基于FasterR-CNN的教室監(jiān)控人數(shù)識別系統(tǒng)的開發(fā)與研究
2020-09-29 07:51:13王子威范伊紅趙錦雯王濤
電腦知識與技術(shù) 2020年17期
王子威 范伊紅 趙錦雯 王濤
摘要:通過Opencv調(diào)用設(shè)備攝像頭將數(shù)據(jù)讀入,視頻流切分成圖片流后進入在Tensorflow框架下訓(xùn)練好的FasterR-CNN模型進行目標(biāo)識別,將識別出的目標(biāo)進行標(biāo)記并輸出。在教室環(huán)境下由于相互遮擋和密集度大的問題嚴(yán)重,原始的訓(xùn)練模型不能很好地識別困難目標(biāo),通過收集大量教室監(jiān)控截圖并進行Data Augmentation數(shù)據(jù)增強來進一步地擴大樣本,提高識別準(zhǔn)確度;使用LabelImg對數(shù)據(jù)進行標(biāo)注生成訓(xùn)練和測試數(shù)據(jù)集,將VOC2007及新標(biāo)注樣本進行合并得到NEW_VOC2007,在此新數(shù)據(jù)集上進行訓(xùn)練及測試生成新模型。實驗證明,新模型能夠更好地適應(yīng)教室環(huán)境的識別,準(zhǔn)確度更高。
關(guān)鍵詞:Tensorflow; Opencv; 卷積神經(jīng)網(wǎng)絡(luò);Faster R-CNN;目標(biāo)識別;LabelImg
中圖分類號:TP391 ? ? ? ? ? 文獻標(biāo)識碼:A
文章編號:1009-3044(2020)17-0035-04
Abstract: In the school environment, pedestrian-intensive, sheltered, multi-scale problems are common.In this paper, Faster R-CNN is used for pedestrian detectionin complex environment of school buildings. When training samples, ?A training strategy for Difficult Sample Mining is introduced, which adjusts the weight of difficult samples while picking out difficult samples, so as to make training more focused. LabelImg is used to lable the data sampled in complex environment. Then VOC2007 and the annotated samples are merged to obtain extended VOC2007 data set. Training and testing are carried out on this basis to establish the model with good performance. The experimental results show that compared with the four-step training method commonly used in Faster R-CNN, the generalization performance is improved by using this training method.
Key words: tensorflow; opencv; convolutional neural network;faster R-CNN;pedestrian detection;labelimg
1引言
近年來,深度學(xué)習(xí)(Deep Learning)在機器學(xué)習(xí)研究的各個領(lǐng)域如計算機視覺、醫(yī)療、自然語言處理等都取得了引人注目的成果。而計算機視覺領(lǐng)域的核心問題之一就是目標(biāo)檢測(object detection),它的任務(wù)是找出圖像當(dāng)中所有感興趣的目標(biāo)(物體),確定其位置和大小。
傳統(tǒng)的目標(biāo)識別算法如Cascade + HOG、DPM + Haar等,必須手動設(shè)計特征提取方案,所以算法很難提高識別準(zhǔn)確度。就目前圖像分類結(jié)果的準(zhǔn)確率來看,卷積神經(jīng)網(wǎng)絡(luò)更為適用。為了加快提取候選區(qū)域的速度,克服人工設(shè)計特征魯棒性差的難題,本文借鑒了目標(biāo)檢測領(lǐng)域的卷積神經(jīng)網(wǎng)絡(luò)Faster R-CNN模型利用區(qū)域建議網(wǎng)絡(luò)(Regional proposal network,PRN)生成建議候選區(qū)域,進行目標(biāo)檢測。Tensorflow是基于Computation Graph的機器學(xué)習(xí)框架,支持GPU和分布式,是目前最有影響力的開源深度學(xué)習(xí)系統(tǒng)。本系統(tǒng)在Tensorflow框架下對Faster R-CNN進行擴充訓(xùn)練集訓(xùn)練,使其能夠更好地在教室環(huán)境下對目標(biāo)進行更準(zhǔn)確的檢測,使其能夠更好地將每個教室的人數(shù)和空座情況反饋給學(xué)生、教師和后勤安保部門,進而減少學(xué)生找教室和教師課堂點名的時間和學(xué)校資源的浪費。
2 Faster R-CNN介紹
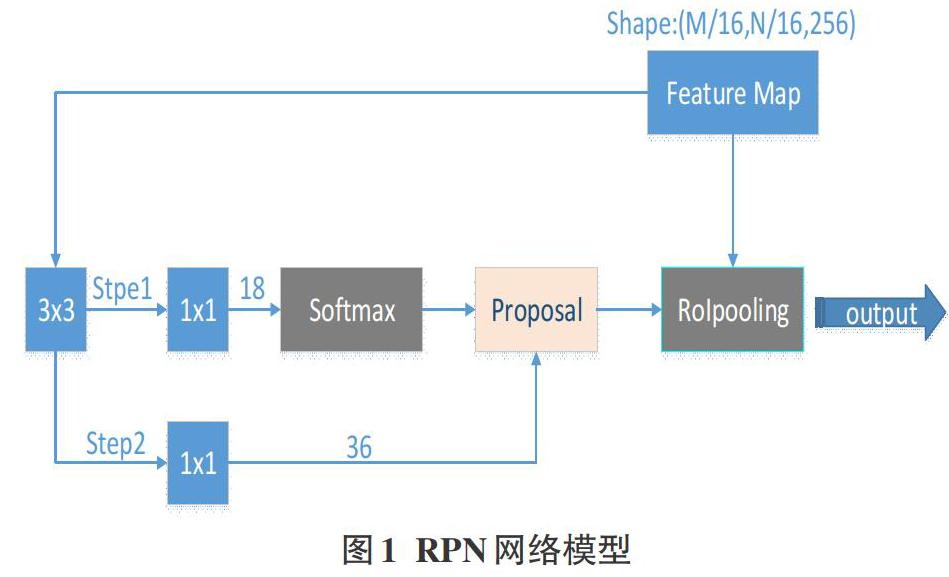
Faster RCNN是基于深度卷積神經(jīng)網(wǎng)絡(luò)的目標(biāo)檢測算法,主要解決兩個問題:1)提出區(qū)域建議網(wǎng)絡(luò)RPN,快速生成候選區(qū)域;2)通過交替訓(xùn)練,使RPN和Fast-RCNN網(wǎng)絡(luò)共享參數(shù)。其結(jié)構(gòu)如圖1所示。RPN用于預(yù)測輸入圖像中可能包含目標(biāo)的候選區(qū)域;Fast RCNN用于分類候選區(qū)域,并修正候選區(qū)域的邊界框。這兩個網(wǎng)絡(luò)使用共享的卷積神經(jīng)網(wǎng)絡(luò)來提取特征(訓(xùn)練模型使用的網(wǎng)絡(luò)為VGG16。Faster R-CNN主要的四個部分有:
1)特征提取層,用于提取圖片的特征,輸入為整張圖片,輸出為提取出的特征稱為feature maps;
2)RPN網(wǎng)絡(luò)(Region Proposal Network),用于推薦候選區(qū)域,這個網(wǎng)絡(luò)是用來代替之前的search selective的。輸入為圖片,輸出為多個候選區(qū)域,即預(yù)測框;
3)RoI pooling層,將不同大小的輸入轉(zhuǎn)換為固定長度的輸出;
4)回歸和分類,識別目標(biāo)類別,計算損失值對模型權(quán)重參數(shù)進行調(diào)整。
2.1特征提取層
特征提取層用于提取圖片的特征,特征圖被共享用于后續(xù)RPN(Region Proposal Network)層和全連接層,特征提取層選用的網(wǎng)絡(luò)為VGG16,VGG16由13個卷積層,3個全連接層,5個池化層構(gòu)成,具有簡單高效的特點,它的卷積層均采用相同的卷積核參數(shù),池化層也均采用相同的池化核參數(shù),能夠很大程度上減少了模型的參數(shù)數(shù)量,降低網(wǎng)絡(luò)復(fù)雜程度而且能夠很好地降低模型的過擬合程度。輸入圖片經(jīng)過Reshape操作統(tǒng)一變成M*N大小地圖片送入特征提取層,經(jīng)過VGG16網(wǎng)絡(luò)運算后輸出從圖片提取的多張?zhí)卣鲌D用于后續(xù)計算。
2.2 RPN網(wǎng)絡(luò)
RPN網(wǎng)絡(luò)(Region Proposal Network),如圖1,用于推薦候選區(qū)域。經(jīng)典的檢測方法如OpenCVadaboost使用滑動窗口+圖像金字塔生成檢測框、RCNN使用SS(Selective Search)方法生成檢測框,都非常耗時,而Faster RCNN則拋棄了傳統(tǒng)的滑動窗口和SS方法,直接使用RPN生成檢測框,這也是Faster RCNN的巨大優(yōu)勢,能極大提升檢測框的生成速度。RPN做兩件事:1)把feature map分割成多個小區(qū)域,識別出哪些小區(qū)域是前景,哪些是背景,簡稱RPN Classification;2)獲取前景區(qū)域的大致坐標(biāo),簡稱RPN bounding box regression。這個網(wǎng)絡(luò)實際分為2條線,上面的網(wǎng)絡(luò)分支通過softmax分類anchors獲得前景和背景;下面的網(wǎng)絡(luò)分支用于計算對于anchors的邊界框回歸的偏移量,以獲得精確的目標(biāo)候選區(qū)。
2.3 RoI pooling層
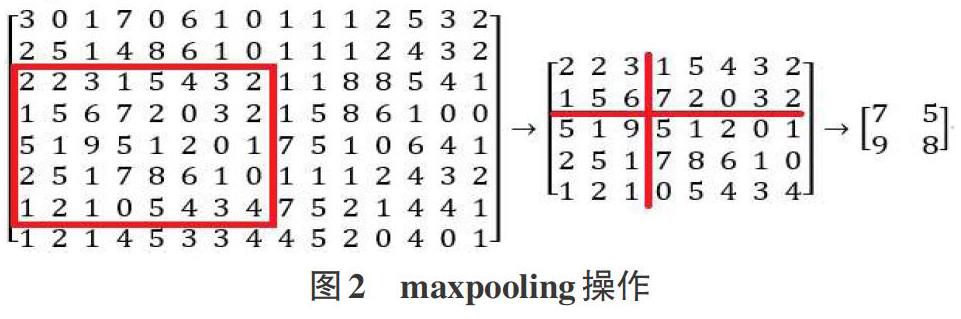
ROI(region of interest),感興趣區(qū)域即用于框出目標(biāo)的方框,該區(qū)域用向量[x,y,l,w]表示,(x,y)表示方框頂點坐標(biāo),l和w分別表示方框的長和寬。RoI Pooling層負(fù)責(zé)收集proposal(建議區(qū)域,即目標(biāo)方框),將proposal劃分為n*n塊子區(qū)域(n取決于RoI Pooling輸出矩陣大小),并通過maxpooling,如圖2,計算每個子區(qū)域的最大值,生成特定大小的特征圖proposal feature maps,送入后續(xù)網(wǎng)絡(luò)。具體計算流程如下(n取2)。
2.4回歸和分類
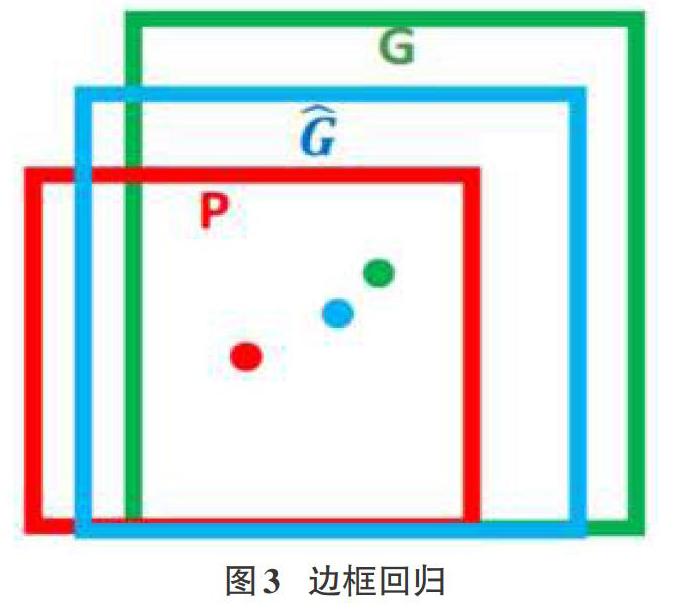
分類用于識別目標(biāo)類并用n*1大小的向量表示每個類別的概率,n表示類別數(shù)。回歸是指通過計算損失值對模型權(quán)重參數(shù)進行調(diào)整,模型預(yù)測效果更加準(zhǔn)確。邊框回歸,如圖3,是指對于窗口一般使用四維向量(x,y,w,h)來表示,分別表示窗口的中心點坐標(biāo)和寬高。對于圖3,紅色的框P代表原始的Proposal,綠色的框G代表目標(biāo)的Ground Truth,我們的目標(biāo)是尋找一種關(guān)系使得輸入原始的窗口P經(jīng)過映射得到一個跟真實窗口G更接近的回歸窗口G^。
3系統(tǒng)設(shè)計
該系統(tǒng)在Tensorflow-GPU框架下進行Faster R-CNN神經(jīng)網(wǎng)絡(luò)模型的訓(xùn)練,訓(xùn)練使用的數(shù)據(jù)集為VOC2007數(shù)據(jù)集,使用的網(wǎng)絡(luò)模型為VGG16,使用CUDA加速深度卷積網(wǎng)絡(luò)的訓(xùn)練,利用GPU強大的并行計算能力,處理神經(jīng)網(wǎng)絡(luò)訓(xùn)練時大量的矩陣運算,最后得到訓(xùn)練后的模型;在第一輪訓(xùn)練的基礎(chǔ)上,把VOC2007數(shù)據(jù)集進行擴展,把大量收集的教室監(jiān)控截圖通過Opencv進行數(shù)據(jù)增強操作,對圖片進行翻轉(zhuǎn)、切割、修改亮度和對比度等進行數(shù)據(jù)再擴充,并通過LabelImg進行標(biāo)圖,將其制作成數(shù)據(jù)集用于訓(xùn)練和測試。再次訓(xùn)練模型得到新模型,新模型更加適應(yīng)教室環(huán)境的目標(biāo)檢測。再通過Opencv調(diào)用設(shè)備的攝像頭進行視頻流數(shù)據(jù)輸入,加載二次訓(xùn)練得到的新模型并將視頻流分割成圖片流并輸入進行目標(biāo)檢測,再將結(jié)果圖片拼湊轉(zhuǎn)換成視頻流輸出。程序流程圖如圖4所示。
在教室環(huán)境下由于相互遮擋和密集度大的問題嚴(yán)重,原始的訓(xùn)練模型不能很好地識別困難目標(biāo),通過收集大量教室監(jiān)控截圖并進行Data Augmentation數(shù)據(jù)增強來進一步擴大樣本,提高識別準(zhǔn)確度。
4模型訓(xùn)練
模型訓(xùn)練的目的是通過大量的數(shù)據(jù)來不斷循環(huán)迭代進行參數(shù)權(quán)重調(diào)整,從而在獲得最優(yōu)的權(quán)重參數(shù)使其在真實情況下獲得更高的準(zhǔn)確率。本文的模型訓(xùn)練方法為四部訓(xùn)練法(也稱聯(lián)合訓(xùn)練):1)單獨訓(xùn)練RPN網(wǎng)絡(luò),網(wǎng)絡(luò)參數(shù)由預(yù)訓(xùn)練模型載入;2)單獨訓(xùn)練Fast-RCNN網(wǎng)絡(luò),將第一步RPN的輸出候選區(qū)域作為檢測網(wǎng)絡(luò)的輸入;3)再次訓(xùn)練RPN,此時固定網(wǎng)絡(luò)公共部分的參數(shù),只更新RPN獨有部分的參數(shù);4)那RPN的結(jié)果再次微調(diào)Fast-RCNN網(wǎng)絡(luò),固定網(wǎng)絡(luò)公共部分的參數(shù),只更新Fast-RCNN獨有部分的參數(shù)。訓(xùn)練通過反向傳播進行神經(jīng)元權(quán)重參數(shù)調(diào)整,神經(jīng)網(wǎng)絡(luò)反向傳播流程圖如圖5所示。
在模型訓(xùn)練中往往會出現(xiàn)過擬合,使得模型在訓(xùn)練集上獲得非常高的準(zhǔn)確率但在新的測試集上準(zhǔn)確率反而大大下降,即訓(xùn)練出的模型泛化性弱,不是一個好模型。神經(jīng)網(wǎng)絡(luò)模型訓(xùn)練的三種情況如圖6所示。
為了避免過擬合的問題,使用了L1正則化方法(regularization)同時使用Dropout隨機忽略一部分神經(jīng)元。正則化的思想就是在損失函數(shù)中加入刻畫模型復(fù)雜程度的指標(biāo)。神經(jīng)網(wǎng)絡(luò)模型的效果以及優(yōu)化的目標(biāo)是通過損失函數(shù)(lossfunction)來定義的。
FasterRCNN的的損失主要分為RPN的損失和Fast RCNN的損失,并且兩部分損失都包括分類損失(cls loss)和回歸損失(bbox regression loss)。使用的損失函數(shù)為Smoooh L1 Loss,計算公式如下:
上式中分類的損失值是在RPN層中計算的,是前景的softmax結(jié)果,由于[Lcls]和[Lreg]結(jié)果差距過大,引入k平衡二者的值。
Faster R-CNN用于處理多分類任務(wù),所以簡單的線性二分類不適用。為了解決這個問題,使用激活函數(shù)來實現(xiàn)去線性化。激活函數(shù)往往是非線性函數(shù),在卷積神經(jīng)網(wǎng)絡(luò)VGG16的每個神經(jīng)元的輸出經(jīng)過一個激活函數(shù)處理使其呈現(xiàn)非線性化,從而使得整個神經(jīng)網(wǎng)絡(luò)的模型也就不再是線性的了。常用的激活函數(shù)有ReLU激活函數(shù)(如圖7)、sigmoid激活函數(shù)、tanh激活函數(shù),而ReLU激活函數(shù)更適用于深層卷積神經(jīng)網(wǎng)絡(luò),故選擇ReLU作為網(wǎng)絡(luò)的激活函數(shù)。
5測試
在神經(jīng)網(wǎng)絡(luò)模型中,往往通過mAP (Mean Average Precision),平均精確度來測量模型的預(yù)測精度。原始模型的mAP和擴充數(shù)據(jù)后進行再訓(xùn)練得到的模型mAP數(shù)據(jù)對比如下表1所示。
由此可見隨著訓(xùn)練輪數(shù)的增加,模型的準(zhǔn)確度再不斷上升,且經(jīng)過40000輪訓(xùn)練后對比發(fā)現(xiàn),使用VOC2007數(shù)據(jù)集經(jīng)過訓(xùn)練得到的模型在教室這種特定的環(huán)境下模型mAP最高值為79.60%,經(jīng)過數(shù)據(jù)增強后擴展原始VOC2007數(shù)據(jù)集能提升模型的mAP最高值為83.43%,提高了4.83%,模型的預(yù)測效果更好。
用原始模型和擴充數(shù)據(jù)集再訓(xùn)練后的識別效果對比圖如圖10所示。(圖10-a、10-b為用原始模型進行目標(biāo)檢測)
對比可知,對原始VOC2007數(shù)據(jù)集進行數(shù)據(jù)增強后的數(shù)據(jù)集擴充能夠使模型更好地適應(yīng)教室環(huán)境下的目標(biāo)檢測,識別的人數(shù)和準(zhǔn)確值都有所提升。
6 結(jié)束語
由于本系統(tǒng)是針對教室這種頻繁出現(xiàn)目標(biāo)重疊、目標(biāo)密度大的復(fù)雜環(huán)境進行目標(biāo)檢測,通過Faster R-CNN在原始的VOC2007數(shù)據(jù)集上進行訓(xùn)練得到的模型并不能夠很好地適應(yīng)教室環(huán)境,所以通過收集大量教室監(jiān)控的截圖并通過Opencv對圖片進行數(shù)據(jù)增強處理,然后通過LabelImg標(biāo)圖來擴展數(shù)據(jù)集,并再次訓(xùn)練模型,使模型更能適應(yīng)特定環(huán)境。經(jīng)過實驗發(fā)現(xiàn),針對特定環(huán)境采用大量該環(huán)境下的圖片通過數(shù)據(jù)增強處理來擴充數(shù)據(jù)集,能夠提升訓(xùn)練出的模型在特定環(huán)境下的識別準(zhǔn)確度。
參考文獻:
[1] Ren SQ,He KM,Girshick R,etal.Faster R-CNN:towards real-time object detection with region proposal networks[J].IEEE Transactions on Pattern Analysis and Machine Intelligence, 2017,39(6):1137-1149.
[2] Breiman, L.Bagging predictors.Maching Learning, 1996,24(2):123-140.
[3] Breiman, L.Randomizing outputs to increase prediction accuracy.Maching Learning, 2000,45(3):113-120.
[4] Murthy S K,Kasif S,SalzbergS.A system for induction of oblique decision trees[J].Journal of Artificial Intelligence Research, 1994,2:1-32.
[5] Felzenszwalb P F,Girshick R B,McAllester D,etal.Object detection with discriminatively trained part-based models[J].IEEETransactionson Pattern Analysis and Machine Intelligence, 2010,32(9):1627-1645.
[6] Utgoff, P.E., N.C. Berkman, and J.A. Clouse.(1997). “decision tree induction based on efficient tree restructuring.” Machine Learning, 29(1):5-44.
[7] Valiant L G.A theory of the learnable[J].Communications of the ACM, 1984,27(11):1134-1142.
【通聯(lián)編輯:唐一東】
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
中學(xué)生數(shù)理化·七年級數(shù)學(xué)人教版(2021年6期)2021-11-22 07:50:58
中學(xué)生數(shù)理化·七年級數(shù)學(xué)人教版(2021年6期)2021-11-22 07:50:58
中學(xué)生數(shù)理化·七年級數(shù)學(xué)人教版(2021年6期)2021-11-22 07:50:58
中學(xué)生數(shù)理化·七年級數(shù)學(xué)人教版(2020年10期)2020-11-26 08:24:50
數(shù)學(xué)物理學(xué)報(2020年2期)2020-06-02 11:29:24
光學(xué)精密工程(2016年6期)2016-11-07 09:07:19
海峽科技與產(chǎn)業(yè)(2016年3期)2016-05-17 04:32:12
中國科技博覽(2016年2期)2016-04-25 20:32:39
小學(xué)生導(dǎo)刊(2016年34期)2016-04-11 00:49:44
