基于即時反饋的反應抑制訓練對青少年和成人執行功能的訓練效應和遷移效應*
2020-10-20 08:32:00蓋笑松曹逸飛
心理學報 2020年10期
王 元 李 柯 蓋笑松 曹逸飛
(1 東北師范大學心理學院,長春 130024) (2 煙臺文化旅游職業學院,山東 煙臺 264000)
1 引言
在眾多認知功能中,執行功能(Executive Function,簡稱EF)在青春期及其之前的階段發展迅速,能夠較好地預測個體的短期成就(如學業成就)和長期發展(如健康、事業成績、社會經濟地位等),其預測性甚至優于傳統的智力因素(Moffitt et al.,2011)。執行功能是問題解決的心理過程中必須用到的一種功能結構,能使個體在完成復雜認知任務時,協調各種資源,控制系統完成各種加工(Diamond,2013),包含三個主要成分,分別是抑制(Inhibition)、工作記憶(Working Memory)和認知靈活性(Cognitive Flexibility) (Miyake et al.,2000)。推理、計劃和問題解決被認為是高級的、整合性的執行功能指標(Diamond,2013)。當前,針對執行功能的訓練及其可塑性研究漸成規模。Diamond 等人對執行功能訓練研究進行了梳理,發現目前主要有6類訓練方法,包括計算機訓練、計算機和非計算機混 合游戲、武術與正念練習、課堂教學、課堂教學補充和體育運動(Diamond &Lee,2011)。其中,計算機訓練是開展較早且成果豐富的干預方案。采用工作記憶,特別是刷新任務為訓練方案的研究已經展現出了對執行功能,甚至包括流體智力較強的遷移效應(Melby-Lerv?g,Redick,&Hulme,2016)。抑制和認知靈活性的訓練研究相對缺乏,特別是抑制訓練鮮有遷移效應產生(Enge et al,2014;Zhao,Chen,&Maes,2018;Zhao &Jia,2019)。
部分研究發現,兒童和青少年經過抑制訓練都出現了遷移效應,但二者之間無差別(Johnstone et al.,2007)。Zhao 等(2018)的研究則發現與成人組相比,兒童受訓者出現了更大的遷移效應。以上研究結果很好地支持了補償模型,即認知訓練的效果與個體的基線水平呈負相關,在訓練效果存在一定閾限的情況下,高基線水平往往意味著可改善的空間更少,可塑性更低(Gaultney,Bjorklund,&Goldstein,1996;Karbach &Kray,2010)。但根據該結果推斷出青少年和成人抑制功能訓練的遷移效應有差別是存在風險的。這是因為不能跳過青春期,直接比較兒童和成人的訓練效果。從兒童期到青春期,個體神經纖維的髓鞘和額葉皮層在持續發育(Diamond,1985;Diamond,1996;Eriksen &Eriksen,1974;Stroop,1935)。雖然在6 歲以前兒童抑制已開始迅速發展,但對他們而言,完成大部分抑制相關任務仍然存在較大困難(Dowsett &Livesey,2015)。這就使得如果想直接比較兒童和成人訓練結果,要么選擇對兒童來說難度適合的任務,但對成人來說任務成績易出現天花板效應;要么選擇對成人來說難度適合的任務,但對兒童來說任務成績易出現地板效應。個體在兒童期抑制多為質變,如對任務規則概念的理解等;而在青春期則以量變為主,如逐步增強的有效抑制(Best &Miller,2010)。到了成人期初期,抑制功能發展成熟并趨于穩定(Williams,Ponesse,Schachar,Logan,&Tannock,1999)。因此,在選擇訓練和遷移任務上,兒童應比青少年、成人難度低,青少年和成人則可相對統一(Anderson,2002),但現有的比較研究均缺乏這方面的考量(Johnstone et al,2007;Zhao &Jia,2019)。因此,本研究首次比較青少年和成人在經過抑制訓練后,是否出現對執行功能的訓練效應和遷移效應。
選擇何種抑制功能加以訓練的前提,是這種抑制功能在青少年和成人階段的發展具有差異性。但青少年是否具有與兒童同樣的反應抑制能力,還是其可塑性與成人接近并未得到一致的結論。根據維度重疊理論(Dimensional Overlap),刺激沖突指任務相關刺激和任務不相關刺激之間存在相似性,對刺激沖突進行有抑制任務即干擾抑制任務(Interference Inhibition),如Stroop 任務和Flanker任務;反應沖突是任務相關刺激集與反應存在相似性(Kornblum,1992;Kornblum,Hasbroucq,&Osman,1990;Kornblum,Stevens,Whipple,&Requin,1999),對反應沖突進行抑制的任務即反應抑制任務(Response Inhibition),常見的有Simon 任務。Jongen和Jonkman (2008)指出6~7 歲的兒童能夠完成干擾抑制任務,而10~12 歲兒童在完成反應抑制任務時仍有較多錯誤,這說明刺激沖突的發展和成熟早于反應沖突,反應沖突機制可能直至青少年或甚至成年早期才能成熟。另一研究者發現,5 歲兒童在Simon 和Stroop 任務中存在沖突適應效應,而在Flanker 任務中該效應不明顯(Ambrosi,Lemaire,&Blaye,2016)。Ambrosi,Servant,Blaye 和Burle (2019)采用分布分析(Distribution Analyses)進一步證明5~6 歲兒童完成 3 種沖突任務(Flanker,Simon,Stroop)的機制與成人相似,只是時間進程不同。Liu等人(2018)探討了兒童在刺激沖突和反應沖突中的沖突適應效應。5 歲兒童、10 歲兒童、大學生完成Flanker 任務和Simon 任務,發現在完成Flanker 任務時,三個年齡階段的被試沖突適應效應的差異不大,而在完成Simon 任務時,5 歲兒童比10 歲、大學生的沖突適應效應明顯更小,說明刺激沖突的大腦機制在5 歲時已相對成熟,但反應沖突的腦機制在兒童期還沒有成熟,可能直至成年早期才能成熟。因此,比較青少年與成人的干擾抑制能力的可塑性,能夠探索干擾抑制能力可能的成熟階段。
Rueda,Rothbart,Mccandliss,Saccomanno 和Posner (2005)使用含干擾控制任務在內的一個訓練任務組,經過5 天的訓練,發現能夠遷移到4~6 歲兒童的推理能力上。但事實上,從這類使用多任務的訓練研究(Denckla,1996)是無法推斷出哪個訓練任務或哪個認知功能的訓練產生的遷移效應。甚至多任務訓練也不能代表訓練效應或遷移效應更佳,Thorell,Lindqvist,Nutley,Bohlin 和Klingberg (2009)同時使用干擾抑制和沖突抑制的訓練研究就未發現任何遷移效應。越來越多的研究者不主張使用多訓練任務或復雜訓練任務(Diamond &Ling,2015;Friedman &Miyake,2004;Shilling,Chetwynd,&Rabbitt,2002),因為這樣容易導致單純的抑制功能訓練劑量不足,多個任務、多個認知成分之間還可能產生相互作用,難以捕捉遷移效應產生的來源。目前使用干擾抑制單任務作為訓練任務的研究相對偏多,如Zhao 等(2018)就發現了Stroop 訓練任務對執行功能多成分和推理的遷移效應,但也有一些研究并未發現任何遷移效應(Strobach,Salminen,Karbach,&Schubert,2014)。個體執行Stroop 任務的過程就是對優勢反應(加工語義信息)進行抑制,并完成對任務相關信息(顏色)的加工的過程(Verbruggen,Liefooghe,&Vandierendonck,2004。與Stop Signal 任務壓抑優勢反應的過程是具有相似性的;其與Go/No-go 任務和Flanker 任務在反應選擇階段也會共享右側背外側前額葉皮層(right DLPFC)和前扣帶回(ACC)等區域(Nee,Wager,&Jonides,2007),這些都為Stroop 任務訓練向抑制任務遷移提供了前提。干擾抑制對競爭性干擾刺激的抑制功能與工作記憶N-back 任務的刷新功能存在機制一致性(Zhao &Jia,2019),這可能是Stroop 任務能夠對包括工作記憶、推理等執行功能成分產生遷移效應的功能基礎。但以上結論也可能導向另外一種假設,那就是Stop signal 任務作為一種與Stroop 任務、Go/No-go 任務加工過程相似,對無關反應做出抑制的功能,其訓練對執行功能同樣會發生訓練效應和遷移效應。
Logan 和Cowan (1984)以Stop Signal 任務為訓練任務,發現6 小時的訓練出現了明顯的訓練效應,但未發現遷移效應。這一結論在對肥胖人群的訓練中也得到了驗證(Guerrieri,Nederkoorn,&Jansen,2008)。沒有產生遷移效應的原因有一種可能是,在訓練產生的反復練習中,刺激-反應聯結不斷發生改變,加上未能成功進行抑制的試次的負強化作用,阻礙了自動化抑制的發展,所以未能使抑制能力得到改善(Spierer,Chavan,&Manuel,2013)。另一種可能是過于注重反應速度,而對stop 試次的正確率有所忽視,導致任務表現的不理想。事實上,正確率是保障被試在stop 和go 試次中更多關注stop 試次正確率,發揮抑制功能的基本指標。只關注速度而放松對正確率的關注,可能意味著較低的抑制水平,或無效的抑制訓練效果(Enge et al,2014)。根據強化理論,個體做出反應后,應立即被告知其反應是否正確。如果答案是正確的,即時反饋就是一種強化物,如果答案是錯誤的,即時反饋就是糾正的措施。可見,反饋的即時性能夠使強化作用得到更好的發揮(Melanko &Larkin,2013)。可以認為,通過在訓練試次間加入反饋,能夠起到高效強化、固化聯結的作用(Littman,2015;Mnih et al,2015)。同時,在試次間加入即時反饋還有助于個體把握“速度-正確率權衡” (Kohls,Peltzer,Herpertz-dahlmann,&Konrad,2010;Leotti &Wager,2010)。在訓練過程中加入反饋,不僅便于個體了解當前表現以調整接下來的反應策略,更能將其作為一種強化物,使個體更傾向于做出正確的反應,更加關注正確率。因此,本研究擬在青少年和成人訓練組中加入即時反饋步驟,而在積極控制組中僅訓練Stop Signal 任務,考察有即時反饋的Stop Signal 任務訓練是否會產生訓練和遷移作用。
綜上,為考察從青春期到成年期階段,反應抑制訓練對執行功能的訓練效應和遷移效應,本研究以基于即時反饋的反應抑制任務——Stop Signal 范式為訓練任務,測量訓練前后青少年和成人在執行功能中反應抑制的 Go/No-go 任務、干擾抑制的Stroop 任務、工作記憶的N-back 任務和推理上是否發生訓練效應及遷移效應,兩種效應是否存在年齡差異。
2 研究方法
2.1 被試
在吉林省一所高校和一所中學招募成人被試150 人,青少年被試60 人。其中成年男性65 人,成年女性85 人,平均年齡20.55 ±0.79 歲;青少年男性人34,青少年女性26 人,平均年齡15.1 ±0.30歲。所有被試均為右利手,視力或矯正視力正常,半年內未參加過類似心理學實驗且自愿參與本次實驗。實驗開始前自主或在家長監護下簽署《知情同意書》。實驗結束后所有被試均獲得10 元/次現金或同等價值小文具作為報酬。將成人被試隨機分配到成人實驗組、成人積極控制組和消極控制組中,其中16 名成人被試因中途退出或個人原因未能完成實驗(實驗組5 名、積極控制組3 名,消極控制組8 名),最終成人實驗組有效樣本量為47 人,成人積極控制組為45 人,消極控制組為42 人。將青少年被試隨機分配到青少年實驗組30 人,青少年積極控制組30 人。
2.2 研究任務
2.2.1 Stop Signal 任務
對經典Stop Signal 任務(Verbruggen &Logan,2008)進行改編,作為訓練任務和反應抑制測量任務。計算機屏幕中央首先呈現注視點(加號“+”),持續時間500 ms;隨后出現任意方向白色箭頭作為go 刺激(左右方向隨機出現次數各半),持續時間1000 ms,要求被試判斷目標刺激類型并做按鍵反應,左向箭頭按“F”鍵,右向箭頭按“J”鍵。在stop試次中,停止信號(箭頭上方藍色小三角)出現時,要求被試抑制對刺激的沖動,不進行任何反應。每個block 內所有試次均以完全隨機形式呈現。任務以自適應方式增加難度,即stop 試次箭頭出現與三角出現之間的時間間隔(SSD)隨前一stop 試次表現而不斷調整,為確保刺激識別有效性,變化范圍設置為250~750 ms,反應正確增加50 ms,反之則減少50 ms。實驗組與積極控制組在該任務上的區別是,在實驗組程序中加入即時反饋,即每一試次后,在屏幕中央會緊接著呈現當次反應的反應時和判斷正誤。共有32 個練習試次,正式實驗共有4 個block,每個block 共有100 個試次。具體流程見圖1。本研究使用2 個指標代表該任務成績:(1)SSRT 計算每個反應刺激與停止刺激之間的時間間隔,即停止信號間隔(stop signal delay,SSD)的平均值,用go反應時減去平均的SSD 就得到了每個被試的停止信號反應時(stop signal reaction time,SSRT)。SSRT越長,反應抑制能力越差。(2) stop 試次正確率。
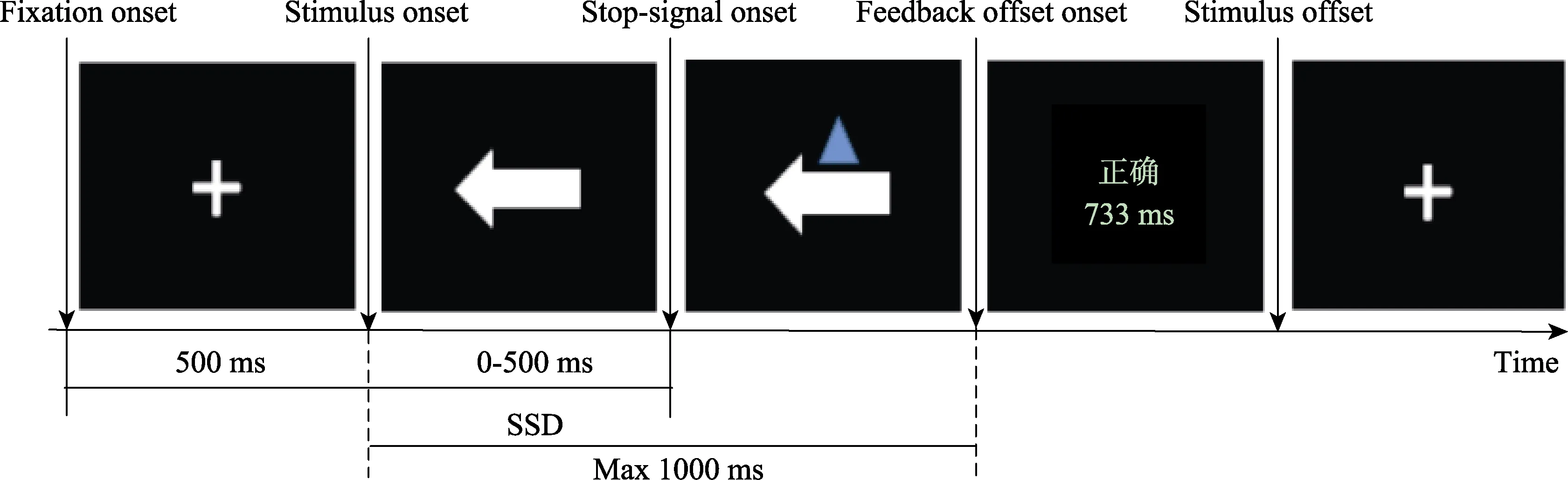
圖1 有反饋的自適應步速Stop Signal 任務流程圖
2.2.2 Go/No-go 任務
采用該任務作為反應抑制的測量任務。任務刺激由一個白色數字(1~9)組成,計算機屏幕中央首先呈現注視點“+”500 ms,隨后隨機出現1~9 內任意數字1000 ms (“3”與其他數字出現次數各占總次數的25%與75%),要求被試看到數字“3”不進行反應,其他數字按空格鍵進行反應。每個block 內所有試次均以完全隨機的方式呈現。共有4 個block,每個block 含32 個練習試次及100 個實驗試次。本研究使用3 個指標代表該任務成績:(1) Go 試次反應時;(2) No-go 試次正確率;(3)d′。
2.2.3 Stroop 任務
該任務作為干擾抑制的測量任務。任務刺激由不同顏色的顏色詞(“紅”、“綠”、“黃”、“藍”)組成,計算機屏幕中央首先呈現白色注視點“+”500 ms,隨后隨機出現顏色詞1000 ms,要求被試對字的顏色進行判斷,(紅色按“R”鍵,綠色按“F”鍵,黃色按“U”鍵,藍色按“J”鍵)。在一致試次中,刺激詞語的詞義與顏色相同;在不一致試次中,刺激詞語的詞義與顏色不同。其中一致試次與不一致試次數量分別占總試次數的75%、25%。實驗共有4 個block,每個block 包含36 個練習試次及100 個實驗試次。本研究使用Stroop 效應代表該任務成績,即不一致試次反應時與一致試次反應時的差值。
2.2.4 N-back 任務
選用N-back 任務作為工作記憶的刷新能力測量任務,作為遠遷移指標之一。任務刺激由大寫英文字母(A~Z)組成,屏幕中央首先呈現500 ms 注視點“+”,隨后隨機呈現任意英文字母,要求被試根據之前字母對當前字母進行判斷并做出反應。在一致試次中,當前呈現字母與n 個步驟前呈現字母相同,要求被試按“F”鍵進行反應;不一致試次中,呈現字母不相同,按“J”鍵進行反應。本任務共分為2個block——2-back block 和3-back block,要求被試分別根據2、3 個步驟之前呈現字母來判斷當前字母,每個block 包括20 個練習試次及100 個實驗試次。以正確率代表該任務成績。
2.2.5 瑞文標準推理測驗
使用瑞文標準推理測驗(Raven,Raven,&Court,2000)作為執行功能整體性指標推理能力的測量任務,遠遷移指標之一。該測驗為非文字測驗,要求被試根據已給出圖形在選項中選出圖形缺失的部分。本測驗共包含60 道題目。將該測驗分為前測用測驗和后測用測驗。前測測驗中包含A、C、E測驗的奇數項目和B、D 測驗的偶數項目,合計30道題;后測測驗中包含A、C、E 測驗的偶數項目和B、D 測驗的奇數項目,合計30 道題。以正確率為指標。
2.3 研究程序
本研究包括前測、訓練、后測三個階段。在前、后測階段,抑制功能任務(Stop Signal、Go/No-go、Stroop)、工作記憶任務(N-back)、瑞文標準推理測驗采用隨機順序進行測量,為避免疲勞效應,均分為兩天進行。在訓練階段,對實驗組和積極控制組進行持續3 周,每周3 次的Stop Signal 任務訓練,其中實驗組訓練任務中加入即時反饋,積極控制組無反饋。訓練共分為8 個block,每個block 包含100個試次。
2.4 實驗儀器
本研究采用E-prime 2.0 軟件編輯、運行實驗程序和記錄被試反應。任務刺激由臺式計算機呈現,顯示器為18.5 英寸戴爾E1916HM,屏幕分辨率為1366×768,刷新率60 Hz。被試雙眼位置距離顯示器屏幕約60 cm,在亮度適中、環境安靜的實驗室單獨展開實驗。
2.5 數據分析
使用SPSS 22.0 軟件進行數據分析,對測試成績進行標準化處理并采用重復測量方差分析對訓練改善及遷移效果進行探究。其中,反應錯誤或反應時 >4000 ms 的試次,及其他任務中反應時 <200 ms,超出3 個標準差的試次均予以剔除或均值替代處理。
3 結果
3.1 訓練進程及訓練效應
3.2 遷移效應
前測和后測的結果詳見表2。分別對各任務的指標進行2(測量時間:前測、后測) × 5(組別:青少年實驗組、青少年積極組、成年實驗組、成年積極組、消極組)重復測量方差分析,結果如下:
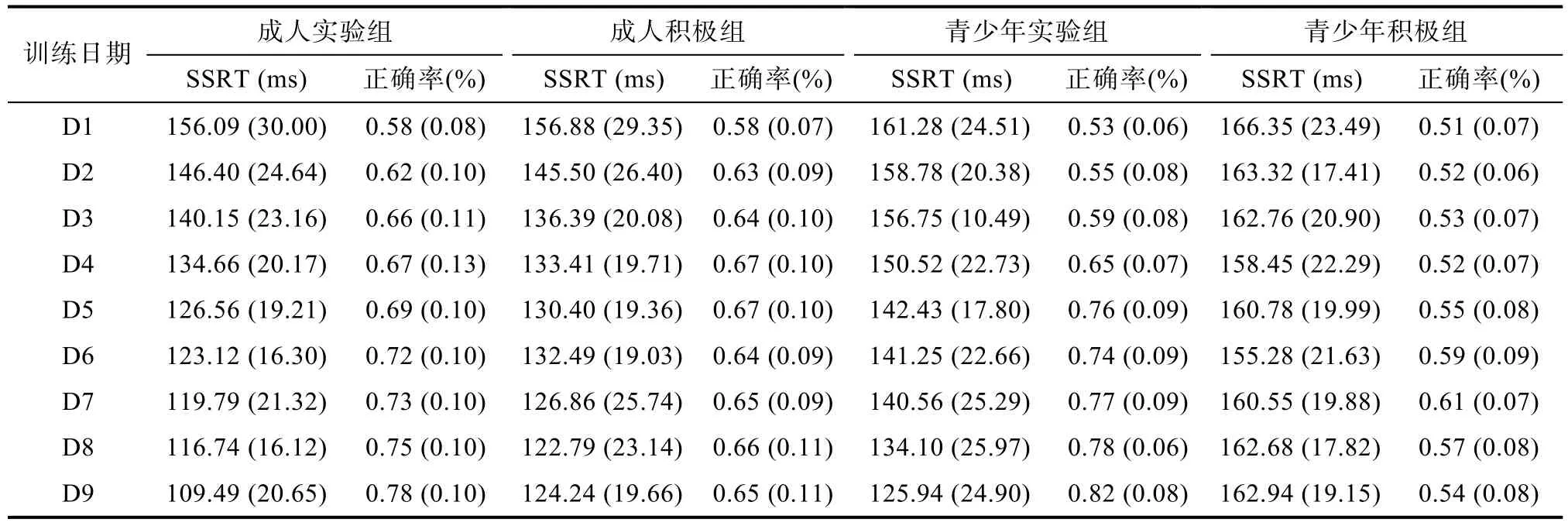
表1 四個訓練組每日Stop Signal 任務訓練效應的描述統計
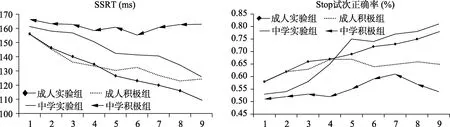
圖2 Stop Signal 任務訓練進程圖
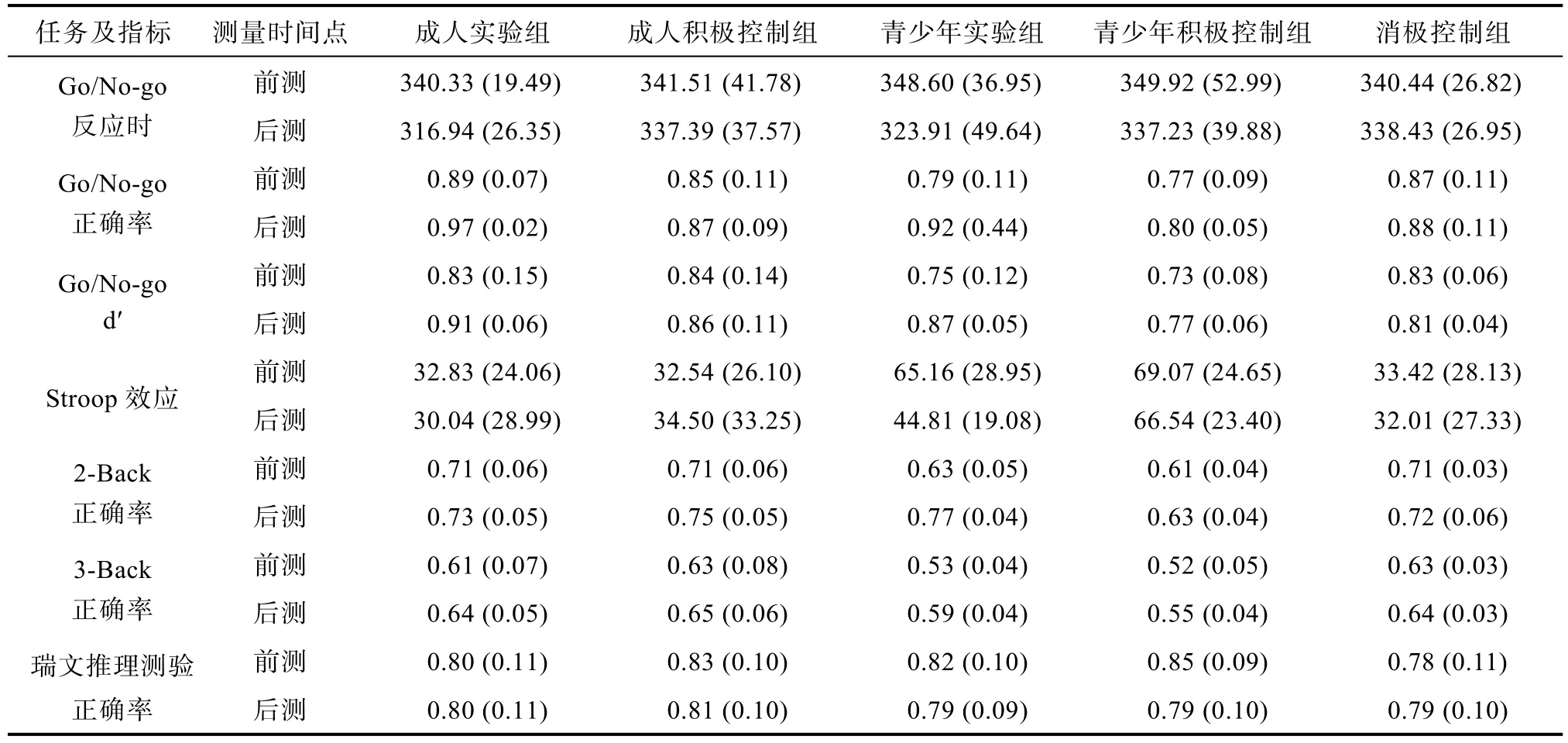
表2 各任務在兩次測量時間上遷移效應的描述統計結果
3.2.1 反應抑制任務——Go/No-go 任務
對Go/No-go 任務的反應時、正確率、d′分別進行重復測量方差分析。
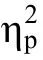
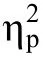
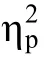
綜合三個指標的結果可見,帶反饋的反應抑制訓練對成人和青少年在Go/No-go 任務成績有明顯的改善,Go/No-go 任務和其他任務的遷移效應的變化趨勢詳見圖3。
3.2.2 干擾抑制任務——Stroop 任務
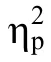
3.2.3 工作記憶刷新任務——N-back 任務
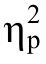
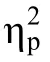
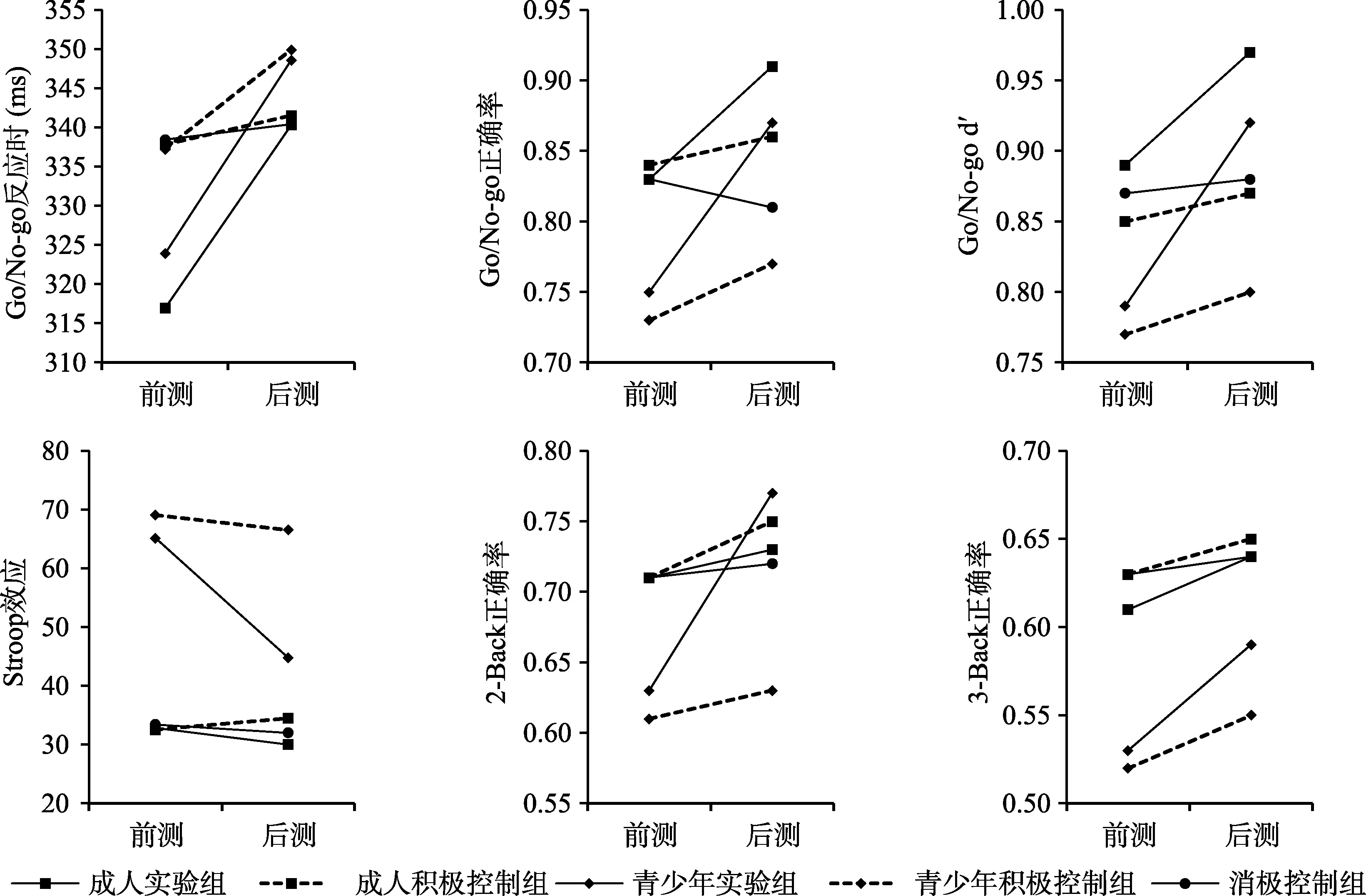
圖3 因訓練發生遷移效應的各任務成績變化趨勢圖
3.2.4 瑞文標準推理測驗
4 討論
通過為期3 周27 次的Stop Signal 任務訓練,本研究發現基于即時反饋的Stop Signal 訓練任務能夠對青少年和成人產生訓練效應。青少年和成人在同為反應抑制的Go/No-go 任務上都發生了近遷移,在工作記憶上發生遠遷移,但在瑞文標準推理測驗正確率上均未發生改善。青少年出現了在干擾抑制Stroop 任務上的近遷移;但未見成人在這個任務上發生遷移。結果支持Stop Signal 任務訓練可以改善執行功能的結論(Johnstone et al,2007),但遷移受到認知可塑性的年齡差異和任務性質的雙重影響,因訓練產生遷移效應的任務成績變化趨勢。
本研究顯示,青少年和成人在抑制功能訓練效應和遷移效應上存在差異,與Johnstone 等(2007)和Zhao 等(2018)的間接結論相互印證,同時部分支持以往成人經過該訓練無遷移效應的結論(Enge et al,2014)。該結果也符合前額葉皮層的發育與抑制功能關系的發展證據(Diamond,1985;Diamond,1996),和行為學證據(Anderson,Anderson,Northam,Jacobs,&Catroppa,2001)。根據Best 和Miller (2010)的分析,青春期抑制功能的發展以量變形式出現,以成年期為轉折點。我們的結果很好地充實了其觀點,所謂量變是與兒童期較快的變化速率相比得到的結論,但事實上青春期的量變解決的卻是抑制有效性的問題,而兒童期發展解決的是能或不能抑制的問題。青少年抑制功能的不斷發展帶來的直接結果是自上而下地促進執行功能相關認知功能的變化。結果支持補償模型的觀點,青少年組訓練任務的正確率基線水平是低于成年組的(見表2),經過訓練,其改善顯著優于成年組(Gaultney et al.,1996;Karbach &Kray,2010)。
本研究在訓練后,都發現了對青少年和成人的Go/No-go 任務的遷移效應,支持了Enge 等的成人訓練結果(Enge et al,2014)。Stop Signal 任務的本質是加工當前任務中的刺激和stop 信號觸發的停止加工二者之間的競爭,進行任務刺激加工的反應時與stop 信號延遲和stop 信號反應時之和的大小比較,直接決定了是做出反應還是抑制反應(Logan &Cowan,1984)。結合訓練進程和有無即時反饋的數據分析結果可以見,SSRT 和正確率都有明顯的改善,訓練提高了個體的“速度-正確率權衡”,即獲得了更快的速度和更低的虛報率。這種改善更易遷移到同樣需要對兩類刺激做出“速度-正確率權衡”的Go/No-go 任務上。在Go/No-go 任務中,要求個體看到Go 刺激時盡快做出反應,而對No-go 刺激不做反應,故更短的 Go 刺激反應時和更低的No-go 刺激虛報率代表了該任務成績的改善,這也需要個體具有良好的“速度-正確率權衡”。此外,De Jong 等認為,外周機制(Peripheral Mechanism)與迅速的、非選擇性的抑制任務相關聯,如No-go 任務;而stop 任務則受制于中心機制(Central Mechanism)(de Jong,Coles,&Logan,1995)。但Van Boxtel 認為在stop 信號延遲(SSD)的時長未超過閾限時,No-go任務與stop 任務是在中心機制與外周機制共同作用下展開的,兩種任務屬于同一機制(van Boxtel,van der Molen,Jennings,&Brunia,2001)。因此Stop Signal 任務的改善效果對處于同一機制下的Go/No-go 任務發生遷移是十分容易的。
研究僅在青少年組發現了對Stroop 任務的遷移效應。Stroop 任務和Stop Signal 任務都存在對優勢反應抑制的加工階段,能夠解釋遷移效應的發生。但成年組沒有發生遷移,成年組結果與Enge等的成人訓練結果(Enge et al,2014)和Wilkinson 和Yang (2012)采用Stroop 訓練任務改善Go/No-go 任務的結果是一致的。這可能與Stroop 任務對選擇性注意的高度依賴存在關系。Stroop 任務與Flanker任務類似,都要求對于無關的分心物進行過濾,以完成反應,只不過在Stroop 任務中分心物和靶子都是同一個刺激的不同屬性。由于其分心物自動加工程度更高,具有高度優先性,因此在Stroop 任務中需要調用更多的選擇性注意來過濾分心物。選擇性注意在兒童到青少年時期不斷發展,直到成年期才成熟(Brodeur &Pond,2001;Karatekin,2004)。依據補償模型(Gaultney et al.,1996;Karbach &Kray,2010),青少年相對低的選擇性注意因訓練而改善的程度大于成人,這可以在一定程度上解釋青少年出現了訓練對Stroop 任務的遷移效應。
針對執行功能工作記憶成分和整體指標推理能力的遠遷移結果顯示,訓練成功改善了青少年和成人的工作記憶刷新功能,但未能改善推理能力。在執行功能訓練相關的研究中,后測、追蹤階段中,若訓練對與訓練任務測量相同心理功能任務成績有明顯影響即稱為近遷移。如訓練空間工作記憶廣度任務,在同樣測量工作記憶廣度的言語工作記憶廣度任務上有明顯的成績改善,就可以認為空間工作記憶廣度任務訓練對言語工作記憶廣度任務產生了近遷移。可見,近遷移是發生在功能接近的任務之間的。相反的,因訓練而改善了測量其他心理功能的任務成績,如抑制功能訓練改善工作記憶、認知靈活性、流體智力等非抑制功能成分時,就認為訓練產生了遠遷移。從神經水平而言,遠遷移是訓練效應跨越訓練領域,與訓練任務共享類似神經環路的基礎上發生的(Dahlin,2013;Jaeggi,Buschkuehl,Jonides,&Perrig,2008);從行為水平上看,能夠發生遠遷移的認知功能應該與訓練任務具有類似的認知機制(Morrison &Chein,2011)。Conway,Kane 和Engle (2003),以及Gray,Chabris和Braver (2003)的研究均支持當保持和加工信息時為了減少干擾,執行控制機制就會發揮作用,此時會觀察到工作記憶任務所需的前額葉皮層被激活。在行為層面,刷新和抑制都需要抑制無關信息(Maraver,Bajo,&Gomez-Ariza,2016)。我們的結果能夠支持二者存在神經基礎和認知機制相關性的推論。雖然反應抑制與推理具有共同的認知成分,但是否發生遷移效應仍存在爭議(Ji,Wang,Chen,Du,&Zhan,2016;Loosli et al.,2016),本研究未發現兩組在推理上的遷移效應,這可能是反應抑制與推理之間相關程度不高有關(Bellaj,Salhi,le Gall,&Roy,2015)。
加入即時反饋后,成人的訓練效應并未發生變化,而青少年組則在訓練的第5~9 次開始出現了明顯的改善。反饋還同時影響到了成人在Go/No-go任務和2-back 任務上的遷移效應,但未影響Stroop任務、3-back 任務和瑞文推理測驗成績。在青少年組看到了反饋在執行功能的抑制和工作記憶成分上引發的遷移效應的差異,推理成績卻未受影響。以上結果有力地支持了反饋能夠改善“速度-正確率權衡”的觀點(Leotti &Wager,2010;Kohls et al,2010)。個體傾向于為了成功執行接下來stop 任務而延長當前任務的反應時(Boehler,Appelbaum,Krebs,Hopf,&Woldorff,2012),導致SSRT 降低而stop 試次正確率上升、反應速度下降(Leotti &Wager,2010)。反饋信息作為一種強化物能夠誘發個體產生即時情緒,進而會通過自上而下控制系統和趨近-回避動機系統的交互作用來調節下一步的目標指向性行為(Hare &Casey,2005)。青少年組比成人對反饋更加敏感,與青少年對目標指向性注意任務中情緒信號更加敏感關系密切(Monk et al,2003),兒童和青少年表現出對動機性信息更加強烈的情緒偏向。在本研究中,反饋更易使得青少年調整“速度-正確率權衡”,有策略地追求提高正確率(見圖2,訓練進程中stop 試次正確率的變化)。支持Enge 等(2014)對Stop Signal 訓練任務未發生遷移效應的推斷,即個體在任務中過于追求速度,而忽略了正確率。強化理論觀點相一致,認為即時反饋能夠帶來更好的強化作用,對于正確反應可以形成強化,而錯誤行為則可以得到及時的矯正。因此,本研究在每試次結束后加入即時的反饋來提高被試對正確率的關注度,使得被試在每個試次后能夠對自己的表現進行把握,從而更好地決定下一試次的反應選擇。
本研究采用單一訓練任務——反應抑制Stop Signal 范式為訓練任務,比較發現在與成人完成相同的執行功能操作時,青少年能夠從反應抑制訓練中獲益更大。研究結果補充了抑制訓練改善執行功能的發展趨勢,直接驗證了青春期比成年期從抑制訓練中獲益更大的觀點,證明抑制訓練能夠產生效果的基本前提是受訓者應處于成年期以前的年齡階段。在選擇訓練任務上,本研究選取了“認知成分”相對較少的反應抑制任務,證明在大腦可塑性較強的時期,即使使用只在行為層面發生沖突和抑制的訓練任務,同樣可以改善個體的高級認知功能。但改善因訓練任務和遷移任務之間認知機制、激活腦結構的相似性而局限在抑制和工作記憶等基礎因素上。對整合程度較高的推理能力來說,訓練難度仍顯不足。證明干擾抑制和反應抑制任務均可作為訓練任務,但反應抑制任務遷移效果相對狹窄。研究發現即時反饋能夠提升訓練和遷移效應,證明動機性和情緒性因素在認知訓練中發揮強大的動力作用,提示未來有必要將即時反饋作為基礎環節加入訓練程序,以有效提升訓練效果。
同時,必須要認識到本研究仍有一些局限,應在今后的研究中加以注意。首先,本研究僅比較了青少年中期和成年初期兩個非連續年齡組,缺少更趨近于兒童期的青少年初期和更類似于成年期的青春期后期兩個年齡組,缺少發展研究的連續性。未來應豐富青春期向成年期過渡的連續變化趨勢研究。其次,本研究沒有測量認知靈活性。不測量認知靈活性是因為考慮到認知靈活性的典型測量任務是任務轉換范式,有證據表明任務轉換是通過分段復述的方式加強刷新功能,進而加強自身功能,其加工過程大量調用了刷新功能(Boot,Kramer,Simons,Fabiani,&Gratton,2008)。若刷新功能有改善,間接證明認知靈活性有改善,故為縮短前后測和追蹤階段的測量時間,刪減了認知靈活性測量。在測量時間和被試精力允許情況下,今后研究應補充這部分測量。再次,本研究即時反饋僅出現了個體完成一個試次后,進入下一個試次時反饋信息消失,沒有達到即時反饋的實時(on-line)效果。視頻游戲訓練是一種生態化效果和遷移效應較佳的執行功能訓練方案,其突出優勢之一就是在進行游戲過程中即時反饋是以進度條、計時器、分數棒等方式伴隨任務呈現的,個體可以不間斷地受到反饋條件的強化。今后研究可借鑒游戲訓練中實時反饋的方法,不僅在試次后呈現反饋信息,同時在每個試次中都累計已經完成試次的平均反應時和平均正確率,可能會更加提升個體的訓練效果。
5 結論
基于即時反饋的Stop Signal 訓練任務能夠在青春期和成年階段產生訓練效應。遷移效應受到認知可塑性的年齡差異和任務性質的雙重影響。在青少年和成人組,均發生了對同為反應抑制的Go/No-go 任務和工作記憶的遷移效應,但未能出現對推理能力的遷移。對干擾抑制Stroop 任務的遷移僅出現在青少年群體中。本研究為抑制功能訓練研究提供了訓練改進建議,在計算機化訓練中加入即時反饋能夠有效提升訓練效應和遷移效應;補充了抑制訓練改善執行功能的發展趨勢,直接驗證了青春期比成年期從抑制訓練中獲益更大的觀點,提示未來抑制功能訓練對成年期以前的年齡階段更具有塑造作用。
猜你喜歡
中華詩詞(2022年6期)2022-12-31 06:41:24
核科學與工程(2021年4期)2022-01-12 06:30:26
瘋狂英語·新讀寫(2021年7期)2021-10-13 06:35:44
今日農業(2020年19期)2020-12-14 14:16:52
中國科技論壇(2017年7期)2017-07-25 08:49:53
中學物理·高中(2016年12期)2017-04-22 11:53:03
中國火炬(2014年4期)2014-07-24 14:22:19
中國中醫藥現代遠程教育(2014年22期)2014-03-01 04:32:55
中國中醫藥現代遠程教育(2014年16期)2014-03-01 04:28:54
中國火炬(2013年1期)2013-07-24 14:20:18
