基于分布式表示技術的推薦算法綜述
2020-11-18 09:14:20胡學林艾山吾買爾
計算機工程與應用 2020年22期
胡學林,艾山·吾買爾
新疆大學 軟件學院,烏魯木齊830008
1 引言
人類現實生活的需求推動著科學技術的發展進步。近年來,先進的電子元器件技術從學術研究到工業落地,發展迅速,通訊、存儲等互聯網關鍵基礎技術也在快速推進。最直接的結果就是數據總量大幅度增長。預計在2025 年,全球數據總量將從2018 年的33 ZB 增至175 ZB。中國數據總量增速最為迅速,平均每年的增長速度比全球快3%。2018 年,中國數據總量占全球的23.4%,即7.6 ZB,在2025 年將達到48.6 ZB,占全球的27.8%[1-2]。這些數據中蘊含著豐富的人類活動信息,巨大的潛在價值等待人們去挖掘。如何從這些豐富但又復雜的數據中提取出有用的信息成為一個關鍵難題,即如何應對“信息過載”問題。推薦系統就是從海量的數據中,挖掘出用戶感興趣的項目(如商品、電影、音樂等),并推送給用戶[3-7]。
推薦系統的核心是推薦算法。傳統推薦算法一般可以分為基于內容的推薦算法(Content-Based Filtering)[8]、協同過濾推薦算法(Collaborative Filtering)[9]和混合推薦算法(Hybrid Recommender)[10]等三類。基于內容的推薦算法是利用用戶歷史交互過的項目去搜索與此項目具有相似屬性的項目作為推薦結果。這類方法原理簡單,推薦結果比較直觀,具有很好的可解釋性,相比協同過濾,不需要應對數據稀疏[11]問題,但推薦的效果強依賴于高質量的特征提取,因此一個好的基于內容的推薦算法需要構建豐富且有效的特征工程。使用協同過濾方法的推薦系統將從大量用戶歷史行為數據中統計出來的概率作為統計特征,進行計算,得出結果。具體實現方法有矩陣因子分解[12]、奇異值分解[13]等,在其獲得良好成績的同時,也面臨著數據稀疏的問題,尤其是在當前大數據爆發的時代,一個用戶不可能和億萬級項目都存在交互行為,因而對應的交互信息矩陣(如評分矩陣)會十分稀疏,并且還存在冷啟動問題(一個新用戶或新項目在系統中沒有任務歷史數據)[14]。混合推薦系統為了緩解上述兩種方法中存在的數據稀疏和冷啟動的問題,通過融合多源異構的特征信息(如用戶評價、項目標簽等),組合不同的推薦算法進行項目推薦。但這些特征信息的數據結構不同,規模大小不等且分布不均勻[15],如何將這個多源異構的特征信息有效融合也是混合推薦算法要解決的一個問題。
部分研究人員將分布式表示技術引入到推薦系統中,將推薦系統中的項目視為自然語言處理中的單詞,用戶日志中的行為記錄視為語料,通過分布式表示技術將項目表示成融入了用戶行為特征信息的向量,再進行下一步的推薦工作。基于分布式表示技術的推薦算法可以很好地應對數據稀疏與冷啟動問題,且適用的推薦場景多樣。自2016年分布式表示技術首次被引入到推薦領域,基于分布式表示的推薦算法慢慢進入到研究人員的視野。因其可以直接對用戶行為建模,國內外各IT企業都紛紛嘗試引入了相關實現的推薦系統并部署于生產,領域涵蓋電子商務、社交網絡、知識推送、文化娛樂等多類服務,且具有良好的推薦效果。
2 傳統推薦算法
推薦系統最早在20世紀90年代提出,在文獻[16]中首次將推薦系統稱為“數字書架”。
推薦系統的任務對用戶給定的一個項目(音樂、電影等)進行“評分”或“偏好行為”預測,或者是從一個巨大的項目集合,將“評分”或“偏好行為”較高的子集作為推薦結果推送給用戶,因此推薦系統也可以看作是信息過濾系統的一個子集[5]。一個推薦系統中算法模型可以定義為如下:

式(1)中,y^uv為模型的預測結果,θ 為模型參數,u、v分別輸入的用戶(user)和項目(item)的信息,f 為模型參數映射到預測結果的函數。
傳統的推薦算法大致可以分為:基于內容的推薦算法,協同過濾的推薦算法以及混合推薦算法。
2.1 基于內容的推薦算法
基于內容的推薦算法是利用用戶歷史交互過的項目去搜索與此項目具有相似屬性的項目作為推薦結果,在進行推薦之前需要對用戶與項目進行特征信息的提取,構建出項目的特征信息與用戶畫像[6]。基于內容的推薦方法非常適用于用戶信息不足但項目內容豐富的場景,對于用戶可以不需要太多的信息,只需要用戶交互過項目,從這些項目中找出屬性相似或偏好程度較高的項目,并將這些交互項目與待觀測的項目進行特征比對,找出相似度較高的項目進行推薦。
該算法的主要優點是對于新項目無需應對冷啟動問題,不足之處在于對項目特征提取的依賴強,但目前數據信息多源異構,如圖像、視頻數據的特征構建成本高。基于內容的推薦方法在一定程度上會制約推薦結果的多樣性與新穎性[17],因為每次都從相同的項目中獲取推薦結果,最終計算出來的推薦項目基本上差不多,沒有太大變化。
2.2 協同過濾的推薦算法
協同過濾的推薦算法是通過用戶對項目的交互行為,尋找用戶或物品的近鄰集合進行推薦,是基于“過去同意的人將來也會同意,他們也會喜歡過去喜歡的類似項目”的假設[18],即用戶對之前項目的偏好行為,會影響到用戶對之后類似項目的行為。例如用戶對某首歌曲給出較高的評分,下次對類似歌曲也會不失一般性地給出較高的評分。協同過濾的方法主要分為基于內存的協同過濾方法[19-21]與基于模型的協同過濾方法[22-25]。
基于內存的方法使用用戶評分數據來計算用戶與用戶之間或項目與項目之間的相似度,在實際應用中可再細分為基于用戶的協同過濾方法[19]與基于項目的協同過濾方法[20]。基于模型的協同過濾方法使用不同的機器學習算法來構建模型,以預測用戶對未評分項目的評分。常見的協同過濾模型包括貝葉斯網絡[22]、聚類模型[23]、潛在語義模型(例如奇異值分解)[13]。
2.3 混合推薦算法
混合推薦算法是目前實際應用最多的推薦方法,將協同過濾、基于內容的過濾和其他方法結合在一起。根據各推薦算法混合時機的不同,混合推薦可以分為以下三類:
(1)分別進行基于內容的預測和基于協作的預測,然后將二者的預測結果再通過投票機制、線性組合等方式給出最終結果。
(2)將基于內容的功能添加到協同過濾的方法中或者將協同過濾的方法引入到基于內容的推薦方法中,即以一種推薦算法為基礎,另一種推薦算法融入其中成為其功能的一部分。
(3)將多種推薦算法融入到一個統一的模型中,不分先后地將各類數據輸入到統一的模型中,產生推薦結果。
混合推薦可以利用自身多算法集成的優勢,取長補短,有效地緩解冷啟動和數稀疏性問題。值得注意的是,隨著互聯網的普及以及社交媒體的快速發展,大量的用戶社交內容可以被獲取,這些內容豐富多樣,包括社會化關系、文本評論、標簽信息、位置信息、音頻、視頻等。許多學者從這些內容中提取可用的社會關系屬性信息作為輔助信息融入到推薦算法中,從而衍生了大量新的推薦算法,例如社交網絡推薦算法、知識感知的推薦算法[24-25]。
3 分布式表示技術理論
分布式表示技術(Distributed Representation)在自然語言處理中的一種具體實現就是詞嵌入。嵌入源自于數學領域中的一個專有名詞Embedding,在數學中,嵌入是指將一個對象X 映射到一個對象Y ,這樣一個映射過程就是嵌入。詞嵌入本質上遵循離散分布假說(Distributional Hypothesis)[26-28],在語言學的角度,分布式假說是從語義層面衍生出來,即一個詞的意思可以由該詞的上下文表示,因為語義相似的詞擁有相似的上下文。在自然語言處理中,詞嵌入就是將每個單詞嵌入到同一個語義向量空間中。其本質是數學中嵌入,因此可以將這些詞向量通過一系列的數學計算得出一些想要的結果,例如通過余弦相似度(Cosine Similarity)可以得出在這個向量空間語義最相似的單詞。
如圖1 所示,常用的詞向量訓練方法有連續詞袋模型(Continuous Bag-of-Words,CBOW)與跳詞模型(Skip-Gram)兩種,前者通過上下文去預測中心詞,后者通過中心詞去預測上下文[27-28]。本文主要以Skip-Gram為例,對分布表示技術理論進行闡述。
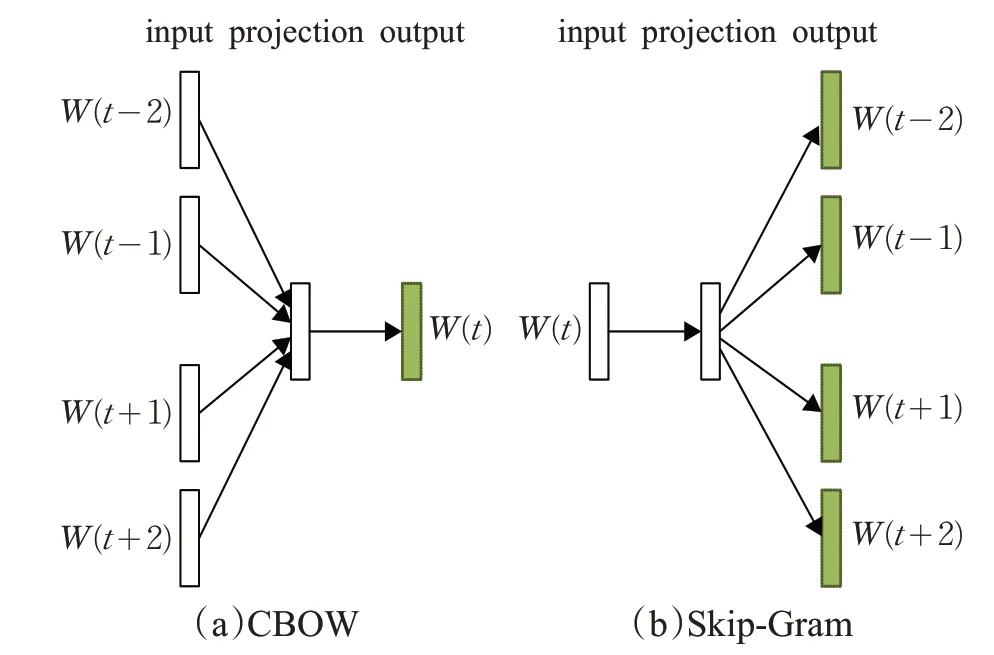
圖1 CBOW與Skip-Gram結構圖
Skip-Gram模型如下所示:
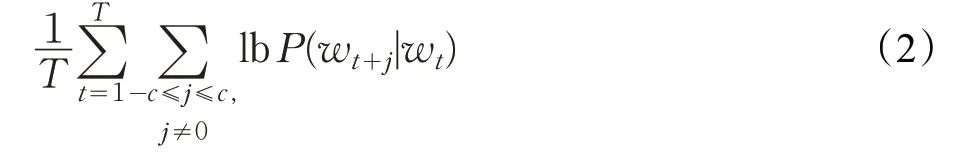
給定序列(w1,w2,…,wT),wi∈W,,Skip-Gram的目標就是最大化式(2)的概率。其中,c 為訓練時的上下文大小,wt是中心詞,P(wt+j|wt)表示wt出現的條件下wt+j出現的概率,即wt與wt+j的共現(Co-occurrences)概率。

式(3)使用Softmax 函數形式來定義標準的Skip-Gram概率公式P(wO|wI),|W|表示詞袋(Bag-of-Words)的大小,即單詞的總數量;v′表示輸出的向量,v 表示輸入向量。式(3)是理想情況下的概率,在現實中W 的數字太大(通常在105~107),直接以式(3)進行計算,運算成本高,因此會進行簡化。簡化的方式就是降低訓練過程中|W|的實際運算數量。常用的方法包括分層Softmax(Hierarchical Softmax)和負采樣方法(Negative Sampling)。
(1)分層Softmax
如圖2 所示,二叉樹中有||W 個葉節點,對應詞袋W 中所有的單詞。樹中任一單詞w,可以通過一條合適的路徑到達根節點root,令n(w,j)為從root 到單詞w 的路徑上的第j 個節點,L(w)為該路徑的長度,則n(w,1)=root,n(w,L(w))=w。

圖2 分層Softmax示意圖
對每個非葉節點,設ch(n)為n 的某個固定的子節點(可以固定為右子節點或左子節點),則分層Softmax可以將P(wO|wI)重新定義如下:
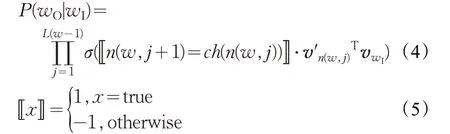
分層Softmax 的計算效率和二叉樹的結構緊密相關,會直接影響模型的訓練時間和準確率。文獻[26]采用的是霍夫曼樹(Binary Huffman Tree)[29],因為它將高頻詞分配在離root節點更近的地方,加快訓練的時間。
(2)負采樣
負采樣思想來源于噪聲對比估計(Noise Contrastive Estimation,NCE),即一個好的模型可以通過邏輯回歸的方式從噪聲數據(負樣例)中分辨出正確(正樣例)的數據[30]。基于這個思想,引出類似的負采樣方法,從而將式(3)簡化為:
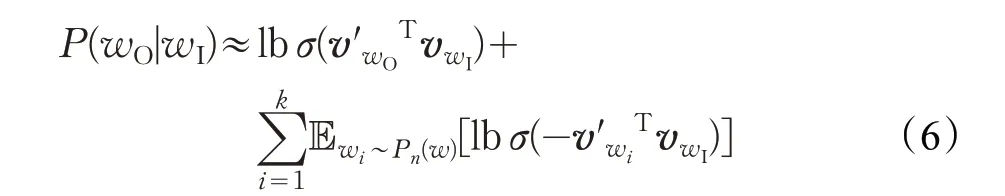
式(6)中,k 為負采樣的個數。Pn為噪音(noise)的分布。將被預測的詞稱為正例,被負采樣采集的詞稱為負例,如圖3所示。
圖3中,在標準的Skip-Gram算法中,單詞“進行”除了與被預測的正例單詞“各個”“分議題”“討論”和“交流”進行計算,還需要與單詞序列中其他所有的非正例單詞進行計算,在基于負采樣方法簡化的式中,只需要與負例單詞“與會”“學者”和“指出”進行計算。通過負采樣的方式,在模型訓練過程,極大地減少了計算以及權值更新的范圍,降低了模型整體的訓練時間。
4 基于分布式表示技術的推薦算法
所有基于分布式表示技術的推薦算法,基本思想都是一致的:將一個用戶的行為日志(如商品的瀏覽記錄、音樂的播放記錄、電影的觀看記錄、房源的預訂記錄等)視為一段自然的文本序列,采用自然語言處理中的詞嵌入方法,將這個序列中的項目(商品、音樂、電影、房源)映射成具有特定信息的空間向量,后續的推薦工作可以借用這些向量的空間相似性(如余弦相似性、歐氏距離等)進行推薦計算。
與自然語言處理又有所不同,在任何一種語系(如漢語、英語)中,單詞數量基本是固定不變的(詞袋數量、語義等多方面),但在某個具體的推薦領域中(如電商、音樂),項目的數量、參數(大小規格、顏色外觀等)以及用戶與項目之間的交互行為都可以變化。因此在基于原來的詞嵌入技術的基礎上,在推薦算法建模的過程中,各類算法會根據具體的業務實際做調整以達到最好的推薦效果。
4.1 一般分布式表示推薦算法
一般分布式表示推薦算法在原有的模型上并沒有做太多的改變,除了調整部分采樣參數。實驗證明基于分布式表示技術的語言模型可以應用于推薦系統中,主要有Item2vec[31]以及Prod2vec[32],以及將BERT[33-34]模型引入到推薦領域的BERT4Rec[35]。
(1)Item2vec
文獻[31]將基于負采樣的Skip-Gram模型(Skip-Gram with Negative Sampling,SGNS)應用在推薦系統中,分別將應用軟件商城中的購買記錄以及用戶音樂收聽記錄序列視作自然語言處理中的文本序列,對于出現在同一集合中項目視為正例,其他項目視為負例。不考慮物品序列生成的時間前后順序,靜態地將在同一集合中出現的項目視為相似的項目。
不修改模型結構的前提下,在訓練時要將項目序列的順序打亂,增加噪聲,也因此忽略了詳細的用戶行為序列;與自然語言處理中相比,在模型訓練參數的調整上,增大了式(5)負采樣的個數。Item2vec計算出的項目向量和SVD 算法得出的項目向量通過KNN 的聚類結果相比,同樣可用于項目的相似度比較,且Item2vec 的向量可以得出更好的聚類效果,說明相比傳統協同過濾的推薦算法,分布式表示算法可以學習得出更出色的表征向量。Item2vev算法的不足是:只簡單地利用了項目間的共現信息,因打亂了原始項目時序,從而忽略了用戶行為的序列信息。
(2)Prod2vec與Bagged-Prod2vec
文獻[32]提出Prod2vec 與Item2vec 的作法基本一致,只是數據集的類型有些差異。作者將視線轉移到電子郵件中的賬單收據和產品廣告中,通過用戶郵箱中帶有時間戳信息的郵件記錄來確定用戶行為序列。相比Item2vec,Prod2vec保留了原有的項目時序關系。
在Prod2vec算法中,假定用戶的一封郵件中的多個商品是相互獨立的,相當于一封郵件中只有一個商品。但是在實際場景中,用戶會同時購買多個商品,也就是說一封郵件的賬單收據是由多個商品記錄構成的,繼續使用Prod2vec無法應對這種情況。因此,在Prod2vec的基礎上提出了Bagged-Prod2vec算法。Bagged-Prod2vec將商品序列建模提升到對郵件序列建模。商品表示向量可通過優化以下目標函數公式得到:
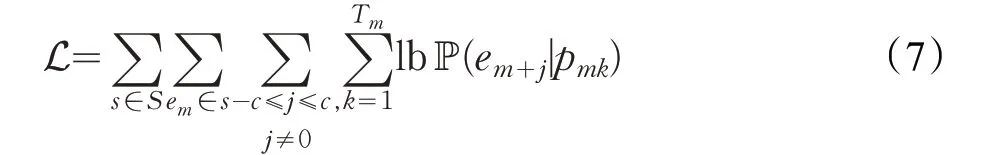
式(7)中,pmk表示第m 封郵件中接收到的第k 個產品;em+j表示第m+j 封郵件中所接收到的所有產品集合{pm+j,1,pm+j,2,…,pm+j,Tm} ,計算與第m 封郵件中第k個商品的上下文商品的概率為:

式(8)中,每個因子式都用式(9)形式計算,并采用負采樣的方法進行簡化。Bagged-Prod2vec算法根據實際的業務場景,對原有模型做了適當性的修改,讓屬于同一郵件的項目的表示向量在空間中距離更加接近,同時讓模型的復雜性變高,訓練時長也增加了。
(3)BERT4Rec

圖3 負采樣示意圖
單向序列預訓練模型是嚴格按照用戶行為發生的時間遞進順序從左到右進行訓練,Prod2vec就是單向序列訓練的。文獻[35]認為單向序列預訓練模型會限制用戶行為序列在用戶偏好捕捉工作上的發揮,采用雙向的項目向量預訓練可以更好地學習用戶的行為特征。于是將BERT首次引入到了推薦任務中,提出BERT4Rec模型:給定用戶集合U={u1,u2,…,u|U|} ,項目集合V={v1,v2,…,v|U|}以及用戶行為序列BERT4Rec 模型旨在預測用戶u 與項目vu+1進行交互的概率,可定義如下:

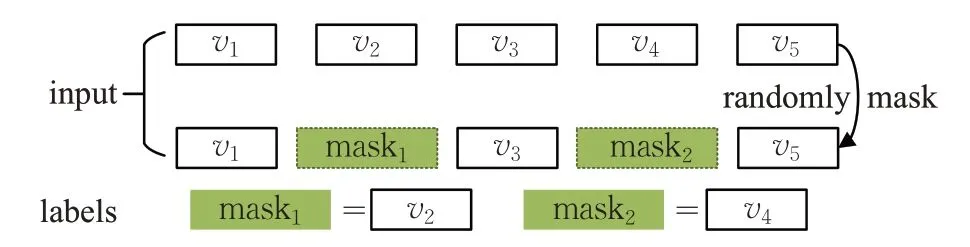
圖4 mask預測示意圖
對輸入序列,隨機將m 個項目進行掩蓋(mask),利用上下文項目去預測被掩蓋的項目的概率。最終定義目標損失函數:

式中,s′u表示用戶行為序列的masked版本;就是被隨機掩蓋的項目集合;是被掩蓋的項目;是真實的項目。BERT4Rec相比前面幾類算法,模型結構更加復雜,訓練成本更高,通過左右兼備地去預測被掩蓋的項目,訓練得出的項目表示向量在推薦過程中取得的效果更好。但因其模型過于復雜,所以不適用于線上的實時推薦。
4.2 引入全局上下文的分布式表示推薦算法
一般的分布式推薦算法并沒有考慮到下述實際應用場景:用戶出于某種目的,在瀏覽了一系列項目后,會將感興趣的某個項目收藏或是直接購買,比如為了購買一雙鞋子,通常會瀏覽許多相類似的產品,最終才會選擇想要購買的商品。因此,除了預測同一集合中各項目之間的共現概率,還可以從這個集合中取出或設立一個關鍵的全局上下文,這個全局上下文每次都會參與預測,通過提升全局上下文與各目標項目之間的相關性,更直接反映用戶行為特點。根據業務場景不同,引入不同全局上下文,并且在訓練過程中,讓目標的表示向量不斷地向全局上下文靠近,將二者在向量空間中的距離拉近,賦予目標表示向量新的潛在信息。引入全局上下文的分布式表示推薦算法有User2vec[32]以及Listing Embeddings[37]等方法。
(1)User2vec
文獻[32]提出的User2vec 模型是將用戶向量設置為全局上下文,可以同時學習用戶和物品的向量表示。結構如圖5所示。
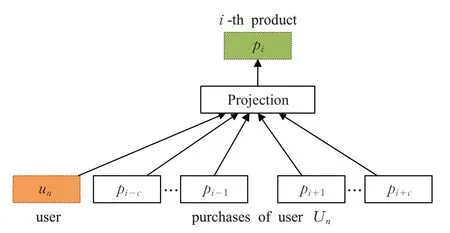
圖5 User2vec結構圖
如圖5所示,User2vec采用的是CBOW預訓練模型,訓練集同樣是用戶行為序列,序列由用戶un與其購買的商品序列(pn1,pn2,…,pnUn)組成。Un是用戶un購買的商品的數量。User2vec的目標損失函數可以定義如下:

式(12)中,c 表示第n 個用戶的行為序列的上下文大小。第n 個用戶在購買了第i-c 至i+c 個商品,再購買第i 個商品的概率以Softmax函數的形式定義如下:

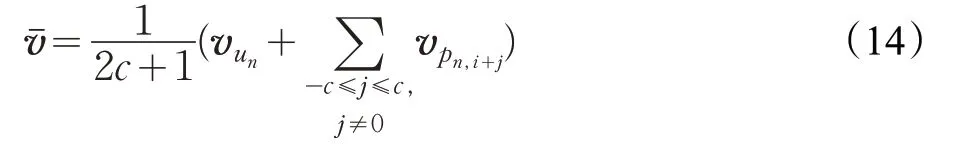
通過將用戶與項目同時嵌入到同一向量空間,從用戶的角度分析,用戶向量可以直接與項目向量進行相似度進行,從空間快速找出合適的項目進行推薦;從項目的角度分析,某個用戶行為序列中不同項目向量在訓練過程中會不斷與用戶向量靠近,讓學習得到的項目向量在空間中距離更接近。不足在于用戶行為多變,意味著用戶向量也要隨著變化,且重新計算的代價較高,不適用于線上實時推薦。
(2)Listing Embeddings
如圖6所示,不同于User2vec將用戶視為全局上下文,文獻[37]將用戶行為中最終預訂(或收藏)的項目作為全局上下文。根據具體的推薦業務場景特點對模型做出調整。應用的推薦領域是旅游房源的訂購推薦。
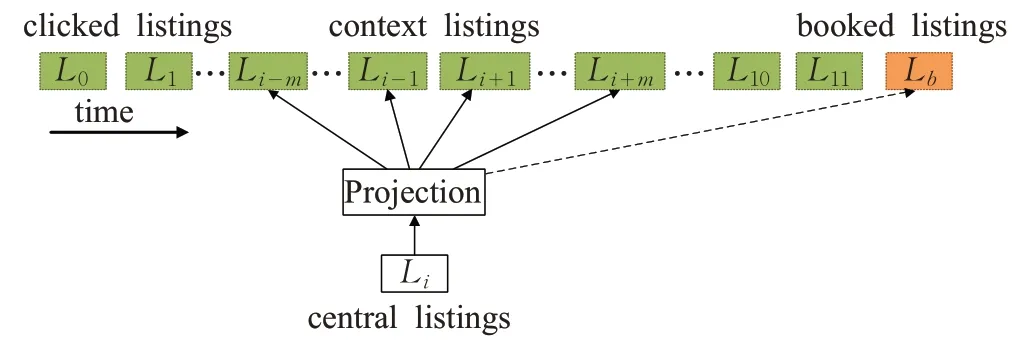
圖6 Listing Embeddings結構圖
根據業務場景的特殊性,一位游客從出發點前往目的地,一般情況下,他不會去瀏覽這兩個地點之外的旅館信息,因此在負采樣過程中,直接將目的地內的房源視為正例,非目的地的房源視為負例,不能完全反映實際,因為現實場景是非目的地的房源在一段用戶瀏覽的房源序列中,出現在序列的幾率不高。因此在負采樣的過程中,負例樣本也應該來源同一目的地。
最終的優化目標可以表示為:

Listing Embeddings在原來的語言模型上的改動并不大,更多地是貼合現實中的用戶消費場景,在訓練數據集上保留了真實的交互場景,訓練過程中,通過將用戶的最終預訂或收藏的項目視為全局上下文,讓用戶交互的項目向全局上下文靠攏,以此捕獲用戶潛在的偏好信息。模型的復雜性不高,且實驗效果貼近于生產實際,適用于線上的實時推薦。
4.3 引入元信息的分布式表示推薦算法
目前,在推薦系統中出現了一個新的項目,這個項目并沒有任何的交互行為,即遭遇了“冷啟動”問題。在這種情況下,引入元信息的分布式表示推薦算法考慮到不論是項目還是用戶,在推薦過程中,都具有各自的元信息,如用戶的年齡、職業、性別、收入情況等,在對用戶行為序列建模的同時,加入了用戶或項目的元信息。這樣不僅可以豐富表示向量包含的信息,還可以應對冷啟動問題。在用戶或項目無任何歷史記錄的前提下,可以將項目的元信息表示向量拼接成一個項目表示向量,去做相應的推薦工作。這類方法有Meta-Prod2vec[38]以及User-type & Listing-type Embeddings[37]。
(1)Meta-Prod2vec
針對下列問題:
①給定當前的訪問對象p(類屬于c),下一個訪問的對象p′,可能是同樣類屬于c。
②給定當前的類別c,下一個訪問的對象p,可能是同樣類屬于c,也可能類屬于相似類別c′,如:購買了泳衣,下一個購買的是防曬霜,二者完全不屬于同一類別,但很接近。
③給定當前的訪問對象項目p,下一個訪問對象的可能類屬于c,或相似類別c′。
④給定當前的類別c,被訪問的當前對象可能是p或p′。
文獻[38]提出了Meta-Prod2vec算法,在建模過程中將元信息也考慮進去,將商品和元信息共同嵌入到用戶興趣空間中,結構如圖7 所示。Meta-Prod2vec 算法對Prod2vec算法的損失函數進行了擴展:
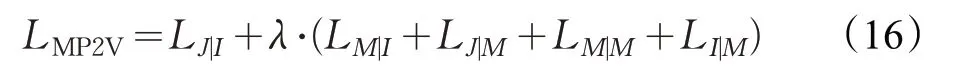
式(16)中,λ={λM|I,λJ|M,λM|M,λI|M}是正則化的超參數集合,LM|I、LJ|M、LM|M、LI|M是針對上述四種未考慮到的場景而引入的目標損失函數,都采用加權的交叉熵(Weighted Cross-Entropy)方式計算,加權就是指前面的超參數λ。
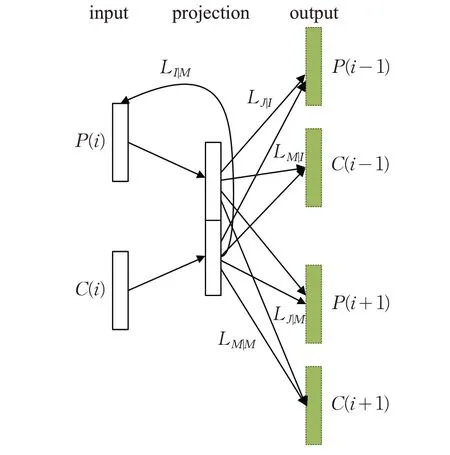
圖7 Meta-Prod2vec結構圖
LM|I:給定輸入商品I ,輸入商品I 的上下文商品元信息的條件概率與計算得出的商品元信息的條件概率的加權交叉熵。
LJ|M:給定輸入商品的元信息M ,輸入商品的上下文商品條件概率與計算出的上下文商品的條件概率的加權交叉熵。
LM|M:給定輸入商品的元信息M ,輸入商品的上下文商品元信息的條件概率與計算出的上下文商品元信息的條件概率的加權交叉熵。
LI|M:給定輸入商品的元信息M ,輸入的商品ids的條件概率與計算得出的商品ids 的條件概率的加權交叉熵。與上述三種損失不同,LI|M并不會去預測上下文,而是商品I 的元信息M 去預測商品本身I 。
對于式(16)中LJ|I的計算同樣采用基于負采用的Skip-Gram模型(SGNS)的方法:
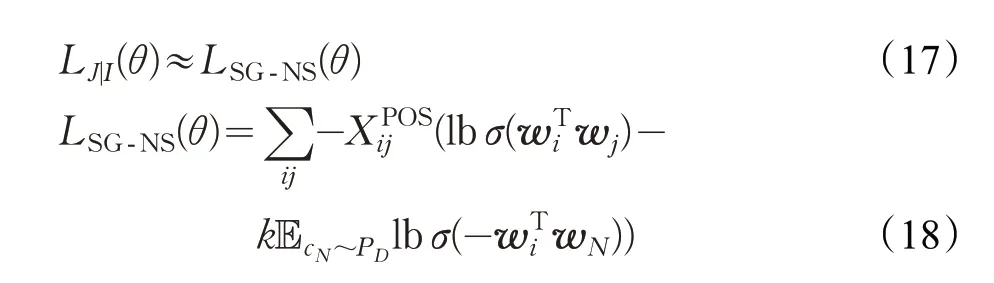
式(18)中,PD是負采樣中的負例樣本的概率分布,k 是負例樣本的個數。 LM|I、LJ|M、LM|M、LI|M的計算與LJ|I類似,采用同樣的公式。
Meta-Prod2vec 將項目的元信息作為輔助信息,與項目本身進行聯合訓練,在對用戶行為序列建模的同時,還考慮了項目自身的屬性特征,豐富了項目的表示向量。并且在訓練過程考慮到不同元信息的影響引入了不同的權重,實驗結果證明了不論在冷啟動還是一般的推薦場景下,Meta-Prod2vec 方法的效果都要比Prod2vec好,且適用于實時推薦。
(2)User-type & Listing-type Embeddings
文獻[37]認為,除了可以將項目的多個元信息分別做向量映射,如一間旅館有地區、價格區間、床位數量、洗手間數量等,對這些元信息進行映射,把一個項目的向量用其對應的數個元信息向量拼接而成。同理,用戶的向量也可以通過同樣的方式進行訓練得到,并且可以將二者嵌入到同一個向量空間中,共同應對冷啟動問題。這樣不管是新添加的項目,還是新注冊的用戶,都可以使用元信息拼接成的表示向量進行推薦。
4.4 圖嵌入推薦算法
上述分布式表示的推薦算法,所應對數據的結構都是一維的項目序列,當遇到社交網絡這一類以圖作為數據結構推薦場景[39]時,直接使用分布式表示方法顯然不行。此節所討論的圖嵌入推薦算法是將圖(如社交網絡)中節點映射成一個低維向量,采取的方法也是分布式嵌入方法。具體過程如圖8所示。

圖8 圖嵌入示意圖
圖(a)給定圖G=(V,E),V 是節點集合,表示數據對象,E 是邊集合,表示兩個數據對象之間的關系[39]。
圖(b)根據一定的規則遍歷圖中鄰接節點,生成節點序列。
圖(c)通過分布式嵌入方法將圖中的節點映射成一個低維的表示向量。
圖(d)中所有節點都會被嵌入到一個連續的多維空間中,在圖中關聯密切的節點在空間中距離也會更近。
常見的基于分布式表示技術的圖嵌入推薦算法有DeepWalk[40]、Node2vec[41]、LINE[42]、EGES[43]等。
(1)DeepWalk
DeepWalk 算法從社交網絡中某一節點出發,隨機游走較短的步數,生成節點序列。然后采用分布式嵌入算法將社交關系映射到一個連續的向量空間中,每個節點會有對應的低維向量,相應地,在社交網絡中相鄰的節點,在向量空間中的向量距離也比較近。文獻[40]對于隨機游走生成的項目序列是否可以使用Word2vec的方法進行訓練,給出了合理解釋。
如圖9 所示,(a)是YouTube 網站的社交網絡中,通過“隨機游走”方式生成的短序列中的頂點的冪等分布;(b)是維基百科中自然文本中單詞的冪等分布。隨著二者樣本數量逐步攀升,圖中二者的分布也驅向近似。圖中直觀地表明了通過隨機游走方式生成的序列符合自然文本的分布,可以直接使用分布式嵌入算法進行建模。
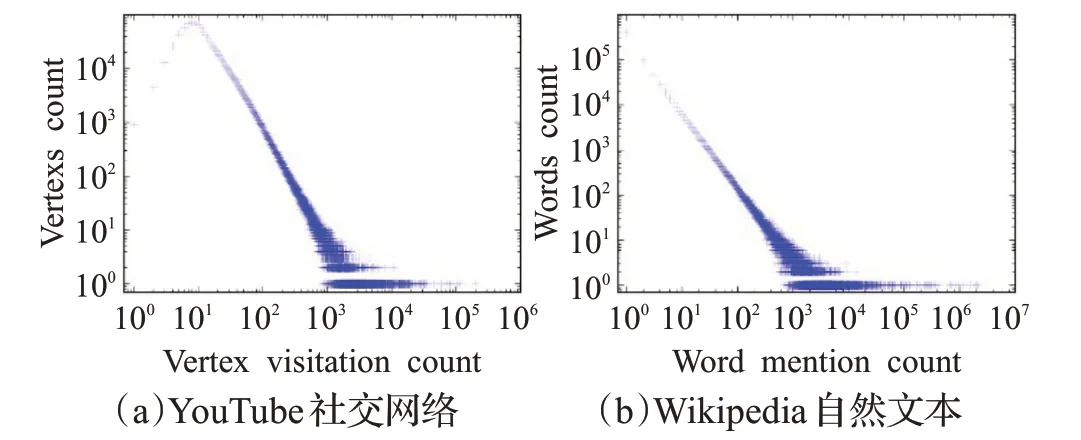
圖9 冪等分布圖
相比其他非分布式表示的圖節點向量表示的方法,DeepWalk 可以通過無監督的訓練方式,即在訓練時把節點表示向量與對應標簽的關聯切斷,得到更加通用的表示向量,可以避免錯誤的傳遞[44]。并且在訓練過程可以采用并行隨機游走的方式提高模型的整體運算效率。不足在于只是簡單地隨機生成序列,在此過程中并沒有關注生成的序列與圖中結構的相關性,即對于圖結構的采樣工作可以更加深入。
(2)LINE
圖10中,節點6與節點7是直連,稱為一階相關,但節點5 和節點6 并沒有直連,卻存在許多共同的鄰接節點,即節點5和節點6的鄰接網絡結構是相似的,稱為二階相關。DeepWalk 只關注了二階相關性,即目標節點與上下文之間的關聯,文獻[42]提出的LINE 在計算某個節點的表示向量時,還考慮了一階相關性。為此LINE中讓每個節點充當兩個角色,一個其是本身,另一個表示作為其他節點的上下文節點。
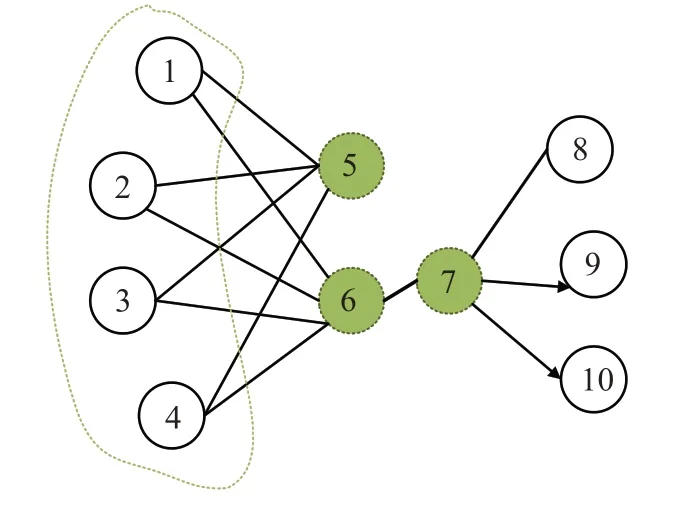
圖10 節點相關性示意圖
對任一邊e=(i,j),其一階相關度為:
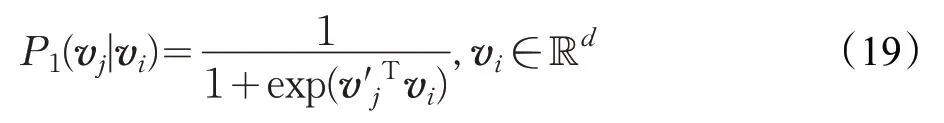
式(19)定義了條件分布P1(·|·)。而兩個節點的經驗分布為,為了保證一階相關性,條件概率可盡可能靠近經驗分布,因此目標函數是使二者距離接近,最終在LINE 中采用了KL散度來定量二者的距離:
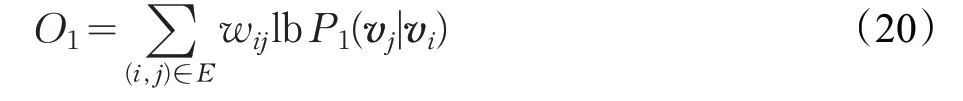
對任一邊e=(i,j),其二階相關度由節點vi生成節點vj的概率表示為:

其中|V|是上下文節點數量,對于任一節點,定義了條件分布P2(·|vi)。同樣為了保證二階相關性,條件概率可盡可能靠近經驗分布為兩節點之間的一階相關度(聯接權重)。通過最小化二者的KL散度,可以確定最終的優化目標函數:
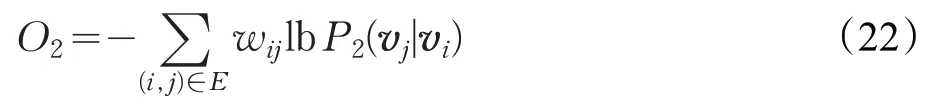
在優化目標函數的訓練過程中,可以得出節點的特征表示。
在時間效率上,一般的圖嵌入算法[45-48]的運算時間至少是O(| V|2),|V|2為節點個數。LINE的時間復雜度為O(dK|E|),d 為向量的維度,K 為序列中負采樣的個數,| E|為圖中合法的邊數,當圖中的節點數量越大,LINE 算法的時間效率優勢更加明顯。相比DeepWalk,在圖的整體關聯度,LINE考慮得更全面,獲得的表示向量包含的信息更豐富,且適用于各種圖結構。
(3)Node2vec
文獻[41]將圖視為一個文檔,節點就是里面的文字,如何生成能夠反映圖結構的文本序列是至關重要的,如圖8(a)所示,采用DFS方式生成的序列,可以反映子圖的同構性[49],而采用BFS 方式生成的序列,可以反映子圖的同質性[50-51],兩種方式生成的節點序列都可以蘊含圖的結構信息。Node2vec 中提出一種啟發式游走方法,在游走過程中引入兩個參數p 和q,來控制游走的方向,同時兼顧兩種方式,以獲得更佳的節點序列。
如圖11 所示,從節點t(起始節點)走到了節點,現在要決定下一個節點的走向。為每個節點分配一個游走概率πvx=αpq(t,x)·wvx,wvx是節點間的權重。
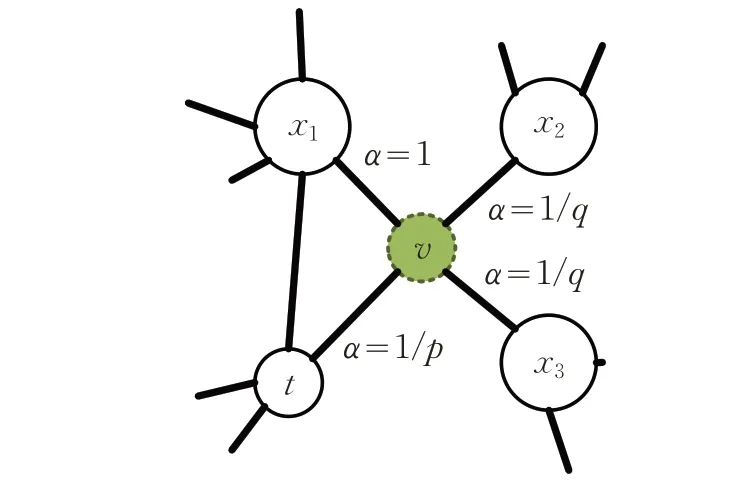
圖11 啟發示游走示意圖
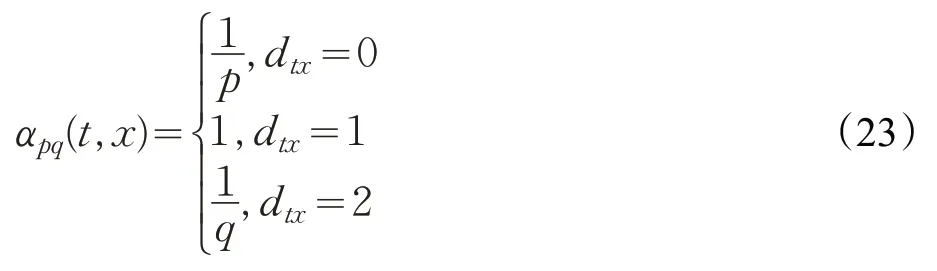
其中,dtx表示節點t 到節點x 的最短路徑,且值域僅為{0,1,2}。如 圖11 中,dtx1=1 ,dtx2=dtx3=2 ,而dtv=0,因其已被訪問過了。
對于返回參數p,控制游走是否回退,取p >max(q,1),可以確保游走到一個未訪問過節點,取p <max(q,1),則會游走回退;對于出-入參數q,當q >1 時,下一次游走會選擇離t 更近的節點,讓游走方式近似BFS,當q <1 時,下一次游走會選擇離t 更遠,游走更近似DFS。當q 值變化,游走的方式也會跟著變化,當q=1,p=1 時,Node2vec退化成DeepWalk。
Node2vec 借用游走參數控制序列的生成順序,相比單一使用DFS 或者BFS 進行序列生成,Node2vec 可以保留更豐富的節點鄰域信息。在訓練過程中可以通過手工設置p 和q 兩個參數來調整模式的關注點,相比DeepWalk 和LINE 提高了自身的靈活度以及在不同推薦場景的適應性。例如在社交網絡的場景下,更強調子圖的同質性,可以調大q 值;在文本引用的場景,更強調子圖的同構性,可以調小q 值。
(4)GES與EGES
在圖嵌入算法中,如果在圖中新增了一個節點,此節點沒有任何的交互記錄,該如何應對呢?為此文獻[43]在DeepWalk 的基礎上,提出了GES(Graph Embedding with Side Information)模型。在模型中引入了項目的元信息作為輔助信息,對于一個新項目,可以通過項目的元信息獲得對應的表示向量,以應對冷啟動問題。在給定W 為項目或輔助信息的向量矩陣,表示項目v的表示向量,表示項目v 第s 類輔助信息的表示向量,則一個擁有n 類輔助信息的項目v 由n+1 個向量構成,對項目v 的最終表示向量為:

式(24)中就是把項目本身的表示向量與它的元信息表示向量取均值。這樣,對一個不存在任務交互行為的新項目,可以根據它的部分輔助信息確定其表示向量。如圖12 所示,對于一個新項目,可以從含有相同元信息(如類型、品牌、商家)的類似項目中借用它們的元信息向量用作自己的表示向量。

圖12 項目冷啟動示意圖
EGES(Enhanced Graph Embedding with Side Information)考慮到GES對于所有輔助信息都是統一對待,但實際是同一項目的不同輔助信息在不同的用戶行為上下文中,所占的權重應該是不同的。比如在現實中,用戶A買了一部蘋果手機,會根據蘋果這個品牌去瀏覽蘋果筆記本或平板電腦,對于另外同樣買了一部蘋果手機的用戶B,他會因為價格問題選擇瀏覽價位更低的其他品牌的筆記本或平板,用戶A 的行為,受品牌這一個元信息的影響多一些,用戶B 的行為,受價格這一元信息的影響多一些。因此EGES 為不同的輔助信息分配不同的權重,表示第v 個項目的第s 類輔助信息的權重,一個項目的表示向量為:

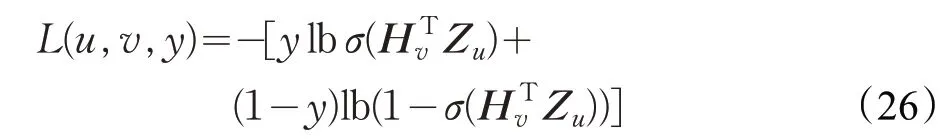
相比其他的圖嵌入方法,GES和EGES使用項目的元信息作為輔助信息除了可以應對冷啟動問題,在訓練過程還保留了用戶行為的潛在信息,并考慮到實際用戶消費場景,做了權重調整,可以全面地學習到不同用戶的行為信息。
5 基于分布式表示的推薦算法的總結與展望
第4 章詳細介紹了幾類經典的分布式表示算法的原理及其可以應對的實際場景,本章將通過以下三個問題對基于分布式表示的推薦算法進行總結。
5.1 分布式表示推薦算法在推薦領域的主要現存問題上的表現
在推薦領域中,一直存在著數據總量大、數據稀疏、冷啟動等關鍵問題。如表1所示,文中提及的算法采用的數據集量較大且都存在著嚴重的數據稀疏問題,部分算法所采用的數據集考慮到用戶信息安全隱去了用戶的信息。面對數據總量大、數據稀疏問題,文中描述的各類算法都取得了不錯的效果,面對數據量不大的圖結構(如PPI數據集),分布式表示推薦算法同樣可以應用。
為了應對冷啟動問題,分布式表示推薦算法將項目或用戶的元信息作為輔助信息,借用元信息的表示向量去生成一個新項目的表示向量,進行推薦計算,可以有效應對冷啟動問題。與傳統的基于內容的推薦算法相比,二者都可以應對冷啟動問題,前者的優勢在于元信息的表示向量在學習過程中融入了用戶的行為信息,適合于實時的推薦場景。
5.2 與傳統推薦算法相比的優勢
協同過濾的推薦方法也可以看作是類嵌入方法,通過矩陣分解技術將原來用戶和項目的交互矩陣,分解成用戶特征矩陣和項目特征矩陣兩個矩陣,最終將用戶和項目嵌入到低維空間中,通過用戶特征向量和項目特征向量的內積來計算用戶對項目的偏好,亦或是通過向量間的相似度來排序得出推薦列表。基于分布式技術推薦算法是通過淺層的神經網絡訓練,將同一行為序列中的項目嵌入到一個低維連續的向量空間,也可以同時將用戶和項目嵌入到空間中得出表示向量,再進行后續的推薦工作。
后者在功能上的優勢在于,不僅關注了用戶對項目的正向交互行為(如點擊、瀏覽、收藏、評分等),同時對用戶的負向行為(如拒絕、不喜歡等)也進行了學習,體現在向量空間中就是:負向的交互項目與正向的交互項目在空間距離上的相互遠離。可以有效地避免了為用戶重復推薦之前不喜歡的項目,這是傳統的協同過濾方法沒有關注的。
協同過濾另一個缺陷是不適應數據快速更新的推薦領域,如新聞推薦等,因新聞總是在快速更新,傳統的協同過濾無法對新數據產生足夠快的響應,導致其不適用于線上的實時推薦[52]。相比之下,后者可以學習用戶行為發生的時序關系,在訓練時,使同一時刻內的若干交互項目的空間距離接近,時序間隔大的項目空間距離疏遠,讓項目的表示向量包含了用戶潛在的行為時序信息,可以快速對用戶的新行為做出響應,適用于當前實時變化的推薦場景[32,37-38],這不僅存在于新聞推薦方面,在電商、短視頻推薦等用戶交互頻繁的場景更是如此。
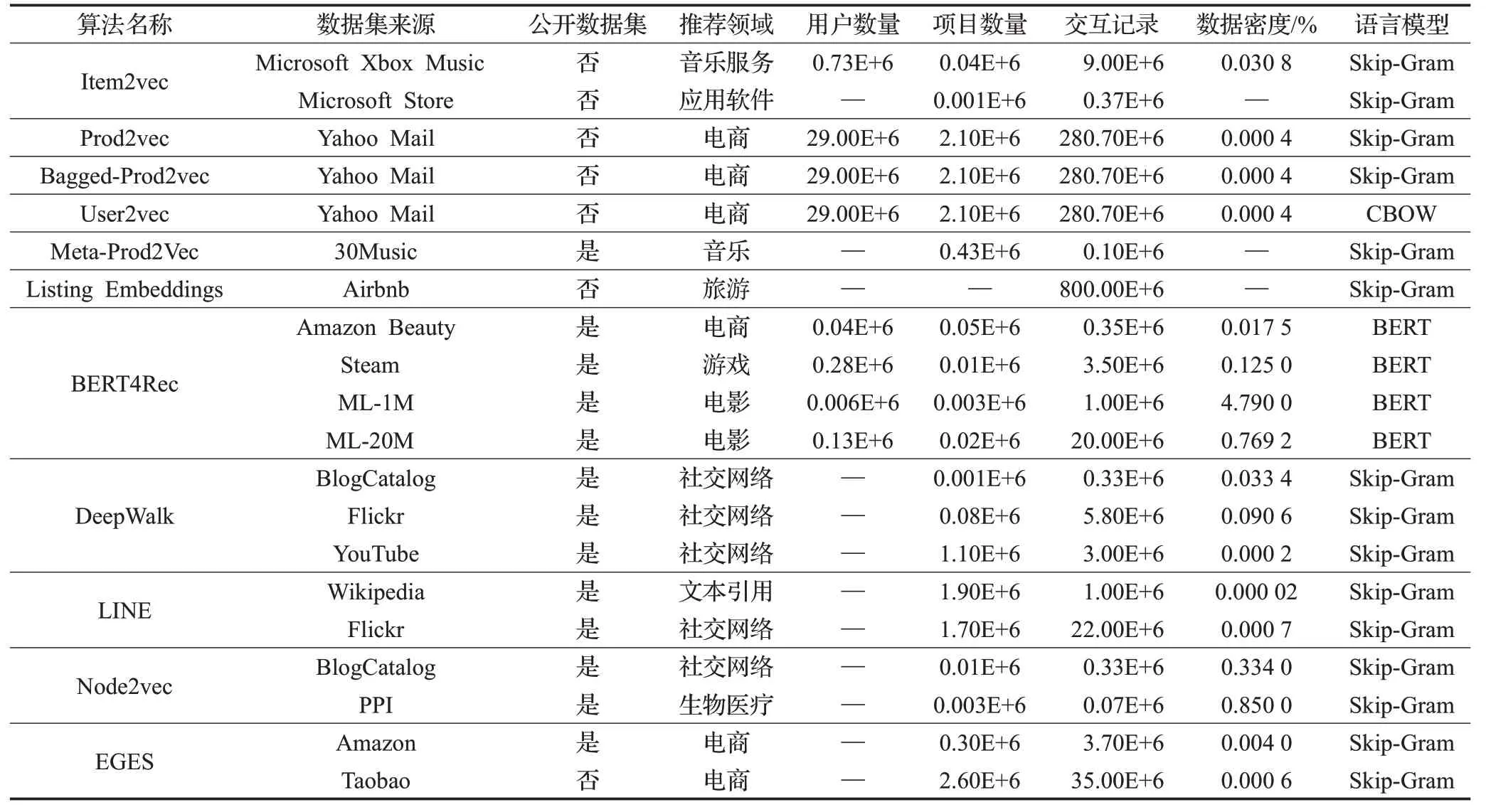
表1 算法數據集及應用場景
傳統的基于內容的推薦算法,一個核心特點是可以緩解冷啟動問題,一個新項目根據它的屬性信息也可以參與推薦,具有很好的可解釋性,但依賴于前期高效的特征工程。引入元信息的分布式表示推薦算法可以在對用戶行為序列建模的時候,將項目或用戶的元信息也融入其中,這種方式不需要對現有的語言模型做太多的修改,在有效應對冷啟動問題的同時還在元信息的層面學習用戶的行為信息。在實際的電商場景中,用戶購買了智能手機后,接著感興趣的商品卻不再是手機,而是手機的相關配件,比如手機殼、貼膜等。一般的基于內容的推薦算法不能學習這種用戶行為,下次推薦的更大概率還是帶有相同標簽的手機,但后者可以應對這種不同類型變換的交互場景,如文獻[43]所描述,還可以通過權重來擬合用戶的行為方式,得出更佳的推薦效果。
應對推薦領域中圖結構的信息處理,分布式表示技術也有著不錯的表現,相比其他的圖節點表示算法,基于分布式表示技術的圖嵌入算法在時間效率上得到了提升,這對于當下數據大幅增長的環境是很重要的。隨著圖節點的不斷增加,其他圖算法的時間復雜度是指數級上漲,圖嵌入算法只是線性提升,這極大地縮短了模型的計算時間。在不同的應用場景下,圖嵌入方法靈活調整自身的表示向量內容,可以應對常規圖算法無法解決的冷啟動問題,在推薦效果上也比其他算法要好[41-43]。
5.3 分布式表示算法的下一步發展
分布式表示算法得出更好的推薦結果,證明了基于分布式表示的推薦算法在推薦領域中的有效性和先進性。對于基于分布式表示的推薦算法還有以下幾個方向值得探討研究:
(1)算法在不同場景下的適應性調整。從上述幾種算法中都可以看出,起始只是純粹地將詞向量方法引入到推薦系統中,沒有做改動,到后來,研究人員會根據實際的業務場景,以及推薦的具體領域做出相應的調整,不僅在靜態的歷史數據中取得了較高的準確率,推薦廠商將相關推薦系統部署到生產,對每日實時更新的數據進行線上評測,線上的效果甚至比線下的效果更好。目前,在一些文娛休閑、電商消費推薦領域,已經有了較為深入的研究工作,但是在金融保險、車輛銷售等推薦周期更長的領域可以繼續開展工作。
(2)與其他深度學習方法結合。隨著深度學習在圖形圖像、語音、文本處理等多領域均取得長足的進展,許多研究人員也將深度學習引入推薦系統中,以期提高系統各項性能并解決存在的問題。基于分布式表示技術本身也是一種深度學習方法,用于對用戶行為序列進行建模,得出項目的隱表示。后期工作可以探索與更多的深度學習模型結合,達到更好的推薦效果。
(3)新的推薦系統架構。目前許多從事自然語言處理工作的科研單位都開源自身在詞向量預訓練實驗中得出的詞向量結果,其涵蓋世界上各類語種,可以提供給其他科研單位或個人進行后續的科學研究或工程實現。但是在推薦系統中,不同推薦領域的項目表示向量多有不同,且部分向量可能還包含了用戶的隱私信息,因此要像詞向量那樣直接公開存在多方面挑戰。目前正在興起的數據聯邦[53-55]等技術平臺支持,讓其變得有可能,為應對系統啟動以及跨域推薦提供了思路。如在電商領域,可以將部分商品經過預訓練得到表示向量,對于新上線的同類型的推薦系統,可以直接采用這個向量對用戶進行推薦,從而有效應對了系統冷啟動問題。
6 結束語
推薦系統是解決信息過載問題的有效工具,核心在于所采用的推薦算法,而一個推薦算法的核心就是正確地捕捉到用戶興趣。高效的推薦算法能夠幫助用戶節約信息檢索時間,提供更好的用戶體驗,增強用戶的“黏性”。傳統的推薦算法在當前數千萬乃至數億用戶量的場景下的推薦效果相形見拙。本文所綜述的基于分布式表示技術的推薦算法,通過對用戶的行為序列建模,將項目映射到用戶潛在的興趣空間中,得出項目的表征向量,再進行后續的推薦工作,取得很好的效果。本文對主要幾種推薦算法進行比較總結,對基于分布式表示技術的推薦算法的發展進行展望,為后續相關研究工作提供參考。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
中華手工(2017年2期)2017-06-06 23:00:31
商用汽車(2016年11期)2016-12-19 01:20:16
光學精密工程(2016年6期)2016-11-07 09:07:19
商用汽車(2016年6期)2016-06-29 09:18:54
商用汽車(2016年4期)2016-05-09 01:23:12
創業家(2015年5期)2015-02-27 07:53:25
中外會展(2014年4期)2014-11-27 07:46:46
