農業用地土壤重金屬樣本點數據精化方法
——以北京市順義區為例
2020-11-11 02:55:20唐柜彪朱慶偉董士偉高秉博潘瑜春王怡蓉郜允兵
農業環境科學學報 2020年10期
唐柜彪,朱慶偉,董士偉,高秉博,潘瑜春,王怡蓉,郜允兵
(1.西安科技大學測繪科學與技術學院,西安710054;2.北京農業信息技術研究中心,北京100097;3.國家農業信息化工程技術研究中心,北京100097;4.中國農業大學土地科學與技術學院,北京100193)
中國工農業的快速發展導致土壤重金屬在污染水平、污染范圍和持續時間方面都呈現出日益嚴重的趨勢。為了應對這種趨勢,國家發布一系列措施,比如,《全國農業可持續發展(2015—2030)》要求圍繞農業污染防治和農村環境治理,開展水土資源保護重大工程建設;《土壤污染防治行動計劃》(土十條)提出開展土壤污染調查,實施農用地分類管理,加強農業污染源監管。面對農業土壤重金屬污染監測調查、分級分類防治、污染監管的新要求,研究農業用地土壤重金屬樣本點的空間分布特征和相應數據去冗精化方法非常關鍵。
土壤采樣是調查土壤屬性空間變異性及其統計參數的重要方式[1-3],精確研究土壤空間信息分布和變異性必須以土壤采樣點在空間均勻性及代表性為依托。因此,用樣本點數據分析前必須先對樣本集中樣本點進行均勻性檢測和冗余數據處理,空間樣本點數據的均勻分布及代表性不僅是檢測評價的關鍵因素,也是判斷分析結果是否準確的重要依據。針對空間樣本點數據的均勻性及代表性問題,國內外學者開展了大量的研究,許多學者采用隨機選擇樣本點研究土壤重金屬污染及評價[4]和預測土壤重金屬空間信息變化[5-8],在一定程度上提高了土壤空間信息分布的預測結果精度,但未充分考慮樣本點在地理空間均勻性和特征空間代表性,忽略了土壤空間信息相關性。 基于格網采樣方式進行土壤重金屬污染評價[9-11],考慮了樣本點在地理空間的均勻性,但忽視其在特征空間的代表性。同時,有研究基于歷史采樣點預測土壤有機質含量[12-13],基于插值方法驗證樣本點在特征空間代表性,但沒有耦合樣本點地理空間均勻性。除此之外,還有其他不少學者也從不同的角度分析,分別對不同的采樣數量和布局研究樣本點在土壤空間的均勻性及代表性問題[14-20]。總體分析對于空間樣本點數據在地理空間分布不均和特征空間的代表性問題,更多是將地理空間樣本點的均勻性和特征空間的代表性剝離計算,未耦合兩者對空間數據精化提供具體方法及理論支撐。
綜合分析國內外相關研究后發現主要存在兩大問題:一是沒有進行樣本點的均勻性檢測及非均勻樣本點的去冗精化。這種數據處理模式可能會出現樣本點代表性差的情景,增加采樣點數據分析過程中的不確定性,進而影響采樣點數據分析結果的精度和準確度;二是構建的樣本點分布均勻性檢測指標體系比較單一、缺乏系統性,致使檢測結果容易出現偏差,也無法體現采樣點數據局部均勻細節,不利于采樣點數據的去冗精化和挖掘分析。具體在重金屬樣本點方面,以隨機布點法、格網布點法和分區布點法為主的重金屬樣本點布設結果也存在上述兩大問題,尤其缺乏重金屬樣本點分布非均勻時的數據精化處理方法。基于此,本文提供一種農業用地土壤重金屬樣本點數據精化方法,構建區域農業重金屬樣本點分布均勻性檢測指標體系進行均勻性檢測,并綜合集成樣本點分布非均勻化去冗精化方法。該方法可以為區域樣本點數據質量評價和數據去冗精化提供一種新的技術方法,可直接服務于土壤污染防治行動計劃(土十條)、土壤污染狀況詳查等,對提升農業環境監測體系和監管信息化水平具有指導作用。
1 材料與方法
1.1 研究區概況及數據來源
順義區位于北京市城區東北方向,城區距市區中心30 km,順義區地勢北高南低,地理位置40°00′ ~40°18′ N,116°28′ ~116°58′ E,境域東西長45 km,南北寬30 km,總面積1 021 km2。土壤為河流洪水攜帶沉積物質造成,表面堆積物主要是砂、亞砂土,北部山地最高點海拔為637 m,境內最低點海拔為24 m。本文研究該區域內的4 個鄉鎮,分別是高麗營鎮、趙全營鎮、牛欄山地區和北石槽鎮,農業用地面積為114.379 km2,農業用地主要是菜地、水澆地、苗圃等。
土壤重金屬樣本點數據來源于北京市農林科學院農產品質量安全管理平臺。為了分析北京市農田環境和農產品質量情況,北京市農林科學院定期組織下屬單位開展北京市土壤樣品采集。本研究數據采集于2009 年春季,樣本點的布局和數量根據田塊的利用方式和面積進行確定,采用GPS定位記錄樣點中心位置,采樣點主要分布于糧田、菜地、果園等農業用地。原始采樣中,每個樣本點在10 m×10 m 格網范圍內選擇5 個0~20 cm 耕層土壤混合,按四分法選取分析樣品1.0 kg。所有土樣在室內自然風干,碾壓磨碎后,過100 目尼龍網篩,按照國家標準分析測定各重金屬元素(Cu、Zn、Pb、Cd、As、Hg)。土壤樣品測定采用20% 樣品平行樣,并加入國家標準土壤樣品(GSS-1和GSS-4)作為質量控制樣品,質控樣品相對誤差小于10%。本研究區域內農業用地共分布95 個樣本點(圖1),選擇以重金屬Cu為例進行數據精化研究。
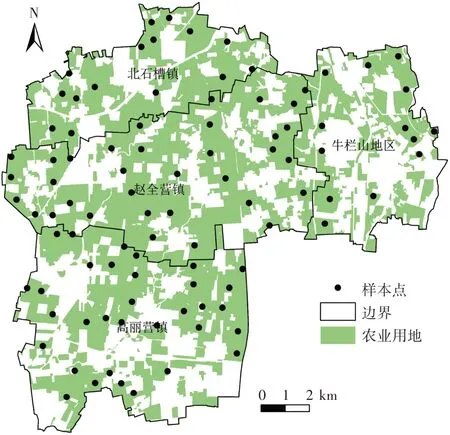
圖1 研究區域Figure 1 Study area
1.2 研究方法
空間樣本點數據精化主要通過對樣本點的均勻性檢測,找出其中存在的冗余數據,將其劃分為聚集樣本點和稀疏樣本點。針對不同類型的樣本點數據進行處理,從而改善其在地理空間分布均勻性以及特征空間的代表性,最終實現空間數據精化目的。
農業用地土壤重金屬樣本點數據精化方法主要包括3 個部分:一是樣本點數據均勻性表征方法;二是樣本點數據去冗精化方法;三是樣本點數據去冗精化效果評價方法。
1.2.1 樣本點數據均勻性表征方法
根據樣本點在空間分布方式的不同,樣本點的均勻性表征方法一般分為:地理空間樣本點均勻性表征方法,特征空間樣本點均勻性表征方法,耦合地理空間和特征空間樣本點均勻性表征方法。地理空間數據的均勻性一般主要考慮地理空間采樣位置均勻而忽視其在特征空間中屬性分布的代表性,比較常用的方法為基于格網采樣法[21]、電荷排斥模擬法[22]、空間模擬退火算法[23]等;特征空間樣本點均勻性表征方法一般主要考慮特征空間屬性分布均勻而忽視樣本點在地理空間位置的均勻性,比較常用的是目的性選擇的方法[4]。針對空間樣本點的均勻性和代表性問題,全局代表性高的樣本點不但在數值空間內很好地囊括了目標區域土壤特性的典型值,而且在地理空間和特征空間也可以極大限度地反映土壤屬性的空間變異[24]。因此耦合地理空間和特征空間樣本點均勻性表征方法是理想選擇,盡管許多學者耦合兩個空間的采樣布設嘗試,比如超拉丁立方體采樣方法[25],但該方法很難操作。考慮樣本點在地理空間的均勻性,又結合樣本點在特征空間分布的代表性,現階段很難找到統一的指標來衡量地理空間的均勻性和特征空間的代表性問題,而且還考慮各方面環境因素,又因為樣本點在地理空間的均勻性和特征空間分布的代表性可能存在一定的矛盾,所以現階段要實現該表征方法異常困難。
本文研究土壤重金屬樣本點數據均勻性檢測和去冗精化局限在地理空間,但樣本點數據去冗精化效果從地理空間和特征空間分別構建指標進行共同評價。地理空間樣本點均勻性表征方法主要涉及兩個重要指標:一是樣本點的均勻因子,二是樣本集的均勻變異指數;通過繪制均勻因子離散圖,檢測其存在的冗余數據。
(1)樣本點均勻因子
均勻因子表示樣本點所在研究區域生成的泰森多邊形面積與平均采樣面積的比值,計算公式見式(1)。

式中:S0為平均采樣面積,km2;Si為第i 個樣本點所在泰森多邊形面積,km2;Vi為第i個樣本點的均勻因子。均勻因子表示單個樣本點的均勻因子與標準值1 的局部偏離程度,偏離程度越小表示樣本點所在區域存在冗余采樣點數量越少。當均勻因子大于1 時,表明樣本點在所在區域比較稀疏,即稀疏樣本點;當均勻因子等于1 時,不需改善樣本點在地理空間數據的均勻性,即均勻樣本點;當均勻因子小于1 時,表示在該區域采集的樣本點處于聚集分布,即聚集樣本點。
(2)均勻變異指數
均勻變異指數表征樣本集中全部樣本點的整體均勻程度,可由公式(2)表達:
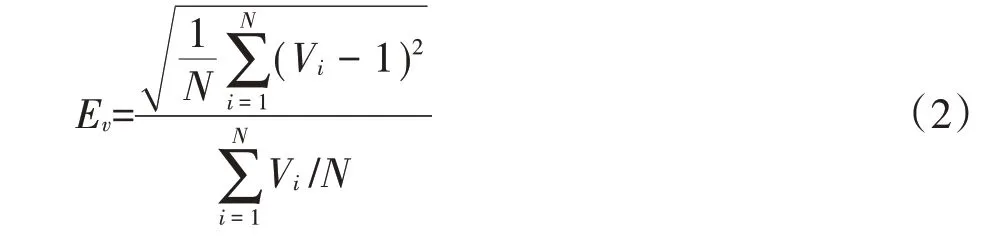
式中:Ev為所有樣本點的均勻變異指數;N 為采樣區域中的樣本點的個數;Vi為第i個樣本點的均勻因子。均勻變異指數越小,表示樣本點在地理空間的分布越均勻。反之,樣本點分布越趨向于聚集和稀疏。
1.2.2 樣本點去冗精化方法
樣本點數據去冗精化方法分為三種不同類型的場景:均勻樣本點去冗精化、聚集樣本點去冗精化和稀疏樣本點去冗精化。
(1)均勻樣本點去冗精化
計算樣本點的均勻因子,當均勻因子都等于1時,即采集的樣本點在空間分布均勻,表示樣本集中沒有冗余數據,無需進行樣本點冗余數據分析與處理。
(2)聚集樣本點去冗精化
計算樣本點的均勻因子,當樣本點均勻因子小于1 時,表示樣本點局部聚集。一般設置小于1 的閾值或根據跳躍性來判斷,當離散圖中均勻因子小于閾值時或產生跳躍,就判斷該樣本點在樣本集中為聚集樣本點,處理方法為刪除該樣本點或樣本點權重調整。然而,刪除地理空間的聚集樣本點時,還應該兼顧特征空間的特征點情景:①有先驗知識或人為設置特征點情景,若聚集樣本點不是特征空間的特征點,則刪除該樣本點;反之,則不能刪除,可以采用樣本點權重調整方法,減少該樣本點的權重值;②沒有先驗知識或人為設置特征點情景,為防止誤刪特征點,在特征空間中引入局部Moran′s I 系數[26]將土壤重金屬含量的空間格局可視化,進一步研究其空間分布規律。Moran′s I 散點圖可以描述局部空間自相關性,將土壤重金屬含量空間分布劃分為5 種類型:高值聚集(HH)、高值被低值包圍(HL)、低值被高值包圍(LH)、低值聚集(LL)和不顯著。當聚集樣本點屬于高值被低值包圍(HL)或低值被高值包圍(LH)時,表示該聚集樣本點在特征空間的空間差異程度顯著較大,可以剔除;若聚集樣本點不屬于HL 或LH,則需要根據其他輔助數據和信息進行判斷。
(3)稀疏樣本點去冗精化
計算樣本點的均勻因子,當樣本點的均勻因子大于1 時,應該根據均勻因子離散圖設置一個大于1 的閾值或根據其跳躍性來判斷。當超出閾值或產生跳躍時,即可判斷對應的樣本點在樣本集中屬于稀疏樣本點。針對稀疏樣本點數據處理有兩種方法:樣本點權重值調整方法和樣本點添加方法。
樣本點權重調整方法不需添加和刪除樣本點,只需對樣本點的權重進行調整。樣本點比較稀疏的區域,根據樣本點影響的范圍增加其權重值,樣本點比較聚集的區域,減少其權重值。例如,可以選擇樣本點所在區域泰森多邊形面積與該區域所有參與調整的樣點泰森多邊形面積總和的比值作為樣本點調整權重。
樣本點添加方法可分為3 種模式,一是基于歷史樣本點添加方法,該方法對時間要求比較苛刻,目標樣本點附近的歷史樣本點需要在一定時間間隔內采集,比如規定時間間隔為一年。否則,時間間隔太長,樣本點的屬性特征值會隨之發生改變。二是現場補測方法,該方法適用于樣本點近期采集作業,根據樣本點數據處理結果或研究目的進行野外現場補測,時間間隔要求比歷史樣本點添加方法更短。三是基于樣本點模型優化方法,耦合樣本點地理空間分布和特征屬性嘗試建立添加樣本點目標函數和優化方法,確定添加樣本點的最佳位置。
上述不同方法具有各自的優缺點,適用不同的應用場景。而稀疏區域添加樣本點數量確定方法,根據樣本點在區域內生成的泰森多邊形面積與平均采樣面積比較確定添加樣本點的個數,如公式(3)。

式中:S0為平均采樣面積,km2;Si為第i 個樣本點所在泰森多邊形面積,km2;Ni四舍五入取整即為增加的樣本點數。
1.2.3 樣本點數據去冗精化效果評價
樣本點數據去冗精化效果評價方法從地理空間和特征空間構建指標共同評價。以空間數據為研究對象對其均勻性檢測,對存在的冗余數據處理結果進行評價,其中包含均勻變異指數、均勻變異指數變化率、特征空間偏離指數和屬性值的插值誤差。以原始樣本點計算結果為參考標準,驗證處理后的樣本點在地理空間的均勻性和特征空間的代表性。綜合分析數據處理之后的均勻因子、均勻變異指數、偏離指數和空間插值誤差,比較土壤樣本點數據精化的結果對樣本點的均勻性及代表性的改善程度進行綜合評價。
(1)地理空間評價指標:均勻變異指數變化率
通過樣本點的均勻因子計算其均勻變異指數,均勻變異指數越小,表示樣本點在地理空間的分布越均勻。均勻變異指數變化率計算公式見式(4)。

式中:V為均勻變異指數變化率;Ev為原始樣本集的均勻變異指數;Ev′為新樣本集的均勻變異指數。刪除聚集樣本點和加密稀疏樣本點后,均勻變異指數變化率越大,表示樣本點數據精化效果越好。反之,表示去冗精化效果不佳。
(2)特征空間評價指標:偏離指數
P-P 圖(Probability-probability plot)和Q-Q 圖(Quantile-quantile plot)通過繪制樣本點及相應總體的概率/分位數散點圖來比較樣本點及其總體的特征分布。為了量化樣本的代表性,反映樣本點在特征空間的偏離程度,定義特征空間偏離指數(Deviation index,DI)為以P-P 圖或Q-Q 圖中y=x線為基準的標準殘差[27],計算公式見式(5)。

式中:DI是偏離指數;qi是第i個樣本點屬性值的分位數/概率;Qi是相應的總體分位數/概率;N是樣本點個數。偏離指數越小,表征樣本點在特征空間中的分布代表性越好。
(3)插值誤差
樣本點數據主要用途之一是空間制圖,基于農業土壤重金屬屬性空間插值誤差大小來定量表征去冗精化對樣本點數據空間制圖的影響。選擇常用的均方根誤差(Root Mean Square Error,RMSE),計算公式為:

式中:RMSE是均方根誤差;Pi是第i個樣本點的預測值,mg·kg-1;Oi是第i個樣本點的觀測值,mg·kg-1;N是樣本點個數。空間插值方法主要推薦克里格插值,它是以變異函數理論和結構分析為基礎,利用區域化變量的原始數據和變異函數的結構特點,對未知樣本點進行線性無偏、最優估計。首先對原始樣本集屬性空間插值計算插值誤差;其次數據去冗精化后,計算去冗精化樣本集的空間插值誤差,并與原始樣本集的空間插值誤差比較。當計算出的樣本點數據屬性值的插值誤差大于原始樣本集屬性值的插值誤差,說明樣本點的代表性更差;等于原始樣本集屬性值插值誤差,則樣本集數據精化對樣本點的均勻性沒有影響;小于原始樣本集屬性值的插值誤差,說明樣本集中的樣本點在土壤特征空間信息更具代表性;插值誤差越小表示樣本點的代表性越好。反之,代表性越差。
2 結果與分析
2.1 樣本點數據處理結果及分析
計算原始樣本集樣本點的均勻因子并繪制均勻因子離散圖(圖2),圖中均勻因子是按照從小到大的順序排列,計算樣本點的均勻變異指數為0.429。基于ArcGIS 10.1 軟件平臺,以樣本集中重金屬Cu 為目標變量,利用地統計中探索性數據分析工具Normal QQPlot和普通克里格插值方法,分別計算樣本點屬性Cu 的特征空間偏離指數為0.327 和插值誤差為6.538。通過結果分析,當均勻因子為0.349,即最低點,與下一點均勻因子相比發生很大的跳躍,所以判斷該均勻因子對應的樣本點為聚集樣本點。當均勻因子為2.744,即最高點,與上一點均勻因子相比也發生很大跳躍,所以判斷該均勻因子對應的樣本點為稀疏樣本點。
2.2 樣本點精化區域劃定
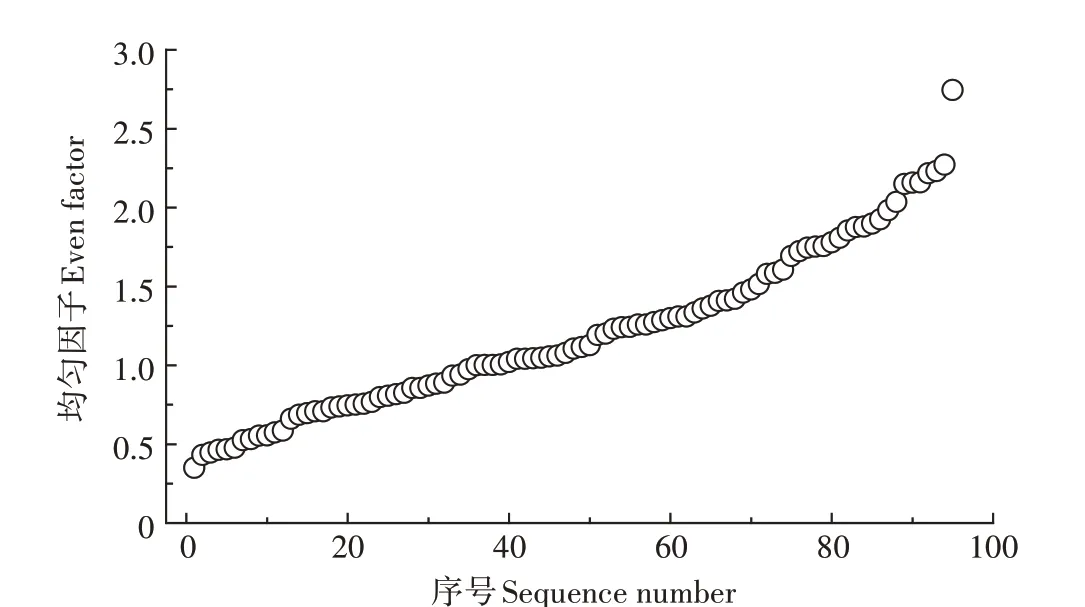
圖2 均勻因子離散圖Figure 2 Discrete graph of even factor
根據數據處理結果及分析可知,樣本集中存在1個聚集樣本點和1 個稀疏樣本點。針對地理空間的聚集樣本點,研究區內沒有先驗知識或人為設置特征點,為防止誤刪特征點,基于ArcGIS 10.1 軟件的Spatial Autocorrelation工具計算原始樣本集的Moran′sI系數,參數設置反距離進行空間關系的概念化,并繪制Moran′ sI散點圖如圖(3)所示,一個聚集樣本點(圖4)在特征空間屬于低值被高值包圍(LH),對該樣本點進行刪除。針對稀疏樣本點,需要在稀疏樣本點影響范圍內加密樣本點。通過計算添加樣本點數量的結果可知,稀疏區域需要增加1個樣本點。
本研究采用數據其樣本采樣時間為2009 年,無法選取現場補測方法,而研究區存在2008 年歷史樣本點數據,因此本研究采用基于歷史樣本點數據添加方法。在稀疏區域內共有3個2008年歷史樣本點(圖4),分別記為1、2、3 號,數據精化前已消除由于時間不一致帶來的系統誤差。
2.3 數據去冗精化結果及分析
通過對原始樣本點的均勻性檢測結果,剔除聚集樣本點和添加不同歷史樣本點共分為3 種不同方案:a 方案具體內容為刪除1 個聚集點,添加1 號樣本點;b 方案具體內容為刪除1 個聚集點,添加2 號樣本點;c 方案具體內容為刪除1 個聚集點,添加3 號樣本點。不同處理方案的均勻因子離散圖和均勻變異指數計算結果分別如圖5 和表1 所示。結果表明,均勻變異指數下降明顯,說明剔除聚集樣本點和添加歷史樣本點能有效去除原始樣本集中的冗余數據。
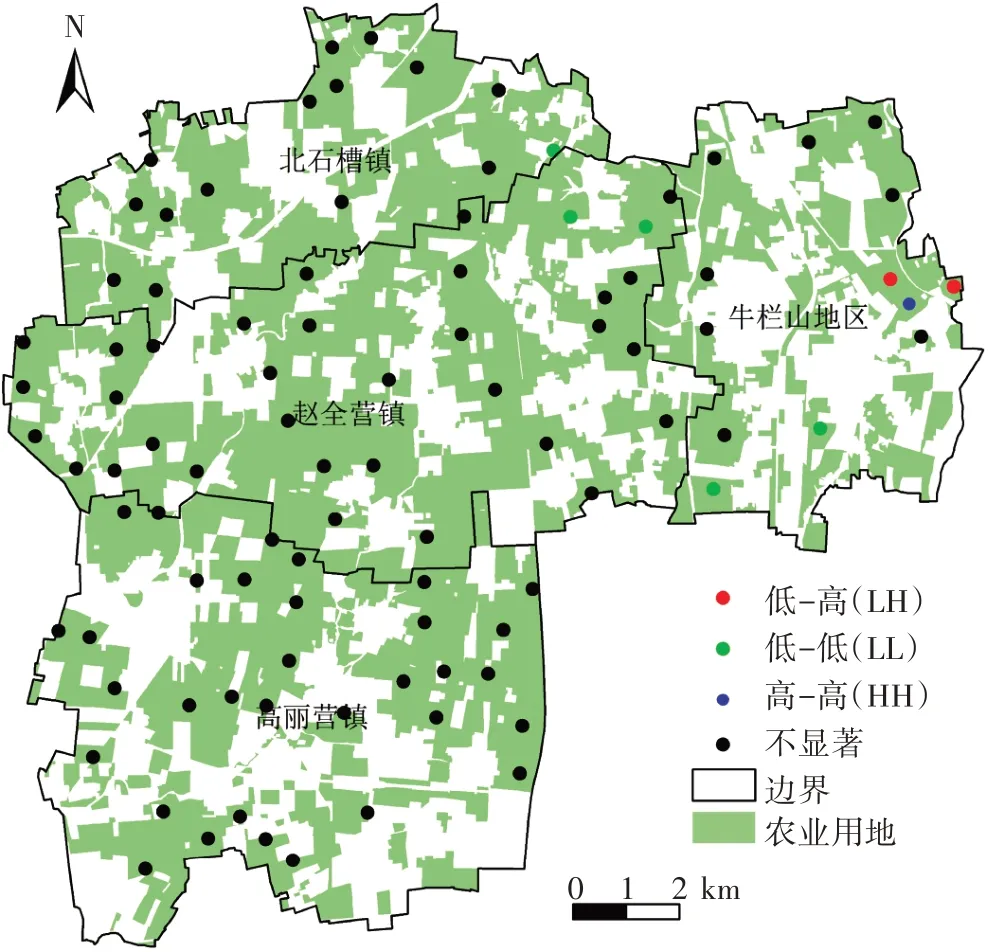
圖3 樣本點的Moran′s I散點圖Figure 3 Moran′s I scatter diagram of sampling sites
計算添加不同位置樣本點處理結果,a 方案均勻變異指數由0.429下降到0.416,樣本點均勻性整體得到改善,但該方案最小泰森多邊形面積由0.349 km2下降到0.330 km2,重新生成1個聚集樣本點(圖5a);b方案和c 方案與原始方案相比,都降低了樣本點所在泰森多邊形的最大面積,增大了最小面積,去冗精化后沒有發現聚集樣本點和稀疏樣本點,改善了樣本點整體均勻性。由于b 方案的均勻變異指數0.406 小于c方案的0.412,即不同方案樣本點的均勻變異指數大小為:原始樣本點>a 方案>c 方案>b 方案。故b 方案是研究區去冗精化的最優方案,即刪除1 個聚集樣本點和添加2號歷史樣本點。
2.4 樣本點數據精化評價
本文中聚集和稀疏樣本點為數據集中均勻因子離散圖兩端的極值,根據地理空間均勻變異指數變化率、特征空間偏離指數和屬性插值誤差來共同評價樣本點數據去冗精化效果。通過計算原始樣本點均勻變異指數為0.429。刪除聚集樣本點和稀疏樣本點添加歷史樣本點數據之后均勻性檢測的效果進行分析比較,結果如表2所示,a均勻變化率最小,則a方案樣本點在地理空間均勻性改善效果最差。針對b 方案和c 方案比較分析,根據圖5 可知,添加2 號和3 號歷史樣本點未重新造成樣本點冗余等情況。根據表2可知,不同方案樣本點的均勻變異指數變化率比較:b方案>c 方案>a 方案。表明b 方案在地理空間的均勻性最好,故添加2 號歷史樣本點改善樣本點的均勻性效果最佳。結果表明本研究數據精化方案在地理空間有效。
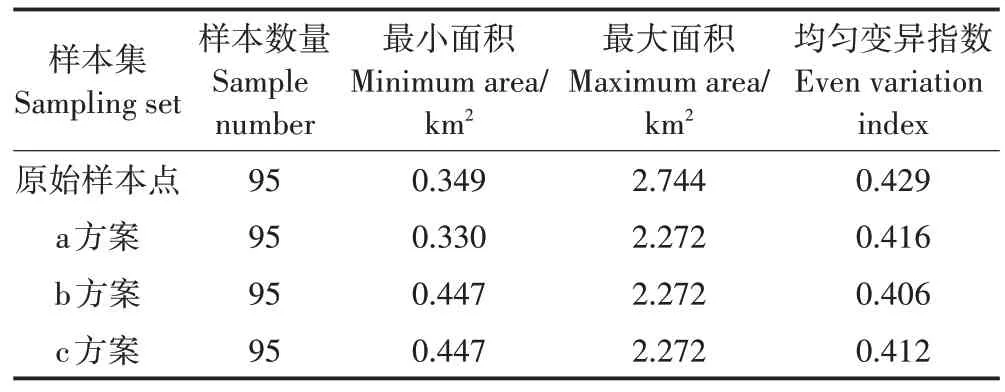
表1 不同數據精化方案Table 1 Different data refinement schemes
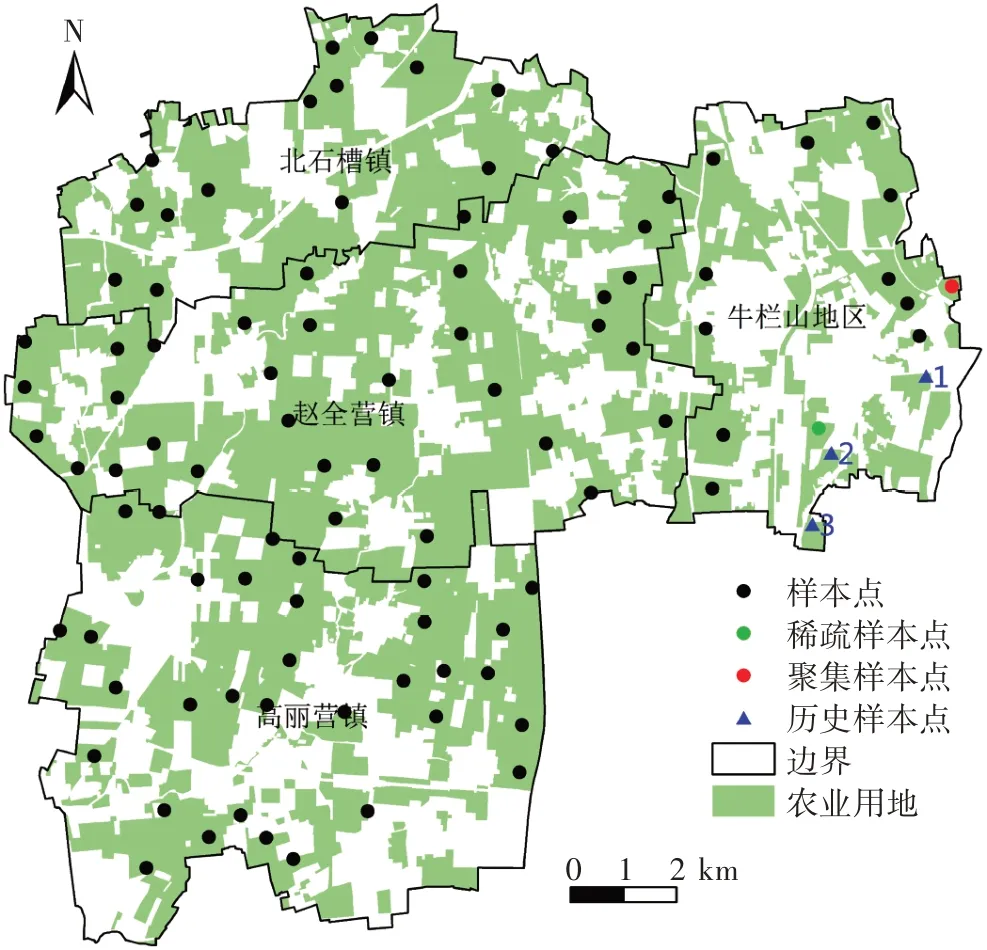
圖4 不同類型樣本點Figure 4 Different types of sampling sites

圖5 不同數據精化方案的離散圖Figure 5 Discrete graphs of different data refinement schemes

表2 均勻變異指數變化率Table 2 Change rate of even variation index
原始樣本點與不同數據精化方案中,以土壤重金屬Cu 元素為目標變量,用Normal QQPlot 分析工具分別計算該屬性的特征空間偏離指數,如表3 所示,不同方案的偏離指數大小為:原始樣本點>c 方案>a 方案>b 方案,表明經過冗余數據處理之后,各方案樣本點的屬性值特征空間偏離指數都在微弱減小,各方案都在一定程度上提高了樣本點在特征空間的代表性。其中b 方案偏離指數最小,表明在特征空間中的代表性最好。
用普通克里格空間插值方法分別計算Cu元素的插值誤差,結果如表3 所示,不同方案的插值誤差大小為:原始樣本點>a方案>c方案>b方案,表明經過冗余數據處理之后,各方案樣本點屬性值的插值誤差都在明顯減小,表明各方案都在一定程度上提高了樣本點的代表性,其中b 方案的效果最佳,與地理空間和特征空間評價結果一致。
綜上所述,通過不同方案比較,b 方案數據精化效果最好,提高了地理空間樣本點的均勻性和特征空間的代表性。
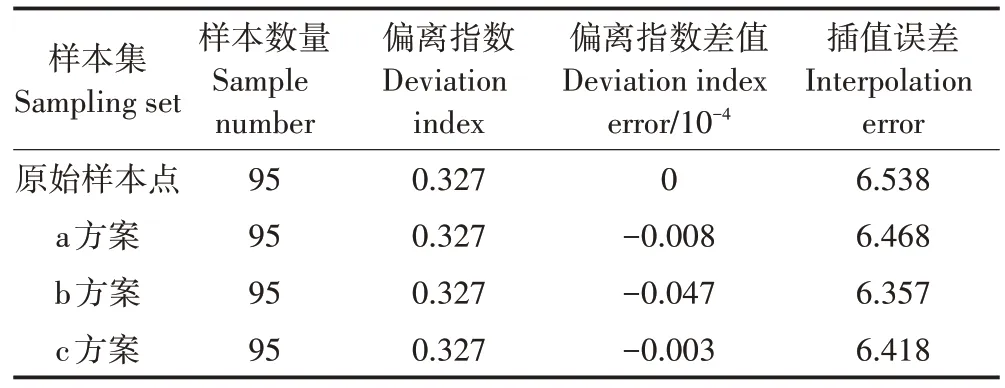
表3 Cu特征空間偏離指數和插值誤差Table 3 The feature space deviation index and interpolation error of Cu
3 討論
3.1 樣本點數據精化方法與相關研究的對比分析
對比分析本研究樣本點數據精化方法與相關研究成果,可以歸納為3 種類型:(1)樣本點數據沒有進行均勻性檢測或進行了均勻性檢測但沒有進行相應的數據精化處理,例如,韓宗偉等[13]不同采樣尺度的土壤有機質數據分析;(2)非均勻化樣本點數據進行了簡單數據精化處理,但沒有系統評價數據精化效果,例如,吳丹等[28]對農用機井的加密優化;(3)系統構建樣本點分布均勻性檢測指標體系進行均勻性檢測,并綜合集成樣本點分布非均勻化去冗精化方法,例如,本研究土壤重金屬樣本點的數據精化。
3.2 樣本點數據精化方法的不確定性分析
研發的樣本點數據精化方法提高了樣本點的均勻性和代表性,但研究過程中存在一定的不確定性。(1)地理空間極大值點(稀疏樣本點)和極小值點(聚集樣本點)不同于特征空間的特征點,二者之間沒有明顯的對應關系。由于缺乏數據進行真實性檢驗,本研究可以基于局部Moran′s I 系數進行判斷,但對于其他應用場景,則需要根據其他輔助數據和信息進行判斷;(2)添加歷史采集的樣本點方法存在局限性,在稀疏區域添加樣本點的空間位置只是較優位置,并不一定是最佳位置,該目標函數和優化方法是個研究難點,正在考慮結合深度學習算法來進一步嘗試;(3)本研究的數據精化處理過程中,聚集樣本點數量和稀疏樣本點數量恰好相等,使得不同數據精化方案和原始樣本集中樣本點總數相等。針對其他樣本集,若出現數量不相等的情景,如何設置閾值準確判斷和優化聚集樣本點和稀疏樣本點非常關鍵。此外,隨著樣本數、間距和分布格局不同,變異函數的理論模型可能會發生變化,影響去冗精化效果評估。
針對精化方法目前存在的不確定性,未來將進一步研究耦合地理空間和特征空間樣本點去冗精化方法、不同樣本點數量下的數據精化方案、樣本點權重調整方法、樣本點優化模型布設最佳加密點、目標變量空間非平穩情況下的去冗精化方法等。
3.3 樣本點數據精化方法的應用推廣
研發的農業用地土壤重金屬樣本點數據精化方法,以其兼顧樣本點地理空間均勻性和特征空間代表性的優勢,可以應用在面源與重金屬污染、場地污染監測、耕地質量評價、氣象和環境評估、海洋環境預警等樣本點、監測點或監測站的優化布局,減少數據冗余,提高點位的代表性,具有很好的應用前景。
4 結論
(1)根據不同類型樣本點去冗精化的結果評價,顯示b 方案(刪除1 個聚集點,添加2 號歷史樣本點)的均勻變異指數變化率最大,特征空間偏離指數和插值誤差最小,提高了地理空間樣本點的均勻性和特征空間的代表性,數據精化效果最佳。
(2)本研究數據精化方法在一定程度上可以兼顧樣本點地理空間的均勻性及特征空間代表性,不僅為大數據去冗精化提供一種參考方法,而且可以用于樣本點布設方案設計,在土壤污染防治行動計劃(土十條)、土壤污染狀況詳查以及其他行業的點位優化布局中具有很好的應用潛力。
(3)在數據特征點判斷、去冗精化方法選擇和閾值設置方面存在一定的不確定性,未來將進一步研究不同適用條件下耦合地理空間和特征空間的樣本點去冗精化方法。
猜你喜歡
數學小靈通·3-4年級(2024年2期)2024-05-15 02:02:28
世界科學技術-中醫藥現代化(2020年2期)2020-07-25 02:05:36
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當代陜西(2019年10期)2019-06-03 10:12:04
兒童故事畫報(2019年5期)2019-05-26 14:26:14
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
Coco薇(2016年2期)2016-03-22 02:42:52
Coco薇(2015年1期)2015-08-13 02:47:34
小雪花·成長指南(2015年7期)2015-08-11 15:03:12
小雪花·成長指南(2015年4期)2015-05-19 14:47:56
