基于FPGA的卷積神經(jīng)網(wǎng)絡(luò)定點(diǎn)加速
2020-10-18 12:57:00雷小康尹志剛趙瑞蓮
計(jì)算機(jī)應(yīng)用 2020年10期
雷小康,尹志剛,趙瑞蓮
(1.北京化工大學(xué)信息科學(xué)與技術(shù)學(xué)院,北京 100029;2.中國科學(xué)院自動(dòng)化研究所,北京 100190)
(*通信作者電子郵箱zhigang.yin@ia.ac.cn)
0 引言
近年來,人工神經(jīng)網(wǎng)絡(luò)在日常生活中的應(yīng)用越來越廣泛,卷積神經(jīng)網(wǎng)絡(luò)(Convolutional Neural Network,CNN)是一種源自人工神經(jīng)網(wǎng)絡(luò)的機(jī)器學(xué)習(xí)算法,它簡化了傳統(tǒng)識別算法中復(fù)雜的特征提取和數(shù)據(jù)重建的過程,在視頻監(jiān)控、機(jī)器視覺、圖像搜索、模式識別等領(lǐng)域得到越來越廣泛的應(yīng)用。
隨著深度學(xué)習(xí)的普及和Caffe、Tensorflow、Torch 等深度學(xué)習(xí)框架的成熟,卷積神經(jīng)網(wǎng)絡(luò)模型的識別精度越來越高。比較有名的有:LeNet-5[1]手寫數(shù)字識別卷積神經(jīng)網(wǎng)絡(luò),精度達(dá)99%以上;AlexNet[2]模型和VGG-16[3]模型的提出突破了傳統(tǒng)圖像識別的精度;GooLeNet[4]和ResNet[5]推動(dòng)了卷積神經(jīng)網(wǎng)絡(luò)的應(yīng)用,但是卷積神經(jīng)網(wǎng)絡(luò)參數(shù)也隨之越來越多,龐大的計(jì)算量導(dǎo)致CNN 模型很難移植到手機(jī)端或嵌入式芯片中。因此,如何在保證卷積神經(jīng)網(wǎng)絡(luò)模型精度的前提下,對深度卷積神經(jīng)網(wǎng)絡(luò)進(jìn)行壓縮和加速,并在嵌入式設(shè)備上部署,已成為一個(gè)重要的研究課題。
早期有學(xué)者提出了一些CNN 模型壓縮方法,如:Denil等[6]使用低秩分解的方法減少了深層網(wǎng)絡(luò)模型的動(dòng)態(tài)參數(shù)數(shù)量;Sainath 等[7]研究了深度神經(jīng)網(wǎng)絡(luò)中最終加權(quán)層的低階矩陣分解方法以進(jìn)行聲學(xué)建模。但是低秩分解方法計(jì)算成本高昂,并且需要大量的重新訓(xùn)練來達(dá)到收斂。自2016 年以來Han 等[8-10]提出通過設(shè)定閾值來修剪權(quán)值參數(shù),結(jié)合K-Means聚類和霍夫曼編碼進(jìn)一步壓縮網(wǎng)絡(luò),達(dá)到網(wǎng)絡(luò)稀疏化的目的;Iandola 等[11]提出Fire Module 模型結(jié)構(gòu),用更小的卷積核代替較大的卷積核,通過減少參數(shù)數(shù)量進(jìn)行模型壓縮。這兩種方法雖然減少了網(wǎng)絡(luò)參數(shù),但是卷積計(jì)算仍然采用浮點(diǎn)數(shù)卷積運(yùn)算,計(jì)算復(fù)雜度并沒有降低。
Gysel[12]提出一種對卷積神經(jīng)網(wǎng)絡(luò)定點(diǎn)化仿真的工具Ristretto,將浮點(diǎn)數(shù)仿真表示為定點(diǎn)數(shù),采用一系列CNN 模型定點(diǎn)化方法,研究不同定點(diǎn)化模型與精度損失之間的關(guān)系;Rajasegaran 等[13]提出膠囊網(wǎng)絡(luò),采用3D 動(dòng)態(tài)路由卷積算法,雖然一定程度上減少了參數(shù)數(shù)量,但是CNN 模型參數(shù)依然使用浮點(diǎn)數(shù)存儲(chǔ),卷積計(jì)算采用浮點(diǎn)數(shù)卷積運(yùn)算,模型參數(shù)的存儲(chǔ)大小不變,無法在嵌入式硬件上實(shí)現(xiàn)。Zhao 等[14-16]提出基于現(xiàn)場可編程門陣列(Field Programmable Gate Array,F(xiàn)PGA)的卷積神經(jīng)網(wǎng)絡(luò)加速方法,將CNN 參數(shù)定點(diǎn)量化,但是沒有考慮成本較低的硬件資源的限制。
FPGA 是一種集成電路,包含大量的定點(diǎn)計(jì)算單元,與圖形處理器(Graphics Processing Unit,GPU)相比,F(xiàn)PGA 具有低功耗低成本的特點(diǎn),并且在大多數(shù)情況下能達(dá)到GPU 相近的加速效果。
綜合上述研究,本文針對傳統(tǒng)浮點(diǎn)數(shù)卷積計(jì)算復(fù)雜度高、浮點(diǎn)模型占用存儲(chǔ)空間大以及運(yùn)行速度慢的問題,提出一種基于FPGA 的優(yōu)化定點(diǎn)卷積計(jì)算方法。本文的主要工作包括以下幾個(gè)方面:
1)本文通過設(shè)計(jì)動(dòng)態(tài)定點(diǎn)量化方法,將浮點(diǎn)CNN 模型的權(quán)值參數(shù)和各層特征圖參數(shù)動(dòng)態(tài)量化為定點(diǎn)模型;
2)考慮數(shù)據(jù)的存儲(chǔ)方式及卷積核的特點(diǎn),將參數(shù)量化為7-bit,設(shè)計(jì)參數(shù)復(fù)用和流水線卷積計(jì)算方法,在精度損失很小的情況下,卷積計(jì)算速度加速比達(dá)到18.69。
1 卷積神經(jīng)網(wǎng)絡(luò)模型參數(shù)預(yù)處理
為提高訓(xùn)練結(jié)果的準(zhǔn)確性,卷積神經(jīng)網(wǎng)絡(luò)在訓(xùn)練過程中一般會(huì)使用多種優(yōu)化方法,但是,在模型訓(xùn)練完成之后的前向推理過程,預(yù)先對卷積神經(jīng)網(wǎng)絡(luò)模型參數(shù)進(jìn)行處理,可以減少前向推理的計(jì)算量,有利于對模型定點(diǎn)量化,提高運(yùn)算速度。
1.1 卷積神經(jīng)網(wǎng)絡(luò)
卷積神經(jīng)網(wǎng)絡(luò)一般包含輸入層、卷積層、激活層和全連接層。本文采用的CNN 模型包括輸入和權(quán)值參數(shù)的卷積計(jì)算、批量歸一化、激活層和池化層,最后一層使用YOLO[17]層檢測目標(biāo)的坐標(biāo)位置。
卷積計(jì)算本質(zhì)上是大量數(shù)據(jù)的乘累加操作,公式如下:
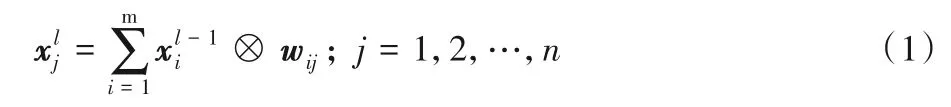
其中:m為輸入特征圖個(gè)數(shù);n為卷積計(jì)算后輸出特征圖個(gè)數(shù);為第l層的第j個(gè)特征圖;wij為第i通道的第j個(gè)權(quán)值參數(shù)矩陣。
目前大多數(shù)CNN 模型在訓(xùn)練時(shí)都會(huì)在每個(gè)卷積層后面增加批量歸一化(Batch Normalization,BN)層[18]。BN 層用于將數(shù)據(jù)歸一化,可以有效解決梯度爆炸問題,加速網(wǎng)絡(luò)收斂,并且可以解決過擬合的問題,一般放在卷積層之后,計(jì)算公式如下:
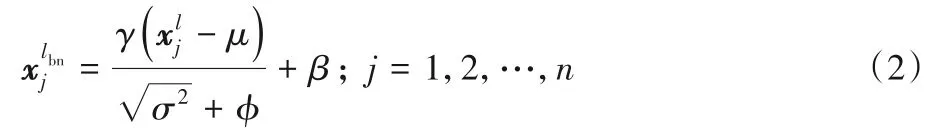
其中:γ為縮放因子;μ為均值;σ2為方差;φ為很小的正數(shù),本文取值為10-6;β為偏置;為式(1)中卷積計(jì)算結(jié)果;為經(jīng)過BN計(jì)算后的結(jié)果。
激活層本文采用ReLU 函數(shù)作為激活函數(shù),計(jì)算公式如下:

本文池化層使用最大值池化。
1.2 權(quán)值參數(shù)預(yù)處理
BN 層在訓(xùn)練時(shí)起到了積極作用,但是會(huì)導(dǎo)致在網(wǎng)絡(luò)前向推理時(shí)多了一層運(yùn)算,占用了更多的計(jì)算資源,在一定程度上會(huì)降低運(yùn)算速度。因此,本文將BN 層的參數(shù)合并到卷積層的權(quán)值參數(shù)中,來提升模型前向推理的計(jì)算速度。依據(jù)式(1)~(2)可得:
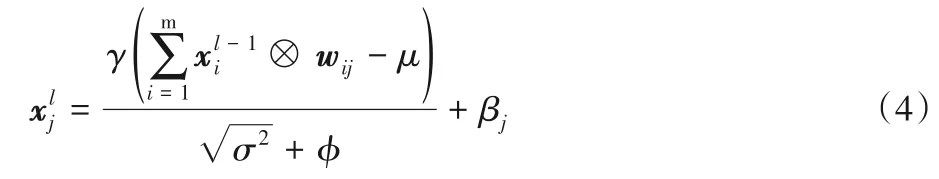
展開后得到:

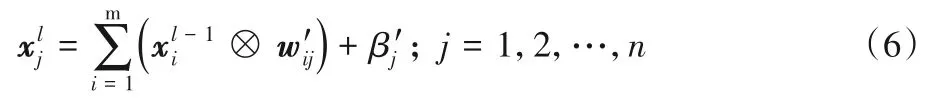
經(jīng)過變換,卷積計(jì)算和BN 計(jì)算由式(1)~(2)轉(zhuǎn)化為式(6),每一次的卷積計(jì)算都減少了開方和除法操作,一定程度上可以加速卷積計(jì)算。
2 CNN模型參數(shù)定點(diǎn)化優(yōu)化方法
參數(shù)預(yù)處理將卷積神經(jīng)網(wǎng)絡(luò)簡化為只包含卷積層、池化層和激活層,主要計(jì)算量在卷積層,本文針通過對卷積層的權(quán)值和輸入特征參數(shù)定點(diǎn)量化,將卷積層的浮點(diǎn)卷積計(jì)算轉(zhuǎn)換為高效的定點(diǎn)卷積計(jì)算,提高運(yùn)算速度。
2.1 權(quán)值參數(shù)定點(diǎn)化
在FPGA 中浮點(diǎn)運(yùn)算相較于定點(diǎn)運(yùn)算要耗費(fèi)數(shù)倍的資源和時(shí)間,統(tǒng)計(jì)不同網(wǎng)絡(luò)模型權(quán)值參數(shù)的分布可以發(fā)現(xiàn),不同CNN 模型的權(quán)值大致對稱分布在零值兩側(cè),且不同卷積層的權(quán)值參數(shù)具有顯著的動(dòng)態(tài)范圍,在對其定點(diǎn)量化[12]時(shí),若將所有層的參數(shù)量化為同一個(gè)范圍,會(huì)造成較大的精度損失。
本文設(shè)計(jì)動(dòng)態(tài)指數(shù)定點(diǎn)量化的方式對權(quán)值參數(shù)進(jìn)行量化,在對每一層參數(shù)進(jìn)行量化時(shí),將每層參數(shù)分組為具有指數(shù)為常數(shù)fl的組中,分配給小數(shù)部分的位數(shù)在該組內(nèi)是恒定的,但與其他組相比是不同的。每個(gè)網(wǎng)絡(luò)層分為三組,分別用于層輸入、權(quán)重、層輸出,可以更好地覆蓋每層輸入?yún)?shù)和權(quán)重參數(shù)的動(dòng)態(tài)范圍。

圖1 權(quán)值參數(shù)動(dòng)態(tài)定點(diǎn)量化Fig.1 Dynamic fixed-point quantization of weight parameters
動(dòng)態(tài)定點(diǎn)量化計(jì)算公式如式(7)所示:

其中:B是量化的位寬長度;s是符號位;fl是不同卷積層的量化指數(shù)位長度;是定點(diǎn)數(shù)的尾數(shù)部分。
卷積計(jì)算時(shí)使用定點(diǎn)化后的CNN 模型,卷積計(jì)算轉(zhuǎn)化為定點(diǎn)數(shù)的尾數(shù)部分進(jìn)行乘累加運(yùn)算,將運(yùn)算的結(jié)果使用每層的量化尺度再進(jìn)行量化,之后參與下一層的卷積計(jì)算,依此類推,直到完成所有的卷積計(jì)算。
2.2 輸入?yún)?shù)定點(diǎn)化
在對輸入層數(shù)據(jù)量化時(shí),由于每次傳入的圖片數(shù)據(jù)不一樣,每一層計(jì)算的輸出差異很大,因此每次的輸入不能直接確定量化范圍。卷積計(jì)算時(shí),每層的輸入都計(jì)算量化位寬會(huì)增加前向推理運(yùn)算時(shí)間。為了減少計(jì)算量并且保證精度損失不大,本文采用Kullback-Leibler(KL)散度來計(jì)算輸入?yún)?shù)定點(diǎn)化的尺度[19]。
首先構(gòu)建一種由32-bit 數(shù)據(jù)向n-bit 定點(diǎn)數(shù)的映射關(guān)系,該映射中的邊界并不是兩種數(shù)據(jù)類型的最大值(圖2(a)),而是設(shè)置一個(gè)閾值T(圖2(b)),將這個(gè)閾值與n-bit 定點(diǎn)數(shù)的最大值(例如8-bit 定點(diǎn)數(shù)最大為127)構(gòu)建映射關(guān)系,計(jì)算輸入尺度fl_in。
確定這種映射關(guān)系的閾值T和尺度采用KL 散度。不同的網(wǎng)絡(luò)閾值T和每層的尺度是不同的,32-bit 浮點(diǎn)數(shù)映射到n-bit 定點(diǎn)數(shù)相當(dāng)于重新編碼信息,在選擇閾值T和尺度時(shí)應(yīng)盡量保證減少信息的丟失,設(shè)置一個(gè)矯正數(shù)據(jù)集來進(jìn)行輸入尺度的選取,計(jì)算最小化KL 散度來確定最佳尺度,如式(8)所示:
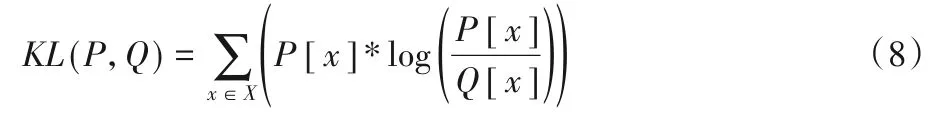
其中:P[x]和Q[x]是兩個(gè)離散概率分布;x為量化到不同位寬長度的參數(shù)個(gè)數(shù)。
當(dāng)式(8)中KL 取最小值時(shí),得到閾值T,通過式(9)計(jì)算得出每層參數(shù)的尺度fl_in:

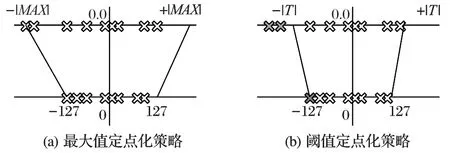
圖2 輸入定點(diǎn)化閾值選擇策略Fig.2 Fixed-point threshold selection strategy of inputs
3 基于FPGA的定點(diǎn)化CNN加速設(shè)計(jì)
針對第2 章提出的CNN 定點(diǎn)化方法,考慮Arm 處理器與FPGA 之間的交互,設(shè)計(jì)了基于FPGA 的CNN 加速計(jì)算模型,如圖3 所示。本文提出的定點(diǎn)計(jì)算模型主要分為五個(gè)模塊,分別為參數(shù)量化模塊、參數(shù)加載模塊、輸入模塊、卷積計(jì)算模塊和輸出模塊。
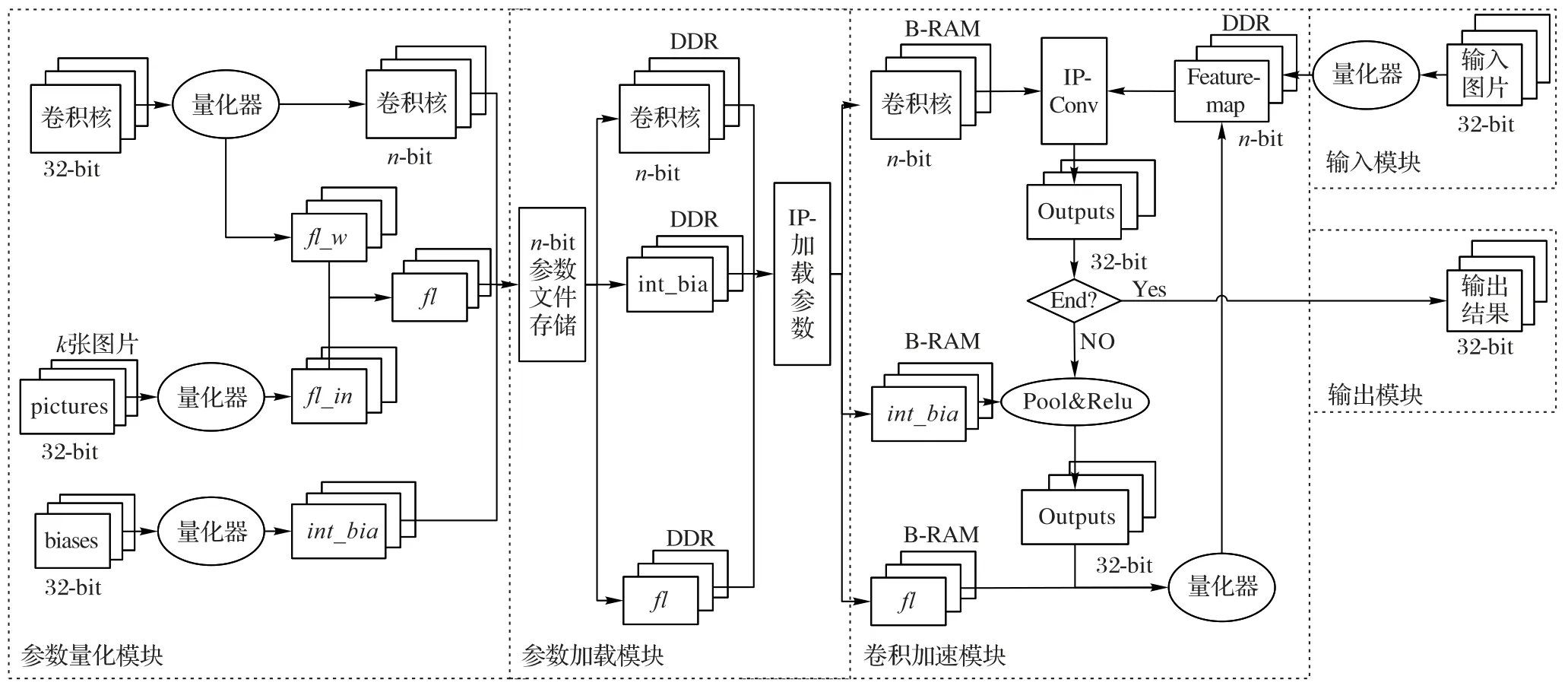
圖3 定點(diǎn)計(jì)算模型Fig.3 Fixed-point computation model
3.1 參數(shù)量化
參數(shù)量化模塊是預(yù)先計(jì)算定點(diǎn)CNN 模型,將定點(diǎn)后的參數(shù)存儲(chǔ)在文件中,卷積計(jì)算時(shí),直接使用定點(diǎn)化后的參數(shù)文件。該模塊由三部分構(gòu)成:第一部分是卷積核(權(quán)值參數(shù))經(jīng)過量化器進(jìn)行量化,量化方法使用2.1 節(jié)中的方法,計(jì)算出n-bit權(quán)值參數(shù)以及每層參數(shù)的尺度fl_w;第二部分是使用2.2節(jié)中的方法確定輸入量化尺度fl_in,經(jīng)過矯正數(shù)據(jù)集(k張圖片)計(jì)算出fl_in;第三部分使用2.1 節(jié)中的方法對偏置進(jìn)行int-32量化,得到定點(diǎn)化后的偏置。根據(jù)fl_w和fl_in計(jì)算每層整體尺度fl,計(jì)算方法如式(10)所示:
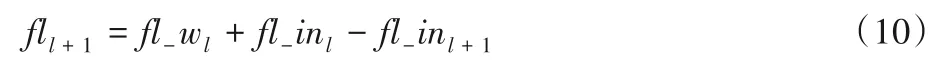
其中:l指第l層卷積。
最后將定點(diǎn)化后的權(quán)值參數(shù)、尺度fl以及偏置存儲(chǔ)在文件中,得到定點(diǎn)化后的CNN模型。
3.2 參數(shù)加載
在卷積運(yùn)算時(shí),需要將定點(diǎn)化后的CNN 模型參數(shù)文件加載到FPGA 內(nèi)部存儲(chǔ)器Block-RAM 中。本文使用vivado HLS工具設(shè)計(jì)讀取參數(shù)文件的接口,使用AXI(Advanced eXtensible Interface)高速總線接口,如圖4所示。
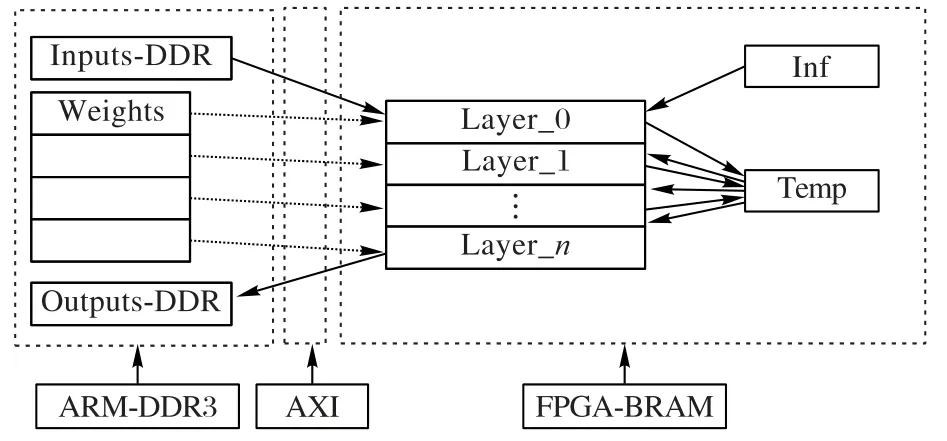
圖4 數(shù)據(jù)加載接口設(shè)計(jì)Fig.4 Data loading interface design
首先ARM 處理器將參數(shù)文件中的參數(shù)讀取到雙倍數(shù)據(jù)率同步動(dòng)態(tài)隨機(jī)存取存儲(chǔ)器(Double Data Rate Synchronous Dynamic Random Access Memory,DDR)中,再將輸入?yún)?shù)、權(quán)值參數(shù)和輸出參數(shù)的地址通過AXI 總線配置到FPGA 中,F(xiàn)PGA 將數(shù)據(jù)讀取到Block RAM 中,一些接口配置信息存儲(chǔ)在Inf中,中間層計(jì)算結(jié)果存儲(chǔ)在Temp中。
3.3 輸入模塊
輸入模塊是對輸入圖像像素值的預(yù)處理,RGB 三通道的圖像作為輸入,將圖像像素值利用2.2 節(jié)介紹的方法進(jìn)行定點(diǎn)化,得到定點(diǎn)化后的輸入數(shù)據(jù)。
3.4 卷積加速
本文使用vivado HLS 高層次綜合工具完成FPGA 硬件編程部分,根據(jù)卷積計(jì)算特性,設(shè)計(jì)了一種卷積加速計(jì)算的方法。
首先考慮數(shù)據(jù)的復(fù)用。由于FPGA 內(nèi)部存儲(chǔ)資源有限,每個(gè)卷積核(權(quán)重參數(shù))會(huì)多次與特征圖進(jìn)行卷積,所以在卷積計(jì)算前,將特征圖矩陣進(jìn)行拆分,分批加載數(shù)據(jù),將大矩陣拆分為小的矩陣,再將小矩陣依次加載到FPGA的Block-RAM中緩存。本文使用的模型每一層的特征圖的長和寬均為16的倍數(shù),因此將每一層的特征圖拆分為邊長為16 的小矩陣,分批對16×16 的特征圖與3×3 的卷積核進(jìn)行卷積計(jì)算,最終將計(jì)算結(jié)果合并在一起。
其次考慮卷積計(jì)算的流水線操作。加速卷積計(jì)算采用將3×3卷積核及拆分后的16×16小特征圖矩陣,循環(huán)展開及流水線卷積計(jì)算,偽代碼如下所示:


3.5 輸出模塊
該模塊將3.4 節(jié)中卷積計(jì)算的結(jié)果合并到一個(gè)大矩陣中,作為下一層的輸入?yún)?shù),循環(huán)計(jì)算得到最后一層的計(jì)算結(jié)果,最后一層計(jì)算的結(jié)果返回到ARM 中參與YOLO 層的分類和檢測計(jì)算。
4 實(shí)驗(yàn)與結(jié)果分析
4.1 實(shí)驗(yàn)設(shè)計(jì)
考慮本文方法需要在硬件FPGA 上實(shí)現(xiàn)加速計(jì)算,因此選擇C語言編寫的基于YOLO-V3深度學(xué)習(xí)框架Darknet,利用Xilinx的HLS工具將C語言綜合為硬件描述語言,縮短硬件開發(fā)周期。
本文在人臉數(shù)據(jù)集和船舶數(shù)據(jù)集兩個(gè)數(shù)據(jù)集上驗(yàn)證,兩個(gè)數(shù)據(jù)集為Pascal VOC 格式的標(biāo)準(zhǔn)數(shù)據(jù)集。人臉數(shù)據(jù)集包含1 665 張1 280×720 的高清圖像,分別為5 個(gè)人不同角度的圖片,其中隨機(jī)選取1 278 張作為訓(xùn)練集,剩余387 張作為測試集;船舶數(shù)據(jù)集包含7 618 張圖片,分為帆船、航母、貨船、游輪、游艇和戰(zhàn)艦六類,隨機(jī)選取5 484 張圖片作為訓(xùn)練集,2 134 張圖片作為測試集。本文設(shè)計(jì)的CNN 模型為15 層的卷積網(wǎng)絡(luò),模型大小為1 545 KB。
實(shí)驗(yàn)分為兩部分:
第一部分使用不同量化位寬對參數(shù)定點(diǎn)化,分析不同量化位寬對精度的影響,計(jì)算模型的精度、召回率和平均準(zhǔn)確率(mean Average Precision,mAP)。mAP 評價(jià)的是目標(biāo)預(yù)測位置的準(zhǔn)確率,mAP越大,預(yù)測的坐標(biāo)位置越接近真實(shí)位置。
第二部分,針對定點(diǎn)化后的CNN 模型使用FPGA 加速前向推理計(jì)算,分析加速效果。該部分使用第一部分定點(diǎn)化效果較好的模型,使用vivado SDK 工具測試CNN 模型在ARM 上的運(yùn)行速度,使用vivado HLS 綜合工具,設(shè)計(jì)FPGA 加速方法,測試CNN模型的加速效果。
4.2 實(shí)驗(yàn)結(jié)果與分析
針對實(shí)驗(yàn)的第一部分,考慮不同量化位寬對精度、召回率和mAP的影響,針對人臉數(shù)據(jù)集進(jìn)行驗(yàn)證,結(jié)果如表1所示。
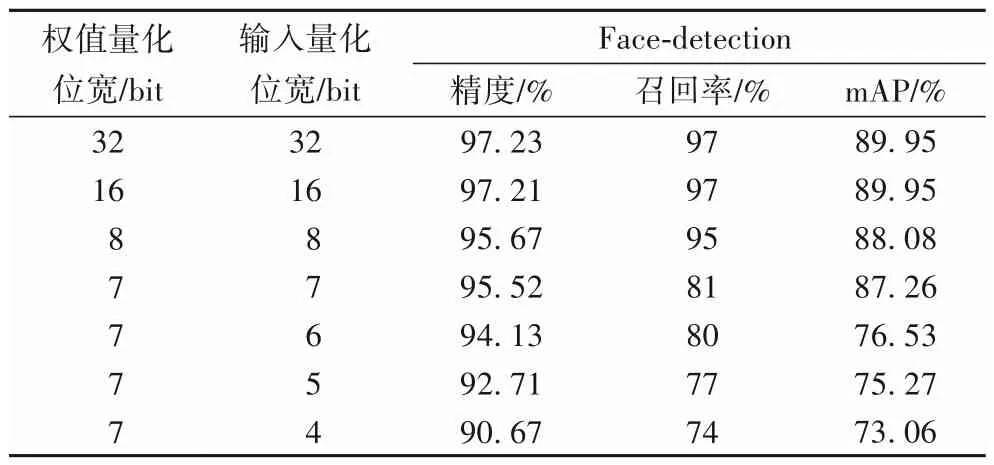
表1 不同量化位寬下的人臉數(shù)據(jù)集識別結(jié)果精度Tab.1 Recognition accuracy results under different quantization bit widths on face dataset
在船舶數(shù)據(jù)集上的驗(yàn)證結(jié)果如圖5~6 所示。圖5 僅對權(quán)值進(jìn)行定點(diǎn)化,圖5(a)為保持每層的輸入特征值原始位寬(32-bit)不變,每類平均準(zhǔn)確率(Average Precision,AP)值隨量化位寬的變化情況;圖5(b)為mAP 值、精度和召回率隨量化位寬的變化情況。圖6 對輸入特征值和權(quán)值都進(jìn)行定點(diǎn)化,圖6(a)為每層的輸入特征值和權(quán)值同時(shí)定點(diǎn)化,每類AP值隨量化位寬的變化情況;圖6(b)為每層的輸入特征值和權(quán)值同時(shí)定點(diǎn)化,mAP值、精度和召回率隨量化位寬的變化情況。
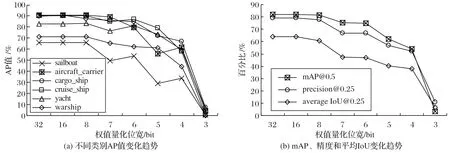
圖5 權(quán)值定點(diǎn)化結(jié)果Fig.5 Results of fixed-point processing of weights
由圖5~6可看出:本文方法在僅對權(quán)值定點(diǎn)化和對權(quán)值、輸入特征值同時(shí)定點(diǎn)化兩種方式下差異很小,可以滿足兩種不同的量化方式,具有較好的魯棒性。綜合表1 還可看出:權(quán)值和輸入?yún)?shù)量化位寬大于7-bit 時(shí),精度和mAP 影響不大;量化位寬小于7-bit時(shí),精度和mAP影響較大。
當(dāng)權(quán)值參數(shù)壓縮到8-bit 或者7-bit 時(shí),壓縮比率較大,且精度損失很小。考慮到使用的卷積核大小為3×3,一個(gè)卷積核占用63-bit,可以用一個(gè)64-bit 的數(shù)據(jù)類型一次性讀取一個(gè)完整的卷積核的數(shù)據(jù)進(jìn)行運(yùn)算,充分利用FPGA 資源,高效讀取數(shù)據(jù)。因此本文最終采用7-bit的定點(diǎn)模型作為FPGA 的加速目標(biāo),針對人臉檢測的CNN 模型定點(diǎn)量化后的CNN 模型大小由1 545 KB 壓縮為344 KB,壓縮后的權(quán)重參數(shù)文件大小約為原來的22%。
使用2.3 節(jié)數(shù)據(jù)復(fù)用和流水線計(jì)算方法,將代碼綜合成電路,硬件資源利用情況與文獻(xiàn)[20-21]方法對比如表2 所示,LUT(Look-Up-Table)利用率為54.7%,Block RAM 利用率為65.3%,DSP(Digital Signal Processor)資源中的乘加器利用率高達(dá)94.5%,可以看出本文方法較為充分地利用了FPGA的資源。
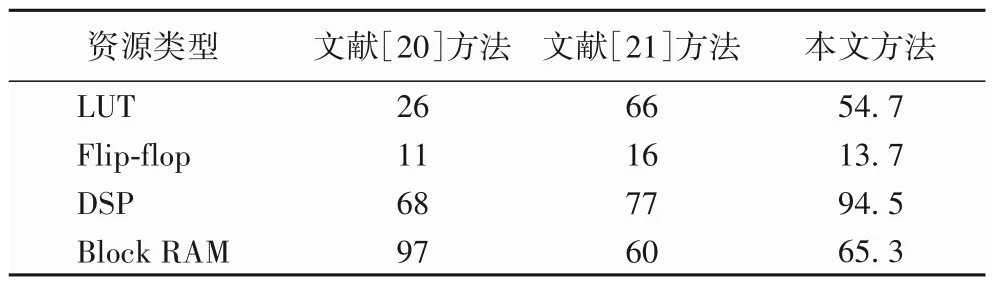
表2 資源利用情況 單位:%Tab.2 Resource utilization conditions unit:%
針對人臉檢測模型,與文獻(xiàn)[20-21]方法相比,采用本文方法,在功耗增加很小的情況下,F(xiàn)PGA具有更高的運(yùn)算峰值,加速效果更好,實(shí)驗(yàn)結(jié)果如表3所示。
針對不同平臺(tái)人臉檢測模型量化前后CNN 前向推理計(jì)算耗時(shí)如表4所示。將模型量化前、量化后和FPGA加速的結(jié)果進(jìn)行對比,可以看出本文提出的方法對CNN 計(jì)算速度有較大提升,加速比為18.69。

表3 FPGA加速效果Tab.3 FPGA acceleration effect
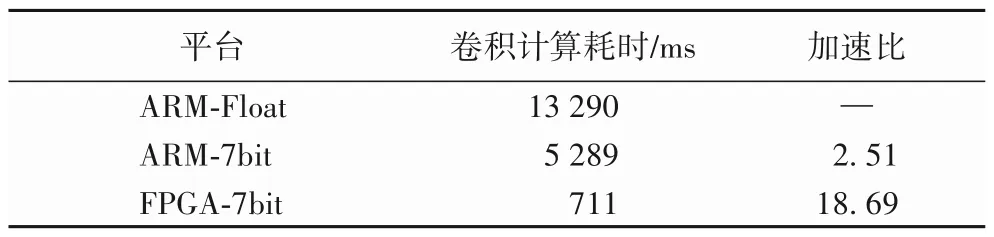
表4 定點(diǎn)量化卷積加速效果Tab.4 Fixed-point quantization convolution acceleration effect
5 結(jié)語
本文提出了一種基于FPGA 的卷積神經(jīng)網(wǎng)絡(luò)定點(diǎn)化加速計(jì)算方法,設(shè)計(jì)了卷積計(jì)算策略,并在FPGA 上驗(yàn)證本文提出的方法的有效性。通過與現(xiàn)有的兩個(gè)工作進(jìn)行比較,本文的方法有更高的運(yùn)算峰值,同時(shí),F(xiàn)PGA 資源利用率較高。最后通過在人臉數(shù)據(jù)集和船舶數(shù)據(jù)集上進(jìn)行精度和計(jì)算速度測試,精度損失在可接受的范圍內(nèi),模型壓縮為原來的22%,速度提升了17.69 倍,一定程度上可以滿足嵌入式設(shè)備的需求。本文提出的方法是基于特定大小的卷積核(3×3)對CNN 模型進(jìn)行定點(diǎn)化加速研究,針對卷積核大小不是3×3 的CNN 模型并不適用,后續(xù)的研究將考慮更通用的CNN 模型,針對更加通用的CNN模型定點(diǎn)化進(jìn)行研究。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
中學(xué)生數(shù)理化·七年級數(shù)學(xué)人教版(2020年10期)2020-11-26 08:24:50
數(shù)學(xué)物理學(xué)報(bào)(2020年2期)2020-06-02 11:29:24
兒童故事畫報(bào)(2019年5期)2019-05-26 14:26:14
光學(xué)精密工程(2016年6期)2016-11-07 09:07:19
Coco薇(2016年2期)2016-03-22 02:42:52
核科學(xué)與工程(2015年4期)2015-09-26 11:59:03
Coco薇(2015年1期)2015-08-13 02:47:34
小雪花·成長指南(2015年7期)2015-08-11 15:03:12
小雪花·成長指南(2015年4期)2015-05-19 14:47:56
