用于草坪場景理解的輕量化圖像分割算法
2020-10-28 01:44:02侯枘辰鞏彥麗
計算機技術與發(fā)展 2020年10期
侯枘辰,劉 瑜,廉 華,鞏彥麗
(浙江理工大學 機械與自動控制學院,浙江 杭州 310018)
0 引 言
隨著經濟社會發(fā)展進程的加快,人們對于環(huán)境的要求從最基礎的滿足生存需求轉移到了滿足發(fā)展需求。隨著綠化草坪面積的不斷增加,草坪養(yǎng)護的工作量也日益增多,草坪養(yǎng)護的過程中,修剪是一項量大且枯燥的工作。基于生產率提升的需求,使得該工作亟需自動化程度、安全性能好的智能割草機器人設備。目前大部分的草坪場景都是在城市內,場景較為復雜,草坪形狀不一,草坪上可能會有各種的障礙物,草坪附近可能有停車、有行人。這給智能移動割草機器人的自主導航與避障帶來較大的困難,因此研究草坪復雜場景的理解識別變得尤為重要。場景理解[1]是對圖像場景中各類對象進行像素級的分割,是智能割草機器人設備研究中基礎且關鍵的技術之一,可以準確地識別出環(huán)境中的障礙物,分辨出需要工作的區(qū)域,為之后的自主導航和避障提供支持。
近年來,深度學習成為圖像分割的重要方式[2],加州伯克利分校的Shelhamer等提出用于圖像分割的全卷積網絡FCN(fully convolutional networks)[3],第一次將深度學習應用到圖像分割領域,主要思想是使用卷積操作代替分類任務中的全連接層,以及上采樣操作將特征圖還原至原始尺寸;劍橋大學機器智能實驗室提出了SegNet網絡[4],該網絡將圖像分割分成了編碼階段和解碼階段,可以更準確地將特征還原至原始位置;Chen等提出了DeepLab圖像分割模型[5],先通過全卷積網絡粗提取特征,再通過全連接條件隨機場優(yōu)化,得到精確的分割圖;Lin G等人設計了RefineNet模塊[6],不斷輸入低層特征得到精確的分割結果。
但是像素級的圖像分割算法存在運算量大、占用資源多、處理速度較慢等缺點,難以滿足硬件配置不高的割草機器人實時檢測的需求。因此該文在RefineNet的基礎上,結合MobileNetV3網絡[7]提出一種用于草坪場景理解的輕量級圖像分割卷積神經網絡,該網絡同時兼顧分割準確率和運行速度,具有更好的綜合性能。同時建立了草坪場景的分割數據集,將構建的神經網絡模型在該數據集上訓練,驗證了移動機器人在草坪場景理解上的可行性。
1 算法理論
1.1 RefineNet網絡
圖像分割任務可以被看作是一種密集的分類任務,深度神經網絡中重復的下采樣操作使得原始圖像在分辨率上產生了嚴重的損失,在整個過程中會丟失大量的圖像結構信息,因此很多在分類任務上表現很好的網絡在分割任務上顯得力不從心。
RefineNet網絡是2016年由Lin G等人提出的,是一種以ResNet101[8]為主干網絡用于圖像分割的神經網絡框架。RefineNet是一種生成式的多路徑增強網絡,具有以下優(yōu)勢:(1)可以利用多個層次網絡層提取特征,采用遞歸的方式增強低分辨率(粗糙)的語義特征以產生高分辨率的分割特征圖;(2)級聯的網絡結構可以進行端到端的訓練;(3)提出了一種鏈式池化操作,可以以一種高效的方式捕捉背景的上下文信息。因此RefineNet在圖像分割的任務上有很好的表現。圖1是標準的RefineNet網絡結構。

(a)網絡框架
1.2 算法的輕量化
該文旨在提出一種用于圖像分割的輕量化神經網絡結構,從圖1可以看出,RefineNet的網絡分為編碼網絡和解碼網絡,因此對網絡的輕量化可以從兩個方面進行。在編碼網絡方面,在保證不影響準確率的前提下,使用深度可分離卷積代替?zhèn)鹘y(tǒng)卷積;在解碼網絡方面,使用小尺寸的卷積核代替大尺寸卷積核。
1.2.1 深度可分離卷積的編碼網絡
標準RefineNet網絡的特征提取網絡采用的是ResNet101網絡,ResNet網絡提出了殘差學習的思想,在網絡中添加了直連通道,解決了隨著網絡加深而產生的梯度下降和梯度爆炸問題,但其使用的依舊是傳統(tǒng)卷積方式。
而MobileNet采用深度可分離的卷積方式,深度可分離卷積[9]是將標準的卷積分解成一個深度卷積和一個點卷積:首先采用1×1的卷積核對每一個通道進行卷積,然后再采用3×3的卷積核進行通道間的信息融合。假設輸入的尺寸是DF×DF×M,輸出的尺寸是DK×DK×N,對于標準卷積,卷積核數為DK×DK×M×N,所以計算量為DF×DF×M×N×DK×DK,而相應的深度可分離卷積的計算量為DF×DF×M×DK×DK+DF×DF×M×N。這樣就將標準卷積計算中的乘法運算轉換成為了加法運算,在不損失精確值的同時,極大地減少了計算量和模型的大小。使用h-swish激活函數代替了ReLU激活函數,有效地提高了網絡的精度,h-swish激活函數[10]的表達式如式(1)所示:
(1)
圖2是使用的MobileNetV3的網絡塊結構,不僅使用了深度可分離卷積的思想,同時結合了具有線性瓶頸的逆殘差結構[9]和輕量型注意力機制[11],在減小網絡計算量的情況下,保證了網絡的精度。
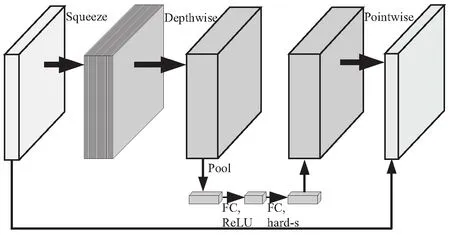
圖2 MobileNetV3網絡塊結構
1.2.2 輕量化的解碼網絡
由圖1可以看出,RefineNet的解碼網絡主要依賴兩個模塊:RCU(residual convolutional unit)和CPR(chained residual pooling),所有的這些模塊都采用了3×3的卷積和5×5的池化,并進行相應的填充以保持空間尺寸。采用大尺寸卷積核的目的是為了增加接受域的大小,但是經過實驗發(fā)現,在RefineNet網絡下,使用1×1的卷積核替代接受域并沒有明顯的差異。反而因為3×3的卷積核的大量使用,網絡的參數數量和浮點運算數量都會變得很大,影響了網絡在移動端的處理效率。因此,將原網絡的CPR模塊和融合模塊中3×3的卷積核用1×1的卷積核代替,僅在最后的分類層中使用了3×3的卷積核。通過這樣的方式,網絡的參數減少了50%。
通過分析各模塊的功能,可以得到如表1所示的結果,在輕量化后的網絡結構里,不管是在精確分割分類還是增加上下文覆蓋率上,CPR模塊都是主要的模塊,而RCU模塊對結果只有微小的提升。所以為了最大限度上地減小參數量和模型大小,在最后的網絡結構里,去除掉了RCU模塊。圖3是輕量化后的解碼網絡。
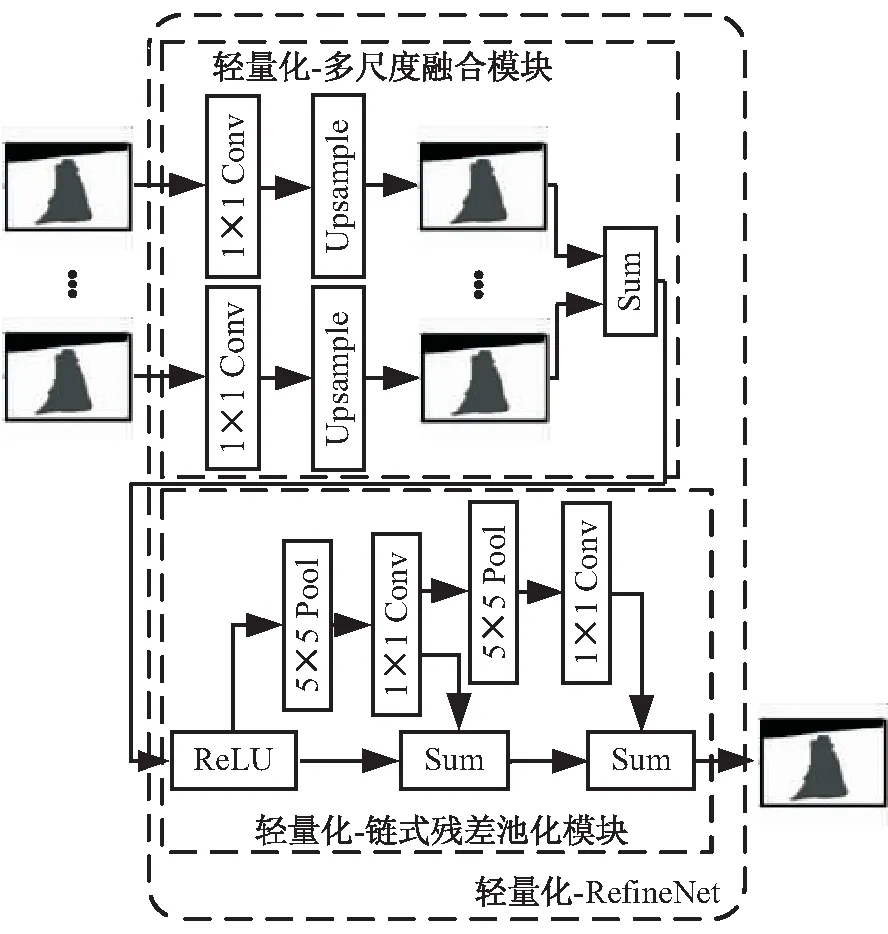
圖3 輕量化的RefineNet解碼模塊
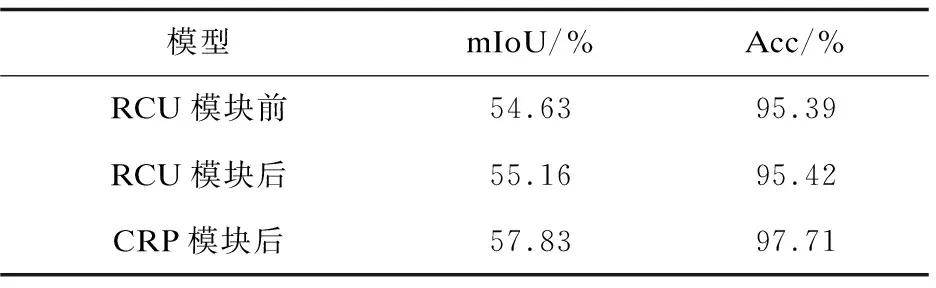
表1 各模塊的效果分析
2 數據集的制作
對于草坪的場景分割任務來說,目前并沒有公開的數據集,因此該文通過獲取網絡上的圖片以及使用相機收集生活中的草坪場景,共231張,通過顏色抖動、隨機裁剪、圖片旋轉等數據增強[12]方式擴充至2 540張,作為實際的訓練測試數據集。
根據生活中草坪的實際環(huán)境,結合網絡的使用場景,將任務定義為識別出環(huán)境中的障礙物,分辨出需要工作的區(qū)域,因此將草坪場景圖像中的對象劃分為5種類別,分別是“背景、草地、行人、汽車以及道路”。使用公開的LabelMe工具對數據集進行標注,并將所有的圖片按照PASAL VOC2012分割樣本集的格式處理和存儲,將整個數據集按照10∶1的比例分為訓練集和測試集。圖4是部分原數據集以及增強后的數據集圖片。

圖4 訓練集樣本與Mask圖
3 實驗結果分析
3.1 訓 練
前文提到,目前沒有用于草坪場景分割的公共數據集,人工標注制作數據集需要耗費大量的人力物力,因此采用遷移學習[13](transfer learning)的方法對構建的網絡進行訓練。遷移學習本質是利用將一個問題上訓練的所得,用于改進在另一個問題的效果,因此可以在文中有限的數據集上,有效地提高模型的泛化能力。該文采用了MobileNetV3在PASAL VOC2012數據集[14]上的訓練模型作為整個網絡的預訓練模型。首先,將預訓練模型的部分參數載入RefineNet網絡,由于預訓練模型的參數是分類網絡訓練得來的,所以只加載特征提取層的參數;然后,沒有預訓練參數的RefineNet模塊解碼網絡部分參數使用Kaiming初始化的方法進行初始化,可以有效地避免激活函數的輸出值趨向于0,保證網絡的訓練效率。
經過預訓練后對網絡進行評估,圖5是分割的結果。從圖中可以看出:該網絡的性能較好,可以實現多種類別的像素級的分割,對目標邊緣細節(jié)信息的分割效果也很好。但同時也會在局部出現一些誤檢和漏檢的情況,造成這些情況的原因是,與目標識別任務比較,圖像分割任務要做到像素級別的分類,本身任務的難度較大,再加上該文使用輕量化的網絡,參數量相對較少,會對特征描述的能力造成一定的影響。

圖5 PASAL VOC2012數據集上的分割效果
實驗過程均在以下的工作條件下完成訓練與測試:IntelCore i5 8300-H CPU,配備8 GB RAM與Win10操作系統(tǒng),NVIDIA GTX1050Ti配備4 G顯存,以及Pytorch深度學習框架,并配置RefineNet的運行環(huán)境,然后將標定完成后的樣本數據集使用輕量化后的RefineNet進行訓練與評估[15]。
3.2 評估參數
分割任務中常用的評價指標是平均交叉聯合度量(mean intersection over union,MIoU,也稱為平均交并比),是各類目標IoU的均值,其中IoU計算方式如式(2)所示:
(2)
其中,TP是被模型預測為正的正模型,FP是被模型預測為正的負樣本,FN是被模型預測為負的正樣本。在圖像分割任務中,更高的MIoU值通常代表著模型對小目標有著更好的檢測分割能力。
3.3 結果分析
使用的數據集是前文所提到的手動標注的草坪場景分割數據集,該數據集包含了2 540張圖片,其中2 300張用來訓練,240張用來測試。從運行時間、參數量、浮點數運算量和算法性能進行對比測試。運行時間通過輸入480×480的圖像測試取得,測試的結果如表2所示。
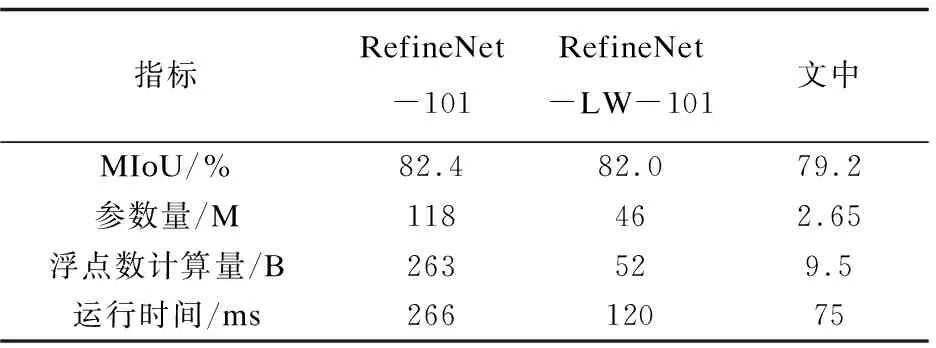
表2 不同方法的結果比較
表2中,RefineNet-101表示的是原始的以ResNet101為編碼網絡的RefineNet,RefineNet-LW-101表示的是僅僅輕量化解碼網絡后的RefineNet,文中網絡是編碼網絡和解碼網絡均輕量化后的網絡。從表中的數據可以看出,文中的網絡具有輕量化、運行速度快、準確率較高的特點。通過對比可以看出,對解碼網絡的輕量化(用1×1的小尺寸卷積代替3×3的卷積并去掉RCU模塊)使得網絡的參數量有大幅度的降低,約61%,并且運行速度也有很大的提升,運行時間少約55%;在解碼網絡輕量化的基礎上,再對編碼網絡輕量化(使用MobileNetV3作為特征提取網絡)又很大地降低了網絡的參數量,約94%,提高了網絡的運行速度,運行時間約少37%,并且保證了較高的準確率。
與采用ResNet101作為編碼模塊的網絡相比,ResNet101得益于更深更寬的網絡結構,作為特征提取模塊時取得了最高的準確率,而文中算法在準確率上有一定的落后,但是整個網絡的參數量僅有ResNet101的3%左右,而且運行時間也不到ResNet101的30%。所以算法結構兼顧了運行效率和準確率,在移動機器人的草坪場景理解任務上有更好的綜合性能。提出的網絡在草坪場景下的分割效果如圖6、圖7所示,其中圖6中的數據是測試集中的結果,而圖7中的數據來源是元數據集中沒有的隨機圖片。由圖7可以看出:設計的網絡具有較好的綜合性能,能夠準確地實現草坪場景下的圖像分割。

圖6 草坪場景數據集上的分割效果

圖7 隨機樣本的分割效果
4 結束語
設計了一種兼顧準確率和運行效率的輕量化神經網絡圖像分割算法,在網絡的編碼階段結合使用了MobileNetV3網絡;在網絡的解碼階段中,通過分析原RefineNet模塊中各部分的功能,通過使用1×1的小尺寸卷積核代替3×3的卷積核,并且去掉RCU單元,大幅度地減少了網絡的參數量,有效地提高了網絡的運行效率。與其他的網絡相比,該方法準確率較高,MIoU指標達到了79.2%,運行速率較快,75ms/幀,綜合性能較好,更適合應用于移動機器人草坪場景理解的任務中。采用圖像分割的方法進行場景理解可以獲得比傳統(tǒng)目標檢測方法更豐富的信息,在草坪場景的任務中,對草坪區(qū)域的識別效果更好,是未來移動機器人視覺感知技術的發(fā)展方向。下一步工作是通過增大訓練樣本數,對不同時期形態(tài)的草坪進行識別,以進一步提高模型的識別度。
