CStock:一種結合新聞與股價的股票走勢預測模型
2020-11-16 10:24:46陳可心
計算機技術與發展 2020年9期
陳可心,黃 剛
(南京郵電大學 計算機學院,江蘇 南京 210023)
0 引 言
股票預測研究是金融大數據的一個應用研究方向,隨著中國經濟的快速增長和金融市場的不斷擴大,越來越多的投資者開始關注提高投資回報率并能有效地避免一定風險的方法,其中對股票走勢預測在商業和金融領域具有重要的意義。面對股票價格的漲跌,投資者會獲得難以預測的收益甚至虧損,因此預測股票的走勢,選取值得投資的股票成為投資者關心的問題。鑒于股票市場的復雜性、不穩定性,預測股票走勢所需要考慮的變量和信息來源的數量巨大,預測股票走勢是一個非常艱難的任務,如今依舊是各領域重點關注與討論的對象。傳統的分析方法主要是利用既有的股票數據和相關技術圖表,結合投資者自身經驗對股票走勢進行預測。但是這種方法在當今日益龐大且復雜的股票市場中并不適用。除了效率低、過于依靠人工經驗以外,還存在股票內容信息完整性差、特征數據冗余等一系列問題,對股票數據的利用率低,效果不佳,難以滿足市場發展的需要。
隨著機器學習技術的不斷發展,越來越多的投資者開始使用機器學習技術對股票數據進行分析,從價格歷史數據中學習以預測未來價格,搭建股票市場預測模型。常見的機器學習算法有Logistic回歸、遺傳算法、支持向量機等,并取得了不錯的結果。而隨著神經網絡技術的興起,通過搭建深度的神經網絡來刻畫股票價格并預測股票的走勢,受到了人們的廣泛關注,一些學者對這方面也展開了深入的研究[1-2]。NairBB等人[3]基于決策樹構建去噪混合股價預測模型。該模型首先對股票數據的相關特征進行特征提取,然后使用決策樹算法對提取過的特征進行特征選擇并使用PCA算法進行降維處理,降維后的數據輸入到模糊模型中預測股價。Ticknor等人[4]構建了一個貝葉斯神經網絡模型,不需要對數據進行預處理操作和周期分析,僅把市場價格和技術指標作為預測模型的輸入,來預測未來股票的收盤價格。蘇治等人[5]構建了一種通過遺傳算法對數據進行降維優化的SVM模型,采用量化選股方法分別從短期和中長期對其選股性能和預測精度進行了實證分析。程昌品等人[6]采用了先對股票價格序列使用小波分解,分離出非平穩時間序列中的低頻信息和高頻信息,然后對高頻信息構建ARIMA模型,對低頻信息使用SVM模型進行擬合的方法,得到了較好的結果。郝知遠等人[7]基于輿論情報數據并進行自然語言處理及挖掘的建模預測分析的研究工作.其主要方法是依據最大化收益思想,提出了根據ROC曲線下的面積AUC值進行遺傳參數尋優的支持向量機,解決傳統方法在預測中可用性不高的問題。韓山杰等人[8]基于谷歌人工智能學習系統TensorFlow,構建多感知器MLP(multi-layer perceptron)神經網絡模型,用于預測每日收盤股價。并就股價預測問題將TensorFlow與傳統BP(back propagation)神經網絡進行性能對比。Chen K等人[1]分析在加入不同數量的特征及不同的數據預處理狀況下,使用長短期記憶網絡LSTM對預測結果的影響;與隨機預測方法相比LSTM模型提高了股票收益預測的準確率。王子玥等人[9]使用LSTM進行股票價格的預測,提出變步長集成方法及改進的MSE損失函數,預測上能取得較為可觀的提升,但未得出通用的最優步長范圍。Minh DL等人[10]提出了一種利用財經新聞和情感詞典預測股票價格走向的框架,將股票價格趨勢預測的雙流門控循環單元(TGRU)和在股票新聞和情緒詞典上訓練出Stock2Vec嵌入模型相結合。
不同于現有方法的是,文中提出了一種CStock量化選股模型,利用contextual long short-term memory (CLSTM)以及bi-directional long short-term memory(BiLSTM)結合股票相關的新聞信息和已知股價走勢信息,從而有效地對股票走勢進行預測。
CLSTM和BiLSTM模型起源于循環神經網絡[11](recurrent neural network,RNN)。RNN是一種節點定向連接成環的人工神經網絡,可以利用它內部的記憶來處理任意時序的輸入序列。傳統的RNN存在梯度消失和梯度爆炸問題,因此,Hochreiter等人提出了一種基于RNN的優化,即長短期記憶網絡(long short-term memory,LSTM),一種時間遞歸神經網絡,常被用于處理和預測時間序列中間隔和延遲相對較長的重要事件。
LSTM在傳統RNN的基礎上,通過添加門控,使其變成門控RNN,可以有效減少梯度消失(爆炸)等問題。LSTM循環網絡除了外部的RNN循環外,還具有內部的“LSTM細胞”循環。其門控包括輸入門、遺忘門和輸出門。LSTM網絡比傳統RNN更適合學習長期依賴,即可以減少梯度消失(爆炸)等問題。對于股票這類帶有很強時間序列特性的數據,選擇循環神經網絡可以更好地結合歷史信息。
BiLSTM則是將兩個不同方向的LSTM結合,形成雙向循環神經網絡,以同時提取數據的正、反向信息。而相較于LSTM,BiLSTM能同時利用兩個方向上的時序信息,更容易挖掘出潛在模式。CLSTM是Shalini Ghosh等人在2016年提出的一種基于話題的LSTM。在LSTM的基礎上,CLSTM考慮了不同的話題下,輸入門、輸出門、遺忘門的權重狀態。使得LSTM關注到話題之上,給LSTM一種指導。
1 選股模型
現有預測股票市場的模型主要是利用了股票市場中的交易數據。而影響股票市場波動的因素有很多,比如與股票相關的財經新聞或政治事件等,這些股票市場數據以外的信息都會影響到市場的波動。隨著文本挖掘技術[12]的出現,使得獲取相關文本數據來預測股票市場走勢成為現實。
文中運用了文本挖掘和深度學習的相關知識,結合嵌入式詞向量技術[13],采用Bi-LSTM雙向循環神經網絡、CLSTM和CNN卷積神經網絡對和股票有關的時序數據、文本數據進行分析,挖掘數據的深層次特征,構建選股模型。
文中對股票的數據分為數值型數據和文本型數據兩部分,各部分使用不同的網絡結構。其中數值型數據包括開盤價,最高價,最低價,收盤價,變化率。文本型數據包括股票名稱,股票相關新聞。
1.1 模型介紹
文中使用了一種BiLSTM和CLSTM相結合的模型,對股票走勢進行預測。將文本型數據作為CLSTM的Contextual信息輸入。同時,將數值型數據作為BiLSTM的輸入數據。
1.1.1 字符型數據
(1)新聞信息提取。
股票相關新聞信息描述了該上市公司的運營狀態。因為新聞信息與股票走勢存在較大相關性,人們常常根據新聞信息對股票走勢進行預測。為了對股票相關新聞信息進行編碼,對股票相關的新聞信息通過tf-idf[14]的方法,提取出相關關鍵詞集合K。使用Embedding的方法,將一個大小為n的集合K中的每一個詞wi映射為對應的詞向量wi。對于向量集合w,使用全連接神經網絡,對其信息進行提取。
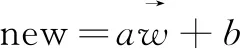
(1)
其中,a為每個詞向量的權重大小,a屬于Rn,b為偏置向量的權重大小,b屬于Rn,new為新聞信息提取結果向量。
(2)股票信息。
對每個股票進行Embedding,將其轉化成對應的股票向量S。對字符型數據通過Embedding的方法,使得其變為相應的詞向量vc。將生成的詞向量送入CLSTM,將股票名稱(Name)作為Topic,對股票新聞關鍵詞Keys進行處理,特別的,這里使用CLSTM的輸出矩陣作為輸出,得到相應的隱含層矩陣信息hc。
hc=CLSTM(Embedding(Name),Embedding(Keys))
(2)
將CLSTM的輸出矩陣作為卷積層Conv1D的輸入,然后使用最大池化層Maxpool1D對卷積結果進行池化操作。采用最大池化的方法提取特征值的最大特征來代替整個局部特征并大幅降低特征向量的維度。處理后得到特征向量ha。
1.1.2 數值型數據
文中對數值型數據x使用BiLSTM進行處理,使用BiLSTM輸出矩陣的最后一維作為其輸出,得到相應的隱含層信息hi。
1.1.3 全連接層
通過對數值型數據得到的輸出hi和字符型數據得到的輸出ha進行連接,通過全連接層進行計算,得到輸出fc。
fc=Concat(hi,fc)*Wfc+bfc
(3)
其中,Wfc為全連接層的權重矩陣,bfc為偏置向量。
1.1.4 Softmax分類器
通過對全連接層的數據進行分析,得到分類為股票上升的概率和股票下降的概率P:
P=Softmax(fc)
(4)
即,完成分類。
1.2 模型設計
網絡模型如圖1所示。該模型的輸入層包括數據信息和新聞信息兩大部分,模型的主體部分首先使用BiLSTM對數據信息方面的特征分別進行處理,將文本型數據作為CLSTM的Contextual信息輸入,而后將輸出矩陣結合CNN再次處理。最后使用多層全連接神經網絡對所有數據進行處理。
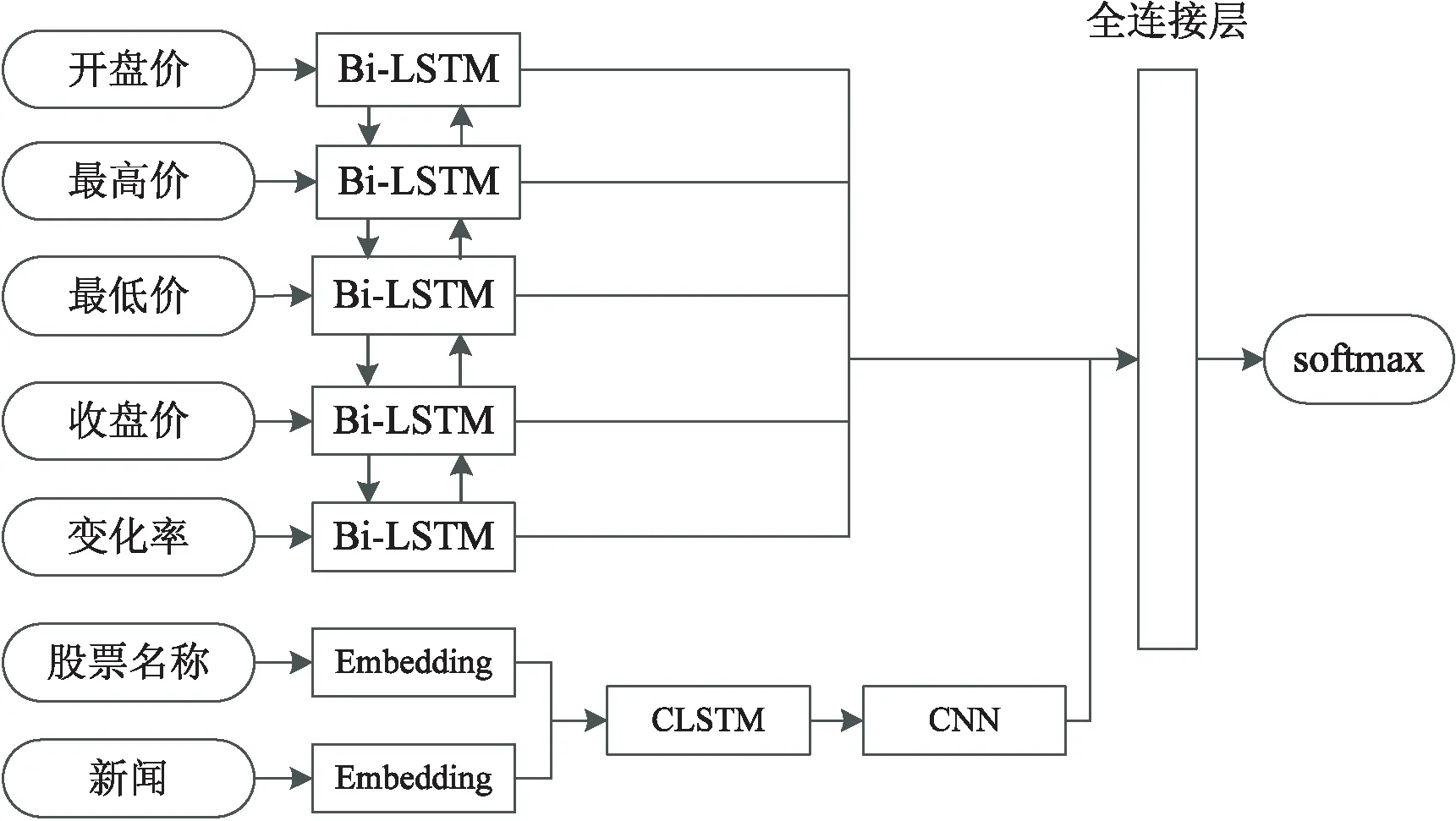
圖1 網絡模型
1.3 選股策略
通過神經網絡預測模型的輸出,可以得到每個股票上升的概率P。通過對P進行排序,選出最高概率的10只股票S1,S2,…,S10,通過對其概率進行求和。
(5)
然后按照如下公式進行選股,對每股的投入Inv(Si)如下:
Inv(Si)=P(Si)/Sum
(6)
則每次投資的收益率為:
(7)
其中,G(Si)表示Si股當天的實際價格變化率。
1.4 原型系統
文中設計的原型系統主要包括四層,首先是實時數據獲取層,接著是數據存儲層,接著是數據分析層,最后是輸出層。原型系統結構如圖2所示。
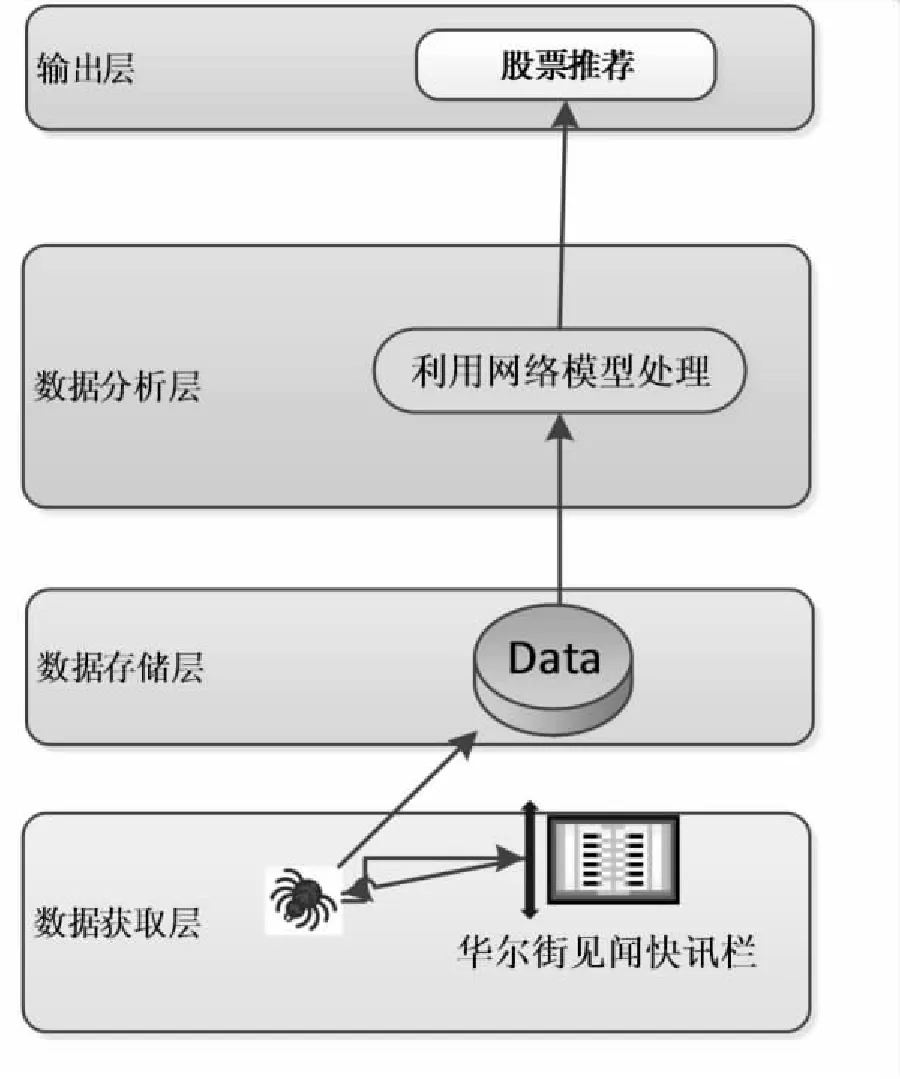
圖2 原型系統結構
1.4.1 數據獲取層
網絡爬蟲(web crawler),又稱為網絡蜘蛛(web spider)或web信息采集器,是一種按照一定規則,自動抓取或下載網絡信息的計算機程序或自動化腳本,是目前搜索引擎的重要組成部分。狹義上理解:利用標準的HTTP協議,根據網絡超鏈接(如https://www.baidu.com/)和web文檔檢索的方法(如深度優先)遍歷萬維網信息空間的軟件程序。功能上理解:確定待爬的URL隊列,獲取每個URL對應的網頁內容(如HTML/JSON),解析網頁內容,并存儲對應的數據。
網絡爬蟲按照系統架構和實現技術,大致可以分為以下幾種類型:通用網絡爬蟲(general purpose web crawler)、聚焦網絡爬蟲(focused web crawler)、增量式網絡爬蟲(incremental web crawler)、深層網絡爬蟲(deep web crawler)。實際的網絡爬蟲系統通常是幾種爬蟲技術相結合實現的。
通用網絡爬蟲:爬行對象從一些種子URL擴充到整個web,主要為門戶站點搜索引擎和大型web服務提供商采集數據。通用網絡爬蟲的爬取范圍和數量巨大,對于爬行速度和存儲空間要求較高,對于爬行頁面的順序要求較低,通常采用并行工作方式,有較強的應用價值。
聚焦網絡爬蟲,又稱為主題網絡爬蟲:是指選擇性地爬行那些與預先定義好的主題相關的頁面。和通用爬蟲相比,聚焦爬蟲只需要爬行與主題相關的頁面,極大地節省了硬件和網絡資源,保存的頁面也由于數量少而更新快,可以很好地滿足一些特定人群對特定領域信息的需求。
文中設計的原型系統為聚焦網絡爬蟲,對華爾街見聞快訊欄介紹的數據進行爬取。
1.4.2 數據存儲層
系統實時地通過網絡爬蟲將數據存儲到數據庫中,以便于模型對于數據的分析。同時經過一段時間對數據進行清理,防止數據庫出現內存不夠的情況。
1.4.3 數據分析層
實時地將數據輸入到已經訓練好的模型當中,本原型系統采用的是離線模型,將已經訓練好的模型直接用來分析數據。
1.4.4 輸出層
輸出模型最終分析的結果,對用戶進行展示,引導用戶選擇模型分析得出的最優股票。
2 實 驗
2.1 數據集
文中利用網絡爬蟲來獲取數據。爬取了華爾街見聞快訊欄目中2017年1月1日至2018年12月31日的新聞標題及相應的發布時間作為財經新聞的初始樣本數據,同時從Wind數據庫中獲取了2017年1月4日至2018年12月29日中交易日的交易數據,包括開盤價、最高價、最低價、交易量、漲跌幅。
實驗使用美股數據作為數據集合,取100,100,*分別作為測試集,驗證集,訓練集的大小,使用train-development-test模型進行訓練。
2.2 設 置
實驗運行在Ubuntu 16.04操作系統上,使用Tensorflow,Python3等工具,設定網絡BiLSTM和CLSTM的層數為2,隱含層大小為64(雙向128),使用交叉熵作為損失函數。
2.3 數據表示
文中使用了數值型數據和文本型數據,下面將分開討論:
2.3.1 數值型數據
文中使用的數值型數據包括每股每日的開盤價、最高價、最低價、收盤價和價格變動率,為了簡化模型,使用了近50天內的股票數據作為基礎數據,用于預測股票走勢。
2.3.2 文本型數據
文中希望對股票及其相應的新聞進行提取,從新聞中獲取股票可能的走勢信息,如國家政策支持可能導致股票上升等。由于每條新聞過長,因而采用了Tf-idf(term frequency-inverse document frequency),一種用于信息檢索與數據挖掘的常用加權技術,對每條新聞進行處理,提取出新聞相關的關鍵詞作為輸入。為了和數值型數據對齊,同樣采用了近50天內的新聞數據同時結合相應的股票注冊名信息作為輸入,用于預測股票走勢。
2.4 數據輸出
通過對上述數據進行訓練,預測該日股票的走勢。在嘗試了擬合股票走勢和分類股票走勢等方法之后,采用分類方法進行實驗,即對股票走勢進行二分類(上升/下降)來進行預測。實驗表明,將問題簡化為分類問題比擬合股票走勢準確率更高。
2.5 評 估
準確率:實驗在測試集上預測的準確率Acc(每股上升與否)為:
Acc=0.523 2
(8)
實驗采用上述選股策略對測試集進行回測,選擇連續的一百天,并除去回測當天數據小于100股的情況,進行測試,使用收益率作為衡量指標,其結果如圖3和圖4所示。
每日收益率:圖3表示每次投資可獲得的收益率和天數的關系,其中橫坐標表示天數,縱坐標表示收益率,點為每次投資的收益率,虛線為0坐標,其中收益大于0.00的天數為 Gdays,統計可得:
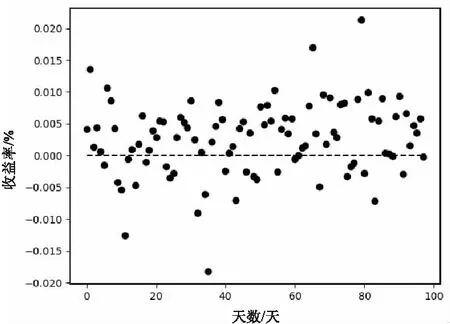
圖3 每日收益率
Gdays=0.704 1
(9)
結果表明每天收益大于0的實際概率接近0.704 1。
總收益率:圖4表示假設每天都采取模型給出的投資策略(這里忽略了手續費等支出),其收益和時間的關系,其中橫坐標表示天數,縱坐標表示相比于第0天的收益率,其中最高點的坐標為(98,0.284 9),即如果用此模型進行選股,那么在98天時,可以累計獲得相當于本金28.49%的收益。
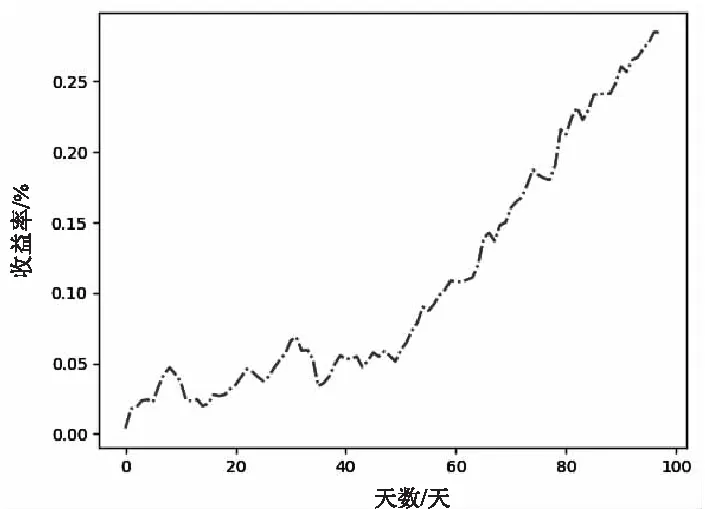
圖4 總收益率
3 結束語
文中提出了一種基于LSTM的神經網絡模型,用于預測股票走勢,同時給出了一種相應的選股策略。實驗表明,考慮了數值型數據(開盤價,最高價,最低價,收盤價,價格變動)和字符型數據(股票名,新聞關鍵詞)之后,可以獲得較為不錯的收益。雖然CStock對于股票走勢預測是可行的,但是現實生活中還有很多影響股市的因素沒有加入到實驗的特征值中,如:股民情緒。下一步可以通過抓取投資者在Twitter上的討論信息等的股評,利用NLP進行分析,這樣可能會得到更加精準的預測結果。在投資頻率方面,將本模型運用于實際中時,交易手續費問題不容忽視,需要對預測的模型進行輸出大小的修改,從而減少手續費的消耗。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
中華手工(2017年2期)2017-06-06 23:00:31
光學精密工程(2016年6期)2016-11-07 09:07:19
核科學與工程(2015年4期)2015-09-26 11:59:03
中外會展(2014年4期)2014-11-27 07:46:46
中學數學雜志(初中版)(2006年1期)2006-12-29 00:00:00
建筑創作(2001年3期)2001-08-22 18:48:14
祝您健康(1987年3期)1987-12-30 09:52:32
