基于K-means聚類算法分類的水果等級識別與應用
2020-10-19 06:50:54朱玲
農機化研究 2020年8期
朱 玲
(湖北工業大學 工程技術學院,武漢 430068)
0 引言
高品質的水果和蔬菜是在當今競爭激烈市場成功的首要條件,也是水果加工成果汁、糖漿和葡萄酒的基礎,人們對優質和新鮮的水果需求不斷增長。傳統的水果和蔬菜分類和分級耗時長,需要大量的人力物力。本文采用K-means聚類和BP神經網絡相結合的方法,設計了一種水果等級分類識別模型,可以實現對水果質量等級的自動分類,能夠大大提高水果等級分類效率。
1 K-means聚類算法
所謂“聚類”,就是將統一類型的成員集中進行管理和分類,是數據挖掘技術的一個重要分支。在數據挖掘算法中,聚類算法主要包括基于層次、密度、劃分、網絡和模型的5種基本算法,而K-means是聚類算法中一種常用的基于劃分的算法。
K-means聚類算法的簡要描述如下:假設有1個樣本集X={xi|i=1,2,3,…,N},存在K個等級類型Cj(j=1,2,…,K)和K個聚類中心Aj(j=1,2,3,…,K),則N個樣本間的歐式距離公式為
(1)
樣本集X的聚類中心為
(2)
K-means聚類算法的核心思想是:確定k個中心點,進行最小化聚類誤差,而聚類誤差定義為所有數據點到其各自聚類中心的距離之和,從而判斷該對象是屬于哪一類。
(3)
其中,Cj為第j個等級集合的樣本數據;cj為第j個等級類型的聚類中心;E為樣本聚類誤差平方準則和,當E逐漸收斂時,聚類過程結束。
K-means算法采用模糊分組的方法,將n個向量Xi(i=1,2,...,n)分為c組,并求每組的聚類中心,隸屬矩陣u允許有取值在0,1間的元素,通過歸一化規定,1個數據集的隸屬度的和總等于1,其表達式為
(4)
則可以得到FCM的目標函數為
(5)
其中,ci為模糊組I的聚類中心;dij=‖ci-xj‖為第I個聚類中心與第J個數據點間的歐幾里德距離,且m∈[1,∞)是一個加權指數。通過構造如下新的目標函數,可求得使式(2)達到最小值的必要條件,即
(6)
其中,λj、j=1~n是式(1)的n個約束式的拉格朗日乘子,對所有輸入參量求導,使式(2)達到最小的必要條件為
(7)
(8)
假設采集到的農作物環境分類數據集合為X={x1,x2,...,xN},其中每一個數據集合xk有n個特性指標,設為Xk={x1k,x2k,...,xNk}T。
K-means聚類算法流程如下:
1)隨機選擇k個模式作為初始k中心,分配剩下N-k模式到中心最近的聚類,并計算所獲得聚類的新中心。
2)根據歐式距離公式(1),計算距離聚類中心的距離,并選擇最小值的類作為該對象的所屬類別,即
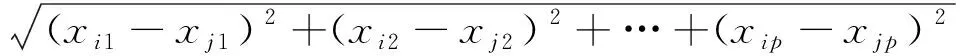
(9)
其中,xi=(xi1,xi2,…,xip)和xj=(xj1,xj2,…,xjp)為包含P維的對象。
3)在每個類簇中,計算數據對象均值,從而得到新的聚類中心,即
(10)
4)一直重復進行2)和3),直至結果趨于收斂。
為了更清晰地表達聚類算法的核心思想,本文將用一組數據詳細描述K-means算法流程,假設存在10個樣本對象{x1,x2,x3,…,x10},而每個樣本有兩種屬性{xi1,xi2},如表1所示。
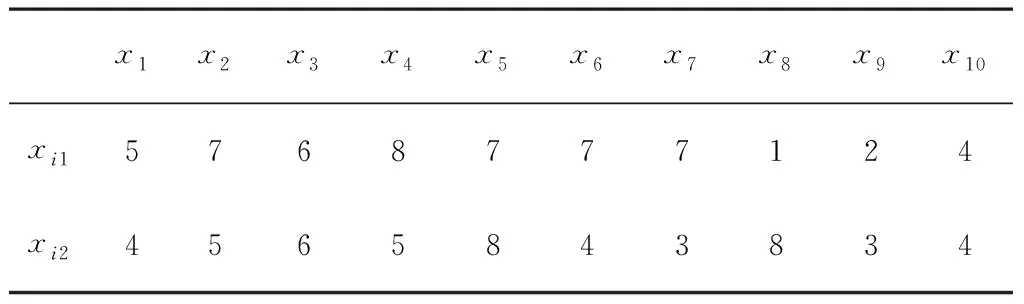
表1 K-means聚類算法數據集Table 1 The data set of K-means clustering algorithms。
設定聚類數為2,采用K-means聚類算法分別計算各對象到聚類中心的距離,迭代的過程如圖1和圖2所示(實圓為類簇中心)。當迭代到第4次時,趨于收斂。因此,經過K-means計算得到兩類分別為{x1,x8,x9,x10}和{x2,x3,x4,x5,x6,x7},總共迭代了4次。
根據歐式距離公式(1),計算距離聚類中心的距離,并選擇最小值的類作為該對象的所屬類別。
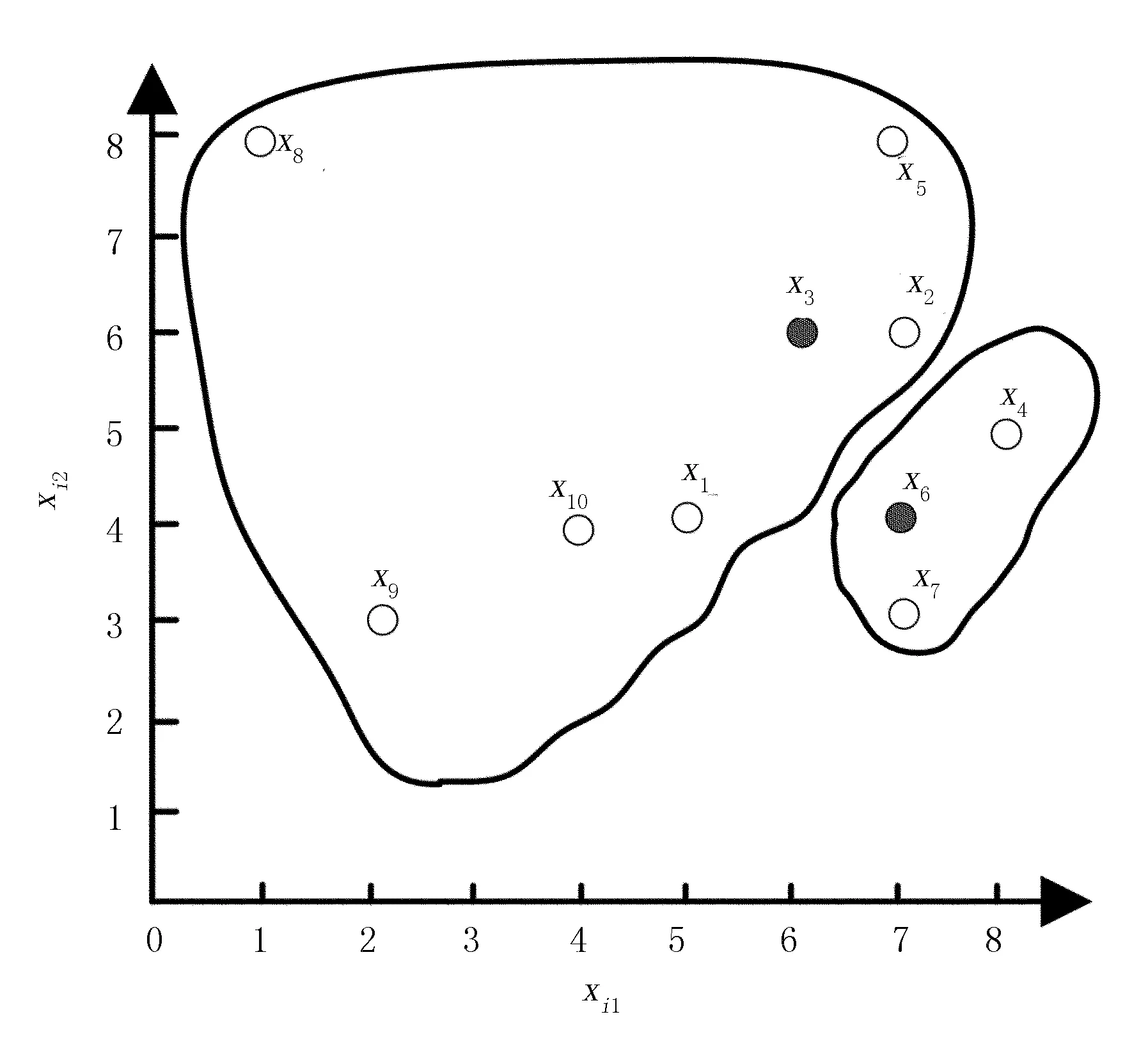
圖1 K-means聚類算法第1次迭代Fig.1 The first iteration of K-means clustering algorithm。
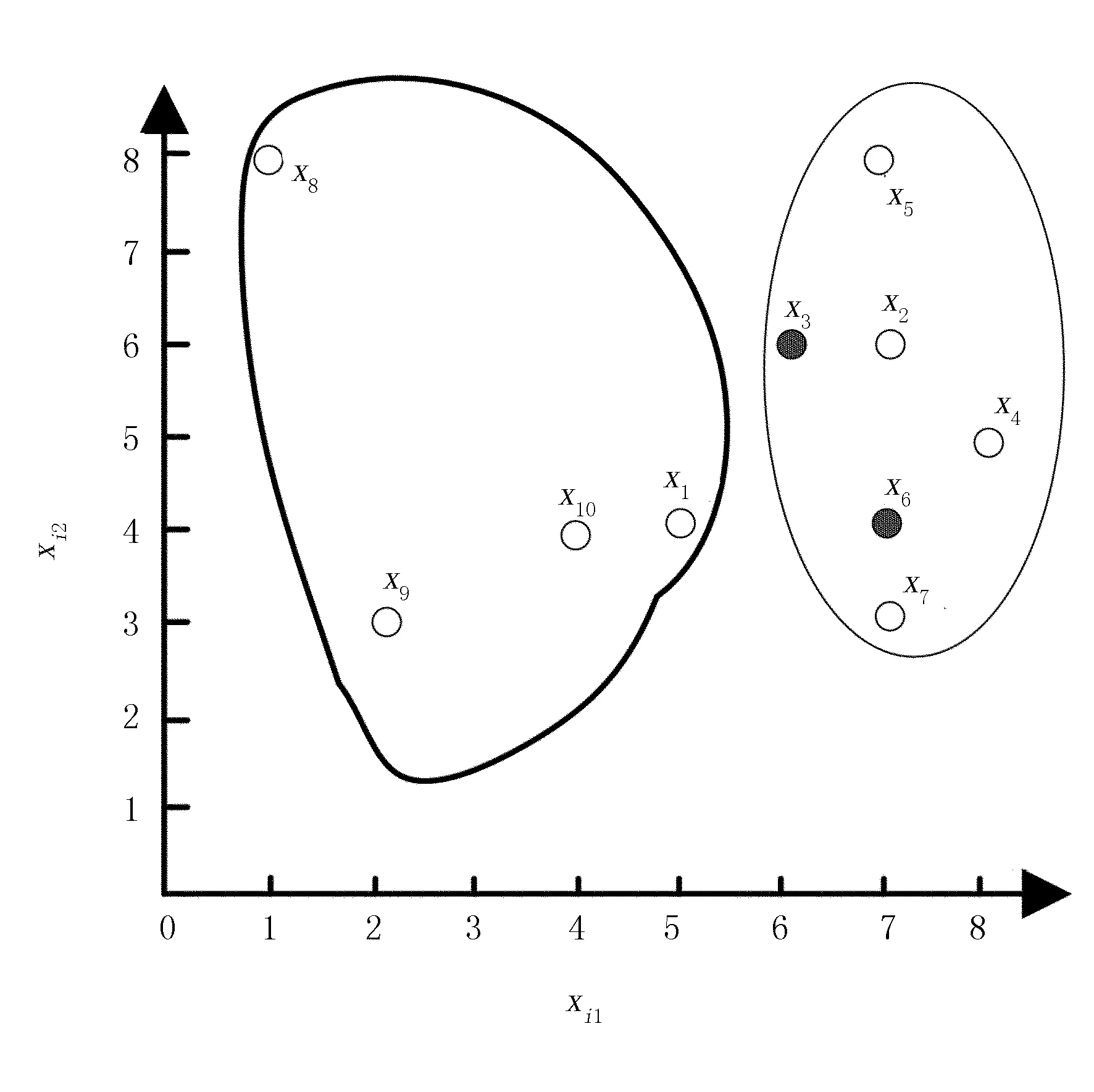
圖2 K-means聚類算法第4次迭代Fig.2 The fourth iteration of K-means clustering algorithm。
2 水果圖像采集與處理
2.1 水果圖像的獲取
為了盡量逼近真實識別分類環境,采集到具有代表性的樣本。試驗采用1200萬像素的相機對水果進行拍攝,背景色均為白色,分別在不同光線、角度獲取了大量原始數據。本文采集到的水果主要包括蘋果、梨子、火龍果、石榴、香蕉、橘子等水果,每種水果分別獲取了500張高清的相片,共計3000幅。獲取到的水果圖像如圖3所示。
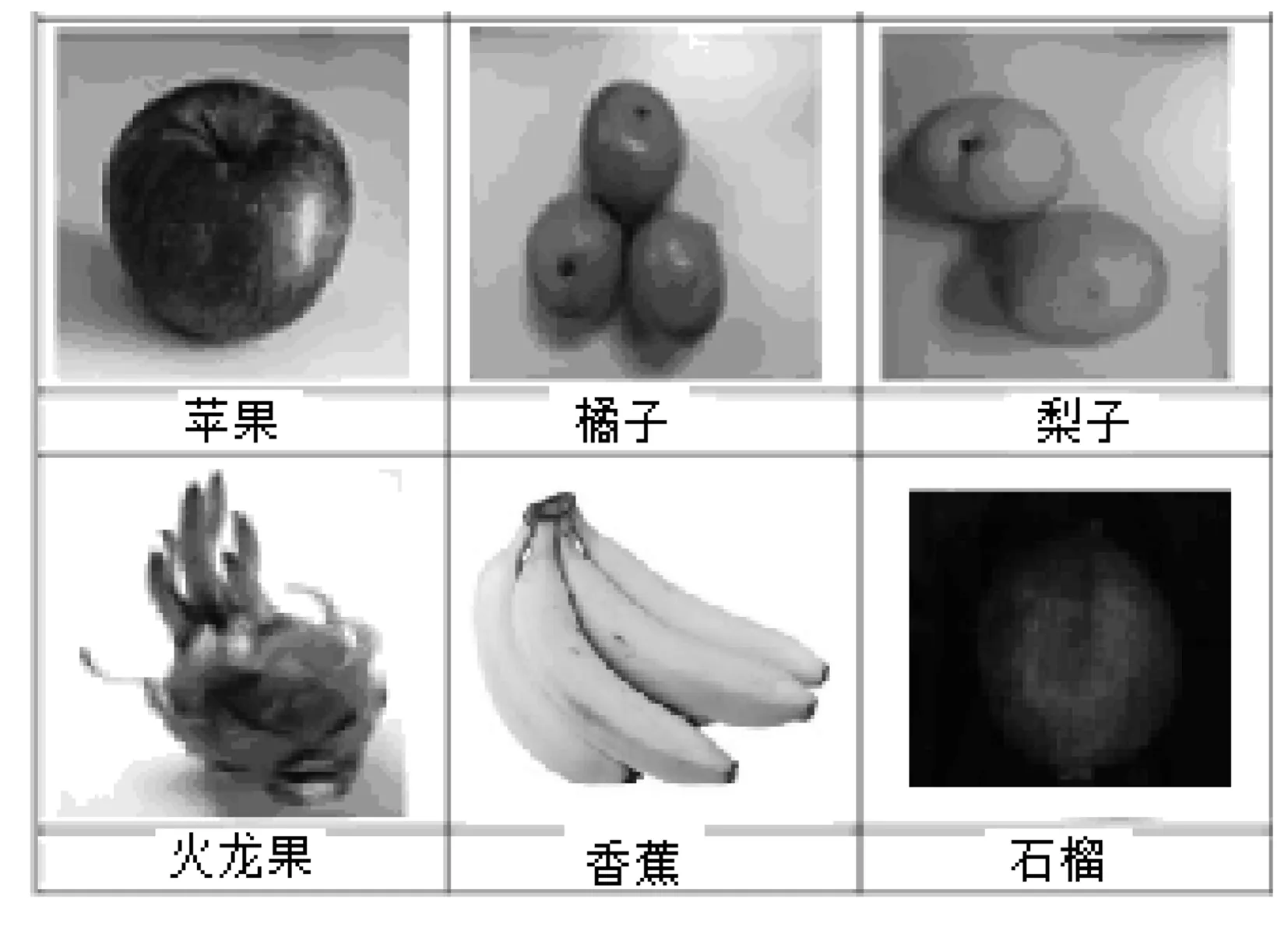
圖3 獲取到的水果圖像Fig.3 The obtained fruit image。
在水果圖像拍攝過程中,充分考慮了角度、光線和遮擋問題,使得拍攝到的圖像更加符合要求,如圖4所示。

圖4 不同角度、光線和遮擋下采集到的水果圖像Fig.4 The captured fruit images from different angles, light and occlusion。
為了方便處理,采用Photoshop CS6.0軟件對采集到的相片進行歸一化處理,得到了640×480的圖像。
2.2 水果圖像的預處理
水果圖像預處理主要包括尺寸裁剪、濾波、圖像增強、特征抽取和分割等,是進行水果等級識別分類的基礎,且圖像增強是非常關鍵的一個環節。為了實現更好的圖像預處理,對圖像進行了彩色空間選擇和濾波。
1)彩色空間選擇。圖像預處理中有很多的顏色空間模型,其中RGB顏色模型的亮度和色彩未實現分離,具有較強的關聯性,邊緣像素無法較好地保存。RGB顏色模型如圖5所示。
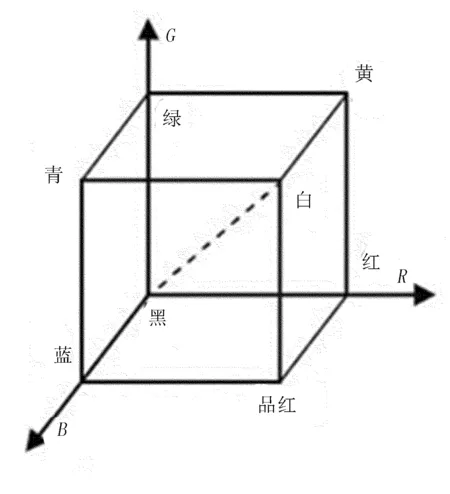
圖5 RGB顏色模型Fig.5 RGB color model。
HSV模型中,H通道可以消除目標物體受到亮度的影響,V通道則可以反應出目標物體的信號強度。顏色模型如圖6所示。
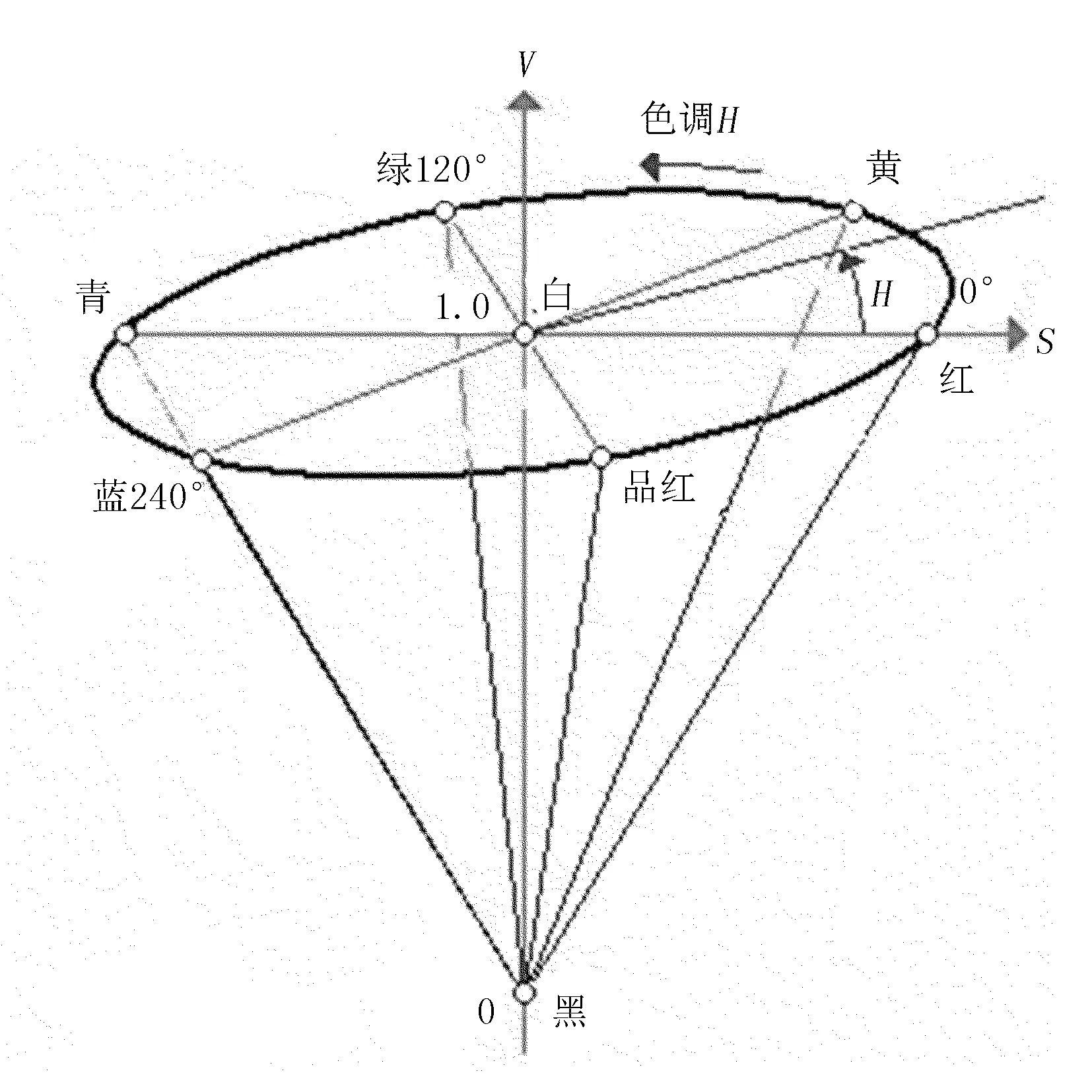
圖6 HSI顏色模型Fig.6 HIS color model。
在進行圖像預處理過程中,先將采集到的圖像轉為HSV模型,然后對圖片進行亮度、均衡化、閾值化等處理,再轉換成RGB顏色模型進行最終的圖像增強。RGB顏色模型轉化成HSV模型的公式為
Max←max(B,G,R)
(11)
Min←min(B,G,R)
(12)
(13)
(14)
V←Max
(15)
其中,H為色調值;S為飽和度值;V為明度值;R為紅;G為綠;B為藍。Max和Min分別為B、G和R中的最大值、最小值。H∈[0,360]為角度的色相角,而S、V∈[0,1]為飽和度和亮度值。
2)濾波器選擇。圖像處理常用的有均值、高斯、直方圖均衡化和中值等濾波算法,在研究過程中,為了提高圖像處理的質量,采用了中值和直方圖均衡化兩種算法。
直方圖均衡化處理中的主要濾波函數為
(15)
其中,0≤rj≤1,k=0,1,2,3,…,l-1;l為灰度級所有的數目;Pr(rj)為灰度第j級的的概率;nj和n為灰度出現的次數和總數。
中值濾波的基本思想是使用標準模板在原始圖像中滑動,對原始圖像內的像素做大小排序,取序列的中值作為圖像該像素點處中值濾波的結果。中值濾波器計算公式為
yk=med(xk-n,xk-n+1,xk-n,…,xk,xk+n+1,xk+n)
(16)
3 K-means聚類和BP神經網絡結合
為了提高系統分類識別的精準度,在K-means聚類算法的基礎上增加了BP神經網絡算法。二者結合的構造分類模型,如圖7所示。
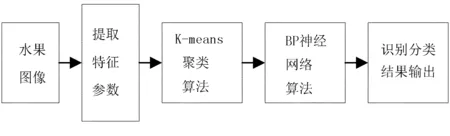
圖7 水果等級識別的分類模型Fig.7 The classification model of fruit grade recognition。
水果等級識別的分類模型描述如下:
輸入:待識別分類的水果圖像;
輸出:已經識別分類的水果圖像。
本文研究的K-means聚類和BP神經網絡相結合的水果等級識別方法的實現過程如下:
1)提出特征參數。對輸入的圖像進行圖像預處理,然后提取水果圖像的特征值。
2)聚類。選取分類類別為特級、一級、二級、三級等4個等級,對等待識別分類的圖像利用K-means方法進行聚類,得到準確的聚類中心。
3)BP神經網絡。設置神經網絡的結構,確定輸入、隱藏和輸出等網絡層數、訓練函數、實現神經網絡的識別分類器。
4)分類識別。對訓練完成的分類模型輸入測試數據,計算出識別分類的正確率。
4 水果分類識別結果分析
本文總共采集了3 000張水果圖像,其中2 100張用于分類模型的訓練集,600張用于測試集,300張用于試驗驗證。試驗中,將水果圖像直接作為分類模型的輸入圖像,分別制作訓練集和試驗集水果的等級標簽,標簽用特級、一級、二級和三級表示;將訓練集、試驗集和水果便簽放于K-means聚類和BP神經網絡相結合的水果分類模型中訓練,驗證分類模型的性能。判定標準為:分類識別正確率越高,模型性能越好。
分類識別正確率為
(17)
其中,la和label分別為數據輸入、輸出的標簽;sum表示分類的總和。
訓練完成后,對50張石榴圖像進行了分類測試試驗,分別采用K-means算法、BP神經網絡算法和二者結合的分類算法進行了分類識別。通過3種算法的識別正確率,可以判斷出哪種算法最優。石榴圖像如圖8所示,3種算法的等級分類識別正確率如表2所示。
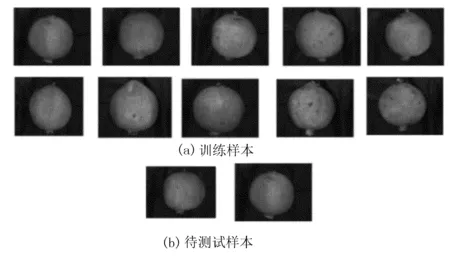
圖8 石榴圖像Fig.8 The pomegranate image。

表2 3種算法的等級分類識別正確率Table 2 The recognition correct rate of classification of three algorithms。
由表1可以看出:單獨采用K-means算法的等級分類正確率為91.52%,BP神經網絡算法為89.36%,采用K-means聚類和BP神經網絡相結合的水果分類算法的正確率為96.28%。因此,采用K-means聚類和BP神經網絡相結合的方法,大大提高了水果分類識別的準確率,并使得識別時間大幅縮短,具有一定的現實意義。
5 結論
針對目前水果質量等級分類難、耗時長的問題,采用K-means聚類和BP神經網絡相結合的方法,設計了一種水果等級分類識別算法,可以實現對水果質量等級的自動分類。試驗結果表明:采用K-means聚類和BP神經網絡相結合的方法,大大提高了水果分類識別的準確率,并使得識別時間大幅降低,具有一定的現實意義。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
數學小靈通(1-2年級)(2021年4期)2021-06-09 06:25:56
大眾健康(2021年6期)2021-06-08 19:30:06
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
中學生數理化·七年級數學人教版(2019年4期)2019-05-20 10:06:32
中學生數理化·七年級數學人教版(2018年6期)2018-06-26 08:36:06
初中生世界·七年級(2017年9期)2017-10-13 22:27:46
光學精密工程(2016年6期)2016-11-07 09:07:19
核科學與工程(2015年4期)2015-09-26 11:59:03
