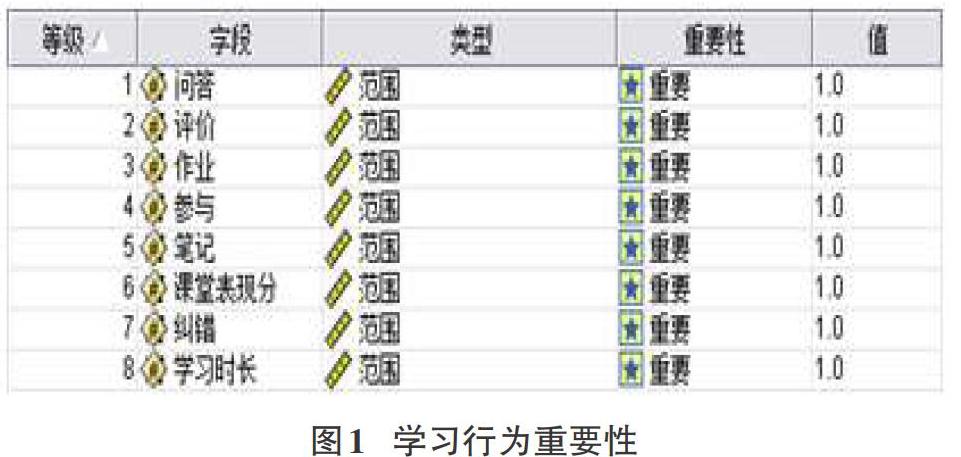
通過對云課堂平臺上獲取到的學習者學習數據的前期數據預處理后,共有456條樣本作為分析對象。以各種學習行為作為輸入變量,學習者的期末考核成績作為輸出變量,先找到對輸出變量影響較大的輸入變量,便于后續建模,因為過多的輸入變量會產生共線性問題,篩選出有效的輸入變量既可以提高模型穩定性,也能提高模型精確度。
利用“建模-特征選擇”節點,分析出對輸出變量有顯著意義的輸入變量如圖1所示,可以看出對學習者的學習效果即期末考試成績有重要影響的學習行為有:對學習資源的各種交互(包括問答、評價、筆記、糾錯)、在線學習中的參與次數(包括提問、討論、投票、頭腦風暴、測驗、課前課后參與、評價、總結等)、課堂表現(各類線上活動得分)、作業、學習時長。其他變量(如學習進度、考勤、訪問次數等)在本樣本中的標準差極小,即這些學習行為差異性非常小,因此不作為后續建模的輸入變量。
3.2.2 網絡學習行為與學習效果的關聯分析
通過對各種學習行為重要性分析,選入8類學習行為作為建立關聯模型的輸入變量,由于這些輸入變量都是數值型變量,因此選用關聯分析中的GRI算法,對不同學習行為和學習效果進行關聯分析。
1)關聯分析建模
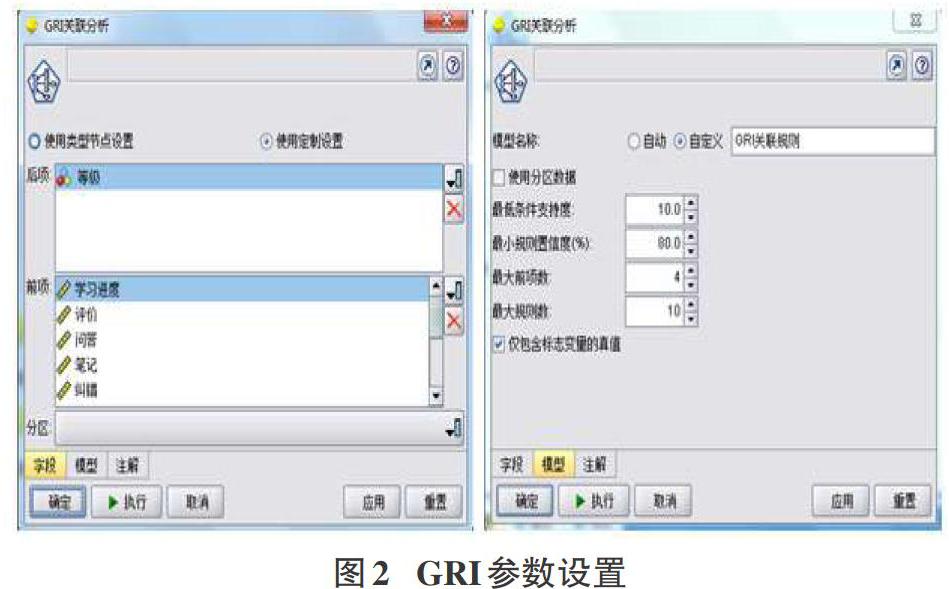
利用“建模-GRI”節點構建關聯分析模型,選擇自行指定建模變量,其中關聯規則的前項為8類關鍵學習行為對應的8個變量,后項為考試成績等級,這里將考試成績分成A-優秀、B-良好、C-及格、D-不及格四個等級。
關聯分析中,需要設定兩個閾值即最小置信度和最小支持度,這里把最小支持度設定為10%,最小置信度設定為80%,分析后得到的置信度和支持度均大于給定閾值的關聯規則即為強規則。另外,為防止關聯規則過于復雜,指定前項中包含的最大項目數為4,生成關聯規則的最大數目為10,GRI算法的參數設置如圖2所示。
2)分析結果
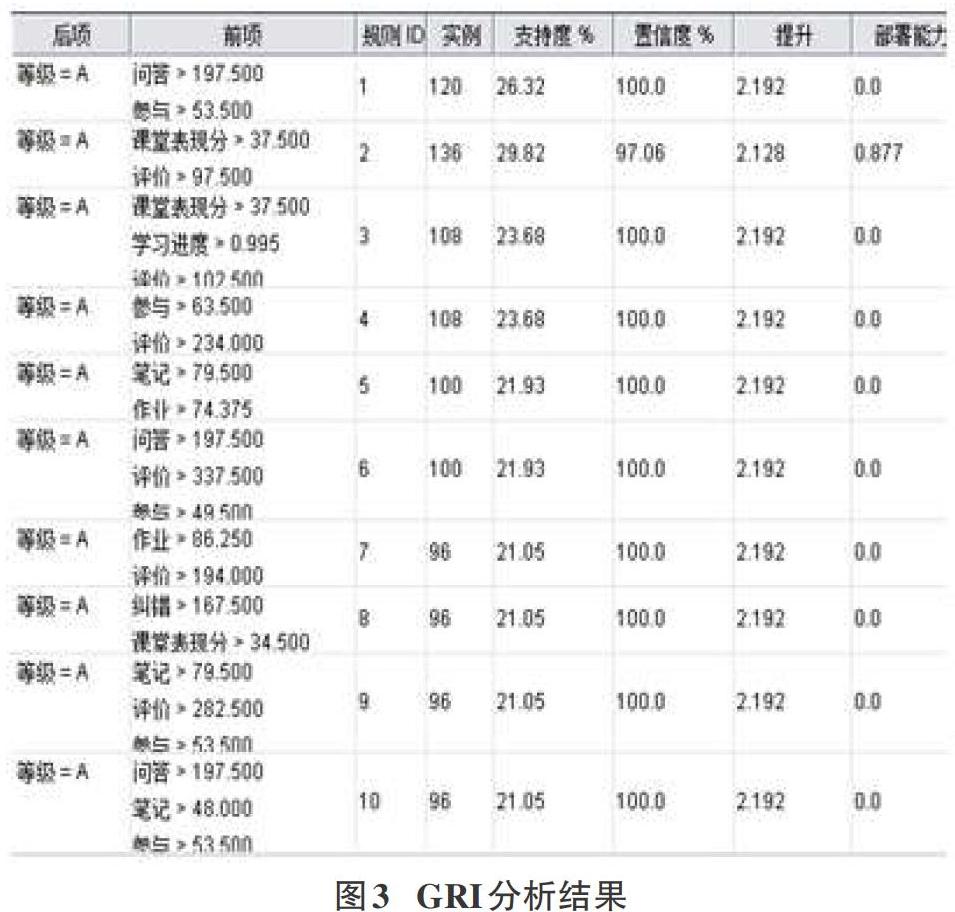
通過GRI算法關聯分析,我們得到了關于后項成績為A即優秀的10條關聯規則,如圖3所示。這些規則的置信度基本都達到了100%,說明規則的準確性較高;最大的頻繁項集大小是3;提升度都大于1,反映了前項中的學習行為對后項中的學習效果有促進作用。
可利用關聯規則考察分析哪些學習行為符合哪條關聯規律,如規則1反映了“問答>197.5、參與>53.5”的學習行為與“等級=A”有關聯關系,由此可認為具有這些學習行為表現的學習者成績傾向于優秀的可能性較高。從分析得到的其他關聯規則中,還可以發現各種不同的學習行為與“等級=A”之間的關聯性。關聯規則是對樣本隱含規律的一種歸納和總結,這些規律體現了大部分學習者學習行為和學習效果的相互關系和影響,但值得注意的是,這些關聯規則是基于特定訓練樣本集得出的,同時,由于關聯規則本身并沒有關于預測精度和誤差的評價指標,因此通常不直接用于預測[3]。
3.2.3 網絡學習行為聚類分析
根據已有網絡學習行為數據類型特點,我們采用K-means聚類分析研究不同學習群體的學習行為特征。
1)聚類分析建模
利用“建模-K-Means”節點建立聚類模型,指定聚類數目為4類,同時輸出各樣本與所屬類中心點的距離以及各個類中心點間的距離。以“聚類-1”這種字符后加數字形式表示聚類后的各類名稱。選擇“簡單”模式即默認的參數進行聚類,聚類的迭代次數20,容忍度為0表示當最大的類中心偏移量小于0時停止聚類,滿足兩個條件中的一個即停止聚類。集合編碼值可對分類型變量重新編碼后調整其權重,由于分析的變量都是數值型,這里就不用設置,模型的參數設置如圖4所示。
2)分析結果
聚類結果如圖5所示,其中顯示了四類包含的樣本量、各變量的均值和標準差以及各類中心與其他類中心的距離,可以看出聚類-1和聚類-4之間的距離短,即兩類較相似,而聚類-2和聚類-3較相似。
可以把聚類分析得到的四類結果看成四類學習群體,利用“圖形-網格”節點,生成成績等級和四類群體的關系如圖6所示,保留強關系后發現,群體2和群體3中成績優秀較多,群體1和群體4中成績良好的較多,這也符合上面得到的各類之間的相似度。
以圖形矩陣的形式顯示各類中各變量的特征如圖7所示,最后一列紅色五邊形表示八種學習行為在各類之間存在顯著差異,從圖中可以更直觀地反映不同學習群體的學習行為特征,從而分析挖掘同一類型群體中學習者的行為共性、不同類型群體之間的學習行為特性及差異。如成績優秀比例較高的群體2和群體3的學習行為主要特征是學習過程中對于學習資料的筆記、評價、問答等較多,而學習時長相比較群體1則較少,說明學習中的思考、互動對于學習效果有一定促進作用。
3.2.4 網絡學習行為決策樹分析
下面通過構建基于C5.0算法的決策樹模型來挖掘網絡學習行為規律,預測不同網絡學習行為可能產生的學習效果。
1)決策樹分析建模
建立模型前,利用“字段選項-分區”節點先把樣本集隨機分割成訓練集和測試集兩部分,訓練集用于建立和訓練模型,測試集用于估計模型的誤差。
利用“建模-C5.0”節點構建決策樹模型,C5.0算法能生成決策樹,還可以生成推理規則集,使用推進方式即boosting 技術和交叉驗證法建立模型,以提高模型預測精度和穩健性。C5.0決策樹模型參數設置如圖8所示。
2)模型結果
構建C5.0決策樹模型的結果如圖9所示,左圖是從決策樹上直接獲得的推理規則,可以看到每個節點所包含的樣本量及置信度;右圖是生成的9層深度決策樹(取部分),樹的第一個最佳分組變量是評價,并以此形成二叉樹,到下一層分別以學習時長和作業為分組變量繼續往下生長。
從模型結果,我們發現學習者在評價、作業、課堂表現方面越突出以及學習時長越長,成績為A優秀的置信度達到94%以上;而對于評價和學習時長方面表現較差的學習者,成績為C合格的置信度為100%。將模型結果連到數據流中,并用“表”節點查看預測結果如圖10所示,可以查看各樣本的預測值($C-等級)和預測置信度($CC-等級),因此,通過決策樹模型可以預測不同網絡學習行為可能產生的學習效果。
4 小結
利用數據挖掘方法對學習者的網絡學習行為進行分析和研究,挖掘蘊含在數據中的豐富價值,可以幫助我們找到網絡學習行為與學習效果的關聯,了解各類學生的學習特征,掌握網絡學習行為規律,從而為學習者、教師及學校提供精準的支持服務,為網絡教學提供決策,具有現實的應用價值。
4.1 有利于學習者調整學習狀態、改善學習習慣,促進高效的網絡學習
對于學習者,可以根據學習行為的分析結果,與其他學習者的比較,檢查自己的學習情況,更全面清楚地了解自身的優勢和不足,并調整下一步的學習計劃和策略、改善學習習慣,從而進行更高效的網上學習活動。
4.2 有利于教師優化教學策略、開展個性化教學和實施科學的學習評價
對于教師,能準確掌握學習者的學習狀態、學習風格和偏好、知識掌握程度等信息,從而采取有效的教學策略,引導、幫助學習者學習。同時,教師可根據不同類型學習者的網絡學習行為特征,為各類學習者制定不同的學習計劃和教學策略,提供的個性化學習資源以及不同類型的教學服務。另外,對學習者的網絡學習行為進行跟蹤、記錄、分析和可視化,使學習評價更全面、真實和科學。
4.3 有利于指導網絡學習資源開發和網絡教學平臺的建設和改進
對網絡學習行為數據的挖掘分析能深入了解學習者使用學習資源的行為方式和習慣,幫助資源設計者開發出符合學習者學習方式和習慣的網絡學習資源,為學習者提供更多資源獲取渠道、多種處理和使用資源的方法。同時,通過了解學習者使用平臺的方式,有助于平臺設計者改進、健全網絡教學平臺,提高平臺的個性化和智能化。
本文對數據挖掘方法應用于網絡教學進行了初步研究,尚存在有待改進的地方,今后將會繼續深入數據挖掘技術在教育教學方面的研究與應用,為促進信息技術與教學深度融合,探索建立信息化教學模式,構建和實施智慧課堂等方面提供借鑒和參考。
參考文獻:
[1] Bing Liu. Web 數據挖掘(第2版)[M].北京:清華大學出版社,2012.
[2] 趙子江.數據庫原理與SQL SERVER應用[M].北京:機械工業出版社,2006.
[3] 薛薇,陳歡歌.Clementine數據挖掘方法及應用[M].北京:電子工業出版社,2012.
[4] 數據挖掘-聚類分析總結[EB/OL].[2018-10-27].https://www.cnblogs.com/rix-yb/p/9851514.html.
[5] 第3章_分類與決策樹[EB/OL].[2017-08-09].https://max.book118.com/html/2015/0709/20732251.shtm.
[6] 陳萍. 數據挖掘技術在網絡教學中的應用研究[D].廣州:廣東技術師范學院,2015(5):12-14.
[7] 李慶香. 數據挖掘技術在高校學生成績分析中的應用研究[D].西南大學,2009.
【通聯編輯:王力】
猜你喜歡
艦船科學技術(2022年14期)2022-09-22 03:10:36
大眾投資指南(2021年35期)2021-02-16 01:06:26
中國交通信息化(2020年1期)2020-07-27 02:50:04
電力與能源(2017年6期)2017-05-14 06:19:37
中國中醫藥信息雜志(2016年7期)2016-12-01 06:07:55
信息通信技術(2015年6期)2015-12-26 01:16:46
西安工程大學學報(2014年2期)2014-02-28 18:03:05
河南科技(2014年23期)2014-02-27 14:18:43
電子設計工程(2014年18期)2014-02-27 12:00:13
電子設計工程(2014年18期)2014-02-27 12:00:12
