科學合作網絡姓名消歧問題研究*
2020-10-09 01:12:26王曼玲宗曉麗韓紅旗
甘肅科技 2020年16期
張 龍 ,付 媛 ,王曼玲 ,宗曉麗 ,韓紅旗
(1.甘肅省科學技術情報研究所,甘肅 蘭州 730000;2.中國科學技術信息研究所,北京 海淀100038;3.西北師范大學,甘肅 蘭州 730070;4.甘肅政法學院,甘肅 蘭州 730070)
1 概述
目前,使用搜索引擎查詢自己所需要的信息已經成為現代人工作和生活必不可少的一部分,而從海量數據中高效快速地返回用戶感興趣的內容成為信息檢索的重要挑戰,同時用戶對搜索引擎的查準率和查全率也提出了更高的要求。搜索人物姓名相關信息是用戶搜索的重要方式之一,也是用戶在互聯網搜索的主要目的之一,據統計在搜索引擎查詢中對人名的搜索和查詢請求約占5%~10%,是信息查找的關鍵點。然而,據美國人口調查報告顯示,有10億人卻僅僅用了90000個不同的名字。在我國,重名現象也非常嚴重,全國公民身份信息系統中姓名為“張偉”的就有299025人。重名現象的普遍性導致了互聯網文本中姓名歧義現象嚴重,搜索結果并未對有歧義的人名進行有效的信息組織,用戶需要花費大量時間從重名人物中篩選出自己感興趣的人物信息。如何挖掘到包含有相同姓名文本之間的聯系,有效地解決姓名歧義問題,并提供可視化展示,是大數據時代人工智能領域里自然語言處理所面臨的重要挑戰。為此,姓名消歧成為了近年來國內外學者的研究熱點之一[1]。當前科研文獻數據量急速增長,如何有效地消除文獻著者中文姓名歧義尤為重要。
2 姓名消歧方案設計
2.1 消歧方案基本流程
文獻著者姓名消歧是將同名作者發表的文獻對應到相應人物實體的過程,該過程也是一篇文獻被若干個同名作者認領的過程,最終目的是每個作者認領各自的作品,對于無人認領的作品,在數據庫中新增該同名作者。從文獻特征消歧順序和語義指紋的認領決策兩個方面進行優化,設計了以下基于語義指紋的姓名消歧方案,基本流程如圖1所示。
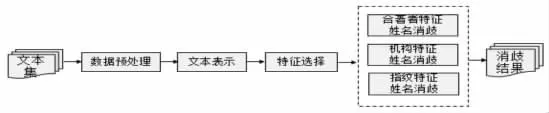
圖1 姓名消歧方案基本流程
2.2 語義指紋生成方案設計
以文本特征為基礎,將高維的對象轉換為二進制碼,相似對象擁有相似的指紋信息,其中Charikar提出的SimHash算法被認為是生成指紋最好的算法[2]。SimHash算法把文本特征轉化為二進制指紋值,指紋距離的大小除了能表示原始內容是否相等的信息外,還能通過指紋距離大小判斷原始文本的相似度,進行文本相似度計算,降維得到的64位指紋的相似度能夠同原始文本特征的相似度保持一致,體現了語義指紋的語義性。語義指紋生成流程如圖2所示,輸入PDF格式的文獻文本,輸出二進制指紋值,指紋生成過程主要包括6個步驟:格式轉換、中文分詞、求Hash值、Hash值加權、結果合并、降維,SimHash算法原理如圖3所示。
中文分詞:對文獻全文文本進行分詞,去除停用詞,作為文本特征,得到有效的特征向量,并根據TF-IDF確定特征詞的權重,詞語的權重代表詞的重要程度,權重越大代表詞越重要。
求Hash值:對每一個特征,利用Hash函數計算特征向量的Hash值,得到二進制數表示的32位或64位簽名,將字符串轉化為二進制數。
Hash值加權:對特征向量的Hash值加權,如果64位二進制哈希值的某一位數為1,則這一位Hash值加權為正權值,如果64位二進制哈希值的某一位數為0,則這一位Hash值加權為負權值,得到每個特征向量的Hash值加權。
合并:將各個特征向量的Hash值加權結果進行累加,得到一個序列串。
降維:對特征向量的Hash值加權累加結果的序列串進行降維,每一位如果大于0,則置為1,否則變為0,從而得到該文本的SimHash指紋值。
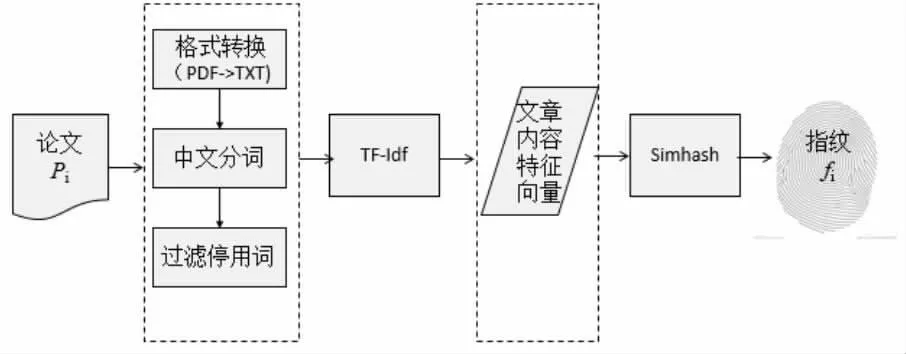
圖2 語義指紋生成方案設計
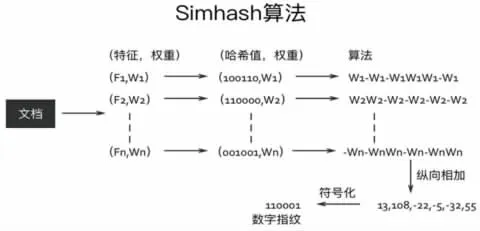
圖3 SimHash算法原理
2.3 指紋比較方案設計
選擇合著者特征、作者機構特征和文本語義指紋特征,融合設計了指紋比較器。在綜合特征姓名消歧指紋比較器中,語義指紋相似性通過海明距離度量,即兩個指紋值相差的位數[3];文獻合著者和作者機構通過字符串匹配;新論文的指紋fi與庫中已分類的作者指紋fx作對比,并合成一個H(i,x)三元組,前兩個分量分別為合著者相似度、作者單位相似度,分量的值在0與1之間,0表示合著者或者作者單位不同,1表示有相同的合著者,作者單位相同,第三個分量為文本語義指紋距離。指紋比較器如圖4所示,工作步驟如下:
1)當兩篇同名作者的文獻有相同姓名的合著者時,這兩篇文獻確定為同一個作者,將該論文分配給該作者;
2)當兩篇同名作者的文獻無相同的合著者但作者單位具有較大的相似性時,比較兩篇文獻的指紋距離,當指紋距離小于δ3時,這兩篇文獻確定為同一個作者,將該論文分配給該作者;
3)當兩篇文獻既無相同的合著者,也不屬于同一個作者單位時,則通過兩篇文獻的指紋相似度來判斷,當指紋距離小于δ1時,這兩篇文獻確定為同一個作者,將該論文分配給該作者,當指紋距離在(δ1,δ2)之間,則無法確定為同一個作者,需要進行下一步的認領決策。
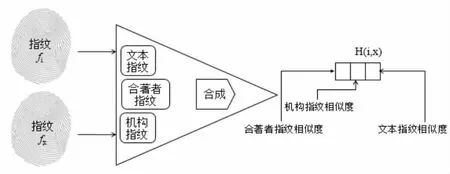
圖4 指紋比較方案設計
2.4 認領決策方案設計
一篇新的論文指紋與同名作者的N篇文獻的指紋作對比后得到了N個指紋距離,認領決策器開始工作,圖5為一篇新論文找一個作者認領的過程。
1)當比較結果指紋距離小于δ1時,兩篇文獻確定為同一個作者,將該論文分配給該作者;
2)比較結果指紋距離輸出值 H(x)在(δ1,δ2)(δ1,δ2為設定的閾值,本研究實驗中 δ1=18,δ2=25)的個數為 n,若 n/N>24%,則決策器輸出為Yes,則該論文被該作者認領;
3)否則,決策器輸出為No。
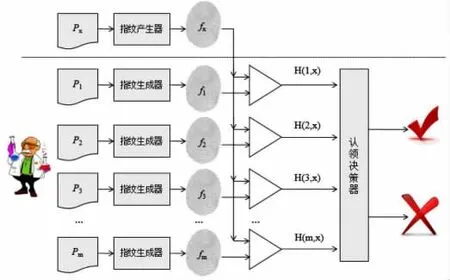
圖5 認領決策方案設計
2.5 作品指派方案設計
一篇新的文獻在每一個作者認領后,可能存在如下結果,如圖6所示:
1)當只有一位作者認領時,將該論文指派為該作者的作品;
2)當存在兩位或兩位以上作者認領該文獻時,由爭議仲裁器仲裁,仲裁后將該論文指派給其中的一位作者;
3)當無人認領該文獻時,該文獻是一位新的同名作者的作品,將其指派給新的作者。
當一篇文獻同時被幾位作者認領,出現爭議時,爭議仲裁器工作過程如下:
當存在多個認領作者時,仲裁器才起作用,不失一般性,假設作者a1和a2競爭,考察兩個作者的決策器中各比較器的輸出值,各個指紋距離和的平均值[4]。若∑H(a1)/Na1<∑H(a2)/Na2,則將該論文指派給作者a1,否則指派給a2。
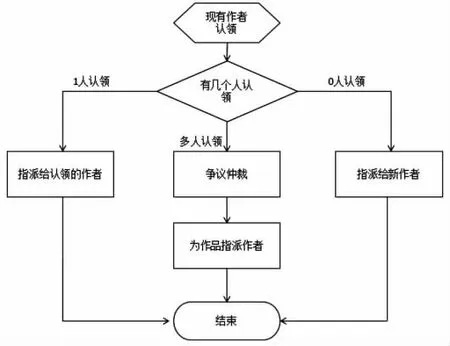
圖6 作品指派方案設計
3 消歧實驗數據構建
文獻數據庫中海量的文獻數據,并不適合直接用來測試消歧方法,需要選取有代表性的部分文獻數據,構建文獻測試數據樣本集,來評價姓名消歧方法的有效性,本研究的文獻數據來源于萬方數據。文獻中一般包含標題、作者、合著者、作者機構、期刊、日期、摘要、關鍵詞、作者郵箱、全文等特征,但并非所有特征都適應于姓名消歧,需要篩選出具有較強消歧能力的特征[5]。為了驗證姓名消歧方法的有效性,需構建一個包含待消歧作者姓名的文獻數據集,應該具有以下特征:
1)首先選取重名較多的常用作者名的文獻,同時也要包含使用頻率較少的作者名的文獻;
2)不同作者發表的文獻數不同,既包含發表文獻數量多的作者,也包含發表文獻數量較少的作者;
3)需要涵蓋全面的合著類型文獻,既要包含合著文獻,也要包含作者獨著文獻;
4)需要涵蓋不同的作者單位類型,有的作者所屬單位只有一個,有的作者在多個單位就職,發表的多篇文獻中的所屬單位可能有多個;
5)作者發表文獻領域的分布,有的作者所發表的文獻屬于一個研究領域,而有的作者發表的文獻涉及多個領域。
綜合上述條件,構建了具有代表性的文獻數據集。在萬方數據中選取作者名為“李建軍”、“李軍”、“王琳”等7個名字,下載全文PDF格式數據845條。每個作者名代表了一類型的作者,如“李建軍”代表的是重名作者較多的一類,本數據集中共包含該姓名的實際作者數為14,且包括了合著者文獻和作者獨著文獻。“王偉”也是重名作者較多的一類,本數據集中共包含該姓名的實際作者數為9人,其中同屬于大連理工大學的就有3人,其中的一個作者“王偉”同時在同濟大學土木工程防災國家重點實驗室、上海巖石工程勘察設計研究院以及上海市閔行區建設工程安全質量監督站兼職,是一個作者屬于多個機構的類型。“吳雁林”代表個性化的辨識度較高的重名較少作者名,本測試集中僅包含該姓名的實際作者數為3,三人文獻數比較均衡。“張強”代表了少數作者包含較多文獻,其余重名作者所占文獻數較少的類型,本測試集中屬于該姓名的實際作者數為10人,北京理工大學的張強老師的文獻所占比例高達1/4,屬于文獻占比不均衡的一類。本研究構建的文獻數據樣本共標注了7個不同名字,分屬于68個不同的作者,見表1。
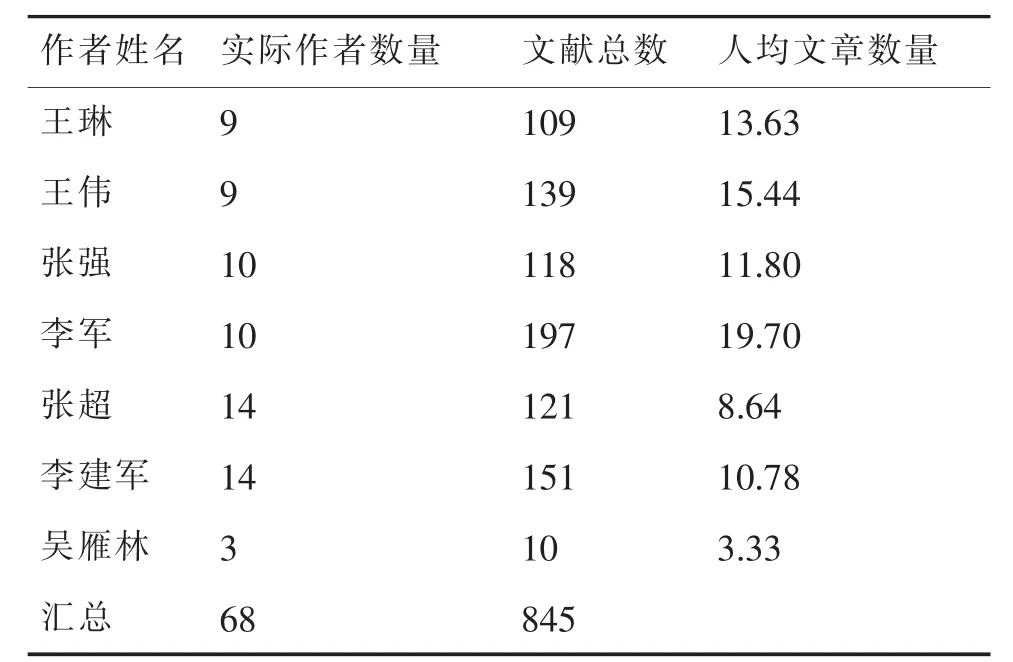
表1 文獻數據測試樣本集
文獻數據測試樣本集分為六個類型:重名較多型、生僻名型、文獻占比不均型、文獻占比均衡型、同一機構型、文獻稀疏型。文獻占比不均型指少數作者所占文獻占大多數,其余作者占少數文獻,在文獻數據庫中大多數重名都屬于這種情況。文獻占比均衡型指屬于每個作者的文獻數占比均勻。同一機構型指重名的不同作者屬于同一機構。有的作者包含多種類型,如“張強”同時屬于重名較多型和文獻占比不均型。如圖7為各個類型所占比例。
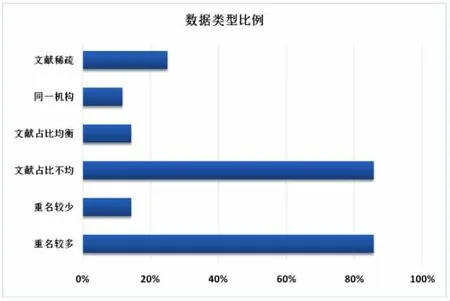
圖7 數據類型比例
4 姓名消歧實驗及結論
實驗數據源為之前構建的文獻數據集的測試數據,本實驗在Windows7操作系統下開發,各模塊采用Java編程語言編寫,編譯環境為eclipse,JDK1.8,利用MySQL數據庫存儲,并使用了較權威的漢語分詞系統NLPIR進行分詞,所有文獻以PDF格式存儲。采用準確率、召回率和F值對基于語義指紋的綜合特征姓名消歧方法進行評估。實驗結果見表2,綜合特征和單特征消歧對比如圖8所示。
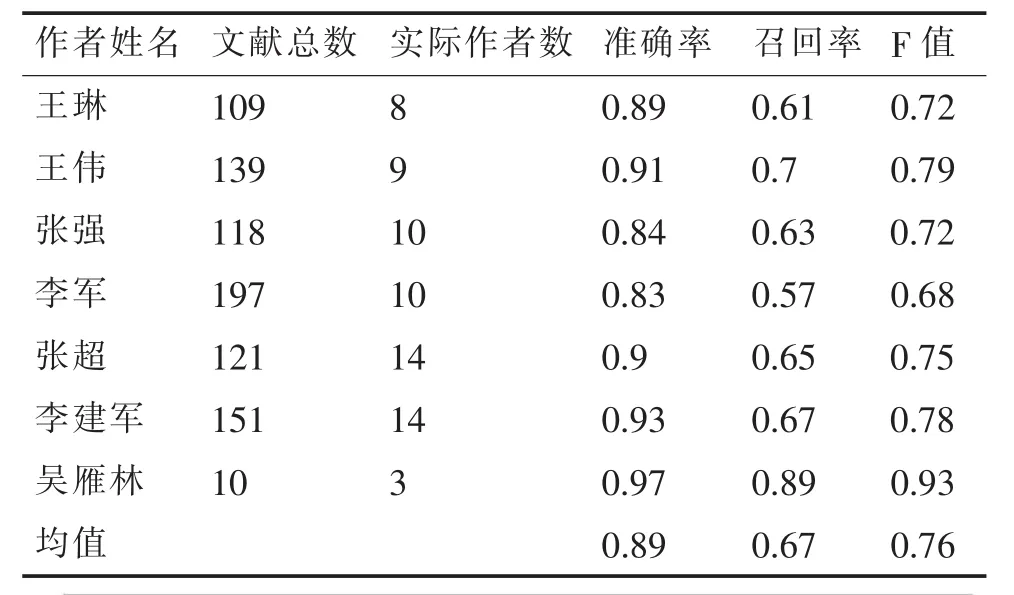
表2 基于語義指紋的綜合特征姓名消歧實驗結果
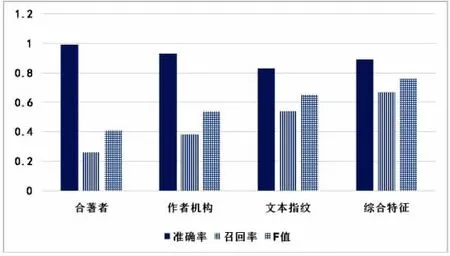
圖8 綜合特征和單特征姓名消歧對比
由圖8可知,基于語義指紋的綜合特征姓名消歧方法在整體效果上明顯好于獨立特征的姓名消歧方法,主要表現在綜合特征消歧的較高召回率上。雖然合著者特征和作者單位特征在可以達到較高的準確率,但是召回率卻很低,整體消歧效果并不好。
指紋單特征姓名消歧的準確率較低而召回率較高,前者是將屬于一個作者的多篇文獻分為多個作者,而后者是將幾個不同作者的文獻歸為一個作者,所以幾個特征可以進行優勢互補。基于語義指紋的文獻著者姓名消歧方法使整體效果有所提升和改善,但準確率比合著者單特征和作者單位單特征消歧低。綜合特征姓名消歧,避免了只從合著者、作者單位、語義指紋,單方面的局限性,造成的消歧結果出現較低的召回率或者較低的準確率,同時融合了獨立特征的消歧結果,有效地提高了姓名消歧的召回率,也確保了相對較高的準確率。
猜你喜歡
開放教育研究(2020年2期)2020-03-31 01:54:14
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
制造技術與機床(2019年10期)2019-10-26 02:48:08
當代陜西(2019年10期)2019-06-03 10:12:04
電子制作(2018年18期)2018-11-14 01:48:06
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
現代語文(2016年21期)2016-05-25 13:13:44
小學教學參考(2015年20期)2016-01-15 08:44:38
大連民族大學學報(2015年2期)2015-02-27 08:28:11
語文知識(2014年1期)2014-02-28 21:59:13
