多核并行脈沖神經網絡模擬器的設計
2020-11-18 09:15:18劉家華陳靖宇
計算機工程與應用 2020年22期
關鍵詞:模型
劉家華,陳靖宇
廣東工業大學 計算機學院,廣州510006
1 引言
脈沖神經網絡(Spiking Neural Network,SNN)[1]是第三代人工神經網絡,它結合了生物神經系統與人工神經網絡的結構、功能與原理,對腦神經系統進行建模,模擬仿真人的智能行為,如學習、識別、推理演算等[2],與傳統的人工神經網絡相比,脈沖神經網絡更接近人腦神經網絡的工作機理。脈沖神經網絡以脈沖神經元[3]為基本單元,脈沖神經元(Spiking Neuron)膜電位非線性累積,當到達閾值電位后脈沖放電并進入不應期冷卻,脈沖通過軸突傳遞給下一個神經元,大量的脈沖神經元構成的神經網絡不僅擁有更強大的計算能力,而且可以處理復雜的信息信號和模擬連續函數[4]。不同的神經元具有不同的幾何形態和電學特性,通過對這些形態不一的神經元進行數學建模與數值分析,才能開展多種神經計算與模擬仿真。
隨著神經科學研究成果的積累,早期人們對生物神經系統的構造和運行機理已有了比較全面的認識,對不同的生物神經元構建出具有生物可解釋性的脈沖神經元模型。Hodgkin 等人通過對烏賊軸突神經的研究,揭示了各種可興奮性細胞的基本規律,提出了Hodgkin-Huxley神經元模型[5]。Lapicque用電子線路模擬神經元的神經生理現象,簡化了Hodgkin-Huxley神經元模型負責的高維非線性方程,提出了漏電Integrate-and-Fire 神經元模型[6]。Izhikevich 通過對Hodgkin-Huxley 神經元模型的分岔分析,結合了Integrate-and-Fire 神經元模擬的計算效率,提出了Izhikevich 二維脈沖神經元模型[7],以1 000個Izhikevich為模型的神經元在1 s的生物時間仿真1 000 生物周期。近幾年來,人們對脈沖神經網絡模型進行深入研究,相繼提出了許多空間復雜的神經元模型,如表1 所示,BULE BRAIN 團隊提出的Hippocampus神經元模型,它有13種不同形態的神經元,由約80萬個神經元和3.6億個突觸連接構成。
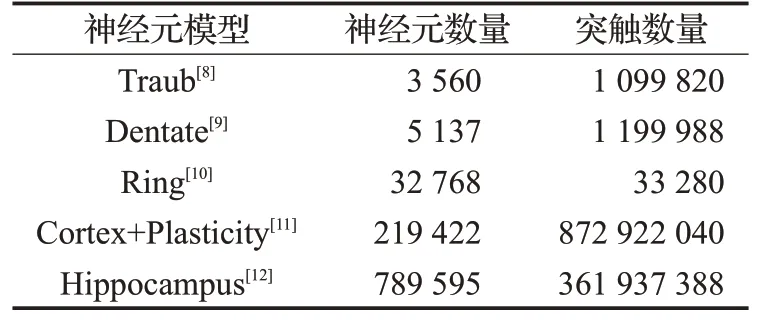
表1 多種神經元模擬示例
龐大的神經元分布與頻繁的神經元間的脈沖交互,在串行方式下難以進行仿真實驗。針對這個問題,許多科研團隊提出了一些解決方案。曼切斯特大學類腦科學研究團隊研發了SpiNNaker 脈沖神經網絡模擬器[13]。SpiNNaker 模擬器構建于sPyNNaker[14]軟件層與SpiNNaker 的類腦計算機[15],支持更新神經元狀態的時間驅動和脈沖處理的事件驅動,可以高效率多線程并行地模擬大規模不同模型的脈沖神經網絡。NEURON為脈沖神經網絡提供了一種分布式并行計算平臺[16],神經元計算任務可以分布在不同的處理器節點上,以時間同步方式進行神經元仿真實驗。雖然眾多的模擬平臺為脈沖神經網絡提供了模擬環境,但國內使用權限的原因,國內研究者難以在神經科學平臺上進行模擬實驗。如何僅僅利用個人計算機實現脈沖神經網絡高效率地模擬仿真,成為國內神經科學研究者所關注的問題之一。
隨著計算機硬件的支持,計算資源的提升,個人計算機內核數不斷增多(如ARM A83 處理器8 核,Intel i7-8740處理器6核),為此,本文設計了一種多核并行的脈沖神經元網絡模擬器框架,利用多核的計算能力,高效地對大規模脈沖神經網絡進行并行計算。在并行計算任務的分發方面,將神經元進行編碼,并對每個核進行映射。在網絡通信方面,采用源地址尋址的通信方式,自定義分布式路由表實現處理器內多核間的脈沖傳輸。采用同步時間驅動策略,在每個生物周期進行動態同步,解決并行同步問題。以Izhikevich 脈沖神經元為模型,在大規模的脈沖網絡結構上進行仿真實驗。實驗結果表明,本文的模擬器在大規模的網絡結構中,并行仿真計算的效率優于傳統的串行仿真計算。
2 多核并行的脈沖神經網絡模擬器
Izhikevich 脈沖神經元模型是單房室神經元,由于該模型結構簡單,本文以Izhikevich 脈沖神經元模型作為模擬器仿真實驗對象。在多核并行模擬器設計中,涉及到并行任務的分發、多核間的網絡傳輸、時間同步的問題。針對這些問題,進行了神經元的映射與編碼設計,自定義路由表與動態同步設計。
2.1 Izhikevich脈沖神經元模型
數學上來講,脈沖神經元是一種混合系統:神經元的狀態根據一些生物物理方程不斷變化,這些方程通常是微分方程(確定性或隨機性、普通或偏微分方程),通過突觸接收到脈沖信號觸發一些變量的變化。因此脈沖神經元的動力學可以描述如下:

其中,X 是描述神經元狀態的向量,f 表示神經元狀態變量演化的微分方程,gi指脈沖通過突觸i 后對神經元的影響,當X ∈A 滿足某個條件時就會發出一個脈沖[17]。例如Izhikevich 模型Vm≥θ(這里Vm是神經元膜電位對應矢量X)神經元產生一個脈沖,同時作為X的膜電位將被重置。Izhikevich的二維脈沖神經元模型如下所示:
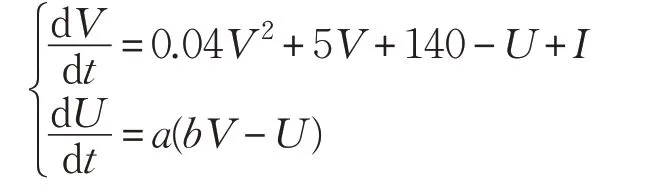
如果神經元的膜電位V ≥30 mV,輔助的復位機制為:
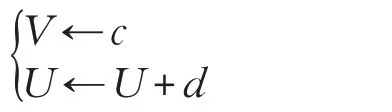
式中,V 表示膜電位;U 表示恢復變量,用來代理生理模型中激活的K+電流和流失的Na+電流,實現對膜電位V 的負反饋。Izhikevich神經元模型中的參數a、b、c、d是無量綱參數,隨著參數a、b、c、d 取值的變化,Izhikevich神經元模型可以表現出豐富的脈沖發放模式。參數a表示恢復變量U 的時間尺度,a 的值越小,表明恢復得越慢;參數b 表示恢復變量U 依賴于膜電位V 的閾值下隨機波動的敏感程度;參數c 表示神經元發放脈沖后膜電位V 的復位值;參數d 表示神經元發放脈沖后恢復變量U 的復位值。
2.2 神經元的映射與編碼
映射與編碼設計思路:(1)每一個神經元總有唯一內核與它對應;(2)充分利用每個內核的計算資源,每個內核間神經元個數差不超過M ;(3)確保神經元的獨立性,映射前后神經元有獨立的編碼。
大規模的脈沖神經網絡在多核中并行計算時,需要將計算任務分發至每個內核中,即將網絡中的神經元映射至對應的內核。內核的集合為C={Cm;m=1,2,…,M},M 是內核的個數,神經元的集合為V={Vn;n=1,2,…,N},N 是神經元個數。神經元與內核的映射關系可以表達為:
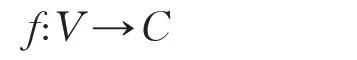
神經元初始分配順序序號,神經元采用均分的方法映射至對應的內核,每個內核平均分配到的神經元個數為AVG,AVG 可以表示為:
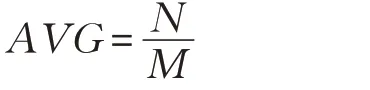
若有多余的神經元,多余的神經元分配至最后一個內核,最后一個內核神經元個數為EXTRA,EXTRA 可以表示為:
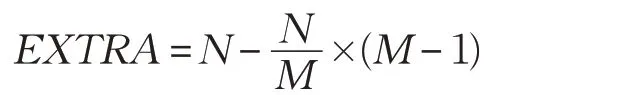
神經元映射對應的內核后,由源序號重新編碼。神經元編碼定義為32 位,編碼規則如下:前12 位為CPU的ID(保留12位CPU位方便以后的擴展應用),中間4位為內核ID,后16位為神經元核內局部ID,如圖1所示。
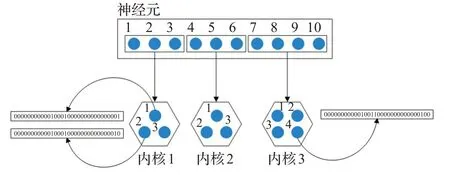
圖1 神經元的映射與編碼
2.3 路由表的創建
路由表設計思路:(1)根據網絡拓撲結構可生成靜態路由表;(2)源神經元通過查表可尋找目的神經元;(3)多表結合,減少查詢的時間復雜度。
以源地址尋址作為內核間神經元的通信方式,由此在每一個內核中設計了兩份路由表:(1)第一份路由表為發送表(Table 1),其作用是當本核內神經元生成脈沖,通過Table 1由源神經元ID查詢到對應目的神經元ID。若目的神經元為本核內的神經元,直接根據路由表的權值影響本核目的神經元的權值。若目的神經元為核外的神經元,將脈沖(源ID)通過I/O傳輸方式寫入對應的神經元所在的內核緩存中。(2)第二份路由表為接收表(Table 2),當本核收到來自其他核發來的脈沖(源ID),通過Table 2 查詢該脈沖影響本核內的哪些神經元,并根據Table 2獲取到影響權值大小。如圖2所示,根據自定義的網絡拓撲結構與突觸連接權值生成權值文件,在神經元映射與編碼后,根據權值文件生成每個內核對應的兩份路由表。生成路由表的算法如下所示。
算法1 生成路由表

查表的時間復雜度為O(1),通過實驗測速,源神經元查詢多個目的神經元在1 μs內完成。
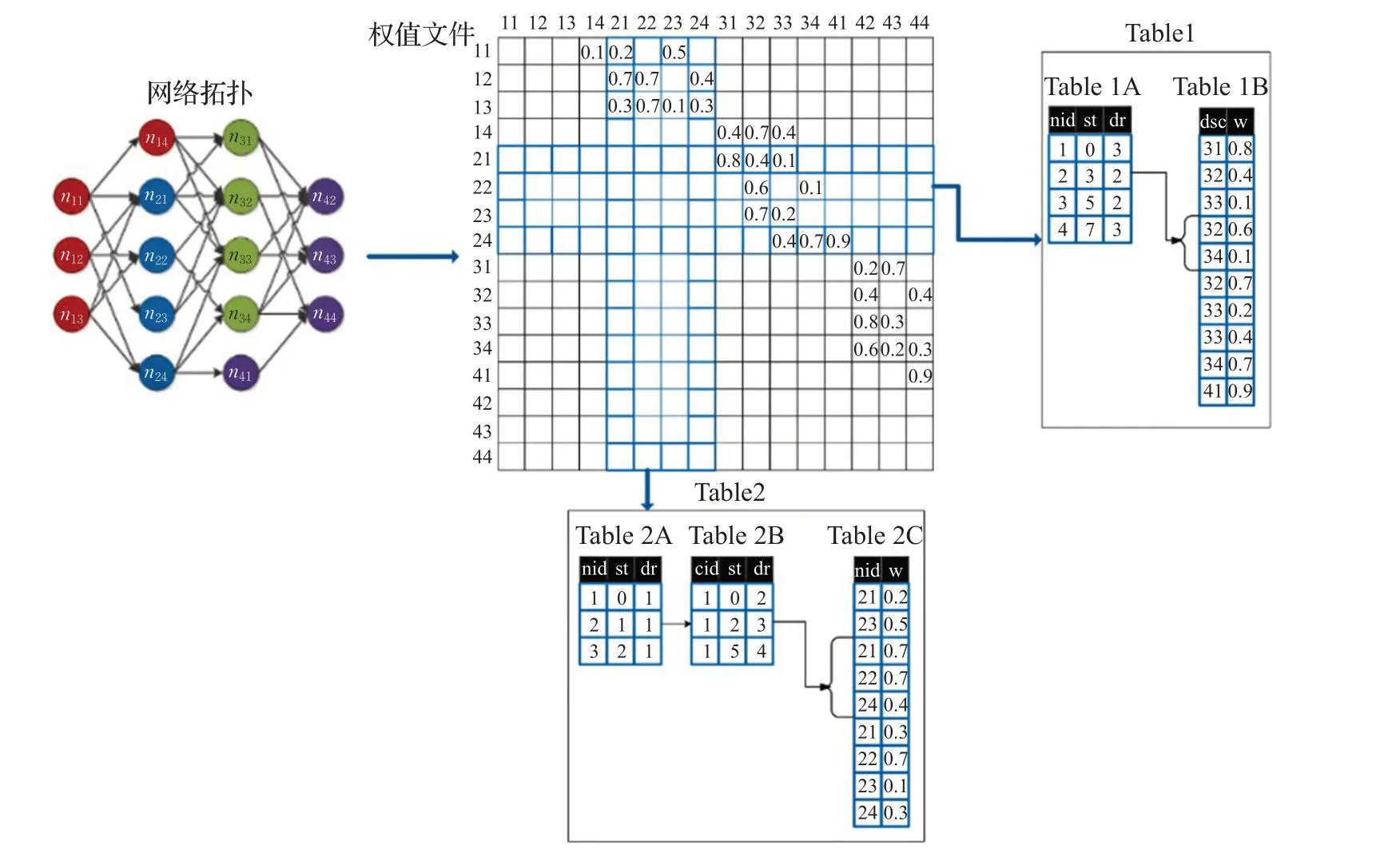
圖2 路由表的生成
2.4 同步時間驅動仿真策略與動態同步
神經網絡仿真有兩大類算法:同步時間驅動算法[18]和異步事件驅動算法[19]。其中同步時間驅動算法所有的神經元在每一個周期都進行同步更新,異步事件驅動算法只有當神經元在接收或發出一個脈沖時才會更新。時間驅動算法與事件驅動算法在理論上相比,神經元處理時間上時間驅動算法是近似的,沒有事件驅動算法精確。但考慮到模擬器是為大規模仿真而設計的,在大規模仿真中,性能是一個關鍵問題,由于網絡延遲存在,異步驅動算法無法在精確時間內完成點對點的脈沖傳輸,并且無法大規模集成地對神經元群批處理。再者事件驅動算法的精度依賴于特定的神經元模型[20],存在模擬器的擴展性不高的問題。通過綜合考慮,本文模擬器采用的同步時間驅動算法如下所示。
算法2 同步時間驅動

在同步時間驅動算法中,所有神經元的狀態變量在每個周期進行一次更新X(t)→X(t+dt),更新所有變量后,對每個神經元檢查閾值條件。每個滿足該條件的神經元產生一個脈沖,該脈沖傳輸到其目標神經元,更新相應的變量(X ←gi(X))。
算法的仿真時間由兩部分組成:(1)更新神經元狀態;(2)脈沖的傳播。假設神經元的數目為N ,那么時間復雜度為O(N/dt)。假如在每個生物周期中,平均有FN 個脈沖由神經元生成(F 是脈沖平均生成率),需要傳播至P 個目標神經元,總時間成本為T,T 可以表示為:

這里,cu是單個神經元更新狀態花費的時間,cp是單個脈沖傳輸所花費的時間。
動態同步設計思路:(1)內核完成每個周期計算任務與脈沖傳輸后進行一次狀態同步;(2)以最先完成計算任務的內核時間點作為同步開始,以全部內核完成同步的時間點作為同步結束;(3)解決同步時網絡延遲、脈沖數據丟失的問題。
在時間同步方面,同步分為初始同步與周期同步。初始同步:每一個內核綁定獨自的線程,在每個線程中設置線程柵欄,只有當每個內核都完成本核的初始化后,打開線程柵欄使得所有線程在同一時間點開始運行。周期同步:在每個周期對每一個內核進行周期同步,如圖3 所示。當一個內核完成本周期的計算任務后,通過廣播的方式發送同步數據包給其他核。然后自身進入接收階段并每隔一段時間間隔t 重復發送同步數據包(防止同步包的丟失)。t 由神經元數量N 與內核數量M 決定,可以表示為:
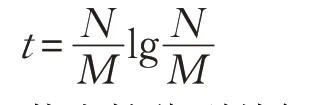
若本核收到其他核傳來的同步數據包時,記錄對應核的周期完成情況。只有當每個內核自身完成本周期的計算任務和收到其他內核的同步數據包后,則開啟下一個周期。若本周期計算完成但長時間沒收到其他核的同步數據包,則重新廣播本核本周期的同步數據包。
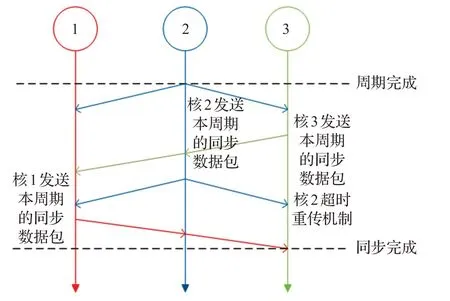
圖3 脈沖神經網絡周期同步
2.5 多核并行模擬器仿真模擬流程
內核結構如圖4 所示,每個線程綁定獨立的內核,內核中存放映射后的神經元,同時內核也存放對應的兩份路由表Table1 與Table 2,其中Table 1 為發送表,Table 2為接收表。在共享內存上對每個核分配兩塊獨立的內存空間,分別為緩存1(Buffer 1)與緩存2(Buffer 2)。其中Buffer 1 存放本核神經元生成的脈沖,Buffer 2 接收存放外核傳來的脈沖。
模擬流程如圖5所示,根據網絡拓撲結構生成對應的權值文件,由權值文件創建每個核對應的路由表,根據配置參數初始化所有神經元。將每個核綁定至獨立的線程,當每個核部署完成并初始同步后開始周期模擬。每個核的每個周期的主要工作分為三步:(1)更新核內每個神經元的狀態,根據脈沖神經元的模型計算出神經元的膜電位,若神經元膜電位高于閾值則生成脈沖(源ID),將脈沖放置核內的緩存1(Buffer 1)中;(2)處理神經元生成的脈沖,當遍歷更新完核內所有神經元狀態后,查看緩存1 是否有本核神經元生成的脈沖,如果有脈沖,則逐一取出并通過查發送表(Table 1)直接影響本核內對應神經元的膜電位或將脈沖發送至對應核的緩存2(Buffer 2)中;(3)處理外核傳來的脈沖,查看緩存2 中是否有外核傳來的脈沖,如果有脈沖,則逐一取出并通過查接收表(Table 2)直接影響本核內對應神經元的膜電位。當每個核完成本周期的任務后,所有核進行一次周期同步。仿真模擬結束后,記錄每個脈沖神經元在每個周期的生成脈沖情況。
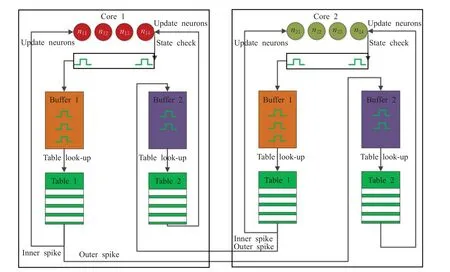
圖4 內核結構
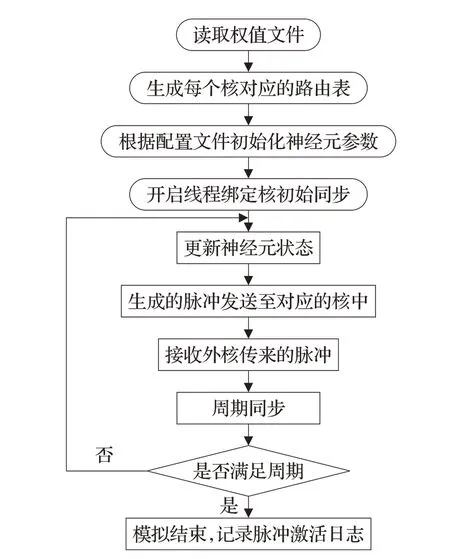
圖5 模擬仿真流程
3 實驗結果與分析
本文的實驗環境基于Intel Core i7-8750 六核處理器,內存24 GB,Liunx操作系統,GCC-version7.3版本下完成編寫程序與編譯。
3.1 多核并行實現Izhikevich算法模型
根據Izhikevich文獻[7]的模型生成相同的脈沖神經網絡結構,總共有1 000個脈沖神經元,神經元之間以全連接的方式連接,神經元間的突觸權值隨機生成,興奮性神經元突觸權值在0~0.5 范圍,抑制性神經元突觸權值在-1~0范圍,神經元的其余配置參數如表2所示。

表2 神經元的配置參數
圖6 是Izhikevich 提供的源碼在1 000 個生物周期以串行的方式模擬仿真的結果,模擬仿真時間為69 ms,脈沖激活數是7 591。圖7 是在六核單處理器環境下在1 000 個生物周期以并行的方式仿真的結果,模擬仿真時間是805 ms,脈沖激活數是8 256。對比結果顯示兩者脈沖激活數相近,多核并行模擬器生成的脈沖激活結果圖與Izhikevich 提供的實驗結果圖呈現出相同的alpha波段與gamma波段,驗證了模擬器的理論正確性。
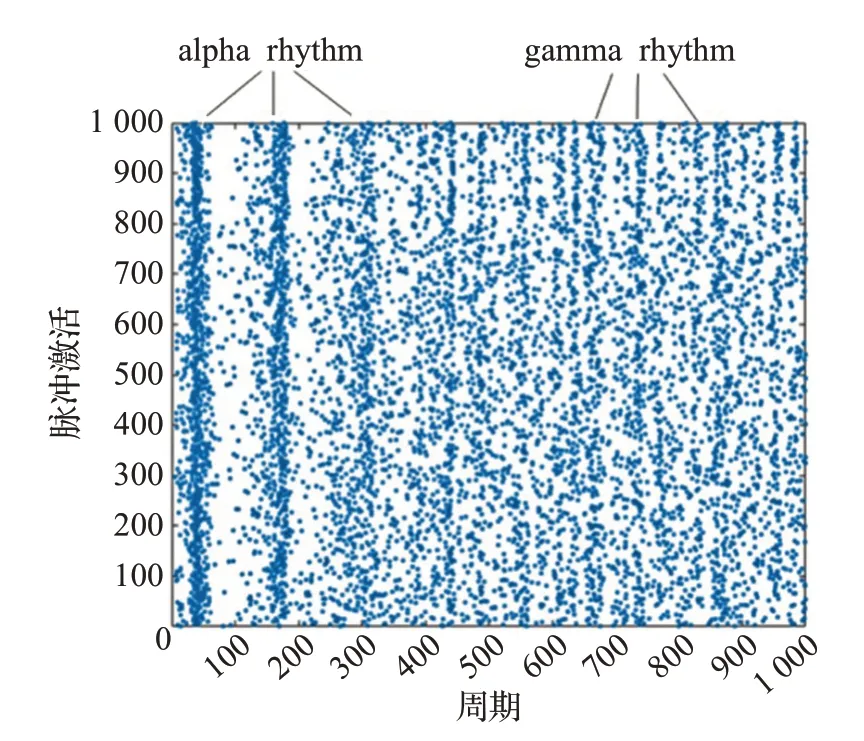
圖6 Izhikevich原文仿真的實驗結果
3.2 大規模脈沖神經網絡的仿真模擬
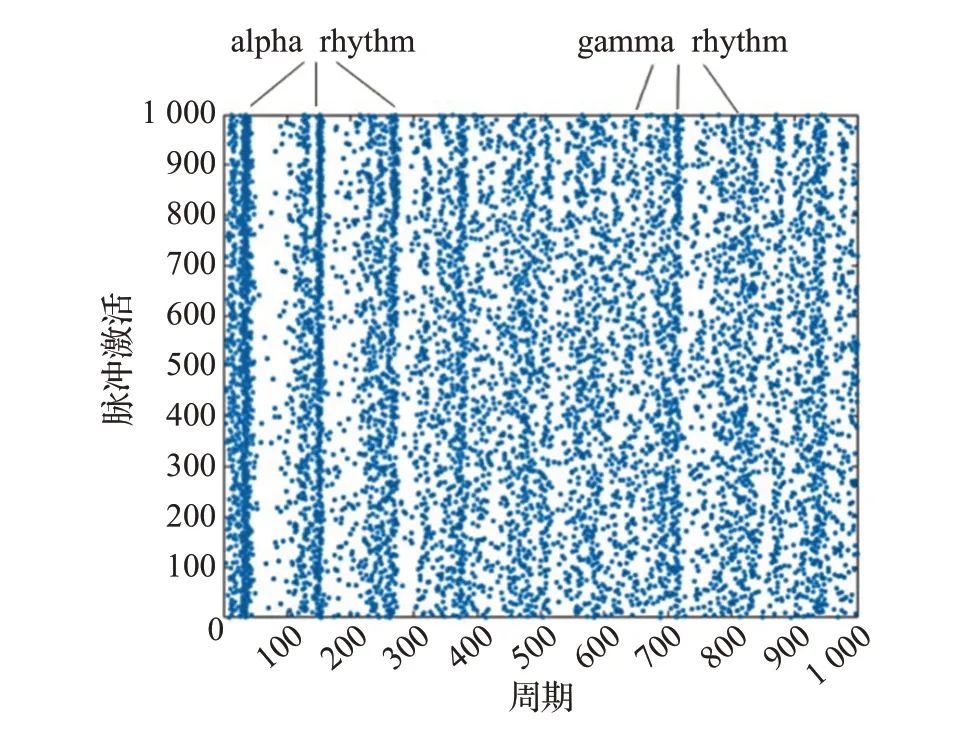
圖7 模擬器仿真的實驗結果
針對Izhikevich模型的串行計算環境與本文并行計算環境做不同數量集的對比實驗,生成三種不同數量級的網絡結構,分別為10 000、50 000、100 000 個Izhikevich模型的脈沖神經元網絡。在10 000個脈沖神經元模型中定義8 000 個興奮性神經元和2 000 個抑制性神經元隨機分布,網絡結構定義為每個神經元與10%的神經元隨機連接。在50 000個脈沖神經元模型中,定義40 000 個興奮性神經元和10 000 個抑制性神經元隨機分布,網絡結構定義為每個神經元與10%的神經元隨機連接。在100 000 個脈沖神經元模型中,定義80 000個興奮性神經元和20 000個抑制性神經元隨機分布,網絡結構定義為每個神經元與10%的神經元隨機連接。配置參數與上個實驗參數相同,10 000、50 000、100 000不同規模數量集的脈沖神經網絡在1 000個生物周期在模擬器上所花費時間如圖8~圖10所示。
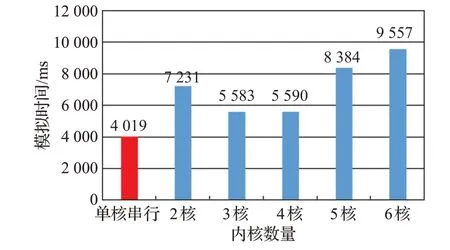
圖8 10 000神經元不同核的模擬時間
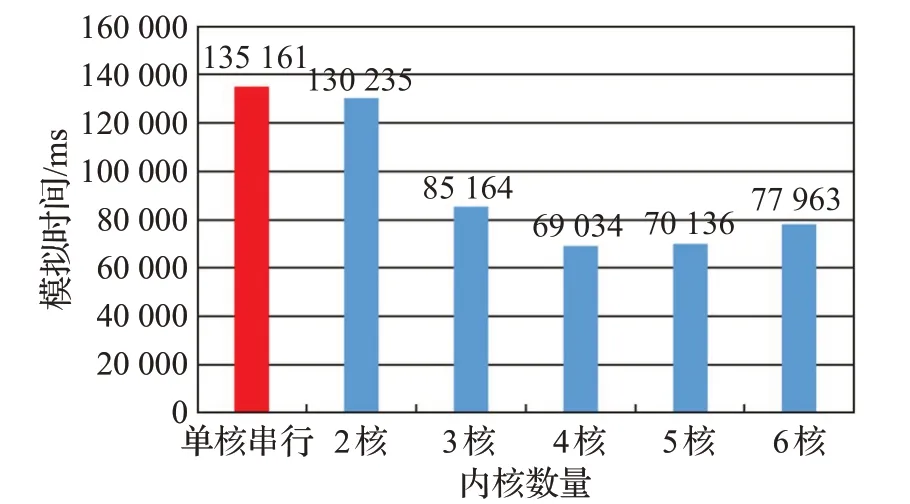
圖9 50 000神經元不同核的模擬時間
3.3 實驗分析
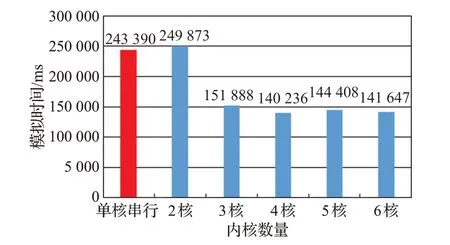
圖10 100 000神經元不同核的模擬時間
在多核并行模擬器下成功復現了1 000個Izhikevich神經元模型的脈沖網絡,在此基礎上進行10 000、50 000、100 000個神經元的脈沖網絡的模擬對比實驗。
仿真設計及實現并行模擬的目的是希望并行模擬比相應的串行模擬更快,為了評估并行計算對仿真模擬效率的提高,通常用加速比[21](Speedup)作為衡量標準,加速比S 可以表示為:

其中,Te為串行程序模擬時間,Tp為并行程序模擬時間。仿真結果如表3所示。
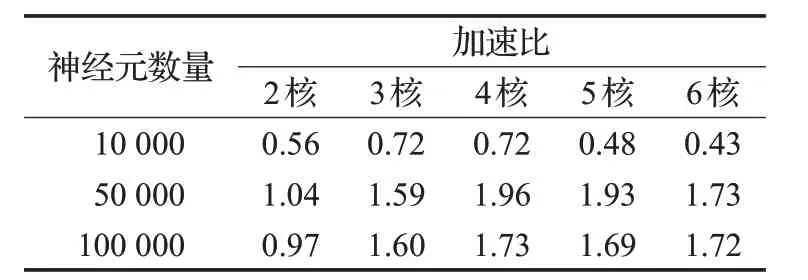
表3 不同規模的并行計算加速比
從表3可以看出,多核并行計算在規模較小的數據集上(10 000數量以下的神經元)效率不如串行計算,但在大規模數據集上并行計算可以提高仿真速度,最大加速比為1.96,當內核達到一定數量時,加速比逐漸收斂。如圖11 所示,本實驗中當內核數量達到4 核后,內核數量越多并行計算的效率卻得不到更好的提高。
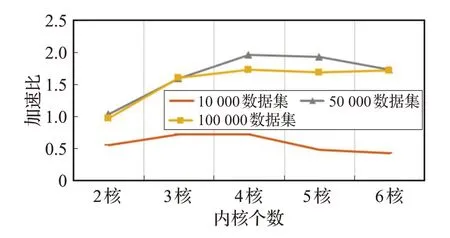
圖11 不同規模數據集的模擬情況
本文在10 000與50 000數量集的實驗中,記錄每個階段花費的時間,如表4 所示,模擬時間開銷主要在神經元狀態的更新與脈沖的傳輸。在10 000數據集中,神經元整體狀態更新所花費時間與內核間脈沖傳輸的時間比為230。在50 000 數據集中,神經元整體狀態更新所花費時間與內核間脈沖傳輸的時間比為516。
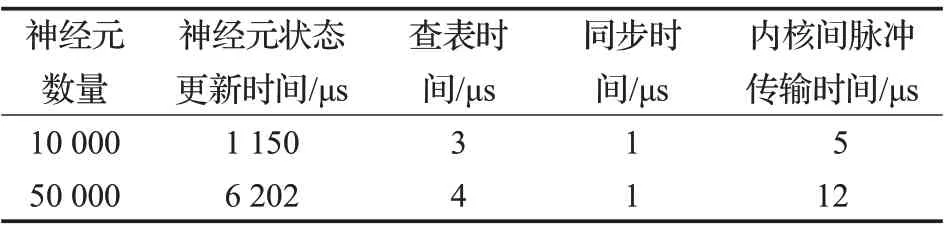
表4 各階段的時間開銷
在多核間的網絡傳輸中,采用共享內存的方式實現多核間的數據傳輸,共享內存是數據共享的最快方式,但多線程之間的數據傳輸需要對緩存區提供互斥條件。當內核外神經元交互頻繁時,多個線程容易同一時刻對同一個緩存區進行訪問而出現線程阻塞的情況,由此導致網絡出現延遲的情況。
綜上分析,當核內計算量不繁重,內核的平均計算速度遠快于網絡傳輸速度時,并行計算效果不如串行計算。當內核平均計算速度接近網絡傳輸速度時(大規模計算下),并行計算速率優于傳統的串行計算。而在大規模計算下,網絡傳輸交互頻繁時,內核越多,周期計算效率不一定得到有效的提高。
4 結論與展望
面對大規模的脈沖神經網絡模擬,一般研究者在個人計算機上以串行的方式難以高效率地進行模擬仿真,本文設計一種多核并行脈沖神經網絡模擬器,為脈沖神經網絡提供一個多核并行計算的模擬環境。在大規模神經網絡模擬中,模擬器可以充分利用每個內核的計算資源,高效率進行脈沖神經網絡的模擬。實驗結果表明,本文設計的模擬器與傳統的串行仿真模擬相比,在大規模數據集的并行計算環境下,速度約為串行計算的兩倍。本實驗也可以為類似的脈沖神經網絡的模擬并行化設計提供參考。
在本文實驗中發現,當內核數達到一定數量時,加速比將逐漸減少,后續的工作中,可以設置多級緩存,減少多核間的網絡傳輸延時。同時還發現,當內核間的神經元交互頻繁時,網絡傳輸效率不高,在后續工作中,可優化神經元的映射算法,將交互頻繁的神經元映射至同一內核中,減少網絡傳輸的負載。在未來的工作中,增添模擬器的接口模擬,以便不同的脈沖神經元模型都可以在模擬器上并行模擬計算。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
網絡安全與數據管理(2022年1期)2022-08-29 03:15:20
導航定位學報(2022年4期)2022-08-15 08:27:00
中學生數理化·中考版(2022年8期)2022-06-14 06:55:24
新世紀智能(數學備考)(2021年9期)2021-11-24 01:14:36
成都醫學院學報(2021年2期)2021-07-19 08:35:14
新世紀智能(數學備考)(2020年9期)2021-01-04 00:25:14
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
光學精密工程(2016年6期)2016-11-07 09:07:19
