基于卷積神經網絡的抽油機故障診斷
2020-10-15 01:50:58劉志剛宋考平楊二龍
電子科技大學學報 2020年5期
杜 娟,劉志剛,*,宋考平,楊二龍
(1. 東北石油大學計算機與信息技術學院 黑龍江 大慶 163318;2. 東北石油大學石油與天然氣工程博士后工作站 黑龍江 大慶 163318;3. 中國石油大學非常規油氣研究院 北京 昌平區 102249)
由于井下地層因素復雜,抽油桿柱運動到井下抽油泵的過程中存在許多不明因素均易引發抽油機故障,降低生產抽油效率,甚至造成油井安全事故。載荷(P)和位移(S)是抽油機驢頭在上下往復運動時產生的參數,二者構成的閉合曲線即為示功圖,它可實時反映氣、油、水、砂、蠟等井內因素對抽油機工況的影響[1],因此基于示功圖的抽油機故障診斷是數字化油田中一項重要研究內容。
抽油機狀態采集頻繁,傳統示功圖人工分析法需要消耗大量的人力、物力,且受專業經驗影響而難于推廣。人工神經網絡(artificial neural network,ANN)具有良好的非線性逼近能力,BP 神經網絡[2-3]、RBF[4]、小波神經網絡[5]、極限學習機[6]、自組織神經網絡[7-8]等模型相繼被應用到抽油機故障診斷中,正逐步取代傳統的人工分析。但受限于模型的內部機制,這些方法存在以下不足:1) 特征提取時直接將示功圖的上百個位移?載荷數據對作為輸入,造成神經網絡模型內部映射結構復雜,嚴重影響模型的診斷精度;2) 故障診斷是以示功圖輪廓特征為基礎,而位移?載荷的直接點對點的輸入神經網絡模型,無法有效提取示功圖的輪廓特征。
近年來,隨著大規模數據集的不斷涌現和計算機GPU 計算能力的不斷提高,以卷積神經網絡(convolutional neural networks, CNN)為代表的深度學習模型,如VGG-16[9]、ResNet[10]、DenseNet[11]等,已成為模式識別、目標檢測、語言處理等研究領域的研究熱點。自2018 年開始,文獻[12-14]嘗試應用CNN 進行抽油機故障診斷的探索性研究,取得了較好的應用效果。但直接應用CNN 診斷工況存在如下問題:1) CNN 模型計算密集、參數數量龐大,訓練需耗費極大的GPU 計算資源,需要較大的存儲和運行內存,而部分抽油機工況檢測設備的硬件性能和功耗較低,直接運行此模型難度較大;2)部分工況示功圖輪廓特征區分度較低,如氣體影響、供液不足、固定漏失、游動漏失等,直接卷積提取輪廓特征的診斷精度并不理想。
通過CNN 診斷抽油機故障需要重點研究的問題:1) 有效提取示功圖的輪廓特征,并加強對區分度高的輪廓特征提取;2) 降低模型存儲,提高模型的適用性。為此,本文采用深度分離卷積作為CNN特征提取的基礎架構,提出一種正則化注意力卷積模塊,該模塊可以嵌入到CNN 的任意兩個連續卷積層中,通過通道壓縮、注意力和通道失活,實現特征加強和抑制;其次,提出一種注意力損失函數使得模型訓練關注難分的示功圖樣本,進一步提高模型的診斷能力。為方便表述,將上述過程構建的CNN 命名為輕量注意力卷積神經網絡(lightweight attention convolutional neural network, LA-CNN)。仿真實驗通過油田某礦的抽油機工況數據集對模型有效性進行驗證。
1 深度分離卷積
深度分離卷積[15]通過深度卷積和點卷積,將標準卷積通道和空間的聯合映射分離成二者單獨映射,有效減少模型參數數量和空間存儲。2017 年,Google 引入深度分離卷積,提出MobileNet-V1[16],其模型參數僅為4.2 MB,存儲空間為17 MB,適用低功耗的嵌入式便攜設備。2018 年,Google 進一步提出MobileNet-V2[17]。為方便描述,記卷積核為(DK,DK,C),其中卷積核的寬、高一致,統一用DK表示, C為通道。深度分離卷積是將原有跨通道計算的 N個(DK,DK,M)標準卷積轉成轉換成 M個(DK,DK,1)的深度卷積和跨通道的 N個(1,1,M)的點卷積。記輸入特征圖為{DF,DF,M},輸出特征圖為{DF,DF,N},其中 DF為特征圖的寬和高,則各卷積計算量如下:
1) 標準卷積為:
count0=DKDKMNDFDF
2) 深度卷積為:
count1=DKDKMDFDF
3) 點卷積為:
count2=MNDFDF
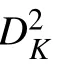
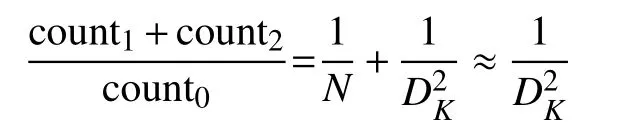
2 輕量注意力卷積神經網絡LA-CNN
近年來,仿照人類感知系統的注意力機制可快速、有效地定位目標信息,抑制無關信息和節省計算資源,是目前國內外研究的熱點問題,在細粒度識別[18-19]、目標檢測[20-21]、圖像描述[22-23]等領域均有應用。文獻[24]提出SENet,通過通道的壓縮、擴展完成注意力的計算,雖然在ImageNet 大規模數據集上的分類精度較高,但由于缺乏正則化機制,對于規模較小的抽油機工況數據集,卻容易出現過擬合。目前增強CNN 對小規模數據集泛化能力的重要方法是Dropout,隨機設置神經元的輸出或者連接權值為零,但該方法僅限于在全連接層中使用。卷積層的基本信息單位是通道,不是神經元,因此Dropout 并不適用于卷積層。
為此,為提高示功圖的輪廓特征提取,本文提出了一種可嵌入連續深度分離卷積層正則化注意力模塊,該模塊首先利用全局池化計算對上一個卷積層輸出特征圖中的每個通道進行壓縮,并引入一個全連接層來構建通道注意力向量;然后計算通道選擇掩碼,建立適用于通道的正則化機制,完成通道的失活。模塊的具體結構如圖1 所示。
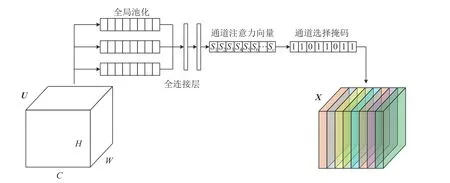
圖1 嵌入兩個連續深度分離卷積層的正則化注意力模塊
2.1 正則化注意力卷積模塊
1) 通道聚合
使用最大、平均和隨機3 種全局池化,沿通道方向壓縮特征圖的每個通道空間維度,從多個角度完成空間信息的聚。為方便描述,記上一個深度分離卷積輸出特征圖為U=[u1,u2,···,uC],ui∈RH×W,C為通道數,H 和W 分別為特征圖的高和寬。按全局最大池化,將每個 ui壓縮到通道注意力分量smax,具體定義為:
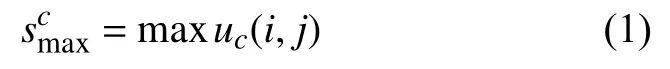
按全局平均和隨機池化的計算,分別壓縮每個ui到通道注意力分量smean和 ssto中,這兩個分量的具體定義為:
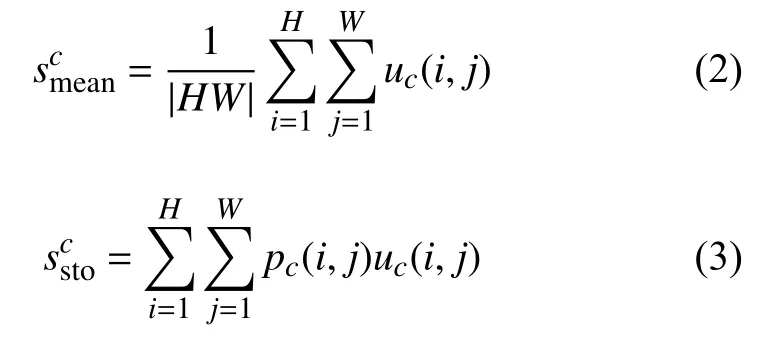
式中,pc(i,j)為通道中某元素的選擇概率:
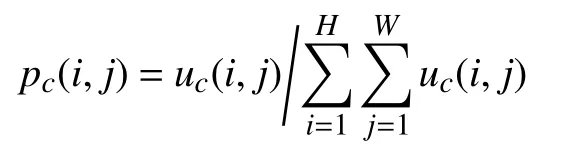
2) 通道注意力
將通道注意力分量smax、 smean和 ssto作為全連接層的輸入,通過與權值參數的逐點相乘、累加和激活函數完成聚合,進一步增加非線性,并通過模型訓練不斷更新、計算每個通道對樣本的注意力。因此,通道注意力s=[s1,s2,···,sC]的定義如下:
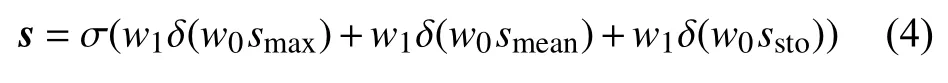
式中, σ是sigmoid 函數; δ是ReLu 函數; w0和w1為全連接層的權值,這些參數對于3 個通道注意力分量是共享的。
3) 通道正則化
根據通道注意力構建通道注意力掩碼m=[m1,m2,···,mC],其中掩碼 mi標識某通道是否被激活,第i個通道被選擇的概率定義為:

如果某通道選擇概率 pi大于隨機選擇概率,則通道被激活,否則失活。即通道的選擇概率越大,則通道越容易被激活。因此,掩碼 mi可定義為:
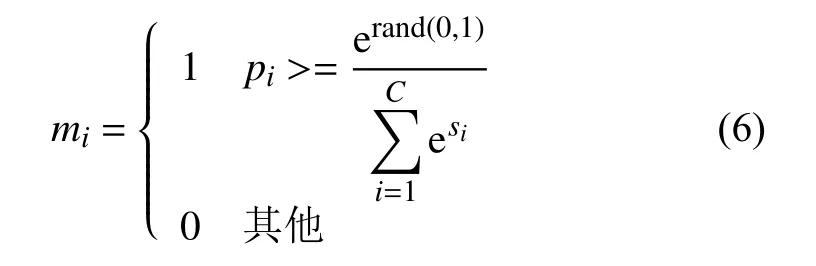
4) 正則化注意力特征圖
根據通道注意力s和 通道注意力掩碼 m,在原始特征圖 U的基礎上,構建正則化注意力特征圖X ∈RC×H×W,具體定義為:

式中, ?代表逐點相乘。
2.2 注意力交叉熵損失函數
在抽油機工況數據集中,出砂、桿斷、活塞脫出、正常等工況的示功圖輪廓特征區分較為明顯,具體如圖2 所示。這些樣本在模型訓練過程中較易識別正確,而氣體影響、供液不足的示功圖特征較為相近,診斷錯誤率較高。由于易分樣本對模型的訓練貢獻較小,難分樣本較大地影響著模型訓練和后期的診斷精度,因此模型訓練應較多的關注此類樣本。
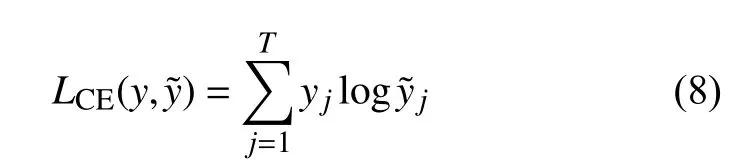
標準CNN 訓練使用的交叉熵損失函數為:式中, y 是樣本的實際類別; y?是樣本在全連接層的Softmax 輸出; T是樣本的類別數。
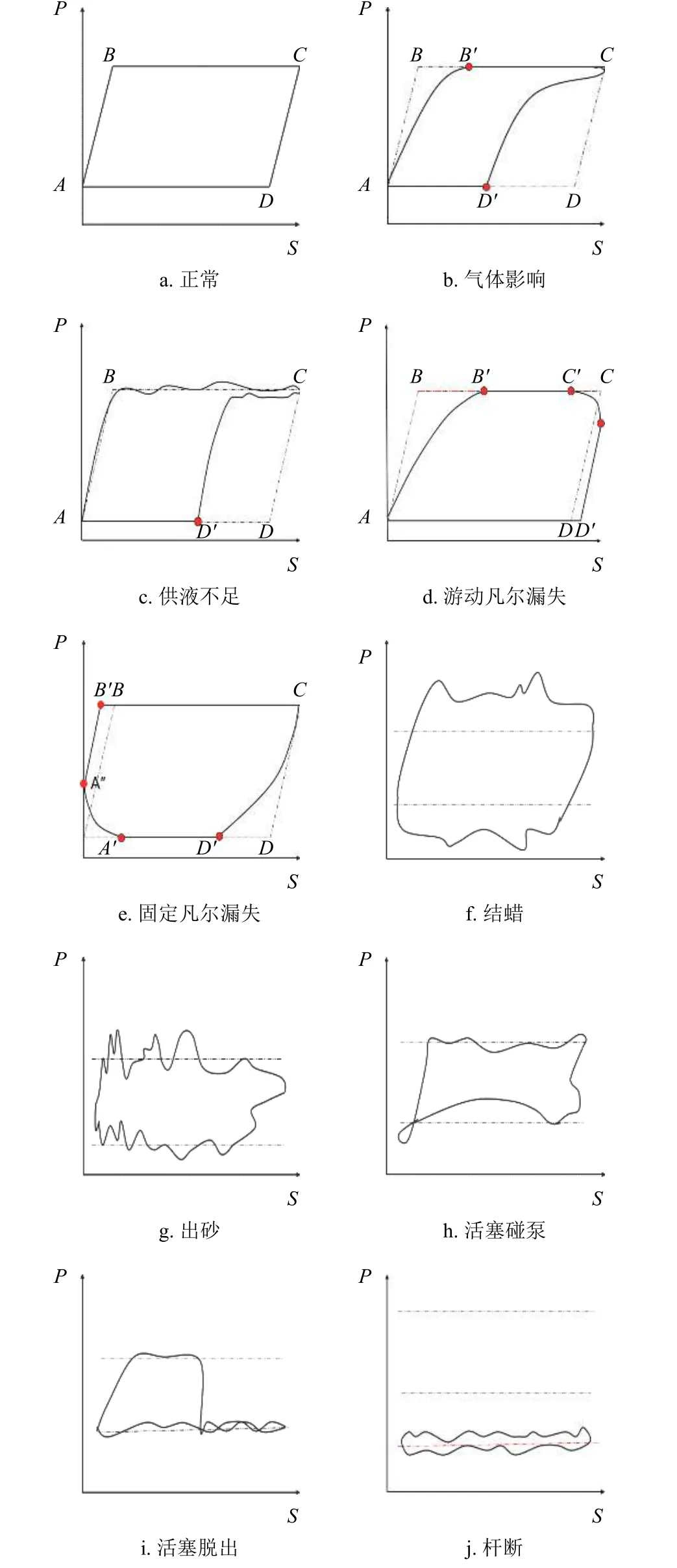
圖2 10 種常見的抽油機工況對應的示功圖
根據式(8),交叉熵損失函數無法有效區分難分樣本和易分樣本,所有樣本在訓練中被等同對待,若易分樣本數量高于難分樣本,導致模型訓練時難分負樣本被易分正樣本“淹沒”。本文受注意力機制啟發,提出了注意力損失函數,定義為:
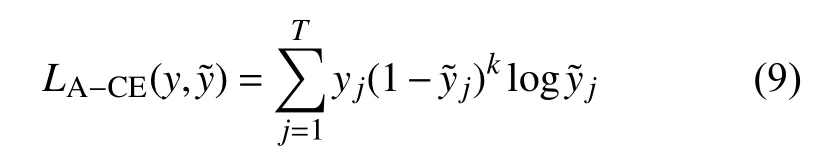
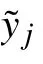
3 仿真實驗
3.1 工況數據集
本文實驗對10 種常見的抽油機工況進行診斷,具體包括:正常、固定凡爾漏失、游動凡爾漏失、桿斷、出砂、結蠟、活塞碰泵、活塞脫出、氣體影響、供液不足,每種示功圖如圖2 所示。選取大慶油田某油礦40 臺抽油機的示功圖樣本25 963 個,每個樣本對應工況已在生產過程中通過人工標注完成。為保持樣本平衡,本文實驗對故障工況的樣本進行數據增強,方法包括位移載荷偏移、旋轉、平移,最后樣本集共包含工況樣本18 500 個。模型訓練過程中,采用5-fold 交叉驗證,即工況樣本集平均分成5 份,每次取其中4 份作為訓練集,剩余1 份作為測試集。實驗過程中將示功圖的載荷、位移繪制成示功圖,然后轉換為224×224 像素圖像。
3.2 實驗結果及分析
本文為驗證LA-CNN 有效性,對比模型包括VGG-16[9]、ResNet-50[10]、MobileNet-V1[16]和MobileNet-V2[17],其中前兩種是經典CNN,后兩種是輕量CNN。此外還與其他示功圖工況診斷方法對比,包括文獻[3]的BP 網絡診斷法、文獻[25]的UKFRBF 診斷法。表1 為不同CNN 模型的訓練時間和抽油機故障診斷精度對比。
實驗結果表明:1) 在硬件資源和功耗較低的抽油機故障檢測設備上,很難直接運行深度學習模型VGG-16 和ResNet-50;2) 在模型存儲上,使用深度分離卷積的MobileNet-V1,MobileNet-V2 和本文的LA-CNN 模型相對于深度學習模型VGG-16 均縮減了近50 倍左右,LA-CNN 相對于模型MobileNet-V1,幾乎沒有變化;3) 在模型精度上,MobileNet-V1 和MobileNet-V2 模型的故障診斷精度相對較低,分別為87.5%和88.8%,不能很好地滿足故障診斷實際要求。但引入注意力的機制后,LA-CNN 的診斷精度比MobileNet 模型有明顯的提高,達到95.1%,僅比VGG-16 的診斷精度低0.6 個百分點,滿足抽油機故障診斷的精度要求;4) 淺層神經網絡診斷示功圖存在精度較低的不足,如文獻[3]和文獻[25]的BP和RBF,主要受限于模型輸入無法有效體現載荷和位移的映射關系,示功圖輪廓的表征特征魯棒性較差。
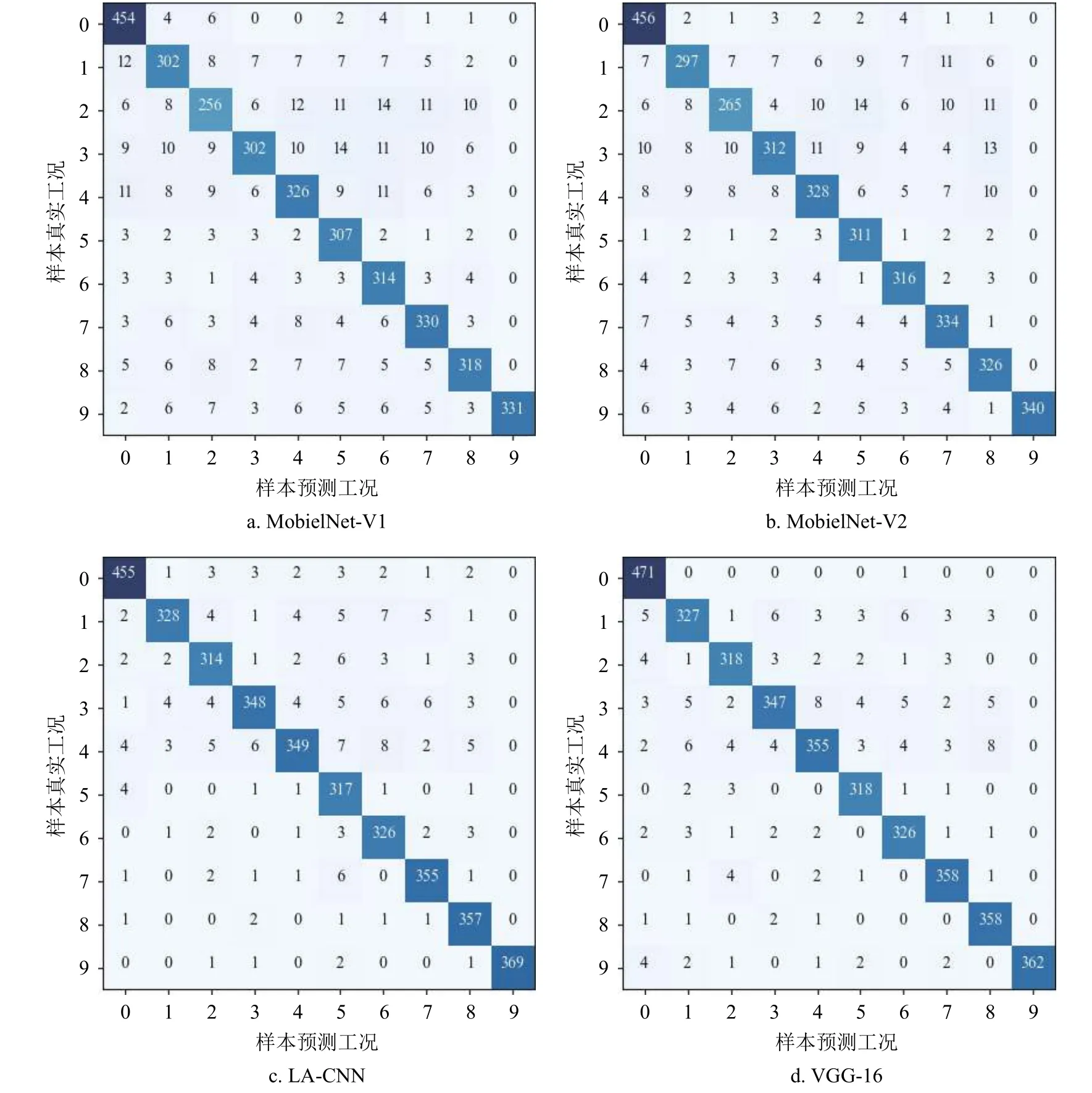
圖3 不同模型診斷抽油機故障的混淆矩陣對比
本文LA-CNN 模型在不同測試數據集上的每種工況的診斷結果如表2 所示,可明顯看出LACNN 在抽油機的大多數工況上都獲得了較高的診斷準確率,其中正常、供液不足、結蠟、出砂、活塞碰泵、活塞脫出、桿斷的診斷精度均超過94%。圖3 為MobielNet-V1、MobielNet-V2、VGG-16 和LA-CNN 的抽油機故障診斷結果的混淆矩陣對比,其中坐標軸0~9 依次代表正常、氣體影響、供液不足、固定凡爾漏失、雙凡爾漏失、結蠟、出砂、活塞碰泵、活塞脫出、桿斷,縱軸表示樣本的真實工況標簽,水平軸表示樣本的預測標簽,對角線則表示測試集中各種工況樣本診斷正確的數量。
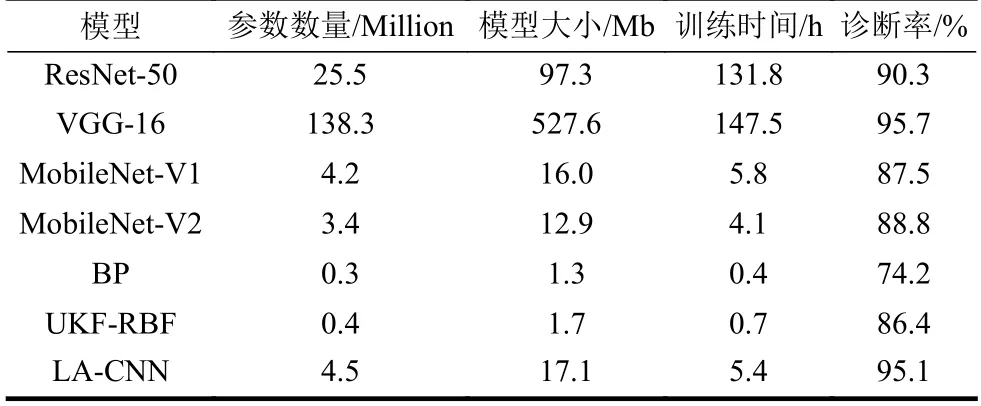
表1 5 種深度卷積神經網絡模型的訓練和診斷結果對比

表2 LA-CNN 模型的不同測試集的故障診斷準確率%
為進一步驗證本文的正則化注意力模塊和注意力損失函數的有效性,通過融合實驗進行性能對比分析,包括深度分離卷積、正則化注意力和注意力損失函數間的不同組合,對比指標是模型訓練時間和故障診斷精度。表3 為LA-CNN 的融合實驗性能對比,實驗結果表明:1) 在CNN 中嵌入正則化注意力模塊后,增加的訓練時間可以忽略不計,但診斷精度明顯提高;2) 引入注意力損失函數,通過控制樣本損失權重調節樣本貢獻,使模型訓練過程中較多地關注難分負樣本,比僅使用注意力機制又提高2.9 個百分點。
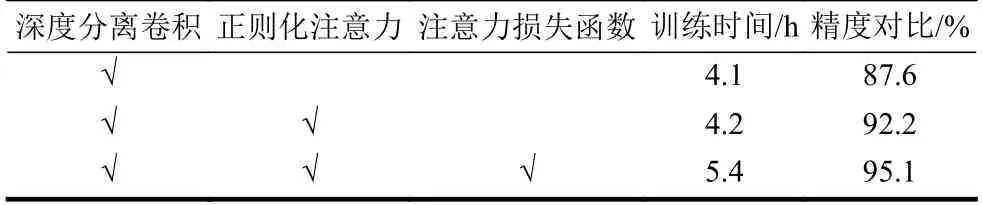
表3 LA-CNN 模型的融合實驗對比
此外,為驗證注意力損失函數中的調節因子k對模型性能的影響,將其分別作為LA-CNN、VGG-16 和MobileNet 的損失函數,并給出各個取值時不同模型的故障診斷精度對比,從而從實驗分析角度給出k 的最終取值。圖4 是k不同取值時不同模型的抽油機故障診斷準確率對比。
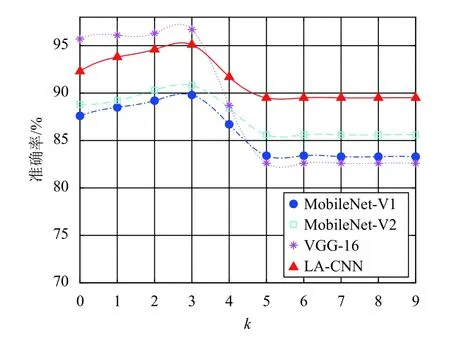
圖4 調節因子對故障診斷性能的影響
實驗結果表明k=3時,各個模型的故障診斷精度均達到理想狀態,其中LA-CNN 達到95.1%。主要原因如下:
1) k=0時,各個模型仍然使用的是交叉熵損失函數,所有樣本對損失的貢獻權重相等;
2) k ∈[1,3]時,易分樣本的損失權重逐步得到抑制,模型訓練關注難分樣本;
3) k>3時,易分樣本對模型訓練損失的貢獻基本被抑制到0,同時難分負樣本的數量較少,模型診斷能力下降。
4 結 束 語
本文介紹了一種輕量型卷積神經網絡LA-CNN及抽油機故障診斷應用,將位移?載荷的輪廓曲線轉換為圖像,直接使用卷積神經網絡提取圖形的輪廓特征。在模型結構上采用了深度分離卷積來降低模型存儲,為提高抽油機故障診斷精度,適應小規模工況樣本集,提出正則化注意力模塊和注意力損失函數,對特征圖的通道特征進行抑制或加強,建立適用于通道的失活機制,訓練過程更多關注難分樣本。這種正則化注意力機制可有效提高模型的診斷精度。仿真結果表明,LA-CNN 導出后的模型參數僅占5.4 Mb,可滿足檢測設備硬件和功耗低的要求,并具有較高的故障診斷精度。最后通過融合實驗進一步驗證所提正則化注意力模塊和注意力損失函數的有效性。該方法的研究為大數據環境下的卷積神經網絡開展基于示功圖的抽油機故障診斷提供了一種新的思路。
本文的研究工作得到了東北石油大學青年基金(2017PYZL-06, 2018YDL-22)和東北石油大學優秀中青年科研創新團隊(KYCXTD201903)的資助,在此表示感謝!
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
石油石化節能(2022年12期)2022-12-30 04:45:02
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
光學精密工程(2016年6期)2016-11-07 09:07:19
重慶工商大學學報(自然科學版)(2015年10期)2015-12-28 07:43:58
中國煤層氣(2014年6期)2014-08-07 03:07:05
振動、測試與診斷(2014年5期)2014-03-01 01:14:21
機械與電子(2014年1期)2014-02-28 02:07:31
河南科技(2014年16期)2014-02-27 14:13:19
