基于關聯規則算法的推薦方法研究綜述
2020-11-18 09:14:24紀文璐王海龍蘇貴斌
計算機工程與應用 2020年22期
紀文璐,王海龍,蘇貴斌,柳 林
1.內蒙古師范大學 計算機科學技術學院,呼和浩特010020
2.內蒙古師范大學 教務處,呼和浩特010020
1 引言
伴隨互聯網、云計算、大數據以及移動技術的迅猛發展,其產生的數據已呈現爆炸式增長[1]。由于數據規模龐大、繁瑣,重疊信息過多等問題,導致用戶對數據利用率不高,無法準確提取有價值的數據。因此,從繁雜的數據海洋中捕獲有效數據,為用戶提供高質量信息,成為推薦系統領域的研究目標[2]。例如大型電子商務平臺亞馬遜的個性化產品推薦、潘多拉播放器的音樂推薦、Facebook社交網絡的好友推薦以及YouTube網站的視頻推薦等著名的推薦系統以及其他各類個性化領域[3],它們從各自擅長的角度提供不同領域的內容推薦,運營商在獲得可觀的利潤的同時也為廣大用戶提供便利。開心的時候適合聽什么樣的歌曲,剛有寶寶的父母喜歡什么商品的可能性更大等一系列問題的解決,都使得被推薦用戶得到更好的體驗[4]。由此可見,推薦系統已經成為現代化社會一種極其有效解決用戶需求的方式[5]。推薦系統的本質是從一堆毫無條理的原始數據中,通過提取用戶數據的特征屬性、興趣愛好,和對用戶的偏好挖掘來進行相似的信息推送,從而完成構建。推薦系統是以推薦算法為核心,融合各類模型以及通過建立用戶與項目之間的數學二元組關系,并利用存在的相似性來判斷并分析數據,進而挖掘每個用戶潛在的感興趣物品。不僅可以讓用戶在繁雜的內容中發現所中意的信息,也會將興趣度高的信息展現給用戶,同時應用各式推薦方法[6-8],達到優質推薦的目的。
推薦系統的概念最早在1992 年的郵件過濾系統[9]中被提出,目的是為了解決郵件過載問題。文中首次使用了協同過濾的概念,之后被廣泛引用,它通過用戶使用的歷史記錄以及各物品之間的相似程度,進而深入挖掘用戶潛在的感興趣物品[10]。推薦系統的主要構成內容包括用戶、物品和推薦算法,其中推薦算法的高效性、魯棒性都決定著推薦系統性能的優劣[11]。傳統的推薦算法一般可以分為三大類,即基于內容的推薦算法[12]、協同過濾推薦算法[13]以及混合推薦算法[14]。
由于傳統推薦算法中未能考慮到物品與物品之間的深層關系,IBM 公司于1993 年首次提出了關聯規則模型后,Manchanda等人[15]緊接著于1999年在實際的商業交易數據應用中指出,消費者在多選項場景下,一個共同主線上所供選擇的項目之間可能以某種特殊的關系進行關聯,即用戶會在不同情況下做出不同選擇。例如在購物時,一個類別選擇的結果會影響到另一個類別,因為這兩者之間可能使用關系互補(如面粉和酵母),也可能因為購買周期相似(如啤酒和尿布),或者更多無法被容易發現的深層規則。因此在實際應用中,研究人員將關聯規則技術運用到推薦算法中來提高推薦性能,從而彌補傳統推薦算法的不足[16]。
通過歸納總結一些學者在推薦算法中使用關聯規則技術的研究結果,分別從不同角度來分析和解決傳統推薦算法在推薦過程中存在的各類問題。例如緩解基于內容推薦中的冷啟動問題,消除協同過濾推薦中的數據稀疏問題以及擴展當下熱門的社交網絡推薦中用戶友好匹配的問題,進而從介紹、分析、實驗的角度將關聯規則技術引入到各類模型中去解決問題,并在研究過程中指出其優缺點、研究結果以及未來的研究熱點方向。
2 傳統推薦算法概述
自協同過濾(Collaborative Filtering,CF)算法被提出之后,推薦系統就成為一類新興的、有較高實用價值和關注度的學科被廣大學者進行深入研究。推薦系統的核心就是推薦算法,傳統的推薦算法主要由三類組成,協同過濾算法、基于內容的推薦算法以及混合推薦算法。
2.1 協同過濾推薦算法
協同過濾推薦算法的核心思想就是充分利用與目標用戶興趣偏好相同的用戶群體喜好來進行高精度推薦。其中協同過濾推薦算法主要有兩種形式,分別是基于用戶[17]的推薦和基于項目[18]的推薦,推薦方式如圖1、圖2 所示,兩者當中基于用戶的推薦出現較早,但二者的推薦原理基本相同。基于用戶推薦的基本原理就是通過提取所有用戶在使用過程中產生的歷史數據特征值,去發現他們對某一種或多種項目的偏好程度,然后經由算法對數據進行相似度處理,最后根據鄰居用戶數據組的歷史偏好信息向目標用戶進行高效且精確的推薦[19]。基于項目的推薦則是將基于用戶推薦中用戶之間的相似度計算變成了項目之間的相似度計算,據此來獲得相應的預測結果,并將排名結果較好的項目信息反饋給用戶,從而獲取高質量推薦。由于協同過濾主要是根據用戶的歷史行為數據發掘偏好,因此它在推薦過程中產生的優缺點也非常明顯,詳見表1。為解決數據稀疏等問題[20],廣大學者通過研究用戶矩陣對其進行改進[21],以緩解由于數據稀疏導致的推薦效果不佳等問題。
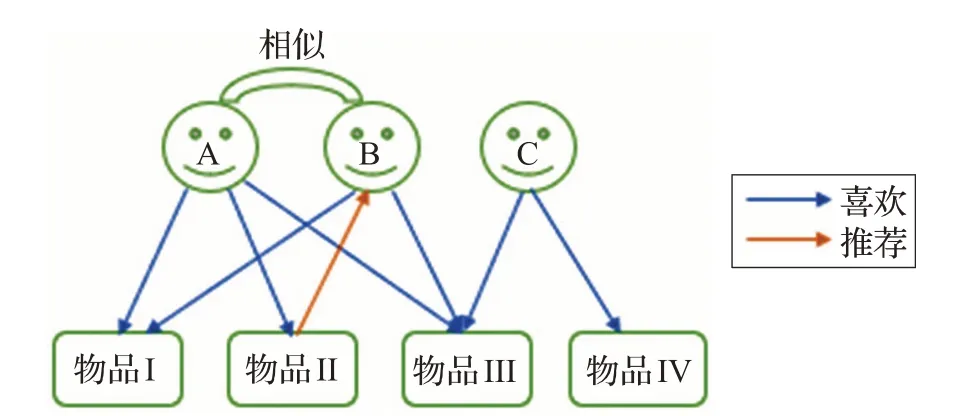
圖1 基于用戶相似的推薦
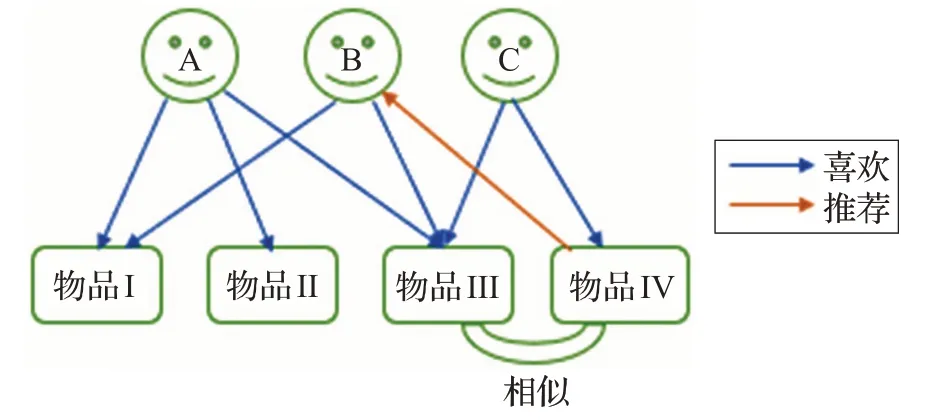
圖2 基于項目相似的推薦
2.2 基于內容的推薦算法
基于內容的推薦是一種極其經典且重要的推薦方法,應用較為廣泛[22],其原理就是通過對比目標用戶的中意項目元數據,根據內容相似程度為目標用戶產生新的推薦。例如常見購物網站的“猜你喜歡”功能,便是使用基于內容的推薦算法來為大家推薦感興趣的商品。在電子商務模式下,推薦系統會根據目標用戶的興趣喜好來對商品的特征進行提取,構建一個用戶興趣特征向量,之后根據提取的特征值對商品進行比對,從而為目標用戶推薦優質商品。雖然基于內容的推薦原理簡單,但與協同過濾相比,新項目“冷啟動”[23]和“數據稀疏”[24]問題的緩解是其重要優勢。另外一個優勢就是用戶間的獨立性。因為每個用戶的興趣描述模型僅僅基于該用戶本身的經歷,所以用戶之間不會相互影響[25],但同時也存在新用戶的冷啟動以及無法處理其他類型數據等問題,詳見表1。
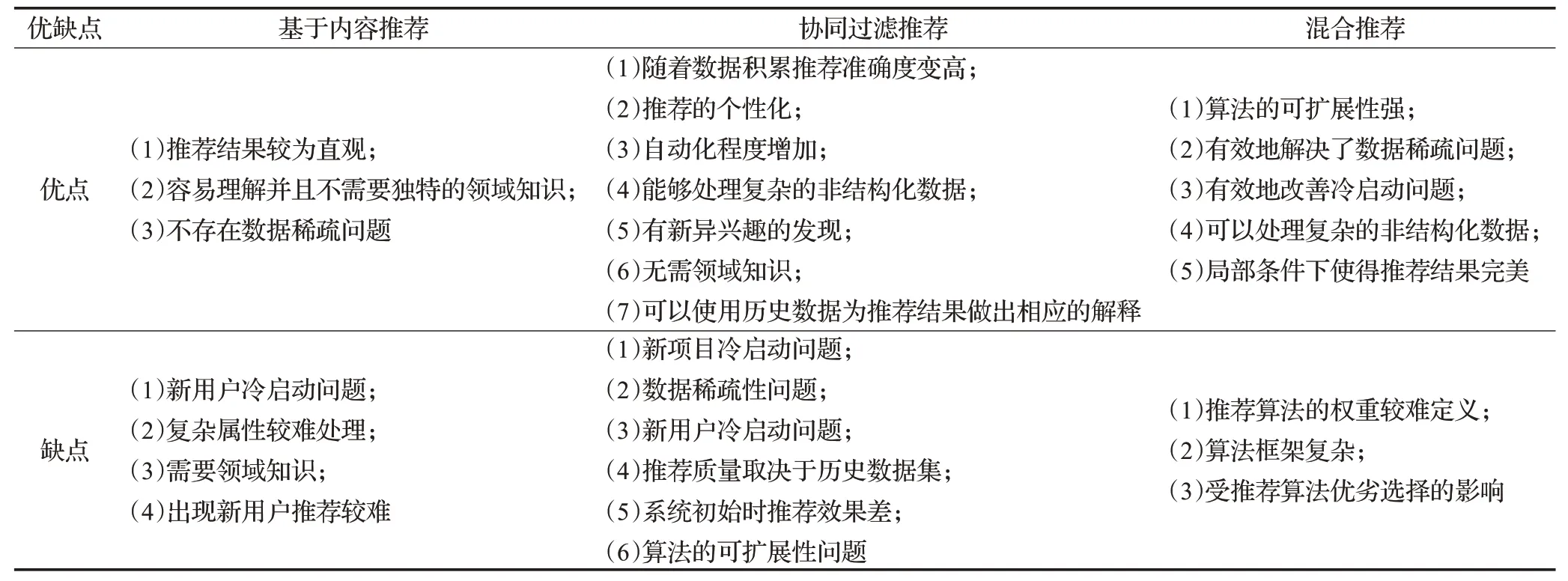
表1 傳統推薦算法分析比較表
2.3 混合推薦算法
混合推薦是通過組合多種推薦技術來解決各單體算法模型的不足。文獻[26]提出一種基于特征變換和概率矩陣分解的混合社交網絡推薦算法,該方法針對數據稀疏和冷啟動問題,以概率矩陣因式分解方法作為框架,將社交網絡中用戶的信任特征作為推薦的有效依據,其中各類特征值在推薦系統中所占權重還需研究改善。根據用戶需求和興趣特征,文獻[27]提出一種基于學習風格和個性化的混合推薦策略,通過獲取學習者不同的學習興趣和風格,對不同的學習風格進行聚類處理,使用關聯規則算法挖掘學習者的頻繁序列,對學習者的興趣進行分析,最后通過評級來完成個性化推薦。該方法做出了個性化的推薦引導,但對于如何準確獲取學習者的特殊學習情況與需求,仍需更加深入地發現和獲取。文獻[28]針對新用戶冷啟動問題較為嚴重的情況,提出一種綜合評分和對稀疏邊緣降噪以及矩陣模型分解相結合的混合推薦算法,以用來提高推薦精度并對冷啟動問題做出相應改善,但是冷啟動問題依然存在,如何使用改善的混合方法模型去優化推薦效果將會是下一個研究任務。文獻[29]總結了6 類混合推薦算法,分別是加權混合、交叉調和、特征混合、瀑布型混合、特征擴充以及元模型混合推薦算法,但仍有更為針對性和特定條件下的混合算法等待研究者的發現。
3 關聯規則與數據挖掘
3.1 關聯規則
所謂關聯,即反映一個事件與其他事件存在一定程度上的依賴或者關聯,并可以根據相關規則進行預測。關聯規則[30]是一種使用較為廣泛的模式識別方法,例如購物分析、網絡分析等,其中購物分析典型的應用場景就是在商場中找出共同購買的集合。關聯規則用于表述數據內隱含的關聯性,一般用三個指標來衡量關聯規則,分別是置信度、支持度和提升度。支持度表示規則中兩者同時出現的概率,且無先后順序之分;置信度表示A 出現,同時B 出現的概率;提升度描述了關聯規則中A 與B 的相關性。其定義分別如下所示:
定義1 設I={i1,i2,…,im}為所有項目的集合,設A是一個由項目構成的集合,稱為項集,事務T 是一個項目子集,每個事務對應項目上的一個子集,即T ?I 。關聯規則就是形如X ?Y 的邏輯蘊含關系,其中X ?I,Y ?I 且X ∩Y=?。
定義2 支持度(Support),是指規則中A 與B 同時出現的概率,如果兩者同時出現的概率小,則關系不大,若同時出現的概率非常頻繁,則說明A、B 是相關的,即:
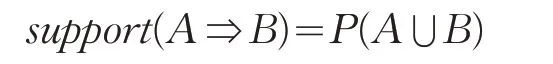
定義3 置信度(Confidence),展示當A 出現時B 也會出現的概率,若置信度為100%,則AB 可以捆綁推出,否則將不考慮將AB 置為關系親密,即:
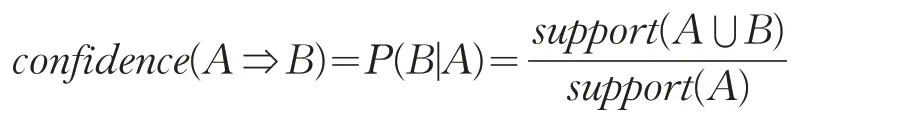
定義4 提升度(Lift),表示包含A 同時包含B 的比例,與包含B 的比例的比值。提升度大于1 且越高,正相關性越高,提升度小于1且越低則相反,即:

通常使用這三個指標來對一個關聯規則進行衡量,根據三個“度”篩選出滿足使用條件的關聯規則。特別的,滿足最小支持度和最小置信度的規則被稱為強關聯規則,此條件下如果提升度大于1則是有效的強關聯規則,提升度小于1則是無效的強關聯規則,提升度等于1則表示兩者相互獨立無關系。
3.2 數據挖掘
數據挖掘指從大量數據中經算法來搜索潛藏信息的過程[31],它是用來獲取關聯規則屬性篩選數據的一種重要方法,優質關聯屬性的獲取也為基于關聯規則推薦算法提供較好的基礎支撐。數據挖掘屬于一種決策支持過程,主要基于人工智能、機器學習以及模式識別等,還可以與用戶或知識庫進行交互。挖掘對象也不局限于某類型的數據源,可以是關系數據庫,也可以是數據倉庫、文本、多媒體數據等包含半結構化數據甚至異構性數據的數據源。
3.3 數據挖掘和關聯規則技術
對數據挖掘[32]而言,其目的就是從源數據庫中挖掘出滿足最小支持度和最小可信度的關聯規則。最著名的算法是1993年Agrawal等人提出的Apriori算法[33],其算法思想是:首先找出頻繁性至少和預測最小支持度相同的所有頻集,然后由其產生強關聯規則,最小支持度和最小可信度是為發現有意義的關聯規則而預先設定的兩個閾值。文獻[34]對上述算法進行優化研究。文獻[35]針對挖掘效率的不足,提出一種基于時間戳和垂直格式的關聯規則挖掘算法,用于解決效率較低的問題。
關聯規則反映了事物之間的相互依賴性和關聯性,關聯規則技術則是將數據資料中產生的高關聯性項目組進行收集處理,然后構建起一定的規則。它本質上是根據大量的數據來發現項與項之間存在的有趣而密切的相關關系,根據定義又可歸納為大于或等于最小支持度閾值和最小置信度閾值的規則,被稱作為強關聯規則,而關聯規則技術的最終目標就是為了尋找強關聯規則并應用它。具體步驟為:根據歷史記錄準備數據,計算項與項之間支持度、置信度以及提升度的主要指數,隨之產生可信的有效關聯推薦。
在運用關聯規則技術對數據進行處理的過程中,所處理的變量可分為布爾型和數值型。其中布爾型基本都是離散化和種類化的數據,而這些恰恰可以反映出變量之間的關聯規則。例如在沃爾瑪購物時,首先使用關聯規則挖掘技術對交易資料庫中的數據進行挖掘,并且設定Support 和Confidence 兩個最小閾值,符合需求的關聯規則應同時滿足這兩個條件。例如經過挖掘獲取了關聯規則「啤酒,尿布」,滿足兩個閾值后,便可以獲得「啤酒,尿布」的關聯規則,且該關聯規則行為將會被記錄,由此商品的推薦行為則根據相應的關聯規則進行。另外關聯規則技術對數據的處理分類除變量類別外,還有數據的抽象層數以及維數。
4 基于關聯規則的推薦算法
傳統推薦算法一般情況下并不會考慮兩者間被推薦前存在何種深層關系,推薦質量的提升因此會受到一定影響,而基于關聯規則的推薦算法則可以發現被推薦物品兩者間的深層關系[36],將數據進行歸類處理,并可以處理復雜的非結構化數據等,準確率也會隨著數據積累不斷提高[37]。本文將會圍繞關聯規則推薦算法在國內外的研究現狀以及進展,將數據的規則處理問題以變量類別、抽象層次、數據維度三個角度分析并應用關聯規則技術,從傳統推薦算法和社交網絡推薦[38]中尋找存在問題的解決辦法,并對研究方法進行總結。
4.1 基于規則處理的變量類別推薦方法
關聯規則處理數據的變量類別有布爾型和數值型兩種。布爾型關聯規則處理的值都是離散化、種類化的,可以顯示變量之間的某種關系。而數值型關聯規則可以和多維關聯或多層關聯規則結合起來,對數值型字段進行處理,將其進行動態的分割,或者直接對原始的數據進行處理。例如:性別=“男”=>職業=“教師”,是布爾型關聯規則;性別=“男”=>age(年齡)=33,涉及的年齡是數值類型,因此是一個數值型關聯規則。數值型和布爾型的關聯規則在推薦過程中廣泛存在,例如非結構化數據領域應用的推薦以及電子商務推薦等。
推薦依靠的數據通常是根據目標用戶的興趣偏好獲得,并通過與預測物品之間的數據分析匹配,從而完成基于內容推薦的效果。該方法雖可以直接獲取推薦結果,但是由于方法簡單,只考慮數據信息等問題,會導致推薦結果的多樣性下降,同時還伴隨著新用戶的冷啟動問題。為解決冷啟動問題,Osadchiy等人[39]建立了一種獨立于個人用戶興趣的集體偏好模型,該模型無需復雜過程進行評分,而是通過成對的關聯規則標準來進行推薦。實驗表明了基于成對關聯規則的推薦在對抗冷啟動問題上有較好的推薦效果。同時,多媒體等非結構化數據的處理在推薦過程中表現不佳,因此嘗試將數值型關聯規則技術融入其中,根據數據之間存在的相關規則對其進行挖掘,通過相互的關聯特征進行更為準確的和高效的推薦。例如文獻[40]提出了一個智能音樂系統,系統根據用戶先前的收聽模式風格、當前播放等數據內容對用戶可能更喜歡聽的下一曲進行預測。為了計算更精確的音樂相似性,文中使用關聯規則技術來挖掘發現用戶的收聽模式,從而進行預測。伴隨音樂發現服務,利用音樂收聽模式信息和音樂數據相似度來對新歌進行推薦,研究結果充分展示了系統以及推薦效果的可行性。
伴隨著項目數據的不斷積累,稀疏性加劇,為使用關聯規則技術解決協同過濾的數據稀疏等問題,文獻[41]提出一種基于關聯規則的協同過濾改進算法。針對由于協同過濾算法過分依賴用戶歷史數據集的交易數據而導致的數據稀疏性問題,該算法首先使用Apriori 算法將規則進行拆分,得到一對一或者多對一形式的規則,在形成不同的關聯規則匹配方法后根據相似度閾值的大小選擇對應的算法進行推薦,將高評分項目推送給用戶。實驗證明,基于關聯規則的協同過濾改進算法在一定程度上緩解了數據稀疏性問題,提高了推薦精度,但是推薦作用的提升還需要取決于推薦項目之間的關聯性多少。因此發掘項目之間更多不同層次之間的關聯關系,匹配更多的關聯規則將會從另一個方向來提高推薦準確性,變量類別推薦方法目前已被運用到音樂推薦、電子商務等個性化推薦中,并取得了不錯的成效。
基于變量類別的推薦方法,主要推薦機制是根據用戶對數據的使用情況,發掘用戶與數據之間的關聯規則。使用關聯規則算法對使用情況進行預測,對其獲取的關聯規則進行拆分整合,并形成對應的規則形式,在此基礎上根據對支持度、置信度的約束獲取推薦效果的改變。這樣的方法雖可以在一定程度上緩解傳統協同過濾算法中的數據稀疏和冷啟動問題,但是只考慮用戶對數據的使用則會影響推薦的覆蓋面和準確度。因此,將變量類別的關聯規則技術與傳統推薦算法相結合雖可以緩解經典推薦問題,應用于一些領域中進行高效推薦,但在研究中仍需要更多考慮相關用戶及數據的潛在關聯內容和規則特性,使其可以得到充分發掘,并據此進行合理高質量的推薦。
4.2 基于規則處理的抽象層次推薦方法
關聯規則中數據的抽象層次分為單層關聯規則和多層關聯規則,但是在單層關聯規則中所有變量未考慮它們的層次不盡相同,具體表現在協同過濾推薦中最重要的用戶與物品相似度關系。例如:聯想筆記本=>華為筆記本,是一個細節數據上的單層關聯規則;但計算機=>華為筆記本,是一個高層次和細節層次之間的多層關聯規則。
文獻[42]提出一種基于多層關聯規則的推薦算法,主要目的是為了解決當下傳統推薦算法存在的數據稀疏性問題和可擴展性問題。該算法通過挖掘多層關聯規則條件下用戶對商品的興趣偏好,對用戶建立預測模型。文章通過建立一套基于關聯規則的電商推薦系統,將系統的規則挖掘分為兩個核心部分:一部分以多層關聯規則模型為基礎獲取可靠規則并寫入規則庫;另一部分則是通過用戶的使用操作來實時產生推薦結果,并將結果以特定的形式反饋系統。實驗證明,對比協同過濾推薦而言,多層關聯規則推薦有效地緩解了協同過濾中數據稀疏和可擴展性的問題。
劉君強等人在文獻[43]中將關聯規則中的一種分類標準以單層關聯規則和多層關聯規則進行劃分。其中單層關聯規則挖掘算法為經典Apriori 算法,但在多層關聯規則中卻并不能較優地使用,因此產生了針對于多層關聯規則的挖掘算法,但該方法無法對關聯規則進行跨層挖掘。文章由此定義了一種跨層擴展頻繁項目圖Clefig,并據此提出相應算法用來高效地挖掘單層、多層特別是跨層之間的關聯規則。實驗結果表明,該方法在多層、跨層以及支持率閾值較小的單層挖掘中有較大的算法優勢,并且可以進一步推廣到數值型的跨層關聯規則挖掘中。
協同過濾推薦一般是依靠用戶評分和存在的大量歷史數據集,由此便會存在數據稀疏和冷啟動問題。基于該類問題,研究學者將關聯規則技術引入協同過濾推薦中,在協同過濾計算相似度的過程中加入了多層關聯規則推薦技術,使得數據稀疏和冷啟動問題得到一定程度上的緩解,并且增強推薦的拓展性。對于興趣相似度問題,文獻[44]就電影推薦提出了一種針對產品特征進行Vague值提取與表示的方法,由于通常需要根據產品特征屬性的相似度對產品提前分類,因此又引入了產品分類樹的概念,經過將產品分類樹、關聯規則、特征提取與相似度分析結合,得出了多樣化的推薦效果。實驗結果表明,該方法與傳統推薦方法相比,無論在推薦精度還是推薦多樣性上都更為有效。通過研究發現[45],在基于內容的推薦中使用抽象層次的關聯規則技術可以發掘物品之間存在的隱含關系,從而挑選大量高質量的規則,并快速匹配用戶瀏覽記錄和關聯規則數據庫,提高關聯規則的推薦效率,以此來更好地為海量在線用戶形成實時推薦。
基于抽象層次的推薦機制主要是通過發現被推薦內容之間更為隱含的不同層次知識,并且根據發掘的用戶與物品的深層次偏好,通過相似度的計算來獲取更為優質的推薦內容。但通常情況下,單一層次的規則結構往往伴隨著準確度不足等問題,因此更多的研究指向多層次的規則發現,并由此獲取更為多樣的關聯規則,挖掘出隱藏于表層之下的豐富知識,為用戶實現高質量的信息推薦需求。綜上分析可知,基于抽象層次的關聯規則推薦,也可以有效地緩解由于數據稀疏、用戶相似度帶來的一系列問題,而且還能夠提高算法的可擴展性和多樣性,對預測未評分待推薦的高質量物品提供了一個全新的高效的展示平臺。相比于變量類別的方法,抽象層次的推薦方式將使得隱含知識和推薦內容更為豐富。但是單一層次的規則化推薦對于推薦的準確性仍力不從心,而多層規則的使用算法則需要繼續從數據挖掘精度和算法運算速度等方面進行改進,以此來獲取更高質量的規則內容和推薦效果,為實際的使用帶來更多的研究空間。
4.3 基于規則處理的數據維度推薦方法
現實存在的大部分數據,例如商品購置等通常只能涉及到一個維度的數據關聯,在處理和推薦社交網絡等不同環境下多屬性和多維度的數據時,關聯規則技術的優勢就會凸顯。例如:性別=“女”=>職業=“醫生”=>年齡“28”=>愛好=“旅行”,這條規則就涉及到多種維度的各類字段信息,是幾個維度上的一條共同關聯規則。
王俊紅等人在文獻[46]中提出了一種基于多維概念格的關聯規則發現方法,目的是為了在引用多維數據序列對概念內涵進行不同維度描述的過程中,同時使用關聯規則提取方法,由此來發現最大頻繁多維數據序列與不同維度屬性數據之間的緊密關系。實驗結果表明,在同樣的算法作用但不同的數據屬性背景下,獲取的規則也不盡相同,多維概念格所獲得的規則不單單描述了概念格之間的關系,也顯示了各不同屬性背景彼此之間的關系。因此,多維度的關聯規則更容易發現內容豐富的高質量信息。同時協同過濾算法在推薦過程中將用戶-項目評分矩陣作為數據的獲取來源,導致推薦時無法準確發現用戶與項目屬性之間的關聯關系。黎丹雨等人在文獻[47]中提出了一種運用于推薦算法系統的多層多維數據模型,該模型在挖掘數據多維序列之后輸出關聯規則,并用得到的關聯規則進行評分矩陣的修改,從而對原有用戶與項目之間的關聯關系進行多維改進。實驗結果表明,該模型對推薦系統的性能有較大的提升,由此證明用戶與物品屬性之間的多維規則對推薦系統的影響不容忽視,但該模型在挖掘多維關聯規則時由于“祖先”關系,會存在一定的冗余規則,如何更好地發現冗余規則仍需要探索研究。
通常社交網絡中產生的部分用戶數據都會是多維度下的一條關聯規則,基于社會網絡的推薦可以完美地模擬現實,并且通過好友的推薦增加彼此信任度。由于移動設備以及互聯網的興起,更多的人希望通過社交平臺來拓展自己的人際關系,但同樣社會化的推薦也存在一定的缺陷。例如由于不是根據共同興趣愛好而匹配在一起的好友,他們的興趣愛好也會不盡相同,導致算法的準確率偏低,也存在數據稀疏等問題。于是將多維度的關聯規則技術融合進社交化推薦當中,用來保證推薦品質。
部分學者通過分析社交網絡中的興趣類別推薦和交換差異數據,運用不同手段將關聯規則技術融合到社交網絡的推薦過程中,其中最重要的切入點就是興趣相似點的發掘和使用。文獻[48]提出了一種碎片信息相似度的計算方法,隨著信息方式的快速變化發展,長文博客減少,傳播信息的主要方式變為通過碎片化進行。但由于沒有上下文作為參考,使用句子相似度來判斷其是否為一類信息則是最為顯著和有效的辦法。相似度包含了多種維度的數據關聯屬性,根據多維數據條件下獲取的關聯規則便可以更為全面地匹配好友信息。胡文江等人[49]提出了一種基于關聯規則的社會網絡改進好友推薦算法,利用關聯規則算法建立用戶關系矩陣,獲取關系矩陣下的多維關聯規則后計算并且排列結果,同時對用戶之間的友好關系以及用戶標簽相似度進行改進,以提高推薦效率,增加推薦權重。文獻[50]指出,用戶興趣是社交媒體分析的重要組成部分,而興趣則由多個不同維度屬性的數據構成一個完整的用戶興趣數據集,作者通過對其捕捉和理解來發現社交媒體網站的獨立用戶通常屬于多個不同的興趣社區,并且他們的興趣隨著時間而不斷變化。因此,建模和預測動態用戶興趣,對社交媒體分析研究中的個性化推薦提出了一個巨大的挑戰。通過研究基于時間加權關聯規則挖掘的時間重疊社區檢測方法,提出了一種針對該研究問題的新穎解決方案,并使用Movie Lens 和Netflix 數據集進行了實驗。實驗結果表明,該方法在推薦精度和多樣性方面優于幾種現有方法。
用戶社交網絡中產生的推薦對用戶可以快速匹配好友,使得好友圈子更加豐富,雖然在關聯規則技術的運用下,多維社交化網絡的推薦日益成熟,但對于用戶使用而言,有關用戶隱私安全的保護[51]仍然是值得關注和解決的一個重要內容。李學國等人[52]針對社交網絡中大量隱私數據的保護問題,提出了一個基于有損分解來保護隱私數據的策略,通過對數據特征重構、分散存儲、隨機干擾、設置密碼保護等方式,將社交網絡隱私保護的關聯規則數據挖掘工作進行實現。黃海平等人[53]則從圖結構入手,針對現在研究中對于社交網絡圖數據隱私保護采取無權值的方法做出改進,提出了一種基于非交互的差分隱私保護模型的帶權值的社交網絡圖擾動方法。該方法通過添加擾動噪音、根據權值將邊劃分等步驟,獲得較好的運行效率和數據效用,從而有效保證了用戶數據的隱私安全,但該方法更適用于數據量較為龐大的社交網絡數據分析,具有一定局限性。
運用處理數據維度較多的關聯規則技術,主要是發掘更多的屬性特質,從而獲取更豐富的高質量信息內容。其一方面在社交網絡推薦的使用中能有效解決推薦時所產生的稀疏性問題,提高推薦精度,增加用戶興趣好友的獲取質量,同時保證用戶的數據使用得到安全保障。另一方面相比于上文其他的兩種推薦方法,多維度數據屬性下的關聯規則發現和使用,會發現更多用戶與項目屬性、項目與用戶屬性之間的豐富關聯關系和內容知識,這將極大地保證推薦效果的品質,提升推薦的多樣性,以及拓展更為便捷的推薦服務。如此,基于關聯規則的推薦方法將會以現有傳統推薦方法為基礎,更好地完善推薦的種類、效果、覆蓋面以及豐富度。
但是數據維度推薦方法中同樣存在著一些重要的問題,例如單維度的規則并不會對更多的新內容提供豐富的支持,因此推薦效果也會大打折扣;而多維度的關聯規則也并非最優方法,還需從評分矩陣或用戶相似度方面著手改進,亦可將抽象層次和多維度數據進行結合,構建多層模型并融入多維數據序列,以尋求更為準確和豐富的用戶推薦使用方法。
本文基于關聯規則中三種不同的推薦方法,通過分析和總結部分研究學者對關聯規則技術的運用,來闡述關聯規則技術在推薦中可以解決的相關問題以及仍存在的相關問題,詳細優缺點對比及相關內容見表2。在推薦算法中使用關聯規則技術,不僅僅可以更深入地發現被推薦內容彼此之間的關聯,并且對于傳統推薦算法消除存在的缺陷及其他問題的改進都有一定程度的提升,但存在的部分問題也迫在眉睫,仍需要做出更多的研究和改進,以謀求對推薦結果準確性的提升和豐富度的保證。
上述的三種基于關聯規則的推薦方法雖然在推薦過程中各具優勢,但是它們的局限性也是有目共睹的。第一,使用變量類別的推薦方法雖可以緩解傳統算法中的經典問題并應用于非結構化個性推薦中,但其過分地依賴用戶歷史數據是一大問題,并且研究中發現僅使用簡單的關聯規則算法獲取的成對規則效果單一,并沒有更豐富的屬性和關聯,因此推薦效率不高,應用范圍有限。第二,使用抽象層次推薦方法較上一類方法性能有所提升,并對算法的可擴展性有所幫助,也可以發現物品之間的深層次隱含關系,但對于單層次規則和部分數據屬性而言,它的局限性也較為明顯,例如單層次規則提取準確度較低,從而導致推薦的精度下降,也存在由于無法正常跨層獲取和處理內容導致的推薦效果不佳,因此存在方法的局部使用局限性。第三,在數據維度推薦方法中,雖可以更好地執行推薦,但單維規則不能較好地獲取新內容中隱含的規則知識和屬性,同時用戶相似度和不同背景下發掘的海量屬性也會對推薦結果造成不小的影響,關聯屬性值的過多獲取對于推薦效果而言也并非多多益善,因此如何獲取有效的、關鍵的、非冗余的多維數據規則屬性將會是改變推薦效果局限性的主要辦法之一。
5 基于關聯規則推薦方法的研究趨勢與展望
經過幾十年的發展,推薦系統憑借其可以高效、獨特地為用戶獲取信息的特性,已成為諸多領域中不可或缺的重要因子,其研究已經體現出了重大的社會價值、經濟效益以及技術創新,同時對推薦技術不斷更新的研究也是現代社會用于有效解決信息科學的中心問題之一。盡管基于關聯規則的推薦算法在幾個方面已經取得較好的研究成果,但其應用研究在取得長足發展的過程中仍然面臨著諸多的挑戰和新的難題,值得深入調研。
(1)基于關聯規則的推薦雖然可以較好地緩解數據稀疏性和冷啟動的問題,但它們仍將是推薦算法的難題,雖使用了不同的方法去改進,但問題依然存在。如何通過抽取強規則來獲取用戶特征,提高推薦性能,挖掘多領域之間的復雜關系,并由此給出更好的推薦,將會是未來一個重要的研究方向。
(2)雖然基于關聯規則的推薦解決了許多傳統推薦算法的局限性難題,但是其性能評價標準以及可擴展性問題,包括用戶對算法的敏感度、適應度、優化規則以及質量效果都應該成為研究的重要目標和方向。
(3)當前數據流在推薦算法運行過程中普遍存在算法安全性較差和推薦精確度較低的情況,現對其安全性的主流研究主要通過對用戶使用的行為數據進行分析和處理,以此來改善算法存在的問題。例如文獻[54]使用數據挖掘、頻繁項集等方式將用戶屬性內容與蟻群算法進行融合,將蟻群收斂路徑判斷為安全隱患路徑,并由此去除異常值,再根據挖掘算法獲取頻繁項集,基于頻繁項集計算用戶相似度,最終獲得最符合用戶使用的安全數據流。還有部分研究根據對用戶數據的擬合來對算法的安全性和推薦的準確性做出相應改善,但僅對用戶數據的屬性進行分析仍存在著一定的研究局限性。因此保證算法更加安全可靠,從而為用戶提供高效準確的推薦環境一直都是極其重要的研究方向。在改進時,可以從算法模型優化、用戶的模糊聚類等方面進行考慮,不過分地追求用戶屬性的詳細情況,使其通過更合適的聚類方式進行相似度計算,為用戶獲取更準確的數據流。還可以引入使用頻率較高的差分隱私機制數據保護方法,在推薦過程中保證數據流具有更高安全性的同時,保證推薦結果高效和準確。
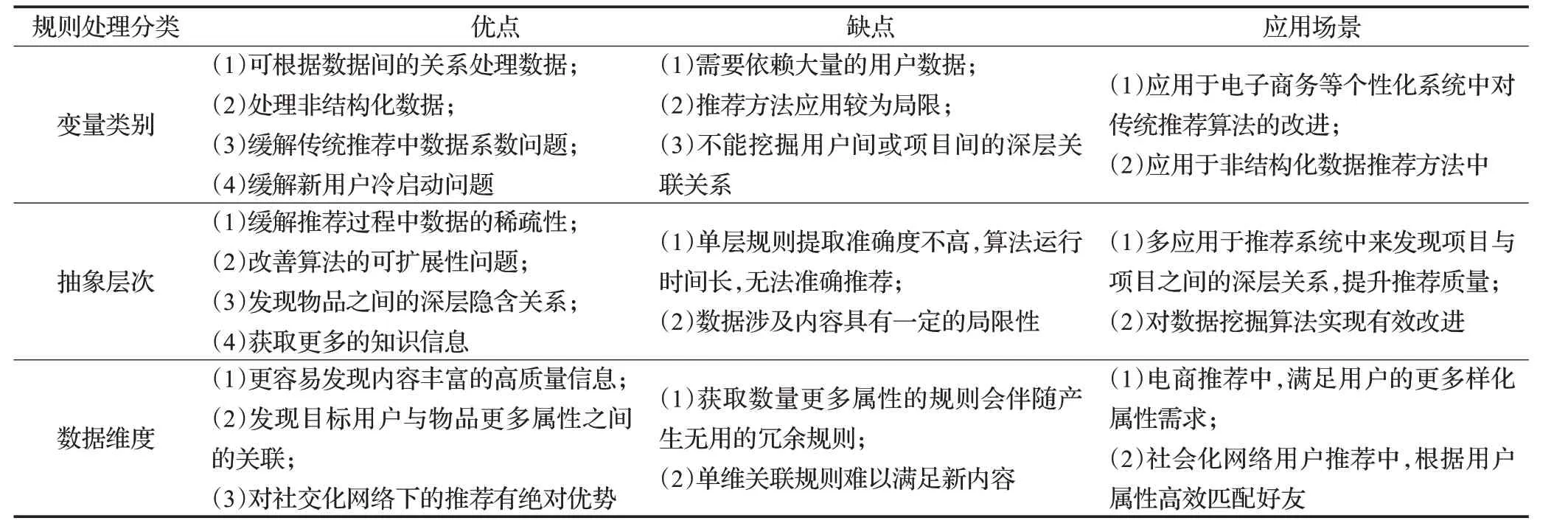
表2 關聯規則技術處理的三種方式在推薦算法中的使用
(4)規則化數據在數值處理過程中會出現由于數值的離散化導致關鍵信息丟失的現象,從而影響關聯規則推薦的準確性。過往主流研究通常通過平均數、中位數、隨機值等相關值或預測模型來獲取丟失的關鍵信息,對于更多的規則化數據,則將其映射到高維空間進行缺失值的處理,它會保留數據的原始全部信息,但同時也存在較大的缺陷,譬如計算量較大,并且需要在數據樣本規模較大時效果才顯著。在未來的對于數據處理時由于離散化導致關鍵信息丟失的研究中,可以從幾個方面來尋求改進。例如為丟失數據信息引入區別于已有數據屬性值的特殊值對其進行虛擬標記,通過其獨特的表征來發現數值的缺失并進行相應的補全;或對數據使用過程中無關緊要的丟失值選擇性地忽略不處理;或根據歐式距離計算缺失數據值樣本周圍的k 個數據,并通過k 個值的加權平均值來預測丟失值的具體內容信息等方法,都將會在一定程度上保證對關鍵數據信息的獲取和保護,從而提升推薦效果。
6 結束語
關聯規則及其相關研究已經逐步從互聯網電子商務走向復雜程度更高的非結構化數據等處理當中,迎來更多新的研究方向。基于關聯規則推薦算法的研究一直以來有著較大的科學研究價值和社會經濟效益,備受應用者與研究者的關注,學者們紛紛就基于關聯規則的推薦提出不同的見解和研究結果。本文通過不同的研究角度對基于關聯規則的推薦算法進行了綜述,并總結和展望了發展趨勢,以便更好地被研究使用以及進一步提高推薦質量,未來也將會有更為深入的研究內容等待著探索。
猜你喜歡
小獼猴智力畫刊(2022年3期)2022-03-29 01:09:42
當代陜西(2021年17期)2021-11-06 03:21:36
數學小靈通(1-2年級)(2021年4期)2021-06-09 06:26:14
學苑創造·A版(2018年11期)2018-02-01 06:29:20
Coco薇(2017年11期)2018-01-03 20:59:57
讀者(2017年5期)2017-02-15 18:04:18
暨南學報(哲學社會科學版)(2016年9期)2017-01-15 13:52:02
商用汽車(2016年11期)2016-12-19 01:20:16
商用汽車(2016年6期)2016-06-29 09:18:54
商用汽車(2016年4期)2016-05-09 01:23:12
