基于半監督集成學習的詞義消歧
2020-11-13 01:53:32張春祥熊經釗高雪瑤
哈爾濱工程大學學報 2020年8期
張春祥, 熊經釗, 高雪瑤
(1.哈爾濱理工大學 軟件與微電子學院,黑龍江 哈爾濱 150080;2.哈爾濱理工大學 計算機科學與技術學院,黑龍江 哈爾濱 150080)
詞義消歧的目的是確定歧義詞匯在特定上下文環境中的具體含義。詞義消歧對機器翻譯、話題關聯檢測、語音識別、文本分類、信息檢索和主題挖掘等應用有很大的影響[1-2]。錢濤等[3]、SONAKSHI等[4]和EDILSON等[5]使用圖來描述詞義消歧問題。ROCCO等[6]根據分布信息來計算語義的相似性,提出了一種新的基于進化博弈理論的詞義消歧模型。SALLAM等[7]將蜂群優化元啟發式算法應用于詞義消歧過程,利用多個人工蜂代理來協同處理該問題。SULEMA等[8]利用Alpha-Beta聯想記憶對歧義詞及其上下文之間的關聯性進行計算,提出了一種基于簡化LESK算法的詞義消歧方法。與其他基于LESK的方法相比,該方法具有一定的優越性。MYUNG等[9]提出了一種基于詞嵌入的消歧方法,使消歧特征向量具有可加性和組合性,消歧特征向量更加緊湊和高效。OSMAN等[10]和CLAUDIO等[11]以少量帶有語義注釋的語料為基礎,挖掘大量無標注語料中的語言學知識來進行半監督詞義消歧。楊陟卓[12]和孟禹光等[13]分別利用上下文的譯文和詞性來確定歧義詞匯的含義。WANG等[14]以共現知識和訓練文檔的類知識為基礎,利用語義擴散核來解決詞匯的歧義問題。郭瑛媚等[15]以話題信息、位置關系和互信息為消歧特征,提出了一種無監督的跨語言詞義消歧算法。利用在線詞典和Web搜索引擎,使用上下文信息來確定評論句中多義評論詞的具體含義。楊安等[16]和鹿文鵬等[17]利用領域知識來進行詞義消歧。HUNG等[18]和唐共波等[19]分別利用情感詞匯網絡詞典與知網中的義原來進行詞義消歧。許坤利等[20]用啟發式信息從語料中挖掘實體和關系,對謂詞進行消歧。WANG等[21]和ANTONIO等[22]以生物醫學中的專業知識為基礎來建立詞義消歧模型,解決了文本中詞語的歧義問題。
本文以歧義詞匯為中心,從其左右4個鄰接詞匯單元中抽取詞形、詞性和語義類作為消歧特征,統計其出現的頻率。以邏輯回歸模型、梯度提升決策樹和支持向量機為基礎,采用軟投票策略來構造集成詞義消歧模型。同時,使用半監督學習方法來優化集成詞義消歧模型。
1 詞義消歧特征的選擇
本文利用詞法知識和語義知識來確定歧義詞的含義。以歧義詞為中心,選擇左右4個鄰接詞匯單元。從每個詞匯單元中,抽取詞形、詞性和語義類作為消歧特征。
對于包含歧義詞“中醫”的漢語句子,其消歧特征的提取過程如下所示:
漢語句子:一位當中醫的親戚。
分詞結果:一 位 當 中醫 的 親戚。
詞性標注:一/m 位/q 當/v 中醫/n 的/u 親戚/n。/w
語義標注:一/m/Eb02 位/q/Di15 當/v/Hj24 中醫/n/Dk03 的/u/Ed01 親戚/n/Ah01。/w/-1
消歧特征的提取過程如圖1所示。
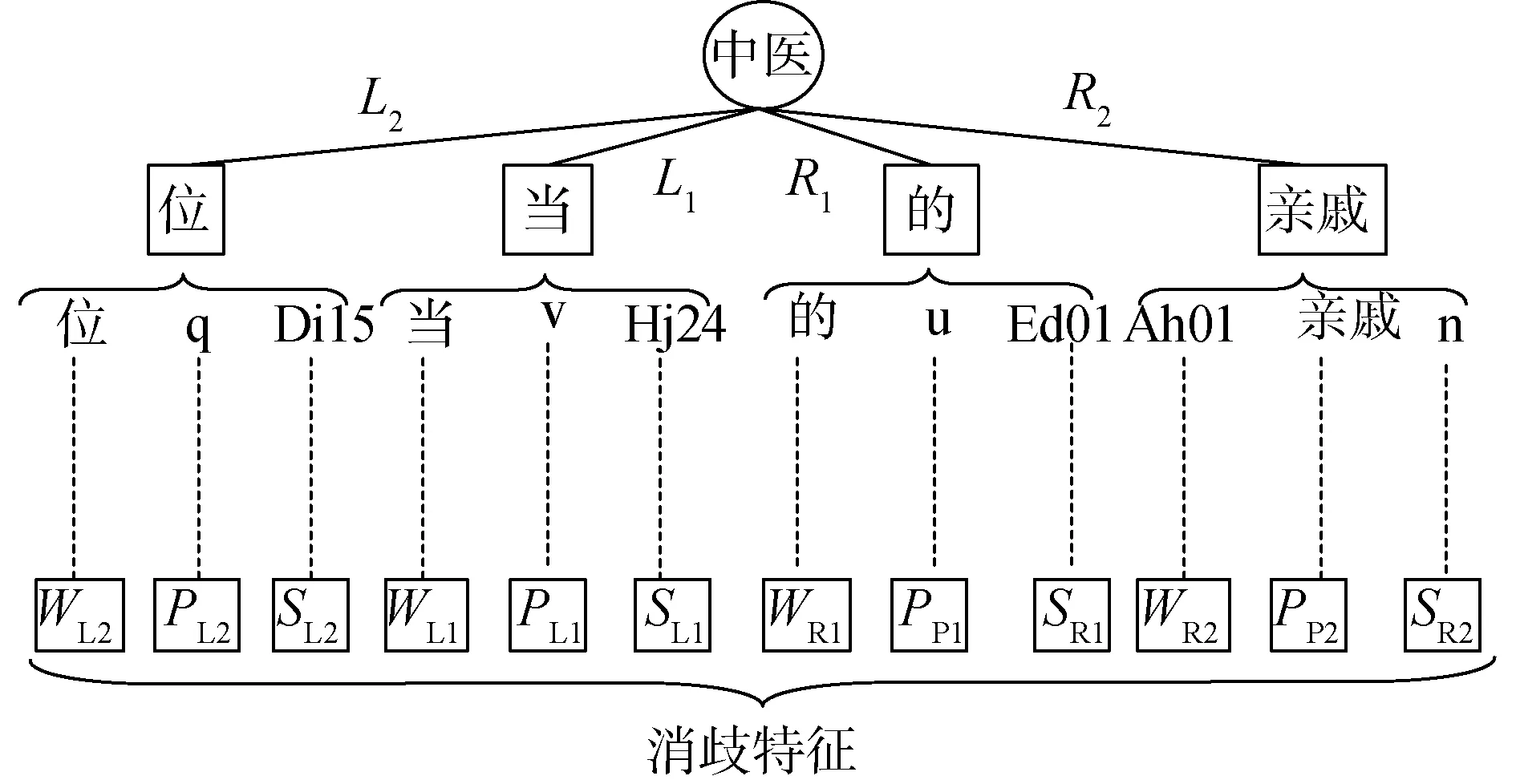
圖1 消歧特征的提取Fig.1 Extract disambiguation features
從漢語句子中,提取歧義詞“中醫”左右4個鄰接詞匯單元,分別為:“位/q/Di15”、“當/v/Hj24”、“的/u/Ed01”和“親戚/n/Ah01”。詞形用W來表示;詞性用P來表示;語義類用S來表示。歧義詞左側的2個鄰接詞匯單元的詞形分別用WL1、WL2來表示;右側的2個鄰接詞匯單元的詞形分別用WR1、WR2來表示。左側2個鄰接詞匯單元的詞性分別用PL1、PL2來表示;右側2個鄰接詞匯單元的詞性分別用PR1、PR2來表示。左側2個鄰接詞匯單元的語義類分別用SL1、SL2來表示;右側2個鄰接詞匯單元的語義類分別用SR1、SR2來表示。從4個鄰接詞匯單元中,共抽取了12種消歧特征。
在哈爾濱工業大學人工語義標注語料中,每個漢語句子都進行了詞匯切分。每個單詞都標注了詞性。以《同義詞詞林》為基礎,按照上下文信息標注了每個詞匯的語義類別。以該人工語義標注語料為基礎,統計消歧特征的頻率F,如表1所示。

表1 消歧特征的頻率Table 1 Frequency of disambiguation features
本文利用詞義消歧特征的頻率來判別歧義詞的真實含義。統計12個消歧特征的頻率,F(WL2)、F(PL2)、F(SL2)、F(WL1)、F(PL1)、F(SL1)、F(WR1)、F(PR1)、F(SR1)、F(WR2)、F(PR2)、F(SR2),得到詞義消歧特征向量Efeature=(F(WL2),F(PL2),F(SL2),F(WL1),F(PL1),F(SL1),F(WR1),F(PR1),F(SR1),F(WR2),F(PR2),F(SR2))。
2 基本詞義消歧模型
歧義詞w具有m個語義類sk=k(k=1, 2,…,m)。其消歧特征向量為Efeature。本文使用邏輯回歸(logistic regression,LR)模型、梯度提升決策樹(gradient boosting decision tree,GBDT)和支持向量機(support vector machine,SVM)來確定歧義詞w的語義類別。
2.1 基于邏輯回歸模型的詞義消歧

(1)
從語義標注語料中,抽取包含歧義詞w的漢語句子。從每一個漢語句子中,抽取歧義詞w的特征向量。歧義詞w的特征向量和標注的語義類別構成二元組。將歧義詞w的所有二元組搜集起來形成集合L。利用L來計算交叉熵代價函數J(θk):
(1-u)lb(1-FLR(Efeature))]
(2)
式中:Lk=L,(Efeature,u)∈Lk,u∈{0, 1}。當歧義詞w的語義類為sk時,u的值為1;w的語義類不為sk時,u的值為0。

(3)
歧義詞w不屬于語義類sk的概率:
(4)
邏輯回歸詞義消歧模型為FLR(Efeature),選擇具有最大概率的語義類作為歧義詞w的預測語義類別:
(5)
2.2 基于梯度提升決策樹的詞義消歧
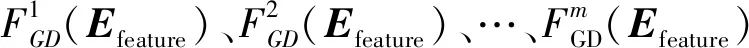
(6)

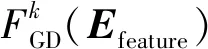
1)初始化梯度提升決策樹。
(7)
2)采用向前分布算法,得到第n步的模型:
(8)
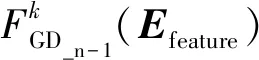
(9)
其中,(Efeature,u)∈Lk,u∈{0, 1}。當歧義詞w的語義類為sk時,u的值為1;w的語義類不為sk時,u的值為0。Loss為損失函數,采用平方差誤差損失函數來進行計算:
(10)
使用softmax函數來計算w屬于語義類sk的概率,選擇具有最大概率的語義類作為歧義詞w的預測語義類別。基于梯度提升決策樹的詞義消歧模型FGD(Efeature)為:
(11)
2.3 基于支持向量機的詞義消歧
對于歧義詞w而言,設計m個二類SVM模型FSVM1(Efeature、FSVM2(Efeature)、…、FSVMm(Efeature)來進行消歧。其中,FSVMk(Efeature)用于判別歧義詞w是否屬于語義類別sk:
(12)
式中:wk為分類超平面的法向量;bk為分類超平面截距;sgn為符號函數。

(13)
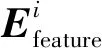
使用softmax函數來計算w屬于語義類sk的概率,選擇具有最大概率的語義類作為歧義詞w的預測語義類別。SVM詞義消歧模型FSVM(Efeature):
(14)
3 半監督集成詞義消歧
分類模型會根據自己學習到的知識來對未標記數據進行預測。本文運用軟投票策略來融合FLR(Efeature)、FGD(Efeature)和FSVM(Efeature),獲取集成詞義消歧模型FEN(Efeature)。在確定歧義詞w的語義類別時,不但考慮了少數服從多數的原則,而且考慮了模型對語義類別的概率分布。基于軟投票集成的詞義消歧過程如下:
輸入:歧義詞w的特征向量Efeature,
輸出:歧義詞w的語義類別S。

(15)
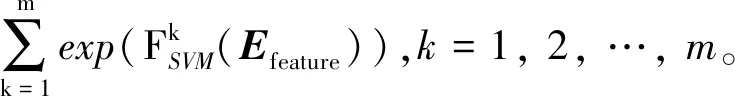
(16)
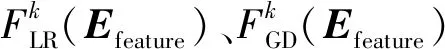
P=(P(sk|w,FLR)+P(sk|w,FGD)+
P(sk|w,FSVM))/3。
(17)
5)集成分類器為:
P(sk|w,FGD)+P(sk|w,FSVM))/3
(18)
選擇具有最大概率的語義類作為歧義詞w的預測語義類別。
從語義標注語料中,抽取包含歧義詞w的漢語句子。從每一個漢語句子中,抽取歧義詞w的特征向量。歧義詞w的特征向量和標注的語義類別構成二元組。將歧義詞w的所有二元組搜集起來形成集合L。從無標注語料中,抽取包含歧義詞w的漢語句子。從每一個漢語句子中,抽取歧義詞w的特征向量。將歧義詞w的所有特征向量搜集起來形成集合U。基于半監督集成學習的詞義消歧分類器的訓練過程:
輸入:語義標注集合L和無語義標注集合U。
輸出:詞義消歧分類器FEN(Efeature)。

3)L=L∪{(t,FEN(t))},U=U-{t}。
4)若U不為空集,則重復執行步驟1到步驟4);否則,執行步驟5)。
5)輸出優化后的詞義消歧分類器FEN(Efeature)。
4 實驗結果與分析
采用SemEval-2007: Task#5的訓練語料和測試語料來度量本文所提出方法的性能。從SemEval-2007: Task#5中,選取28個常用的歧義詞。其中,具有2種語義類的歧義詞共有16個,分別為“表面”、“菜”、“單位”、“動搖”、“兒女”、“機組”、“鏡頭”、“開通”、“氣息”、“氣象”、“使”、“推翻”、“望”、“眼光”、“震驚”、“中醫”。具有3種語義類的歧義詞共有9個,分別為“補”、“本”、“成立”、“隊伍”、“旗幟”、“日子”、“天地”、“挑”、“長城”。具有4種語義類的歧義詞共有3個,分別為“吃”、“動”、“叫”。共進行了8組實驗來度量本文所提出方法的性能。在這8組實驗中,都選擇了歧義詞左右鄰接的4個詞匯單元的詞形、詞性和語義類作為消歧特征。
實驗1采用FLR(Efeature)作為詞義消歧分類模型。實驗2利用FGD(Efeature)進行詞義消歧。實驗3采用FSVM(Efeature)作為詞義消歧分類模型。實驗4利用FEN(Efeature)進行詞義消歧。使用SemEval-2007: Task#5的訓練語料來優化這4組實驗的詞義消歧模型。實驗1到實驗4采用有監督學習方法來訓練詞義消歧分類器。利用優化后的FLR(Efeature)、FGD(Efeature)、FSVM(Efeature)和FEN(Efeature)對SemEval-2007: Task#5的測試語料進行語義分類。
采用SemEval-2007提供的評測指標來進行評測,計算過程為:
(19)
式中:N為所有目標歧義詞匯數目;mi是第i個歧義詞匯正確分類的測試句子數;ni是包含第i個歧義詞的所有測試句子數;pi為第i個歧義詞的消歧準確率;pavg為詞義消歧的平均準確率。
實驗1~4的消歧準確率如表2所示。
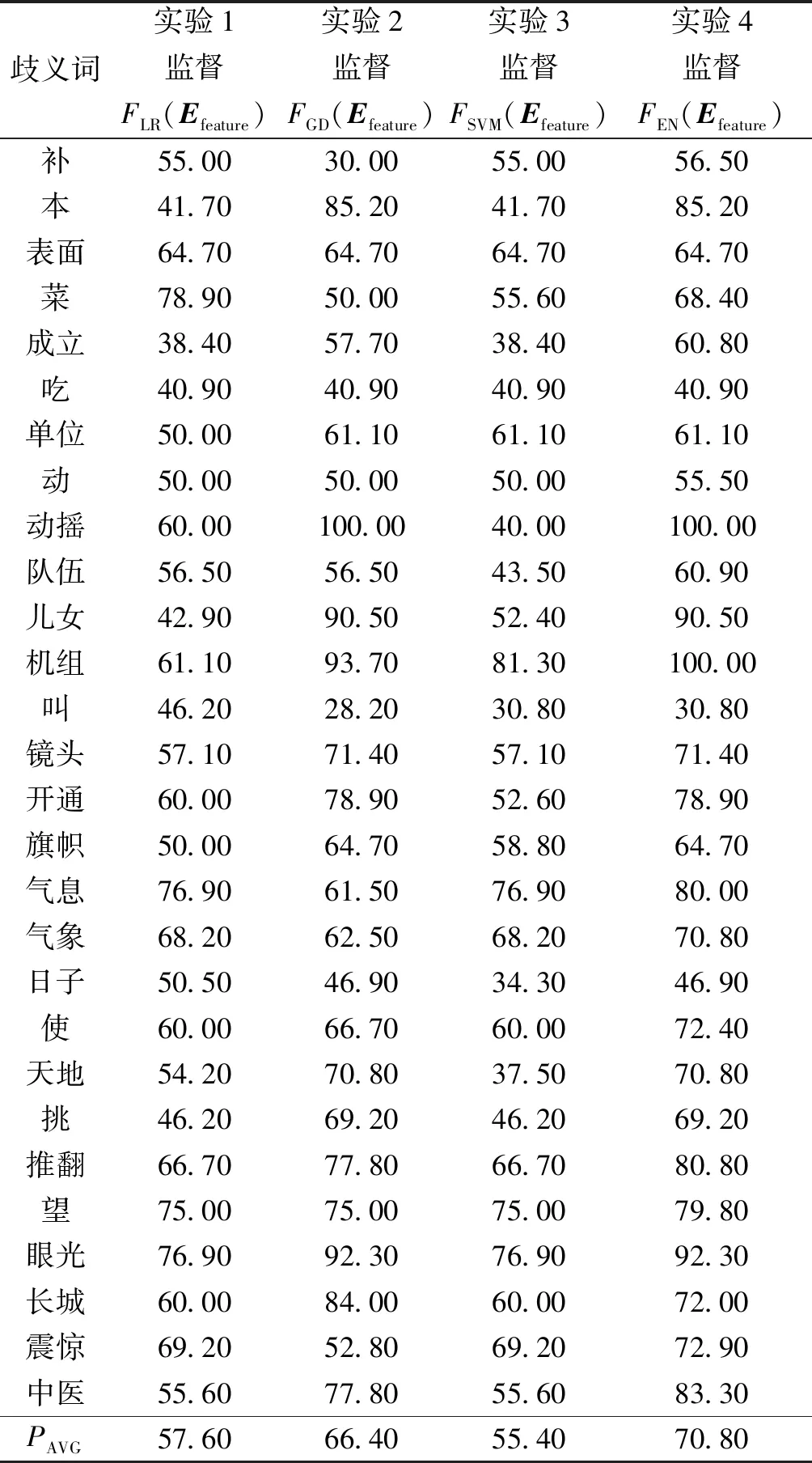
表2 實驗1~4的消歧準確率Table 2 Disambiguation accuracy from experiment 1~4 %
實驗4的消歧平均準確率達到了70.80%,比實驗1提高了13.20%,比實驗2提高了4.40%,比實驗3提高了15.40%。其原因在于:實驗4采用軟投票對邏輯回歸模型、梯度提升決策樹和SVM模型進行集成,綜合了各種分類模型的優點,取長補短,其消歧效果要比單一分類模型好。
實驗5~8利用本文所提出的方法來進行詞義消歧。以SemEval-2007: Task#5的訓練語料為基礎,結合哈爾濱工業大學無標注語料使用本文所提出的方法來優化集成分類器FEN(Efeature)。在訓練結束后,獲得了優化的集成分類器FEN(Efeature)。同時,也得到了半監督學習下的優化的FLR(Efeature)、FGD(Efeature)和FSVM(Efeature)。實驗5利用半監督學習獲得的FLR(Efeature)作為詞義消歧分類器。實驗6使用半監督學習獲得的FGD(Efeature)進行詞義消歧。實驗7利用半監督學習獲得的FSVM(Efeature)作為詞義消歧分類器。實驗8使用半監督學習獲得的FEN(Efeature)進行詞義消歧。在實驗5~8中,分別對SemEval-2007: Task#5的測試語料進行語義分類。實驗5~8的消歧準確率如表3所示。
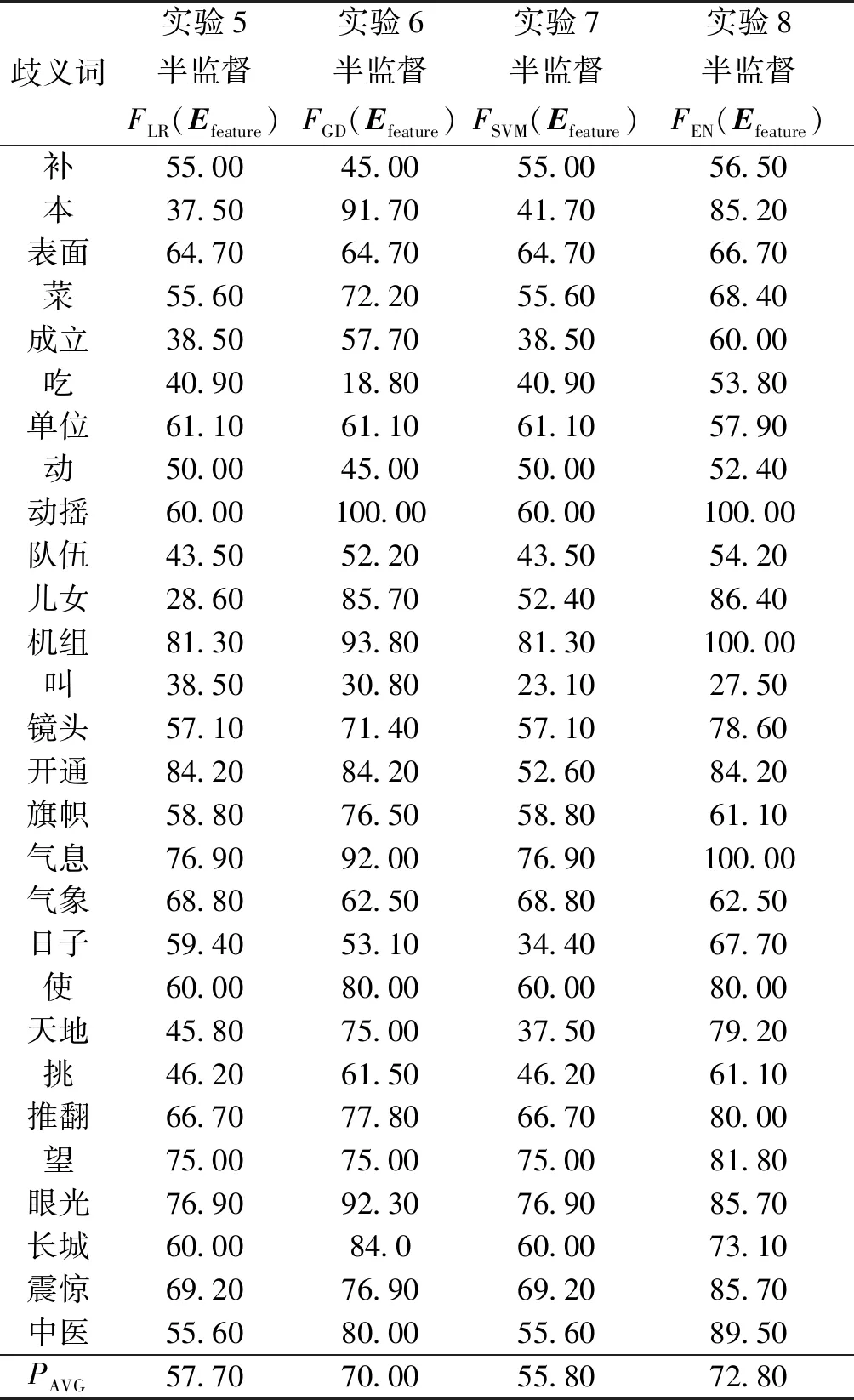
表3 實驗5~8的消歧準確率Table 3 Disambiguation accuracy from experiment 5~8 %
對比表2和表3可以看出:實驗5的平均消歧準確率比實驗1提高了0.10%;實驗6的平均消歧準確率比實驗2提高了3.60%;實驗7的平均消歧準確率比實驗3提高了0.40%;實驗8的平均消歧準確率比實驗4提高了2.0%。其原因為:實驗1到實驗4是以人工語義標注語料為基礎,采用有監督學習方法來優化詞義消歧模型。大規模人工標注語料的語義類別是極其困難的,因此,實驗1~4所獲取的語言學知識將是有限的。實驗5~8是以人工語義標注語料為基礎,結合大量無標注語料采用半監督學習方法來優化詞義消歧模型。大量無標注語料是比較容易獲得的,其中蘊含了豐富的語言學知識,能夠為詞義消歧過程提供指導信息。因此,實驗5的平均消歧準確率要高于實驗1,實驗6的平均消歧準確率要高于實驗2,實驗7的平均消歧準確率要高于實驗3,實驗8的平均消歧準確率要高于實驗4。
在實驗5~8中,分別統計具有2種、3種和4種語義類的詞匯的平均消歧準確率,如圖2所示。
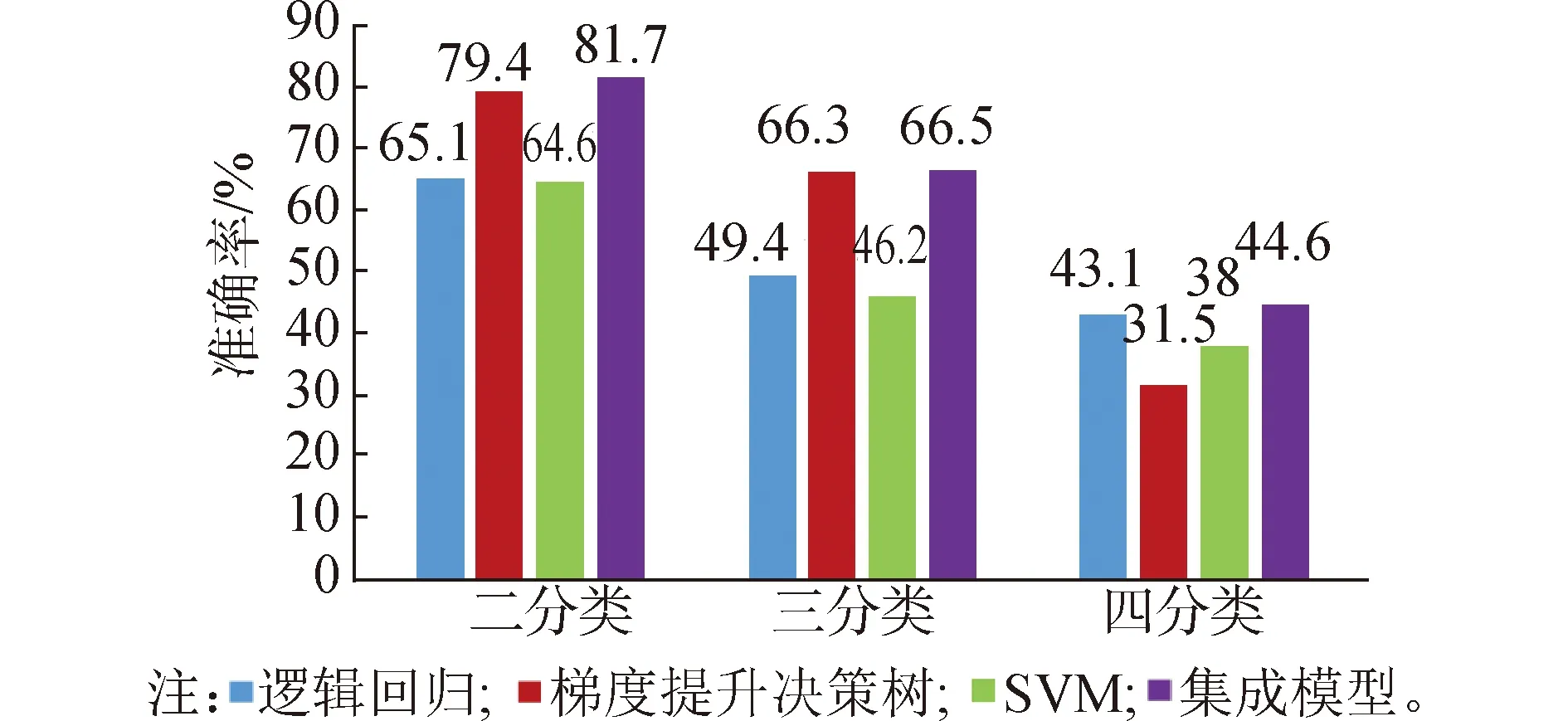
圖2 在不同語義類別數下實驗5~8的平均消歧準確率Fig.2 Average disambiguation accuracy under different number of sense categories from experiment 5~8
從圖2中可以看出:在2種、3種和4種語義類下,FEN(Efeature)的平均消歧準確率要好于FLR(Efeature)、FGD(Efeature)和FSVM(Efeature)。
5 結論
1)本文所提出方法的消歧性能要優于邏輯回歸模型、梯度提升決策樹和支持向量機,能夠更準確地確定歧義詞匯的語義類別。
2)根據實驗論證能夠證明本文提出的方法具有一定的優勢,能夠更加準確地確定中文歧義詞的具體含義,可以應用到中文消歧的實踐中。
猜你喜歡
小獼猴智力畫刊(2022年9期)2022-11-04 02:31:42
中華胰腺病雜志(2021年1期)2021-02-26 11:28:36
山東醫藥(2020年34期)2020-12-09 01:22:24
開放教育研究(2020年2期)2020-03-31 01:54:14
小哥白尼(趣味科學)(2019年6期)2019-10-10 01:01:50
中華胰腺病雜志(2019年4期)2019-08-29 08:52:20
發明與創新(2016年38期)2016-08-22 03:02:52
太空探索(2016年5期)2016-07-12 15:17:55
現代語文(2016年21期)2016-05-25 13:13:44
大連民族大學學報(2015年2期)2015-02-27 08:28:11
