基于Tree LSTM+CRF的屬性級(jí)觀點(diǎn)挖掘
2020-11-12 01:35:24
(山東科技大學(xué) 計(jì)算機(jī)科學(xué)與工程學(xué)院,山東 青島 266590)
隨著互聯(lián)網(wǎng)的發(fā)展,互聯(lián)網(wǎng)上的評(píng)論信息越來(lái)越多,屬性級(jí)觀點(diǎn)挖掘因能夠挖掘出評(píng)論中包含的各個(gè)評(píng)價(jià)對(duì)象及觀點(diǎn)內(nèi)容、提取評(píng)論句中有價(jià)值的信息、快速準(zhǔn)確地得出用戶(hù)的關(guān)注點(diǎn)而備受關(guān)注。觀點(diǎn)由屬性(aspect)、觀點(diǎn)內(nèi)容(opinion)、持有者(holder)及情感(sentiment)組成,評(píng)價(jià)對(duì)象(aspect terms)是出現(xiàn)在評(píng)論句中涉及屬性的單詞或詞組。例如:在評(píng)論句“The service of the restaurant is good,but the food tastes general.”中,service和food是具體的評(píng)價(jià)對(duì)象,good和tastes general是其對(duì)應(yīng)的觀點(diǎn)內(nèi)容。本研究的目的是抽取評(píng)論中包含的評(píng)價(jià)對(duì)象和觀點(diǎn)內(nèi)容。
屬性級(jí)觀點(diǎn)挖掘最早由Hu等[1-2]提出,而后引起了諸多研究者的關(guān)注。目前,常用的屬性級(jí)觀點(diǎn)挖掘方法可以分為無(wú)監(jiān)督學(xué)習(xí)方法和有監(jiān)督學(xué)習(xí)方法。無(wú)監(jiān)督學(xué)習(xí)方法中,Hu等[1]對(duì)數(shù)據(jù)詞性標(biāo)注后以Apriori算法進(jìn)行關(guān)聯(lián)規(guī)則挖掘找到頻繁名詞及名詞短語(yǔ),然后對(duì)錯(cuò)誤詞語(yǔ)進(jìn)行剪枝后得到要抽取的評(píng)價(jià)對(duì)象。Popescu等[3]在文獻(xiàn)[1]的基礎(chǔ)上,將PMI(point-wise mutual information)加入剪枝策略中,計(jì)算頻繁項(xiàng)與預(yù)定義的判別短語(yǔ)的PMI值,確定是否為要抽取的評(píng)價(jià)對(duì)象。劉鴻宇等[4]根據(jù)依存句法模板和規(guī)則抽取頻繁項(xiàng),通過(guò)剪枝處理得到要抽取的評(píng)價(jià)對(duì)象。江騰蛟等[5]提出了基于淺層語(yǔ)義與語(yǔ)法分析相結(jié)合的評(píng)價(jià)搭配抽取方法。廖祥文等[6]利用詞對(duì)齊模型抽取候選評(píng)價(jià)對(duì)象與評(píng)價(jià)搭配組合,建立多層情感關(guān)系圖,利用隨機(jī)游走方法計(jì)算置信度,最后選取置信度高的候選評(píng)價(jià)對(duì)象與觀點(diǎn)內(nèi)容作為輸出。這些無(wú)監(jiān)督方法相對(duì)來(lái)說(shuō)可操作性強(qiáng),無(wú)需大量標(biāo)注數(shù)據(jù),但人工干預(yù)過(guò)多,需要提前建立模板,適用于目標(biāo)領(lǐng)域較小的數(shù)據(jù)集。有監(jiān)督學(xué)習(xí)方法中,常采用PLSA(probabilistic latent semantic analysis)和LDA(latent dirichlet allocation)等主題模型;而另外一些研究者將該任務(wù)看作是文本序列標(biāo)注問(wèn)題,采用隱馬爾可夫模型(hidden Markov model,HMM)和條件隨機(jī)場(chǎng)(conditional random fields,CRF)等方法。Wei等[7]先建立詞集對(duì)評(píng)論文本進(jìn)行標(biāo)注,再使用HMM進(jìn)行訓(xùn)練,抽取評(píng)價(jià)對(duì)象和觀點(diǎn)內(nèi)容并判斷極性。劉全超等[8]利用CRF,選擇句法特征、語(yǔ)法特征、語(yǔ)義特征及相對(duì)位置特證,抽取評(píng)價(jià)對(duì)象與觀點(diǎn)內(nèi)容的搭配。丁晟春等[9]采用CRF選取詞、詞性、情感詞以及本體四個(gè)特征抽取評(píng)價(jià)對(duì)象。這類(lèi)有監(jiān)督的方法準(zhǔn)確率較高,但由于需要大量人為設(shè)計(jì)特征,所以領(lǐng)域局限性強(qiáng)。
最近的研究中,研究者們開(kāi)始嘗試基于深度學(xué)習(xí)方法的屬性級(jí)觀點(diǎn)抽取方法。Irsoy等[10]使用深層雙向循環(huán)神經(jīng)網(wǎng)絡(luò)抽取觀點(diǎn)內(nèi)容。Liu等[11]提出使用循環(huán)神經(jīng)網(wǎng)絡(luò)(recurrent neural network,RNN)結(jié)合詞向量的方式抽取評(píng)價(jià)對(duì)象和觀點(diǎn)內(nèi)容。Yin等[12]提出一種無(wú)監(jiān)督的方法,利用循環(huán)神經(jīng)網(wǎng)絡(luò)學(xué)習(xí)融合依存路徑信息的詞向量,然后用詞向量作為CRF的特征來(lái)抽取評(píng)價(jià)對(duì)象。Wang等[13]提出基于注意力的LSTM模型進(jìn)行屬性級(jí)的情感分類(lèi)。Giannkopoulos等[14]提出B-LSTM(bidirectional long short-term memory),結(jié)合CRF的分類(lèi)器從有監(jiān)督和無(wú)監(jiān)督兩類(lèi)研究方向抽取評(píng)價(jià)對(duì)象信息。Wang等[15]提出一種名為RNCRF(recursive neural conditional random fields)的聯(lián)合模型抽取評(píng)價(jià)對(duì)象和觀點(diǎn)內(nèi)容,首先根據(jù)句子的依存句法關(guān)系構(gòu)建依存樹(shù)遞歸神經(jīng)網(wǎng)絡(luò),將評(píng)價(jià)對(duì)象與觀點(diǎn)內(nèi)容的信息編碼到遞歸神經(jīng)網(wǎng)絡(luò)(recursive neural network,RNN)中學(xué)習(xí)更高級(jí)的隱層表示,然后將結(jié)果輸入CRF進(jìn)行序列標(biāo)注。
本研究提出一個(gè)樹(shù)結(jié)構(gòu)長(zhǎng)短期記憶網(wǎng)絡(luò)(tree-structured long short-term memory networks,Tree LSTM),結(jié)合條件隨機(jī)場(chǎng)的聯(lián)合模型來(lái)抽取評(píng)價(jià)對(duì)象和觀點(diǎn)內(nèi)容,在很好地表征詞語(yǔ)之間的層次關(guān)系的同時(shí),有效避免傳統(tǒng)CRF需要大量人工定義特征并且編寫(xiě)特征模板的弊端。
1 Tree LSTM+CRF
以評(píng)論“iPhone is pretty good.”為例,本研究提出的聯(lián)合模型如圖1所示。模型共分為三層,底層是各詞的詞向量,中間層是Tree LSTM模塊,頂層是CRF模塊。

圖1 Tree LSTM+CRF聯(lián)合模型結(jié)構(gòu)Fig.1 Tree LSTM+CRF joint model structure
1.1 Tree LSTM
為了更好地理解本文模型,首先給出Tree LSTM中包含的各個(gè)參數(shù)含義(表1)。其中v為詞典大小,包含所有在評(píng)論語(yǔ)句中出現(xiàn)的詞,d為詞向量維度。

表1 Tree LSTM各參數(shù)代表內(nèi)容 Tab.1 Tree LSTM parameters representing content
構(gòu)建Tree LSTM的過(guò)程:
1) 對(duì)所有評(píng)論語(yǔ)句進(jìn)行依存句法分析,得到每個(gè)句子的依存分析樹(shù)。
2) 按依存分析樹(shù)的結(jié)構(gòu),以LSTM單元為節(jié)點(diǎn)為每個(gè)句子生成Tree LSTM模塊。
圖2為根據(jù)依存句法分析得到的例句的依存分析樹(shù)和Tree LSTM。下面將基于依存句法關(guān)系,由葉子節(jié)點(diǎn)到內(nèi)部節(jié)點(diǎn)逐個(gè)計(jì)算各節(jié)點(diǎn)的隱向量。以圖2(b)為例,首先計(jì)算葉子節(jié)點(diǎn)單詞“iPhone”的隱向量值:
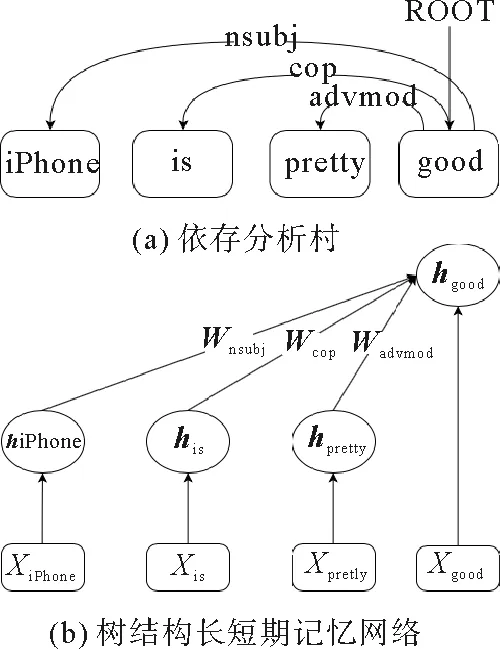
圖2 例句的依存分析樹(shù)及其生成的Tree LSTMFig.2 Dependent analysis tree for example sentences and its generated Tree LSTM
iiPhone=sigmoid(Wi·xiPhone+bi),
(1)
uiPhone=tanh (Wu·xiPhone+bu),
(2)
ciPhone=iiPhone⊙uiPhone,
(3)
oiPhone=sigmoid(Wo·xiPhone+bo),
(4)
hiPhone=oiPhone⊙tanh (ciPhone)。
(5)
其中,⊙代表逐元素乘積,參數(shù)含義如表1所示,在經(jīng)過(guò)LSTM多個(gè)門(mén)計(jì)算之后即可得出單詞“iPhone”的隱向量值hiPhone。其他葉子節(jié)點(diǎn)的隱向量值同樣方法計(jì)算得到。例如單詞“is”的隱向量值計(jì)算如下:
iis=sigmoid(Wi·xis+bi),
(6)
uis=tanh (Wu·xis+bu),
(7)
cis=iis⊙uis,
(8)
ois=sigmoid(Wo·xis+bo),
(9)
his=ois⊙tanh (cis)。
(10)
當(dāng)所有葉子節(jié)點(diǎn)計(jì)算完畢后根據(jù)依存關(guān)系計(jì)算內(nèi)部節(jié)點(diǎn)的值,單詞“good”的隱向量值計(jì)算如下:
igood=sigmoid(Wi·xgood+Ui·WnsubjhiPhone+Ui·Wcop·his+
Ui·Wadvmod·hpretty+bi) ,
(11)
fgood-iPhone=sigmoid(Wf·xgood+Uf·Wnsubj·hiPhone+bf) ,
(12)
fgood-is=sigmoid(Wf·xgood+Uf·Wcop·his+bf) ,
(13)
fgood-pretty=sigmoid(Wf·xgood+Uf·Wadvmod·hpretty+bf) ,
(14)
ugood=tanh (Wu·xgood+Uu·Wnsubj·hiPhone+Uu·Wcop·his+Uu·Wadvmod·hpretty+bu) ,
(15)
cgood=igood⊙ugood+fgood-iPhone⊙ciPhone+fgood-is⊙cis+
fgood-pretty⊙cpretty,
(16)
ogood=sigmoid(Wo·xgood+Uo·Wnsubj·hiPhone+Uo·Wcop·his+
Uo·Wadvmod·hpretty+bo) ,
(17)
hgood=ogood⊙tanh(cgood) 。
(18)
在計(jì)算內(nèi)部節(jié)點(diǎn)隱向量值時(shí),輸入該節(jié)點(diǎn)的除了該詞詞向量外,還有該詞與其多個(gè)子節(jié)點(diǎn)的依存關(guān)系信息。每個(gè)子節(jié)點(diǎn)都會(huì)有一個(gè)遺忘門(mén)去處理該子節(jié)點(diǎn)傳來(lái)的信息,經(jīng)過(guò)LSTM多個(gè)門(mén)單元計(jì)算后即得出此內(nèi)部節(jié)點(diǎn)的隱向量值,內(nèi)部節(jié)點(diǎn)的一般計(jì)算公式總結(jié)如下:
(19)
fjk=sigmoid(Wf·xj+Uf·Wr(jk)·hk+bf) ,
(20)
(21)
(22)
(23)
hj=oj⊙tanh (cj) 。
(24)
其中,C(j)代表當(dāng)前節(jié)點(diǎn)j的所有子節(jié)點(diǎn)的集合,Wr(jk)代表單詞j、k之間的依存關(guān)系矩陣。當(dāng)該句所有詞的隱向量值計(jì)算完畢后,即將結(jié)果輸入到條件隨機(jī)場(chǎng)中進(jìn)行序列標(biāo)注。
1.2 CRF
條件隨機(jī)場(chǎng)是序列標(biāo)注任務(wù)中的主流方法之一,是一種判別式概率模型。本研究使用線(xiàn)性鏈條件隨機(jī)場(chǎng),輸入是Tree LSTM各個(gè)節(jié)點(diǎn)求出的值,輸出是標(biāo)簽,聯(lián)合模型如圖1所示。
對(duì)每個(gè)句子,將經(jīng)過(guò)Tree LSTM計(jì)算并輸入到CRF中的隱向量序列表示為H={h1,h2,…,hn},模型輸出的標(biāo)簽序列表示為Y={y1,y2,…,yn},單詞的標(biāo)注標(biāo)簽本文選用標(biāo)準(zhǔn)的BIO標(biāo)注方式,即yi∈{BA,IA,BO,IO,O},其中BA代表評(píng)價(jià)對(duì)象的開(kāi)始部分,IA代表評(píng)價(jià)對(duì)象的內(nèi)部,BO代表觀點(diǎn)內(nèi)容的開(kāi)始部分,IO代表觀點(diǎn)內(nèi)容的內(nèi)部,O代表其他詞。例如評(píng)論句“The service of the restaurant is good,but the food tastes general.”,CRF的輸入為H={hThe,hservice,hof,hthe,hrestaurant,his,hgood,hbut,hthe,hfood,htastes,hgeneral},模型的輸出結(jié)果為Y={O,BA,O,O,O,O,BO,O,O,BA,BO,IO}。
在給定輸入H的條件下,Y的條件概率分布計(jì)算:
(25)
其中:Z(H)為規(guī)范化因子,用于歸一化;ψc(Yc|H)為勢(shì)函數(shù);P(Y|H)是所有最大團(tuán)C上勢(shì)函數(shù)的乘積。此處最大團(tuán)包含兩類(lèi),一是Tree LSTM輸入到CRF的代表狀態(tài)特征的團(tuán),二是輸出序列中代表轉(zhuǎn)移特征的團(tuán)。在計(jì)算狀態(tài)特征勢(shì)函數(shù)時(shí),額外融合上下文窗口大小為3的信息,則詞“is”處的狀態(tài)特征勢(shì)函數(shù)計(jì)算示例如圖3所示:
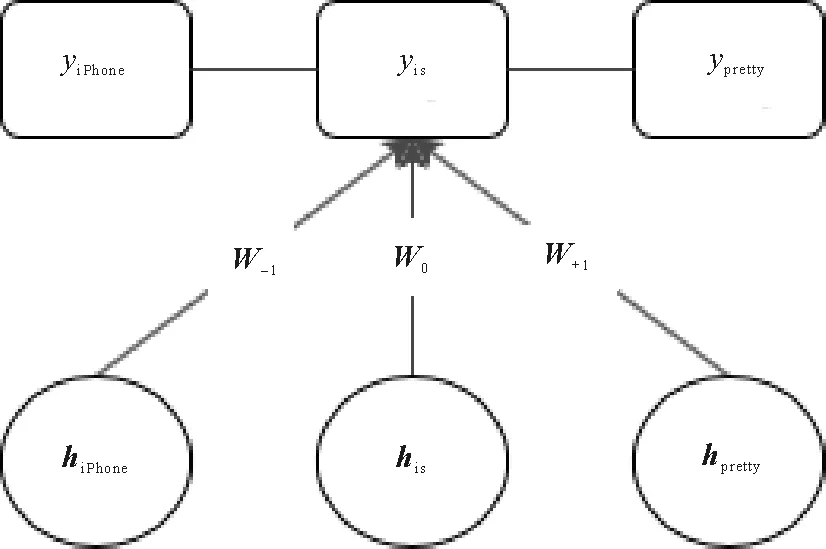
圖3 詞“is”處窗口大小為3的狀態(tài)特征勢(shì)函數(shù)計(jì)算示例Fig.3 Example of state feature potential function calculation with window size 3 at word “is”
在上下文窗口為3時(shí),節(jié)點(diǎn)k處的狀態(tài)特征勢(shì)函數(shù)計(jì)算公式:
(26)

(27)
式中計(jì)算勢(shì)函數(shù)時(shí)前三項(xiàng)代表計(jì)算窗口為3的狀態(tài)特征勢(shì)函數(shù),第四項(xiàng)代表計(jì)算轉(zhuǎn)移特征勢(shì)函數(shù)。
1.3 模型訓(xùn)練
在對(duì)整個(gè)模型訓(xùn)練時(shí),應(yīng)用鏈?zhǔn)椒▌t利用反向傳播的方法學(xué)習(xí)各個(gè)參數(shù)。誤差首先從條件隨機(jī)場(chǎng)開(kāi)始反向傳播,沿模型結(jié)構(gòu)傳到Tree LSTM中,ROOT指向的節(jié)點(diǎn)只接收到從CRF傳來(lái)的誤差,其他節(jié)點(diǎn)將接收到來(lái)自CRF的誤差和來(lái)自依存關(guān)系父節(jié)點(diǎn)傳來(lái)的誤差,LSTM單元中各門(mén)的參數(shù)也將根據(jù)鏈?zhǔn)椒▌t學(xué)習(xí)更新。
2 實(shí)驗(yàn)及分析
2.1 數(shù)據(jù)集及實(shí)驗(yàn)設(shè)置
本節(jié)使用SemEval Challenge 2014 任務(wù)4的數(shù)據(jù)集對(duì)模型進(jìn)行訓(xùn)練與測(cè)試,該數(shù)據(jù)集包含筆記本和餐館兩個(gè)領(lǐng)域的評(píng)論數(shù)據(jù),詳細(xì)信息如表2所示,該數(shù)據(jù)僅僅包含對(duì)評(píng)價(jià)對(duì)象的標(biāo)注,實(shí)驗(yàn)使用了Wang等[15]對(duì)觀點(diǎn)內(nèi)容手工標(biāo)注的數(shù)據(jù)。

表2 SemEval Challenge 2014 任務(wù)4 數(shù)據(jù)集Tab.2 Dataset of SemEval Challenge 2014 Task 4
在訓(xùn)練詞向量時(shí),使用gensim word2vec方法進(jìn)行訓(xùn)練,餐館領(lǐng)域的訓(xùn)練語(yǔ)料數(shù)據(jù)選擇Yelp cha-llenge dataset的評(píng)論數(shù)據(jù),筆記本領(lǐng)域訓(xùn)練語(yǔ)料數(shù)據(jù)選擇Amazon的電子產(chǎn)品評(píng)論數(shù)據(jù),詞向量的維數(shù)在比對(duì)后選擇350維,對(duì)比實(shí)驗(yàn)在2.2節(jié)中敘述。評(píng)論語(yǔ)句的依存句法分析樹(shù)使用Stanford Parser生成,模型中的線(xiàn)性鏈CRF使用CRFSuite實(shí)現(xiàn)。

由于SemEval Challenge 2014 任務(wù)4的評(píng)測(cè)模型僅對(duì)評(píng)價(jià)對(duì)象進(jìn)行了抽取,為了方便比較,將本模型去除觀點(diǎn)內(nèi)容標(biāo)簽后重新訓(xùn)練學(xué)習(xí),得到只抽取評(píng)價(jià)對(duì)象的聯(lián)合模型并命名為T(mén)ree LSTM+CRF-O。
2.2 實(shí)驗(yàn)與結(jié)果分析
為了驗(yàn)證提出模型的有效性,本研究還實(shí)現(xiàn)了以下幾個(gè)模型:
1) SemEval-1,SemEval-2:SemEval Challenge 2014任務(wù)4評(píng)測(cè)時(shí)性能最好的兩個(gè)模型。
2) CRF-1:包含基礎(chǔ)語(yǔ)言特征(詞、文體、詞性、上下文、上下文詞性)的CRF模型。
3) CRF-2:包含上述基礎(chǔ)語(yǔ)言特征和依存關(guān)系特征(中心詞和詞之間的依存關(guān)系)的CRF模型。
4) W+L+D+B:Yin等[12]提出的CRF模型包含無(wú)監(jiān)督學(xué)習(xí)得到的詞嵌入特征、依存關(guān)系特征,線(xiàn)性上下文嵌入特征以及基礎(chǔ)特征模板。
5) LSTM,LSTM-CRF,Bi-LSTM-CRF:分別指LSTM為基礎(chǔ)的長(zhǎng)短期記憶網(wǎng)絡(luò),LSTM-CRF為長(zhǎng)短期記憶網(wǎng)絡(luò)結(jié)合CRF的模型,Bi-LSTM-CRF為雙向長(zhǎng)短期記憶網(wǎng)絡(luò)結(jié)合CRF的模型。LSTM網(wǎng)絡(luò)中的權(quán)重通過(guò)區(qū)間[-0.2,0.2]的隨機(jī)均勻分布初始化,隱層的大小設(shè)置為50,學(xué)習(xí)率設(shè)置為0.01。
6) RNCRF,RNCRF-O:Wang等[15]提出的遞歸神經(jīng)網(wǎng)絡(luò)和CRF的聯(lián)合模型,RNCRF-O是為方便比較而忽略掉觀點(diǎn)內(nèi)容標(biāo)注的模型。
選用F1值作為模型性能的評(píng)價(jià)指標(biāo),計(jì)算方法如公式(28)~(30)所示。其中,TP是模型正確標(biāo)注的數(shù)量,TP+FP是模型標(biāo)注的總數(shù),TP+FN是測(cè)試集中存在的標(biāo)注總數(shù)。
(28)
(29)
(30)
實(shí)驗(yàn)結(jié)果如表3所示。
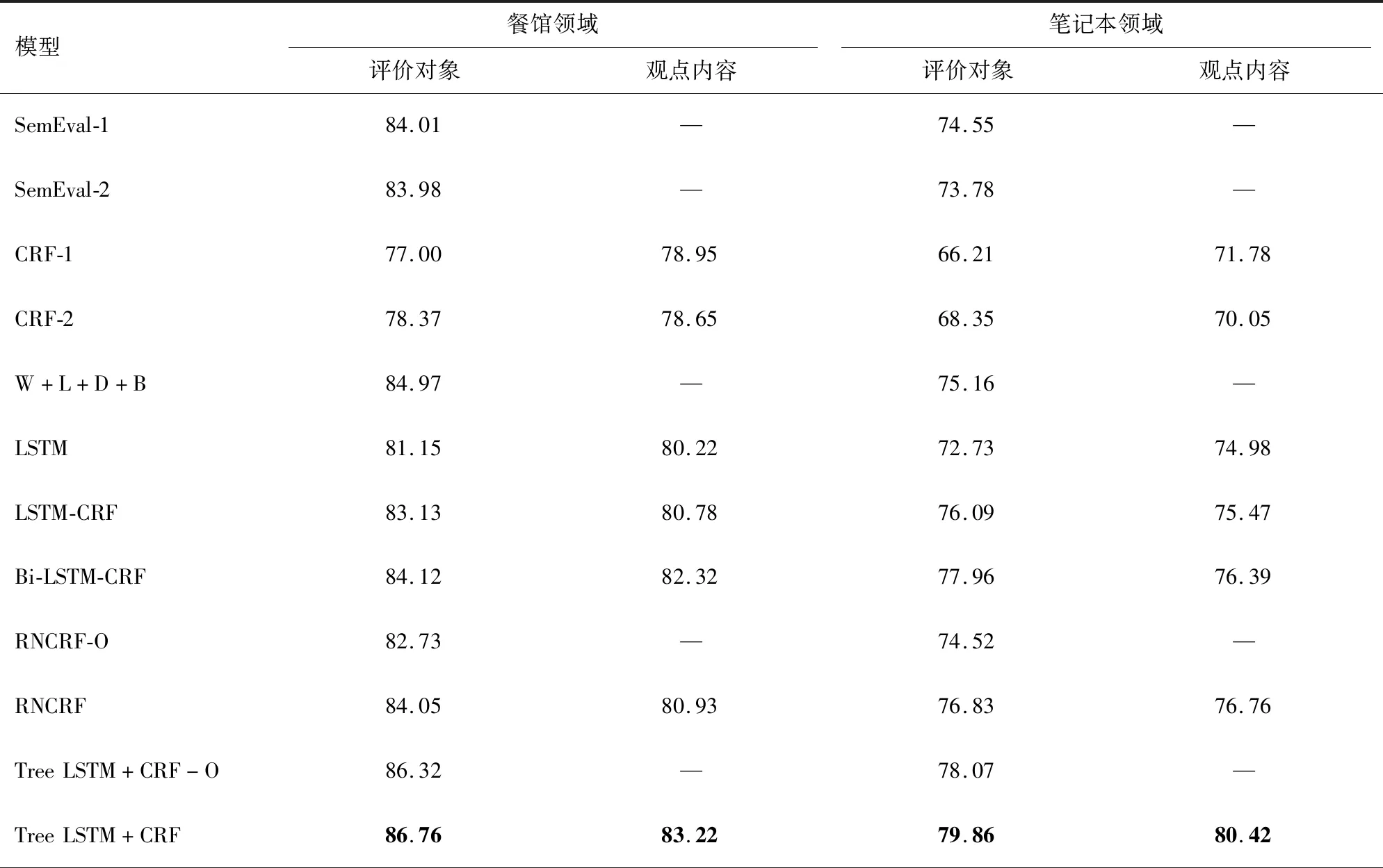
表3 各模型實(shí)驗(yàn)結(jié)果的F1-Score值Tab.3 F1-Score of experimental results of each model
由表3可知,本模型比SemEval Challenge的最優(yōu)模型SemEval-1與SemEval-2效果好,在餐館與筆記本領(lǐng)域分別比SemEval-1高出2.75%和5.31%。在與普通條件隨機(jī)場(chǎng)的對(duì)比中,在加入依存關(guān)系特征后,CRF-2在評(píng)價(jià)對(duì)象抽取上比CRF-1在餐館和筆記本領(lǐng)域分別高出1.37%和2.14%,說(shuō)明依存關(guān)系特征確實(shí)有助于評(píng)價(jià)對(duì)象的抽取,同時(shí)CRF模型的結(jié)果低于其他模型,說(shuō)明深度學(xué)習(xí)方法比條件隨機(jī)場(chǎng)學(xué)習(xí)信息更加有效。LSTM模型的結(jié)果要差于LSTM-CRF模型,這是由于條件隨機(jī)場(chǎng)能夠糾正類(lèi)似IA、BA這樣的標(biāo)注順序錯(cuò)誤,所以大部分模型都會(huì)在神經(jīng)網(wǎng)絡(luò)之后連接條件隨機(jī)場(chǎng)進(jìn)行標(biāo)注。雙向LSTM因?yàn)槟軌虿东@2個(gè)方向的信息而比普通LSTM模型效果要好。本模型比RNCRF模型效果略好,說(shuō)明將普通遞歸神經(jīng)網(wǎng)絡(luò)單元替換為L(zhǎng)STM單元和設(shè)計(jì)樹(shù)結(jié)構(gòu)下LSTM單元門(mén)結(jié)構(gòu)的計(jì)算方法是有效的;比時(shí)間序列的Bi-LSTM-CRF模型的結(jié)果好,說(shuō)明樹(shù)結(jié)構(gòu)在依存關(guān)系信息的處理中優(yōu)于時(shí)間序列結(jié)構(gòu)。由于依存關(guān)系是由子單詞指向父單詞,類(lèi)似于樹(shù)結(jié)構(gòu),所以在依存關(guān)系特征上樹(shù)結(jié)構(gòu)效果更好。Tree LSTM+CRF-O是去除觀點(diǎn)內(nèi)容標(biāo)注的模型,從實(shí)驗(yàn)結(jié)果可以看出,該模型性能損失不大,表明本模型魯棒性好。
圖4給出了RNCRF和Tree LSTM+CRF兩個(gè)模型實(shí)際標(biāo)注的結(jié)果示例。從圖4中的例子中可看出,本模型比普通遞歸神經(jīng)網(wǎng)絡(luò)能更好地處理依存關(guān)系特征和詞本身特征,對(duì)低頻出現(xiàn)的評(píng)價(jià)對(duì)象和依存關(guān)系相對(duì)復(fù)雜的句子標(biāo)注結(jié)果更好。

圖4 RNCRF與Tree LSTM+CRF標(biāo)注結(jié)果對(duì)比Fig.4 Comparison of RNCRF and Tree LSTM+CRF labeling results
進(jìn)一步還對(duì)不同詞向量維度對(duì)模型的影響進(jìn)行了實(shí)驗(yàn)。實(shí)驗(yàn)選取維度范圍為50~500維,維度間隔為50,實(shí)驗(yàn)結(jié)果如圖5所示。

圖5 詞向量維度對(duì)比實(shí)驗(yàn)結(jié)果Fig.5 Word vector dimension comparison experiment results
由圖5可以看出,在餐館領(lǐng)域,評(píng)價(jià)對(duì)象的抽取結(jié)果普遍優(yōu)于觀點(diǎn)內(nèi)容的抽取結(jié)果;而在筆記本領(lǐng)域,觀點(diǎn)內(nèi)容的抽取結(jié)果普遍優(yōu)于對(duì)評(píng)價(jià)對(duì)象的抽取結(jié)果。而且模型在兩個(gè)領(lǐng)域下都在350維處效果最好,模型性能隨維度變化有波動(dòng)但波動(dòng)幅度不超過(guò)3%,模型性能相對(duì)穩(wěn)定。
3 總結(jié)與展望
評(píng)價(jià)對(duì)象和觀點(diǎn)內(nèi)容的抽取是觀點(diǎn)挖掘中的重要研究?jī)?nèi)容。本研究提出一個(gè)基于Tree LSTM結(jié)合CRF的聯(lián)合模型來(lái)抽取評(píng)論語(yǔ)句中的顯式評(píng)價(jià)對(duì)象與觀點(diǎn)內(nèi)容。該模型包含兩部分,第一部分是根據(jù)評(píng)論語(yǔ)句的依存結(jié)構(gòu)樹(shù)構(gòu)建的Tree LSTM,用于融合詞向量和依存句法關(guān)系向量從而學(xué)習(xí)每個(gè)詞的高層特征;第二部分是條件隨機(jī)場(chǎng),將從Tree LSTM得到的每個(gè)詞的隱向量輸入其中進(jìn)行序列標(biāo)注工作,將隱向量映射到代表評(píng)價(jià)對(duì)象、觀點(diǎn)內(nèi)容和其他詞的標(biāo)簽上,實(shí)現(xiàn)了評(píng)價(jià)對(duì)象與觀點(diǎn)內(nèi)容的抽取。在SemEval Cha-llenge 2014 任務(wù)4的數(shù)據(jù)集上的實(shí)驗(yàn)結(jié)果表明本Tree LSTM能很好地表征詞語(yǔ)之間的層次關(guān)系,同時(shí)聯(lián)合模型有效避免了傳統(tǒng)CRF需要構(gòu)建特征工程的弊端。
目前本模型只是實(shí)現(xiàn)了簡(jiǎn)單的抽取工作,下一步將對(duì)評(píng)論句進(jìn)行情感分析,深入分析用戶(hù)所表達(dá)的觀點(diǎn);并嘗試對(duì)評(píng)論中的隱式評(píng)價(jià)對(duì)象進(jìn)行抽取,以全面分析用戶(hù)的觀點(diǎn)。
猜你喜歡
科學(xué)大眾(2022年11期)2022-06-21 09:20:52
石油瀝青(2021年4期)2021-10-14 08:50:44
瘋狂英語(yǔ)·新策略(2019年10期)2019-12-13 08:43:28
當(dāng)代陜西(2019年10期)2019-06-03 10:12:04
數(shù)學(xué)小靈通·3-4年級(jí)(2017年9期)2017-10-13 08:10:54
臺(tái)聲(2016年2期)2016-09-16 01:06:53
中國(guó)教育技術(shù)裝備(2015年19期)2015-03-01 02:43:07
河南科技(2014年23期)2014-02-27 14:19:15
俄羅斯問(wèn)題研究(2012年1期)2012-03-25 09:54:51
體育師友(2012年4期)2012-03-20 15:30:10
